ICASSP 2023论文模型开源|语音分离Mossformer
人类能在复杂的多人说话环境中轻易地分离干扰声音,选择性聆听感兴趣的主讲人说话。但这对机器却不容易,如何构建一个能够媲美人类听觉系统的自动化系统颇具挑战性。
本文将详细解读ICASSP2023本届会议收录的单通道语音分离模型Mossformer论文,以及如何基于开发者自有数据进行该模型的调优训练。
▏语音分离模型能做什么?
由于麦克风采集的音频信号中除了主说话人之外,通常还包括噪声、其他人说话的声音、混响等干扰。语音分离的目标即是把独立的目标语音信号从混合的音频信号中分离出来。其应用范围不仅包括听力假体、移动通信、鲁棒的自动语音以及说话人识别等,最近也被广泛应用在各个语音方向的机器学习场景中。
根据干扰的不同,语音分离任务可以是单纯的多说话人分离,也可以包括噪声消除和解混响等附加任务。在没有噪声和混响的情况下,单纯的语音分离任务已经被研究了几十年,从最初的传统信号处理算法如独立分量分析(ICA)和非负矩阵分解(NMF),到最近的基于端到端深度神经网络(DNN)算法,算法的分离性能有了明显的进步。至今,语音分离仍然是一个高度活跃的研究领域,我们最新推出的MossFormer语音分离模型,是在现有深度学习算法的基础上,通过融入更先进的门控注意力机制和带记忆的深度卷积网络,从而更有效地对长语音序列进行建模和学习,大幅提升深度学习分离算法的性能。
目前比较流行的语音分离模型架构一般由三个主要组成模块:编码器、分离器和解码器。编码器的作用是将原始的语音信号转换为高维的表示,类似于傅立叶变换后的频谱信息,但使用的转换不是预先设定好的,而是通过训练模型自己学习到的。分离器的作用是根据输入的高维表示来估计语音的分量,并将其分离成多个独立的语音信号。解码器的作用是将分离出的语音信号重新编码成原始语音信号的形式。下图给出的是语音分离模型架构的示意图:
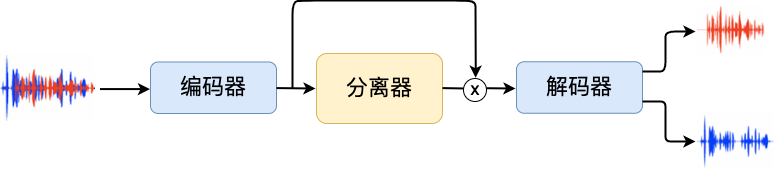
图1. 语音分离模型架构示意图
分离器模块是影响语音分离性能的关键模块,主要的架构包括深度卷积网络(例如:Conv-TasNet)、循环神经网络(例如:DPRNN),和Transformer(例如:SepFormer)等,其中基于自注意力机制的Transformer架构在最近的研究中表现出了很好的性能。利用自注意力机制可以有效地捕捉长距离的依赖关系,从而更好地建模语音信号。
与传统的循环神经网络相比,Transformer可以并行计算,提高了计算效率,同时也可以更好地避免梯度消失的问题。基于Transformer的架构在单声道语音分离任务中获得了显著的性能改进,但和最近给出的分离Cramer-Rao上限相比,仍存在明显差距,主要原因在于,由于注意力计算的二次复杂度,Transformer架构的自注意力受限于上下文长度。为了能够处理极长的输入序列,当前的Transformer模型使用双路径框架,将输入序列分成较小的块并分别处理块内和块间的信息,跨块的长距离信息依赖需要通过中间状态隐式建模,这一事实可能对长距离建模能力产生负面影响,导致模型次优表现。
▏2023 ICASSP-MossFormer模型
为了有效解决双路径架构中跨块间的间接元素交互问题,我们提出了一种基于联合自注意力的带门控单头Transformer语音分离模型架构,并使用卷积增强模块,命名为MossFormer(Monaural speech separation Transformer)。
MossFormer采用联合局部和全局自注意力架构,同时对局部段执行完整自注意力运算和对全局执行线性化低成本自注意力运算。联合注意力使MossFormer模型能够直接处理全序列元素交互,真正有效地捕捉长距离的依赖关系,解决双路径模型在远程元素交互的建模能力问题。此外,我们采用了强大的带注意力门控机制,可以使用大幅简化的单头自注意力,MossFormer除了关注长距离建模外,还使用深度卷积来帮助模型更好地处理局部的特征,从而提高模型的性能。相关工作已被语音顶会ICASSP 2023录用。
模型架构
