全面对比与选择指南:Milvus、PGVector、Zilliz及其他向量数据库
本文全面探讨了Milvus、PGVector、Zilliz等向量数据库的特性、性能、应用场景及选型建议,通过详细的对比分析,帮助开发者和架构师根据具体需求选择最合适的向量数据库解决方案。
文章目录
- 向量数据库概述
- 向量数据库的关键功能
- 向量数据库的扩展和选择
- 向量数据库与传统数据库的区别
- 不同类型的向量数据库
- 纯矢量数据库
- 全文检索数据库
- 开源矢量库
- 支持矢量的NoSQL数据库
- 支持矢量的SQL数据库
- 主要向量数据库对比
- Milvus简介与优势
- PGVector简介与应用
- Zilliz简介与服务
- Elastic Cloud与Zilliz Cloud的性能对比
- Qdrant Cloud与Zilliz Cloud的性能对比
- 性能与可扩展性对比
- 性能基准测试结果
- 可扩展性分析
- 云原生支持
- 功能与特性对比
- 向量数据库的必备特性
- 多租户和数据隔离
- 完整的API套件
- 直观的用户界面和控制台
- 安装与配置
- 安装Docker和PostgreSQL
- 安装Docker
- 安装PostgreSQL
- 创建数据库和表
- 创建数据库
- 创建表
- 安装pgvector插件
- 安装插件
- Milvus的安装与快速启动
- 安装Milvus
- 快速启动
- Zilliz Cloud的部署与使用
- 部署Zilliz Cloud
- 使用Zilliz Cloud
- 应用场景与案例分析
- 图像检索中的应用
- 技术实现
- AI工具集成中的角色
- 应用案例
- RAG系统的需求
- 应用案例
- 如何选择向量数据库
- 入门或demo的选择
- 产品开发的选择
- 现有系统上使用矢量功能的选择
- 架构建议
- 结论与建议
- 根据需求选择合适的数据库
- 未来发展趋势与技术更新
- 选择矢量数据库的建议
向量数据库概述
向量数据库的关键功能
向量数据库是专门设计来处理和存储高维向量数据的数据库系统。它们的关键功能包括:
- 高效的相似性搜索:向量数据库能够快速地在大量高维向量中找到最相似的向量,这对于图像识别、语音识别和推荐系统等应用至关重要。
- 支持多种索引类型:如IVF_FLAT、IVF_SQ8、HNSW等,这些索引类型可以根据不同的应用场景和性能需求进行选择。
- 动态扩展性:随着数据量的增加,向量数据库能够通过增加节点或资源来扩展其处理能力,确保系统的性能不受影响。
- 支持复杂的查询和过滤:除了基本的相似性搜索,向量数据库还支持复杂的查询操作,如混合查询和标量过滤,这使得它们能够处理更复杂的业务逻辑。
向量数据库的扩展和选择
选择和扩展向量数据库时,需要考虑以下几个关键因素:
- 数据规模和查询复杂度:根据数据量的大小和查询的复杂度选择合适的向量数据库。例如,对于大规模数据集,可能需要一个支持分布式架构的数据库。
- 性能需求:不同的应用场景对性能的要求不同,如实时搜索可能需要更高的查询速度。
- 成本效益:考虑数据库的运行成本,包括硬件资源、维护费用和许可费用。
- 社区和支持:选择一个有活跃社区和良好支持的数据库可以确保长期的技术支持和问题解决。
向量数据库与传统数据库的区别
向量数据库与传统数据库(如关系型数据库)在设计和功能上有显著的区别:
- 数据模型:传统数据库通常基于表格模型,而向量数据库处理的是高维向量数据。
- 查询机制:传统数据库主要依赖于精确的SQL查询,而向量数据库则侧重于相似性搜索和近似查询。
- 索引结构:向量数据库使用专门的索引结构(如倒排索引、图索引等)来优化相似性搜索,而传统数据库通常使用B树或哈希索引。
- 扩展性:向量数据库通常设计为可水平扩展,能够处理大规模数据集,而传统数据库可能在处理大数据时遇到性能瓶颈。
通过这些对比,我们可以看到向量数据库在处理特定类型的数据和查询时具有独特的优势,特别是在需要高效处理大量高维数据的应用中。
不同类型的向量数据库
纯矢量数据库
纯矢量数据库是专门设计用于存储和处理矢量数据的数据库系统。这类数据库通常提供高效的矢量索引和搜索功能,适用于需要快速进行相似性搜索的场景。例如,Milvus是一个开源的纯矢量数据库,它支持多种矢量索引类型,如IVF、HNSW等,可以处理大规模的矢量数据集,并提供实时搜索能力。纯矢量数据库的优势在于其专为矢量数据优化,能够提供高性能的查询和处理能力。
全文检索数据库
全文检索数据库虽然主要用于文本数据的搜索,但许多现代的全文检索系统也支持矢量搜索功能。例如,Elasticsearch通过插件如Elasticsearch-HNSW可以实现矢量搜索。这类数据库的优势在于它们通常具有强大的文本处理能力,同时也能处理向量数据,适合需要结合文本和向量搜索的应用场景。
开源矢量库
开源矢量库是指那些提供向量处理功能的开放源代码库。这些库通常不提供完整的数据库管理系统功能,但提供了构建向量数据库所需的核心功能。例如,Faiss是Facebook开发的一个开源库,它提供了高效的矢量索引和搜索算法,可以集成到其他系统中以增强其向量处理能力。
支持矢量的NoSQL数据库
NoSQL数据库如MongoDB和Cassandra等,也开始支持矢量数据类型和相关的查询功能。这些数据库通常具有良好的扩展性和灵活的数据模型,适合处理非结构化数据。例如,MongoDB通过其MLAB插件支持矢量索引,可以在保持NoSQL数据库的灵活性的同时,处理向量数据。
支持矢量的SQL数据库
支持矢量的SQL数据库是指那些传统的关系型数据库,它们通过插件或扩展来支持矢量数据类型和查询。例如,PostgreSQL通过pgvector插件可以实现矢量相似度查询。这类数据库的优势在于它们通常具有成熟的数据管理功能和广泛的应用基础,适合需要在现有关系型数据库基础上增加向量处理能力的场景。
通过上述分类,我们可以看到向量数据库的多样性,不同的数据库类型适合不同的应用场景和需求。选择合适的向量数据库时,需要考虑数据量、查询性能、扩展性、易用性以及与现有系统的兼容性等因素。
主要向量数据库对比
Milvus简介与优势
Milvus 是一个开源的向量数据库,专为处理大规模向量相似性搜索而设计。它支持多种索引类型,如IVF、HNSW等,这些索引类型可以根据不同的应用场景和性能需求进行选择。Milvus的核心优势在于其高性能和可扩展性,能够处理数十亿甚至更多的向量数据。此外,Milvus提供了丰富的API和SDK,支持Python、Java等多种编程语言,使得开发者可以轻松地集成和使用。
PGVector简介与应用
PGVector 是一个PostgreSQL扩展,它允许在PostgreSQL数据库中存储、查询和索引向量数据。PGVector支持多种向量索引类型,如HNSW和IVFFlat,这些索引可以显著提高向量搜索的效率。PGVector的应用场景包括但不限于图像识别、语音识别和推荐系统等。由于其与PostgreSQL的紧密集成,PGVector非常适合那些已经使用PostgreSQL作为主要数据库系统的项目,可以无缝地扩展其功能以支持向量数据处理。
Zilliz简介与服务
Zilliz 提供了一个完全托管的向量数据库服务,名为Zilliz Cloud。Zilliz Cloud旨在提供高速、大规模和高性能的向量数据处理能力。它支持多种向量索引和查询功能,并且提供了易于使用的管理界面和API。Zilliz Cloud的优势在于其云原生架构,可以轻松地扩展以适应不断增长的数据量和查询需求。此外,Zilliz Cloud还提供了灵活的定价选项,适合各种规模的项目和团队。
Elastic Cloud与Zilliz Cloud的性能对比
