注意力机制和Transformer模型各部分功能解释
文章目录
- Transformer
- 1、各部分功能解释
- 2、通过例子解释
- a.输入预处理
- 位置编码
- b.Encoder 的处理
- c.Decoder的输入
- Decoder的工作流程
- d.输出预测
- 总结
Attention代码和原理理解
Transformer
运行机理:
(1)假设我们需要进行文本生成任务。我们将已经有的文本首先通过词嵌入并进行位置编码作为输入,输入到encoder中,encoder的目的是使得词不仅仅有了自己的信息,还有了自己上下文的信息,即全局信息,即词有了语义信息。
(2)在训练时,我们使用当前已经预测出来的词作为decoder的输入(当然这些词使用的是正确的词即使可能预测过程中有错误,也使用掩码掩盖未来的词),我们将其与encoder输出的向量进行结合使用注意力层最后使用全连接得到新的预测结果,得到一个预测接下来我们继续将这个预测的词增加作为decoder的输入,直到预测结束。
注意:
- Decoder的输入:从一个特定的起始符号开始,并逐步使用之前步骤生成的词来生成新的词,直到序列完成。
- Encoder的输入:在整个序列生成过程中保持不变,为Decoder提供必要的上下文信息。
1、各部分功能解释
Transformer快速入门
标准的 Transformer 模型主要由两个模块构成:
-
Encoder(左边):负责理解输入文本,为每个输入构造对应的语义表示(语义特征);
-
Decoder(右边):负责生成输出,使用 Encoder 输出的语义表示结合其他输入来生成目标序列。Decoder的输入是当前预测出来的文本,在训练时是正确文本,而预测时是预测出来的文本。 当然都包含位置编码,训练时也需要使用掩码。
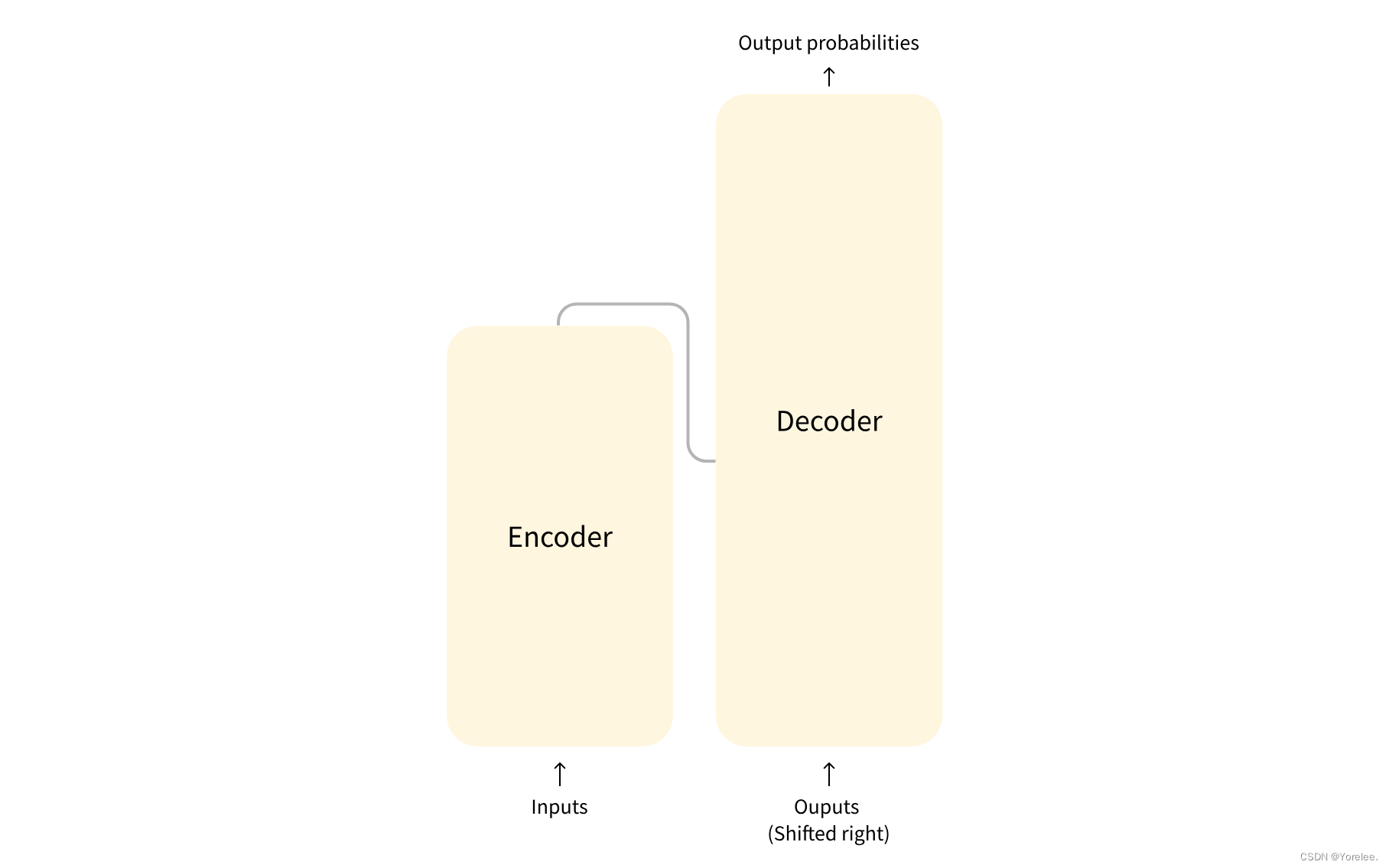
这两个模块可以根据任务的需求而单独使用: -
纯 Encoder 模型:适用于只需要理解输入语义的任务,例如句子分类、命名实体识别;
-
纯 Decoder 模型:适用于生成式任务,例如文本生成;
-
Encoder-Decoder 模型或 Seq2Seq 模型:适用于需要基于输入的生成式任务,例如翻译、摘要。
2、通过例子解释
Transformer模型在处理 “Harry Potter is a wizard and hates __ the most.” 这一句子时的工作流程和各个组件的作用。
