Scala语言:大数据开发的未来之星 - 零基础到精通入门指南
前言
随着大数据时代的到来,数据量的急剧增长为软件开发带来了新的挑战和机遇。Scala语言因其函数式编程和面向对象的特性,以及与Apache
Spark的完美协作,在大数据开发领域迅速崛起,成为该领域的新兴宠儿。本篇将从零基础开始,介绍Scala语言的基础以及如何将Scala应用于大数据开发。

Scala简介
Scala是一种多范式的编程语言,其设计旨在以简洁、优雅的方式表达常见的编程模式,并能够扩展到大型系统的结构。Scala运行在Java虚拟机上,并能无缝地与其他Java代码和库进行交互。
在大数据开发领域,Scala的优势包括:
- 简洁性:Scala代码比等效的Java代码更加简洁。
- 函数式编程:Scala支持函数式编程,适合并行处理大量的数据。
- 高性能:Scala编译后的字节码运行效率高。
- 大数据生态系统:Scala与Hadoop及其他大数据工具高度集成。
Scala的基础知识
对于零基础的开发者来说,学习Scala需要从理解其基本语法和特性开始。
数据类型和控制结构
Scala支持多种数据类型,包括基本数据类型(如Int, Double, Boolean等)和复杂的数据结构(如List, Set, Map等)。Scala的控制结构也非常丰富,如if, for, while等。
// 定义变量
val message: String = "Hello, Scala!"
val number: Int = 42// 条件判断
if (number > 10) {println("Number is greater than 10")
} else {println("Number is less than or equal to 10")
}// 循环
for (i <- 1 to 10) {println(i)
}
函数和闭包
Scala中的函数是一等公民,可以赋给变量、作为参数传递或作为返回值返回。
// 定义函数
def add(a: Int, b: Int): Int = a + b// 使用闭包
val adder = (x: Int) => x + 10
println(adder(5)) // 输出 15
类和对象
Scala类和对象的定义非常直观,与Java语法相似但更为简洁。
// 定义类
class Person(name: String, age: Int) {def sayHello() = println(s"Hello, my name is $name and I am $age years old.")
}// 实例化类
val person = new Person("Alice", 30)
person.sayHello() // 输出 "Hello, my name is Alice and I am 30 years old."
高阶函数和集合
Scala集合提供的高阶函数(例如map, filter, reduce等)非常适合处理集合数据。
val numbers = List(1, 2, 3, 4, 5)
val doubled = numbers.map(_ * 2) // List(2, 4, 6, 8, 10)
val filtered = numbers.filter(_ % 2 == 0) // List(2, 4)
样例类和模式匹配
样例类和模式匹配是Scala中的特色功能,它们主要用于处理不可变数据。
// 定义样例类
case class User(name: String, age: Int)val user = User("Bob", 25)
val greeting = user match {case User(name, age) if age > 20 => s"Hello, $name! You are already $age."case User(name, age) => s"Hello, $name! You are $age."
}
println(greeting)
Scala在大数据中的应用
Scala与Apache Spark的结合是在大数据处理领域应用Scala语言的最好例子。Spark是一个强大的大数据处理框架,而Scala以其简洁的语法和强大的性能成为开发Spark应用程序的理想选择。
Spark RDD
Spark RDD(弹性分布式数据集)是Spark的核心数据结构,Scala可以非常自然地操作RDD。
import org.apache.spark._val conf = new SparkConf().setAppName("SparkScalaExample").setMaster("local")
val sc = new SparkContext(conf)val data = Array(1, 2, 3, 4, 5)
val dataRDD = sc.parallelize(data)val doubledRDD = dataRDD.map(_ * 2)
