【将xml文件转yolov5训练数据txt标签文件】连classes.txt都可以生成
将xml文件转yolov5训练数据txt标签文件
- 前言
- 一、代码
- 解析
- 二、使用方法
- 总结
前言
找遍全网,我觉得写得最详细的就是这个博文⇨将xml文件转yolov5训练数据txt标签文件
虽然我还是没有跑成功。那个正则表达式我不会改QWQ,但是不妨碍我会训练ai。
最终成功了,现在就把训练成功的代码贴上来,顺便加点注释,英雄不问出处吧!
-------2024/6/9
一、代码
# 实现xml格式转yolov5格式import os
import xml.etree.ElementTree as ET# 定义一个函数用于从XML文件中提取类别信息
def extract_classes_from_xml(xml_file, all_classes):global treetree = ET.parse(xml_file)for obj in tree.findall('object'):class_name = obj.find('name').textif class_name not in all_classes:all_classes[class_name] = len(all_classes)return all_classesdef main():# 准备保存 classes 信息的文件classes_file_path = 'S:\\IMG\\PCB_DATASET_VOC\\VOCdevkit\\VOC2007\\labels\\classes.txt'# 遍历XML文件夹xml_folder = 'S:\\IMG\\PCB_DATASET_VOC\\VOCdevkit\\VOC2007\\Annotations'txt_folder = 'S:\\IMG\\PCB_DATASET_VOC\\VOCdevkit\\VOC2007\\labels'all_classes = {}# 准备保存类别信息的文件with open(classes_file_path, 'w') as classes_file:for xml_file in os.listdir(xml_folder):if not xml_file.endswith('.xml'):continueimage_id = os.path.splitext(xml_file)[0]# 从XML文件中提取类别信息all_classes = extract_classes_from_xml(os.path.join(xml_folder, xml_file), all_classes)with open(os.path.join(txt_folder, f'{image_id}.txt'), 'w') as txt_file:for obj in ET.parse(os.path.join(xml_folder, xml_file)).findall('object'):class_name = obj.find('name').textclass_id = all_classes[class_name]bbox = obj.find('bndbox')x_min = float(bbox.find('xmin').text)y_min = float(bbox.find('ymin').text)x_max = float(bbox.find('xmax').text)y_max = float(bbox.find('ymax').text)width = x_max - x_minheight = y_max - y_minx_center = x_min + width / 2y_center = y_min + height / 2img_width = float(tree.find('size').find('width').text)img_height = float(tree.find('size').find('height').text)x_center /= img_widthy_center /= img_heightwidth /= img_widthheight /= img_heightline = f"{class_id} {x_center} {y_center} {width} {height}\n"txt_file.write(line)print(f" {image_id}.xml to {image_id}.txt 转换完成")for class_name, class_id in all_classes.items():classes_file.write(f"{class_name}\n")print("转换完成,祝愿您顺利")if __name__ == "__main__":main()
解析
难点只有with open(classes_file_path, 'w') as classes_file这里的
从一个XML文件中读取标注信息,并将这些信息转换成用于训练图像识别模型的格式。
下面是对这段代码的逐行解释:
- 打开文件用于写入类别信息
with open(classes_file_path, 'w') as classes_file:
这里打开了classes_file_path指向的文件用于写入。classes_file会用来保存所有的类别名称。
- 这段代码遍历了xml_folder中的所有文件。os.listdir()返回一个包含指定目录中所有文件和目录名称的列表。
for xml_file in os.listdir(xml_folder):
- 这个条件检查确保只处理以.xml结尾的文件。如果不是XML文件,则跳过当前循环迭代。
if not xml_file.endswith('.xml'): continue
