JAVA面试(六)
缓存
- Memcached
- redis
- Redis常见数据类型和使用
- Redis缓存持久化
- RDB-快照
- AOF-追加文件
- Redis数据过期机制
- 惰性删除
- 定期删除
- Redis缓存淘汰策略(8种)
- 算法
- LRU (Least Recently Used):最近最少使用
- LFU(Least Frequently Used):最近最少频率使用
- Redis事务
- Redis为什么要用分布式缓存
- Redis集群
- 主从模式 - 最简单的
- 哨兵模式
- Redis Cluster
- Redis常见问题及解决方案
- 缓存击穿
- 缓存穿透
- 缓存雪崩
- bigKey
- 热Key
- 慢查询命令
- 如何保障数据库和缓存数据的一致性
- 延时双删
- 异步更新缓存
- 假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如果将它们全部找出来?
- 什么情况下可能会导致 Redis 阻塞
- 怎么提高缓存命中率
- 怎么实现分布式锁
- 分布式点这里
- MongDB
- 数据库点这里
- 消息队列
- Spring、SpringBoot、SpringCloud点这里
Memcached
简洁的key-value存储系统,其实是内存中维护一张巨大的Hash表。不支持集群,Memcached彼此之间不进行通信,所以,可能会造成数据丢失。
和redis对比
| Memcached | Redis | |
|---|---|---|
| 数据类型 | 只支持key-value | |
| 数据持久化 | Memcached 把数据全部存在内存之中 | Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用 |
| 集群模式支持 | 没有原生的集群模式 | 3.0 版本起是原生支持集群模式的 |
| 线程模型 | 多线程,非阻塞 IO 复用的网络模型 | 单线程的多路 IO 复用模型 |
| 特性支持 | Redis 支持发布订阅模型、Lua 脚本、事务等功能 | |
| 过期数据删除 | 只用了惰性删除策略 | 惰性删除策略、定期删除策略 |
redis
redis是一个缓存中间件。
数据基于内存,内存的访问速度比磁盘快很多
单线程,基于I/O多路复用
- 6.0后支持多线程,但是命令执行还是单线程
Redis 除了可以用作缓存之外,还可以用于分布式锁、限流、消息队列、延时队列等>场景
- 延时队列:Redisson 内置了延时队列(基于 Sorted Set 实现的)
- 消息队列:Redis 自带的 List 数据结构可以作为一个简单的队列使用。(Rpush +Lpop)
Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。- 限流: 通过 Redis + Lua 脚本的方式来实现限流。key是ip,value是访问次数
- redis搜索引擎:借助 RediSearch
- redis延时任务
Redis常见数据类型和使用
5 种基础数据类型
String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
- String,二进制安全的,可以存储图片或者序列化的对象,值最大存储为512M
set key value
get key- Hash
hset key field value
hget key field- List
lpush key value [value ...]
lrange key start end- Set(集合)
sadd key element [element ...]
smembers key- ZSet(有序集合)
zadd key score member [score member ...]
zrank key member3 种特殊数据类型