Elastic Cloud 是一个流行的云服务,它基于Elasticsearch,提供了强大的搜索和分析功能。虽然Elasticsearch主要用于文本搜索,但它也支持向量搜索功能。与Zilliz Cloud相比,Elastic Cloud在处理文本数据方面表现出色,但在向量搜索方面可能不如Zilliz Cloud专业。Zilliz Cloud专为向量数据设计,提供了优化的索引和查询机制,适合需要高性能向量搜索的应用。
Qdrant Cloud与Zilliz Cloud的性能对比
Qdrant Cloud 是一个新兴的向量数据库服务,它提供了高性能的向量搜索和数据管理功能。Qdrant Cloud支持多种向量索引类型,并且提供了易于使用的API和SDK。与Zilliz Cloud相比,Qdrant Cloud可能在某些特定的向量搜索场景中表现出色,但Zilliz Cloud提供了更全面的云服务支持,包括数据备份、恢复和监控等功能。选择哪个服务取决于具体的应用需求和性能要求。
性能与可扩展性对比
性能基准测试结果
在评估向量数据库的性能时,关键指标包括查询速度、数据插入速率和系统稳定性。以下是几种主流向量数据库的性能基准测试结果对比:
-
Milvus:Milvus在处理大规模向量数据时表现出色,特别是在十亿级向量搜索任务中,其查询速度和准确性均达到行业领先水平。根据官方数据,Milvus能够在毫秒级别内返回搜索结果,这对于实时应用非常关键。
-
PGVector:作为PostgreSQL的扩展,PGVector在中小规模数据集上表现良好,但在处理大规模数据时,其性能可能受限于单节点的处理能力。在性能测试中,PGVector的查询速度和数据插入效率在中小规模数据集上表现稳定。
-
Zilliz:Zilliz Cloud提供了优化的向量搜索服务,其性能在云环境中表现优异。在云端测试中,Zilliz Cloud能够处理高并发的查询请求,且延迟较低。其性能优化主要得益于云原生架构和高效的资源管理。
可扩展性分析
向量数据库的可扩展性是衡量其能否有效处理不断增长数据量的关键。以下是各数据库的可扩展性特点:
-
Milvus:Milvus支持水平扩展,可以通过增加节点来提高处理能力,适合需要处理大量数据的企业级应用。其分布式架构设计使得系统能够轻松应对数据量的增长。
-
PGVector:PGVector依赖于PostgreSQL的扩展性,虽然可以通过增加硬件资源来提升性能,但在处理极大规模数据时可能面临挑战。其扩展性受限于PostgreSQL的架构。
-
Zilliz:Zilliz Cloud设计为云原生服务,天然支持水平扩展,能够根据业务需求灵活调整资源。这种设计使得Zilliz Cloud能够无缝适应数据量和查询负载的变化,适合需要快速扩展的业务场景。
云原生支持
云原生支持意味着数据库能够充分利用云基础设施的优势,如自动扩展、高可用性和灵活的资源配置。以下是各数据库的云原生支持情况:
-
Milvus:Milvus虽然是一个强大的开源项目,但其云原生支持需要通过第三方云服务提供商实现。Milvus社区也提供了部署在Kubernetes上的指南,便于实现云原生部署。
-
PGVector:作为PostgreSQL的扩展,PGVector可以部署在云环境中,但需要额外的配置和管理来实现云原生特性。
-
Zilliz:Zilliz Cloud是一个完全托管的云服务,提供了完整的云原生支持,包括自动扩展、备份恢复和多区域部署等功能。这种服务模式极大地简化了向量数据库的部署和管理,特别适合没有强大IT支持的团队或企业。
通过上述对比,我们可以看到不同向量数据库在性能和可扩展性方面的差异,选择时应根据具体的业务需求和资源配置进行权衡。
功能与特性对比
向量数据库的必备特性
向量数据库的必备特性主要包括:
- 高效的向量索引和搜索:支持快速检索相似向量,如使用HNSW、IVF等索引技术。
- 多种距离度量支持:能够根据不同应用场景选择合适的距离度量方法,如欧氏距离、余弦相似度等。
- 高维数据处理能力:有效处理高维度数据,适应深度学习模型生成的特征向量。
- 实时数据操作:支持实时插入、更新和查询,确保数据的实时性和准确性。
- 可扩展性:随着数据量的增加,能够通过增加节点或资源来扩展系统性能。
多租户和数据隔离
在多租户环境中,向量数据库需要提供以下支持:
- 租户隔离:确保不同租户的数据和操作相互独立,避免相互干扰。
- 资源分配:合理分配计算和存储资源,确保每个租户的服务质量。
- 数据隔离:每个租户的数据应完全隔离,保证数据的隐私和安全。
- 灵活的访问控制:提供细粒度的权限管理,允许管理员为不同租户设置不同的访问权限。
完整的API套件
一个功能全面的向量数据库应提供以下API支持:
- 数据管理API:支持数据的插入、更新、删除和查询。
- 索引管理API:允许创建、更新和删除索引,以及索引的优化。
- 查询API:提供复杂的查询功能,如范围查询、模糊查询等。
- 监控和统计API:允许用户监控系统状态和性能,以及收集统计数据。
- 扩展API:支持第三方插件或扩展,以增强数据库的功能。
直观的用户界面和控制台
用户界面和控制台应具备以下特点:
- 易用性:界面应简洁直观,易于新用户快速上手。
- 功能性:提供全面的数据管理和监控功能,满足不同用户的需求。
- 响应性:界面应快速响应用户操作,提供流畅的用户体验。
- 定制性:允许用户根据需要定制界面布局和功能。
- 安全性:确保所有用户操作都符合安全标准,保护数据不被未授权访问。
通过这些功能与特性的对比,开发者和架构师可以更好地理解不同向量数据库的优势和局限,从而做出更合适的选择。
安装与配置
安装Docker和PostgreSQL
在开始使用向量数据库之前,首先需要安装Docker和PostgreSQL。Docker是一个开源的应用容器引擎,可以让开发者打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何支持Docker的平台上。PostgreSQL是一个强大的开源对象关系数据库系统。
安装Docker
- 访问Docker官网下载适合您操作系统的Docker安装包。
- 运行安装包,按照提示完成安装。
- 安装完成后,打开命令行工具,输入
docker --version,如果显示Docker版本信息,则表示安装成功。
安装PostgreSQL
- 使用Docker命令安装PostgreSQL:
这将启动一个名为docker run --name some-postgres -e POSTGRES_PASSWORD=mysecretpassword -d postgressome-postgres的PostgreSQL容器,并设置密码为mysecretpassword。 - 连接到PostgreSQL容器:
docker exec -it some-postgres psql -U postgres
创建数据库和表
安装好PostgreSQL后,接下来需要创建数据库和表来存储数据。
创建数据库
- 在PostgreSQL命令行中,创建一个新的数据库:
CREATE DATABASE mydatabase;
创建表
- 切换到新创建的数据库:
\c mydatabase - 创建一个表:
CREATE TABLE mytable (id SERIAL PRIMARY KEY, data TEXT);
安装pgvector插件
pgvector是一个PostgreSQL插件,用于支持向量数据的存储和查询。
安装插件
- 在PostgreSQL中安装pgvector插件:
CREATE EXTENSION vector;
Milvus的安装与快速启动