- 这里使用os.path.splitext()函数将文件名和扩展名分离,并获取文件名部分。image_id现在包含了没有扩展名的文件名。
image_id = os.path.splitext(xml_file)[0]
os.path.splitext()函数可以将文件路径分割成路径名和文件扩展名两部分,并以元组的形式返回。
这样做的原因是因为在很多操作系统中,文件名通常包含了文件的路径以及文件扩展名,如/path/to/file.xml。通过使用os.path.splitext(),我们可以方便地分离出文件名和扩展名部分,进而更方便地对它们进行处理。
例如,假设xml_file的值为"example.xml",那么os.path.splitext(xml_file)将返回(“example”, “.xml”),然后通过[0]索引取得文件名部分"example"。这样就实现了将文件名和扩展名分离的目的。
总的来说,os.path.splitext()函数在处理文件路径和文件名时非常实用,能够帮助我们轻松地获取文件名和扩展名,从而进行文件处理操作。
- 从XML文件中提取类别信息
all_classes = extract_classes_from_xml(os.path.join(xml_folder, xml_file), all_classes)
这里调用了extract_classes_from_xml()函数,一个从XML文件中提取所有类别名称的函数,并将这些类别名称保存到一个字典中,其中类别名称是键,而类别ID是值。
函数extract_classes_from_xml接收两个参数:xml_file和all_classes。
1、xml_file是XML文件的路径,
2、all_classes是一个字典,用于存储已知的所有类别名称和它们的ID。
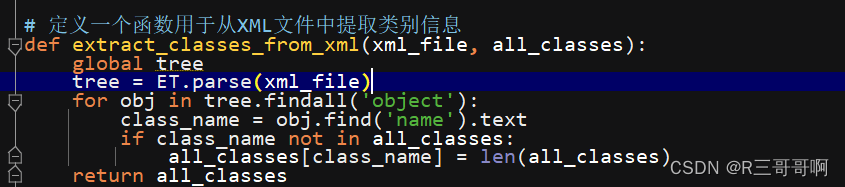
在函数内部,首先使用ET.parse(xml_file)解析XML文件,并将其存储在全局变量tree中。然后,使用tree.findall(‘object’)遍历所有 < object >标签。对于每个< object >标签,提取其name标签中的文本,即类别名称。如果这个类别名称之前没有在all_classes字典中出现过,那么就将其添加到字典中,并设置其ID为当前类别ID。这里的类别ID是字典中类别名称的数量,即len(all_classes)。
最后,函数返回更新后的类别字典all_classes。这个字典包含了所有在XML文件中出现的类别名称及其对应的ID。
在主代码中,每次调用extract_classes_from_xml时,都会更新all_classes字典,因为它包含了所有之前遇到过的类别名称。这样,最终all_classes将包含所有的类别名称和它们的ID,这些信息将被用于创建训练数据文件和类别文件。
- 这段代码打开了一个文件用于写入,该文件位于txt_folder中,文件名是image_id加上.txt扩展名。
with open(os.path.join(txt_folder, f'{image_id}.txt'), 'w') as txt_file:
- 这段代码遍历了XML文档中的所有< object >标签。ET是ElementTree的缩写,.parse()函数解析XML文件
for obj in ET.parse(os.path.join(xml_folder, xml_file)).findall('object'):
- 这段代码从每个< object >标签中提取类别的名称,并通过all_classes字典将类别名称映射到一个类别ID。
class_name = obj.find('name').text
class_id = all_classes[class_name]
- 提取了边界框的四个坐标信息,即左上角和右下角的(x, y)值。
bbox = obj.find('bndbox')
x_min = float(bbox.find('xmin').text)
y_min = float(bbox.find('ymin').text)
x_max = float(bbox.find('xmax').text)
y_max = float(bbox.find('ymax').text)
- 计算了边界框的宽度、高度以及中心点的位置。
width = x_max - x_min
height = y_max - y_min
x_center = x_min + width / 2
y_center = y_min + height / 2
- 这里提取了图像的宽度和高度。
img_width = float(tree.find('size').find('width').text)
img_height = float(tree.find('size').find('height').text)
- 将边界框的坐标和尺寸进行归一化,即将它们除以图像的宽度和高度,使它们落在0到1之间。
x_center /= img_width
y_center /= img_height
width /= img_width
height /= img_height
- 生成了保存到文本文件的一行数据,其中包含了类别ID、归一化后的边界框中心坐标、宽度和高度。
line = f"{class_id} {x_center} {y_center} {width} {height}\n"
txt_file.write(line)
最后,将每个XML文件中的目标信息转换并写入一个对应的txt文件中,同时将类别信息写入classes_file中。整个过程将针对每个XML文件中的目标执行,最终完成目标检测训练数据的准备工作。
二、使用方法
网上下载的数据集有的是xml的,复制路径
创建一个目标位置的文件夹。
将地址填入合适的地方