HyperLogLog(基数统计)、Bitmap (位图)、Geospatial
(地理位置)。除了上面提到的之外,还有一些其他的比如 Bloom filter(布隆过滤器)open in new
window、Bitfield(位域)。
场景应用:排行耪
选用ZSet,这是一个有序集合。根据score来排序
Zrange (从小到大排序)、 ZrevRange (从大到小排序)、ZrevRank (指定元素排名)。
Redis缓存持久化
4.0之后,RDB 和 AOF 混合使用实现持久化
RDB-快照
定时将redis中的所有键值对数据保存到到一个临时文件中,这个文件就是dump.rdb文件。恢复时候将这个临时文件替换上次持久化的文件即可。
AOF-追加文件
每次操作命令时候,将这次的操作通过Write函数追加到文件中。恢复时候,会自动执行备份文件中的所有命令,达到恢复上次数据的效果。
总结:
- RDB是默认持久化方式,当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复。
- 持久化机制: 当Redis重启后通过把硬盘文件重新加载到内存
- 实现:单独创建fork()一个子进程,将当前父进程的数据库数据复制到子进程的内存中,然后由子进程写入到临时文件中,持久化的过程结束了,再用这个临时文件替换上次的快照文件,然后子进程退出,内存释放。
Redis数据过期机制
设置expire(过期时间)后才会触发。
Redis 采用的是 定期删除+惰性/懒汉式删除 结合的策略
惰性删除
当查询key时候,先看该key是否过期,没有过期就返回数据;负责,删除该key,且不返回数据
定期删除
在一定时间,随机抽取设置过期时间的key,若这些含的key大部分过期,就删除这些过期key
-
Redis 的定期删除过程是随机的(周期性地随机从设置了过期时间的 key 中抽查一批),所以并不保证所有过期键都会被立即删除。这也就解释了为什么有的 key 过期了,并没有被删除。
-
并且,执行时间已经超过了阈值,那么就中断这一次定期删除循环,以避免使用过多的 CPU 时间
-
可在配置文件中设置频率
由 hz 参数控制的。hz 默认为 10,代表每秒执行 10 次
Redis缓存淘汰策略(8种)
当redis内存不够用的时候,当一个新key需要存放时候就会按某种规则将内存中的数据删掉,这个删除规则就是淘汰策略。
- noeviction:默认策略。不删除任何key,新增的key也不写入,内部不足直接报错
- volatile-ttl:对设置TTL时间的key,剩余时间越短的先删除
- allkeys-random:对全体key随机淘汰
- volatile-random:对设置TTL时间的key随机淘汰
- allkeys-LRU:对全体key使用LRU短发淘汰
有明显冷热数据区分- volatile-LRU: 对设置TTL时间的key使用LRU短发淘汰
数据有置顶的需求 — 置顶数据不设置过期时间,这些数据就一直不被删除,会淘汰其他设置过期时间的数据- allkeys-LFU:对全体key使用LFU短发淘汰
- volatile-LFU: 对设置TTL时间的key使用LFU短发淘汰
算法
LRU (Least Recently Used):最近最少使用
用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
public class LRUCache<K, V> extends LinkedHashMap<K, V> {private final int CACHE_SIZE;// 这里就是传递进来最多能缓存多少数据public LRUCache(int cacheSize) {super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true);//这块就是设置一个hashmap的初始大小,//同时最后一个true指的是让linkedhashmap按照访问顺序来进行排序//即 最近访问的放在头,最老访问的就在尾CACHE_SIZE = cacheSize;}@Overrideprotected boolean removeEldestEntry(Map.Entry eldest) {return size() > CACHE_SIZE; // 这个意思就是说当map中的数据量大于指定的缓存个数的时候,就自动删除最老的数据}}
