高效处理海量慢SQL日志文件:Java与JSQLParser去重方案详解
在大数据处理环境下,慢SQL日志优化是一个必要的步骤,尤其当日志文件达到数GB时,直接操作日志文件会带来诸多不便。本文将介绍如何通过Java和JSQLParser库来解析和去重慢SQL日志,以提高性能和可维护性。
背景
公司生产环境中,某些操作产生的SQL执行时间较长,会记录在慢SQL日志文件中。慢SQL日志文件包含了SQL的执行时间、用户信息、查询语句等内容。由于这些日志文件可能包含大量重复的SQL语句,逐条查看和处理既耗时又低效,因此有必要进行去重操作。
目标
本文旨在通过以下步骤实现慢SQL日志的去重:
- 读取日志文件内容,解析出注释和SQL语句。
- 解析SQL,定义SQL相同的标准。
- 实现对象存储解析出来的各个部分,重写equals和hashCode方法。
- 使用Set集合去重。
- 将去重后的结果写入文件。
工具和依赖
为了实现上述目标,我们将使用以下工具和依赖:
- Java 8或以上版本
- Maven
- JSQLParser库
Maven依赖
<dependency><groupId>com.github.jsqlparser</groupId><artifactId>jsqlparser</artifactId><version>4.9</version>
</dependency>
SQL日志示例
以下是一个慢SQL日志的示例,其中包含了时间、用户信息、数据库模式、查询时间、发送的字节数、时间戳以及SQL语句:
# Time: 2024-05-10T20:30:12.035337+08:00
# User@Host: root[root] @ [192.168.110.110] Id: 13708199
# Schema: laterdatabase Last_errno: 0 Killed: 0
# Query_time: 5.000000 Lock_time: 0.000122 Rows_sent: 1 Rows_examined: 610953 Rows_affected: 0
# Bytes_sent: 56
SET timestamp=1715344212;
SELECT * FROM emp where name = '%三%';
# Time: 2024-05-10T11:28:27.315966+08:00
# User@Host: root[root] @ [192.168.110.110] Id: 13666423
# Schema: scott Last_errno: 0 Killed: 0
# Query_time: 3.290658 Lock_time: 0.000131 Rows_sent: 0 Rows_examined: 0 Rows_affected: 1
# Bytes_sent: 11
SET timestamp=1715311707;
insert into scott.emp ( name, age) values ('张三', 38);
# Time: 2024-05-10T20:30:12.035337+08:00
# User@Host: root[root] @ [192.168.110.110] Id: 13708199
# Schema: laterdatabase Last_errno: 0 Killed: 0
# Query_time: 5.000000 Lock_time: 0.000122 Rows_sent: 1 Rows_examined: 610953 Rows_affected: 0
# Bytes_sent: 56
SET timestamp=1715344212;
SELECT * FROM emp where name = '%三%';
# Time: 2024-05-14T16:18:03.879351+08:00
# User@Host: root[root] @ [192.168.110.110] Id: 13966826
# Schema: scott Last_errno: 0 Killed: 0
# Query_time: 3.120938 Lock_time: 0.000100 Rows_sent: 0 Rows_examined: 1 Rows_affected: 1
# Bytes_sent: 52
SET timestamp=1715674683;
UPDATE emp SET `ename` = '张三', `age` = 18 WHERE `id` = 1045983421034180 ;
# Time: 2024-05-10T20:30:12.035337+08:00
# User@Host: root[root] @ [192.168.110.110] Id: 13708199
# Schema: laterdatabase Last_errno: 0 Killed: 0
# Query_time: 5.000000 Lock_time: 0.000122 Rows_sent: 1 Rows_examined: 610953 Rows_affected: 0
# Bytes_sent: 56
SET timestamp=1715344212;
SELECT * FROM emp where name = '%三%';
# Time: 2024-05-06T01:58:36.959671+08:00
# User@Host: root[root] @ [192.168.110.110] Id: 13387119
# Schema: scott Last_errno: 0 Killed: 0
# Query_time: 6.161219 Lock_time: 0.000875 Rows_sent: 0 Rows_examined: 2137468 Rows_affected: 0
# Bytes_sent: 11
SET timestamp=1714931916;
delete from emp where id = 1;
# Time: 2024-05-10T20:30:12.035337+08:00
# User@Host: root[root] @ [192.168.110.110] Id: 13708199
# Schema: laterdatabase Last_errno: 0 Killed: 0
# Query_time: 5.000000 Lock_time: 0.000122 Rows_sent: 1 Rows_examined: 610953 Rows_affected: 0
# Bytes_sent: 56
SET timestamp=1715344212;
SELECT * FROM emp where name = '%三%';
去重后的效果
# slow.log 未知服务 4
# Time: 2024-05-10T20:30:12.035337+08:00
# User@Host: root[root] @ [192.168.110.110] Id: 13708199
# Schema: laterdatabase Last_errno: 0 Killed: 0
# Query_time: 5.000000 Lock_time: 0.000122 Rows_sent: 1 Rows_examined: 610953 Rows_affected: 0
# Bytes_sent: 56
SET timestamp=1715344212;
SELECT * FROM emp where name = '%三%';# slow.log 未知服务 1
# Time: 2024-05-14T16:18:03.879351+08:00
# User@Host: root[root] @ [192.168.110.110] Id: 13966826
# Schema: scott Last_errno: 0 Killed: 0
# Query_time: 3.120938 Lock_time: 0.000100 Rows_sent: 0 Rows_examined: 1 Rows_affected: 1
# Bytes_sent: 52
SET timestamp=1715674683;
UPDATE emp SET `ename` = '张三', `age` = 18 WHERE `id` = 1045983421034180 ;# slow.log 未知服务 1
# Time: 2024-05-06T01:58:36.959671+08:00
# User@Host: root[root] @ [192.168.110.110] Id: 13387119
# Schema: scott Last_errno: 0 Killed: 0
# Query_time: 6.161219 Lock_time: 0.000875 Rows_sent: 0 Rows_examined: 2137468 Rows_affected: 0
# Bytes_sent: 11
SET timestamp=1714931916;
delete from emp where id = 1;# slow.log 未知服务 1
# Time: 2024-05-10T11:28:27.315966+08:00
# User@Host: root[root] @ [192.168.110.110] Id: 13666423
# Schema: scott Last_errno: 0 Killed: 0
# Query_time: 3.290658 Lock_time: 0.000131 Rows_sent: 0 Rows_examined: 0 Rows_affected: 1
# Bytes_sent: 11
SET timestamp=1715311707;
insert into scott.emp ( name, age) values ('张三', 38);
额外信息说明
# slow.log 未知服务 4为去重时额外添加进去的行,slow.log代表sql所在原文件(如果慢sql日志文件被切分成好多个小文件时方便定位第一次出现的位置)未知服务代表服务名称,如果项目是微服务架构,可以将ip替换为服务名,可读性更高,只需要关注自己负责的未付即可,也可以在输出去重后的文件时按照微服务名称命名,每个微服务的日志单独写入到一个文件.# slow.log 未知服务 4最后的数字表示该sql出现的次数
去重与统计
import lombok.Data;
import lombok.experimental.Accessors;
import net.sf.jsqlparser.parser.CCJSqlParserUtil;
import net.sf.jsqlparser.statement.Statement;
import net.sf.jsqlparser.statement.delete.Delete;
import net.sf.jsqlparser.statement.insert.Insert;
import net.sf.jsqlparser.statement.select.Select;
import net.sf.jsqlparser.statement.select.SelectItem;
import net.sf.jsqlparser.statement.update.Update;
import net.sf.jsqlparser.statement.update.UpdateSet;
import net.sf.jsqlparser.util.TablesNamesFinder;
import org.springframework.util.StringUtils;import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;@Data
@Accessors(chain = true)
