详解MySQL中的PERCENT_RANK函数
目录
- 1. 引入
- 1. 基本使用
- 2:分组使用
- 3:处理重复值
- 4. 使用优势
- 4.1 手动计算百分等级
- 4.2 使用 `PERCENT_RANK` 的优势
- 4.3 使用 `PERCENT_RANK`
- 5. 总结
在 MySQL 中,PERCENT_RANK 函数用于计算一个值在其分组中的百分等级。
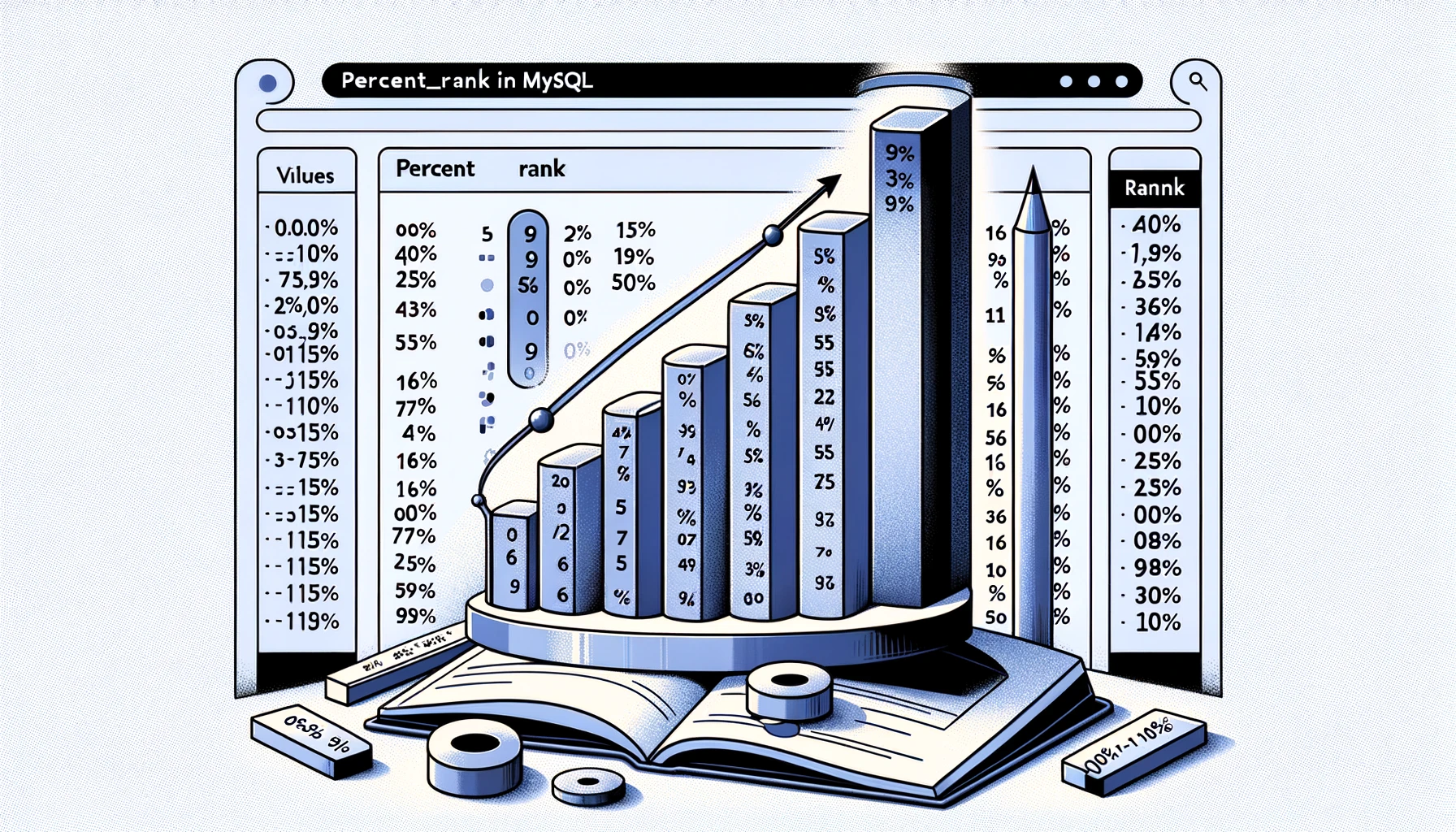
它的返回值范围是从 0 到 1,表示一个值在排序后的数据集中相对于其他值的位置。百分等级的计算公式为:
P E R C E N T _ R A N K = rank − 1 total_rows − 1 {PERCENT\_RANK} = \frac{\text{rank} - 1}{\text{total\_rows} - 1} PERCENT_RANK=total_rows−1rank−1
其中,rank 是当前行的排序位置,total_rows 是总行数。
1. 引入
下面通过一个具体例子来说明 PERCENT_RANK 的用法。
假设我们有一个包含学生分数的表 students_scores,表结构如下:
CREATE TABLE students_scores (student_id INT,student_name VARCHAR(50),score DECIMAL(5, 2)
);
我们向表中插入一些数据:
INSERT INTO students_scores (student_id, student_name, score) VALUES
(1, 'Alice', 85.0),
(2, 'Bob', 90.5),
(3, 'Charlie', 78.0),
(4, 'David', 92.0),
(5, 'Eve', 88.0);
现在,我们希望计算每个学生分数的百分等级。可以使用以下 SQL 查询:
SELECTstudent_id,student_name,score,PERCENT_RANK() OVER (ORDER BY score DESC) AS percent_rank
FROMstudents_scores;
执行上述查询后,将得到以下结果:
| student_id | student_name | score | percent_rank |
|---|---|---|---|
| 4 | David | 92.0 | 0.0000 |
| 2 | Bob | 90.5 | 0.2500 |
| 5 | Eve | 88.0 | 0.5000 |
| 1 | Alice | 85.0 | 0.7500 |
| 3 | Charlie | 78.0 | 1.0000 |
在这个结果集中,percent_rank 列表示每个学生的分数在所有学生中的相对位置。例如,David 的分数是最高的,因此他的 percent_rank 是 0。Charlie 的分数是最低的,因此他的 percent_rank 是 1。其他学生的 percent_rank 介于 0 和 1 之间,反映了他们的分数在整个分数分布中的相对位置。