LFU(Least Frequently Used):最近最少频率使用
会统计每个key的访问频率,值越小淘汰优先级越高。
Redis的数据淘汰策略有哪些 ?- 以下回答背熟,大概用时1min。
redis有个策略叫数据淘汰策略,具体指的是当Redis中的内存不够用时,此时在向Redis中添加新的key,那么Redis就会按照某一种规则将内存中的数据删除掉。这个策略redis提供了8种方案,默认的叫noeviction,就是不删除任何数据,内部不足直接报错。方案的切换是可以在redis的配置文件中进行设置的,里面有两个非常重要的概念,一个是LRU,另外一个是LFU。
LRU,即Least Recently Used,意思就是最近最少使用,我们用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
LFU,即Least Frequently Used,意思就是最近最少频率使用。我们会统计每个key的访问频率,值越小淘汰优先级越高。
Redis事务
- redis提供了一种命令,可以将多个命令打包一起后按顺序执行,执行途中不会被影响
- MULTI(开始事务),EXEC(执行事务)直接包着命令集
不能保证原子性。可以这么说,是一种比较弱的事务。原子性就是要么都成功,要么都失败,对应到redis中,批量命令执行时候,假如中间出错了,前面执行过的无法回滚
Redis为什么要用分布式缓存
Redis集群
https://segmentfault.com/a/1190000043133394
主从模式 - 最简单的
这里是引用
Redis主从复制优点: 做到读写分离,提高服务器性能;
Redis主从复制缺点: 在主从模式中,一旦Master节点由于故障不能提供服务,需要人工将Slave节点晋升为Master节点
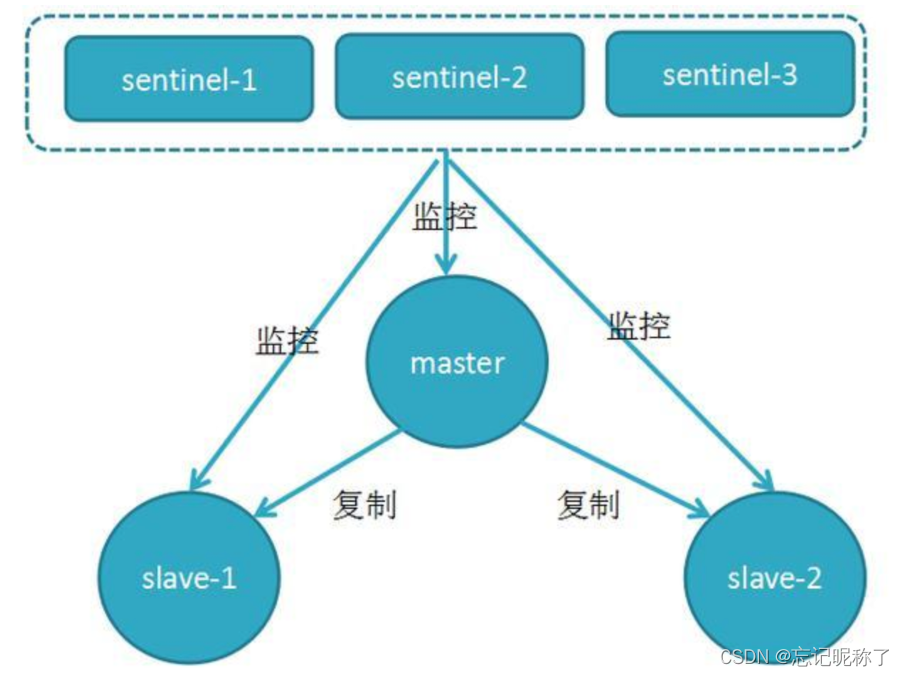
哨兵模式
当主服务器宕机后,需要手动把一台从服务器切换为主服务器,需要人工干预费事费力,为了解决这个问题出现了哨兵模式
哨兵模式优点:最大的优点就是主从可以自动切换,系统更健壮,可用性更高;哨兵模式缺点:最大的缺点就是还要多维护一套哨兵模式,实现起来也变的更加复杂增加维护成本;
Redis Cluster
主要是针对海量数据+高并发+高可用的海量数据场景,Redis集群模式的性能和高可用性均优于哨兵模式。
Redis常见问题及解决方案
缓存击穿
热key在缓存中过期了,所以不在缓存中,会导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
解决方案:
- 永不过期(不推荐):设置热点数据永不过期或者过期时间比较长。
- 提前预热(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
- 加锁(看情况);:在缓存失效后,通过设置互斥锁确保只有一个请求去查询数据库并更新缓存
缓存穿透
大量请求的 key 是不合理的,根本不存在于缓存中,也不存在于数据库中 。导致这些请求直接到了数据库上对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
解决方案:
- 首先做好参数校验,不合法的参数请求直接抛出异常信息返回给客户端
- 缓存无效 key,SET key value EX 10086 设置过期时间
- 布隆过滤器
- 接口限流,用户或者 IP 对接口进行限流,对于异常频繁的访问行为,还可以采取黑名单机制
缓存雪崩
缓存在同一时间大面积的失效,导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力
