【MySQL统计函数count详解】
MySQL统计函数count详解
- 1. count()概述
- 2. count(1)和count(*)和count(列名)的区别
- 3. count(*)的实现方式
1. count()概述
count() 是一个聚合函数,返回指定匹配条件的行数。开发中常用来统计表中数据,全部数据,不为null数据,或者去重数据。
2. count(1)和count(*)和count(列名)的区别
1.函数说明
count(1):统计所有的记录(包括null)。
count(*):统计所有的记录(包括null)。
count(字段):统计该"字段"不为null的记录。
count(distinct 字段):统计该"字段"去重且不为null的记录。
count(1)中的1并不是表示第一个字段,而是表示一个固定值。其实就可以想成表中有这么一个字段,这个字段就是固定值1,count(1),就是计算一共有多少个1。count(*),执行时会把星号翻译成字段的具体名字,效果也是一样的,不过多了一个翻译的动作,比固定值的方式效率稍微低一些。
2.执行效率
他们之间根据不同情况会有些许区别,MySQL 会对count()做优化。(1)如果表中只有一列,则count( )效率最优。(2)如果表有多列,且存在主键,count (主键列名)效率最优,其次是:count (1) >count( *)。(3)如果表有多列,且不存在主键,则count(1 )效率优于count( *)
3.执行过程
count(*)包括了所有的列,相当于行数,在统计结果的时候, 包括列值为NULL的行。
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候, 包括列值为NULL的行。
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数, 即某个字段值为NULL时,不统计。
4.注意事项
阿里开发手册规范相关规定:
1.【强制】不要使用 count(列名)或 count(常量)来替代 count(),count()是 SQL92 定义的标 准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关. 说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行.
2.【强制】count(distinct col) 计算该列除 NULL 之外的不重复行数,注意 count(distinct col1, col2) 如果其中一列全为 NULL,那么即使另一列有不同的值,也返回为 0.
3. count(*)的实现方式
在日常开发中经常会统计一个表的行数,通过select count(*) from t很容易实现,可是随着记录数越来越多,统计函数执行越来越慢,然后呢可能会想mysql记录个总数不行吗,为什么每次都要逐行累加呢,count(列名)的时候还要判空,那么今天我们就聊聊count(*)的实现方式。
你首先要明确的是,在不同的MySQL引擎中,count(*)有不同的实现方式。
MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count()的时候会直接返回这个数,效率很高;
而InnoDB引擎就麻烦了,它执行count()的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
这里需要注意的是,我们在这篇文章里讨论的是没有过滤条件的count(*),如果加了where 条件的话,MyISAM表也是不能返回得这么快的。
我们一起分析了为什么要使用InnoDB,因为不论是在事务支持、并发能力还是在数据安全方面,InnoDB都优于MyISAM。我猜你的表也一定是用了InnoDB引擎。这就是当你的记录数越来越多的时候,计算一个表的总行数会越来越慢的原因。那为什么InnoDB不跟不 MyISAM一样,也把数字存起来呢?
这是因为即使是在同一个时刻的多个查询,由于多版本并发控制(MVCC)的原因,InnoDB表“应该返回多少行”也是不确定的。这里,我用一个算count(*)的例子来为你解释一下。
假设表t中现在有10000条记录,我们设计了三个用户并行的会话。
- 会话A先启动事务并查询一次表的总行数;
- 会话B启动事务,插入一行后记录后,查询表的总行数;
- 会话C先启动一个单独的语句,插入一行记录后,查询表的总行数。
我们假设从上到下是按照时间顺序执行的,同一行语句是在同一时刻执行的。 你会看到,在最后一个时刻,三个会话A、B、C会同时查询表t的总行数,但拿到的结果却不同。这和InnoDB的事务设计有关系,可重复读是它默认的隔离级别,在代码上就是通过多版本并发控制,也就是MVCC来实现的。每一行记录都要判断自己是否对这个会话可见,因此对于count(*)请求来说,InnoDB只好把数据一行一行地读出依次判断,可见的行才能够用于计算“基于这个查询”的表的总行数。不同版本的会话统计的行数是不一样的,所以统计行数直接保存不支持。
你会看到,在最后一个时刻,三个会话A、B、C会同时查询表t的总行数,但拿到的结果却不同。这和InnoDB的事务设计有关系,可重复读是它默认的隔离级别,在代码上就是通过多版本并发控制,也就是MVCC来实现的。每一行记录都要判断自己是否对这个会话可见,因此对于count(*)请求来说,InnoDB只好把数据一行一行地读出依次判断,可见的行才能够用于计算“基于这个查询”的表的总行数。不同版本的会话统计的行数是不一样的,所以统计行数直接保存不支持。
当然,现在这个看上去笨笨的MySQL,在执行count(*)操作的时候还是做了优化的。
你知道的,InnoDB是索引组织表,主键索引树的叶子节点是数据,而普通索引树的叶子节点是主键值。所以,普通索引树比主键索引树小很多。对于count(*)这样的操作,遍历哪个索引树得到的结果逻辑上都是一样的。因此,MySQL优化器会找到最小的那棵树来遍历。在保证逻辑正 在确的前提下,尽量减少扫描的数据量,是数据库系统设计的通用法则之一。