Milvus是一个开源的向量数据库,用于存储、索引和查询大规模向量数据。
安装Milvus
- 访问Milvus官网下载适合您操作系统的Milvus安装包。
- 按照官方文档的指引进行安装。
快速启动
- 启动Milvus服务:
milvus start - 使用Milvus提供的客户端工具或API进行数据插入和查询。
Zilliz Cloud的部署与使用
Zilliz Cloud是一个完全托管的向量数据库服务,提供了深度优化和开箱即用的Milvus体验。
部署Zilliz Cloud
- 访问Zilliz Cloud官网并注册账号。
- 创建一个新的项目。
- 部署Milvus实例。
使用Zilliz Cloud
- 使用Zilliz Cloud提供的API或SDK连接到集群。
- 开始使用向量搜索功能。
通过上述步骤,您可以成功安装和配置向量数据库,为后续的应用开发和数据处理打下坚实的基础。
应用场景与案例分析
图像检索中的应用
在图像检索领域,向量数据库如Milvus和PGVector展现出了其强大的功能和效率。这些数据库能够高效地存储和检索图像的特征向量,实现快速且准确的图像匹配。例如,在电子商务平台中,用户上传一张商品图片,系统可以通过向量数据库快速检索出相似的商品,从而提供个性化的购物推荐。这种应用不仅提高了用户体验,也增加了销售机会。
技术实现
- 图像特征提取:使用深度学习模型提取图像的特征向量。
- 向量存储与索引:将特征向量存储在向量数据库中,并创建高效的索引结构。
- 相似性搜索:通过计算用户上传图像的特征向量与数据库中图像向量的相似度,快速检索出最相似的图像。
AI工具集成中的角色
向量数据库在AI工具集成中也扮演着关键角色。随着机器学习和深度学习技术的发展,越来越多的AI工具需要处理大量的向量数据。向量数据库如Zilliz Cloud提供了与这些AI工具无缝集成的接口,使得数据科学家和工程师可以更方便地进行模型训练和数据分析。
应用案例
- 自然语言处理:在NLP应用中,文本数据被转换为向量表示,存储在向量数据库中。这些向量可以通过相似性搜索来找到相关的文本片段。
- 推荐系统:在推荐系统中,用户和物品的特征向量被存储在向量数据库中,通过计算相似度来推荐用户可能感兴趣的物品。
RAG系统的需求
RAG(Retrieval-Augmented Generation)系统是一种结合了信息检索和生成模型的AI系统,用于生成基于特定上下文的信息。向量数据库在RAG系统中的作用主要体现在以下几个方面:
- 知识检索:RAG系统首先使用向量数据库进行知识检索,找到与查询最相关的信息片段。
- 上下文增强:检索到的信息随后被用作生成模型的上下文,帮助模型生成更准确和相关的输出。
- 实时更新:向量数据库支持实时数据更新,这对于RAG系统来说非常重要,因为它们需要处理最新的数据和信息。
应用案例
- 问答系统:在客户服务中,RAG系统可以使用向量数据库来检索相关的历史对话和产品信息,以生成更准确的回答。
- 聊天机器人:在聊天机器人中,RAG系统利用向量数据库检索相关知识,以提供更加智能和自然的对话体验。
通过这些案例分析,我们可以看到向量数据库在多种应用场景中的重要性和灵活性,它们是现代AI和大数据应用的关键组件。
如何选择向量数据库
选择合适的向量数据库对于项目的成功至关重要。不同的应用场景和需求可能需要不同的数据库解决方案。以下是根据不同阶段和需求选择向量数据库的建议。
入门或demo的选择
对于初学者或需要快速搭建原型(demo)的开发者来说,选择一个易于安装、配置简单且功能齐全的向量数据库至关重要。以下是一些建议:
- PGVector:作为PostgreSQL的扩展,PGVector提供了简单的向量存储和查询功能。它适合初学者学习向量数据库的基本概念,且安装过程简单,只需在现有的PostgreSQL数据库中添加扩展即可。
- Zilliz Cloud:Zilliz Cloud提供了一个完全托管的向量数据库服务,适合快速搭建demo。它提供了直观的用户界面和完整的API支持,使得即使是初学者也能快速上手。
产品开发的选择
在产品开发阶段,性能、可扩展性和稳定性成为主要考虑因素。以下是一些建议:
- Milvus:Milvus是一个开源的向量数据库,专为大规模向量相似性搜索设计。它支持高并发查询和插入,适合需要高性能和可扩展性的产品开发。
- Elasticsearch:虽然Elasticsearch主要用于全文搜索,但它也提供了向量搜索功能。对于已经使用Elasticsearch的项目,添加向量搜索功能可以利用现有的基础设施。
现有系统上使用矢量功能的选择
如果您的现有系统需要集成向量功能,选择与现有系统兼容的向量数据库至关重要。以下是一些建议:
- PGVector:如果您的系统已经使用PostgreSQL,添加PGVector扩展可以无缝集成向量功能,无需更改现有架构。
- Elasticsearch:对于使用Elasticsearch的系统,通过其向量搜索插件可以轻松添加向量搜索功能。
架构建议
在选择向量数据库时,还需要考虑整体系统架构。以下是一些架构建议:
- 云原生支持:选择支持云原生的向量数据库,如Zilliz Cloud,可以利用云服务的弹性伸缩和自动管理功能,简化运维。
- 多租户支持:如果您的应用需要支持多租户,选择支持多租户和数据隔离的向量数据库,如Milvus,可以确保每个租户的数据安全和性能。
- API和SDK支持:确保所选的向量数据库提供丰富的API和SDK支持,以便于集成到不同的应用和平台中。
总之,选择向量数据库时,应根据项目的具体需求、现有技术栈和未来的扩展计划来做出决策。通过对比不同数据库的性能、功能和易用性,可以找到最适合您项目的解决方案。
结论与建议
根据需求选择合适的数据库
在选择向量数据库时,关键在于理解并匹配您的具体需求与各个数据库的特性和性能。例如,如果您需要处理大规模的图像或视频数据,并且对性能有极高要求,Milvus或Zilliz Cloud可能是理想的选择。这些数据库专为高吞吐量和低延迟的向量搜索设计,能够支持从百万到数十亿甚至数万亿的向量数据。
对于那些数据量较小,且更注重快速部署和简单操作的项目,Chroma或PGVector可能更为适合。这些数据库虽然可能在可扩展性和高级功能上有所限制,但它们提供了更为直观和易于管理的界面,适合快速开发和原型验证。
未来发展趋势与技术更新
随着人工智能和机器学习技术的不断进步,向量数据库的需求和功能也在持续演进。未来的向量数据库将更加注重云原生支持、多模态数据处理能力以及与AI框架的深度集成。此外,随着数据隐私和安全性的日益重要,未来的向量数据库也将加强在这些方面的功能。
技术更新方面,预计会有更多的优化算法和索引技术被引入,以提高搜索效率和准确性。同时,随着硬件技术的进步,如GPU和TPU的广泛应用,向量数据库的性能将得到进一步提升。
选择矢量数据库的建议
-
明确需求:在选择数据库之前,首先要明确您的项目需求,包括数据量、查询速度、可扩展性、成本等因素。
-
考虑未来发展:选择那些能够支持未来技术发展和业务扩展的数据库。例如,选择支持云原生架构的数据库,可以更容易地进行水平扩展。
-
评估社区和支持:一个活跃的开发社区可以提供更多的资源和帮助,同时也能确保数据库的持续更新和维护。
-
进行实际测试:在做出最终决定之前,进行实际的性能测试和功能验证,以确保所选数据库能够满足您的具体需求。
-
考虑成本效益:虽然高性能的数据库可能成本较高,但考虑到长期运营成本和潜在的业务增长,选择性价比高的数据库是明智的。
总之,选择向量数据库是一个需要综合考虑多个因素的决策过程。通过深入了解不同数据库的特性和性能,结合自身的需求和未来发展趋势,您将能够做出最合适的选择。
相关文章:

