多模态大模型解读
目录
1. CLIP
2. ALBEF
3. BLIP
4. BLIP2
参考文献
(2023年)视觉+语言的多模态大模型的目前主流方法是:借助预训练好的LLM和图像编码器,用一个图文特征对齐模块来连接,从而让语言模型理解图像特征并进行深层次的问答推理。
这样可以利用已有的大量单模态训练数据训练得到的单模态模型,减少对于高质量图文对数据的依赖,并通过特征对齐、指令微调等方式打通两个模态的表征。下图来自其他 up 的概括内容,来自:https://zhuanlan.zhihu.com/p/653902791
对于CLIP部分公式均参照该链接,仅了解损失函数。

图 基础MLLM的架构整理
1. CLIP
分别对图像、文本进行特征提取,两部分的backbone可以分别采用Resnet系列模型/VIT系列模型、BERT模型。特征提取后,直接相乘计算余弦相似度,然后采用对比损失(info-nce-loss)。
训练损失
- 交叉熵代价损失(cross entropy):基础有监督学习分类损失函数。

图 n个类别多分类的交叉熵代价函数
- NCE(noise contrastive estimation):相比于交叉熵损失,这里将多问题转化为二分类问题,即正样本和噪声样本,目标学习正样本和噪声样本之间的差异。

图 噪声对比
- info-NCE:NCE的变体,将噪声样本按多类别看待。存在一个temp的温度系数。
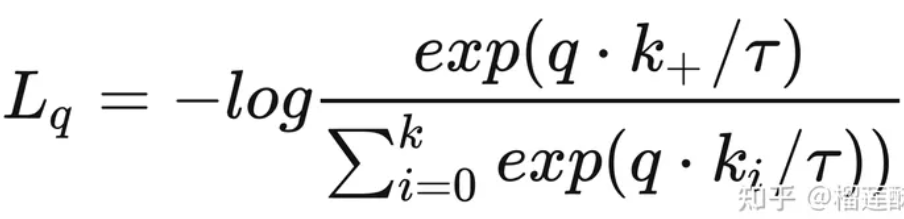
图 info-NCE loss
2. ALBEF
动机:该项工作之前的视觉预训练模型一般采用Object Detector的方式,这种Detector能够提取图像上的目标或边界信息。然而这种训练方式有如下几点限制:
- 图像特征和文本编码token分别处于各子的特征空间,这使得多模态关联性挖掘存在巨大挑战;
- 这种训练方式会产生额外的解释开销和计算开销;
- 对于物体目标含量低的样本,模型性能受限于Detector的检测精度;
- 图像文本样本数据一般来源于网络,具有严重的噪声影响,会导致模型性能降级。
ALBEF模型架构:如图所示,ALBEF模型架构分为image encoder 、text encoder 和多模态编码器,其中左半部分类似Transformer,text encoder将12层分为两部分,前6层作为text encoder,后6层作为视觉特征和文本特征的融合。由于视觉和文本的编码都包含[CLS]标签,这种标签因自注意力机制的影响被认为包含全局信息,所以可以将视觉和文本的全局信息进行 Image-Text Contrastive Loss。

图 ALBEF架构图
如图ITM部分,该部分称为图像文本匹配(Image-Text matching),该部分利用的负样本采用 hard negatives 的方式进行生成,即通过ITC(iamge-text Contrastive)计算出的次分类结果,该结果能够作为模型难以理解的样本,进而计算损失。
除此之外,由于动机中描述的网络图文样本对的噪声影响,ALBEF设计一个Momentum Model(动量模型)解决上述问题。简要描述该组件的作用,即类似知识蒸馏方法,拷贝出原始模型的动量版本,通过动量模型对原始模型规约,加深原始模型和动量模型间的图文对匹配程度,进而消除原始样本数据中的噪声干扰。
3. BLIP
动机:从模型的角度,当前预训练模型的任务涵盖范围受限。例如,基于Encoder的模型无法做生成任务,而基于Encoder-Decoder的模型无法做检索任务,不能更充分的理解任务信息。从数据的角度,网络图文对具有严重的数据噪声。
BLIP模型架构:BLIP全称Bootstrapped Language-Image Pre-training,该模型包括三个下游任务:图像文本对比学习、图像文本匹配和语言建模(LM,该任务类似GPT,给定段落前一段话,预测后一段;而不是BERT那种完型填空的方式)。

