十分钟学会微调大语言模型
有同学给我留言说想知道怎么训练自己的大语言模型,让它更贴合自己的业务场景。完整的大语言模型训练成本比较高昂,不是我们业余玩家能搞的,如果我们只是想在某个业务场景或者垂直的方面加强大模型的能力,可以进行微调训练。
本文就来介绍一种大语言模型微调的方法,使用的工具是我最近在用的 Text Generation WebUI,它提供了一个训练LoRA的功能。
LoRA是什么
LoRA之于大语言模型,就像设计模式中的装饰器模式:装饰器模式允许向一个对象添加新的功能,而不改变其结构。具体来说,装饰器模式会创建一个装饰类,用来包装原有的类,并在保持原有类方法签名完整性的前提下,提供额外的功能。
LoRA,全称为Low-Rank Adaptation,是一种微调大型语言模型的技术。LoRA通过向大型语言模型添加一层额外的、低秩的可训练权重,来增强或调整模型的功能,而不需要改变原有模型的结构或重新训练整个模型。这就像是用装饰器包装了一个对象,增强了其功能,但没有改变原有对象的本质。
LoRA的关键思想是在模型的某些部分(通常是Transfomer注意力机制的权重矩阵)中引入低秩矩阵(低秩就是矩阵的行和列相对大模型的矩阵比较少)。在前向传播和反向传播过程中,这些低秩矩阵与大模型的权重矩阵相结合,从而实现对模型的微调。
相比完整的训练,LoRA训练具备两个明显的优势:
- 高效:微调过程中需要的计算资源和存储空间相对很少,如果训练数据只是几千条对话数据,我们可以在分钟级的时间内完成微调。
- 灵活:因为引入的参数数量相对较少,可以在一定程度上避免过拟合问题,使得模型更容易适应新任务。
因此,研究人员和开发者使用LoRA,可以在不牺牲模型性能的前提下,以较低的成本对模型进行有效的定制和优化。
工具安装
安装比较简单,如果遇到问题,欢迎留言讨论。
为了方便测试,我在云环境也创建了一个镜像,相关的环境都配置好了,大家都可以用,内置了几个国内开源的大语言模型,比如清华智谱的ChatGLM3-6B、零一万物的Yi-34B,还有最近阿里云开源的Qwen1.5-32B。
镜像使用方法:
2、GPU型号:最好选择 3090 或者 4090。因为大模型需要的显存一般都不低,6B、7B的模型做推理都需要15G左右的显存。GPU数量选择1个就够了。

3、镜像:选择“社区镜像”,输入 yinghuoai-text-generation-webui ,即可选择到我分享的镜像。

4、服务器开机后,点击“JupyterLab”进入一个可编程的Web交互环境。

5、镜像内置了一个“启动器”,点击其中的启动按钮可以直接启动WebUI。

程序默认加载的是阿里开源的 Qwen1.5-7B-Chat 模型,你也可以更换别的模型,只需要去掉命令前边的“#”,注意同时只能加载一个模型,其它模型不使用时,请使用“#”注释掉。

6、在下方的日志中看到类似输出的时候,就代表启动成功了。其中的 [xxx.gradio.live]就是WebUI的链接,点击就可以在浏览器打开它的使用界面。

Lora训练方法
终于来到重点环节了。
训练
训练需要一个基础模型,镜像默认加载的是 Qwen1.5-7B-Chat。你也可以在WebUI中更换别的模型(前提是已经下载到模型目录),在 Model 页签这里选择别的模型,然后点击 Load 加载它。