如果你用过showtable status 命令的话,就会发现这个命令的输出结果里面也有一个TABLE_ROWS用于显示这个表当前有多少行,这个命令执行挺快的,那这个TABLE_ROWS能代替count(*)吗?
你可能还记得在第10篇文章《 MySQL为什么有时候会选错索引?》中我提到过,索引统计的值是通过采样来估算的。实际上,TABLE_ROWS就是从这个采样估算得来的,因此它也很不准。有多不准呢,官方文档说误差可能达到40%到50%。所以, 所 show table status s 命令显示的行 命数也不能直接使用。
到这里我们小结一下:
MyISAM表虽然count(*)很快,但是不支持事务,而且带有条件的时候也是不能直接使用记录的总数的;
showtable status命令虽然返回很快,但是不准确;
InnoDB表直接count(*)会遍历全表,虽然结果准确,但会导致性能问题。
那么,回到文章开头的问题,如果你现在有一个页面经常要显示交易系统的操作记录总数,到底应该怎么办呢?答案是,我们只能自己计数。接下来,我们讨论一下,看看自己计数有哪些方法,以及每种方法的优缺点有哪些。这里,我先和你说一下这些方法的基本思路:你需要自己找一个地方,把操作记录表的行数存起来。
用缓存系统保存计数
对于更新很频繁的库来说,你可能会第一时间想到,用缓存系统来支持。
你可以用一个Redis服务来保存这个表的总行数。这个表每被插入一行Redis计数就加1,每被删除一行Redis计数就减1。这种方式下,读和更新操作都很快,但你再想一下这种方式存在什么问题吗?没错,缓存系统可能会丢失更新。
Redis的数据不能永久地留在内存里,所以你会找一个地方把这个值定期地持久化存储起来。但即使这样,仍然可能丢失更新。试想如果刚刚在数据表中插入了一行,Redis中保存的值也加了1,然后Redis异常重启了,重启后你要从存储redis数据的地方把这个值读回来,而刚刚加1的这个计数操作却丢失了。
当然了,这还是有解的。比如,Redis异常重启以后,到数据库里面单独执行一次count(*)获取真实的行数,再把这个值写回到Redis里就可以了。异常重启毕竟不是经常出现的情况,这一次全表扫描的成本,还是可以接受的。但实际上,将计数保存在缓存系统中的方式,还不只是丢失更新的问题。即使 将 Redis R 正常工 正作,这个值还是逻辑上不精确的。 作你可以设想一下有这么一个页面,要显示操作记录的总数,同时还要显示最近操作的100条记录。那么,这个页面的逻辑就需要先到Redis里面取出计数,再到数据表里面取数据记录。我们是这么定义不精确的:
- 一种是,查到的100行结果里面有最新插入记录,而Redis的计数里还没加1;
- 另一种是,查到的100行结果里没有最新插入的记录,而Redis的计数里已经加了1。
这两种情况,都是逻辑不一致的。
数据库保存计数
根据上面的分析,用缓存系统保存计数有丢失数据和计数不精确的问题。那么,如果我们把这 如个计数直接放到数据库里单独的一张计数表 个 C中,又会怎么样呢?
首先,这解决了崩溃丢失的问题,InnoDB是支持崩溃恢复不丢数据的。然后,我们再看看能不能解决计数不精确的问题。
不同count用法
这里,首先你要弄清楚count()的语义。count()是一个聚合函数,对于返回的结果集,一行行地判断,如果count函数的参数不是NULL,累计值就加1,否则不加。最后返回累计值。
所以,count(*)、count(主键id)和count(1) 都表示返回满足条件的结果集的总行数;而count(字段),则表示返回满足条件的数据行里面,参数“字段”不为NULL的总个数。
至于分析性能差别的时候,你可以记住这么几个原则:
- server层要什么就给什么;
- InnoDB只给必要的值;
- 现在的优化器只优化了count(*)的语义为“取行数”,其他“显而易见”的优化并没有做。
这是什么意思呢?接下来,我们就一个个地来看看。
对于对 count( c 主键主 id) i 来说来 :
InnoDB引擎会遍历整张表,把每一行的id值都取出来,返回给server层。server层拿到id后,判断是不可能为空的,就按行累加。
对于对 count(1) c 来说来 ,InnoDB引擎遍历整张表,但不取值。server层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
单看这两个用法的差别的话,你能对比出来,count(1)执行得要比count(主键id)快。因为从引擎返回id会涉及到解析数据行,以及拷贝字段值的操作。
对 count( c 字段字 )来说来 :
- 如果这个“字段”是定义为not null的话,一行行地从记录里面读出这个字段,判断不能为null,按行累加;
- 如果这个“字段”定义允许为null,那么执行的时候,判断到有可能是null,还要把值取出来再判断一下,不是null才累加。
也就是前面的第一条原则,server层要什么字段,InnoDB就返回什么字段。
对 count( * )来说来 :
但 count(*) 是例外 是 ,并不会把全部字段取出来,而是专门做了优化,不取值。count(*)肯定不是null,按行累加。
看到这里,你一定会说,优化器就不能自己判断一下吗,主键id肯定非空啊,为什么不能按照count(*)来处理,多么简单的优化啊。
当然,MySQL专门针对这个语句进行优化,也不是不可以。但是这种需要专门优化的情况太多了,而且MySQL已经优化过count(*)了,你直接使用这种用法就可以了。
所以结论是:按照效率排序的话,count(字段)<count(主键id)<count(1)≈count(*),所以我建议你,尽量使用count(*)。
文章知识点与官方知识档案匹配,可进一步学习相关知识
相关文章:
【MySQL统计函数count详解】
MySQL统计函数count详解 1. count()概述2. count(1)和count(*)和count(列名)的区别3. count(*)的实现方式 1. count()概述 count() 是一个聚合函数,返回指定匹配条件的行数。开发中常用来统计表中数据,全部数据,不为null数据,或…...