MossFormer语音分离模型由一个卷积编码器-解码器结构和一个掩蔽网络组成(见图2)。编码器-解码器结构负责特征提取和波形重建,其中,编码器负责特征提取,由一维 (1D) 卷积层 (Conv1D) 和整流线性单元 (ReLU) 组成,后者将编码输出限制为非负值。解码器是一维转置卷积层,它使用与编码器相同的内核大小和步幅。
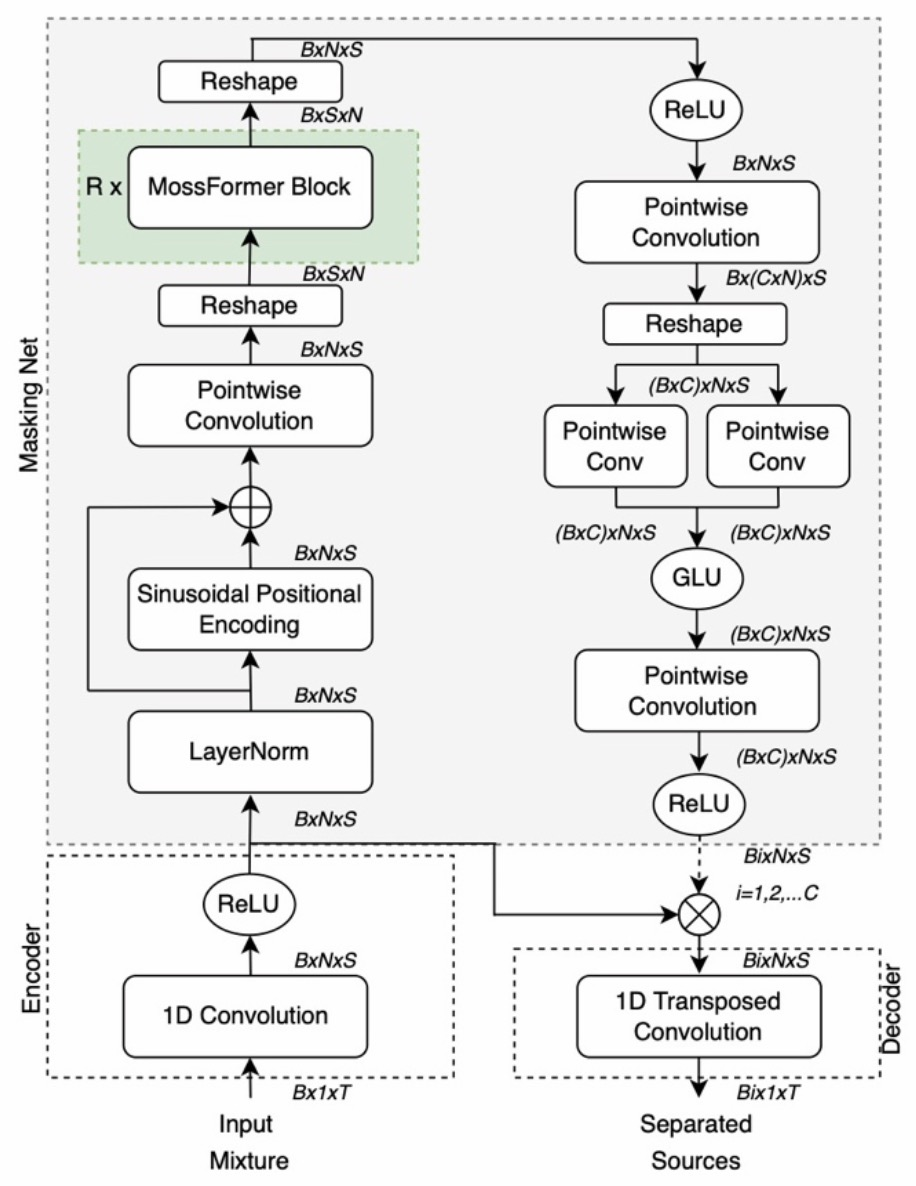
图2. MossFormer模型整体结构示意图
掩码网络执行从编码器输出到𝐶组掩码的非线性映射,掩码网络的主组成部分是MossFormer模块,该模块是基于带卷积增强联合自注意力(convolution-augmented joint self-attentions)的门控单头自注意力架构(gated single-head transformer architecture )开发出来的。具体的,一个MossFormer 模块由四个卷积模块、缩放和偏移操作、联合局部和全局单头自注意力(SHSA)以及三个门控操作组成,负责进行长序列的处理。详细模块结构见图3。在MossFormer模块中,序列由卷积模块和注意力门控机制进行处理。卷积模块使用线性投影和深度卷积来处理序列。注意力门控机制执行联合局部和全局自注意力和门控操作。MossFormer模块仅学习残差部分并应用跳跃连接从输入连接到输出以提升训练效率。当前MossFormer块的输出被输入到下一个MossFormer块中。该过程被重复R次。
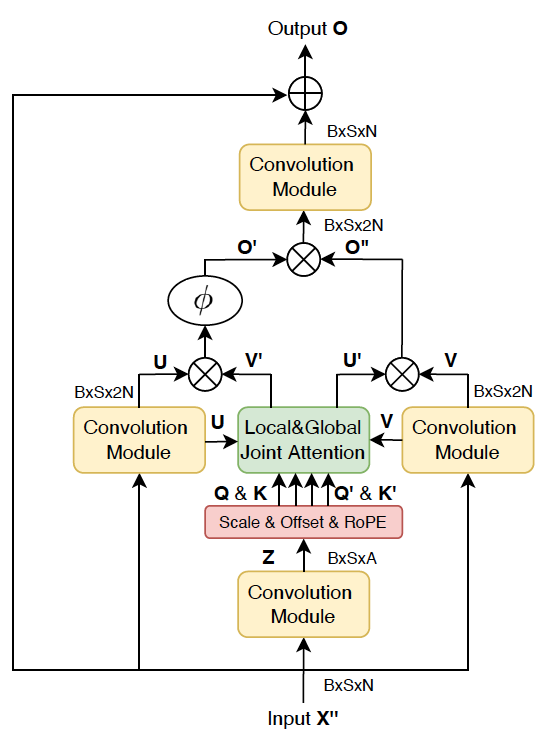
图3. MossFormer模块架构示意图
模型性能
我们在公开数据集WSJ0-2/3mix 和 WHAM!/WHAMR!上对模型进行了性能对比验证。WSJ0-2/3mix数据集是基于WSJ0数据语料库生成的。包括30小时的训练数据集、10小时的验证数据集、和5小时的测试集,混合语音是由随机选择的不同说话者的语音混合而成,混合语音按照-5 dB和5 dB随机信噪比(SNR)进行混合。该数据集包含2个和3个说话人,为纯净数据集,不含噪声和混响。
WHAM!数据集是在WSJ0-2mix数据集的基础上,通过进一步添加独特的环境噪声生成的,环境噪声主要包括从餐厅、咖啡馆、酒吧和公园录制的噪声。WHAMR! 数据集进一步扩展了WHAM!数据集,除了环境噪声之外,还为语音信号添加了人工混响效果。
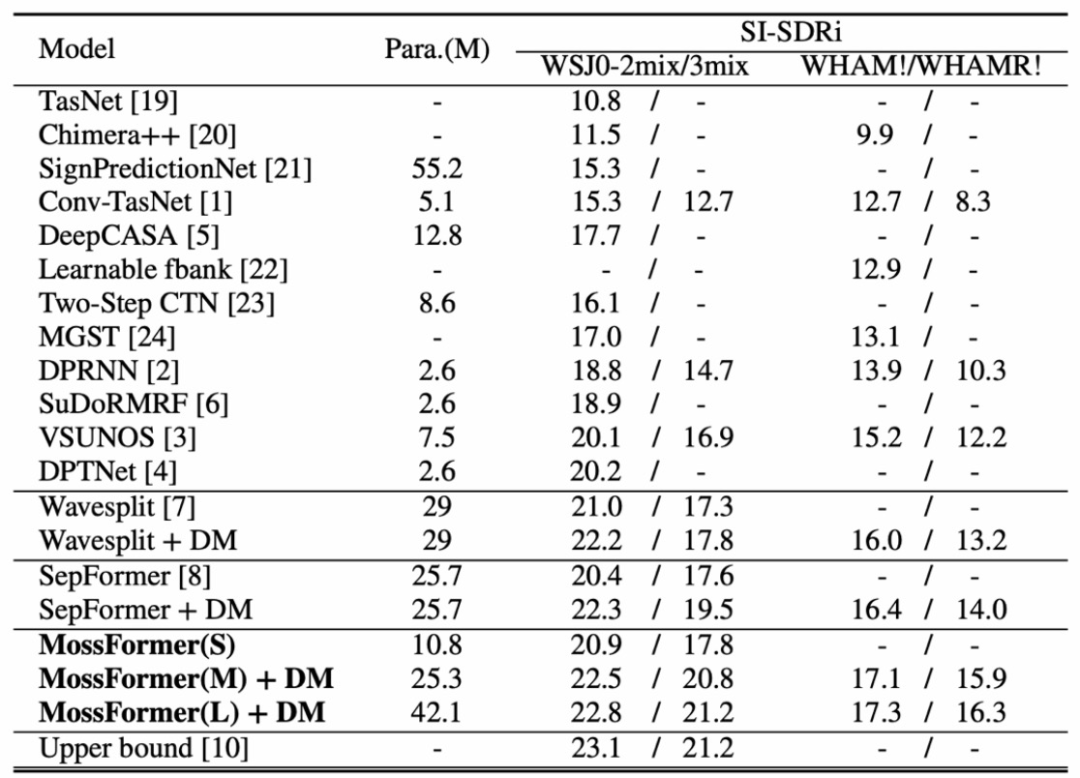
MossFormer模型与其它SOTA模型在公开数据集WSJ0-2mix/3mix和WHAM!/WHAMR!上的对比结果如下表 (模型算法引用标注沿用发表的论文引用顺序):
SI-SNR (Scale Invariant Signal-to-Noise Ratio) 尺度不变信噪比,是在普通信噪比基础上通过正则化消减信号变化导致的影响,是针对宽带噪声失真的语音增强算法的常规衡量方法。SI-SNRi (SI-SNR improvement) 是衡量对比原始混合语音,SI-SNR在分离后语音上的提升量。
DM (Dynamic Mixing)是一种动态混合数据增强算法,用来补充训练数据的不足和提升模型训练的泛化能力。
结果对比
我们分别给出了小模型MossFormer(S)、中等模型MossFormer(M)、和大模型MossFormer(L)的结果。在WSJ0-2/3mix数据集上,除了具有10M参数的MossFormer(S)在WSJ0-2mix上表现稍差于具有29M参数的Wavesplit以外,我们的MossFormer模型结果优于之前所有模型的表现。使用数据增强后,MossFormer(L)在WSJ0-2mix/3mix上分别达到了22.8 dB和21.2 dB。不仅达到了Cramer-Rao分离上限,而且在WSJ0-2mix/3mix上取得了最新的SOTA结果。
在带噪和混响WHAM!到WHAMR!数据集上,MossFormer(M)和MossFormer(L)比以前的模型表现出更大的优势,MossFormer(L)分别在WHAM!和WHAMR!上取得了最新的SOTA结果。例如,MossFormer(L)相比于SepFormer,分别提升了0.9 dB和2.3 dB。由于WHAM!/WHAMR!数据集是在WSJ0-2mix的基础上引入额外的噪声和混响来构建的,因此,在WHAM!/WHAMR!上的分离任务变得更加困难,因为模型不仅需要处理语音分离,还需要进行降噪和去混响处理。我们观察到,混响对Wavesplit和SepFormer的影响比对MossFormer的影响更大,显示MossFormer得益于独特的联合自注意力架构和深度卷积处理,可以更好的学习局部特征模式和全局长距离依赖性,从而获得更佳的分离性能。
