【Python机器学习系列】针对特定数据构建管道流水线进行机器学习预测(案例+源码)
这是我的第305篇原创文章。
一、引言
机器学习项目中有可以自动化的标准工作流程。在 Python scikit-learn 中,管道有助于明确定义和自动化这些工作流程。使用pipeline后,我们每一步的输出都会自动的作为下一个的输入。一套完整的机器学习应用流程如下:

其中特征工程(本质是多个转换器)以及模型的构建和训练(本质是一个估计器)可以通过一个流水线管道来实现。根据要解决的问题,自定义转换器可以帮助克服预定义转换器无法处理的困难。同时也能够十分灵活的处理列。下面将会使用一些例子来说明它的强大之处。这个例子的目的是让读者熟悉他们可以用来创建转换器和管道的工具,这将使他们能够尽可能高效地以任何方式针对任何数据集设计和预处理特征。
二、自定义转换器
2.1 数据提取转换器

该数据集包含分类和数值自变量的混合,它们必须通过单独的管道进行适当的预处理,然后我们将它们组合在一起。因此,两个管道的第一步都必须是提取需要进行预处理的适当列。下面是名为 FeatureSelector 的自定义转换器的代码。此构造函数的转换方法仅提取并返回 Pandas 数据集,其中仅包含其名称在其初始化期间作为参数传递给它的那些列。
class FeatureSelector(BaseEstimator, TransformerMixin):# 构造函数,传递列参数用于列抽取# 可以加入一些打印信息,看看执行的流程def __init__(self, feature_names):self.feature_names = feature_names# print('FeatureSelector init exce...')# 返回对象本身def fit(self, X, y=None):# print('FeatureSelector fit exce...')return self# 我们需要重写transform方法def transform(self, X, y=None):# print('FeatureSelector transform exce...')return X[self.feature_names]2.2 分类管道中的自定义转化器
自定义转换器将在分类管道中处理的功能列表:
-
-
date :此列中的日期格式为“YYYYMMDDT000000”,必须经过清理和处理才能以任何有意义的方式使用。这个转换器的构造函数将允许我们为参数“use_dates”指定一个值列表,具体取决于我们是要为年、月和日或这些值的某种组合创建一个单独的列,还是简单地完全忽略该列传入一个空列表。通过不对该功能的规范进行硬编码,我们可以随时尝试不同的值组合,而无需重写代码。
-
waterfront:房子是否是近邻海滨。转换为二进制 - 是或否
-
view : 房子被查看了多少次。大多数值是 0。其余的值在 1 和 4 之间分布非常稀疏。转换为二进制 — 是或否
-
yr_renovated : 房子翻新的年份。大部分值都是 0,大概是从不,而其余的在几年之间的分布非常稀薄。转换为二进制 - 是或否
-
# 构建自定义的分类列Transformer
class CategoricalTransformer(BaseEstimator, TransformerMixin):def __init__(self, use_dates=['year', 'month', 'day']):self._use_dates = use_dates# print('CategoricalTransformer init exce...')def fit(self, X, y=None):return selfdef get_year(self, obj):return str(obj)[:4]def get_month(self, obj):return str(obj)[4:6]def get_day(self, obj):return str(obj)[6:8]def create_binary(self, obj):if obj == 0:return 'No'else:return 'Yes'def transform(self, X, y=None):# print('CategoricalTransformer transform exce...')for spec in self._use_dates:exec("X.loc[:,'{}'] = X['date'].apply(self.get_{})".format(spec, spec))X = X.drop(columns=['date'], axis=1)X.loc[:, 'view'] = X['view'].apply(self.create_binary)X.loc[:, 'waterfront'] = X['waterfront'].apply(self.create_binary)X.loc[:, 'yr_renovated'] = X['yr_renovated'].apply(self.create_binary)return X.values2.3 数值管道中的自定义转换器
自定义数值转换器在管道中处理的功能列表:
-
-
bedrooms:房子里的卧室数量。照原样通过。
-
bathrooms: 房子里的浴室数量。这个转换器的构造函数将有一个参数“bath_per_bead”,它接受一个布尔值。如果为 True,则构造函数将通过计算浴室/卧室来创建一个新列,以计算每间卧室的浴室数量并删除原始浴室列。如果为 False,则它只会按原样通过浴室列。
-
sqft_living :房屋居住面积的平方英尺。照原样通过。
-
sqft_lot :以平方英尺为单位的地块总面积。照原样通过。
-
floors:房屋的楼层数。照原样通过。
-
condition :描述房屋状况的离散变量,取值范围为 1–5。照原样通过。
-
grade:给予住房单元的总体等级,基于金县分级系统,值从 1 到 13。照原样通过。
-
sqft_basement :房屋地下室的大小(如果有),以平方英尺为单位。0 表示没有地下室的房屋。照原样通过。
-
yr_built : 房子的建造年份。这个转换器的构造函数将有另一个参数“years_old”,它也接受一个布尔值。如果为 True,则构造函数将通过从 2019 年减去房屋建造年份来计算 2019 年房屋的年龄来创建一个新列,并删除原始的 yr_built 列。如果为 False,则它只会按原样传递 yr_built 列
-
# 自定义数值列的转换处理器
class NumericalTransformer(BaseEstimator, TransformerMixin):# 构造函数,bath_per_bed ,years_old控制是否计算卧室和时间处理def __init__(self, bath_per_bed=True, years_old=True):self._bath_per_bed = bath_per_bedself._years_old = years_old# 直接返回转换器本身def fit(self, X, y=None):return self# 我们编写的自定义变换方法创建了上述特征并删除了冗余特征def transform(self, X, y=None):if self._bath_per_bed:# 创建新列X.loc[:, 'bath_per_bed'] = X['bathrooms'] / X['bedrooms']# 删除冗余列X.drop('bathrooms', axis=1)if self._years_old:# 创建新列X.loc[:, 'years_old'] = 2019 - X['yr_built']# 删除冗余列X.drop('yr_built', axis=1)# 将数据集中的任何无穷大值转换为 NanX = X.replace([np.inf, -np.inf], np.nan)# 返回一个 numpy 数组return X.values三、实现过程
3.1 读取数据
data = pd.read_csv(r'data.csv')
df = pd.DataFrame(data)
print(df.head())df:

3.2 划分数据集
X = data.drop('price', axis=1)
y = data['price'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)3.3 特征分类传递
传递分类管道的分类特征:
categorical_features = ['date', 'waterfront', 'view', 'yr_renovated']传递数值管道的数值特征:
numerical_features = ['bedrooms', 'bathrooms', 'sqft_living', 'sqft_lot', 'floors', 'condition', 'grade', 'sqft_basement', 'yr_built']3.4 管道流水线定义
定义分类管道中的步骤:
categorical_pipeline = Pipeline(steps=[('cat_selector', FeatureSelector(categorical_features)),('cat_transformer', CategoricalTransformer()),('one_hot_encoder', OneHotEncoder(sparse=False))])定义数值管道中的步骤:
numerical_pipeline = Pipeline(steps=[('num_selector', FeatureSelector(numerical_features)),('num_transformer', NumericalTransformer()),('imputer', SimpleImputer(strategy='median')),('std_scaler', StandardScaler())])3.5 管道组合
使用FeatureUnion将数值和分类管道水平组合成一个完整大管道:
full_pipeline = FeatureUnion(transformer_list=[('categorical_pipeline', categorical_pipeline),('numerical_pipeline', numerical_pipeline)])3.6 建立完整管道
完整管道将估算器作为最后一步:
full_pipeline_m = Pipeline(steps=[('full_pipeline', full_pipeline),('model', LinearRegression())])3.7 管道流水线对训练集进行特征处理和训练
full_pipeline_m.fit(X_train, y_train)3.8 管道流水线对测试集进行特征处理和预测
y_pred = full_pipeline_m.predict(X_test)
print(y_pred)y_pred:
![]()
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。
相关文章:
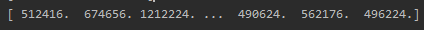
【Python机器学习系列】针对特定数据构建管道流水线进行机器学习预测(案例+源码)
这是我的第305篇原创文章。 一、引言 机器学习项目中有可以自动化的标准工作流程。在 Python scikit-learn 中,管道有助于明确定义和自动化这些工作流程。使用pipeline后,我们每一步的输出都会自动的作为下一个的输入。一套完整的机器学习应用流程如下&a…...