我们先来快速的过一遍训练过程,请按照下边的步骤开启LoRA训练:
1、切换到 Training 页签。
2、点击 Train LoRA,进入LoRA训练设置页面。
3、填写Lora模型的名字,注意名字中不能包含英文的点(.)。
4、点击 Formatted DataSet,代表训练将使用格式化的数据集。
5、Data Format 数据格式,这里选择 alpaca-format,这是一种Json数据格式,每条数据声明了指令、输入和输出(其中input是可选的,我们可以把input的内容填写到instructions中,从而去掉input节点),如下所示:
{"instruction": "下面是一个对话:","input":"只剩一个心脏了还能活吗?","output": "能,人本来就只有一个心脏。"
}6、Dataset 选择数据集,我这里从 huggingface 上下载了一份弱智吧的问答数据集,镜像中已经内置。你如果使用自己的训练数据集,请上传到 text-generation-webui/training/datasets 中,然后在这里刷新后就可以选择到。
7、点击 Start LoRA Training 开始训练。
8、这里会展示训练的进度,还剩多长时间。

训练完成后,这里会显示“Done”。注意这里有个问题:如果WebUI和服务器断开了网络连接,这里就不更新进度了,此时可以去 AutoDL的 jupyterlab 或者你的命令界面中查看训练进度。

验证
训练完成后,我们需要测试下效果,参考如下步骤:
1、切换到 Model 页面。
2、点击 Reload 重新加载模型,因为此时模型已经被训练污染了。
3、刷新LoRA列表。
4、选择我们训练出来的模型。
5、Apply LoRAs 应用LoRA模型。

然后在 Parameters 中选择内置的聊天对话角色。

最后切换到 Chat 页面,开始对话测试。下面是我分别使用基础模型和添加LoRA模型后的对话截图,测试不是很严谨,但也能看到比较明显的差别。
两个 Qwen1.5-7B-Chat 很难回答正确的问题:
- 生鱼片是死鱼片吗?
- 小明的爸爸妈妈为什么不邀请小明参加他们的婚礼?


训练参数
在上边的步骤中我们使用的都是默认的训练参数,一般也就够了。但有时候对训练出的生成效果不太满意,就可以手动调整下训练参数,重新训练。
我这里把主要的几个参数介绍下:
1、目标模块
这个参数仅针对 llama 类型的模型结构,默认勾选的是 q_proj 和 v_proj,具体的名词不容易理解,我就不多说了,可以简单的认为是对模型的理解能力进行优化,一般这两个就够了。当然我们可以勾选更多的项目,优化模型的生成效果。但是可能会导致两个问题,一是训练要使用更多的资源,更慢;二是可能导致过拟合问题,也就是只在训练的数据上表现的好,面对新问题就不灵了。Qwen1.5-7B的模型结构也是llama类型的。

2、Epochs
这个参数代表我们要训练多少轮。训练的轮次越多,模型从训练数据中学到的越多,生成就越精确,不过也可能会导致过拟合的问题,所以需要根据实际测试的结果进行调整。
3、LoRA Rank
维度计数,模型权重的更新量。值越大越文件越大,内容控制力更强;较低的值则表示文件更小,控制程度较低。
对于较为简单的任务或者数据量较小的应用场景,可以选择较低的值,比如4或8。这样可以保持模型的简洁性,减少所需的存储空间和计算资源,同时避免过拟合。
对于复杂的自然语言处理任务,特别是需要捕捉精细语义关系、句法结构或领域专业知识的任务,或者大规模训练数据时,可能需要选择较高的值,如128、256甚至1024以上,这样才有足够的容量来学习到复杂的模式。更高的LoRA Rank需要更多的显存支持。
LoRA Rank还应该与LLM的基础模型规模相匹配,百亿权重的模型可以设置更大值,因为它可以承受更多的权重调整而不会过拟合。
4、LoRA Alpha
数值越高代表LoRA的影响力越大,默认是LoRA Rank值的两倍。当这个值较高时,适应新任务的能力会增强,但是对基础模型的影响会比较大,有过拟合的风险,尤其是在数据量有限的情况下。当这个值比较低时,对基础模型参数的改变较为温和,这可以保持预训练模型的泛化能力,但也会降低对新任务的适应性,特别是LoRA任务与预训练任务差异比较大时。
5、Learning Rate
学习率。机器学习在训练过程中会不断检查自己与训练数据的偏离程度,它有个名词叫损失(loss),一个合适的学习率会让损失逐渐收敛在一个最小值。如果学习率太大,步子就会迈的太大,不能获取较好的效果;但是如果学习率太小,又会训练的很慢,成本太高。如下图所示:

默认值 3e-4 表示 3 乘以 10 的负 4 次方,也就是 0.0003。最大1e-2表示0.01,最小1e-6表示0.000001。
另外需要平衡学习率和轮次:
高学习率 + 低轮次 = 非常快但质量较低的训练。
低学习率 + 高轮次 = 较慢但质量较高的训练。
6、LR Scheduler
学习率调度算法,默认的是线性衰减,也就是随着学习轮次的增加学习率逐渐降低。
还有使用常量、余弦退火、逆平方根、多项式时间等算法,线性衰减和余弦退火比较简单有效,平常使用的比较多,逆平方根衰减和多项式时间衰减在处理大规模数据或需要长时间训练时能提供更为稳定的收敛表现。
一个好的模型与训练数据和训练参数都有很大的关系,很难一蹴而就。
如果你对训练的结果不满意,可以调整这几个参数试试。注意重新训练前,先把基础模型重新加载。

以上就是本文的主要内容,如有问题,欢迎给我留言交流。
关注萤火架构,提升技术认知!
本文转自 https://juejin.cn/post/7359103640106106918,如有侵权,请联系删除。
相关文章:
十分钟学会微调大语言模型
有同学给我留言说想知道怎么训练自己的大语言模型,让它更贴合自己的业务场景。完整的大语言模型训练成本比较高昂,不是我们业余玩家能搞的,如果我们只是想在某个业务场景或者垂直的方面加强大模型的能力,可以进行微调训练。 本文…...

结合简单工厂和工厂方法模式:实现灵活的对象创建
前言 在软件开发过程中,创建对象的方式直接影响代码的灵活性和可维护性。设计模式提供了一种解决复杂问题的方法,其中简单工厂模式和工厂方法模式是两种常用的创建型模式。在这篇文章中,我们将结合这两种模式,通过一个实际案例&a…...

网抑云特殊版,登录即永久
前言 今天分享一款特殊版本的音乐软件,相信大家在听网抑云的时候会有两大烦恼, 一是歌曲需要开通VIP才可以收听,不管怎么说也是国内厂商普遍操作 但是第二种烦恼你万万想不到的是,开通了会员后,惊奇的发现ÿ…...

Kotlin 实战小记:No-Arg 引用解决 No constructor found的问题
一、问题 新的项目试用一下kotlin, 调用数据库查询数据的时候报了这个问题:org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.executor.ExecutorException: No constructor found in com.neusoft.collect.entity.cm.CmRoom matc…...
——列表表格)
HTML(5)——列表表格
列表 无序列表 作用:布局排列整齐的不需要规定顺序的区域。 标签:ul嵌套il,ul是无序列表,li是列表条目 注:ul标签只能包裹li标签,li标签可以包含任何内容 有序列表 作用:布局排列整齐的需…...

FreeBSD通过CBSD管理低资源容器jail来安装Ubuntu子系统实践
简介 FreeBSD、CBSD、Jail和Ubuntu,四者的组合方案可以说是强强联合,极具性价比和竞争力!同时安装简单方便,整体方案非常先进。 CBSD是为FreeBSD jail子系统、bhyve、QEMU/NVMM和Xen编写的管理层。该项目定位为一个综合解决方案…...

SpringCloud总结(springcloud alibaba)
目录 版本说明(很重要) springcloud alibaba对应组件版本说明 简述 spring cloud albaba 几大模块 周会讨论 - spring cloud alibaba每周都会有周会讨论,社区活跃 spring cloud alibaba官网 注册配置中心 简单介绍 nacos 步骤 示例代码 依赖…...

轻轻松松上手的LangChain学习说明书
本文为笔者学习LangChain时对官方文档以及一系列资料进行一些总结~覆盖对Langchain的核心六大模块的理解与核心使用方法,全文篇幅较长,共计50000字,可先码住辅助用于学习Langchain。 一、Langchain是什么? 如今各类AI…...

