【数据结构】选择题
-
在数据结构中,从逻辑上可以把数据结构分为(线性结构和非线性结构)
-
当输入规模为n时,下列算法渐进复杂性中最低的是()

-
时间复杂度
-
某线性表采用顺序存储结构,每个元素占4个存储单元,首地址为100,则第12个元素的存储地址为(144)
-
在单链表中,若p所指的结点不是最后结点,在p之后插入s所指结点,则执行()
- s->next=p->next; p->next=s;
- 设h为不带头结点的单向链表。在h的头上插入一个新结点t的语句是()
- t->next=h; h=t;
-
链表的适用场合:线性表在(线性表需经常插入或删除数据元素)情况下适合采用链式存储结构
-
设一个堆栈的入栈顺序是1、2、3、4、5。若第一个出栈的元素是4,则最后一个出栈的元素必定是(1或者5)
-
若元素a、b、c、d、e、f依次进栈,允许进栈、退栈操作交替进行,但不允许连续三次进行退栈工作,则不可能得到的出栈序列是(a f e d c b)
-
若已知一队列用单向链表表示,该单向链表的当前状态(含3个对象)是:1->2->3,其中x->y表示x的下一节点是y。此时,如果将对象4入队,然后队列头的对象出队,则单向链表的状态是(2->3->4)
-
在一个不带头结点的非空链式队列中,假设f和r分别为队头和队尾指针,则删除结点的运算是( f=f->next;)
-
已知二叉树的前序遍历序列为 ABDCEFG,中序遍历序列为 DBCAFEG,则后序遍历序列为(DCBFGEA)
-
完全二叉树的第4层有1个节点,该完全二叉树总计有(8)个节点
-
深度为k的完全二叉树的第k层至少有(1)个结点
-
具有65个结点的完全二叉树其深度为(根的深度为1):7
-
一个高度为h的满二叉树共有n个结点,其中有m个叶子结点,则有( n = 2m - 1 )成立
-
一棵完全二叉树上有62个结点,其中叶子结点的个数是(31)
-
根据使用频率为5个字符设计的哈夫曼编码不可能是(100,11,10,1,0 )
-
在哈夫曼树中,任何一个结点它的度都是(0或2)
-
设给定权值总数有n 个,其哈夫曼树的结点总数为( 2n-1)
-
对 n 个互不相同的符号进行哈夫曼编码。若生成的哈夫曼树共有 115 个结点,则 n 的值是(58)
-
一段文本中包含对象{a,b,c,d,e},其出现次数相应为{3,2,4,2,1},则经过哈夫曼编码后,该文本所占总位数为(27)
-
无向连通图的最小生成树( 有一个或多个)
-
用邻接表表示图进行广度优先遍历时,通常借助(队列 )来实现算法
-
在存储数据时,通常不仅要存储各数据元素的值,而且还要存储(数据元素之间的关系)
-
算法分析的两个主要方面是(空间复杂度和时间复杂度)
-
用数组表示线性表的优点是(便于随机存取)
-
带头结点的单链表h为空的判定条件是(h->next == NULL;)
-
假设有5个整数以1、2、3、4、5的顺序被压入堆栈,且出栈顺序为3、5、4、2、1,那么为了获得这样的输出,堆栈大小至少为(4)
-
设一个栈的输入序列是1、2、3、4、5,则下列序列中,是栈的合法输出序列的是(A)

-
为解决计算机主机与打印机之间速度不匹配问题,通常设置一个打印数据缓冲区,主机将要输出的数据依次写入该缓冲区,而打印机则依次从该缓冲区中取出数据。该缓冲区的逻辑结构应该是(队列)
-
二叉树中第5层(根的层号为1)上的结点个数最多为(16)
-
完全二叉树的第5层有3个节点,该完全二叉树总计有多少个节点(18)
-
深度为k的完全二叉树至少有(1)个结点,至多有(2)个结点