图 BLIT模型架构
- Bootstrapped机制:采用一种迭代的、自我改进的学习过程来提升模型性能,该机制有助于提高模型在跨模态任务中的对齐和理解能力。(1)初始模型训练阶段:首先使用大量的单模态数据(如图像/文本)对文本编码器和图像编码器进行预训练(如图中的 Image Encoder 和 Text Encoder)。然后利用多模态数据,即图文对数据,对初始模型进行训练;(2)迭代更新阶段:采用Captioning and Filtering的方式,从网页噪声图像文本对中学习,训练BLIP。
- image-text contrastive(图像文本对比):和ALBEF类似,利用[CLS]信息进行对比学习。
- Image-grounded Text Encoder(图像文本匹配编码器):采用一种 Cross Attention 模块,将图像信息融入文本编码过程中,增强文本的上下文表示,进而理解图像的相关描述。
- Image-grounded Text Decoder(图像关联文本解码器):将原来的 Bi Self-Attention 替换为 Causal Self-Attention(用于预测下一个token),该解码器用于文本生成或多模态推理任务。
- soft lables:是指标签值在[0,1]之间的概率值,而不是离散的0或1,反映样本属于某一个类的置信度。有助于平滑标签分布,提高模型的泛化能力,减少过拟合。
- Hard Negative Mining Strategy:在训练过程中,专门选择那些模型难以区分的负样本,以增强模型的判别能力。
如何消除网络样本噪声的影响:BLIP采用 Filter-Captioner 的方式,如图所示,通过生成+过滤的方式生成更匹配图像的Caption,进而完善样本集。具体而言,对于给定的训练集,包含网络文本
、人工正确标注文本
,由于前文有 ITC、ITM 和 LM 损失,因此在部分利用这些指标训练 Filter(grounded Encoder)和 Captioner(grounded Decoder),Captioner会生成文本数据
,将
和
交由 Filter 微调更加匹配图像的文本信息,最终获得信息匹配程度更紧密的样本集。