大数据的发展,带动电子商务产业链,促进了社会的进步【电商数据采集API接口推动电商项目的源动力】
最近几年计算机技术在诸多领域得到了有效的应用,同时在多方面深刻影响着我国经济水平的发展。除此之外,人民群众的日常生活水平也受大数据技术的影响。 在这其中电子商务领域也在大数据技术的支持下,得到了明显的进步。虽然电子商务领域的发…...

Python类中变量定义详解
✨前言: Python中的类可以定义两种类型的变量:类变量和实例变量。 类变量(Class Variables): 类变量是在类级别上定义的变量,它们是对所有实例共享的。这意味着类变量只有一个副本,无论你创建了…...

c++ extern 关键字详解
extern关键字在C中用于声明变量或函数的外部链接。它通常用于以下几种场景: 声明全局变量:在一个文件中定义变量,在其他文件中使用extern声明该变量,以便在多个文件之间共享。C和C混合编程:在C代码中引用C语言编写的函…...
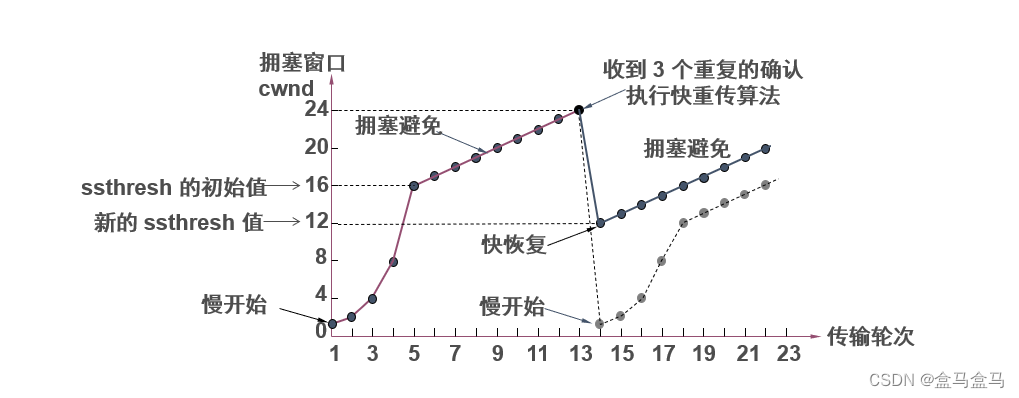
计算机网络:运输层 - TCP 流量控制 拥塞控制
计算机网络:运输层 - TCP 流量控制 & 拥塞控制 滑动窗口流量控制拥塞控制慢开始算法拥塞避免算法快重传算法快恢复算法 滑动窗口 如图所示: 在TCP首部中有一个窗口字段,该字段就基于滑动窗口来辅助流量控制和拥塞控制。所以我们先讲解滑…...