解决方案:
- 针对 Redis 服务不可用的情况:
Redis 集群
多级缓存(本地缓存+Redis 缓存的二级缓存组合)- 针对大量缓存同时失效的情况
设置随机失效时间
针对热点数据提前预热,并设置合理的时间
对于某些关键性和变化不频繁的数据,持久缓存永不过期
bigKey
一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey.
- String 类型的 value 超过 1MB
- 复合类型(List、Hash、Set、Sorted Set 等)的 value 包含的元素超过 5000 个
产生原因:
- 设计不当---- 使用string存储较大文件的二进制流
- 数据规模考虑不到位---- 使用集合类型没有考虑到数据量的快速增长
带来什么问题 — 阻塞
- 客户端超时阻塞:redis是单线程的,操作大key时候耗时
如果解决
- bigkeys 命令去扫描(redis-cli -p 6379 --bigkeys -i 3 表示扫描过程中每次扫描后休息的时间间隔为 3 秒)
- 找到后,手动清理;用合适的数据结构
热Key
访问频率较高的Key。
会出现的问题
- 某个热点数据访问量暴增 占用大量的 CPU 和带宽,影响redis的其他请求处理;严重情况下,导致宕机
如果查看
- 可以通过hotkeys 参数来查找
如果解决
- 读写分离:主节点处理写请求,从节点处理读请求。
- 使用 Redis Cluster:将热点数据分散存储在多个 Redis 节点上
- 二级缓存:hotkey 采用二级缓存的方式进行处理,将 hotkey 存放一份到 JVM 本地内存中(可以用 Caffeine)。
慢查询命令
为什么会有慢
如何保障数据库和缓存数据的一致性
就是通常讨论的淘汰缓存和更新数据库的顺序怎么样比较合适,下文是较好的方案:
延时双删
写入库的前后,都删除缓存【redis.del(key)操作】
步骤
先删除缓存 —> 再写数据库 —> 休眠 500 毫秒 —> 再次删除缓存
缺点:
最差的情况就是在超时时间内数据存在不一 致,而且又增加了写请求的耗时。
异步更新缓存
MySQL binlog 增量订阅消费+消息队列+增量数据更新到 redis
步骤
假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如果将它们全部找出来?
keys 命令和 scan 命令,使用 scan 更好
什么情况下可能会导致 Redis 阻塞
Redis 主机的 CPU 负载过高;
数据持久化占用资源过多;
使用Redis时 API 或 指令不合理
怎么提高缓存命中率
怎么实现分布式锁
分布式点这里
MongDB
分布式文件储存的数据库
- 存储数据:数据库中存储的对象设计BSON,一种类似json的二进制文件,由键值对组成
- 链接方式(默认为27017)
mongodb://[username:password@]host1[:port1][,host2[:port2]- 库简单认识
文档 - row
集合 - table
数据库 - database- 复制工作
MongoDB的复制工作是基于主从复制实现的。其中一个节点被定义为主节点,其他的节点被定义为备份节点,数据会进行实时同步。在某些情况下,主节点可能会失效或消失,这时候从节点将被提升为主节点继续工作。- 支持存储过程吗
支持,它是javascript写的,保存在db.system.js表中。
数据库点这里
消息队列
Spring、SpringBoot、SpringCloud点这里
相关文章:
JAVA面试(六)
缓存 MemcachedredisRedis常见数据类型和使用Redis缓存持久化RDB-快照AOF-追加文件 Redis数据过期机制惰性删除定期删除Redis缓存淘汰策略(8种)算法LRU (Least Recently Used):最近最少使用LFU(Least Frequ…...