a.输入预处理
假设我们的句子 “Harry Potter is a wizard and hates” 已经通过分词处理,并且每个词都被映射到了一个整数ID。例如:
- Harry -> 2021
- Potter -> 1057
- is -> 56
- a -> 15
- wizard -> 498
- and -> 7
- hates -> 372
这些整数ID接着被转换为词嵌入向量。词嵌入层会从一个预训练的嵌入矩阵中提取每个ID对应的向量。
位置编码
对于 “Harry Potter is a wizard and hates” 这七个词,Transformer还需要知道每个词的位置。因此,每个词嵌入向量会加上一个位置向量,位置向量通过一定的函数(如正弦和余弦函数)生成,以反映词在句子中的顺序。
b.Encoder 的处理
经过词嵌入和位置编码后,这组向量输入到Encoder。Encoder中的每一层都包括两部分:多头自注意力机制和前馈神经网络。
- 多头自注意力机制允许模型评估每个词与句子中其他词的关系强度。这有助于捕获比如"Harry Potter"和"wizard"之间的联系。
- 前馈神经网络对自注意力层的输出进行进一步转换。
每一层的输出都会被送入下一层,直到最后一层。Encoder的最终输出是一个加工过的、包含整个句子信息的向量序列。
好的,让我来更详细地解释Transformer模型中Decoder的工作机制,特别是它的输入是如何处理的。
c.Decoder的输入
在理解Decoder的输入之前,我们首先要明确,Transformer模型通常用于处理序列到序列的任务,比如机器翻译、文本摘要等。在这些任务中,Decoder的角色是基于Encoder的输出,生成一个输出序列。
假设我们的任务是文本填空,比如在句子 “Harry Potter is a wizard and hates __ the most.” 中填入缺失的部分。在实际应用(如训练或预测)过程中,Decoder的输入通常有两部分:
-
已知的输出序列的前缀:这是模型在生成每个新词时,已经生成的输出序列的部分。在训练阶段,这通常是目标序列(ground truth)中的前缀;在推理阶段,这是模型逐步生成的输出。例如,如果我们预测的第一个词是 “Voldemort”,那么在预测下一个词时,“Voldemort” 就成了已知的输出序列的前缀。