运行就行了
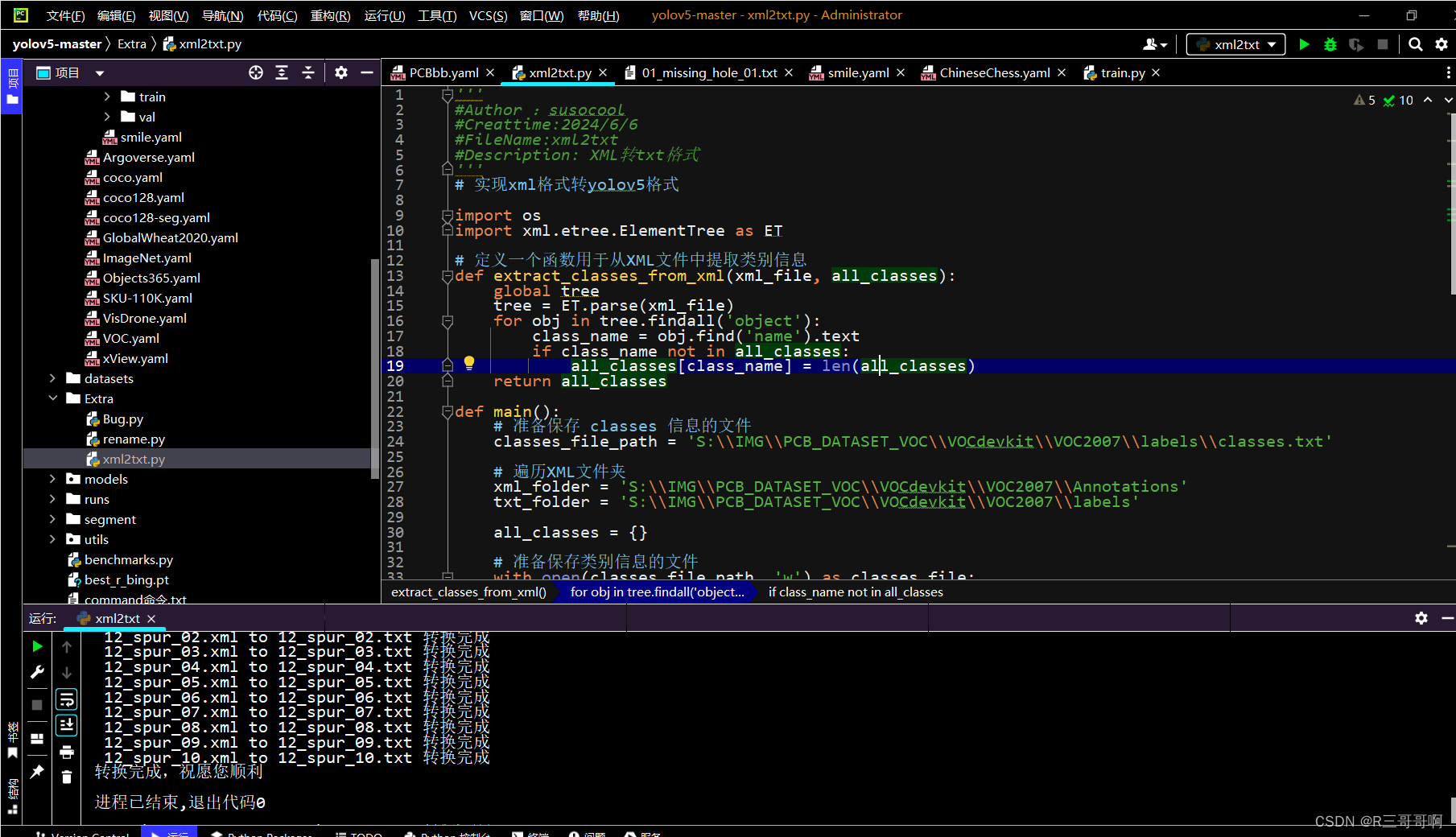
对应的文件也可以了
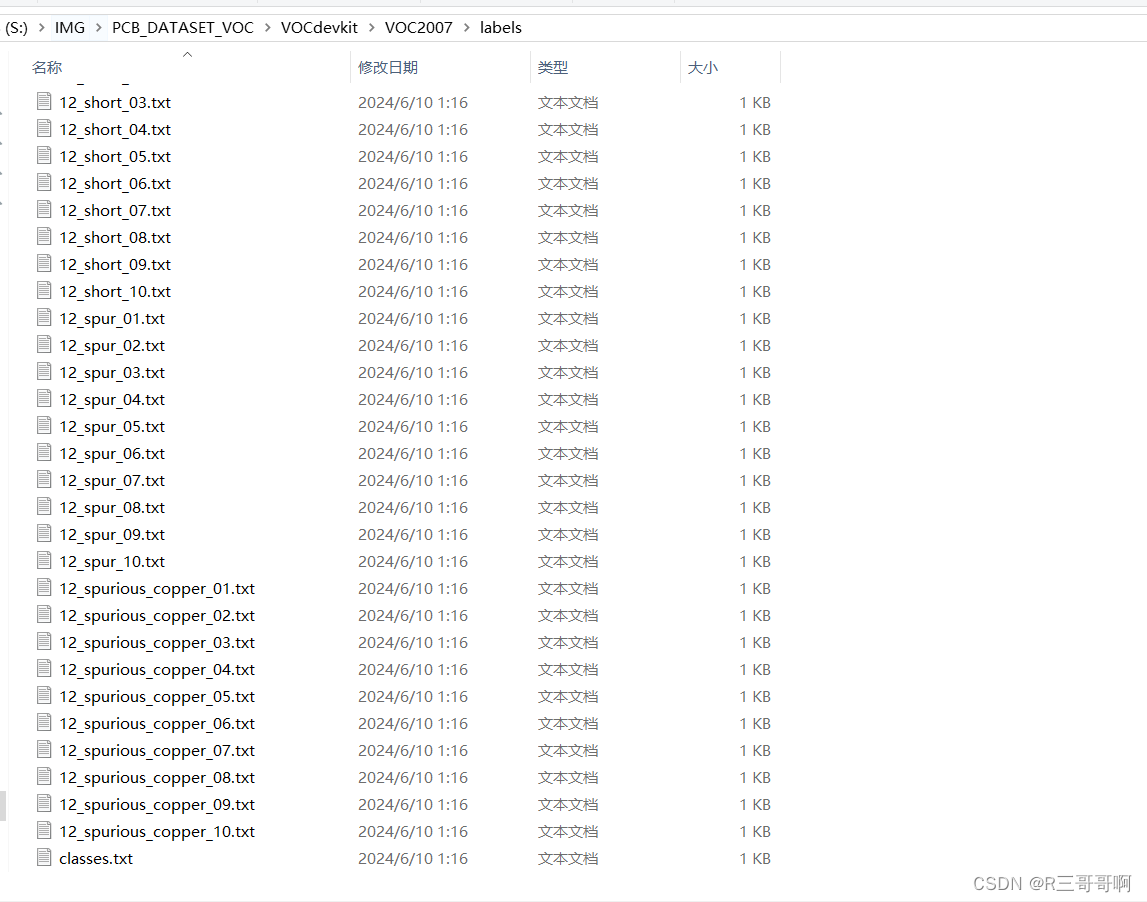
连classes都能识别出来!!!
总结
这篇文章依旧没有总结
相关文章:
【将xml文件转yolov5训练数据txt标签文件】连classes.txt都可以生成
将xml文件转yolov5训练数据txt标签文件 前言一、代码解析 二、使用方法总结 前言 找遍全网,我觉得写得最详细的就是这个博文⇨将xml文件转yolov5训练数据txt标签文件 虽然我还是没有跑成功。那个正则表达式我不会改QWQ,但是不妨碍我会训练ai。 最终成功…...