public class SlowQueryMetadata {private int count = 1;private String time;private String userAndHost;private String schema;private String queryTime;private String bytesSent;private String timestamp;private String sql;private String fileName;private String appName;/*** 和元数据保持一致格式*/@Overridepublic String toString() {return"# " + fileName + "\t" + appName + "\t" + count + "\n" +time + "\n" +userAndHost + "\n" +schema + "\n" +queryTime + "\n" +bytesSent + "\n" +timestamp + "\n" +sql + "\n";}/*** 去重 不同参数的相同格式的sql* 计数*/@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;SlowQueryMetadata slowQueryMetadata = (SlowQueryMetadata) o;boolean equals = Objects.equals(uniqueString(sql), uniqueString(slowQueryMetadata.sql));if (equals) {slowQueryMetadata.setCount(slowQueryMetadata.getCount() + 1);}return equals;}@Overridepublic int hashCode() {return Objects.hash(uniqueString(sql));}/*** 去除sql中的参数*/private String uniqueString(String sql) {if (!StringUtils.hasText(sql)) {return "";}try {sql = sql.replace("\t", " ");sql = sql.replaceAll("\\s+", " ");// 替换掉注释部分 /*...*/sql = sql.replaceAll("/\\*.*?\\*/", "");// 相对比较耗时Statement statement = CCJSqlParserUtil.parse(new StringReader(sql));if (statement instanceof Insert) {return insertStatement((Insert) statement);}if (statement instanceof Update) {return updateStatement((Update) statement);}if (statement instanceof Delete) {return deleteStatement((Delete) statement);}if (statement instanceof Select) {return selectStatement(statement);}} catch (Exception e) {return sql;}return sql;}private String selectStatement(Statement statement) {List<String> tables = new ArrayList<>(new TablesNamesFinder().getTables(statement));Select select = (Select) statement;try {List<SelectItem<?>> selectItems = select.getPlainSelect().getSelectItems();return "select " + selectItems + " " + tables;} catch (Exception e) {return "select " + tables;}}/*** delete语句只要表名相同 删除条件列相同 即可认为是同一条sql*/private String deleteStatement(Delete delete) {StringBuilder builder = new StringBuilder("delete ");builder.append(delete.getTable().getName().trim());builder.append(" where ");String[] ands = delete.getWhere().toString().toLowerCase().split("and");for (String and : ands) {builder.append(and.split("=")[0].trim()).append(" ");}return builder.toString();}/*** 更新语句只要表名 要更新的列名 where条件列名 相同就认为是同一条sql*/private String updateStatement(Update update) {StringBuilder builder = new StringBuilder("update ");builder.append(update.getTable().getName().trim());builder.append(" column ");for (UpdateSet updateSet : update.getUpdateSets()) {builder.append(updateSet.getColumns().toString().trim());}builder.append(" where ");String[] ands = update.getWhere().toString().toLowerCase().split("and");for (String and : ands) {builder.append(and.split("=")[0].trim()).append(" ");}return builder.toString();}/*** 新增语句只要表相同列相同即可认为是相同sql*/private String insertStatement(Insert statement) {return "insert " + statement.getTable().getName() + " " + statement.getColumns().toString();}}
package com.study.jsqlparser;import com.study.jsqlparser.dto.SlowQueryMetadata;
import com.study.jsqlparser.utils.FileUtils;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.StringUtils;import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.stream.Collectors;@Slf4j
public class SlowQueryAnalysis {@SneakyThrowspublic static void main(String[] args) {
// statistics4Directory();statistics4File();}/*** 对单个慢sql文件文件去重*/private static void statistics4File() throws IOException {String fileFullName = "slow.log";// 去重后的sql文件String deduplicationFileFullName = "deduplication.log";File slowFile = new File(fileFullName);List<String> list = FileUtils.readFileByLine(slowFile);log.info("从文件中读取到的总行数:{}", list.size());List<SlowQueryMetadata> slowQueryMetadataList = getSqlDTOList(list, slowFile.getName());log.info("提取出了:{}条sql", slowQueryMetadataList.size());HashSet<SlowQueryMetadata> set = new HashSet<>(slowQueryMetadataList);log.info("去重后的sql条数:{}", set.size());List<String> deduplication = set.stream().sorted(Comparator.comparingInt(SlowQueryMetadata::getCount).reversed()).map(SlowQueryMetadata::toString).collect(Collectors.toList());FileUtils.write2File(new File(deduplicationFileFullName), deduplication);}/*** 对文件夹下所有慢sql文件去重*/private static void statistics4Directory() throws IOException {String directoryFullName = "E:\\xinao\\sql优化\\0516慢SQL已分割\\sql\\";// 去重后的sql文件String deduplicationFileFullName = "deduplication.sql";Set<SlowQueryMetadata> set = new HashSet<>();for (File file : new File(directoryFullName).listFiles()) {String fileName = file.getName();log.info(fileName);List<String> list = FileUtils.readFileByLine(file);log.info("从文件中读取到的总行数:{}", list.size());List<SlowQueryMetadata> slowQueryMetadataList = getSqlDTOList(list, fileName);log.info("提取出了:{}条sql", slowQueryMetadataList.size());set.addAll(slowQueryMetadataList);}log.info("去重后的sql条数:{}", set.size());List<String> deduplication = set.stream().sorted(Comparator.comparingInt(SlowQueryMetadata::getCount).reversed()).map(SlowQueryMetadata::toString).collect(Collectors.toList());FileUtils.write2File(new File(deduplicationFileFullName), deduplication);}private static List<SlowQueryMetadata> getSqlDTOList(List<String> list, String fileName) {List<SlowQueryMetadata> slowQueryMetadataList = new ArrayList<>();for (int i = 0; i < list.size(); i++) {String line = list.get(i);if (!StringUtils.hasText(line)) {continue;}if (line.trim().startsWith("# Time:")) {SlowQueryMetadata slowQueryMetadata = new SlowQueryMetadata();slowQueryMetadata.setFileName(fileName);slowQueryMetadataList.add(slowQueryMetadata);slowQueryMetadata.setTime(line);boolean multilineComment = false;while (i < list.size() - 1) {i++;line = list.get(i);// 处理多行注释if (line.trim().contains("/*")) {multilineComment = true;continue;}if (line.trim().contains("*/")) {multilineComment = false;continue;}if (multilineComment) {continue;}if (line.trim().startsWith("# Time:")) {i--;break;}if (line.startsWith("# User@Host:")) {slowQueryMetadata.setUserAndHost(line);evaluationAppName(line, slowQueryMetadata);}if (line.startsWith("# Schema:")) {slowQueryMetadata.setSchema(line);}if (line.startsWith("# Query_time:")) {slowQueryMetadata.setQueryTime(line);}if (line.startsWith("# Bytes_sent:")) {slowQueryMetadata.setBytesSent(line);}if (line.startsWith("SET timestamp=")) {slowQueryMetadata.setTimestamp(line);}if (line.toLowerCase().trim().startsWith("insert") || line.toLowerCase().trim().startsWith("delete") || line.toLowerCase().trim().startsWith("update") || line.toLowerCase().trim().startsWith("select")) {StringBuilder sql = new StringBuilder(line);while (i < list.size() - 1) {i++;line = list.get(i);if (line.startsWith("# Time: ")) {i--;break;}if (StringUtils.hasText(line) && !line.trim().startsWith("--")) {sql.append(line);}}slowQueryMetadata.setSql(sql.toString());break;}}}}return slowQueryMetadataList;}private static void evaluationAppName(String line, SlowQueryMetadata slowQueryMetadata) {try {// # User@Host: root[root] @ [192.168.100.101] Id: 13523930String ip = line.substring(line.lastIndexOf("[")+1,line.lastIndexOf("]"));Map<String, String> appMap = getAppMap();String appName = appMap.get(ip);if (!StringUtils.hasText(appName)) {appName = "未知服务";}slowQueryMetadata.setAppName(appName);} catch (Exception e) {slowQueryMetadata.setAppName("异常服务");}}private static Map<String, String> getAppMap() {Map<String, String> appMap = new HashMap<>();appMap.put("192.168.100.101", "com-study-gateway");appMap.put("192.168.100.102", "com-study-gateway");appMap.put("192.168.100.103", "com-study-registry");appMap.put("192.168.100.104", "com-study-registry");appMap.put("192.168.100.104", "com-study-obs-web");appMap.put("192.168.100.106", "com-study-uid-web");return appMap;}}
JSQLParser使用
insert语句
@Test
public void testInsertStatement() {String sql = "INSERT INTO emp (name, age) VALUES ('张三', 38)";try {Statement parse = CCJSqlParserUtil.parse(sql);if (parse instanceof Insert) {Insert insert = (Insert) parse;Table table = insert.getTable();String name = table.getName();log.info(name);Values values = insert.getValues();log.info(values.toString());ExpressionList<Column> columns = insert.getColumns();log.info(columns.toString());}} catch (JSQLParserException e) {e.printStackTrace();}
}
19:02:07.239 [main] INFO com.study.jsqlparser.JSQLParserTest - emp
19:02:07.242 [main] INFO com.study.jsqlparser.JSQLParserTest - VALUES ('张三', 38)
19:02:07.242 [main] INFO com.study.jsqlparser.JSQLParserTest - name, age
delete语句
@Test
public void testDeleteStatement() {String sql = "DELETE FROM emp WHERE id = 1";try {Statement parse = CCJSqlParserUtil.parse(sql);if (parse instanceof Delete) {Delete delete = (Delete) parse;Table table = delete.getTable();log.info(table.toString());Expression where = delete.getWhere();log.info(where.toString());}} catch (JSQLParserException e) {e.printStackTrace();}
}
19:08:04.037 [main] INFO com.study.jsqlparser.JSQLParserTest - emp
19:08:04.039 [main] INFO com.study.jsqlparser.JSQLParserTest - id = 1
update 语句
@Test
public void testUpdateStatement() {String sql = "UPDATE emp SET ename = '张三', age = 18 WHERE id = 1045983421034180";try {Statement parse = CCJSqlParserUtil.parse(sql);if (parse instanceof Update) {Update update = (Update) parse;log.info(update.getTable().toString());List<UpdateSet> updateSets = update.getUpdateSets();for (UpdateSet updateSet : updateSets) {ExpressionList<Column> columns = updateSet.getColumns();log.info(columns.toString());ExpressionList<?> values = updateSet.getValues();log.info(values.toString());}Expression where = update.getWhere();log.info(where.toString());}} catch (JSQLParserException e) {e.printStackTrace();}
}
19:19:18.450 [main] INFO com.study.jsqlparser.JSQLParserTest - emp
19:19:18.452 [main] INFO com.study.jsqlparser.JSQLParserTest - ename
19:19:18.452 [main] INFO com.study.jsqlparser.JSQLParserTest - '张三'
19:19:18.452 [main] INFO com.study.jsqlparser.JSQLParserTest - age
19:19:18.452 [main] INFO com.study.jsqlparser.JSQLParserTest - 18
19:19:18.452 [main] INFO com.study.jsqlparser.JSQLParserTest - id = 1045983421034180
简单select语句
@Test
public void testSelectStatement() {String sql = "SELECT name,age FROM emp WHERE name LIKE '%三%' group by name,age having avg(age) >18 limit 10";try {Statement parse = CCJSqlParserUtil.parse(sql);if (parse instanceof Select) {Select select = (Select) parse;PlainSelect plainSelect = select.getPlainSelect();log.info(plainSelect.getSelectItems().toString());log.info(plainSelect.getFromItem().toString());log.info(plainSelect.getWhere().toString());log.info(plainSelect.getGroupBy().toString());log.info(plainSelect.getHaving().toString());log.info(plainSelect.getLimit().toString());}} catch (JSQLParserException e) {e.printStackTrace();}
}
19:47:22.904 [main] INFO com.study.jsqlparser.JSQLParserTest - [name, age]
19:47:22.906 [main] INFO com.study.jsqlparser.JSQLParserTest - emp
19:47:22.906 [main] INFO com.study.jsqlparser.JSQLParserTest - name LIKE '%三%'
19:47:22.906 [main] INFO com.study.jsqlparser.JSQLParserTest - GROUP BY name, age
19:47:22.906 [main] INFO com.study.jsqlparser.JSQLParserTest - avg(age) > 18
19:47:22.907 [main] INFO com.study.jsqlparser.JSQLParserTest - LIMIT 10
复杂 select 语句
@Test