图 Filter-Captioner机制
4. BLIP2
动机:回顾之前的研究,无论是视觉预训练模型还是语言预训练模型,其规模都是庞大的,这种模型架构会产生巨额开销。
BLIP2架构:BLIP2全称Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models,视图将视觉预训练模型和语言预训练模型参数均进行冻结。然而,这会导致视觉特征和文本特征都处于各自的特征空间,存在巨大的 modality gap。因此BLIP2中采用 Q-Former(Query Transformer) 的一种轻量级Transformer技术,该技术用于弥补视觉和语言两种模态的 modality gap,选取最匹配的视觉特征给后续LLM生成文本。
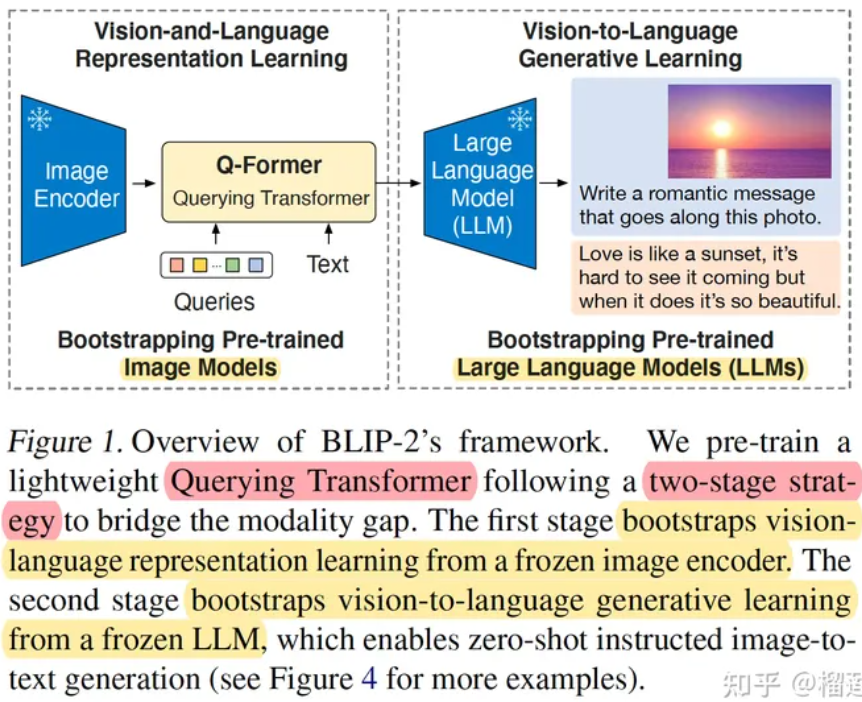
图 BLIP2的模型架构
Q-Former是一个可学习的组件,学习的参数包括若干queries,这些queries最终从 image encoder中提取固定数量的视觉特征,学习与文本更匹配的视觉特征。
queries间的彼此交互通过共享自注意力层,和冻结的图像特征交互使用的跨模态注意力机制层,然后queries也能通过共享自注意力层与文本特征进行交互。整个Q-Former由Image Transformer和Text Transformer两个子模块构成,它们共享相同自注意力层。
- Image Transformer:通过和image encoder交互来提取视觉特征,输入是一系列(文中用的32个*768长度)可学习的 Queries,这些Query通过自注意力层相互交互,并通过交叉注意力层与冻结的图像特征交互,还可以通过共享的自注意力层与文本进行交互;输出的query尺寸是32*768,远小于冻结的图像特征257*1024(ViT-L/14)。
- Text Transformer:既作为文本编码器也作为文本解码器,它的自注意力层与Image Transformer共享,根据预训练任务,用不同的self-attention masks来控制Query和文本的交互方式。
参考文献
多模态大模型 CLIP, BLIP, BLIP2, LLaVA, miniGPT4, InstructBLIP 系列解读
BLIP2的前世与今生
ALBEF原文
BLIP原文
BLIP2原文
相关文章:
多模态大模型解读
目录 1. CLIP 2. ALBEF 3. BLIP 4. BLIP2 参考文献 (2023年)视觉语言的多模态大模型的目前主流方法是:借助预训练好的LLM和图像编码器,用一个图文特征对齐模块来连接,从而让语言模型理解图像特征并进行深层次的问…...

React是什么?
theme: condensed-night-purple highlight: atelier-cave-light React是什么? 官方的解释是:A JavaScript library for building user interfaces用于构建用户界面的 JavaScript 库 那为什么要选择用React呢? 原生的HTML、CSS、JavaScrip的…...

创新入门 | 病毒循环Viral Loop是什么?为何能实现指数增长
今天,很多高速增长的成功创业公司都在采用”病毒循环“的策略去快速传播、并扩大用户基础。究竟什么是“病毒循环”?初创公司的创始人为何需要重视这个策略?这篇文章中将会一一解答与病毒循环有关的各种问题。 一、什么是病毒循环(…...