Python 学习 第三册 第12章 图的最优化问题
----用教授的方式学习。 目录 12.1图的最优化问题 12.1.1最短路径:深度优先搜索和广度优先搜索 12.1图的最优化问题 我们下面研究另一种最优化问题。假设你有一个航空公司航线的价格列表,其中包括美国任意两个城市之间的航班价格。假设有3个城市A、B和C,从A出发经过B到达…...

建筑工程乙级资质与工程质量控制体系的构建
1. 质量管理体系建立 ISO 9001认证:虽然不是直接要求,但许多乙级资质企业会选择通过ISO 9001质量管理体系认证,以标准化管理流程,提升质量管理水平。质量方针与目标:明确企业的质量方针,设定可量化、可追踪…...

kafka学习笔记07
Kafka高可用集群搭建节点需求规划 开放端口。 Kafka高可用集群之zookeeper集群搭建环境准备 删除之前的kafka和zookeeper。 重新进行环境部署: 我们解压我们的zookeeper: 编辑第一个zookeeper的配置文件: 我们重复类似的操作,创建三个zookeeper节点: 记…...
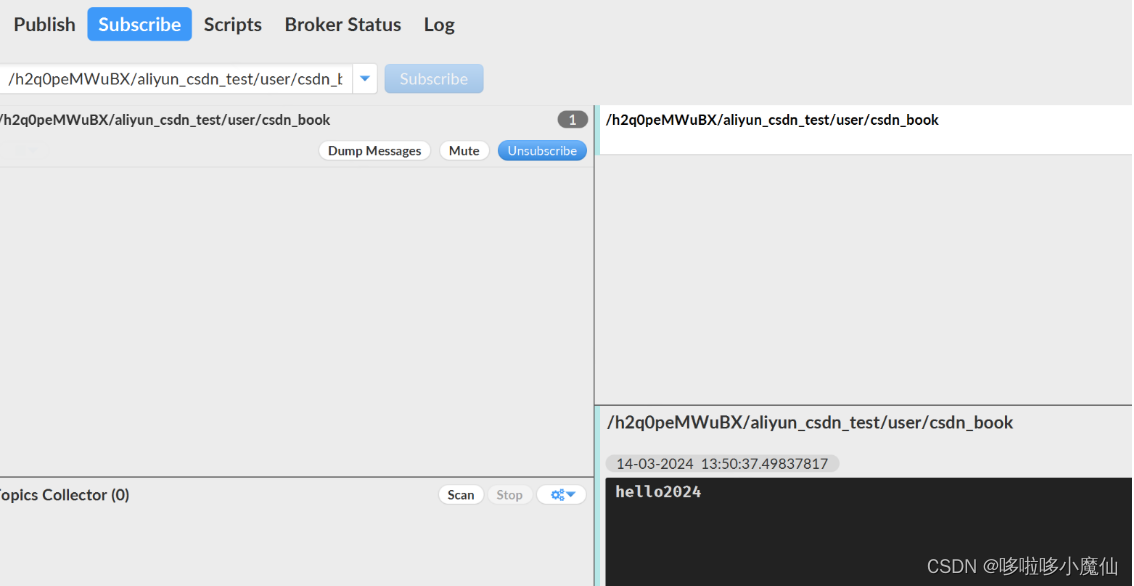
MQTTfx连接阿里云(详细版)
1、介绍 作为物联网开放平台,阿里云可谓是吸引大多数嵌入式爱好者的平台。物联网MQTT协议火热的今天,你使用过阿里云吗?本篇文章带你接触阿里云,实现MQTT通信。 我们在测试MQTT之前先了解下什么是MQTT协议。大家都知道它是一种发…...