通过这个例子,我们可以看到 PERCENT_RANK 函数如何计算并返回数据集中的每个值的百分等级。
1. 基本使用
假设我们有一个表 employees,包含员工的销售数据:
CREATE TABLE employees (employee_id INT,employee_name VARCHAR(50),sales DECIMAL(10, 2)
);INSERT INTO employees (employee_id, employee_name, sales) VALUES
(1, 'John', 1500.00),
(2, 'Jane', 2000.00),
(3, 'Alice', 2500.00),
(4, 'Bob', 3000.00),
(5, 'Eve', 1000.00);
我们希望计算每个员工销售额的百分等级。可以使用以下查询:
SELECTemployee_id,employee_name,sales,PERCENT_RANK() OVER (ORDER BY sales DESC) AS percent_rank
FROMemployees;
查询结果如下:
| employee_id | employee_name | sales | percent_rank |
|---|---|---|---|
| 4 | Bob | 3000.00 | 0.0000 |
| 3 | Alice | 2500.00 | 0.2500 |
| 2 | Jane | 2000.00 | 0.5000 |
| 1 | John | 1500.00 | 0.7500 |
| 5 | Eve | 1000.00 | 1.0000 |
2:分组使用
假设我们有一个包含员工销售数据的表 department_sales,每个员工属于不同的部门:
CREATE TABLE department_sales (employee_id INT,employee_name VARCHAR(50),department VARCHAR(50),sales DECIMAL(10, 2)
);INSERT INTO department_sales (employee_id, employee_name, department, sales) VALUES
(1, 'John', 'Electronics', 1500.00),
(2, 'Jane', 'Electronics', 2000.00),
(3, 'Alice', 'Furniture', 2500.00),
(4, 'Bob', 'Furniture', 3000.00),
(5, 'Eve', 'Electronics', 1000.00),
(6, 'Charlie', 'Furniture', 2800.00);