-
位置编码:和Encoder相同,每个词的词嵌入会加上位置编码。位置编码帮助模型理解词在序列中的位置关系,这对于生成有顺序关系的文本尤其重要。
Decoder的工作流程
在得到输入后,Decoder的每一层会执行以下几个操作:
-
掩蔽多头自注意力(Masked Multi-Head Self-Attention):
- 这一步骤和Encoder中的自注意力类似,但有一个关键区别:它会使用掩蔽(masking)来防止未来位置的信息泄漏。这意味着在生成第 ( n ) 个词的预测时,模型只能访问第 ( n-1 ) 个词及之前的词的信息。
- 例如,当模型正在生成 “Voldemort” 后面的词时,它不能“看到”这个词之后的任何词。
-
编码器-解码器自注意力(Encoder-Decoder Attention):
- 这一步是Decoder的核心部分,其中Decoder利用自己的输出作为查询(Query),而将Encoder的输出作为键(Key)和值(Value)。
- 这允许Decoder根据自己已经生成的文本部分(通过查询),和输入句子的语义表示(通过键和值),生成下一个词的预测。这是一个信息整合的过程,通过Encoder的上下文信息来指导输出序列的生成。
-
前向馈网络(Feed-Forward Network):
- 与Encoder中相同,每个自注意力层后面都会跟一个前向馈网络,这个网络对每个位置的输出独立处理,进一步转换特征表示。
d.输出预测
Decoder的输出通过一个线性层和softmax层,生成每个可能词的概率分布。选择概率最高的词作为预测结果。
总结
因此,在Decoder中,输入主要是基于到目前为止已经生成的输出序列(加上位置信息),而这些输入通过Decoder的多层结构进行处理,每层都包括掩蔽自注意力、编码器-解码器自注意力和前向馈网络,以生成最终的输出序列。这种结构设计使得Transformer能够在考虑到整个输入序列的上下文的同时,逐步构建输出序列。
相关文章:
注意力机制和Transformer模型各部分功能解释
文章目录 Transformer1、各部分功能解释2、通过例子解释a.输入预处理位置编码b.Encoder 的处理c.Decoder的输入Decoder的工作流程d.输出预测总结 Attention代码和原理理解 Transformer 运行机理: (1)假设我们需要进行文本生成任务。我们将已…...