鸿蒙HarmonyOS实战:渲染控制、路由案例
条件渲染 简单来说,就是动态控制组件的显示与隐藏,类似于vue中的v-if 但是这里写法就是用if、else、else if看起来更像是原生的感觉 效果 循环渲染 我们实际开发中,数据一般是后端返回来的对象格式,对此我们需要进行遍历&#…...
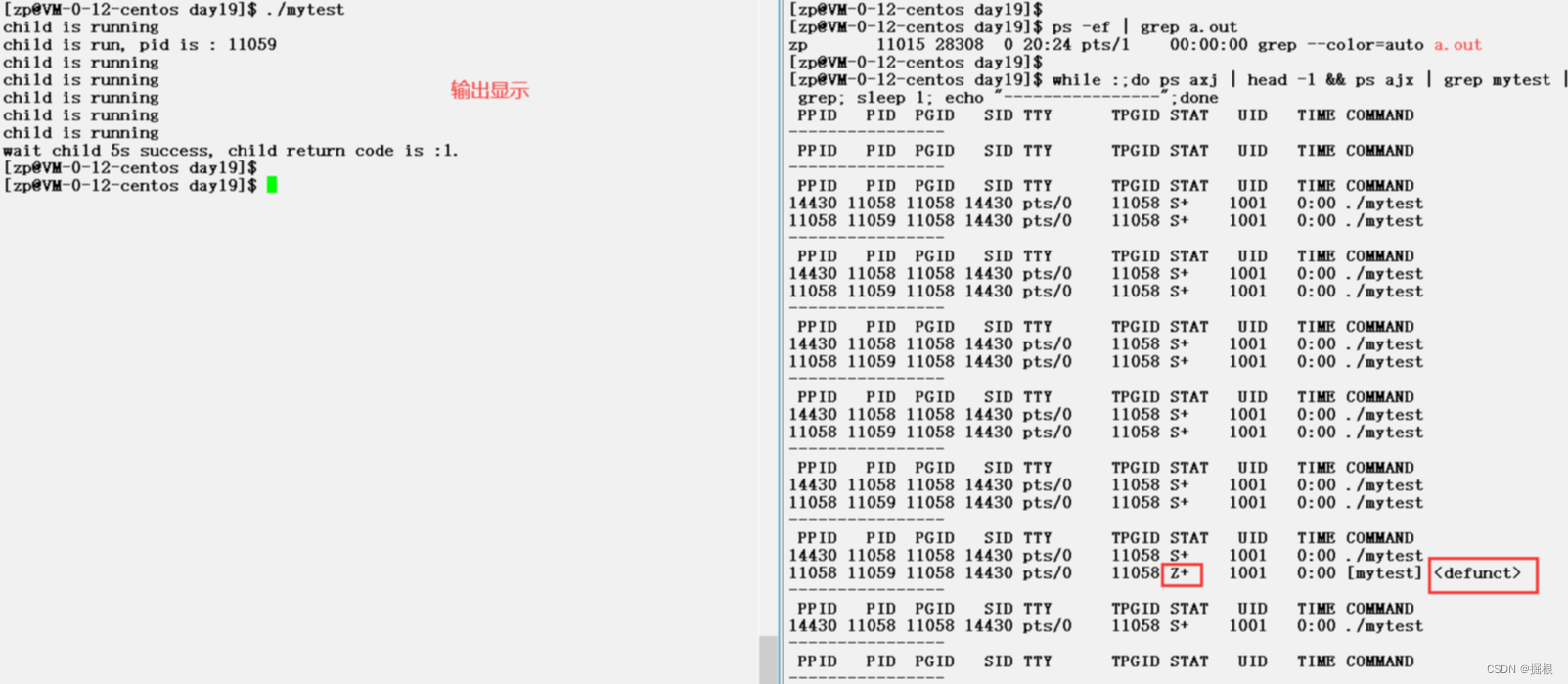
【Linux】进程控制2——进程等待(waitwaitpid)
1. 进程等待必要性 我们知道,子进程退出,父进程如果不管不顾,就可能造成"僵尸进程”的问题,进而造成内存泄漏。另外,进程一旦变成僵尸状态,那就刀枪不入,“杀人不眨眼”的kill -9 也无能为…...