Python学习打卡:day10
day10 笔记来源于:黑马程序员python教程,8天python从入门到精通,学python看这套就够了 目录 day1073、文件的读取操作文件的操作步骤open()打开函数mode常用的三种基础访问模式读操作相关方法read()方法readlines()方法readline()方法for循…...
新书速览|Ubuntu Linux运维从零开始学
《Ubuntu Linux运维从零开始学》 本书内容 Ubuntu Linux是目前最流行的Linux操作系统之一。Ubuntu的目标在于为一般用户提供一个最新的、相当稳定的、主要由自由软件构建而成的操作系统。Ubuntu具有庞大的社区力量,用户可以方便地从社区获得帮助。《Ubuntu Linux运…...
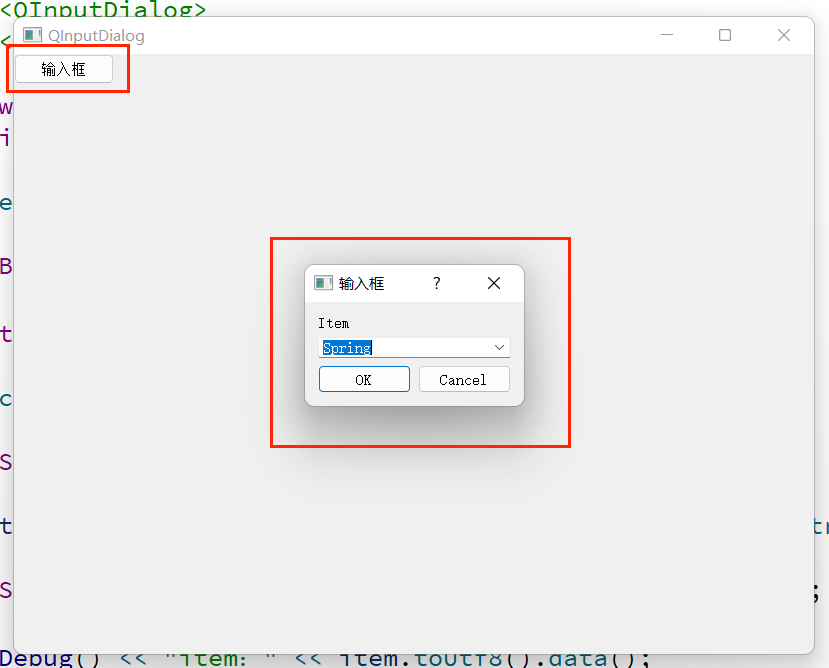
[Qt的学习日常]--窗口
前言 作者:小蜗牛向前冲 名言:我可以接受失败,但我不能接受放弃 如果觉的博主的文章还不错的话,还请点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 目录 一、窗口的分…...
Vue发送http请求