全面对比与选择指南:Milvus、PGVector、Zilliz及其他向量数据库
本文全面探讨了Milvus、PGVector、Zilliz等向量数据库的特性、性能、应用场景及选型建议,通过详细的对比分析,帮助开发者和架构师根据具体需求选择最合适的向量数据库解决方案。 文章目录 向量数据库概述向量数据库的关键功能向量数据库的扩展和选择向量…...

svm 超参数
https://www.cnblogs.com/ChevisZhang/p/12932674.html https://wenku.baidu.com/view/b8a2c73cfd4733687e21af45b307e87100f6f861.html?wkts1718332423081&bdQuerysvm%E7%9A%84%E8%B6%85%E5%8F%82%E6%95%B0 用交叉验证找到最好的参数 C 和γ 。使用 RBF 核时,…...

001-基于Sklearn的机器学习入门:Sklearn库基本功能和标准数据集
本节将介绍Sklearn库基本功能,以及其自带的几个标准数据集的调用方法。本节是学习后面内容的基础,如果您已经对本节内容相当熟悉,可跳过本节内容。 1.1 Sklearn库基本功能 的 1.2 Sklearn库标准数据集 Sklearn自带许多标准数据集ÿ…...

充电学习—7、BC1.2 PD协议
BC1.2(battery charging)充电端口识别机制: SDP、CDP、DCP 1、VBUS detect:vbus检测 PD(portable device,便携式设备)中有个检测VBUS是否有效的电路,电路有个参考值,高…...