doubledRDD.foreach(println)
Spark SQL
Spark SQL提供了在Spark应用程序中处理结构化数据的工具。Scala可以用来编写SQL查询,还可以将其与Spark的RDD和DataFrame API相结合使用。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._val spark = SparkSession.builder().appName("ScalaSparkSQLExample").getOrCreate()
val df = spark.read.json("examples/src/main/resources/people.json")// 显示schema
df.printSchema()// 选择数据
val names = df.select("name")
names.show()// 过滤数据
val teenagers = df.filter(col("age") > 13 and col("age") < 19)
teenagers.show()
Spark MLlib
Spark MLlib是Spark的一个机器学习库,Scala可以用来实现机器学习算法和数据挖掘。
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.classification.SVMWithSGDval data = sc.textFile("data/mllib/sample_svm_data.txt")
val parsedData = data.map { line =>val parts = line.split(' ')LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(',').map(_.toDouble)))
}
val model = SVMWithSGD.train(parsedData, 100)
实践案例
实现一个简单的词频统计工具
假设我们有一个日志文件,我们想要统计每个词出现的频率。这将是一个典型的MapReduce问题,我们可以使用Scala和Spark来解决。
import org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]) {val conf = new SparkConf().setAppName("WordCount")val sc = new SparkContext(conf)val textFile = sc.textFile("hdfs://example/path/to/your/input.txt")val counts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)counts.saveAsTextFile("hdfs://example/path/to/your/output")}
}
结语
Scala语言的简洁性和大数据领域的紧密结合,使其成为大数据开发领域的一个重要工具。无论是从零基础开始学习Scala,还是在大数据领域寻求突破,Scala都能提供强大的支持和丰富的资源。Scala作为大数据开发的未来之星,值得每一名开发者学习和掌握。
参考文献
- Scala官网
- Apache Spark官方文档
以上是一篇以Scala语言为入门大数据开发指南的CSDN技术博客文章。由于不能直接提供实践中的真实代码和数据,示例代码仅作为参考。在实际应用中,读者可根据具体的项目需求和数据结构进行调整和优化。
码克疯v1 | 技术界的疯狂探索者 | 在代码的宇宙中,我是那颗永不满足的探索星。
相关文章:
Scala语言:大数据开发的未来之星 - 零基础到精通入门指南
前言 随着大数据时代的到来,数据量的急剧增长为软件开发带来了新的挑战和机遇。Scala语言因其函数式编程和面向对象的特性,以及与Apache Spark的完美协作,在大数据开发领域迅速崛起,成为该领域的新兴宠儿。本篇将从零基础开始&…...
Springboot整合Zookeeper分布式组件实例
一、Zookeeper概述 1.1 Zookeeper的定义 Zookeeper是一个开源的分布式协调服务,主要用于分布式应用程序中的协调管理。它由Apache软件基金会维护,是Hadoop生态系统中的重要成员。Zookeeper提供了一个高效且可靠的分布式锁服务,以及群集管理…...
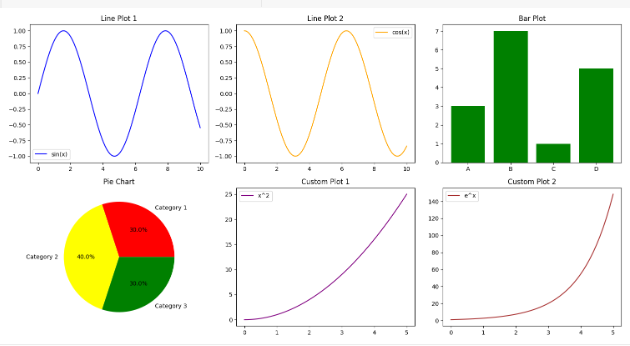
Python | 使用Matplotlib生成子图的示例
数据可视化在分析和解释数据的过程中起着举足轻重的作用。Python中的Matplotlib库提供了一个强大的工具包,用于制作各种图表和图表。一个突出的功能是它能够在单个图中生成子图,为以组织良好和结构化的方式呈现数据提供了有价值的工具。使用子图可以同时…...