1.创建项目 创建一个新的 Vue 2 项目非常简单。在终端中,进入您希望创建项目的目录(我的目录是D:\vue),并运行以下命令: vue create vue_test 2.切换到项目目录,运行项目 运行成功后,你将会看到以下的编译成功的提示…...
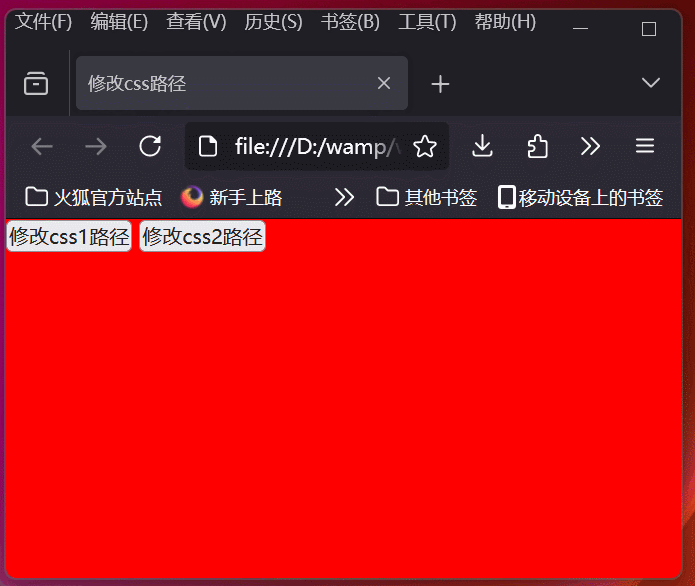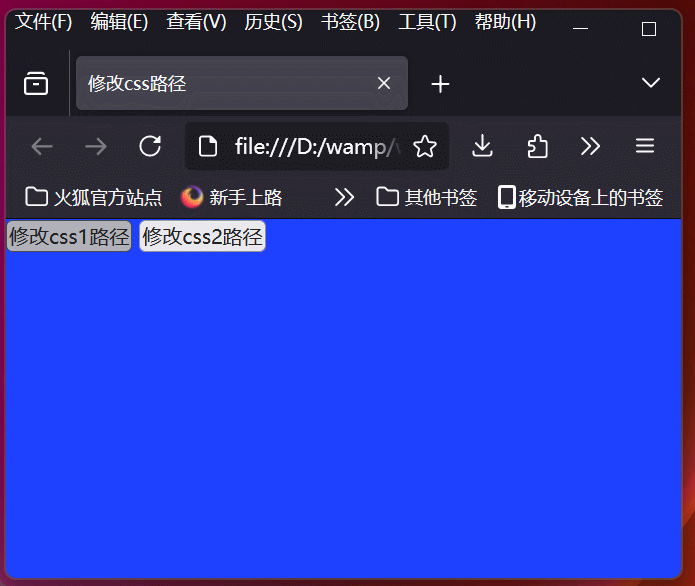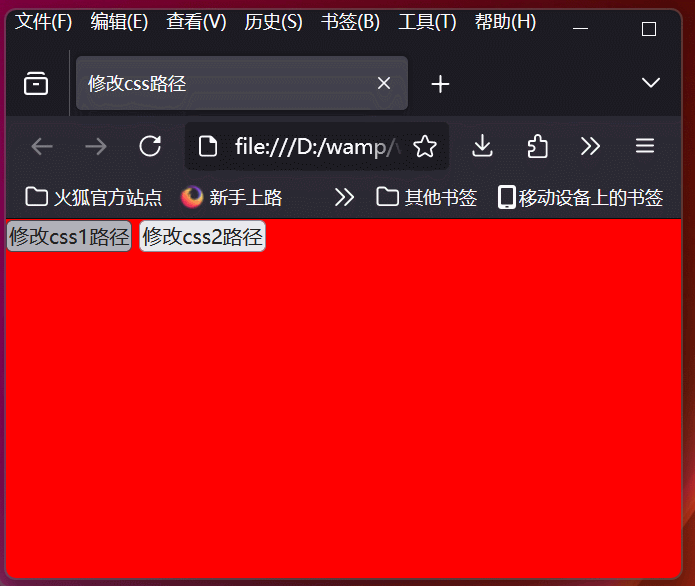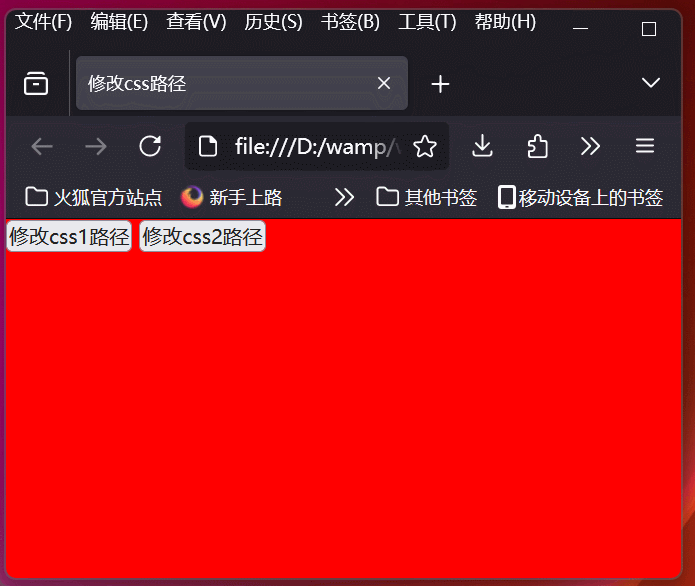
学习使用js和jquery修改css路径,实现html页面主题切换功能
学习使用js和jquery修改css路径,实现html页面主题切换功能 效果图html代码js切换css关键代码jquery切换css关键代码 效果图 html代码 <!DOCTYPE html> <html> <head><meta charset"utf-8"><title>修改css路径</title&g…...
请介绍一下Redis的数据淘汰策略)
(转)请介绍一下Redis的数据淘汰策略
1. **NoEviction(不淘汰)**:当内存不足时,直接返回错误,不淘汰任何数据。该策略适用于禁止数据淘汰的场景,但需要保证内存足够。 2. **AllKeysLFU(最少使用次数淘汰)**:…...

