MYSQL 四、mysql进阶 4(索引的数据结构)
一、为什么使用索引 以及 索引的优缺点
1.为什么使用索引
索引是存储引擎用于快速找到数据记录的一种数据结构,就好比一本教科书的目录部分,通过目录中找到对应文章的页码,便可快速定位到需要的文章。Mysql中也是一样的道理,进行数据查找时,首先查看查询条件是否命中某条索引,符合则通过索引查找相关数据,如果不符合则需要全表扫描,即需要一条一条的查找记录,直到找到与条件符合的记录。
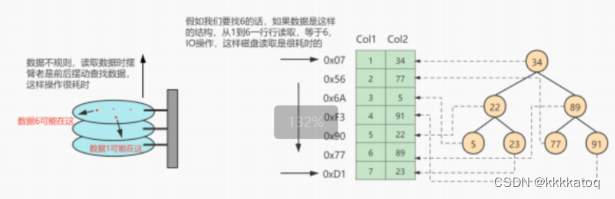
如上图所示,数据库没有索引的情况下,数据 分布在硬盘的不同位置上面,读取数据时,摆臂需要前后摆动查找数据,这样操作非常消耗时间,如果数据顺序摆放,那么也需要从1到6行安顺序读取,这样就相当于进行了6次IO操作,依旧非常耗时,如果我们不借助任何索引结构帮助我们快速定位数据的话,我们查找 Col 2 = 89 这条记录,就要逐行去查找,去比较。从Col 2 = 34 开始 ,进行比较,发现不是,继续下一行。我们当前的表只有不到10行数据,但是如果表很大的话,有上千万条数据。就意味着要做 非常多次磁盘IO 才能找到。现在要查找Col 2 = 89这条记录,CPU 必须先去磁盘查找这条记录,找到之后加载到内存,在对数据进行处理,这个过程最耗时间的就是磁盘IO (涉及到磁盘的旋转时间 (速度较快),磁头的寻道时间速度慢、耗时)。
假如给数据使用 二叉树 这样的数据结构进行存储,如下图所示:
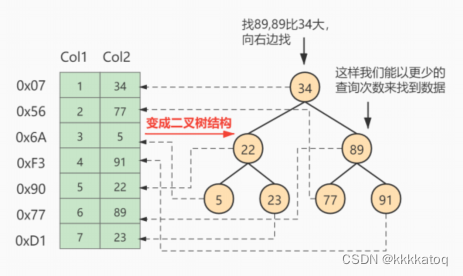
对字段Col 2 添加了索引,就相当于在硬盘上为Col 2维护了一个索引的数据结构,即这个 二叉搜索树,二叉搜索树的每个节点存储的是(k,v)结构,value是该key所在行的文件指针(地址)。比如,该二叉搜索树的根节点就是:(34,0x07)。现在对col 2添加了索引。这时再去查找Col 2 = 89这条记录的时候会先去查找该二叉搜索树(二叉树的遍历查找)。读34到内存,89 》 34;继续右侧数据,读89到内存,89 == 89;找到数据返回。找到之后就根据当前结点的vaiue快速定位到要查找的记录对应的地址,我们可以发现,只需要查找两次就可以定位到记录的地址,查询速度就提高了。
这就是我们为什么要建索引,目的就是为了减少磁盘IO的次数,加快查询速率。
2.索引的优缺点
2.1 索引概述
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
索引的本质:索引是数据结构。你可以简单理解为“排好序的快速查找数据结构”,满足特定查找算法。这些数据结构以某种方式指向数据, 这样就可以在这些数据结构的基础上实现 高级查找算法 。
索引是在存储引擎中实现的,因此每种存储引擎的索引不一定完全相同,并且每种存储引擎并不一定支持所有索引类型,同时,存储引擎可以定义每个表的最大索引数 和 最大索引长度。所有存储引擎支持每个表至少16个索引,总索引长度至少为256字节。有些存储引擎支持更多的索引数和更大的索引长度。
(1)类似大学图书馆建书目索引,提高数据检索的效率,降低 数据库的 IO 成本 ,这也是创建索引最主要的原因。
增加索引也有许多不利的方面,主要表现在如下几个方面:
(3)虽然索引大大提高了查询速度,同时却会 降低更新表的速度 。当对表中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度。
因此,选择使用索引时,需要综合考虑索引的优点和缺点。
索引可以提高查询的速度,但是会影响插入记录的速度,这种情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成后再创建索引。
二、InnoDB中索引的推演
2.1 索引之前的查找
先来看一个精确匹配的例子:
SELECT [列名列表] FROM 表名 WHERE 列名 = xxx;
1). 在一个页中的查找
假设目前表中的记录比较少,所有的记录都可以被存放到一个野种,在查找记录的时候可以根据搜索条件的不同分为两种情况。
- 以主键为搜索条件:
可以在页目录中使用 二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。 - 以其他列作为搜索条件:
因为在数据页中并没有对非主键列建立所谓的页目录,所以我们无法通过二分法快速定位相应的槽,这种情况下只能从最小记录开始依次遍历单链表中的每条记录,然后对比每条记录是不是符合搜索条件,很显然,这种查找的效率是非常低的。
· 2). 在很多页中查找
大部分情况下我们表中存放的记录都是非常多的,需要好多的数据页来存储这些记录。在很多页中查找记录的话可以分为两个步骤:
- 定位到记录所在页
- 从所在页内中查找相应的记录
在没有索引的情况下,不论是根据主键列或者其他列的值进行查找,由于我们并不能快速的定位到记录所在的页,所以只能 从第一个页 沿着 双向链表 一直往下找,在每一个页中根据我们上面的查找方式去查找指定的记录。因为要遍历所有的数据页,所以这种方式显然是 超级耗时 的。如果一个表有一亿条记录呢?此时 索引 应运而生。
2.2 设计索引
建一个表:
mysql> CREATE TABLE index_demo(-> c1 INT ,-> c2 INT ,-> c3 CHAR ( 1 ),-> PRIMARY KEY (c1)-> ) ROW_FORMAT = Compact;
这个新建的 index_demo 表中有2个INT类型的列,1个CHAR(1)类型的列,而且我们规定了c1列为主键,
这个表使用 Compact 行格式来实际存储记录的。Compact 行格式,主要是用来记录存储的这一条记录。比如说添加了两条记录,我们添加两条记录的格式称作为行格式或者称作记录格式。后面会详细讲。
这里我们简化了index_demo表的行格式示意图:
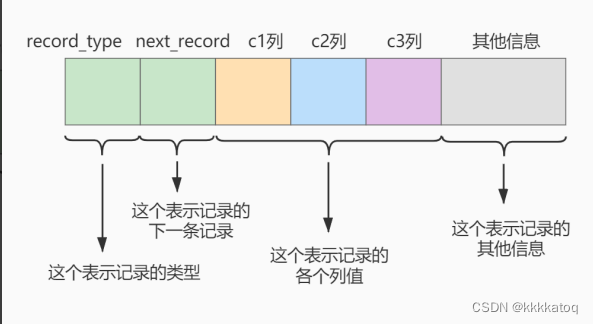
- record_type :记录头信息的一项属性,表示记录的类型, 0 表示普通记录、 2 表示最小记 录、 3 表示最大记录、 1 暂时还没用过,下面讲。
- next_record :记录头信息的一项属性,表示下一条地址相对于本条记录的地址偏移量,我们用 箭头来表明下一条记录是谁。
- 各个列的值 :这里只记录在 index_demo 表中的三个列,分别是 c1 、 c2 和 c3 。
- 其他信息 :除了上述3种信息以外的所有信息,包括其他隐藏列的值以及记录的额外信息。
将记录格式示意图的其他信息项暂时去掉并把它竖起来的效果就是这样:
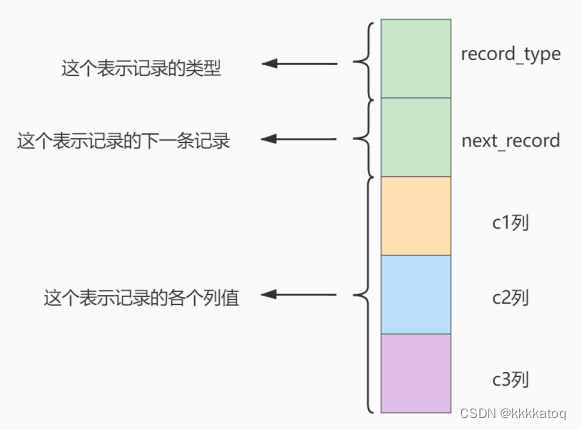
把一些记录放到页里的示意图就是:
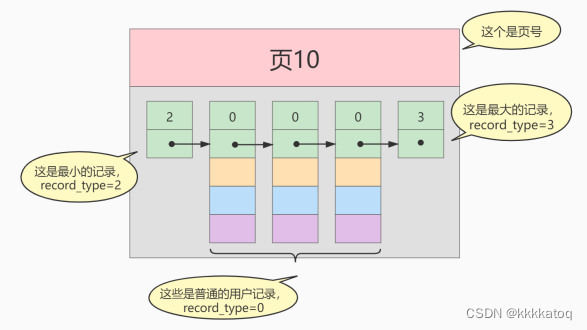
这就是基本的数据页的模型。
1. 一个简单的索引设计方案
我们在根据某个搜索条件查找一些记录时为什么要遍历所有的数据页呢?因为各个页中的记录并没有规律,我们并不知道我们的搜索条件匹配哪些页中的记录,所以不得不依次遍历所有的数据页。所以如果我们 想快速的定位到需要查找的记录在哪些数据页 中该咋办?我们可以为快速定位记录所在的数据页而 建立一个目录 ,建这个目录必须完成下边这些事:
- 下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值。
假设:每个数据页做多能存放三条记录(实际上一个数据页非常大,可以存放下好多记录)。有了这个假设之后我们向 index_demo表中插入3条记录:
INSERT INTO index_demo values (1,4,'u'),(3,9,'d'),(5,3,'y');
那么这些记录已经按照主键值的大小串联成一个单项链表了,如图所示:
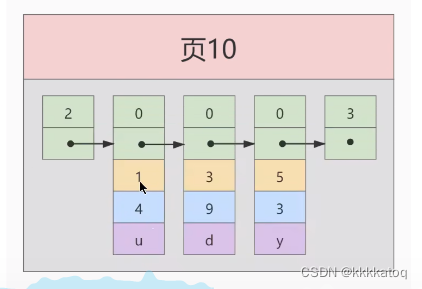
从图中可以看出来,index_demo表中的3条记录都被插入到了编号为 10 的数据页中了,此时我们再来插入一条记录:
INSERT INTO index_demo values (4,4,'a');
因为页10最多只能放3条记录,所以我们不得不再分配一个新页:
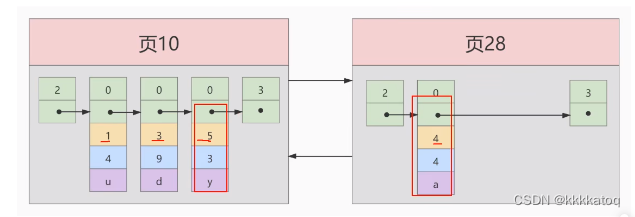
注意:新分配的 数据页编号 可能不是连续的,他们只是通过维护着上一页和下一个页的编号而建立了链表关系,另外,页10中用户记录最大的主键值是 6 ,而 页28中有一条记录的主键值是 4,因为 5>4 ,所以这就不符合下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值的要求,所以再插入主键值为4的记录的时候需要伴随着一次记录移动,也就是把主键值为 5 的记录移动到页 28中,然后再把主键值为 4 的记录插入到页10中,这个过程的示意图如下:
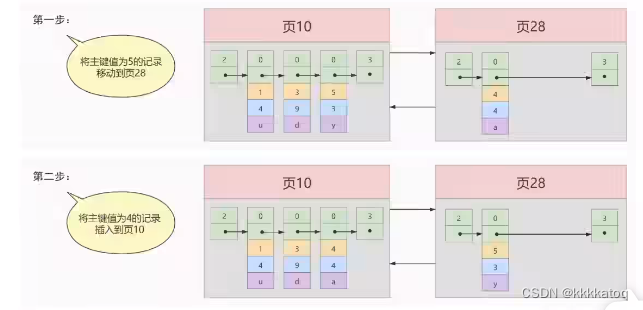
这个过程表明了再对页中的记录进行增删改操作的过程中,我们必须通过一些诸如记录移动的操作来始终保证这个状态一直成立,下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值,这个过程我们成为 页分类。
- 给所有的页建立一个目录项。
由于数据页的 编号可能是不连续的,所以在向 index_demo表中插入许多记录后,可能是这样的效果:

因为这些16Kb的页在 物理存储上是不连续的,所以如果想从这么多页中根据主键值 快速定位某些记录所在值页,我们需要给他们做个 目录,每个目录包括下边两个部分:
- 页的用户记录中最小的主键值,我们用key来表示
- 页号,我们用page_no表示
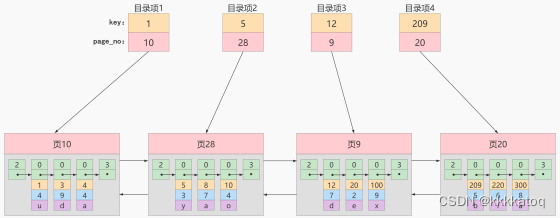
至此,针对数据页做的简易目录就搞定了。这个目录有一个别名,称为 索引 。
① 迭代1次:目录项纪录的页
- InnoDB是使用页来作为管理存储空间的基本单位,很多能保证16kb的连续存储空间,而随着表中记录数量的增多,需要非常大的连续的存储空间 才能把所有的目录都放下,这对记录数量非常多的表是不现实的。
- 我们时长会对记录进行增删,假设我们把 页28 中的记录都删除了,那意味着 目录项2 也就没有存在的必要了,这就需要把目录项2后的目录项都向前移动一下,这样牵一发而动全身的操作效率很差。
- 0:普通的用户记录
- 1:目录项记录
- 2:最小记录
- 3:最大记录