public void testComplexSelectStatement() {String sql = "select d.deptno,d.dname,avg(sal) from emp e join dept d on e.deptno = d.deptno where e.is_deleted = 0 group by d.deptno,d.dname having avg(sal)>10000 ORDER BY avg(sal) limit 10";try {Statement parse = CCJSqlParserUtil.parse(sql);if (parse instanceof Select) {Select select = (Select) parse;PlainSelect plainSelect = select.getPlainSelect();log.info(plainSelect.getSelectItems().toString());log.info(plainSelect.getFromItem().toString());log.info(plainSelect.getJoins().toString());log.info(plainSelect.getWhere().toString());log.info(plainSelect.getGroupBy().toString());log.info(plainSelect.getHaving().toString());log.info(plainSelect.getOrderByElements().toString());log.info(plainSelect.getLimit().toString());}} catch (JSQLParserException e) {e.printStackTrace();}
}
08:34:32.895 [main] INFO com.study.jsqlparser.JSQLParserTest - [d.deptno, d.dname, avg(sal)]
08:34:32.898 [main] INFO com.study.jsqlparser.JSQLParserTest - emp e
08:34:32.899 [main] INFO com.study.jsqlparser.JSQLParserTest - [JOIN dept d ON e.deptno = d.deptno]
08:34:32.899 [main] INFO com.study.jsqlparser.JSQLParserTest - e.is_deleted = 0
08:34:32.899 [main] INFO com.study.jsqlparser.JSQLParserTest - GROUP BY d.deptno, d.dname
08:34:32.899 [main] INFO com.study.jsqlparser.JSQLParserTest - avg(sal) > 10000
08:34:32.899 [main] INFO com.study.jsqlparser.JSQLParserTest - LIMIT 10
08:34:32.899 [main] INFO com.study.jsqlparser.JSQLParserTest - [avg(sal)]
JSQLParserTest完整代码
import lombok.extern.slf4j.Slf4j;
import net.sf.jsqlparser.JSQLParserException;
import net.sf.jsqlparser.expression.Expression;
import net.sf.jsqlparser.expression.operators.relational.ExpressionList;
import net.sf.jsqlparser.parser.CCJSqlParserUtil;
import net.sf.jsqlparser.schema.Column;
import net.sf.jsqlparser.schema.Table;
import net.sf.jsqlparser.statement.Statement;
import net.sf.jsqlparser.statement.delete.Delete;
import net.sf.jsqlparser.statement.insert.Insert;
import net.sf.jsqlparser.statement.select.PlainSelect;
import net.sf.jsqlparser.statement.select.Select;
import net.sf.jsqlparser.statement.select.Values;
import net.sf.jsqlparser.statement.update.Update;
import net.sf.jsqlparser.statement.update.UpdateSet;
import org.junit.jupiter.api.Test;import java.util.List;@Slf4j
public class JSQLParserTest {@Testpublic void testInsertStatement() {String sql = "INSERT INTO emp (name, age) VALUES ('张三', 38)";try {Statement parse = CCJSqlParserUtil.parse(sql);if (parse instanceof Insert) {Insert insert = (Insert) parse;Table table = insert.getTable();String name = table.getName();log.info(name);Values values = insert.getValues();log.info(values.toString());ExpressionList<Column> columns = insert.getColumns();log.info(columns.toString());}} catch (JSQLParserException e) {e.printStackTrace();}}@Testpublic void testDeleteStatement() {String sql = "DELETE FROM emp WHERE id = 1";try {Statement parse = CCJSqlParserUtil.parse(sql);if (parse instanceof Delete) {Delete delete = (Delete) parse;Table table = delete.getTable();log.info(table.toString());Expression where = delete.getWhere();log.info(where.toString());}} catch (JSQLParserException e) {e.printStackTrace();}}//@Testpublic void testUpdateStatement() {String sql = "UPDATE emp SET ename = '张三', age = 18 WHERE id = 1045983421034180";try {Statement parse = CCJSqlParserUtil.parse(sql);if (parse instanceof Update) {Update update = (Update) parse;log.info(update.getTable().toString());List<UpdateSet> updateSets = update.getUpdateSets();for (UpdateSet updateSet : updateSets) {ExpressionList<Column> columns = updateSet.getColumns();log.info(columns.toString());ExpressionList<?> values = updateSet.getValues();log.info(values.toString());}Expression where = update.getWhere();log.info(where.toString());}} catch (JSQLParserException e) {e.printStackTrace();}}@Testpublic void testSelectStatement() {String sql = "SELECT name,age FROM emp WHERE name LIKE '%三%' group by name,age having avg(age) >18 limit 10";try {Statement parse = CCJSqlParserUtil.parse(sql);if (parse instanceof Select) {Select select = (Select) parse;PlainSelect plainSelect = select.getPlainSelect();log.info(plainSelect.getSelectItems().toString());log.info(plainSelect.getFromItem().toString());log.info(plainSelect.getWhere().toString());log.info(plainSelect.getGroupBy().toString());log.info(plainSelect.getHaving().toString());log.info(plainSelect.getLimit().toString());}} catch (JSQLParserException e) {e.printStackTrace();}}@Testpublic void testComplexSelectStatement() {String sql = "select d.deptno,d.dname,avg(sal) from emp e join dept d on e.deptno = d.deptno where e.is_deleted = 0 group by d.deptno,d.dname having avg(sal)>10000 ORDER BY avg(sal) limit 10";try {Statement parse = CCJSqlParserUtil.parse(sql);if (parse instanceof Select) {Select select = (Select) parse;PlainSelect plainSelect = select.getPlainSelect();log.info(plainSelect.getSelectItems().toString());log.info(plainSelect.getFromItem().toString());log.info(plainSelect.getJoins().toString());log.info(plainSelect.getWhere().toString());log.info(plainSelect.getGroupBy().toString());log.info(plainSelect.getHaving().toString());log.info(plainSelect.getOrderByElements().toString());log.info(plainSelect.getLimit().toString());}} catch (JSQLParserException e) {e.printStackTrace();}}
}
结论
通过本文介绍的方法,可以有效地对数GB的慢SQL日志文件进行去重处理,大幅提高查询效率并减小文件规模。这种方法不仅适用于慢SQL日志处理,还可以扩展到其他类似的日志文件去重需求中。
未来工作
未来的优化方向可以包括:
- 更加智能的SQL标准化方法,以处理更复杂的SQL语句。
- 将处理逻辑进一步并行化,利用多线程和分布式计算提高处理速度。
- 开发图形化界面工具,方便运维人员操作和查看去重后的日志。
通过持续的优化和改进,我们可以进一步提升慢SQL日志处理的效率和准确性,为企业的数据处理和优化提供坚实的基础。
相关文章:

高效处理海量慢SQL日志文件:Java与JSQLParser去重方案详解
在大数据处理环境下,慢SQL日志优化是一个必要的步骤,尤其当日志文件达到数GB时,直接操作日志文件会带来诸多不便。本文将介绍如何通过Java和JSQLParser库来解析和去重慢SQL日志,以提高性能和可维护性。 背景 公司生产环境中&…...
企业内部、与合作伙伴/客户文档协作如何高效安全地收集资料?
在企业的日常运营与对外合作中,「文件收集」是一项特别常见的文档协作需求。例如,公司举办项目经验分享大会,组织者需要提前收集演讲者的材料;新项目启动时,项目经理需要快速收集技术方案和报价方案以便招投标和商务活…...

用Unity创造自己的绿洲
“谢谢你能玩我的游戏!” 希望将来我也能做出一款影响全世界的游戏,就比如现在的《英雄联盟》,或是电影里的《绿洲》!然后也说出这么一句话:谢谢你能玩我的游戏! 阶段性的总结一下 那就展示一下最近完成的…...
服务器数据恢复—KVM虚拟机被误删除如何恢复虚拟磁盘文件?
服务器数据恢复环境&故障: 1台服务器,Linux操作系统EXT4文件系统,部署了数台KVM虚拟机,每台虚拟机包含一个qcow2格式的磁盘文件,和一个raw格式的磁盘文件。 工作人员操作失误删除了3台服务器上的KVM虚拟机…...