APP自动化测试-Appium常见操作之详讲
一、基本操作 1、点击操作 示例:element.click() 针对元素进行点击操作 2、初始化:输入中文的处理 说明:如果连接的是虚拟机(真机无需加这两个参数,加上可能会影响手工输入),在初始化配置中…...

写给大数据开发:谈谈数仓建模的反三范式
在数仓建设中,我们经常谈论反三范式。顾名思义,反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能。简单来说,就是浪费存储空间,节省查询时间。用行话讲,这就是以空间换时间。听起来像是用大炮打蚊子&#…...

Stable diffusion 3 正式开源
6月12日晚,著名开源大模型平台Stability AI正式开源了,文生图片模型Stable Diffusion 3 Medium(以下简称“SD3-M”)权重。 SD3-M有20亿参数,平均生成图片时间在2—10秒左右推理效率非常高,同时对硬件的需求…...
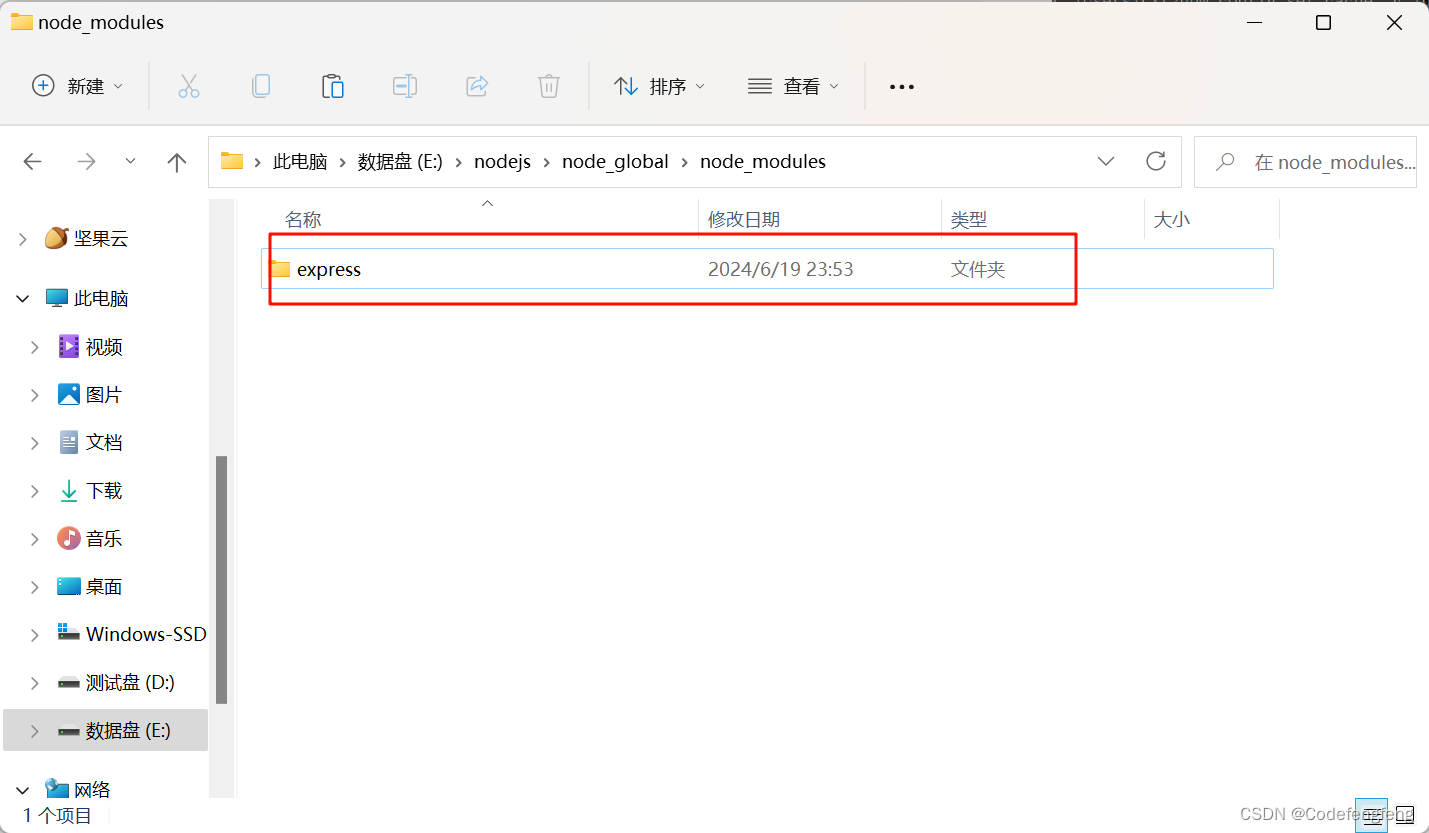
如何配置node.js环境
文章目录 step1. 下载node.js安装包step2. 创建node_global, node_cache文件夹step3.配置node环境变量step3. cmd窗口检查安装的node和npm版本号step4. 设置缓存路径\全局安装路径\下载镜像step5. 测试配置的nodejs环境 step1. 下载node.js安装包 下载地址:node.js…...