Vue3使用provide和inject实现孙组件给爷组件传递数据
前言: 最近在研究gitHub中的一个项目并将与自己之前完成的项目进行结合,其中有一个功能是需要在孙组件将数据传递给爷组件,笔者研究后将使用总结如下: 具体步骤: 1.爷组件先定义一个空的函数传递给孙子 2.孙组件使…...
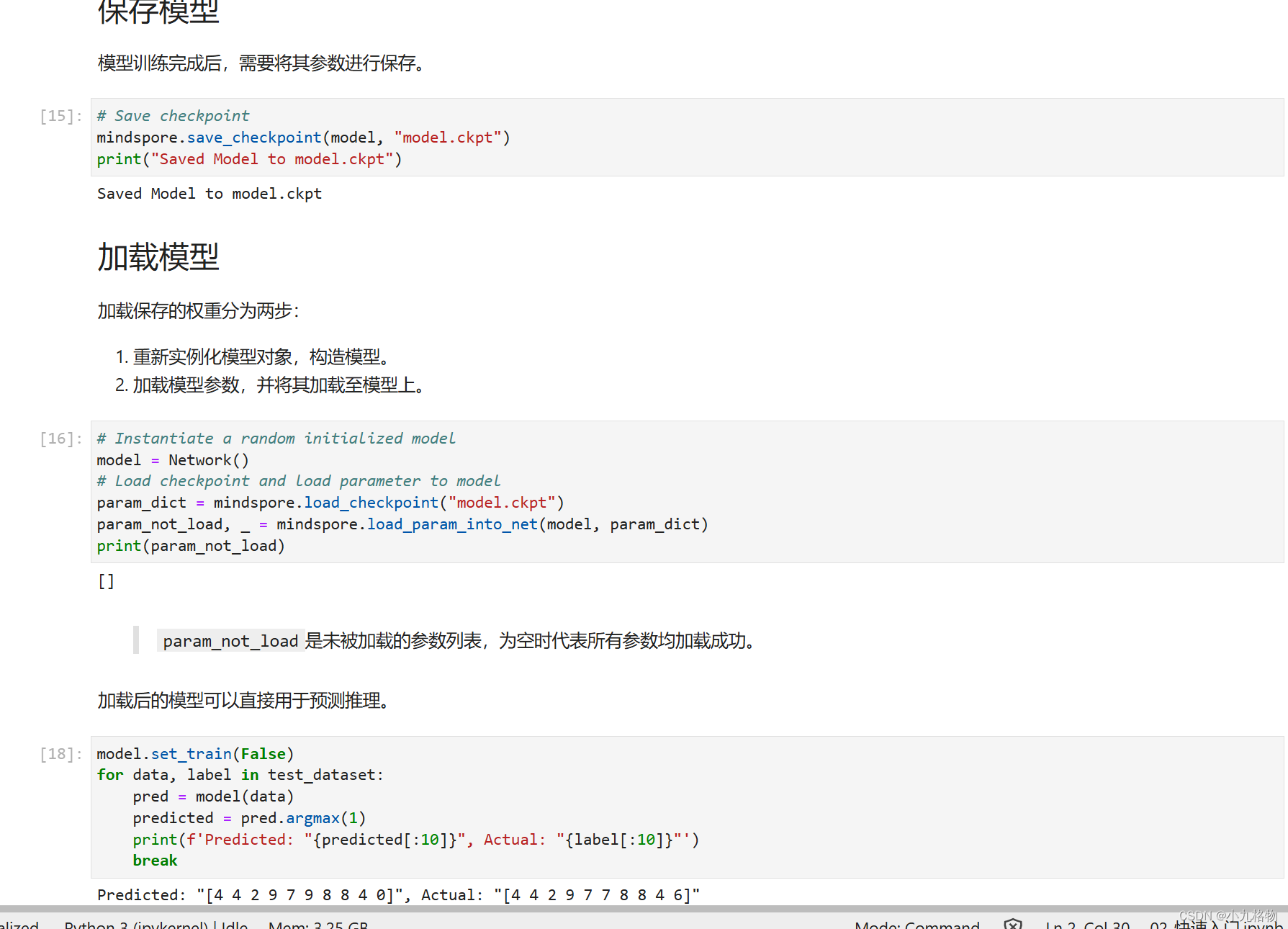
昇思25天学习打卡营第1天|基本介绍及快速入门
1.第一天学习总体复盘 1)成功注册昇思大模型平台,并成功申请算力; 2)在jupyter环境下学习初学入门/初学教程的内容; 在基本介绍部分,快速撸了一边内容,有了一个基本的了解(没理解到位的计划采用…...