工具清单 - 看板工具
# 工具清单 Crepido在新窗口打开 - Create (kanban) boards to track users and projects from flat markdown files. MIT NodejsKanboard在新窗口打开 - Simple and open source visual task board. (Source Code在新窗口打开) MIT PHPmyTinyTodo在新窗口打开 - Simple way t…...

Go微服务: 分布式之发送带有事务消息的示例
分布式之发送带有事务消息 现在做一个RocketMQ的事务消息的 demo 1 )生产者 package mainimport ("context""fmt""time""github.com/apache/rocketmq-client-go/v2""github.com/apache/rocketmq-client-go/v2/prim…...

【go】go初始化命令总结
包初始化 test项目目录下执行 go mod init test go mod tidy生成二进制可执行文件 go build -o test .\main.go...

vue音乐播放条
先看效果 再看代码 <template><div class"footer-player z-30 flex items-center p-2"><div v-if"isShow" class"h-12 w-60 overflow-hidden"><div :style"activeStyle" class"open-detail-control-wrap&…...

halcon实现浓淡补正,中间值补正-抽取暗
代码效果 抽取前 中值抽取暗 halcon函数代码 测试图片参数 NoiseCut:16 Gain:1 输入ImagePart NoiseCut Gain *获取直方图 get_domain (ImagePart, Domain) gray_histo_range(Domain,ImagePart,0,255,256, Histo, BinSize) area_center(Domain, NumPixels, Row, Column) …...
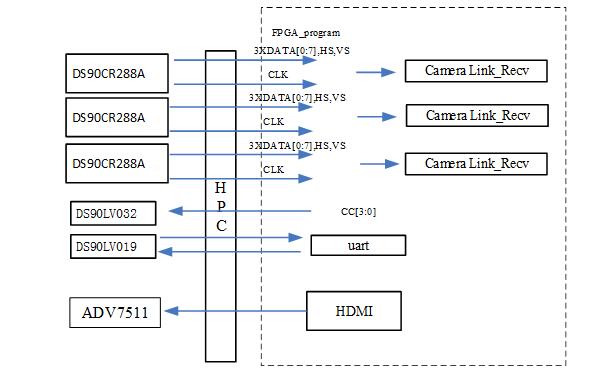
太速科技-FMC213V3-基于FMC兼容1.8V IO的Full Camera Link 输入子卡
FMC213V3-基于FMC兼容1.8V IO的Full Camera Link 输入子卡 一、板卡概述 该板卡为了考虑兼容1.8V电平IO,适配Virtex7,Kintex Ultrascale,Virtex ultrasacle FPGA而特制,如果要兼容原来的3.3V 也可以修改硬件参数。板卡支持1路…...