-
在一棵完全二叉树中,其根的序号为1,( )可判定序号为 p和q 的两个结点是否在同一层

-
如果一个完全二叉树最底下一层为第六层(根为第一层)且该层共有8个叶结点,那么该完全二叉树共有(39)个结点
-
设有13个值,用它们构成一棵哈夫曼树,则该哈夫曼树共有结点数是(25)
-
设哈夫曼树中有199个结点,则该哈夫曼树中有(100)个叶子结点
-
观察下面的数据结构

-
数据结构可以从逻辑上分成 ▁▁▁▁▁ 两大类

-
以下关于数据结构的说法中错误的是( )。

-
计算机所处理的数据一般具有某种关系,这是指(数据元素与数据元素之间存在的某种关系)
-
在计算机的存储器中表示时,逻辑上相邻的两个元素对应的物理地址也是相邻的,这种存储结构称之为(顺序存储结构)
-
数据元素在计算机存储器内表示时,物理相对位置和逻辑相对位置相同并且是连续的,称之为(顺序存储结构)
-
在数据结构中,与所使用的计算机无关的是数据的(逻辑)结构
-
通常要求同一逻辑结构中的所有数据元素具有相同的特性,这意味着(不仅数据元素所包含的数据项的个数要相同,而且对应的数据项的类型要一致)
-
以下属于顺序存储结构优点的是(A)

-
被计算机加工的数据元素不是孤立的,它们彼此之间一般存在某种关系,通常把数据元素之间的这种关系称为(B)

-
与数据元素本身的形式、内容、相对位置、个数无关的是数据的(C)

-
数据在计算机内存中的表示是指(A)

-
算法的时间复杂度取决于(C)

-
下面程序的时间复杂度为(A)

-
执行下面程序段时,执行S语句的频度为(D)

-
算法的时间复杂度取决于( D)

-
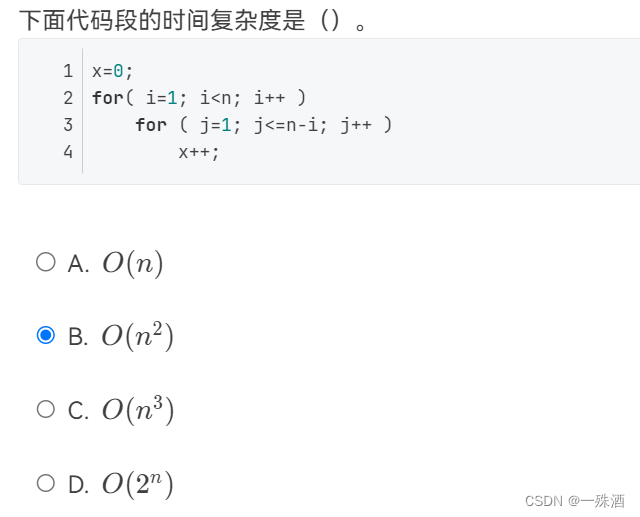
下面代码段的时间复杂度是()




56. 计算算法的时间复杂度属于( )

-
对于顺序存储的长度为N的线性表,访问结点和增加结点的时间复杂度为()

-
在N个结点的顺序表中,算法的时间复杂度为O(1)的操作是()

-
若某线性表最常用的操作是存取任一指定序号的元素和在最后进行插入和删除运算,则利用(顺序表)存储方式最节省时间
-
数组A[1…5,1…6]每个元素占5个单元,将其按行优先次序存储在起始地址为1000的连续的内存单元中,则元素A[5,5]的地址为(1140)
-
在图的广度优先遍历算法中用到一个队列,每个顶点最多进队(1)次
-
图的广度优先遍历类似于二叉树的(层次遍历)
-
图的深度优先遍历递归算法,要用一种称为(栈)的数据结构
-
如果从无向图的任一顶点出发进行一次深度优先搜索可访问所有顶点,则该图一定是(连通图)
-
图的深度优先遍历类似于二叉树的(先序遍历)
-
设一棵非空完全二叉树 T 的所有叶节点均位于同一层,且每个非叶结点都有 2 个子结点。若 T 有 k 个叶结点,则 T 的结点总数是(2k-1)
-
设高为h的二叉树(规定叶子结点的高度为1)只有度为0和2的结点,则此类二叉树的最少结点数和最多结点数分别为(2h−1, 2^h −1)
-
栈和队列的共同点是(只允许在端点处插入和删除元素)
-
循环队列的引入,目的是为了克服(假溢出问题 )
-
用链接方式存储的队列,在进行删除运算时(头、尾指针可能都要修改)
相关文章:
【数据结构】选择题
在数据结构中,从逻辑上可以把数据结构分为(线性结构和非线性结构) 当输入规模为n时,下列算法渐进复杂性中最低的是() 时间复杂度 某线性表采用顺序存储结构,每个元素占4个存储单元…...