SpringBoot 统计接口调用耗时的多种方式
在实际开发中,了解项目中接口的响应时间是必不可少的事情。SpringBoot 项目支持监听接口的功能也不止一个,接下来我们分别以 AOP、ApplicationListener、Tomcat 三个方面去实现三种不同的监听接口响应时间的操作。 AOP 首先我们在项目中创建一个类 &am…...
Linux系统安装Ruby语言
Ruby是一种面向对象的脚本语言,由日本的计算机科学家松本行弘设计并开发,Ruby的设计哲学强调程序员的幸福感,致力于简化编程的复杂性,并提供一种既强大又易于使用的工具。其语法简洁优雅,易于阅读和书写,使…...

网络安全练气篇——OWASP TOP 10
1、什么是OWASP? OWASP(开放式Web应用程序安全项目)是一个开放的社区,由非营利组织 OWASP基金会支持的项目。对所有致力于改进应用程序安全的人士开放,旨在提高对应用程序安全性的认识。 其最具权威的就是“10项最严重…...

python实现进度条的方法和实现代码
在Python中,有多种方式可以实现进度条。这里,我将介绍七种常见的方法:使用tqdm(这是一个外部库,非常流行且易于使用)、rich、click、progressbar2等库以及纯Python的print函数与time库来模拟进度条。 目录…...

被拷打已老实!面试官问我 #{} 和 ${} 的区别是什么?
引言:在使用 MyBatis 进行数据库操作时,#{} 和 ${} 的区别是面试中常见的问题,对理解如何在 MyBatis 中安全有效地处理 SQL 语句至关重要。正确使用这两种占位符不仅影响应用的安全性,还涉及到性能优化。 题目 被拷打已老实&…...

C# —— while循环语句
作用 让顺序执行的代码 可以停下来 循环执行某一代码块 // 条件分支语句: 让代码产生分支 进行执行 // 循环语句 : 让代码可以重复执行 语法 while循环 while (bool值) { 循环体(条件满足时执行的代码块) …...

力扣第205题“同构字符串”
在本篇文章中,我们将详细解读力扣第205题“同构字符串”。通过学习本篇文章,读者将掌握如何使用哈希表来解决这一问题,并了解相关的复杂度分析和模拟面试问答。每种方法都将配以详细的解释,以便于理解。 问题描述 力扣第205题“…...

探索RESTful API开发,构建可扩展的Web服务
介绍 当我们浏览网页、使用手机应用或与各种互联网服务交互时,我们经常听到一个术语:“RESTful API”。它听起来很高深,但实际上,它是构建现代网络应用程序所不可或缺的基础。 什么是RESTful API? 让我们将RESTful …...

苹果安卓网页的H5封装成App的应用和原生开发的应用有什么不一样?
H5封装类成App的应用和原生应用有什么不一样?——一对比谈优缺点 1. 开发速度和复用性 H5封装的App优势:一次编写,多平台运行。你只需要使用一种语言编写代码,就可以发布到不同的平台,降低开发成本。 原生应用优势&…...
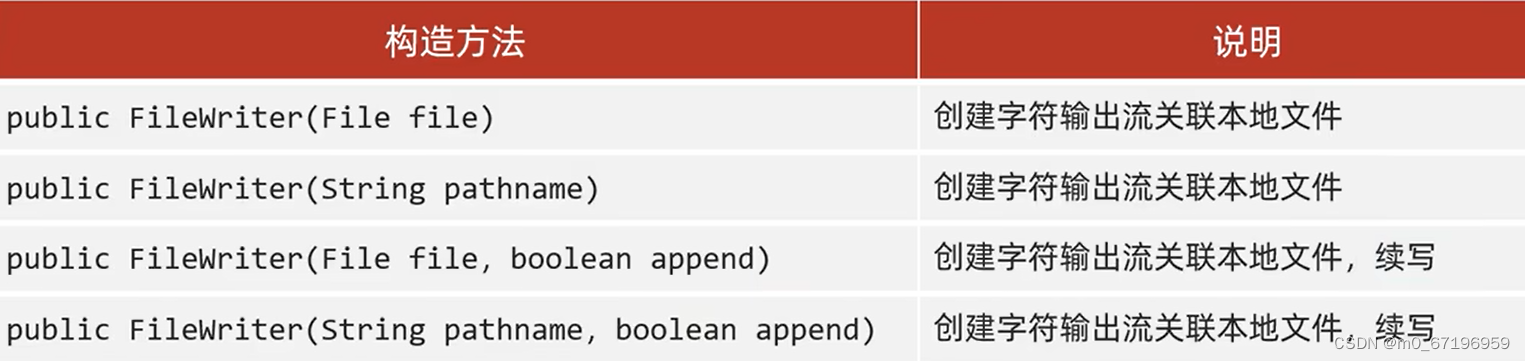
IO流2.
字符流-->字符流的底层其实就是字节流 public class Stream {public static void main(String[] args) throws IOException {//1.创建对象并关联本地文件FileReader frnew FileReader("abc\\a.txt");//2.读取资源read()int ch;while((chfr.read())!-1){System.out…...