GPU短缺和模型效率的推动
1. 引言 随着全球GPU短缺和云计算成本的不断上升,开发更高效的AI模型成为了当前的焦点。技术如低秩适应(LoRA)和量化(Quantization)在优化性能的同时,减少了资源需求。这些技术不仅在当前的AI开发中至关重…...

linux在文件夹中查找文件内容
linux在文件夹中查找文件内容 在Linux中,可以通过以下多个途径,在文件夹中查找文件内容: 1、使用grep命令: grep -r "要查找的内容" /path/to/folder-r参数表示递归地在文件夹及其子文件夹中搜索。/path/to/folder是要搜索的文件夹路径。2、使用ack命令 ack …...
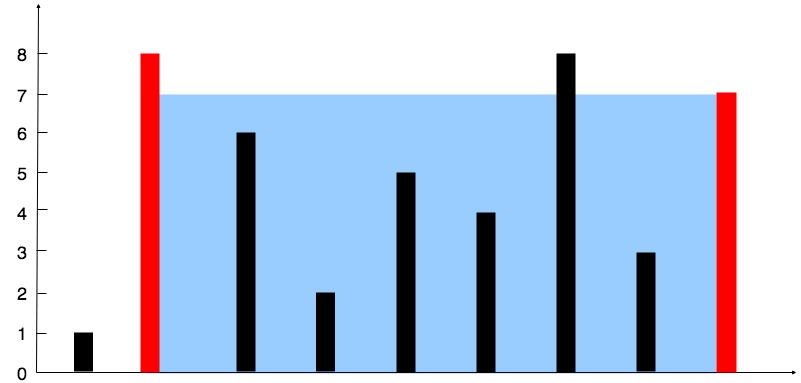
算法:11. 盛最多水的容器
11. 盛最多水的容器 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明:你…...

Hazelcast 分布式缓存 在Seatunnel中的使用
1、背景 最近在调研seatunnel的时候,发现新版的seatunnel提供了一个web服务,可以用于图形化的创建数据同步任务,然后管理任务。这里面有个日志模块,可以查看任务的执行状态。其中有个取读数据条数和同步数据条数。很好奇这个数据…...

分数限制下,选好专业还是选好学校?
目录 分数限制下,选好专业还是选好学校? 方向一:专业解析 1. 专业选择的重要性 2. 不同专业的优势与挑战 3. 个人专业选择经验分享 4. 实际场景下的“专业VS学校”选择方案 方向二:名校效应分析 1. 名校声誉与品牌效应 2…...
软件改为开机自启动
1.按键 win R,输入“shell:startup”命令, 然后就可以打开启动目录了,如下: 2.然后,把要开机启动的程序的图标拖进去即可。 参考:开机启动项如何设置...
)
集群down机的应急和恢复测试(非重做备机)
1. 集群的两台服务器的状态 实例 正常情况主备 ip 端口 node1 主机 192.168.6.6 9088 node2 备机 192.168.6.7 9088 2. 测试的步骤 down掉node1观察node2的状态在node2未自动切换的时候手动将node2调整为单机状态,模拟紧急使用模拟不紧急时࿰…...
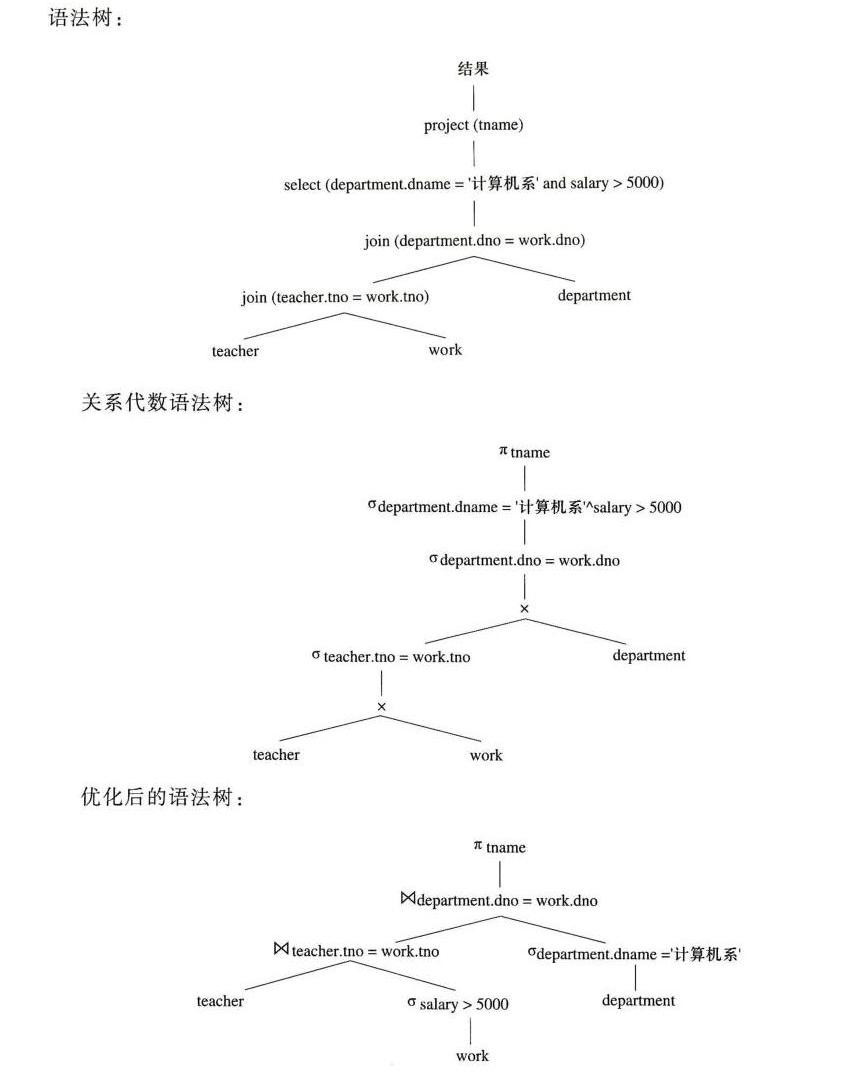
【数据库系统概论复习】关系数据库与关系代数笔记
文章目录 基本概念数据库基本概念关系数据结构完整性约束 关系代数关系代数练习课堂练习 语法树 基本概念 数据库基本概念 DB 数据库, 为了存用户的各种数据,我们要建很多关系(二维表),所以把相关的关系(二…...