短路是怎么形成的
1. 短路分为电源短路和用电器短路。 电源短路:电流不经过任何用电器,直接由正极经过导线流向负极,由于电源内阻很小,导致短路电流很大,特别容易烧坏电源。 用电器短路:也叫部分电路短路,即一根…...
)
【ZZULIOJ】1106: 回文数(函数专题)
题目描述 一个正整数,如果从左向 右读(称之为正序数)和从右向左读(称之为倒序数)是一样的,这样的数就叫回文数。输入两个整数m和n(m<n),输出区间[m,n]之间的回文数。…...

数据库设计规范总结
数据库设计规范总结 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 数据库设计规范是指在设计数据库时应该遵循的一系列规则和标准,旨在提高数据库…...

深度学习(九)——神经网络:最大池化的作用
一、 torch.nn中Pool layers的介绍 官网链接: https://pytorch.org/docs/stable/nn.html#pooling-layers 1. nn.MaxPool2d介绍 nn.MaxPool2d是在进行图像处理时,Pool layers最常用的函数 官方文档:MaxPool2d — PyTorch 2.0 documentation &…...

「前端+鸿蒙」鸿蒙应用开发-ArkTS语法说明-组件声明
ArkTS 是鸿蒙应用开发中的一个框架,它允许开发者使用 TypeScript 语法来创建声明式的用户界面。在 ArkTS 中,组件声明是构建 UI 的基础。以下是 ArkTS 快速入门的指南,包括组件声明的语法说明和示例代码。 ArkTS 快速入门 - 语法说明 - 组件声明 组件基础 在 ArkTS 中,组…...

python的subprocess 模块
subprocess 模块是 2.4 版本中新增的模块, 它允许您生成新进程,连接到它们的 输入 / 输出 / 错误 管道,并获得它们的返回码 (状态信息), 该模块的目的在于取代几个较旧的模块和功能 subprocess 模块可以用于执行系统命令, 拿到执行的结果, 速度比较的快…...

【Arc gis】使用DEM提取流域范围
地址:arcgis DEM 提取流域范围(详细教程)(空间分析--Hydrology)_gis的gridcode是什么意思-CSDN博客...

大模型技术工程师:抓住时代机遇,成为行业精英_
伴随AI大模型的火热,中国科技大厂们正在掀起一场「跑步AI化」的风暴。从顶层战略到业务线重构,AI无疑已成为大厂们押注未来的新故事。 大模型时代已经到来 大模型已成为全球竞争热点,一个大模型时代已经到来。 大模型具备三个特点…...

孟德尔随机化R包:TwoSampleMR和MR-PRESSO安装
1. 孟德尔随机化R包 看一篇文章,介绍孟德尔随机化分析,里面推荐了这两个R包,安装了解一下: Methods:Genome-wide association study (GWAS) data for autoimmune diseases and AMD were obtained from the IEU Open GWAS databas…...

6月18日 Qtday4
作业day4.1 作业4.2...

Vue3模拟国足18强赛抽签
Vue3国足18强赛抽签 国足遇到这个对阵,能顺利出现吗? 1、系统演示 Vue3模拟国足18强赛抽签 2、关键代码 开始抽签 <script setup> import FenDang from "/components/chouqian/FenDang.vue"; import {ref} from "vue";le…...

mesa编译器nir信息储存问题
概述 本来想将一个完整的可以从hlsl-dxil-spirv-nir-code的项目划分为两个动态库a.dll与b.dll。应用程序调用a.dll与b.dll执行相同的过程。 a.dll:执行dxil-spirv-nir前端相关的转换。 b.dll:执行nir-code的转换。 应用程序调用dxc实现hlsl-dxil的过程&…...

windows下mysql设置开机自启动
windows下mysql设置开机自启动 情况1.mysql服务不存在情况2.mysql服务已存在 我们先检查一下电脑是否存在mysql服务 此电脑(右键)—>管理—>服务 看一下能不能找到相关mysql 服务 情况1.mysql服务不存在 以管理员的身份运行命令窗口,找到mysqld.exe 所在的路径 命令如下…...
)
L2-002 链表去重(C++)
给定一个带整数键值的链表 L,你需要把其中绝对值重复的键值结点删掉。即对每个键值 K,只有第一个绝对值等于 K 的结点被保留。同时,所有被删除的结点须被保存在另一个链表上。例如给定 L 为 21→-15→-15→-7→15,你需要输出去重后…...
异或运算在面试题中的应用
异或运算 是 涉及到数据位运算时常见的处理方式。如何进行异或运算?在对应位上,相同为0,不同1,但其实两个数据异或运算就是进行无进位加法。 例如: int a = 7, b = 6, a ^b = ? 算法1: 相同为0,不同为1 a ^ b= : 0 0 0 1 算法2: 无进位…...

【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 单词大师(100分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 …...

LabVIEW在SpaceX的应用
结合真实的资料介绍LabVIEW在SpaceX的应用,涵盖自动化测试系统、数据采集与监控、可视化与分析、模块化设计与扩展,以及效率与可靠性的提高。 自动化测试系统 LabVIEW在SpaceX的自动化测试系统中发挥了关键作用。自动化测试是确保SpaceX火箭及其子系…...