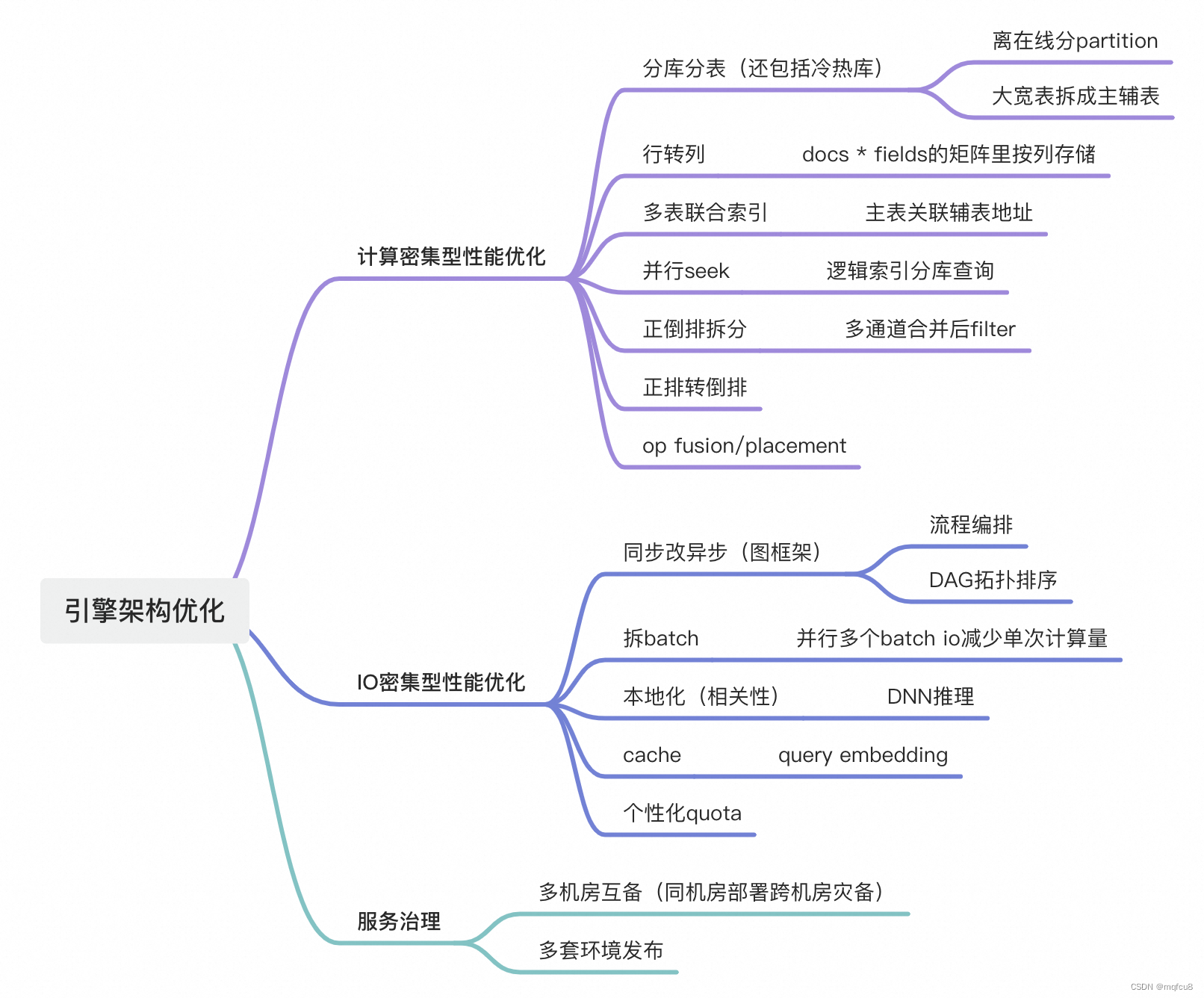
技术点梳理0618
ann建库,分布式建库,性能优化,precision recall参数优化 hnsw,图索引 1. build a)确定层:类似跳表思路建立多层,对每一个插入的节点,random层号l,从图的起始点search_…...

石英砂酸洗提纯方法和工艺
石英砂酸洗提纯方法和工艺是石英砂加工中至关重要的一个环节,其目的是通过化学手段去除石英砂中的杂质,提升其纯度。以下将详细介绍石英砂酸洗提纯的方法和工艺,以便更好地理解和应用这一技术。 一、概述 石英砂酸洗提纯主要是利用酸液对石英…...
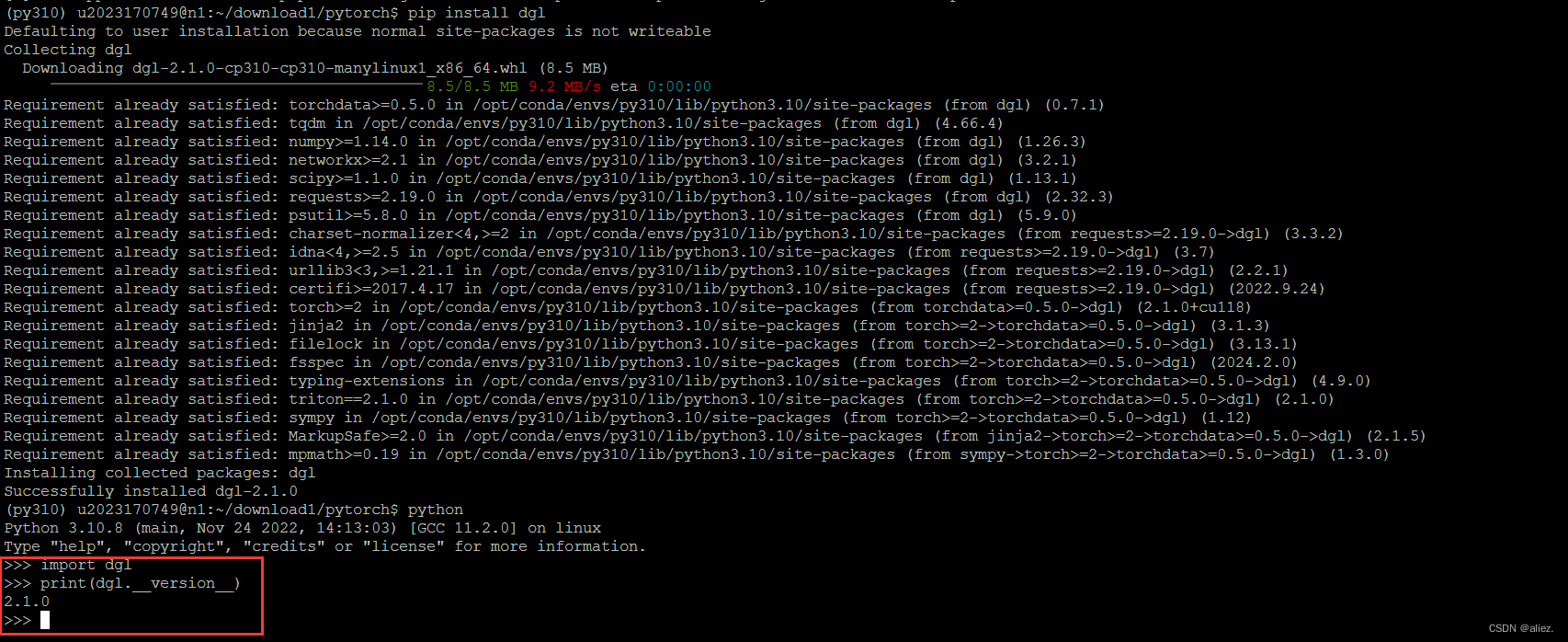
linux安装dgl
1.DGL官网、选择与自己cuda、python版本匹配的dgl的whl文件CUDA11.8、python10并下载 2.用pip install运行 pip install /home/u2023170749/download/dgl-2.2.0cu118-cp310-cp310-manylinux1_x86_64.whl或者直接安装https://blog.csdn.net/weixin_44017989/article/details/13…...
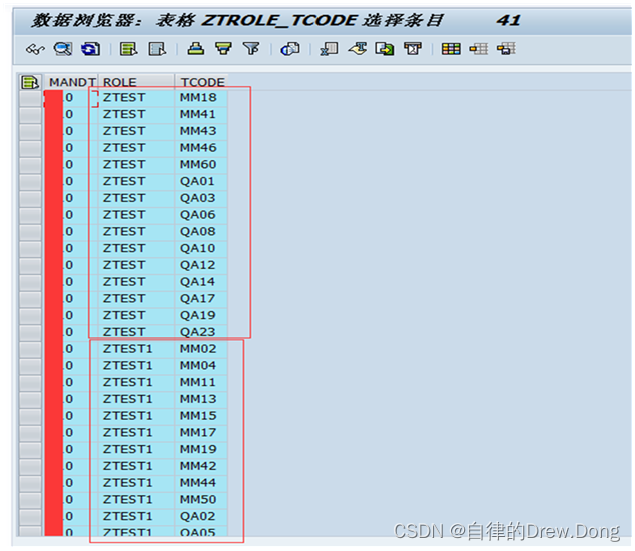
【SAP-ABAP】-权限批导-批量给某个角色导入事务码权限
需求:SAP期初上线的时候,业务顾问经常会遇到批量创建角色和分配角色权限的情况 岗位需求:一般是业务顾问定义权限,BASIS进行后期运维,今天讲两个批导功能,方便期初上线 主要函数:PRGN_READ_ROLE…...