赛氪网受邀参加上海闵行区翻译协会年会,共探科技翻译创新之路
在科技飞速发展的时代背景下,翻译行业正面临着前所未有的机遇与挑战。作为连接高校、企业与社会的桥梁,赛氪网在推动翻译创新、促进学术交流方面展现出了独特的魅力。2024年6月9日,在华东师范大学外语学院举办的第十三届上海市闵行区翻译协会…...

项目管理进阶之EVM(挣值管理)
前言 项目管理进阶系列,终于有时间更新啦!!!欢迎持续关注哦~ 上一节博主重点讲了一个环:PDCA,无论各行各业,上到航空航天、下到种地种菜,都离不开对质量的监督和改进。这个环既是一…...
)
用PyTorch复现DKT模型:从Assistment数据集处理到LSTM训练全流程(附完整代码)
用PyTorch构建DKT模型:从数据预处理到LSTM实战全解析 在教育技术领域,追踪学生知识掌握程度一直是个核心挑战。想象一下,当学生在在线学习平台上完成一系列数学题时,系统如何预测他们下一步可能遇到的困难?这正是深度知…...

新手也能看懂的SQL注入绕过实战:以BUUCTF的BabySQL靶场为例,手把手教你双写绕过
从零破解BabySQL:双写绕过的艺术与科学 当你第一次接触CTF比赛中的SQL注入题目时,那种既兴奋又困惑的感觉一定记忆犹新。面对BabySQL这样的靶场,新手常会遇到一个典型困境:明明知道应该用union select来获取数据,却发现…...

正点原子阿尔法开发板uboot编译避坑指南:从源码到SD卡启动的完整流程
正点原子阿尔法开发板uboot编译全流程实战:从环境搭建到SD卡启动的深度解析 第一次接触正点原子阿尔法开发板时,最令人头疼的莫过于uboot的编译和烧录过程。那些看似简单的命令背后,隐藏着无数新手容易踩中的"暗坑"——从文件格式的…...

CompressO终极指南:免费开源视频图片压缩工具完整使用教程
CompressO终极指南:免费开源视频图片压缩工具完整使用教程 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirrors/co/compres…...
)
保姆级教程:用Winbox给ROS配置一线多拨,实测200M宽带叠加效果(附避坑指南)
家庭网络优化实战:Winbox配置多拨提升宽带利用率 家里装了200M宽带,但下载大文件时总觉得速度没跑满?多人同时在线看4K视频就开始卡顿?其实通过简单的路由器配置,你完全有可能突破运营商单线限制,让宽带利用…...

5分钟掌握ExplorerPatcher:Windows界面定制终极指南
5分钟掌握ExplorerPatcher:Windows界面定制终极指南 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 还在为Windows 11的新界面感到…...

如何用Rusted PackFile Manager彻底重构全面战争模组开发工作流?
如何用Rusted PackFile Manager彻底重构全面战争模组开发工作流? 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: h…...
:API延迟、幻觉率、合规审计通过率三维淘汰制解析)
AI大模型选型生死线(2026企业采购决策白皮书):API延迟、幻觉率、合规审计通过率三维淘汰制解析
更多请点击: https://intelliparadigm.com 第一章:AI大模型选型生死线:2026企业采购决策范式重构 当算力成本下降47%、推理延迟压缩至83ms、私有化微调周期缩短至4.2小时,企业不再比拼“谁用了大模型”,而是在验证“谁…...

SignalTap调试进阶:巧用约束与别名捕获FPGA优化后的关键信号
1. 为什么优化后的信号会"消失"? 很多FPGA工程师都遇到过这样的场景:明明在代码里明确定义了reg和wire信号,但在SignalTap里死活找不到它们的身影。这其实不是工具出了问题,而是Quartus的综合优化在"作怪"。…...

MLC LLM:大语言模型通用编译部署实战指南
1. 项目概述:当大语言模型遇见“通用编译” 最近几个月,我身边不少做AI应用和部署的朋友都在讨论一个词: MLC LLM 。这可不是一个新的大模型,而是一个旨在解决大语言模型(LLM)部署“最后一公里”问题的开…...