- 目录项记录 的 record_type 值是1,而 普通用户记录 的 record_type 值是0。
- 目录项记录只有 主键值和页的编号 两个列,而普通的用户记录的列是用户自己定义的,可能包含 很 多列 ,另外还有InnoDB自己添加的隐藏列。
- 了解:记录头信息里还有一个叫 min_rec_mask 的属性,只有在存储 目录项记录 的页中的主键值 最小的 目录项记录 的 min_rec_mask 值为 1 ,其他别的记录的 min_rec_mask 值都是 0 。
相同点:两者用的是一样的数据页,都会为主键值生成 Page Directory (页目录),从而在按照主键值进行查找时可以使用 二分法 来加快查询速度。
现在以查找主键为 20 的记录为例,根据某个主键值去查找记录的步骤就可以大致拆分成下边两步:
- 1. 先到存储 目录项记录 的页,也就是页30中通过 二分法 快速定位到对应目录项,因为 12 < 20 < 209 ,所以定位到对应的记录所在的页就是页9。
- 2. 再到存储用户记录的页9中根据 二分法 快速定位到主键值为 20 的用户记录。
② 迭代2次:多个目录项纪录的页
虽然说 目录项记录 中只存储主键和对应的页号,比如用户记录需要的存储空间小多了,但是不论怎么说一个页只有16kb 大小,能存放的目录项记录也是有限的,那如果表中的数据太多,以至于一个数据页不足以存放所有的 目录项记录,如何处理呢?
这里我们假设一个存储在目录项记录的页 最多只能存放4条目录项记录,所以如果此时我们再向上图插入一条主键值为 320 的用户记录的话,那就需要分配一个新的存储目录项记录的页:
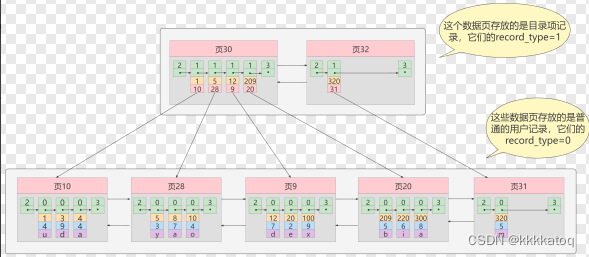
从图中可以看出,我们插入了一条主键值为320的用户记录之后需要两个新的数据页:
- 为存储该用户记录而新生成了 页31 。
- 因为原先存储目录项记录的 页30的容量已满 (我们前边假设只能存储4条目录项记录),所以不得不需要一个新的 页32 来存放 页31 对应的目录项。
1. 确定 目录项记录页
③ 迭代3次:目录项记录页的目录页
问题来了,在这个查询步骤的第一步中跟我们需要定位存储目录项记录的页,但是这些页不是连续的,如果我们表中的数据非常多则会产生很多存储目录项记录的页,那我们怎么根据主键值快速定位一个存储目录项记录的页呢?那就为这些存储目录项记录的页在生成一个更高级的目录,就像是一个多级目录一样,大目录嵌套小目录,小目录里才是实际的数据,所以现在各个页的示意图就是这样子:
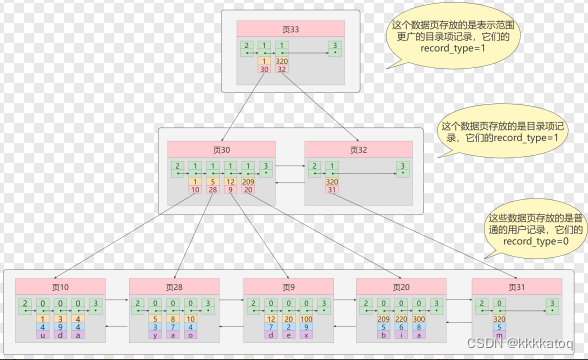
这个数据结构,它的名称是 B+树 。
④ B+Tree
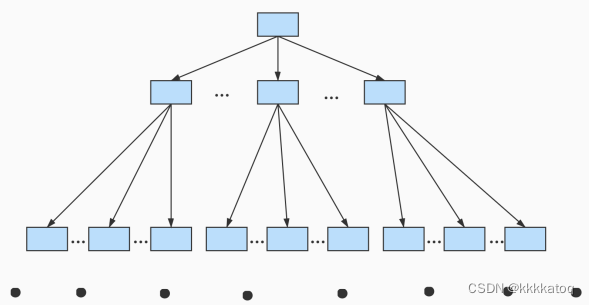
不论是存放用户记录的数据页,还是存放目录项记录的数据页,我们都把他们存放在B+树这个数据结构中了,所以我们也称这些数据页为节点。从图中可以看出,我们的实际用户记录其实都存放在B+树的最底层的节点上,这些节点也被称为叶子节点,其余用来存放目录项的节点称为 非叶子节点 或者内节点,其中B+树最上边的那个节点也成为根节点。
一个B+树的节点其实可以分成好多层,规定最下边的那层,也就是存放我们用户记录的那层为第 0 层,之后依次往上加。之前我们做了一个非常极端的假设:存放用户记录的页 最多存放3条记录 ,存放目录项记录的页 最多存放4条记录 。其实真实环境中一个页存放的记录数量是非常大的,假设所有存放用户记录的叶子节点代表的数据页可以存放 100条用户记录 ,所有存放目录项记录的内节点代表的数据页可以存放 1000条目录项记录 ,那么:
- 如果B+树只有1层,也就是只有1个用于存放用户记录的节点,最多能存放 100 条记录。如果B+树有2层,最多能存放 1000×100=10,0000 条记录。
- 如果B+树有3层,最多能存放 1000×1000×100=1,0000,0000 条记录。
- 如果B+树有4层,最多能存放 1000×1000×1000×100=1000,0000,0000 条记录。相当多的记录!!!
你的表里能存放 100000000000 条记录吗?所以一般情况下,我们 用到的B+树都不会超过4层 ,那我们通过主键值去查找某条记录最多只需要做4个页面内的查找(查找3个目录项页和一个用户记录页),又因为在每个页面内有所谓的 Page Directory (页目录),所以在页面内也可以通过 二分法 实现快速定位记录。
2.3 常见索引概念
索引按照物理实现方式,索引可以分为 2 种:聚簇(聚集)和非聚簇(非聚集)索引。我们也把非聚集索引称为二级索引或者辅助索引。
1. 聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式(所有的用户记录都存储在了叶子节点),也就是所谓的索引即数据,数据即索引。
术语 ”聚簇“ 表示数据行和相邻的键值聚簇的存储在一起。
特点:
1. 使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义:
- 页内 的记录是按照主键的大小顺序排成一个 单向链表 。
- 各个存放 用户记录的页 也是根据页中用户记录的主键大小顺序排成一个 双向链表 。
- 存放 目录项记录的页 分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个 双向链表 。
- 数据访问更快 ,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非 聚簇索引更快
- 聚簇索引对于主键的 排序查找 和 范围查找 速度非常快
- 按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不用从多个数据块中提取数据,所以 节省了大量的io操作 。
- 插入速度严重依赖于插入顺序 ,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键
- 更新主键的代价很高 ,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新
- 二级索引访问需要两次索引查找 ,第一次找到主键值,第二次根据主键值找到行数据
- 对于Mysql数据库目前只有InnoDB数据引擎支持聚簇索引,而MyISAM 并不支持聚簇索引。
- 由于数据物理存储排序方式只有一种,所以每个Mysql的表只能有一个聚簇索引,一般情况下就是该表的主键。
- 为了充分利用聚簇索引的聚簇特性,InnoDB表的主键尽量选用有序的数据id,而不建议用无序的id,比如UUID,MD5,hash,字符串列作为主键无法保证数据的顺序增长。
2. 二级索引(辅助索引、非聚簇索引)
上面介绍的 聚簇索引 只能在搜索条件是 主键值 时才能发挥作用,因为 B+树中的数据都是按照主键进行排序的。那如果我们想以别的列作为搜索条件该怎么办呢?肯定不是从头到尾沿着链表一次遍历记录一遍。
我们可以多建几棵B+树,不同的B+树中的数据采用不同的排序规则,比如说我们用 c2 列的大小作为数据页,页中记录的排序规则,再建一颗B+树,效果如下图所示:

这个叶子节点中存储的不再是完整的数据了,而是c2字段的值和这条记录中c1字段的值。
这个B+树与上边介绍的聚簇索引有几处不同:
- 使用记录c2列的大小进行记录和页的排序,这包括三个方面的含义:
- 页内的记录是按照c2列的大小顺序排成一个单向链表。
- 各个存档用户记录的页也是根据页中记录的c2列大小顺序排成一个双向链表。
- 存放 目录项记录的页 分为不同的层次,在同一层次中的页也是根据页中目录项记录的c2列大小顺序排成一个双线链表。
- B+树的叶子节点存储的并不是完整的用户记录,而只是c2列 + 主键这两个列的值。
- 目录项记录中不再是 主键 + 页号 的搭配,而变成了c2列 + 页号的搭配。
所以如果哦我们现在想通过c2列的值查找某些记录的话,就可以使用我们刚刚剑豪的这个B+树了,以查找c2列的值为4的记录为例,查找过程如下:
确定目录项记录页:
根据 根页面 ,也就是页44,可以快速定位到 目录项记录 所在的页为 页42(因为2<4<9)。
通过目录项记录页确定用户记录真实所在的页:
在页42中可以快速定位到实际存储用户记录的页,但是由于c2列并没有唯一性约束,所以c2列值为4的记录可能分布在多个数据页中,有因为2<4<=4,所以确定实际存储用户记录的页在 页34 和 页 35中。
在真实存储用户记录的页中定位到具体的记录:
到页34和页35中定位到具体的记录。
但是这个B+树的叶子节点中的记录只存储了c2 和 c1 (也就是主键)两个列,所以我们必须再根据主键值去聚簇索引中在查找一遍完整的用户记录。
概念:回表 我们根据这个以c2列大小排序的B+树只能确定我们要查找记录的主键值,所以如果我们想根据c2列的值查找到完整的用户记录的话,仍然需要到 聚簇索引 中再查一遍,这个过程称为 回表 。也就是根据c2列的值查询一条完整的用户记录需要使用到 2 棵B+树!
问题:为什么我们还需要一次 回表 操作呢?直接把完整的用户记录放到叶子节点不OK吗?
如果把完整的用户记录放到叶子节点中是可以不用回表,但是太占地方了,相当于每建立一颗B+树都需要把所有的用户记录再拷贝一遍,这就有点太浪费存储空间了。
因为这种按照 非主键列 建立的B+树需要一次回表操作才可以定位到完整的用户记录,所以这种B+树也被称为二级索引,或者辅助索引,由于我们使用的是c2列的大小作为B+树的排序规则,所以我们也称为这个B+树是为c2列建立的索引。
非聚簇索引的存在不影响数据在聚簇索引中的组织,所以一张表可以有多个非聚簇索引。
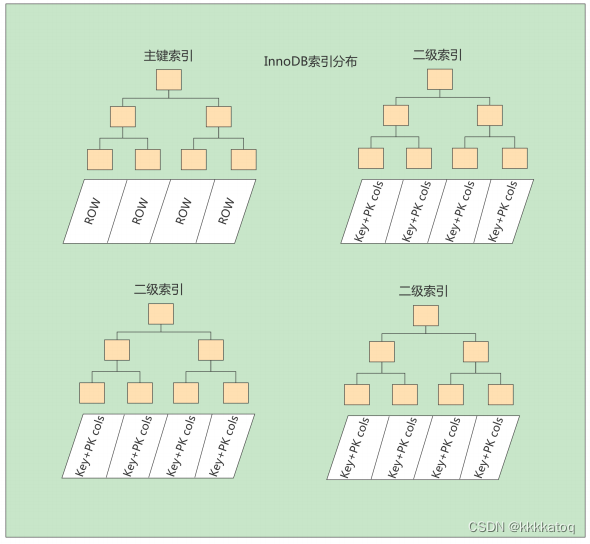
小结:聚簇索引与非聚簇索引的原理不同,在使用上也有一些区别:
1 聚簇索引的叶子节点存储的就是我们的数据记录,非聚簇索引的叶子节点存储的是 数据位置,非聚簇索引不会影响数据表的物理存储顺序。
2 一个表 只能有一个聚簇索引,因为只能有一种排序存储的方式,但可以有多个非聚簇索引,也就是多个索引目录提供数据检索。
3 使用聚簇索引的时候,数据的查询效率高,但是如果对数据进行插入,删除,更新等操作,效率会比非聚簇索引低。
3. 联合索引
我们也可以同时以多个列的大小作为排序规则,也就是同时为多个列建立索引,比方说我们想让B+树按照 c2和c3列 的大小进行排序,这个包含两层含义:
- 先把各个记录和页按照c2列进行排序。
- 在记录的c2列相同的情况下,采用c3列进行排序
为 c2 和 c3 列建立的索引示意图如下: 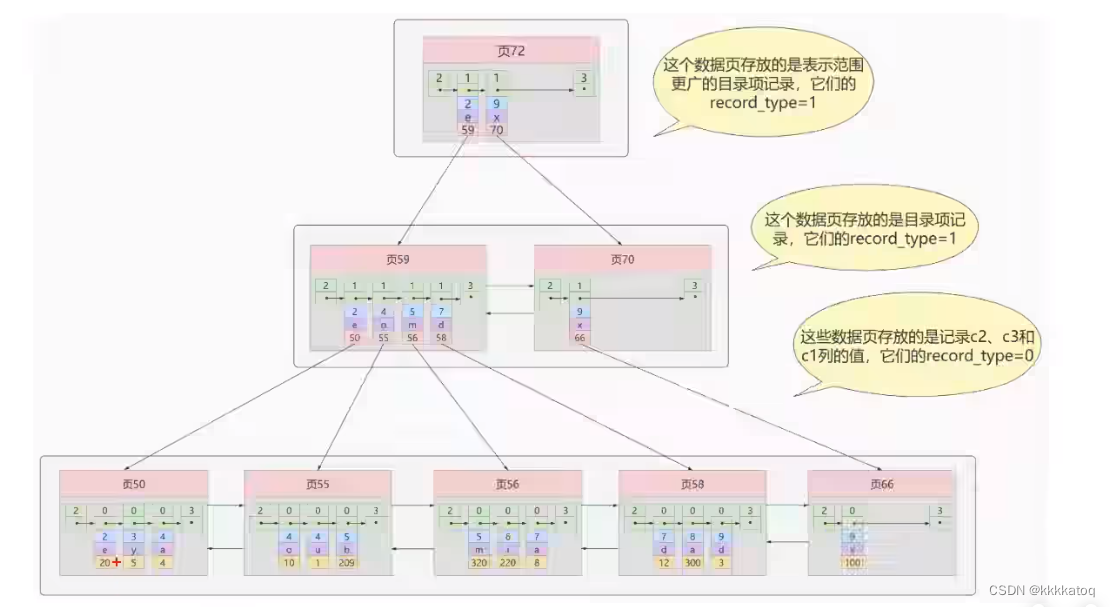 如图所示,我们需要注意以下几点:
如图所示,我们需要注意以下几点:
- 每条目录项记录都有c2、c3页号这三部分组成,各条记录先按照c2列的值进行排序,如果记录的c2相同,则按照c3列的值进行排序。
- B+树叶子节点处的用户记录有c2、c3和主键c1列组成。
- 建立 联合索引 只会建立如上图一样的1棵B+树。
- 为c2和c3列分别建立索引会分别以c2和c3列的大小为排序规则建立2棵
3.4 InnoDB的B+树索引的注意事项
1. 根页面位置万年不动
实际上B+树的形成过程是这样的:
- 每当为某个表创建一个b+树索引(聚簇索引不是人为创建的,默认就有)的时候,都会为这个索引创建一个 根节点 页面,最开始表中没有数据的时候,每个b+树索引对应的根节点中既没有用户记录,也没有目录项记录。
- 随后向表中插入用户记录时,先把用户记录存储到这个根节点中
- 当根节点中的可用空间用完时继续插入记录,此时会将根节点中的所有记录复制到一个新分配的页,比如页a中,然后对这个新页进行 页分裂的操作,得到另一个新页,比如 页b,这时新插入的记录根据键值(也就是聚簇索引中的主键值,二级索引中对应的索引列的值)的大小就会被分配到 页a或页b中,而根节点便升级为存储目录项记录的页。
这个过程特别注意的是:一个B+树索引的根节点自诞生之日起,便不会再移动,这样只要我们对某个表建立一个索引,那么它的根节点的页号便会被记录到某个地方,然后凡是InnoDB存储引擎需要用到这个索引的时候,都会从那个固定的地方取出根节点的页号,从而来访问这个索引。
2. 内节点中目录项记录的唯一性
我们知道B+树索引的内节点中目录项记录的内容是 索引列+页号 的搭配,但是这个搭配对于二级索引来说有点不严谨,还拿 index_demo表为例,假设这个表中的数据是这样的:
3. 一个页面最少存储2条记录
相关文章:
MYSQL 四、mysql进阶 4(索引的数据结构)
一、为什么使用索引 以及 索引的优缺点 1.为什么使用索引 索引是存储引擎用于快速找到数据记录的一种数据结构,就好比一本教科书的目录部分,通过目录中找到对应文章的页码,便可快速定位到需要的文章。Mysql中也是一样的道理,进行数…...
360vr党建线上主题展立体化呈现企业的文化理念和品牌形象
在现代科技的引领下,艺术与VR虚拟现实技术相融合必将成为趋势,深圳VR公司华锐视点荣幸地推出VR艺术品虚拟展厅,为您带来前所未有的艺术观赏体验。体验者足不出户即可置身于一个充满创意与灵感的虚拟艺术空间。 我们深入了解每一位客户的需求与…...
docker通过容器id查看运行命令;Portainer监控管理docker容器
1、docker通过容器id查看运行命令 参考:https://blog.csdn.net/a772304419/article/details/138732138 docker inspect 运行镜像id“Cmd”: [ “–model”, “/qwen-7b”, “–port”, “10860”, “–max-model-len”, “4096”, “–trust-remote-code”, “–t…...
XMind 2024软件最新版下载及详细安装教程
人所共知的是XMind 在公司和教育领域都有很广泛的应用,在公司中它能够用来进行会议管理、项目管理、信息管理、计划和XMind 被认为是一种新一代演示软件的模式。也就是说XMind不仅能够绘制思维导图,还能够绘制鱼骨图、二维图、树形图、逻辑图、组织结构…...