全面对比与选择指南:Milvus、PGVector、Zilliz及其他向量数据库
本文全面探讨了Milvus、PGVector、Zilliz等向量数据库的特性、性能、应用场景及选型建议,通过详细的对比分析,帮助开发者和架构师根据具体需求选择最合适的向量数据库解决方案。 文章目录 向量数据库概述向量数据库的关键功能向量数据库的扩展和选择向量…...

svm 超参数
https://www.cnblogs.com/ChevisZhang/p/12932674.html https://wenku.baidu.com/view/b8a2c73cfd4733687e21af45b307e87100f6f861.html?wkts1718332423081&bdQuerysvm%E7%9A%84%E8%B6%85%E5%8F%82%E6%95%B0 用交叉验证找到最好的参数 C 和γ 。使用 RBF 核时,…...

001-基于Sklearn的机器学习入门:Sklearn库基本功能和标准数据集
本节将介绍Sklearn库基本功能,以及其自带的几个标准数据集的调用方法。本节是学习后面内容的基础,如果您已经对本节内容相当熟悉,可跳过本节内容。 1.1 Sklearn库基本功能 的 1.2 Sklearn库标准数据集 Sklearn自带许多标准数据集ÿ…...

充电学习—7、BC1.2 PD协议
BC1.2(battery charging)充电端口识别机制: SDP、CDP、DCP 1、VBUS detect:vbus检测 PD(portable device,便携式设备)中有个检测VBUS是否有效的电路,电路有个参考值,高…...
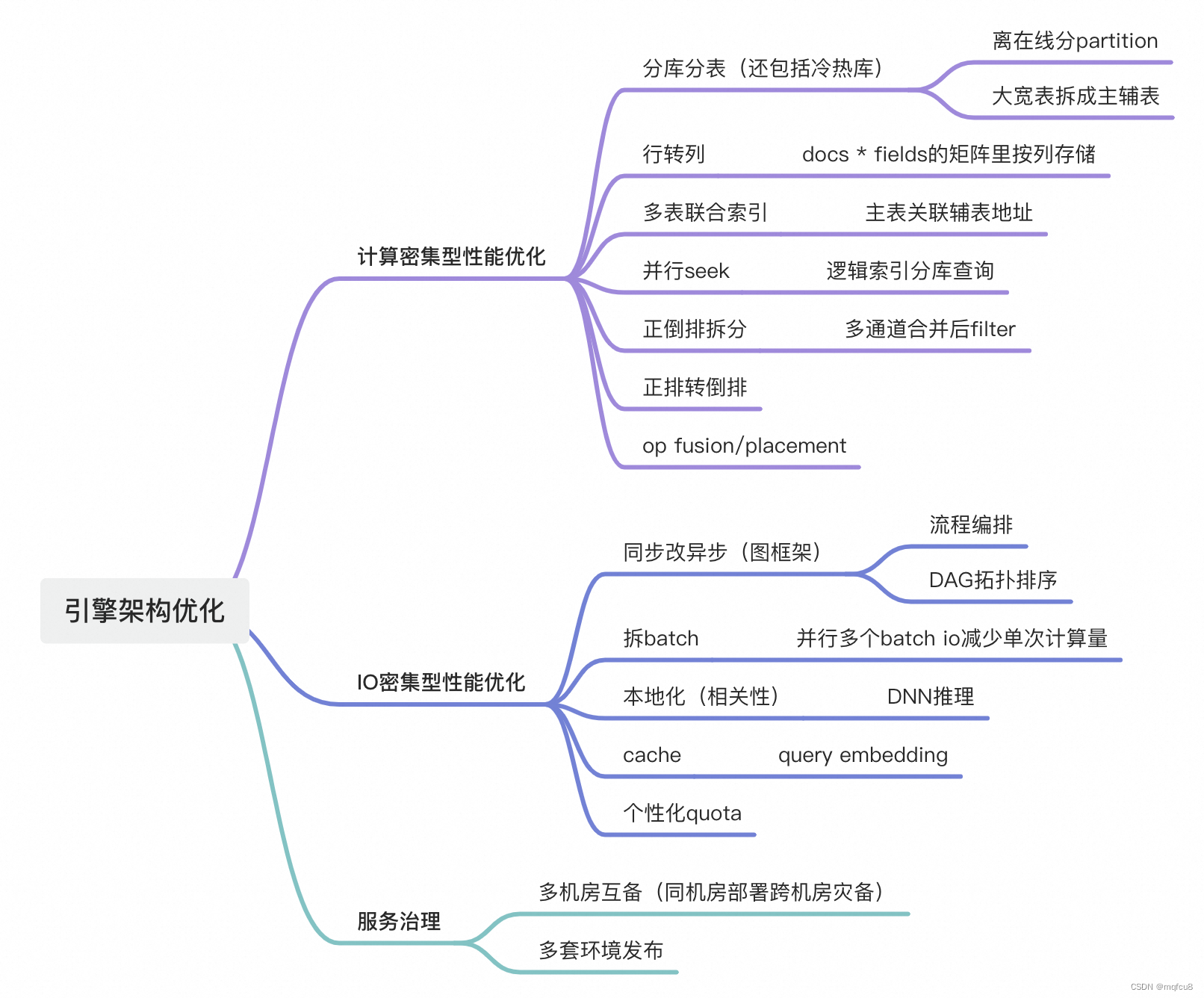
技术点梳理0618
ann建库,分布式建库,性能优化,precision recall参数优化 hnsw,图索引 1. build a)确定层:类似跳表思路建立多层,对每一个插入的节点,random层号l,从图的起始点search_…...