针对k8s集群已经加入集群的服务器进行驱逐
例如k8s 已经有很多服务器,现在由于服务器资源过剩,需要剥离一些服务器出来 查找节点名称: kubectl get nodes设置为不可调度: kubectl cordon k8s-node13恢复可调度 kubectl uncordon k8s-node13在驱逐之前先把需要剥离驱逐的节…...
go 1.22 增强 http.ServerMux 路由能力
之前 server func main() {http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {fmt.Println("Received request:", r.URL.Path)fmt.Fprintf(w, "Hello, client! You requested: %s\n", r.URL.Path)})log.Println("Serv…...
)
赶紧收藏!2024 年最常见 20道设计模式面试题(二)
上一篇地址:赶紧收藏!2024 年最常见 20道设计模式面试题(一)-CSDN博客 三、解释抽象工厂模式,并给出一个实际应用的例子。 抽象工厂模式是一种创建型设计模式,用于创建一系列相关或依赖对象的接口&#x…...

Java面向对象设计 - Java泛型约束
Java面向对象设计 - Java泛型约束 无限通配符 通配符类型由问号表示,如<?> 。 对于通用类型,通配符类型是对象类型用于原始类型。 我们可以将任何已知类型的泛型分配为通配符类型。 这里是示例代码: // MyBag of String type M…...