python tensorflow 各种神经元
感知机神经元(Perceptron Neuron): 最基本的人工神经元模型,用于线性分类任务。 import numpy as npclass Perceptron:def __init__(self, input_size, learning_rate0.01, epochs1000):self.weights np.zeros(input_size 1) #…...

Gone框架介绍27 - 再讲 Goner 和 依赖注入
gone是可以高效开发Web服务的Golang依赖注入框架 github地址:https://github.com/gone-io/gone 文档地址:https://goner.fun/zh/ 文章目录 Goner 和 依赖注入Goner的定义依赖标记Goners 注册Priest函数 Goner 和 依赖注入 Gone 作为一个依赖注入框架&am…...
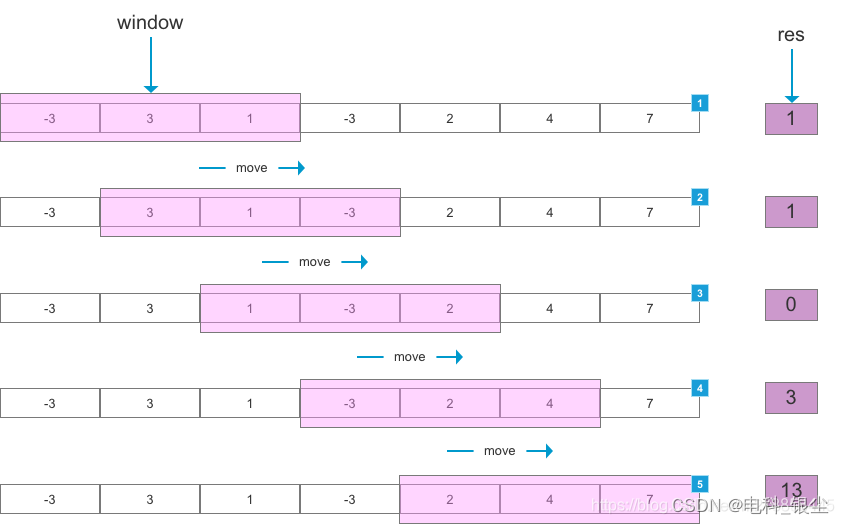
【Python/Pytorch 】-- 滑动窗口算法
文章目录 文章目录 00 写在前面01 基于Python版本的滑动窗口代码02 算法效果 00 写在前面 写这个算法原因是:训练了一个时序网络,该网络模型的时序维度为32,而测试数据的时序维度为90。因此需要采用滑动窗口的方法,生成一系列32…...