数据库 |试卷八试卷九试卷十
1.基数是指元组的个数 2.游标机制 3.触发器自动调用 4.count(*)统计所有行,不忽略空值null,但不但要全局扫描,也要对表的每个字段进行扫描; 5.eacherNO INT NOT NULL UNIQUE,为什么不能断定TeacherNO是主码ÿ…...

【华为HCIA数通网络工程师真题-构建互联互通的IP网络】
文章目录 一、选择题 一、选择题 1、缺省情况下,广播网络上OSPF协议RouterDeadInterval是? 40s (ospf 的 RouterDeadInterval 为四倍 hello time 时间,hello time 周期默认为10s,所以 RouterDeadInterval 默认为 40s …...
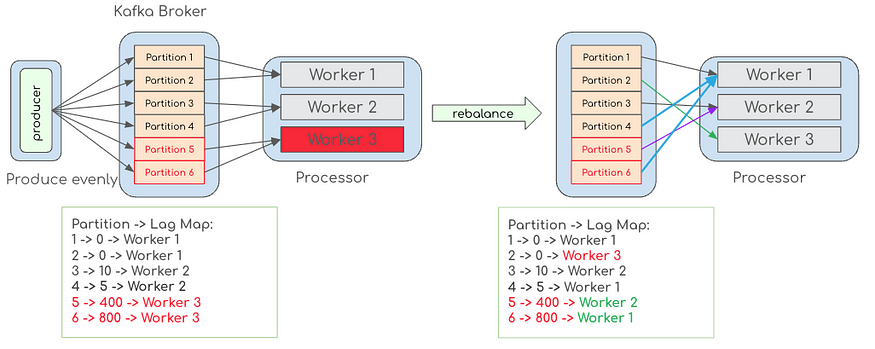
Kafka 负载均衡挑战及解决思路
本文转载自 Agoda Engineering,介绍了在实际应用中,如何应对 Kafka 负载均衡所遇到的各种挑战,并提出相应的解决思路。本文简要阐述了 Kafka 的并行性机制、常用的分区策略以及在实际操作中遇到的异构硬件、不均匀工作负载等问题。通过深入分…...
【Java面试】二十一、JVM篇(中):垃圾回收相关
文章目录 1、类加载器1.1 什么是类加载器1.2 什么是双亲委派机制 2、类装载的执行过程(类的生命周期)3、对象什么时候可以被垃圾回收器处理4、JVM垃圾回收算法4.1 标记清除算法4.2 标记整理算法4.3 复制算法 5、分代收集算法5.1 MinorGC、Mixed GC、Full…...
深入理解预处理
1.预定义符号 C语言设置了⼀些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的。 __FILE__ //进⾏编译的源⽂件 __LINE__ //⽂件当前的⾏号 __DATE__ //⽂件被编译的⽇期 __TIME__ //⽂件被编译的时间 __STDC__ //如果编译器遵循ANSI C&…...

DSP28335:定时器
1.定时器介绍 1.1 定时器工作原理 TMS320F28335的CPU Time有三个,分别为Timer0,Timer1,Timer2,其中Timer2是为操作系统DSP/BIOS保留的,当未移植操作系统时,可用来做普通的定时器。这三个定时器的中断信号分…...