【Android面试八股文】讲一讲String、StringBuffer和StringBuilder在进行字符串操作时候的效率
文章目录 一、String二、StringBuffer三、StringBuilder四、String、StringBuffer和StringBuilder的效率测试五、String、StringBuffer和StringBuilder的选择一、String String是不可变的,final修饰,任何对String的操作都会创建一个新的String对象。在进行大量字符串拼接或修…...

[自动驾驶 SoC]-4 特斯拉FSD
FSD, 参考资料来源FSD Chip - Tesla - WikiChip 另外可参考笔者之前分享文章:[自动驾驶技术]-6 Tesla自动驾驶方案之硬件(AI Day 2021),[自动驾驶技术]-8 Tesla自动驾驶方案之硬件(AI Day 2022…...

Helm Diff插件:可视化Kubernetes部署变更,保障发布安全
1. 项目概述:Helm Diff,一个让Kubernetes部署变更“可视化”的利器 如果你和我一样,长期在Kubernetes(K8s)环境中摸爬滚打,使用Helm来管理复杂的应用部署,那么你一定经历过这样的场景࿱…...

【2026最新】鸿蒙NEXT数据持久化实战:培训班管理系统数据存储全攻略
鸿蒙开发中数据总是丢失?本地存储和网络请求搞不定?本文用15分钟带你彻底搞懂Preferences、RDB、HTTP三大数据持久化方案,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App数据存储从此安全可靠!一、学员信息本地…...

如何用FanControl快速解决电脑风扇噪音问题:完整免费指南
如何用FanControl快速解决电脑风扇噪音问题:完整免费指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...

gifuct-js:高性能JavaScript GIF解码器的架构设计与性能优化策略
gifuct-js:高性能JavaScript GIF解码器的架构设计与性能优化策略 【免费下载链接】gifuct-js Fastest javascript .GIF decoder/parser 项目地址: https://gitcode.com/gh_mirrors/gi/gifuct-js gifuct-js是一个专注于高效GIF文件解析与解码的JavaScript库&a…...

Cursor Free VIP:解锁AI编程助手完整功能的技术解决方案
Cursor Free VIP:解锁AI编程助手完整功能的技术解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your t…...

Claude Code用户如何迁移至Taotoken解决账号与Token限制问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code用户如何迁移至Taotoken解决账号与Token限制问题 对于依赖Claude Code进行编程辅助的开发者而言,直接使用官…...

ElevenLabs语音克隆失败率骤降63%的关键:训练集音频信噪比阈值、时长分布与语速归一化黄金公式
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs英文语音生成的底层架构演进 ElevenLabs 的语音合成系统并非基于传统拼接或参数化 TTS 框架,而是构建在端到端神经声码器与自监督语音表征联合优化的混合架构之上。其核心演进路径…...

BoltAI 资源网关、Agent 平台重塑工业 AI 底
一、工业 AI 进入“基础设施竞争”新阶段2025—2026年,从单点试点、概念验证,快速走向平台化、规模化、体系化落地。过去“一个场景一个模型”的作坊式开发,成本高、复用差、运维乱,已难以支撑制造、能源、化工、装备等行业的全域…...
)
双边滤波Bilateral_Filter(调参的重要性)
一、双边滤波的基本概念 1.双边滤波是一种非线性滤波 2.双边滤波的作用是保边降噪平滑滤波器 3.卷积核大小:33、55、77这个是比较常用的卷积核。二、双边滤波的关键参数 1.空间方差 用用控制空间位置差异的平滑程度。 空间方差越大,空间高斯的影响范围越…...

正规全能艺术台制造厂:可靠厂商选择要点解析
正规全能艺术台制造厂选择指南:5大可靠厂商评估要点FAQ“选对全能艺术台制造厂,不是看广告多响,而是看这5个‘隐性指标’——合规资质、自研技术、服务体系、数据安全、内容迭代能力!”很多公共文化场馆在采购全能艺术台时&#x…...