我们希望计算每个部门中员工销售额的百分等级。可以使用以下查询:
SELECTemployee_id,employee_name,department,sales,PERCENT_RANK() OVER (PARTITION BY department ORDER BY sales DESC) AS percent_rank
FROMdepartment_sales;
查询结果如下:
| employee_id | employee_name | department | sales | percent_rank |
|---|---|---|---|---|
| 2 | Jane | Electronics | 2000.00 | 0.0000 |
| 1 | John | Electronics | 1500.00 | 0.5000 |
| 5 | Eve | Electronics | 1000.00 | 1.0000 |
| 4 | Bob | Furniture | 3000.00 | 0.0000 |
| 6 | Charlie | Furniture | 2800.00 | 0.5000 |
| 3 | Alice | Furniture | 2500.00 | 1.0000 |
3:处理重复值
假设我们有一个包含学生成绩的表 student_grades,其中有些成绩是重复的:
CREATE TABLE student_grades (student_id INT,student_name VARCHAR(50),grade DECIMAL(5, 2)
);INSERT INTO student_grades (student_id, student_name, grade) VALUES
(1, 'Tom', 85.00),
(2, 'Jerry', 90.00),
(3, 'Anna', 85.00),
(4, 'Mike', 95.00),
(5, 'Sue', 90.00);
我们希望计算每个学生成绩的百分等级。可以使用以下查询:
SELECTstudent_id,student_name,grade,PERCENT_RANK() OVER (ORDER BY grade DESC) AS percent_rank
FROMstudent_grades;
查询结果如下:
| student_id | student_name | grade | percent_rank |
|---|---|---|---|
| 4 | Mike | 95.00 | 0.0000 |
| 2 | Jerry | 90.00 | 0.2500 |
| 5 | Sue | 90.00 | 0.2500 |
| 1 | Tom | 85.00 | 0.7500 |
| 3 | Anna | 85.00 | 0.7500 |
通过以上例子可以看到,PERCENT_RANK 函数在处理不同数据集和需求时都非常灵活和有用。它可以帮助我们更好地理解和分析数据中的分布和排名情况。
4. 使用优势
如果不使用 PERCENT_RANK 函数,我们可以通过子查询和一些数学计算来手动计算百分等级。这种方法相对繁琐,需要多次嵌套查询和排序。下面是一个手动计算百分等级的例子,使用与之前例子相同的 students_scores 表。
4.1 手动计算百分等级
假设我们有以下表数据:
CREATE TABLE students_scores (student_id INT,student_name VARCHAR(50),score DECIMAL(5, 2)
);INSERT INTO students_scores (student_id, student_name, score) VALUES
(1, 'Alice', 85.0),
(2, 'Bob', 90.5),
(3, 'Charlie', 78.0),
(4, 'David', 92.0),
(5, 'Eve', 88.0);
手动计算每个学生分数的百分等级可以通过以下查询实现:
SELECTstudent_id,student_name,score,(SELECT COUNT(*) FROM students_scores AS sub WHERE sub.score < main.score) / (SELECT COUNT(*) - 1 FROM students_scores) AS percent_rank
FROMstudents_scores AS main
ORDER BYscore DESC;
上述查询的结果与使用 PERCENT_RANK 函数的结果是相同的。
4.2 使用 PERCENT_RANK 的优势
-
简洁性和易读性:使用
PERCENT_RANK函数可以简化查询的编写,使得代码更为简洁和易读。手动计算百分等级需要嵌套查询和计算,增加了复杂性。 -
性能优化:数据库引擎通常会对窗口函数进行优化,使其执行效率更高。手动计算可能无法充分利用这些优化,从而导致查询性能较低。
-
维护性:使用内置函数减少了自定义计算逻辑,当需求发生变化时,代码的维护和修改也更加方便。
-
减少错误:手动计算时容易出错,例如在计算总行数、排序以及分组等过程中,使用
PERCENT_RANK函数可以减少这些人为错误。
4.3 使用 PERCENT_RANK
我们再来回顾一下如何使用 PERCENT_RANK 函数:
SELECTstudent_id,student_name,score,PERCENT_RANK() OVER (ORDER BY score DESC) AS percent_rank
FROMstudents_scores;
这个查询简单明了,直接利用 PERCENT_RANK 函数计算百分等级,避免了复杂的嵌套查询和计算逻辑。
5. 总结
使用 PERCENT_RANK 函数在简化查询编写、提高性能和减少错误方面具有明显的优势。因此,在可以使用窗口函数的场景下,推荐优先使用 PERCENT_RANK 而不是手动计算百分等级。
相关文章:
详解MySQL中的PERCENT_RANK函数
目录 1. 引入1. 基本使用2:分组使用3:处理重复值4. 使用优势4.1 手动计算百分等级4.2 使用 PERCENT_RANK 的优势4.3 使用 PERCENT_RANK 5. 总结 在 MySQL 中,PERCENT_RANK 函数用于计算一个值在其分组中的百分等级。 它的返回值范围是从 0 …...