石英砂酸洗提纯方法和工艺
石英砂酸洗提纯方法和工艺是石英砂加工中至关重要的一个环节,其目的是通过化学手段去除石英砂中的杂质,提升其纯度。以下将详细介绍石英砂酸洗提纯的方法和工艺,以便更好地理解和应用这一技术。 一、概述 石英砂酸洗提纯主要是利用酸液对石英…...
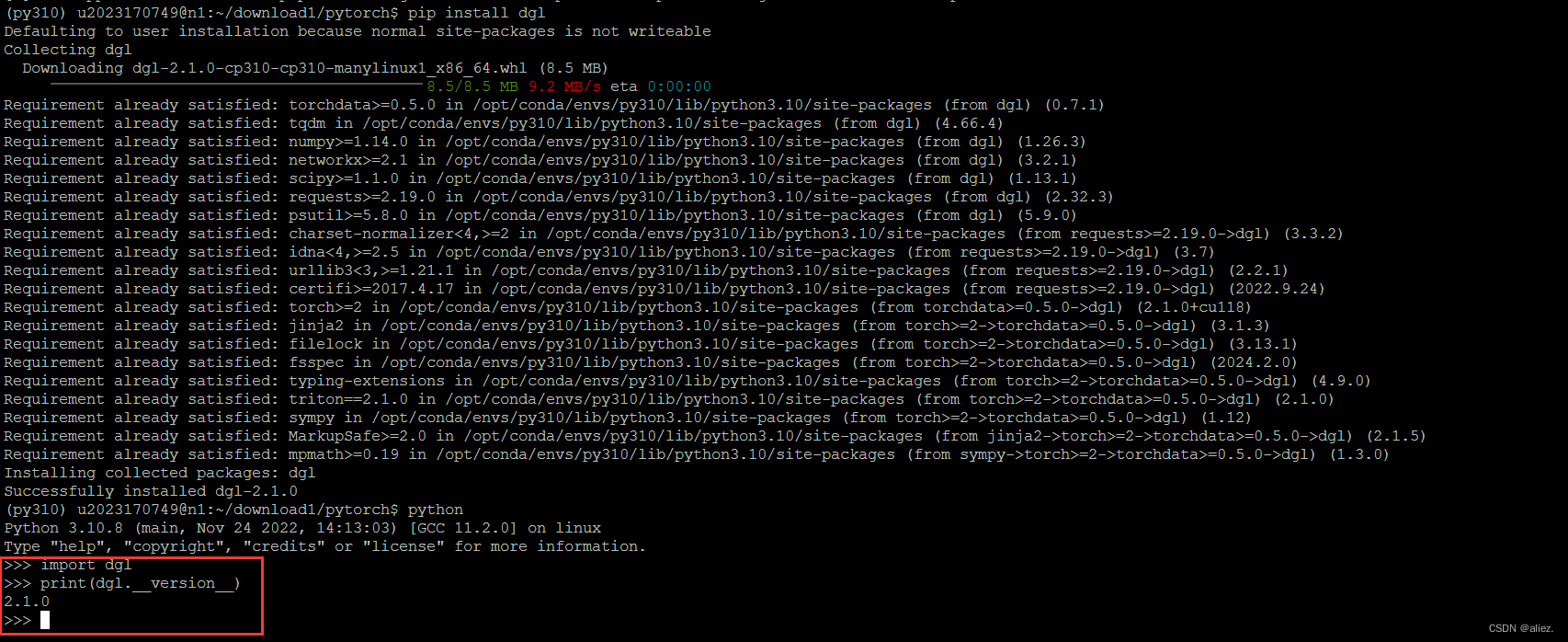
linux安装dgl
1.DGL官网、选择与自己cuda、python版本匹配的dgl的whl文件CUDA11.8、python10并下载 2.用pip install运行 pip install /home/u2023170749/download/dgl-2.2.0cu118-cp310-cp310-manylinux1_x86_64.whl或者直接安装https://blog.csdn.net/weixin_44017989/article/details/13…...
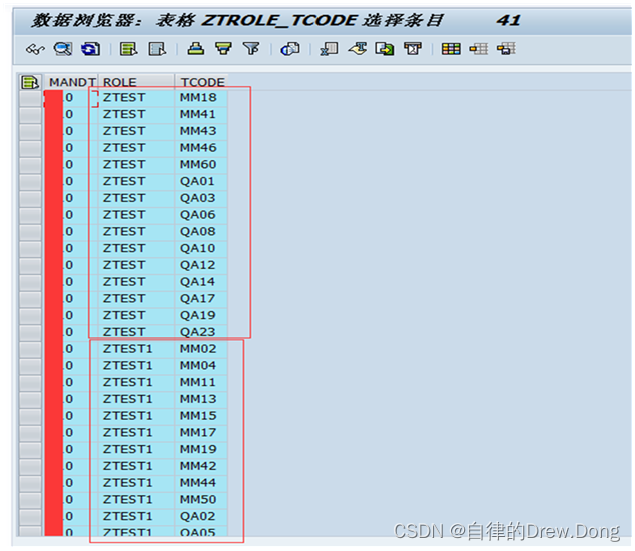
【SAP-ABAP】-权限批导-批量给某个角色导入事务码权限
需求:SAP期初上线的时候,业务顾问经常会遇到批量创建角色和分配角色权限的情况 岗位需求:一般是业务顾问定义权限,BASIS进行后期运维,今天讲两个批导功能,方便期初上线 主要函数:PRGN_READ_ROLE…...