详解MySQL中的PERCENT_RANK函数
目录 1. 引入1. 基本使用2:分组使用3:处理重复值4. 使用优势4.1 手动计算百分等级4.2 使用 PERCENT_RANK 的优势4.3 使用 PERCENT_RANK 5. 总结 在 MySQL 中,PERCENT_RANK 函数用于计算一个值在其分组中的百分等级。 它的返回值范围是从 0 …...

宏任务与微任务
一、宏任务 1、概念 指消息队列中等地被主线程执行的事件 2、种类 script主代码块、setTimeout 、setInterval 、nodejs的setImmediate 、MessageChannel(react的fiber用到)、postMessage、网络I/O、文件I/O、用户交互的回调等事件、UI渲染事件&#x…...
昇思大模型学习·第一天
mindspore快速入门回顾 导入mindspore包 处理数据集 下载mnist数据集进行数据集预处理 MnistDataset()方法train_dataset.get_col_names() 打印列名信息使用create_tuple_iterator 或create_dict_iterator对数据集进行迭代访问 网络构建 mindspore.nn: 构建所有网络的基类用…...

python调用chatgpt
简单写了一下关于文本生成接口的调用,其余更多的调用方法可在官网查看 import os from dotenv import load_dotenv, find_dotenv from openai import OpenAI import httpxdef gpt_config():# 为了安全起见,将key写到当前项目根目录下的.env文件中# find…...
YOLOV8 目标检测:训练自定义数据集
1、下载 yolov8项目:ultralytics/ultralytics:新增 - PyTorch 中的 YOLOv8 🚀 > ONNX > OpenVINO > CoreML > TFLite --- ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreM…...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...

HFSS仿真结果怎么看?以T型波导为例,读懂S参数与电场动态图
HFSS仿真结果深度解析:从S参数到电场动态图的实战指南当你第一次在HFSS中完成T型波导仿真后,面对满屏的曲线和彩色云图,是否感到既兴奋又困惑?那些起伏的S参数曲线究竟告诉你什么信息?电场图中跳跃的颜色又代表怎样的物…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷?
更多请点击: https://intelliparadigm.com 第一章:上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷? 在软件交付生命周期末期,传统人工代码审计与通用SAST工具常因误报率高、上下文理解弱而漏检高危漏…...

Jupyter Notebook里跑argparse脚本总报错?一个空列表参数搞定ipykernel_launcher.py error
Jupyter Notebook中argparse报错的终极解决方案:空列表参数实战解析在数据科学和机器学习的工作流中,Jupyter Notebook因其交互式特性成为众多研究者的首选工具。然而,当我们尝试在Notebook中运行那些原本为命令行设计的Python脚本时…...

NHSE终极教程:5分钟掌握动物森友会存档编辑技巧
NHSE终极教程:5分钟掌握动物森友会存档编辑技巧 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》的收集烦恼吗?想快速打造梦想岛屿却…...
)
大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性)
更多请点击: https://codechina.net 第一章:大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性) 传统LLM测试常聚焦于准确率或BLEU等静态指标,而Cla…...