【C语言】手写学生管理系统丨附源码+教程
最近感觉大家好多在忙C语言课设~ 我来贡献一下,如果对你有帮助的话谢谢大家的点赞收藏喔! 1. 项目分析 小白的神级项目,99%的程序员,都做过这个项目! 掌握这个项目,就基本掌握 C 语言了! 跳…...

流媒体传输协议HTTP-FLV、WebSocket-FLV、HTTP-TS 和 WebSocket-TS的详细介绍、应用场景及对比
一、前言 HTTP-FLV、WS-FLV、HTTP-TS 和 WS-TS 是针对 FLV 和 TS 格式视频流的不同传输方式。它们通过不同的协议实现视频流的传输,以满足不同的应用场景和需求。接下来我们对这些流媒体传输协议进行剖析。 二、传输协议 1、HTTP-FLV 介绍:基于 HTTP…...

【机器学习】线性回归:从基础到实践的深度解析
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 线性回归:从基础到实践的深度解析引言一、线性回归基础1.1 定义与目…...

短视频开源项目MoneyPrinterTurbo:AI副业搞起来,视频制作更轻松!
目录 引言一、MoneyPrinterTurbo简介二、MoneyPrinterTurbo的核心功能三、MoneyPrinterTurbo的未来发展四、MoneyPrinterTurbo与AI副业五、部署实践1、克隆代码2、创建虚拟环境3、安装依赖4、安装好 ImageMagick5、端口映射6、启动Web界面7、模型配置8、填写主题9、视频生成10、…...
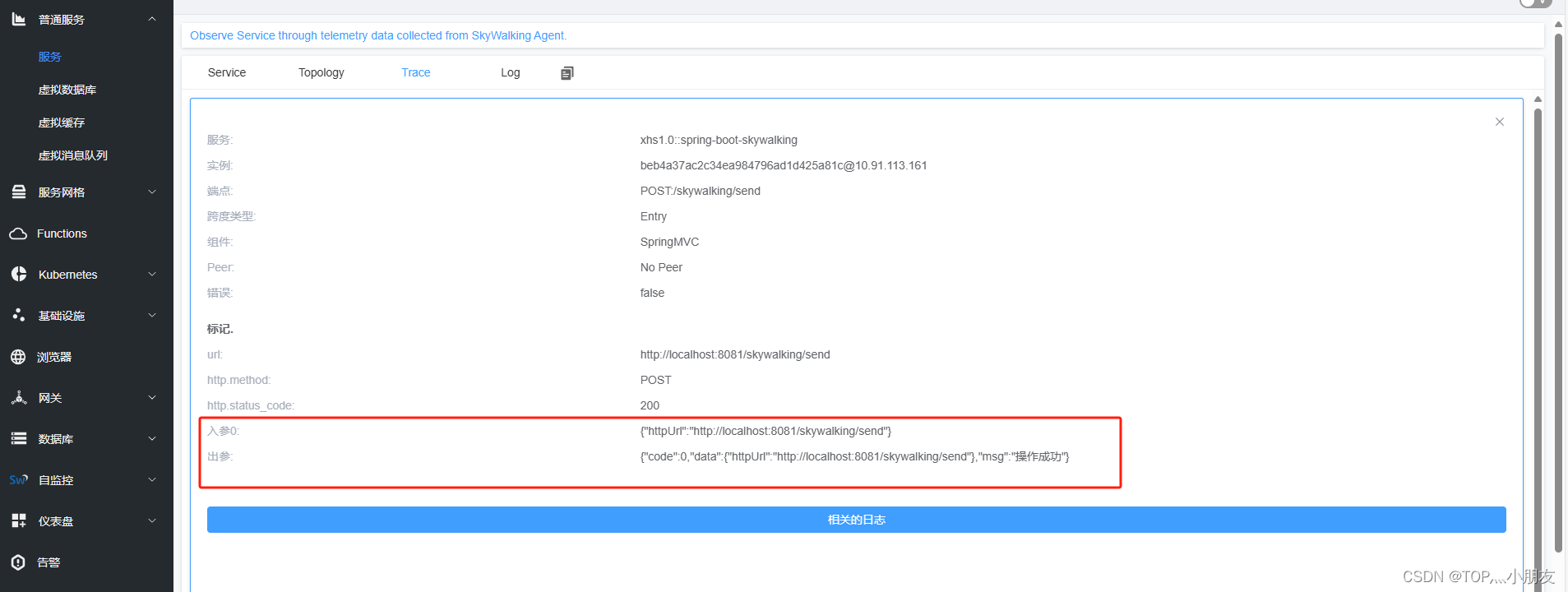
【JAVA】SpringBoot + skywalking 将接口的入参、出参、异常等信息上报到skywalking 链路追踪服务器上
【JAVA】SpringBoot skywalking 将接口的入参、出参、异常等信息上报到skywalking 链路追踪服务器上 1.下载SkyWalking APM https://skywalking.apache.org/downloads/ jdk8 不支持 SkyWalking APM 9.3.0以上版本,所以这里我们下载 9.3.0版本 2.下载 Java Agent …...

[xmake]构建静态库和动态库
xmake 静态库和动态库 在xmake中创建静态库和动态库的方法非常相似。以下是创建静态库和动态库的基本步骤: 创建xmake工程文件(xmake.lua)。 配置工程属性,包括工程名、版本等。 添加源代码文件到工程中。 设置是创建静态库还…...

功能测试 之 单模块测试----轮播图、登录、注册
单功能怎么测? 需求分析 拆解测试点 编写用例 1.轮播图 (1)需求分析 位置:后台--页面--广告管理---广告列表(搜索index页面增加广告位2) 操作完成后需要点击admin---更新缓存,前台页面刷新生效 (2)拆解…...