理论上,MossFormer模型框架可以支持任意多说话人和任意环境下的语音分离任务,我们在ModelScope上首先开放的是基于两个说话人的纯语音分离模型,其目的是让用户可以在较简单的分离任务上,更快速的搭建和测试我们的模型平台。
▏如何训练自有的语音分离模型?
第一步:训练您的模型
环境准备
ModelScope网站官方提供的Notebook环境已经安装好了所有依赖,能够直接开始训练。如果您要在自己的设备上训练,可以参考模型主页上的环境准备步骤操作。环境准备完成后建议运行模型主页上推理示例代码验证模型可以正常工作。
数据准备
魔搭社区上开放的模型使用约30小时2人混合语音作为训练数据。混合语音是基于WSJ0数据集生成的,由于WSJ0的License问题无法在这里分享。我们在ModelScope上提供了基于LibriSpeech数据集生成的混合音频,以便您快速开始训练。其中训练集包含约42小时语音,共13900条,大小约7G。请访问官网页面了解数据集详情,链接在文章末尾。
模型训练
以下列出的为训练示例代码,其中work_dir可以替换成您需要的路径。
数据训练一遍为一个epoch,默认共训练120个epoch,需要约10天。
import osfrom datasets import load_datasetfrom modelscope.metainfo import Trainersfrom modelscope.msdatasets import MsDatasetfrom modelscope.preprocessors.audio import AudioBrainPreprocessorfrom modelscope.trainers import build_trainerfrom modelscope.utils.audio.audio_utils import to_segmentwork_dir = './train_dir'if not os.path.exists(work_dir):os.makedirs(work_dir)train_dataset = MsDataset.load('Libri2Mix_8k', split='train').to_torch_dataset(preprocessors=[AudioBrainPreprocessor(takes='mix_wav:FILE', provides='mix_sig'),AudioBrainPreprocessor(takes='s1_wav:FILE', provides='s1_sig'),AudioBrainPreprocessor(takes='s2_wav:FILE', provides='s2_sig')],to_tensor=False)eval_dataset = MsDataset.load('Libri2Mix_8k', split='validation').to_torch_dataset(preprocessors=[AudioBrainPreprocessor(takes='mix_wav:FILE', provides='mix_sig'),AudioBrainPreprocessor(takes='s1_wav:FILE', provides='s1_sig'),AudioBrainPreprocessor(takes='s2_wav:FILE', provides='s2_sig')],to_tensor=False)kwargs = dict(model='damo/speech_mossformer_separation_temporal_8k',train_dataset=train_dataset,eval_dataset=eval_dataset,work_dir=work_dir)trainer = build_trainer(Trainers.speech_separation, default_args=kwargs)trainer.train()