系统架构理解
一、统一提前查好所有数据后续逻辑用到啥取啥,还是等用到对应数据的时候再查 1、用到啥查啥: 优势:减少依赖调用次数,减轻服务器压力;代码逻辑清晰,没有太多分支判断 劣势:无法避免串行调用&am…...

uni-app页面的跳转三种方式,功能作用有什么区别?
一、三种方式的作用 1、uni.reLaunch 作用是关闭所有页面,然后打开新的页面 类似于重新启动应用,打开的页面栈会被清空,只显示新打开的页面。使用uni.reLaunch方法可以实现整个应用的重定向 uni.reLaunch({url: /pages/login/login }) 2、…...
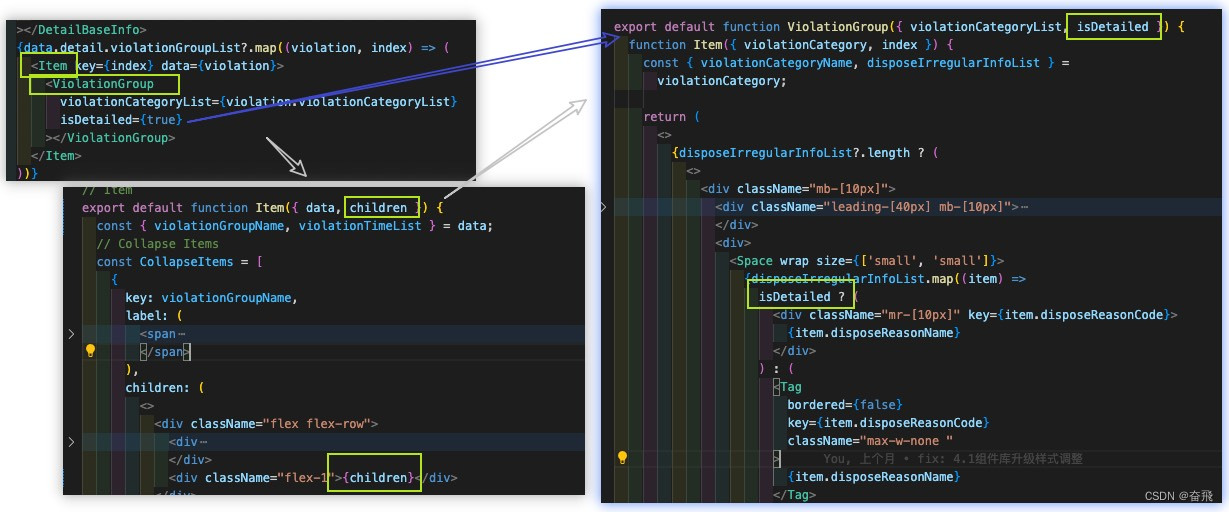
React 通信:深层传递(Props、Context、Children Jsx)
在之前的文章 探讨:围绕 props 阐述 React 通信 中总结了关于“父子”组件传值,但是当需要在组件树中深层传递参数以及需要在组件间复用相同的参数时,传递 props 就会变得很麻烦。 实际案例: 下述展示有两种状态:① 详…...

《Windows API每日一练》5.1 键盘基础
本节我们讲述关于键盘的一些基础知识。当我们按下一个键盘按键时,会产生一个键盘按键消息。这一点你能确定吗?假如是一个菜单快捷键消息,或者是一个子窗口控件消息呢?这就超出了本节讨论的范围,我们将在菜单和子窗口控…...
方法总结)
Class.forName()方法总结
Class.forName()方法总结 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!Class.forName()方法是Java反射机制中的一个重要方法,它用于动态加载类并返…...

Python | Leetcode Python题解之第168题Excel表列名称
题目: 题解: class Solution:def convertToTitle(self, columnNumber: int) -> str:ans list()while columnNumber > 0:columnNumber - 1ans.append(chr(columnNumber % 26 ord("A")))columnNumber // 26return "".join(an…...