什么是内存泄漏?如何避免内存泄漏?
**内存泄漏(Memory Leak)**是指在程序运行过程中,已经动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。内存泄漏具有隐蔽性、积累性的特征&#x…...
(Python))
元组(tuple)(Python)
文章目录 一、定义二、常用操作 一、定义 tuple ("张三", "李四", "王二")二、常用操作 分类关键字/函数/方法说明查询元组[索引]根据索引取值,索引不存在会报错len(元组)元组长度(元素个数)值 in 元组&…...

【C++进阶学习】第二弹——继承(下)——挖掘继承深处的奥秘
继承(上):【C进阶学习】第一弹——继承(上)——探索代码复用的乐趣-CSDN博客 前言: 在前面我们已经讲了继承的基础知识,让大家了解了一下继承是什么,但那些都不是重点,今…...
LangChain-ChatGLM本地搭建|报错合集(win10)
安装过程 1. 创建虚拟环境 conda create -n langchain-chatglm python3.10 conda activate langchain-chatglm2. 部署 langchain-ChatGLM git clone https://github.com/imClumsyPanda/langchain-ChatGLMpip3 install -r requirements.txt pip3 install -U gradio pip3 inst…...

IP地址简介
一、IP地址 Internet Protocol Address,即网络层协议地址,是IP的缩写。 二、IP地址的作用 为什么不直接使用MAC,又加了一个IP地址呢? 事实上底层传输,最终使用的肯定是MAC地址,但是由于在以前&#x…...

谈吐的艺术
被人表扬,该怎么回应 你越是说自己其实没那么好, 对方出于客气, 就越是要证明你其实比你说的好得多。 O可能遇到的问题 每当工作和学习上做出点成绩,有人夸奖我的时候,我都会觉得很尴尬。因为不谦虚会得罪人ÿ…...

Linux 和 分区
文章目录 流程挂载设备文件名 Linux 下各分区的含义家目录 流程 在windows中,一个硬盘要使用只需要分区、格式化之后就可以使用了 在linux中,除了分区和格式化之外,还需要一个叫挂载的操作 挂载 挂载,就相当于windows环境下的写…...

⭐ ▶《强化学习的数学原理》(2024春)_西湖大学赵世钰 Ch3 贝尔曼最优公式 【压缩映射定理】
PPT 截取必要信息。 课程网站做习题。总体 MOOC 过一遍 1、视频 学堂在线 习题 2、过 电子书,补充 【下载:本章 PDF 电子书 GitHub 界面链接】 [又看了一遍视频] 3、总体 MOOC 过一遍 习题 学堂在线 课程页面链接 中国大学MOOC 课程页面链接 B 站 视频链…...