云原生巡检监控报告
一、巡检概述 本次云原生巡检工作主要围绕云原生平台的稳定性、安全性以及性能进行,通过对平台资源的监控、日志分析以及安全扫描,发现了一些潜在的问题和隐患。巡检工作采用了自动化工具和人工分析相结合的方式,确保了巡检结果的准确性和全…...

Linux系统编程——部分内容补充
回顾 进程 内核相关数据结构 代码和数据,一个可执行程序加载到内存变成进程,不仅仅是把代码和数据加载进去就完事了,得“先描述,再组织”,每个进程都有内核数据结构,地址空间,进程相关页表&a…...

数学建模基础:非线性模型
目录 前言 一、非线性方程组 二、非线性规划 三、微分方程模型 四、非线性模型的应用 五、实例示范:传染病传播模型 实例总结 五、总结 前言 非线性模型用于描述变量之间的非线性关系,相比线性模型,其数学形式更为复杂,但…...
Kotlin 语言基础学习
什么是Kotlin ? Kotiln翻译为中文是:靠他灵。它是由JetBrains 这家公司开发的,JetBrains 是一家编译器软件起家的,例如常用的WebStorm、IntelliJ IDEA等软件。 Kotlin官网 JetBrains 官网 Kotlin 语言目前的现状: 目前Android 已将Kotlin 作为官方开发语言。 Spring 框…...

Kafka 之 KRaft —— 配置、存储工具、部署注意事项、缺失的特性
目录 一. 前言 二. 配置(Configuration) 2.1. 处理者角色(Process Roles) 2.2. 控制器(controller) 2.3. 存储工具(Storage Tool) 2.4. 调试(Debugging)…...

专业和学校到底怎么选,兴趣和知名度到底哪个重要?
前言 2024高考已经落下帷幕,再过不久就到了激动人心的查分和填报志愿的时刻,在那天到来,小伙伴们就要根据自己的分数选取院校和专业,接下来我就以参加22年(破防年)河南高考的大二生来讲述一下我自己对于如何选取院校和专业的看法以…...

【MySQL】数据库
数据库概述 【MySQL】数据库概述-CSDN博客 数据库基本操作 【MySQL】数据库基本操作-CSDN博客 数据表基本操作 【MySQL】数据表基本操作-CSDN博客 约束 【MySQL】约束-CSDN博客 基本增删改查 【MySQL】基本增删改查-CSDN博客 多表操作 【MySQL】多表操作-CSDN博客 视图 …...

D111FCE01LC2NB70带流量调节派克比例阀
D111FCE01LC2NB70带流量调节派克比例阀 派克比例阀:由于采用(秉圣135陈工6653询3053)电液混合控制技术,响应速度更快、精度更高、控制更平稳。同时,由于采用高质量的材料制造,具有较高的承压能力和抗磨损性…...
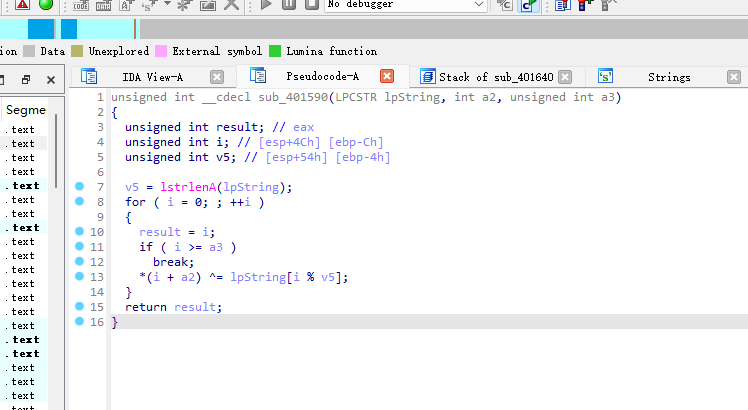
buuctf-findKey
exe文件 运行发现这个窗口,没有任何消息 32位 进入字符串就发现了flag{ 左边红色代表没有F5成功 我们再编译一下(选中红色的全部按p) LRESULT __stdcall sub_401640(HWND hWndParent, UINT Msg, WPARAM wParam, LPARAM lParam) {int v5; // eaxsize_t v6; // eaxDWORD v7; /…...