异常处理总结
自定义异常 系统中的异常可以分为我们能预知的异常和未知的系统异常,对于我们能预知的异常如空值判断,用户名错误,密码错误等异常我们需要返回客户端,对于系统内部异常如SQL语法错误,参数格式转换错误等需要统一包…...

大模型日报2024-06-18
大模型日报 2024-06-18 大模型资讯 大模型产品 Olvy 3.0:AI加速客户反馈分析 摘要: Olvy 3.0推出AI自动监听和智能标签功能,通过Google Meet集成轻松提取洞察,贴近客户,激发同理心。 PlantIdentify-免费植物识别应用 摘要: PlantI…...

NumPy 双曲函数与集合操作详解
NumPy 双曲函数 NumPy 提供了 sinh()、cosh() 和 tanh() 等 ufunc,它们接受弧度值并生成相应的双曲正弦、双曲余弦和双曲正切值。 示例: import numpy as npx np.sinh(np.pi/2)print(x)示例 找到数组 arr 中所有值的双曲余弦值: import…...
)
ABSD-系统架构师(十三)
1、CDN和反向代理的基本原理都是()。 A缓存 B负载均衡 C路由转发 DNAT转发 答案:A 2、(必考)在ABSD(基于架构的软件开发)方法中,顶层被分解为()ÿ…...
)
【小白也能懂得操作】解决 OpenClaw 操作电脑受限问题详细指南(含安装包)
OpenClaw 没有电脑操作权限怎么办?完整解决方法 【新人点击链接直接下载openclaw安装包】 OpenClaw 在运行时需要对系统进行文件读写、键鼠模拟、窗口控制等操作,如果出现无法操作电脑、提示没有权限的问题,会直接影响自动化功能使用。本文…...

大湾区制造企业品牌突围:从“有品无牌”到价值孵化
当看到2023年凯度BrandZ全球品牌百强榜上苹果以8800亿美元蝉联榜首,14个中国品牌入围时,我们能清晰地感受到品牌价值对企业的重要性。然而,在粤港澳大湾区(广东),众多制造型中小企业面临着尴尬的局面&#…...
实现伽马校正的完整流程与资源优化)
别再硬算幂函数了!FPGA图像处理中,用查找表(LUT)实现伽马校正的完整流程与资源优化
别再硬算幂函数了!FPGA图像处理中,用查找表(LUT)实现伽马校正的完整流程与资源优化 在实时图像处理系统中,伽马校正(Gamma Correction)是一个无法绕开的关键环节。无论是医疗影像的增强显示&…...

10个UTF8-CPP最佳实践:让你的C++ Unicode处理更高效
10个UTF8-CPP最佳实践:让你的C Unicode处理更高效 【免费下载链接】utfcpp UTF-8 with C in a Portable Way 项目地址: https://gitcode.com/gh_mirrors/ut/utfcpp UTF8-CPP是一个轻量级的C库,提供了便捷的UTF-8编码和解码功能,帮助开…...

Atmosphere-stable:Nintendo Switch自制系统的技术架构深度剖析与实战指南
Atmosphere-stable:Nintendo Switch自制系统的技术架构深度剖析与实战指南 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 在Nintendo Switch自制系统领域,Atmosphe…...

对抗测试框架:用字节码增强与混沌工程提升系统韧性
1. 项目概述:一个对抗测试的“剧院”最近在开源社区里,我注意到一个名字挺有意思的项目,叫nanami7777777/anti-test-theater。乍一看,这个标题有点让人摸不着头脑——“反测试剧院”?测试和剧院能扯上什么关系…...

树莓派AI智能体进化框架:轻量级边缘持续学习实践
1. 项目概述:一个面向树莓派的AI智能体进化框架最近在折腾树莓派上的AI应用时,发现了一个挺有意思的项目,叫pk-pi-hermes-evolve。光看这个名字,就能拆出不少信息量:“pk”可能指代项目作者或一个特定系列,…...

Cursor编辑器光标主题自定义指南:从原理到实践
1. 项目概述:一个为开发者准备的“光标”资源宝库如果你是一名开发者,或者对提升代码编辑器的视觉体验和操作效率有追求,那么你很可能听说过或正在使用 Cursor 这款新兴的代码编辑器。它凭借深度集成的 AI 能力和现代化的设计,吸引…...

AI LED调光落地灯智能功率 MOSFET 完整选型方案
随着 AI 技术与智能家居深度融合,高端 LED 调光落地灯对驱动电路提出了新要求:超高调光精度、无频闪、多路独立控制及高能效。微碧半导体(VBsemi)基于先进的 Planar 与 Trench 工艺,为您提供覆盖高压隔离驱动、多路调光…...

轻量级包管理器LPM指南:从原理到实践,构建高效软件依赖管理方案
1. 项目概述:一个为开发者而生的轻量级包管理器指南如果你是一名开发者,尤其是经常在Linux或macOS环境下工作的开发者,那么“包管理器”这个词对你来说一定不陌生。从系统级的apt、yum、brew,到语言级的npm、pip、cargo࿰…...