异常处理总结
自定义异常 系统中的异常可以分为我们能预知的异常和未知的系统异常,对于我们能预知的异常如空值判断,用户名错误,密码错误等异常我们需要返回客户端,对于系统内部异常如SQL语法错误,参数格式转换错误等需要统一包…...

大模型日报2024-06-18
大模型日报 2024-06-18 大模型资讯 大模型产品 Olvy 3.0:AI加速客户反馈分析 摘要: Olvy 3.0推出AI自动监听和智能标签功能,通过Google Meet集成轻松提取洞察,贴近客户,激发同理心。 PlantIdentify-免费植物识别应用 摘要: PlantI…...

NumPy 双曲函数与集合操作详解
NumPy 双曲函数 NumPy 提供了 sinh()、cosh() 和 tanh() 等 ufunc,它们接受弧度值并生成相应的双曲正弦、双曲余弦和双曲正切值。 示例: import numpy as npx np.sinh(np.pi/2)print(x)示例 找到数组 arr 中所有值的双曲余弦值: import…...
)
ABSD-系统架构师(十三)
1、CDN和反向代理的基本原理都是()。 A缓存 B负载均衡 C路由转发 DNAT转发 答案:A 2、(必考)在ABSD(基于架构的软件开发)方法中,顶层被分解为()ÿ…...
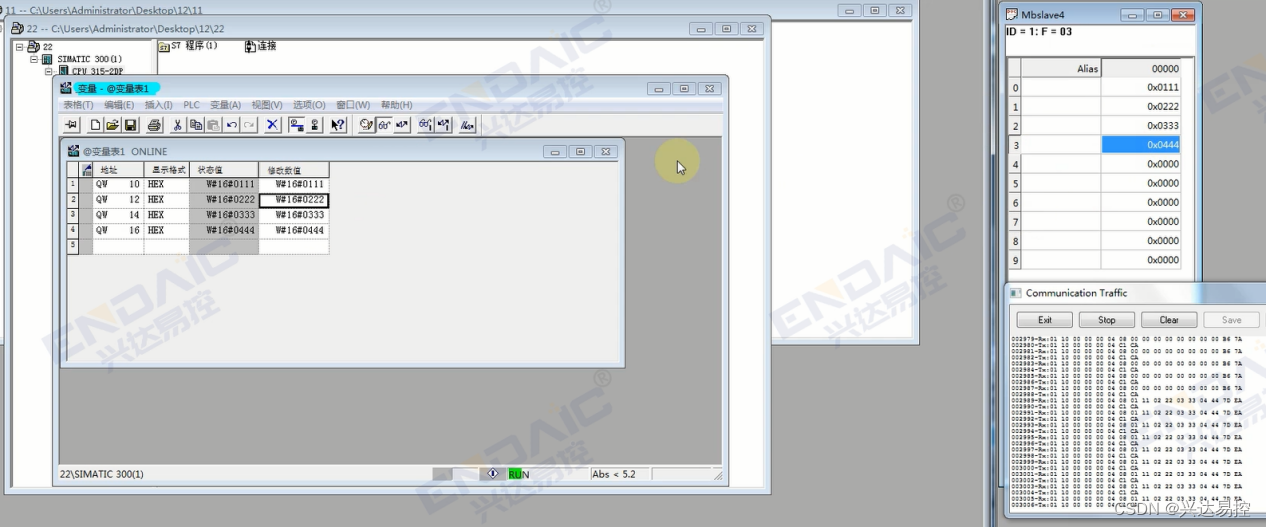
PLC通过Profibus协议转Modbus协议网关接LED大屏通讯
一、背景 Modbus协议和Profibus协议是两种常用于工业控制系统的通信协议,它们在自动化领域中起着重要的作用。Modbus是一种串行通信协议,被广泛应用于各种设备之间的通信,如传感器、执行器、PLC等。而Profibus则是一种现场总线通信协议&…...
第二十三篇——香农第二定律(二):到底要不要扁平化管理?
目录 一、背景介绍二、思路&方案三、过程1.思维导图2.文章中经典的句子理解3.学习之后对于投资市场的理解4.通过这篇文章结合我知道的东西我能想到什么? 四、总结五、升华 一、背景介绍 对于企业的理解,扁平化的管理,如果从香农第二定律…...