代码随想录算法训练营第四十四天 | 322. 零钱兑换、279.完全平方数、139.单词拆分、多重背包理论基础、背包问题总结
322. 零钱兑换 题目链接:https://leetcode.cn/problems/coin-change/ 文档讲解:https://programmercarl.com/0322.%E9%9B%B6%E9%92%B1%E5%85%91%E6%8D%A2.html 视频讲解:https://www.bilibili.com/video/BV14K411R7yv/ 思路 确定dp数组以及下…...
开源AGV调度系统OpenTCS中的路由器(router)详解
OpenTCS中的任务分派器router详解 1. 引言2. 路由器(router)2.1 代价计算函数(Cost functions)2.2 2.1 Routing groups2.1 默认的停车位置选择2.2 可选停车位置属性2.3 默认的充电位置选择2.4 即时运输订单分配 3. 默认任务分派器的配置项4. 参考资料与源…...

关于下载 IDEA、WebStorm 的一些心得感想
背景 实习第一天的时候,睿哥便吩咐我下载一些软件,这些软件以后在写项目的时候会用到,他叫我先装IDEA,WebStorm,微信开发者工具,git,还有Navicat。 这些软件能够被我们正常使用,无非就通过三步…...
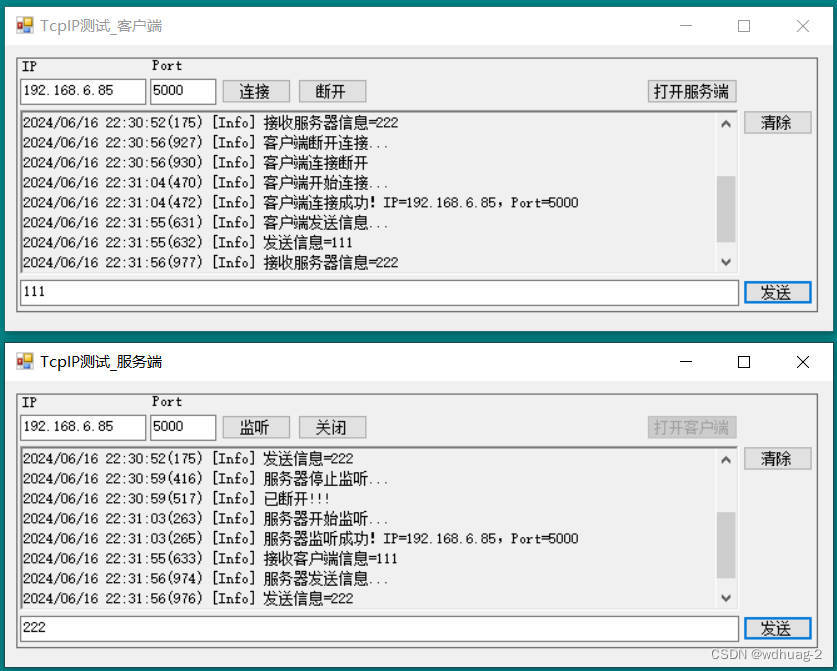
C#使用Scoket实现服务器和客户端互发信息
20240616 By wdhuag 目录 前言: 参考: 一、服务器端: 1、服务器端口绑定: 2、服务器关闭: 二、客户端: 1、客户端连接: 2、客户端断开: 三、通讯: 1、接收信…...

【经验分享】SpringCloud + MyBatis Plus 配置 MySQL,TDengine 双数据源
概述 因为项目中采集工厂中的设备码点的数据量比较大,需要集成TDengine时序数据库,所以需要设置双数据源 操作步骤 导入依赖 <!-- 多数据源支持 --><dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-s…...