Clickhouse集群create drop database可删除集群数据库或只删除本地数据库
集群环境下,在任意一个节点创建数据库,如果加上了ON CLUSTER clustername,则在集群环境的所有节点上都创建了该数据库,并在集群环境的所有节点上都创建了该数据库对应的目录,且数据库的metadata_path对应的目录路径在所…...

【docker】adoptopenjdk/openjdk8-openj9:alpine-slim了解
adoptopenjdk/openjdk8-openj9:alpine-slim 是一个 Docker 镜像的标签,它指的是一个特定的软件包,用于在容器化环境中运行 Java 应用程序。 镜像相关的网站和资源: AdoptOpenJDK 官方网站 - AdoptOpenJDK 这是 AdoptOpenJDK 项目的官方网站&…...
)
点云匹配方法 NDT(正态分布变换)
1. 正态分布变换 (NDT) 在点云匹配中,ICP基于距离直接最优化变换矩阵的参数,由于是欠定方程且旋转矩阵的约束,使得结果很难优化,为此在新的维度优化变换矩阵的参数,被很好的提出: 先将参考点云࿰…...

OpenClaw数据备份实战:基于Synology NAS的增量备份与安全恢复方案
1. 项目概述与核心价值如果你和我一样,把OpenClaw当作一个重要的生产力工具,用它来管理项目、运行自动化任务,甚至托管一些关键的业务逻辑,那么数据安全就成了一个绕不开的话题。我见过太多因为硬盘突然挂掉、云服务商出问题&…...

AI代理如何通过MCP协议实现DeFi自动化操作与策略执行
1. 项目概述:当DeFi遇上AI代理,Robocular/defi-mcp的诞生最近在捣鼓链上自动化策略和AI代理,发现了一个挺有意思的项目——Robocular/defi-mcp。简单来说,这是一个专门为AI代理(特别是那些基于MCP,也就是Mo…...

QGIS图层驾驭术 | 新手必会的三大核心操作
1. 图层基础:理解QGIS的"透明胶片"逻辑 第一次打开QGIS时,看到空白的画布和一堆按钮,很多人会感到无从下手。其实理解图层概念最简单的方式,就是想象你在用传统方法制作地图:把不同内容的透明胶片叠在一起。…...

改进灰狼算法天线优化设计【附代码】
✨ 长期致力于灰狼优化算法、直线阵列天线、平面阵列天线、微带天线研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)Logistic-Tent双重混沌初始化与非…...

图片换背景底色怎么制作?一款微信小程序让你3步搞定
最近在抖音和小红书上刷到不少博主分享换背景的小技巧,我也趁机研究了一遍,发现现在换背景底色真的比以前方便多了。不管是证件照换底色、商品图去背景,还是日常自拍的背景替换,都有办法解决。今天就把我的使用心得分享给你们&…...

从DenseNet到特征复用:揭秘密集连接如何重塑卷积网络
1. 密集连接:卷积网络的第三次进化 记得我第一次跑图像分类任务时,用的还是传统的VGG网络。那时候为了提升准确率,只能不断堆叠卷积层,结果模型体积像吹气球一样膨胀到500MB。直到2017年遇到DenseNet,才发现原来只需要…...

Bun用Claude自己“换心手术“?AI重构软件的新纪元来了
五月中旬的编程界上演了一出荒诞又魔幻的戏码——Bun,这个曾以 Zig 语言为傲的 JavaScript 运行时,在短短六天时间里,由被它拖累的 Claude AI 亲手把自己从 Zig 重写成 Rust 语言。事情得从两年前说起。2024年,Bun 创始人 Jarred …...

信息时代个人知识管理:从碎片化信息到结构化洞察的实践指南
1. 信息海洋中的航行:从碎片到洞察我们正漂浮在一片前所未有的信息海洋里。每天,无数的邮件、通知、文章、帖子像潮水般涌来,我们则像一个个拾贝者,快乐地捡拾着那些零碎的趣闻和知识的金块。这种感觉很奇妙,不是吗&am…...
【玩转PB级数仓GaussDB(DWS)】)
windows系统下操作GaussDB(DWS)【玩转PB级数仓GaussDB(DWS)】
数据仓库服务GaussDB(DWS) 是一种基于华为云基础架构和平台的在线数据处理数据库,提供即开即用、可扩展且完全托管的分析型数据库服务。GaussDB(DWS)是基于华为融合数据仓库GaussDB产品的云原生服务 ,兼容标准ANSI SQL 99和SQL 2003,同时兼容…...