Pikachu上的CSRF以及NSSCTF上的[NISACTF 2022]bingdundun~、 [SWPUCTF 2022 新生赛]xff
目录 一、CSRF CSRF(get) login CSRF(post) CSRF Token 二、CSRF的相关知识点 (1)什么是CSRF? (2)工作原理 (3)CSRF漏洞形成的条件 1、用户要在登录状态(即浏览器保存了该…...

大数据分析-二手车用户数据可视化分析
项目背景 在当今的大数据时代,数据可视化扮演着至关重要的角色。随着信息的爆炸式增长,我们面临着前所未有的数据挑战。这些数据可能来自社交媒体、商业交易、科学研究、医疗记录等各个领域,它们庞大而复杂,难以通过传统的数据处…...
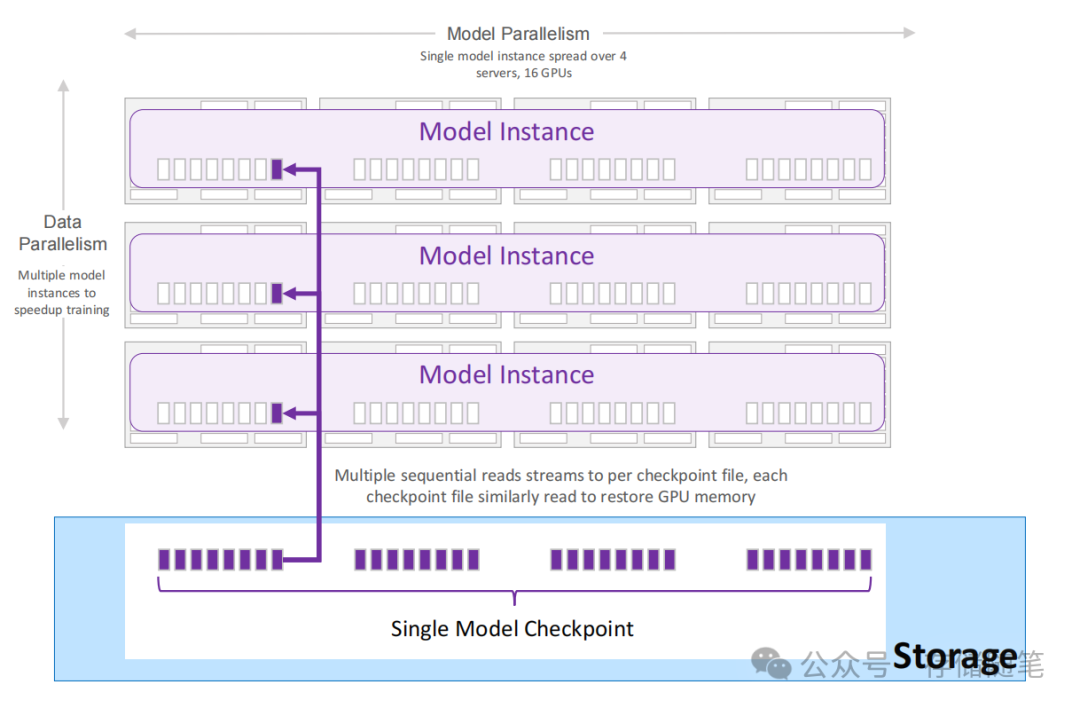
AI训练Checkpoint对存储的影响
检查点(Checkpoints)是机器学习和深度学习训练过程中的一个重要机制,旨在定期保存训练状态,以便在训练过程中遇到失败或中断时能够从中断处恢复训练,而无需从头开始。 随着模型参数量的剧增,Checkpoint文件…...

Python笔记 - 正则表达式
正则表达式(Regular Expression,简称regex)是一种强大的工具,用于匹配字符串模式。在Python中,正则表达式通过re模块提供。本文将带你深入了解Python中的正则表达式,从基础概念到高级用法。 1. 什么是正则…...

安卓网络通信(多线程、HTTP访问、图片加载、即时通信)
本章介绍App开发常用的以下网络通信技术,主要包括:如何以官方推荐的方式使用多线程技术,如何通过okhttp实现常见的HTTP接口访问操作,如何使用Dlide框架加载网络图片,如何分别运用SocketIO和WebSocket实现及时通信功能等…...