stm32f103 HAL库 HC-SR04测距
目录 一、实现测距二、添加TIM3控制LED根据距离以不同频率闪烁三、观察时序Modebus协议12路超声波雷达设计方案1. 系统架构设计2. 硬件设计3. 软件设计4. 通信协议设计5. 用户接口6. 安全和冗余7. 测试和验证8. 电源和物理封装9. 文档和支持 一、实现测距 配置时钟 配置定时器…...
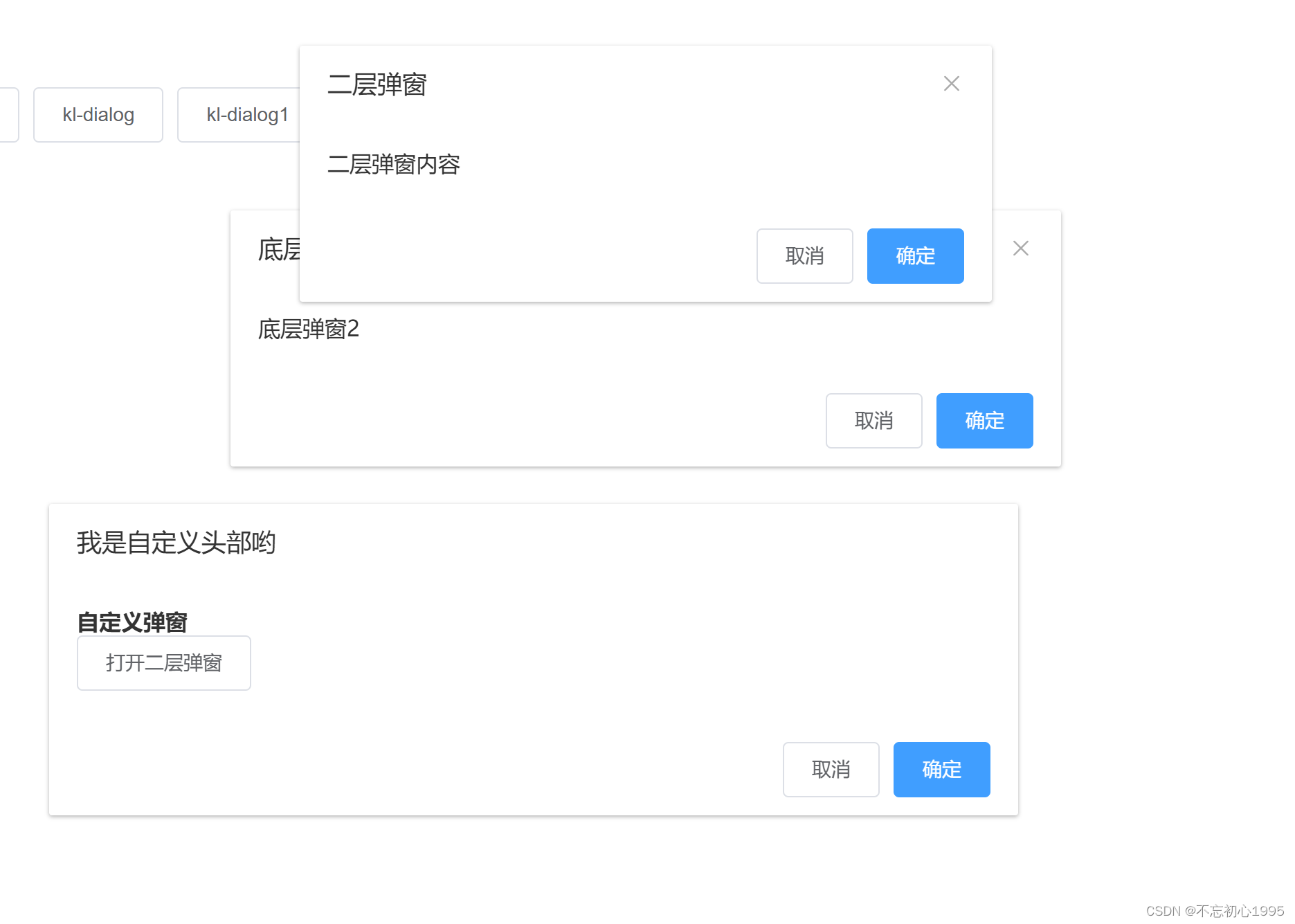
vue中通过自定义指令实现一个可拖拽,缩放的弹窗
效果 功能描述 按住头部可拖拽鼠标放到边框,可缩放多层重叠丰富的插槽,易于扩展 示例 指令代码 export const dragDialog {inserted: function (el, { value, minWidth 400, minHeight 200 }) {// 让弹窗居中let dialogHeight el.clientHeight ?…...

FreeRtos-09事件组的使用
1. 事件组的理论讲解 事件组:就是通过一个整数的bit位来代表一个事件,几个事件的or和and的结果是输出 #define configUSE_16_BIT_TICKS 0 //configUSE_16_BIT_TICKS用1表示16位,用0表示32位 1.1 事件组适用于哪些场景 某个事件若干个事件中的某个事件若干个事件中的所有事…...
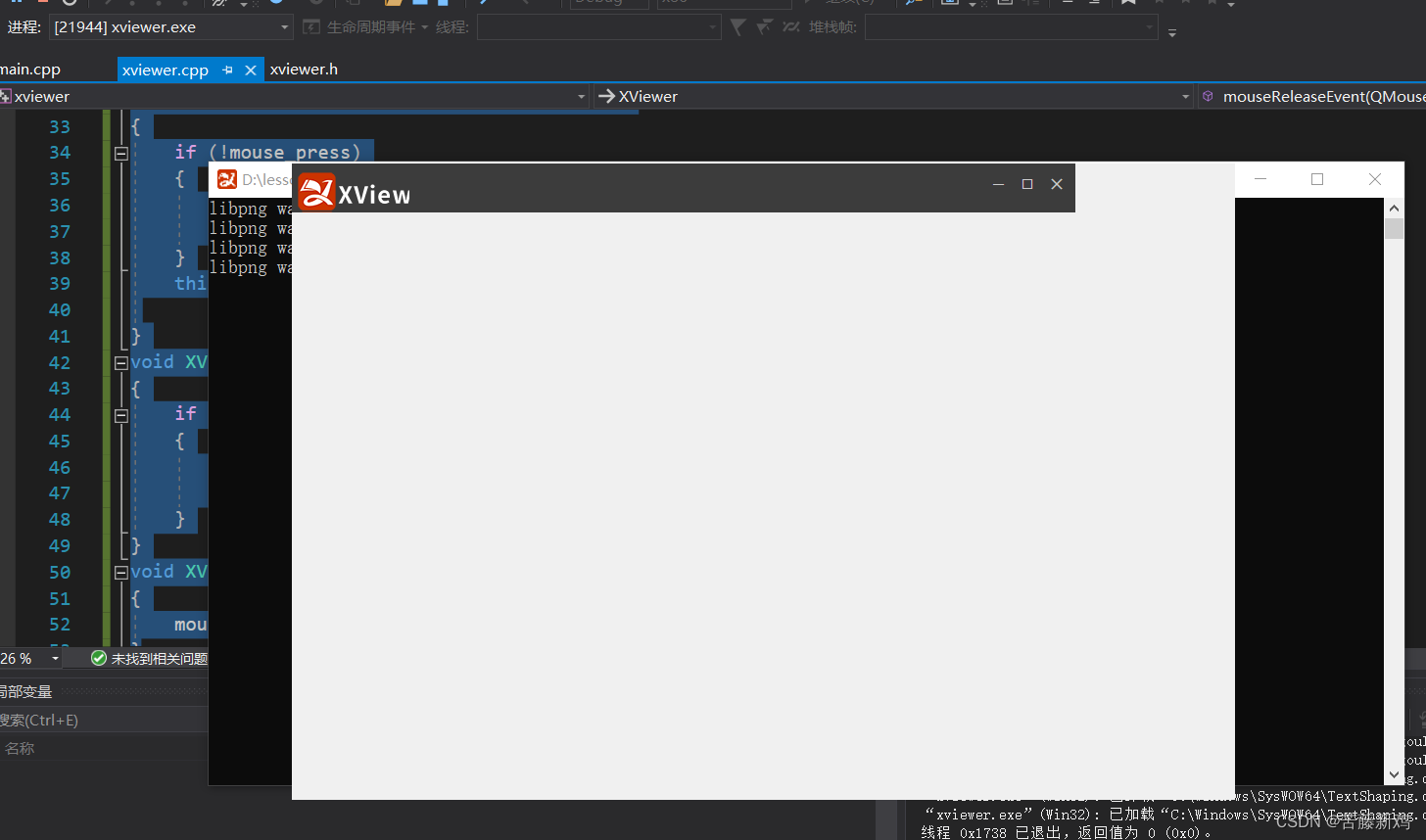
多路h265监控录放开发-(1)建立head窗口并实现鼠标拖动整个窗口
头文件: //鼠标事件 用于拖动窗口//一下三个函数都是QWidget的可重载成员函数void mouseMoveEvent(QMouseEvent* ev) override;void mousePressEvent(QMouseEvent* ev) override;void mouseReleaseEvent(QMouseEvent* ev) override; 源文件: / /// 鼠标…...