宏任务与微任务
一、宏任务 1、概念 指消息队列中等地被主线程执行的事件 2、种类 script主代码块、setTimeout 、setInterval 、nodejs的setImmediate 、MessageChannel(react的fiber用到)、postMessage、网络I/O、文件I/O、用户交互的回调等事件、UI渲染事件&#x…...
昇思大模型学习·第一天
mindspore快速入门回顾 导入mindspore包 处理数据集 下载mnist数据集进行数据集预处理 MnistDataset()方法train_dataset.get_col_names() 打印列名信息使用create_tuple_iterator 或create_dict_iterator对数据集进行迭代访问 网络构建 mindspore.nn: 构建所有网络的基类用…...

python调用chatgpt
简单写了一下关于文本生成接口的调用,其余更多的调用方法可在官网查看 import os from dotenv import load_dotenv, find_dotenv from openai import OpenAI import httpxdef gpt_config():# 为了安全起见,将key写到当前项目根目录下的.env文件中# find…...
YOLOV8 目标检测:训练自定义数据集
1、下载 yolov8项目:ultralytics/ultralytics:新增 - PyTorch 中的 YOLOv8 🚀 > ONNX > OpenVINO > CoreML > TFLite --- ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreM…...

动态更新自建的Redis连接池连接数量
/*** 定时更新Redis连接池信息,防止资源让费*/private static final ScheduledThreadPoolExecutor DYNAMICALLY_UPDATE_REDIS_POOL_THREAD new ScheduledThreadPoolExecutor(1, new ThreadFactory() {Overridepublic Thread newThread(Runnable r) {Thread thread …...

浅谈设计师的设计地位
在当今这个创意无限的时代,设计师的地位日益凸显。他们以独特的视角和精湛的技能,为我们的生活带来了无尽的色彩与灵感。然而,随着行业的不断发展,设计师如何在众多同行中脱颖而出,提升自己的设计地位呢?答…...
C/C++ string模拟实现
1.模拟准备 1.1因为是模拟string,防止与库发生冲突,所以需要命名空间namespace隔离一下,我们来看一下基本内容 namespace yx {class string{private://char _buff[16]; lunix下小于16字节就存buff里char* _str;size_t _size;size_t _capac…...
:behaviors代码复用)
微信小程序学习(八):behaviors代码复用
小程序的 behaviors 方法是一种代码复用的方式,可以将一些通用的逻辑和方法提取出来,然后在多个组件中复用,从而减少代码冗余,提高代码的可维护性。 如果需要 behavior 复用代码,需要使用 Behavior() 方法,…...
】)
【The design pattern of Attribute-Based Dynamic Routing Pattern (ADRP)】
In ASP.NET Core, routing is one of the core functionalities that maps HTTP requests to the corresponding controller actions. While “Route-Driven Design Pattern” is a coined name for a design pattern, we can construct a routing-centric design pattern base…...

2713. 矩阵中严格递增的单元格数
题目 给定一个 m x n 的整数矩阵 mat,我们需要找出从某个单元格出发可以访问的最大单元格数量。移动规则是可以从当前单元格移动到同一行或同一列的任何其他单元格,但目标单元格的值必须严格大于当前单元格的值。需要返回最大可访问的单元格数量。 示例…...

git创建子模块
有种情况我们经常会遇到:某个工作中的项目需要包含并使用另一个项目。 也许是第三方库,或者你独立开发的,用于多个父项目的库。 现在问题来了:你想要把它们当做两个独立的项目,同时又想在一个项目中使用另一个。 Git …...
把Deepin塞进U盘,即插即用!Deepin To Go来袭
前言 小伙伴之前在某篇文章下留言说:把Deepin塞进U盘的教程。 这不就来了吗? 事实是可以的。这时候你要先做点小准备: 一个大小为8GB或以上的普通U盘 一个至少64GB或以上的高速U盘 一个Deepin系统镜像文件 普通U盘的大概介绍࿱…...