Virtual Memory Primitives for User Program翻译
Virtual Memory Primitives for User Program 安德鲁阿普尔(Andrew Appel)和李凯(Kai Li) 普林斯顿大学计算机科学系 摘要 传统上,内存管理单元(MMUS)被操作系统用于实现磁盘分页的虚拟内存…...
网络基础2
目录 应用层HTTP协议认识URLurlencode和urldecode HTTP协议格式http请求格式http响应格式 HTTP的方法GET与POST的区别 HTTP的状态码HTTP常见HeaderCookie与Session 传输层在谈端口号端口号范围划分认识知名端口号netstatpidof UDP协议UDP协议端格式UDP的特点面向数据报UDP的缓冲…...

不只是连线:用立创EDA做PCB布局时,这5个提升电路板可靠性的细节你注意了吗?
不只是连线:用立创EDA做PCB布局时,这5个提升电路板可靠性的细节你注意了吗? 在电子设计领域,PCB布局的质量往往决定了产品的最终表现。许多工程师能够完成基本的电路连接,却容易忽视那些看似微小却至关重要的设计细节。…...

如何快速构建智能图像篡改检测系统:3步实战指南
如何快速构建智能图像篡改检测系统:3步实战指南 【免费下载链接】image_tampering_detection_references A list of papers, codes and other interesting collections pertaining to image tampering detection and localization. 项目地址: https://gitcode.com…...

BilibiliDown:如何5分钟内轻松下载B站视频到本地收藏
BilibiliDown:如何5分钟内轻松下载B站视频到本地收藏 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi…...
)
DeepSeek-Docker性能压测对比报告:NVIDIA A10 vs L4,吞吐量差异达3.7倍(附Prometheus监控模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-Docker性能压测对比报告:NVIDIA A10 vs L4,吞吐量差异达3.7倍(附Prometheus监控模板) 在真实生产级 DeepSeek-R1 模型推理服务部署场景下&#…...

一键获取学术引用数据:Zotero引用统计插件完整指南
一键获取学术引用数据:Zotero引用统计插件完整指南 【免费下载链接】zotero-citationcounts Zotero plugin for auto-fetching citation counts from various sources 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-citationcounts 你是否曾为手动追踪…...

低速率串行信号调试与MSO应用实战指南
1. 低速率串行信号调试的核心挑战在嵌入式系统设计中,低速率串行信号(Low Speed Serial, LSS)承担着模块间通信的关键任务。与高速信号不同,LSS通常工作在1MHz以下频率,采用UART、I2C、SPI等协议。这类信号看似简单&am…...

黑苹果安装实战指南:1000+机型EFI配置与工具集深度解析
黑苹果安装实战指南:1000机型EFI配置与工具集深度解析 【免费下载链接】Hackintosh Hackintosh long-term maintenance model EFI and installation tutorial 项目地址: https://gitcode.com/gh_mirrors/ha/Hackintosh 在非苹果硬件上运行macOS(俗…...

3个颠覆性功能:Topit如何重新定义macOS窗口层级管理
3个颠覆性功能:Topit如何重新定义macOS窗口层级管理 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否曾在编写代码时,需要同时查看…...

告别龟速下载:手把手教你离线部署Wine 5.0的Mono与Gecko组件
1. 为什么你需要离线安装Wine组件 每次在Linux上配置Wine运行Windows程序时,最让人头疼的就是等待Mono和Gecko组件下载的过程。我曾经在一个网络状况不太好的服务器上安装Wine,光是下载这两个组件就花了整整三个小时,期间还因为网络波动失败…...

“房东“骗完租客,转头问AI“会被抓吗“?警方:这就来告诉你答案
一场堪称"教科书级"的黑色幽默2026年5月,杭州上城区发生了一起让人哭笑不得的案件。一个骗子刚刚诈骗完租客,转头打开AI,小心翼翼地问了一句:"我朋友骗了人,会被抓吗?"然后——警察破门…...