针对oracle系列数据库慢数据量大的问题
-- 确保索引存在 create index idx_risk_assessment_hazard on risk_assessment_hazard(data_time, perception_id); create index idx_risk_dispose_base_info on risk_dispose_base_info(perception_id); -- 使用并行查询和with子句进行优化 explain plan for with t2 as (se…...
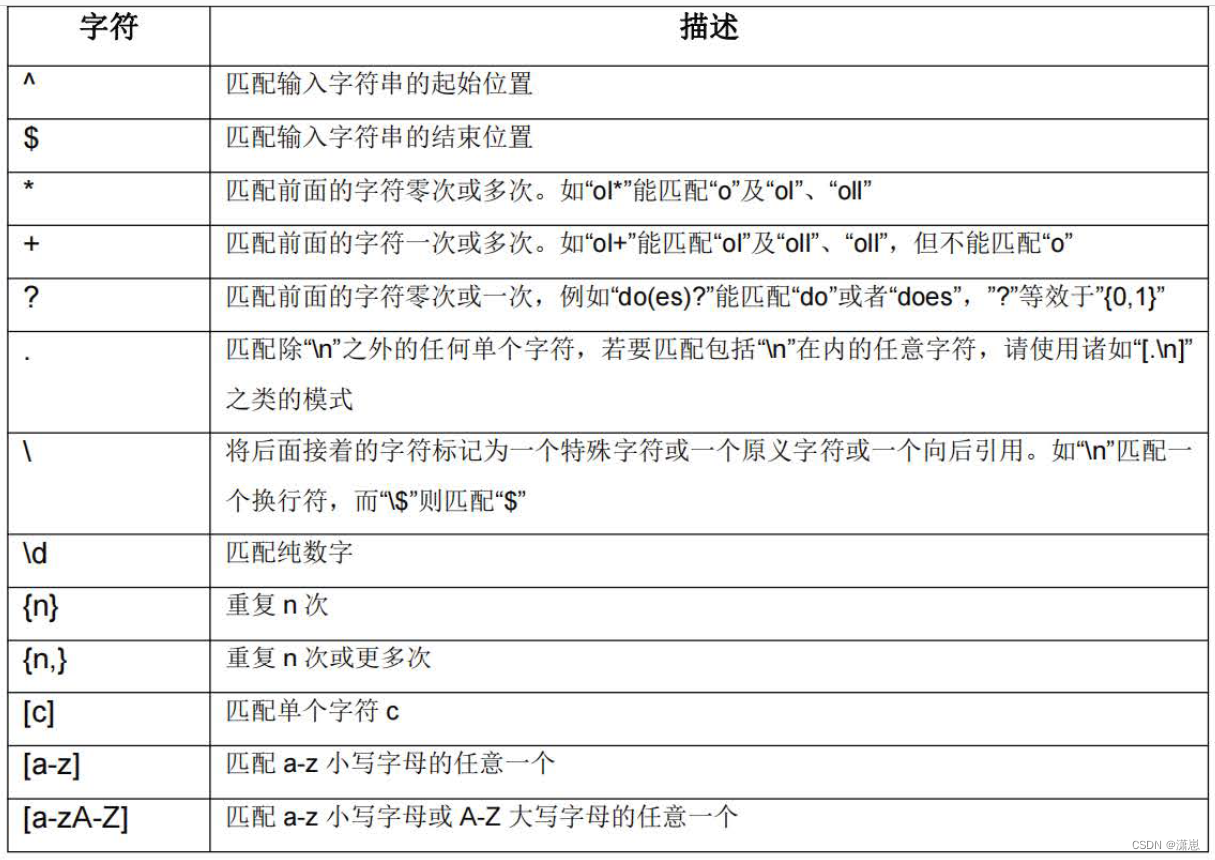
Nginx-Rewrite
1、Rewrite的定义 rewrite功能就是使用nginx提供的全局变量或自己设置的变量,结合正则表达式和标志位实现url重写以及重定向。rewrite只能放在 server { }, location { }, if { }中,并且只能对域名后边的除去传递的参数外的字符串起作用。 例如location…...

2024 年 Python 基于 Kimi 智能助手 Moonshot Ai 模型搭建微信机器人(更新中)
注册 Kimi 开放平台 Kimi:https://www.moonshot.cn/ Kimi智能助手是北京月之暗面科技有限公司(Moonshot AI)于2023年10月9日推出的一款人工智能助手,主要为用户提供高效、便捷的信息服务。它具备多项强大功能,包括多…...
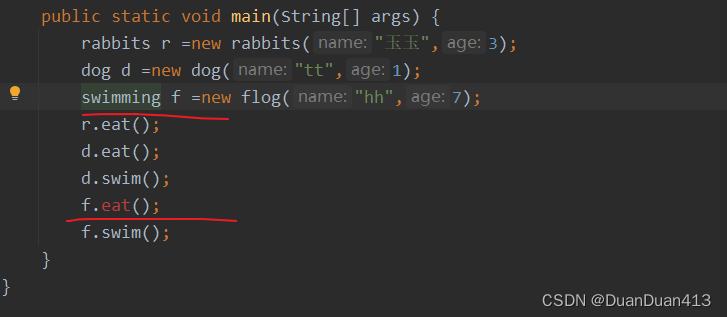
关于接口多态,何时使用接口名创建对象?何时使用子类创建对象?
接口创建对象只能创建他的实现类,所以会出现两种创建方式: 1、接口 对象名 new 类名 2、子类对象 对象名 new 类名 举个例子,swimming是一个接口,flog是他的一个实现类,重写了swimming的eat()方法 子类对象 对象名…...