C#.Net筑基-类型系统②常见类型
01、结构体类型Struct 结构体 struct 是一种用户自定义的值类型,常用于定义一些简单(轻量)的数据结构。对于一些局部使用的数据结构,优先使用结构体,效率要高很多。 可以有构造函数,也可以没有。因此初始…...

【人机交互 复习】第5章 交互式系统的需求
产品特性和用户个体差异引起的不同需求。 一、产品特性 1.功能不同 (1)智能冰箱:应能够提示黄油已用完 (2)字处理器:系统应支持多种格式 2.物理条件不同 (1)移动设备运行的系统应尽…...
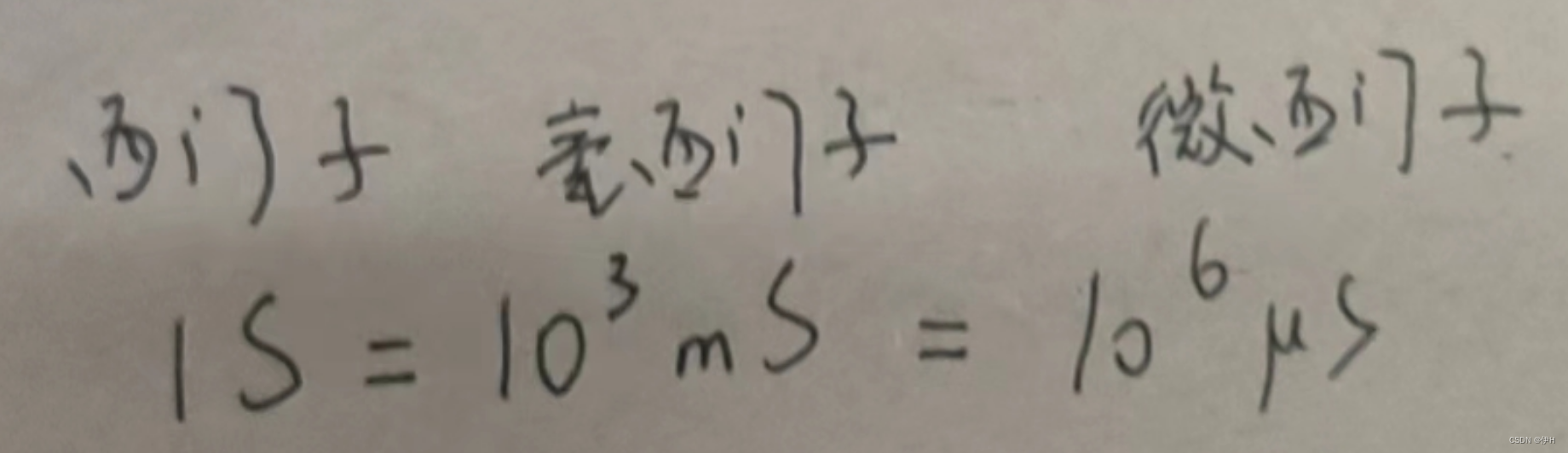
知识的补充
目录 电容和电感的基本性质 高频电路中电容与电感的等效电路 阻抗与导纳 常用单位转换 电容和电感的基本性质 电容C是两个平板比较直,i也比较直,C的 i 随 u 的变化率变化,i 的相位超前。 电感L是个线圈比较弯曲,u也比较弯&…...