第二步:评估你的模型
以下列出的为模型评估代码,其中work_dir必须是您训练时指定的路径。程序会搜索路径下的最佳模型并自动加载。
import osfrom datasets import load_datasetfrom modelscope.metainfo import Trainersfrom modelscope.msdatasets import MsDatasetfrom modelscope.preprocessors.audio import AudioBrainPreprocessorfrom modelscope.trainers import build_trainerfrom modelscope.utils.audio.audio_utils import to_segmentwork_dir = './train_dir'if not os.path.exists(work_dir):os.makedirs(work_dir)train_dataset = Noneeval_dataset = MsDataset.load('Libri2Mix_8k', split='test').to_torch_dataset(preprocessors=[AudioBrainPreprocessor(takes='mix_wav:FILE', provides='mix_sig'),AudioBrainPreprocessor(takes='s1_wav:FILE', provides='s1_sig'),AudioBrainPreprocessor(takes='s2_wav:FILE', provides='s2_sig')],to_tensor=False)kwargs = dict(model='damo/speech_mossformer_separation_temporal_8k',train_dataset=train_dataset,eval_dataset=eval_dataset,work_dir=work_dir)trainer = build_trainer(Trainers.speech_separation, default_args=kwargs)trainer.model.load_check_point(device=trainer.device)print(trainer.evaluate(None))
相关链接
语音分离模型地址:https://modelscope.cn/models/damo/speech_mossformer_separation_temporal_8k/summary
LibriSpeech 2人混合8K音频数据集:
https://modelscope.cn/datasets/modelscope/Libri2Mix_8k/summary
WSJ0数据集:
https://catalog.ldc.upenn.edu/LDC93s6a
WSJ0-mix脚本:
https://github.com/mpariente/pywsj0-mix
References
Shengkui Zhao and Bin Ma, “MossFormer: Pushing the Performance Limit of Monaural Speech Separation using Gated Single-head Transformer with Convolution-augmented Joint Self-Attentions”, accepted by ICASSP 2023.
相关文章:
ICASSP 2023论文模型开源|语音分离Mossformer
人类能在复杂的多人说话环境中轻易地分离干扰声音,选择性聆听感兴趣的主讲人说话。但这对机器却不容易,如何构建一个能够媲美人类听觉系统的自动化系统颇具挑战性。 本文将详细解读ICASSP2023本届会议收录的单通道语音分离模型Mossformer论文࿰…...