短视频热恋进行时:成都柏煜文化传媒有限公司
短视频热恋进行时:情感与创意的碰撞与融合 在数字时代的浪潮中,短视频以其独特的魅力,成为了当代人表达情感、分享生活的新宠。它如同一个浓缩的时空胶囊,将那些瞬间的美好、感人的故事、创意的火花,封装在短短几十秒…...
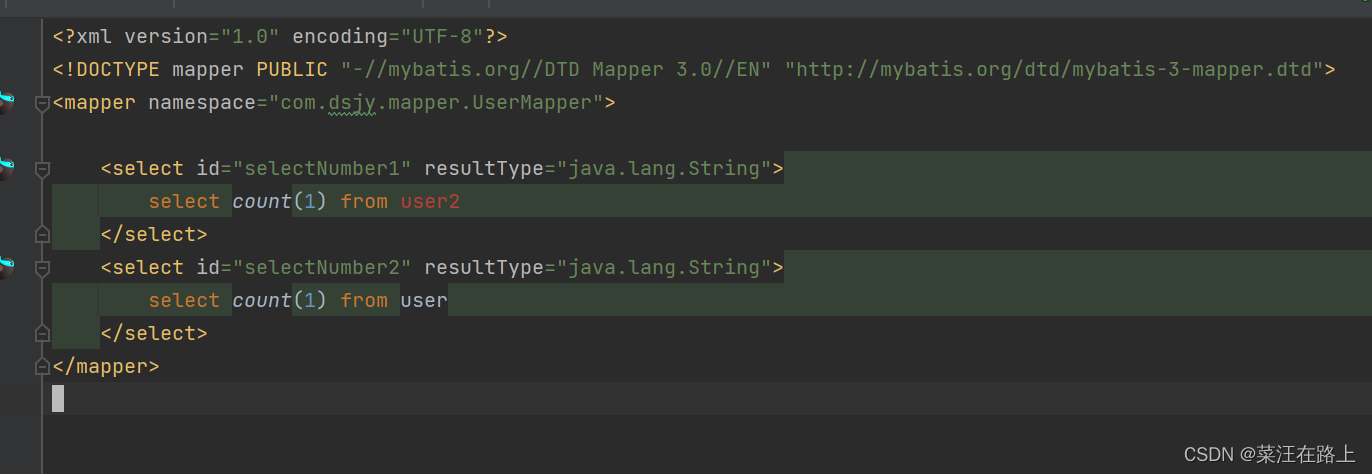
springBoot多数据源使用、配置
又参加了一个新的项目,虽然是去年做的项目,拿来复用改造,但是也学到了很多。这个项目会用到其他项目的数据,如果调用他们的接口取数据,我还是觉得太麻烦了。打算直接配置多数据源。 然后去另一个数据库系统中取出数据…...
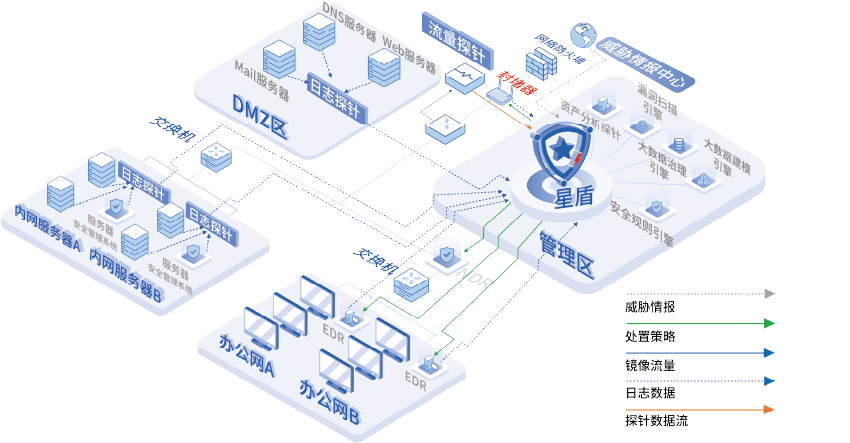
打破安全设备孤岛,多源威胁检测与响应(XDR)如何构建一体化安全防线
在数字化和信息化迅猛发展的当下,安全设备孤岛现象成为网络安全治理中的一大挑战。在多元化的市场环境中,不同厂商的安全设备因数据格式与系统兼容性的差异,导致信息流通受阻、共享困难,形成孤立的安全防线。 安全设备孤岛现象不仅…...
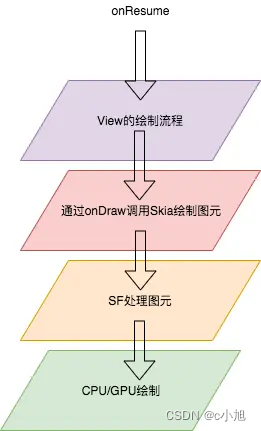
Android SurfaceFlinger——概述(一)
一、基础介绍 SurfaceFlinger 是 Android 系统中的一个关键组件,负责管理屏幕显示的合成和渲染。 服务角色:SurfaceFlinger 作为一个系统服务独立运行,它不依赖于任何应用程序进程,而是由系统启动并持续运行。窗口管理:…...
)
CloudCompare点云滤波保姆级教程:从低通到CSF,7种方法一次搞定(附避坑指南)
CloudCompare点云滤波实战指南:7大核心方法与避坑策略 点云数据处理是三维重建、地形测绘和工业检测等领域的关键环节。面对海量且带有噪声的原始点云,如何高效筛选有效信息成为每个从业者的必修课。CloudCompare作为开源点云处理利器,其丰富…...