微信小程序请求服务器报ERR_CONNECTION_RESET
排查思路 1.域名是否配置或跳过 2.域名是否备案 3.证书是否有效 4.服务器中间件配置证书是否生效 5.服务器中间件转发配置是否生效 6.接口是否正常 本人遇到问题描述,通过浏览器访问本人网站,https,get请求可以通,小程序wx…...

SpringMVC:拦截Mybatis的mapper
我们在使用mybatis的时候会碰到一些公共添加时间,操作人员,更新时间、或者一些分页这个使我们如果要去添加每个对应的- service - dao - mapper - xml 这样就造成很多冗余代码,那这个时候我们就需要使用一些通用方法,统一就行修改…...

MySQL查询性能优化解决方案
解决方案 主键与默认常用查询字段建立索引,普通字段类型选择 UNIQUE,索引方法 BTREE ;长文本使用 FULLTEXT,索引方法为无; 新建表时引擎默认设置为 MyISAM,不使用 InnoDB,因为 MyISAM 支持 MAT…...

系统安全(补充)
拒绝服务漏洞(拒绝服务漏洞将导致网络设备停止服务,危害网络服务可用性)旁路(旁路漏洞绕过网络设备的安全机制,使得安全措施没有效果)代码执行(该类漏洞使得攻击者可以控制网络设备,…...
腾讯云[HiFlow】| 自动化 -------HiFlow:还在复制粘贴?
文章目录 前言:一:HiFlow是什么二:功能介绍1.全连接2.自动化2.1定时处理特定任务2.2实时同步变更信息2.3及时获取通知提醒 3.零代码4.多场景5.可信赖 三:用户体验最后 前言: 随着网络时代的不断发展,自动化…...
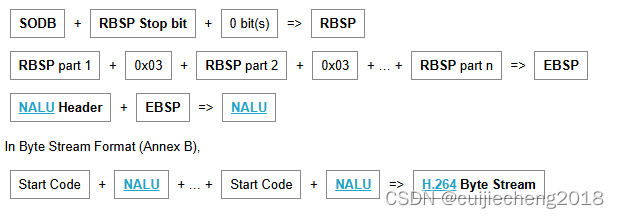
音视频入门基础:H.264专题(3)——EBSP, RBSP和SODB
音视频入门基础:H.264专题系列文章: 音视频入门基础:H.264专题(1)——H.264官方文档下载 音视频入门基础:H.264专题(2)——使用FFmpeg命令生成H.264裸流文件 音视频入门基础&…...

误删群晖NAS数据有什么找回的方法?
1、使用群晖 NAS 自带的备份功能:如果您之前启用了群晖的备份计划,例如 Hyper Backup 或 Snapshot Replication,您可以从备份中恢复数据。 1.1、Hyper Backup 可以将数据备份到多种目的地,包括本地存储、外部硬盘、其他 NAS 设备等…...

【CRASH】freelist异常导致的异常地址访问
freelist异常导致的异常地址访问 问题现象初步分析继续深入新的发现沙盘推演寻找元凶分析代码后记 问题现象 项目一台设备几天内出现了两次crash,都是异常地址访问导致。 [66005.261660] BUG: unable to handle page fault for address: ffffff8881575110初步分析…...

【QT】C++ || 左值引用、右值引用、移动语义、完美转发
在C中,左右值引用是高级语言特性,用于更高效的内存和资源管理。了解左右值引用的概念对于编写高效的C代码非常重要。下面解释左右值引用的概念、用途和区别,并通过示例来说明它们的使用。 左值引用(Lvalue Reference)…...
【深度学习驱动流体力学】计算流体力学算例剖析与实现
目录 一.求解器分类汇总压缩性流动求解器(Compressible Flow Solvers):不可压缩流动求解器(Incompressible Flow Solvers):多相流动求解器(Multiphase Flow Solvers):热传递求解器(Heat Transfer Solvers):其他特殊求解器:其他常见求解器:求解器分类:二.求解器案…...
做特征重要性分析与亚组发现)
从预测到归因:手把手教你用因果森林(grf)做特征重要性分析与亚组发现
从预测到归因:手把手教你用因果森林(grf)做特征重要性分析与亚组发现 在金融风控、个性化营销和医疗疗效评估等领域,我们常常面临一个关键问题:干预措施的效果是否存在显著差异?传统分析方法如A/B测试能告诉…...