ICMR 2024在普吉岛闭幕,学者与泰国舞者共舞,燃爆全场
惊艳!ICMR 2024在普吉岛闭幕,学者与泰国舞者共舞,燃爆全场! 会议之眼 快讯 ICMR(International Conference on Multimedia Retrieval)即国际多媒体检索会议,是一个专注于多媒体检索领域的顶级…...

大模型精调:实现高效迁移学习的艺术
在人工智能领域,大型预训练模型(以下简称“大模型”)已经取得了令人瞩目的成果。这些模型通过在海量数据上进行预训练,能够捕捉到丰富的特征信息,为各种下游任务提供强大的支持。然而,如何将这些大模型应用…...
)
用STM32F103和电位器给你的无刷电机做个“油门”:手把手实现ADC调速(附完整代码)
用STM32F103和电位器打造无刷电机调速系统:从硬件连接到代码实战 旋转电位器旋钮就能精准控制无刷电机转速,这种直观的交互方式在机器人、无人机和工业控制领域有着广泛应用。本文将带您从零开始,基于STM32F103微控制器构建完整的电位器调速…...
)
别再只做静态分析了!用DPABI探索小鼠大脑rs-fMRI的动态功能连接(含Matlab代码片段)
动态功能连接分析:解锁小鼠大脑rs-fMRI的时变奥秘 在神经影像研究领域,静息态功能磁共振成像(rs-fMRI)已成为探索大脑功能组织的强大工具。传统静态分析方法虽然提供了宝贵的基础认知,但大脑本质上是一个动态系统,其功能连接会随时…...

基于MCP协议构建Azure DevOps智能助手:连接AI与开发运维的实践指南
1. 项目概述:一个连接开发与运维的智能“翻译官”如果你和我一样,长期在Azure DevOps的流水线、看板和代码仓库里打转,同时又对新兴的AI编程助手(比如Claude、Cursor)爱不释手,那你肯定遇到过这样的困境&am…...
)
ESP32-C3驱动2寸ST7789屏幕?手把手教你搞定LVGL移植(附避坑代码)
ESP32-C3与ST7789屏幕的LVGL移植实战指南 在物联网设备开发中,显示交互界面往往是提升用户体验的关键一环。ESP32-C3作为乐鑫推出的高性价比RISC-V芯片,搭配ST7789驱动的2寸LCD屏幕,能够构建出性能稳定、成本可控的嵌入式显示方案。本文将带你…...

macOS微信防撤回终极指南:3分钟轻松安装WeChatIntercept插件
macOS微信防撤回终极指南:3分钟轻松安装WeChatIntercept插件 【免费下载链接】WeChatIntercept 微信防撤回插件,一键安装,仅MAC可用,支持v3.7.0微信 项目地址: https://gitcode.com/gh_mirrors/we/WeChatIntercept 还在为微…...

第一:基于人工智能的自动化测试工具【testRigor】
1.testRigor是基于人工智能口驱动的无代码自动化测试平台,它能够自动生成测试用例,无需人工编写测试脚本2.它能通过分析应用的行为模式,智能地设计出覆盖面广、针对性强的测试场景3.官方网址:https://testrigor.com/一.支持平台 1…...

Sunshine自托管游戏串流服务器:构建高性能私人云游戏平台的完整指南
Sunshine自托管游戏串流服务器:构建高性能私人云游戏平台的完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款功能强大的自托管游戏串流服务器&am…...

开源基础大模型实战:从零构建领域专家模型的技术指南
1. 项目概述:从零到一,理解开源基础大模型的价值最近在社区里看到不少朋友在讨论“datawhalechina/base-llm”这个项目,乍一看名字,可能觉得又是一个平平无奇的模型仓库。但如果你真的动手去部署、去尝试、去理解它背后的设计&…...

亿图脑图高级技能:从思维建模到生产力提升的完整指南
1. 项目概述与核心价值最近在整理个人知识库和项目文档时,我一直在寻找一个能让我思维更清晰、协作更高效的“大脑外挂”。市面上思维导图工具不少,但要么功能臃肿、学习曲线陡峭,要么过于轻量、难以应对复杂的结构化思考。直到我深度体验并拆…...

苏州晟雅泰电子的主营业务及应用领域和优势产品有哪些
苏州晟雅泰电子有限公司(SUNTEC)的主营业务是研发生产和代理销售网络变压器等磁性元器件。其核心产品和技术广泛应用于网络通讯、安防监控和服务器/数据中心等领域。🔑 主营业务与核心产品该公司深耕磁性元器件领域,具体产品和服务…...