Pycharm 忽略文件
安装 .ignore插件 规则示例 罗列一些常遇到.getignore忽略规则的使用示例: 1. 在已忽略文件夹中不忽略指定文件夹: /libs/* !/libs/extend/ 2. 在已忽略文件夹中不忽略指定文件 /libs/* !/libs/extend/fastjson.jar 3.只忽略libs目录…...
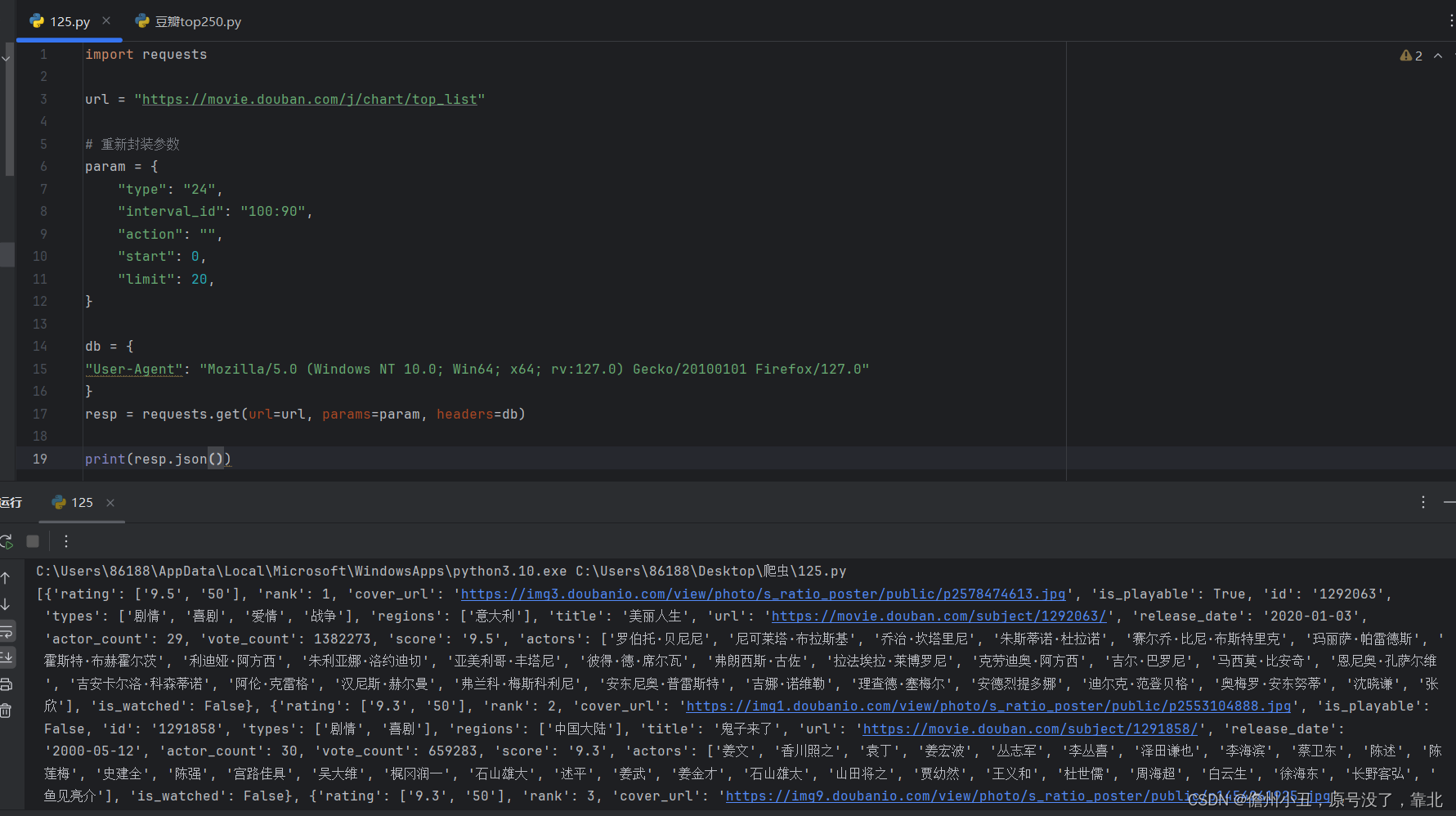
爬虫学习。。。。
爬虫的概念: 爬虫是一种自动化信息采集程序或脚本,用于从互联网上抓取信息。 它通过模拟浏览器请求站点的行为,获取资源后分析并提取有用数据,这些数据可以是HTML代码、JSON数据或二进制数据(如图片、视频)…...

美国铁路客运巨头Amtrak泄漏旅客数据,数据销毁 硬盘销毁 文件销毁
旅客的Guest Rewards常旅客积分账户的个人信息被大量窃取。 美国国家客运铁路公司(Amtrak)近日披露了一起数据泄露事件,旅客的Guest Rewards常旅客积分账户的个人信息被大量窃取。 根据Amtrak向马萨诸塞州提交的泄露通知,5月15日…...
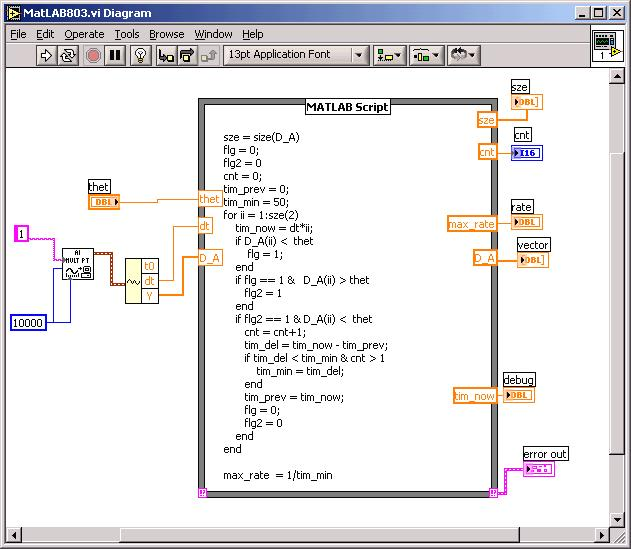
LabVIEW与Matlab联合编程的途径及比较
LabVIEW和Matlab联合编程可以通过多种途径实现,包括调用Matlab脚本节点、使用LabVIEW MathScript RT模块、利用ActiveX和COM接口,以及通过文件读写实现数据交换。每种方法都有其独特的优势和适用场景。本文将详细比较这些方法,帮助开发者…...
秋招突击——6/16——复习{(单调队列优化DP)——最大子序和,背包模型——宠物小精灵收服问题}——新作{二叉树的后序遍历}
文章目录 引言复习(单调队列优化DP)——最大子序和单调队列的基本实现思路——求可移动窗口中的最值总结 背包模型——宠物小精灵收服问题思路分析参考思路分析 新作二叉树的后续遍历加指针调换 总结 引言 复习 (单调队列优化DP)…...
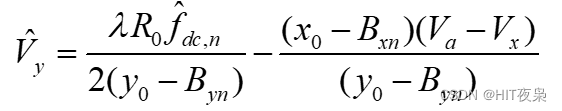
SAR动目标检测系列:【4】动目标二维速度估计
在三大类杂波抑制技术(ATI、DPCA和STAP)中,STAP技术利用杂波与动目标在二维空时谱的差异,以信噪比最优为准则,对地杂波抑制的同时有效保留动目标后向散射能量,有效提高运动目标的检测概率和动目标信号输出信杂比,提供理…...
JavaEE多线程(2)
文章目录 1..多线程的安全1.1出现多线程不安全的原因1.2解决多线程不安全的⽅法1.3三种典型死锁场景1.4如何避免死锁问题2.线程等待通知机制2.1等待通知的作用2.2等待通知的方法——wait2.3唤醒wait的方法——notify 1…多线程的安全 1.1出现多线程不安全的原因 线程在系统中…...