像素剧本圣殿部署指南:Qwen2.5-14B-Instruct在生产环境中稳定运行的GPU显存优化技巧
像素剧本圣殿部署指南:Qwen2.5-14B-Instruct在生产环境中稳定运行的GPU显存优化技巧 1. 项目概述 像素剧本圣殿(Pixel Script Temple)是一款基于Qwen2.5-14B-Instruct大模型深度微调的专业剧本创作工具。它将先进的AI推理能力与独特的8-Bit…...

CLIP 实战宝典:从零开始掌握文本与图像编码的终极技巧
1. CLIP模型基础入门:图文匹配的魔法钥匙 第一次听说CLIP模型时,我正被一个图像搜索项目折磨得焦头烂额。传统方法需要先标注海量数据,再训练复杂的分类器,整个过程就像用算盘计算火箭轨道。直到遇见CLIP,才发现原来图…...

ShardingSphere-Proxy 5.2 容器化部署与开发调试实战指南
1. 为什么选择ShardingSphere-Proxy 5.2作为开发调试工具 在分库分表场景下开发应用时,最让人头疼的就是数据查询和调试问题。想象一下,你的订单数据被分散在4个库的8张表中,每次测试时想确认数据是否正确写入,都得手动连接不同数…...

3D打印雕塑与玻璃钢雕塑的区别、工艺详解及定制雕塑相关疑问解答
3D打印雕塑与玻璃钢雕塑的区别、工艺详解及定制雕塑相关疑问解答3D打印雕塑与玻璃钢雕塑是当代主流雕塑工艺,核心差异在于成型逻辑与材料特性:3D打印以数字化建模为核心,遵循“分层叠加”的增材逻辑;玻璃钢以复合材料为基础&#…...

门店小程序和收银系统有什么区别?
门店小程序和收银系统有什么区别?在门店数字化过程中,很多企业会同时接触到小程序与收银系统,但两者在功能定位和使用场景上存在明显差异。门店小程序和收银系统的本质区别,在于一个偏向“获客与转化入口”,一个偏向“…...

快速验证openclaw:用快马AI一键生成安装脚本与抓取原型
最近在做一个机器人抓取相关的项目,偶然发现了openclaw这个开源工具。作为一个Python实现的轻量级抓取框架,它很适合快速搭建原型。不过在实际使用过程中,我发现它的安装和配置过程有点繁琐,特别是对新手不太友好。于是尝试用InsC…...

VMware 虚拟机 Kali Linux 光标消失?五步实操攻略轻松找回
在 VMware Workstation Pro 中运行 Kali Linux 时,不少用户会遇到 “光标隐形” 的棘手问题 —— 系统可正常操作,但光标一进入虚拟机窗口就消失。这一现象多由硬件兼容性、驱动配置或增强工具缺失导致,并非硬件故障。本文整合社区实测有效方…...

Karp的21个NPC问题:从理论到实践的经典探索
1. Karp与NPC问题的历史背景 1971年,Stephen Cook在论文《The Complexity of Theorem Proving Procedures》中首次提出了NP完全性的概念,并证明了布尔可满足性问题(SAT)属于NP完全问题。这一突破性工作为计算复杂性理论奠定了基石…...

CodeBlocks高效开发环境配置指南:从字体优化到智能编码
1. CodeBlocks开发环境基础配置 刚接触CodeBlocks时,我经常被默认的界面和功能搞得头晕眼花。经过多年实战,我发现合理的初始配置能让开发效率提升至少50%。我们先从最基础的视觉优化开始。 字体设置是影响编码舒适度的首要因素。默认的字体大小在1080p屏…...