【ARMv8/ARMv9 硬件加速系列 3.5.2 -- SVE 向量寄存器 有多少位数?】
文章目录 SVE 向量寄存器SVE 向量寄存器大小SVE 可伸缩性的好处SVE 寄存器长度示例SVE 向量寄存器 在 ARMv9 架构中,包括其 Scalable Vector Extension (SVE) 和 Scalable Vector Extension 2 (SVE2) 的增强,向量寄存器(通常称为 Z 寄存器)的大小设计为可伸缩的,以便在不…...
)
Vulkan入门系列2- 绘制三角形(未完待续)
概述: Vulkan的学习曲线是比较陡峭的,学习Vulkan刚开始像是在爬一个陡坡,等上了这个陡坡之后,后面学习曲线就相对比较平缓了。那么在Vulkan中绘制一个三角形,就相当于是在爬这样一个陡坡,因为绘制三角形需…...
企业UDP文件传输工具测速的方式(下)
在前一篇文章中,我们深入讨论了UDP传输的基本概念和镭速UDP文件传输工具如何使用命令行快速进行速度测试。现在,让我们进一步探索更为高级和灵活的方法,即通过整合镭速UDP的动态或静态库来实现网络速度的测量,以及如何利用这一过程…...

Artalk-CORS,跨域拦截问题
今天重新部署Artalk之后,遇到了CORS——跨域拦截的问题,卡了好一会记录一下。 起因 重新部署之后,浏览器一直提示CORS,之前在其他项目也遇到过类似的问题,原因就在于跨域问题。...