给【AI硬件】创业者的论文、开源项目和产品整理
一、AI 硬件精选论文 《DrEureka: Language Model Guided Sim-To-Real Transfer》 瑜伽球上遛「狗」这项研究由宾夕法尼亚大学、 NVIDIA 、得克萨斯大学奥斯汀分校的研究者联合打造,并且完全开源。他们提出了 DrEureka(域随机化 Eureka)&am…...

模拟面试题卷二
1. 什么是JavaEE框架,你能列举一些常用的JavaEE框架吗? 答:JavaEE框架是一套用于开发企业级应用的技术规范和工具集合。常用的JavaEE框架有Spring、Hibernate、Struts、JSF等。 2. 请解释一下面向对象技术和设计原则是什么,你能…...
22种常用设计模式示例代码
文章目录 创建型模式结构型模式行为模式 仓库地址https://github.com/Xiamu-ssr/DesignPatternsPractice 参考教程 refactoringguru设计模式-目录 创建型模式 软件包复杂度流行度工厂方法factorymethod❄️⭐️⭐️⭐️抽象工厂abstractfactory❄️❄️⭐️⭐️⭐️生成器bui…...

Java面试题:对比ArrayList和LinkedList的内部实现,以及它们在不同场景下的适用性
ArrayList和LinkedList是Java中常用的两个List实现,它们在内部实现和适用场景上有很大差异。下面是详细的对比分析: 内部实现 ArrayList 数据结构:内部使用动态数组(即一个可变长的数组)实现。存储方式:…...
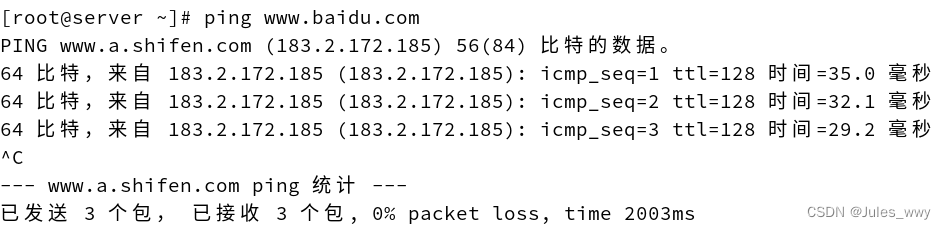
ping: www.baidu.com: 未知的名称或服务(IP号不匹配)
我用的是VMware上的Red Hat Enterprise Linux 9,出现了能联网但ping不通外网的情况。 问题描述:设置中显示正常连接,而且虚拟机右上角有联网的图标,但不能通外网。 按照网上教程修改了/etc/resolv.conf和/etc/sysconfig/network-…...

谷神前端组件增强:子列表
谷神Ag-Grid导出Excel // 谷神Ag-Grid导出Excel let allDiscolumns detailTable.getAllDisColumns() let columnColIds columns.map(column > column.colId) let columnKeys columnColIds.filter(item > ![select, "_OPT_FIELD_"].includes(item)) detailT…...

测试cudaStream队列的深度
测试cudaStream队列的深度 一.代码二.编译运行[得出队列深度为512] 以下代码片段用于测试cudaStream队列的深度 方法: 主线程一直发任务,启一个线程cudaEventQuery查询已完成的任务,二个计数器的值相减 一.代码 #include <iostream> #include <thread> #include …...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

rk35xx 通过recovery升级问题
Firefly 的 recovery 库是一个核心组件,它构建了一个独立的微型 Linux 系统,专门用于在设备主系统之外执行高可靠性的固件升级。简单来说,它的工作流程是:主系统通过命令触发,将升级指令写入特定分区并重启;…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...