中新赛克两款数据安全产品成功获得“可信数安”评估测试证书
6月19日,2024数据智能大会在北京盛大召开。 会上,中国2024年上半年度“可信数安”评估测试证书正式颁发。中新赛克两款参评产品凭借过硬的技术水准和卓越的应用效果,成功获得专项测试证书。 2024年上半年度“可信数安”评估测试通过名单 中新…...

代码随想录——分割回文串(Leetcode 131)
题目链接 回溯 class Solution {List<List<String>> res new ArrayList<List<String>>();List<String> list new ArrayList<String>();public List<List<String>> partition(String s) {backtracking(s, 0);return res;}p…...

Rust 学习方法及学习路线汇总
Rust 学习方法及学习路线汇总 Rust 是一种系统编程语言,旨在提供安全性、并发性和高性能。它是由 Mozilla 公司开发的,于 2010 年首次发布。Rust 能够帮助开发者编写可靠和高效的软件,因此受到了广泛的关注和认可。 如果你有兴趣学习 Rust&…...

一名女DBA的感谢信,到底发生了什么?
昨日我们收到这样一通来电 “早上九点刚上班便收到业务投诉电话,系统卡顿,接口失败率大增,怀疑数据库问题。打开运维平台发现是国产库,生无可恋,第一次生产环境遇到国产库性能问题,没什么排查经验…...

一文看懂:什么是大语言模型
在过去很长一段时间里,计算机只是“执行命令的工具”。但这两年,一种新的技术正在改变这一切——它不仅能理解人类语言,还能写文章、写代码,甚至和你对话。从 ChatGPT 到 DeepSeek,再到 Claude 和 Gemini,“…...

基于MCP协议与本地全文检索的电子元件文档AI查询系统
1. 项目概述:为LLM构建一个本地化的电子元件文档搜索引擎如果你是一名嵌入式工程师、硬件开发者,或者像我一样,经常需要和德州仪器(TI)、意法半导体(ST)、亚德诺(ADI)这些…...

简化OpenAI API调用:轻量级封装库实践指南
1. 项目概述:一个极简的OpenAI API封装库 如果你正在开发一个需要集成AI能力的应用,比如一个聊天机器人、一个内容生成工具,或者一个代码助手,那么你大概率绕不开OpenAI的API。它的功能强大,文档也还算清晰࿰…...
)
从‘古董’到统一:聊聊Linux内核中buffer与cache合并背后的那些事儿(附free命令实战)
从‘古董’到统一:Linux内核中buffer与cache合并背后的设计哲学 在Linux系统的性能优化领域,free命令的输出一直是开发者关注的焦点。当你键入free -h时,那行看似简单的"buff/cache"统计背后,隐藏着一段跨越二十年的内…...

别再死记硬背了!用Wireshark抓包实战,5分钟搞懂IP报文每个字段
用Wireshark解密IP协议:从抓包实战到网络诊断的完全指南 当你第一次打开网络教材看到IP报文那密密麻麻的字段时,是否感觉像在解读外星密码?传统的学习方法让我们死记硬背"版本号4位、首部长度4位、服务类型8位...",但今…...

别再死记硬背了!用这3个真实网络场景,彻底搞懂华为ACL的配置逻辑
华为ACL实战指南:3个典型场景解锁访问控制精髓 每次看到新手工程师面对ACL配置时一脸茫然的样子,我就想起自己当年在机房通宵排错的经历。访问控制列表(ACL)作为网络安全的"门禁系统",其重要性不言而喻&…...

专业右键菜单管理:用ContextMenuManager一键重塑Windows操作效率
专业右键菜单管理:用ContextMenuManager一键重塑Windows操作效率 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 在Windows生态中,右键菜…...

UAssetGUI终极指南:深度解析虚幻引擎资源文件转换技术
UAssetGUI终极指南:深度解析虚幻引擎资源文件转换技术 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAssetGUI是…...

从科幻到现实:波色量子18.4亿融资背后,量子计算在多领域应用大突破!
【导语:科幻电影《流浪地球2》中智能量子计算机“MOSS”令人印象深刻,如今量子计算已从实验室走向商业化。波色量子成立三年获11轮融资共18.4亿,其量子计算在多领域展现出巨大应用潜力。】波色量子:资本竞逐中的宠儿按照“十五五规…...

131.详解YOLO损失函数+网格划分原理,附v1-v8演进脉络+YOLOv8实战代码
摘要 目标检测是计算机视觉的核心任务之一。YOLO(You Only Look Once)系列以其极致的检测速度与良好的精度平衡,成为工业界和学术界最广泛应用的检测框架。本文以理工科严谨逻辑,从YOLO的核心思想出发,覆盖从v1到v8的关键演进,并通过一个完整的可运行案例,带领读者从零…...