vs2019 更改工程项目名称
本地 解决方案所在的位置为:D:\Projcet 解决方案名称:hello.sln 位置:D:\Projcet\hello.sln 工程项目名称:test 位置:D:\Projcet\test (文件夹中包含头文件,源文件) 工程包含的文件: fun.h …...
FusionCompute安装和配置步骤
1. 先去华为官网下载FusionCompute的镜像 下载地址:https://support.huawei.com/enterprise/zh/distributed-storage/fusioncompute-pid-8576912/software/251713663?idAbsPathfixnode01%7C22658044%7C7919788%7C9856606%7C21462752%7C8576912 下载后放在D盘中&am…...

makefile 参数和基本使用
make 常用选项make[-f file] [options] [target]make 默认在当前目录中查找GUNmakefile、makefile 及 Makefile 文件作为make的输入文件-f 指定文件作为输入文件-v 显示版本号-n 只输出命令不执行, 一般作为测试-s 执行命令不显示命令,-w 显示执行前和执…...

golang 占位符还傻傻分不清?
xdm ,写 C/C 语言的时候有格式控制符,例如 %s , %d , %c , %p 等等 在写 golang 的时候,也是有对应的格式控制符,也叫做占位符,写这个占位符,需要有对应的数据与之对应,不能瞎搞 基本常见常用…...