终极艾尔登法环性能优化工具:帧率解锁与视野扩展完全指南
终极艾尔登法环性能优化工具:帧率解锁与视野扩展完全指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/…...

碧蓝航线Alas自动化脚本终极指南:7x24小时全自动游戏管理解决方案
碧蓝航线Alas自动化脚本终极指南:7x24小时全自动游戏管理解决方案 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript …...

为Nodejs后端服务接入Taotoken实现AI内容生成功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Nodejs后端服务接入Taotoken实现AI内容生成功能 在构建现代后端服务时,集成AI内容生成能力已成为提升产品智能化的常…...

Mac上编译C语言的简易方法
1、 null 2、 在 Mac OS X 系统中,可通过 Xcode 学习和编写 C 语言程序。 3、 在Xcode中运行C语言程序需先创建项目,然后在项目中添加源代码文件。 4、 启动 Xcode,点击创建新项目以新建一个工程,具体操作所示。 5、 选择需创建…...

Godot游戏资源解包指南:三步提取PCK文件中的隐藏素材
Godot游戏资源解包指南:三步提取PCK文件中的隐藏素材 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 你是否曾经遇到过这样的情况:下载了一个用Godot引擎开发的游戏ÿ…...

基于Mayan EDMS的文档管理系统部署与优化实践
1. 项目概述:一个面向文档管理的开源解决方案如果你在寻找一个能够替代Confluence、SharePoint,甚至是Google Drive的开源自托管方案,那么joyozhang333-lgtm/mayan-kin这个项目值得你花时间研究。它不是一个全新的轮子,而是基于一…...

自进化AI智能体:从核心架构到工程实践
1. 项目概述:从“自进化”到“智能体协作”的范式跃迁最近在GitHub上看到一个名为“RangeKing/self-evolving-agent”的项目,这个标题本身就充满了吸引力。作为一个长期关注AI Agent(智能体)领域发展的从业者,我深知“…...

2026 AI模型API聚合站真实测评:四大主流平台深度剖析,为企业选型提供精准指南
随着AI技术的大规模应用,AI模型API聚合站成为了企业快速接入先进智能能力、降低技术门槛的关键工具。目前市场上的服务商质量参差不齐,企业在选择时往往需要考虑稳定性、合规性和接入成本等多个因素。为了解决这一难题,本文对当前主流的四大A…...

2026年AI大模型API中转站深度测评:谁能成为生产环境下的最优解决方案?
2026年,AI模型的迭代速度进一步加快。从年初在技术社区引起轰动的OpenClaw架构,到GPT - 5.4、Claude 4.6等性能领先的通用模型,再到视频生成领域的Sora2与Veo3,模型之间的竞争愈发激烈。然而,国内开发者在调用这些模型…...