SSL证书怎样配置部署更安全?
在互联网上,SSL证书是用于加密网站与用户之间传输的数据的一种数字证书。它通过建立安全的连接,确保网站的身份和保护用户的隐私,是网站安全的重要组成部分。然而,要想让SSL证书发挥最大的作用,除了检查证书是否过期外…...
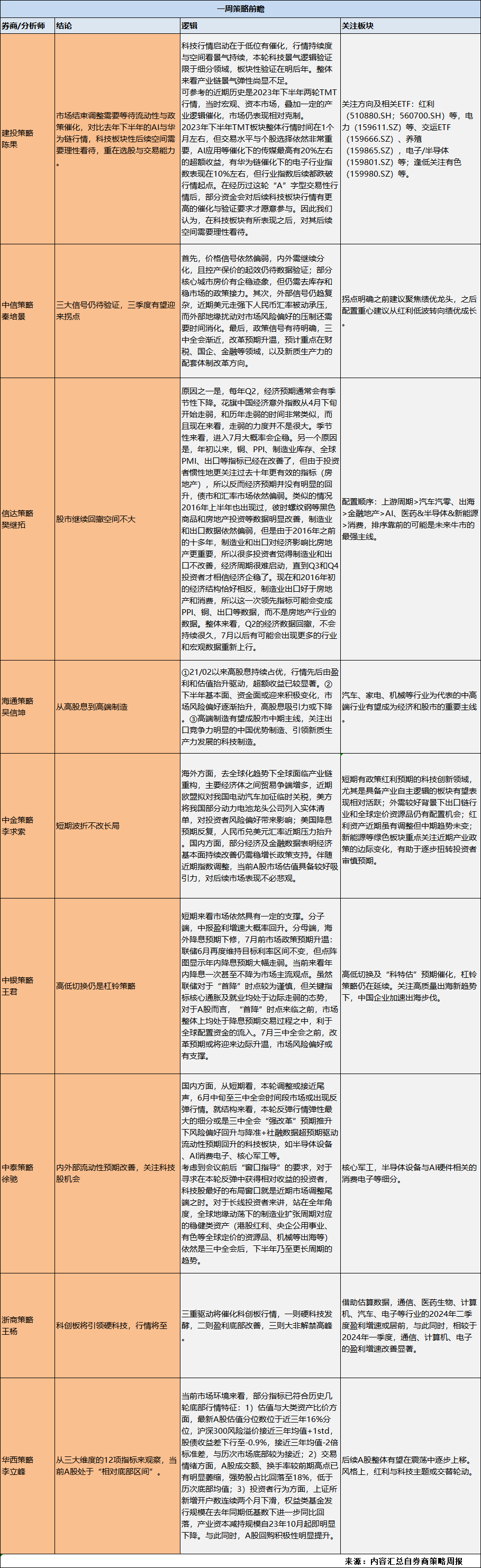
M1失效后,哪个是观察A股的关键新指标?
M1失效后,哪个是观察A股的关键新指标? 央地支出增速差(地方-中央支出增速的差值)或许是解释沪深300定价更有效的前瞻指标。该数值扩张,则有利于大盘指数,反之亦然,该指标从2017年至今对大盘指数…...
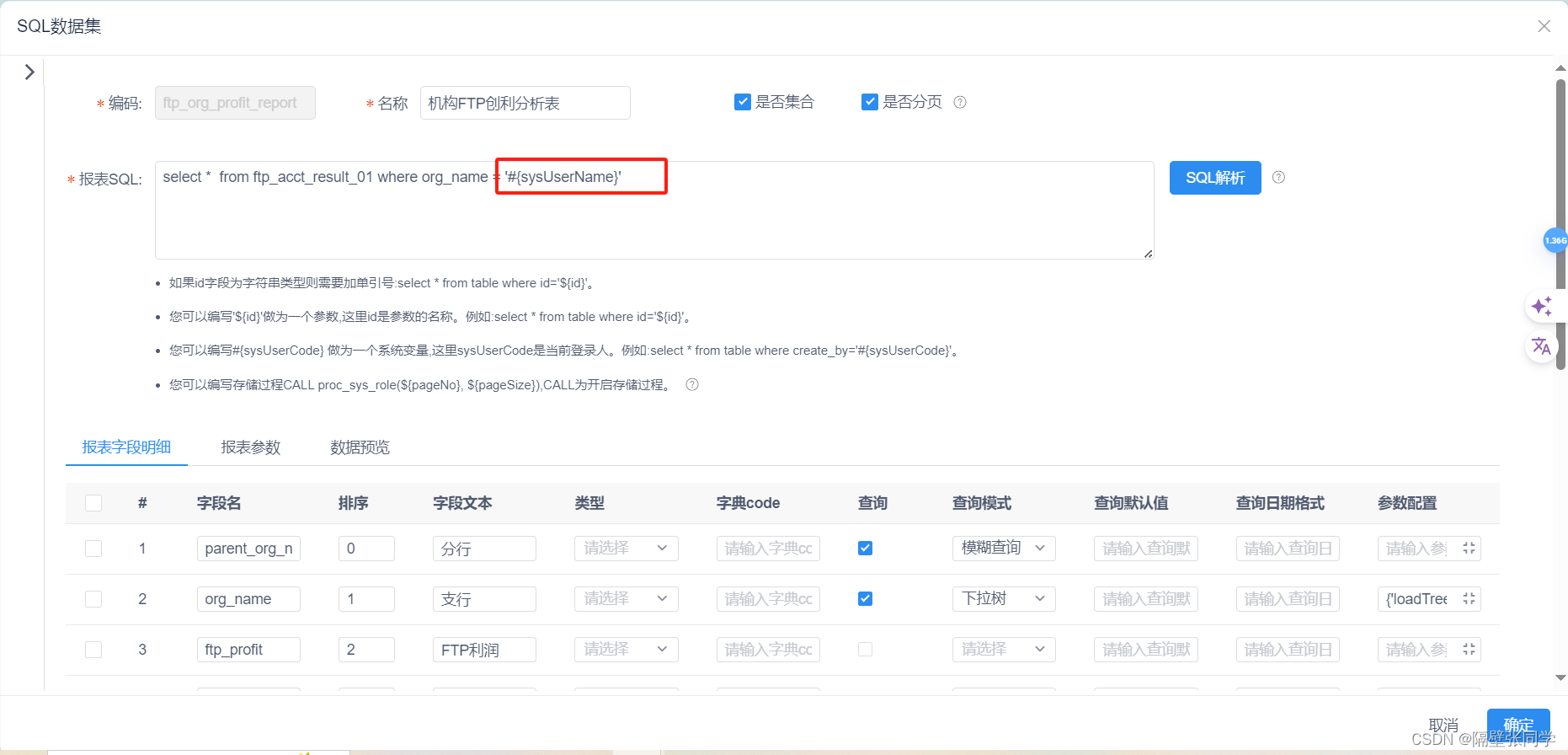
springboot集成积木报表,怎么将平台用户信息传递到积木报表
springboot集成积木报表后怎么将平台用户信息传递到积木报表 起因是因为需要研究在积木报表做数据筛选的时候需要拿到系统当前登录用户信息做筛选新的模块 起因是因为需要研究在积木报表做数据筛选的时候需要拿到系统当前登录用户信息做筛选 官网有详细介绍怎么集成进去的&…...
)
模电小白必看:3种基本放大电路实战对比(附电路图+避坑指南)
模电入门实战:三大基础放大电路深度解析与避坑指南 刚接触模拟电路时,面对共射极、共集极和共基极这三种基本放大电路,很多初学者都会感到困惑——它们看起来相似,但特性却大不相同。本文将用面包板搭建的真实电路和示波器实测波形…...