manacher算法详解
例题 求一个字符串的最长回文子串的长度 O(N2)O(N^2)O(N2)的解法很容易想,就是从每个字符位置向左右同时拓展,然后检查当前是不是回文,更新长度,可以简单写一下代码 int solve(string &ss){int ans 0;int n ss.length();s…...

要做一个关于DDD的内部技术分享,记录下用到的资源,学习笔记(未完)
最后更新于2023年3月10日 14:28:08 问题建模》软件分层》具体结构,是层层递进的关系。有了问题建模,才能进行具体的软件分层的讨论,再有了分层,才能讨论在domain里面应该怎么实现具体结构。 1、问题建模:Domain、Mod…...

KDZD互感器二次负载测试仪
一、概述 电能计量综合误差过大是电能计量中普遍存在的一个关键问题。电压互感器二次回路压降引起的计量误差往往是影响电能计量综合误差的因素。所谓电压互感器二次压降引起的误差,就是指电压互感器二次端子和负载端子之间电压的幅值差相对于二次实际电压的百分数…...
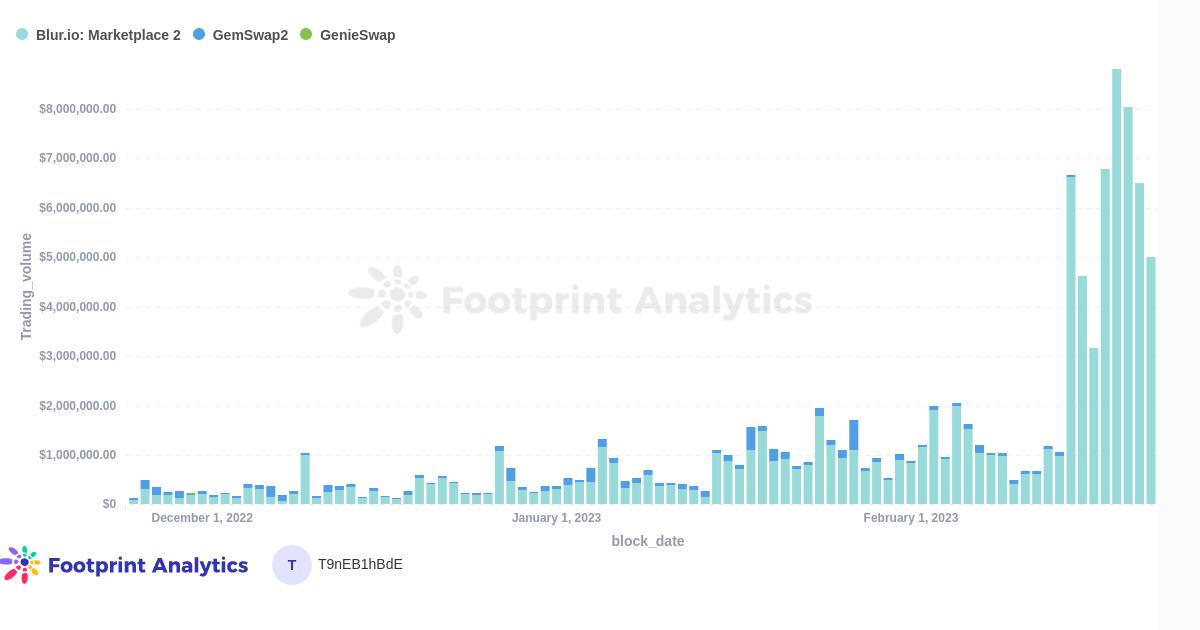
在空投之后,Blur能否颠覆OpenSea的主导地位?
Mar. 2023, Daniel数据源: NFT Aggregators Overview & Aggregator Statistics Overview & Blur Airdrop一年前,通过聚合器进行的NFT交易量开始像滚雪球一样增长,有时甚至超过了直接通过市场平台的交易量。虽然聚合器的使用量从10月到…...
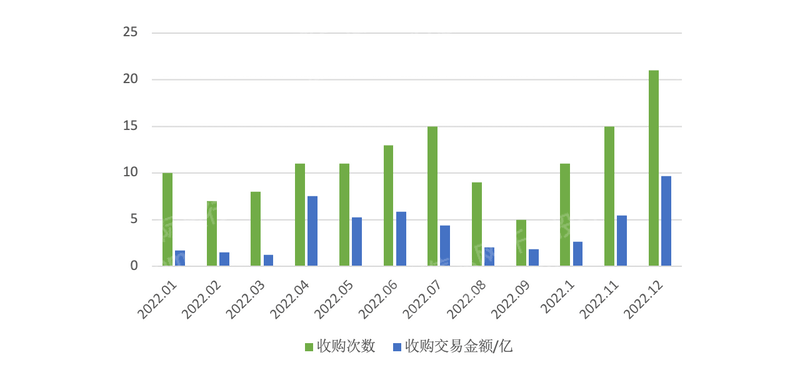
2023年新三板产品及服务研究报告
第一章 概述 全国中小企业股份转让系统(英语:National Equities Exchange and Quotations,缩写NEEQ),简称股转系统,是第三家全国性证券交易场所,因挂牌企业均为高科技企业而不同于原转让系统内…...
张力控制之开环模式
张力控制的相关知识也可以参看专栏的其它文章,链接如下: 张力闭环控制之传感器篇(精密调节气阀应用)_RXXW_Dor的博客-CSDN博客跳舞轮对应张力调节范围,我们可以通过改变气缸的气压方式间接改变,张力跳舞轮在收放卷闭环控制上的详细应用,可以参看下面的文章链接,这里我…...

python的django框架从入门到熟练【保姆式教学】第二篇
在上一篇博客中,我们介绍了Django的基础知识,并创建了一个简单的Web应用程序。在本篇教程中,我们将深入探讨Django的模型层(Model),它是Django应用程序的核心组件之一。 模型层 Django的模型层是一个对象…...
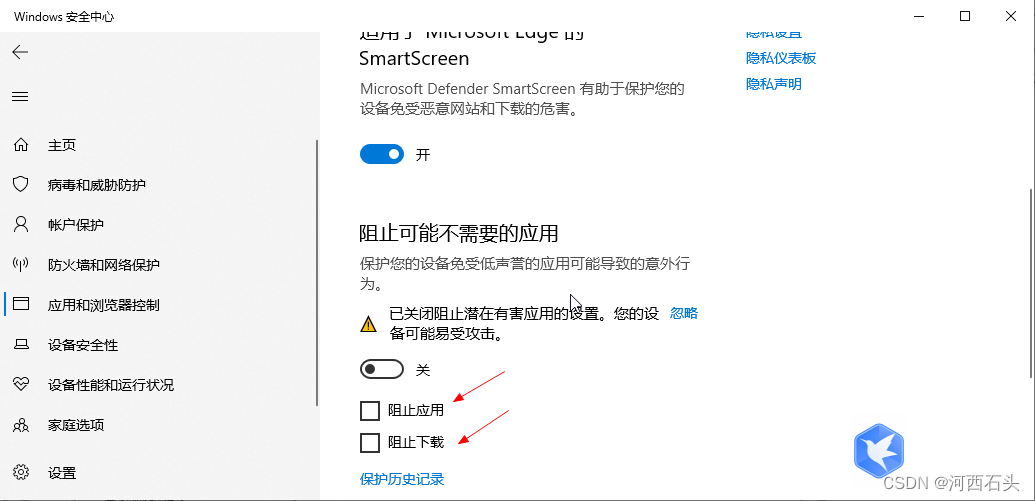
解决win10的过度保护导致文件下载不了程序不能打开运行
win7看来大概是要离我们远去了,虽然我们还能看见她的背影,但大势所趋,我们也只能慢慢的接受win10进入到我们的日常生活。但win10很多时候过度的保护却给我们带来了不便。这里列举两个最常见的问题,当然我这里也给出了解决方案。 文…...

扬帆优配|业务量大突破,这个行业发展明显向好
近期上市的新股,大都在招股阐明书里公布了本年第一季度成绩预告。 我国快递事务量本年已达200亿件 国家邮政局监测数据显现,到3月8日,本年我国快递事务量已到达200.9亿件,比2019年到达200亿件提前了72天,比2022年提前…...
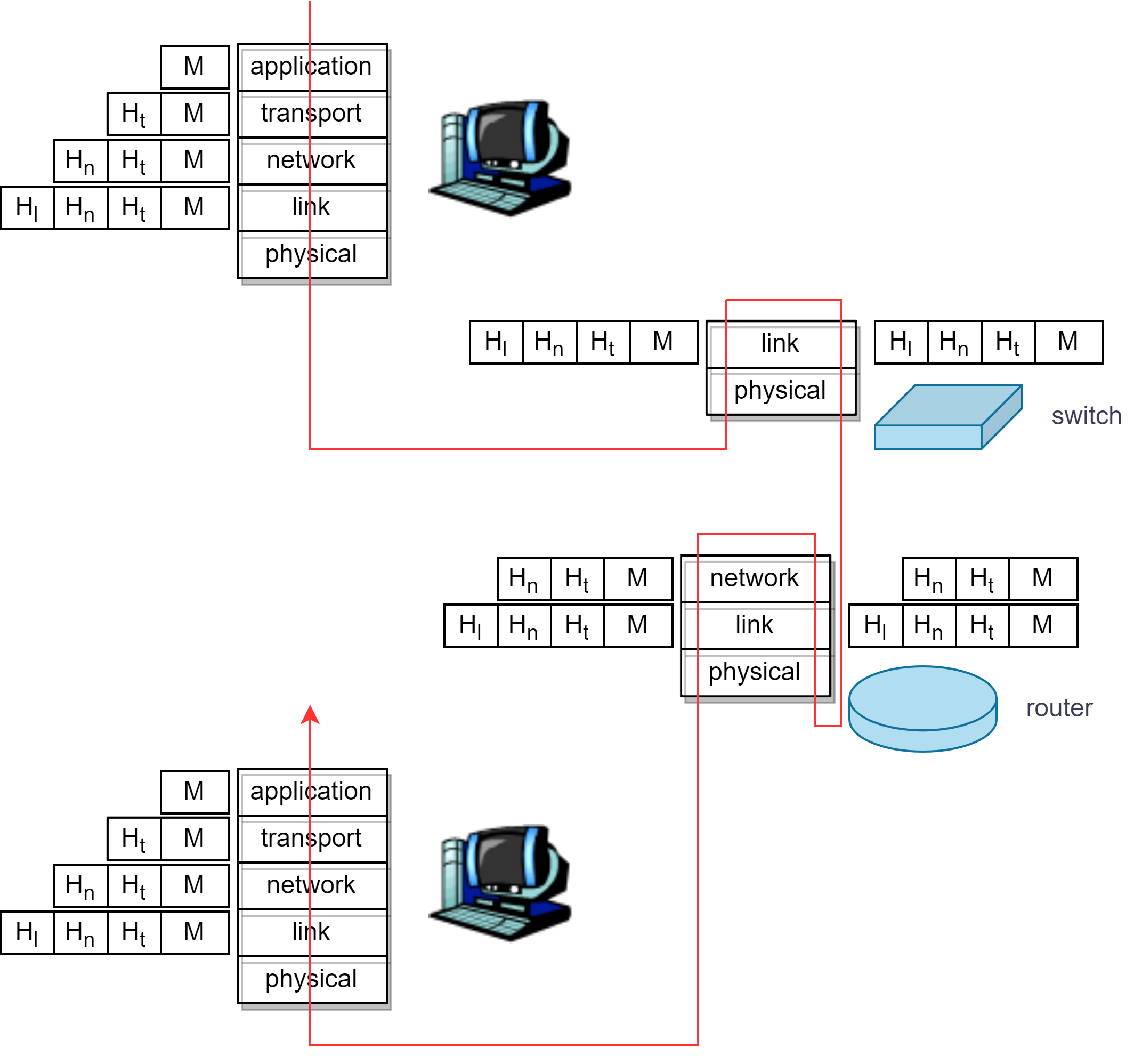
DJ1-4 计算机网络和因特网
目录 一、协议层及其服务模型 ISO/OSI 七层参考模型 TCP/IP 参考模型 1. 网际协议栈(protocol stack) 2. 分层:逻辑通信 3. 协议分层与数据 二、攻击威胁下的网络 1. 植入恶意软件 2. 攻击服务器和网络基础设施 3. 嗅探分组 4. 伪…...

Nginx根据$host及请求的URI规则重定向rewrite
项目背景: 将域名请求从默认的80端口转发到443 ssl。本项目特殊之处是一个端口监听多个域名,某些域名还有跳转到特定的地址。 普通情况: server { listen 80; #默认的80端口,非…...