League Toolkit:重新定义英雄联盟游戏体验的智能辅助工具
League Toolkit:重新定义英雄联盟游戏体验的智能辅助工具 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 价值定位&am…...

HunyuanVideo-Foley入门指南:infer.py命令行参数全量说明与组合技巧
HunyuanVideo-Foley入门指南:infer.py命令行参数全量说明与组合技巧 1. 环境准备与快速部署 HunyuanVideo-Foley是一款强大的视频与音效生成工具,基于RTX 4090D 24GB显存和CUDA 12.4深度优化。在开始使用前,请确保您的硬件配置满足以下要求…...

低成本搭建AI知识库:Qwen3-Embedding-4B量化版仅需3GB显存教程
低成本搭建AI知识库:Qwen3-Embedding-4B量化版仅需3GB显存教程 1. 引言:为什么选择Qwen3-Embedding-4B? 在构建AI知识库时,文本向量化模型的选择至关重要。传统方案要么性能不足,要么资源消耗过大。Qwen3-Embedding-…...

3步免费解锁付费内容:智能内容解锁工具使用指南
3步免费解锁付费内容:智能内容解锁工具使用指南 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在信息获取日益困难的今天,付费墙已经成为阻碍知识传播的主要障…...

别再只盯着标定板了!用ROS camera_calibration搞定海康工业相机,这5个细节决定成败
工业相机标定进阶指南:ROS camera_calibration的五个关键优化点 工业相机的标定质量直接决定了机器视觉系统的测量精度。许多开发者虽然能够完成基础标定流程,却常常在参数解读和精度优化环节遇到瓶颈。本文将深入解析ROS camera_calibration工具在实际工…...

Win11虚拟机密码重置保姆教程:VirtualBox+系统备份双保险
Win11虚拟机密码重置与系统防护全指南:VirtualBox实战策略 在数字化工作环境中,虚拟机已成为隔离测试环境、保障系统安全的标配工具。当我们因各种原因遗忘Windows 11虚拟机密码时,传统物理机的解决方案往往无法直接套用。本文将深入探讨基于…...

Oracle RAC实战:5分钟搞懂SCAN IP和VIP的区别与配置技巧
Oracle RAC实战:SCAN IP与VIP的深度解析与高效配置指南 引言 在Oracle RAC(Real Application Clusters)环境中,高可用性和负载均衡是核心诉求。SCAN IP和VIP作为两大关键技术组件,常常让刚接触RAC的DBA感到困惑。它们虽…...

OpenClaw技能开发入门:基于百川2-13B-4bits制作天气查询插件
OpenClaw技能开发入门:基于百川2-13B-4bits制作天气查询插件 1. 为什么选择OpenClaw开发个人技能? 去年冬天,我每天早上都要手动查询天气决定穿衣厚度,直到发现OpenClaw可以通过自然语言指令自动完成这类重复任务。作为一个开源…...

游戏资源解密工具:RPG Maker Decrypter零基础使用指南
游戏资源解密工具:RPG Maker Decrypter零基础使用指南 【免费下载链接】RPGMakerDecrypter Tool for extracting RPG Maker XP, VX and VX Ace encrypted archives. 项目地址: https://gitcode.com/gh_mirrors/rp/RPGMakerDecrypter RPG Maker Decrypter 是一…...