人工智能实验一:使用搜索算法实现罗马尼亚问题的求解
1.任务描述 本关任务: 了解有信息搜索策略的算法思想;能够运用计算机语言实现搜索算法;应用A*搜索算法解决罗马尼亚问题; 2.相关知识 A*搜索 算法介绍 A*算法常用于 二维地图路径规划,算法所采用的启发式搜索可以…...

Spring Security基础入门
基础概念 什么是认证 认证:用户认证就是判断一个用户的身份身份合法的过程,用户去访问系统资源的时候系统要求验证用户的身份信息,身份合法方可继续访问,不合法则拒绝访问。常见的用户身份认证方式有:用户密码登录&am…...

dnsresolver-limit
文件OperationLimiter.h功能DnsResolver是andnroid中提供DNS能力的小型DNS解析器,limit是其中的一个小模块,支持全局、基于key(UID)的DNS请求限制。DnsResolver是多线程模型,单个DNS请求最多启动3个线程(传统DNS)。在网…...

使用 YoctoProject集成Qt6
By Toradex胡珊逢在嵌入式领域中Qt 作为普遍选择的 UI 方案目前已经发布 Qt6 版本。本文将介绍如何为 Toradex 的计算机模块使用 Yocto Project 将 Qt6 集成到镜像里。首先根据这里的说明,准备好Yocto Project 的编译环境。这里我们选择 Toradex 最新的 Linux BSP V…...

Shell脚本工程化:great.sh框架解决运维脚本可维护性难题
1. 项目概述:一个被低估的Shell脚本构建框架如果你和我一样,常年混迹在运维、DevOps或者后端开发领域,那么对Shell脚本的感情一定是复杂的。一方面,它是我们最趁手的“瑞士军刀”,从服务器初始化、日志分析到自动化部署…...
技术解析与AI硬件加速实践)
计算内存(CIM)技术解析与AI硬件加速实践
1. 计算内存(CIM)技术解析:突破传统架构的能效瓶颈 在AI硬件加速领域,计算内存(Compute-in-Memory, CIM)正引发一场架构革命。传统冯诺依曼架构中"内存墙"问题已成为制约AI计算效率的主要瓶颈——…...
 的6个高阶用法,数据分析师必看)
别再只会用0填充了!Pandas DataFrame.fillna() 的6个高阶用法,数据分析师必看
别再只会用0填充了!Pandas DataFrame.fillna() 的6个高阶用法,数据分析师必看 在数据分析的日常工作中,缺失值处理就像是一道无法回避的数学题。许多刚入行的分析师会条件反射般地输入.fillna(0),这就像用创可贴处理所有伤口——有…...

麻省理工博士生弃博投身数字人类研究:10年、100亿美元、5万台H100或可实现
【导语:麻省理工学院博士生Isaak Freeman放弃攻读博士学位,投身数字人类研究。他认为人类若保持碳基形态将在智力竞争中被AI淘汰,而将意识迁移到数字基质上是出路,并给出实现数字人类的粗略计算和路线图。】数字人类:从…...

从数据中心视角聊token
“我爱你”被AI拆解成了3个tokens,“I love U”也同样被AI拆解成了3个tokens,AI将人类的语言拆解到可被数据分析的最小单位,叫做token,中文是词元,AI通过数据模型的分析,又将无数的token组成了答复反馈给用…...

网安信息收集
声明:任何个人和组织不得从事非法侵入他人网络、干扰他人网络正常功能、窃取网络数据等危害网络安全 的活动;不得提供专门用于从事侵入网络、干扰网络正常功能及防护措施、窃取网络数据等危害网络安全活动的程序、工具;明知他人从事危害网络安…...

从一次内部渗透测试说起:我是如何利用SSRF漏洞,通过Gopher协议拿下Redis的
渗透测试实战:SSRF漏洞到Redis未授权访问的完整攻击链剖析 在一次常规的企业内部渗透测试中,我发现了一个看似普通的SSRF漏洞,却意外打开了通往内网核心系统的大门。这个故事不是教科书式的漏洞复现,而是一个真实攻击者视角下的完…...

如何用DdddOcr在3分钟内构建离线验证码识别系统
如何用DdddOcr在3分钟内构建离线验证码识别系统 【免费下载链接】ddddocr 带带弟弟 通用验证码识别OCR pypi版 项目地址: https://gitcode.com/gh_mirrors/dd/ddddocr 在当今的自动化测试、数据采集和网络安全领域,验证码识别是绕不开的技术难题。传统的在线…...

打破高频、高速四种材料混压
打破高频、高速四种材料混压,铸就PCB行业硬核实力。在航空航天领域,每一次技术的突破都意味着对材料与工艺的极致追求。今天,我们要聊的这款产品,堪称多材料混压天花板,——16层、四种材料混压、三次压合、板厚5.0mm、…...

91160-cli:健康160平台终极挂号神器,5分钟上手解决抢号难题
91160-cli:健康160平台终极挂号神器,5分钟上手解决抢号难题 【免费下载链接】91160-cli 健康160全自动挂号脚本,捡漏神器 项目地址: https://gitcode.com/gh_mirrors/91/91160-cli 你是否还在为抢不到专家号而烦恼?面对健康…...