MyBatis-PageHelper 源码解说
归档 GitHub: MyBatis-PageHelper-源码解说 总说明 源码仓库: https://github.com/pagehelper/Mybatis-PageHelper克隆:git clone https://github.com/pagehelper/Mybatis-PageHelper.git切分支(tag):git checkout m…...

基于uni-app和图鸟UI的智慧校园圈子小程序开发实践
摘要: 随着教育信息化和“互联网教育”的快速发展,智慧校园建设已成为推动校园管理现代化、提高教育教学质量的重要手段。本文介绍了基于uni-app和图鸟UI开发的智慧校园圈子小程序,旨在通过一站式服务、个性化定制、数据互通和安全可靠等特点…...

STM32 keil工程移植到Visual Studio Code环境中编译
1、GCC Vscode 搭建 STM32 开发环境 GCC Vscode 搭建 STM32 开发环境(一)- 环境部署 - 知乎 (zhihu.com) 2、在原有keil工程下找到原本CUBEMX生成的.ioc工程文件 3、将.ioc文件复制一个新的文件夹下双击打开工程,将IDE选为Makefile&…...

细说CountDownLatch
CountDownLatch是Java中提供的一个同步辅助类,它允许一个或多个线程等待其他线程完成操作。在面试中,面试官经常会询问候选人是否在实际项目中使用过CountDownLatch,以评估其对多线程编程和并发控制的理解和经验。本文将详细介绍CountDownLat…...

java-克隆应用
5.2 创建复杂对象 对于某些复杂对象,通过克隆来创建其副本比通过构造函数创建新实例更加高效。例如,当对象包含大量字段或需要进行复杂初始化时,克隆可以显著提高性能。 java 复制代码 class ComplexObject implements Cloneable { private …...
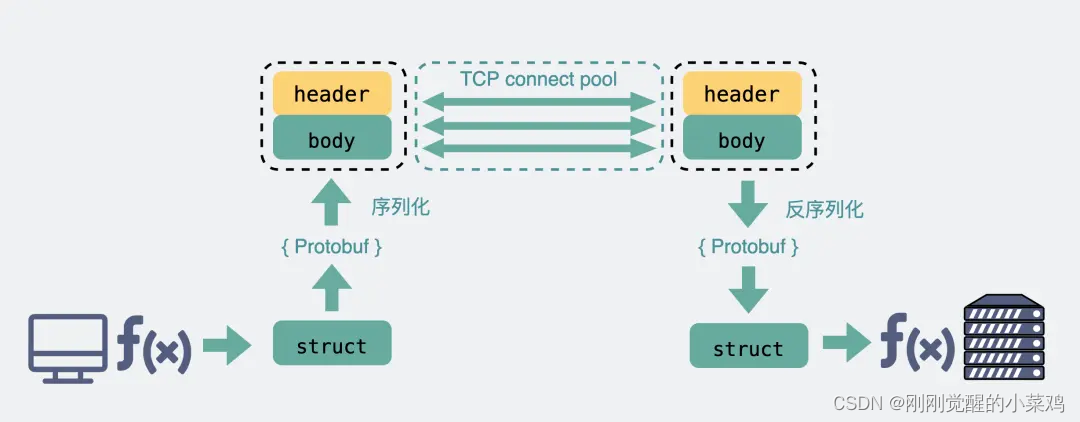
RPC协议
3.8 既然有 HTTP 协议,为什么还要有 RPC 假设我们需要在 A 电脑的进程发一段数据到 B 电脑的进程,我们一般会在代码里使用 Socket 进行编程。 这时候,我们可选项一般也就 TCP 和 UDP 二选一。TCP 可靠,UDP 不可靠。 类似下面这…...

医疗器械3D全景展会在线漫游创造数字化时代的展览新篇章
在数字化浪潮的引领下,VR虚拟网上展会正逐渐成为企业展示品牌实力、吸引潜在客户的首选平台。我们与广交会携手走过三年多的时光,凭借优质的服务和丰富的经验,赢得了客户的广泛赞誉。 面对传统展会活动繁多、企业运营繁忙的挑战,许…...

IP_Endpoint类型在CAPL中的使用
在使用TCP/IP协议栈通信时,创建Socket套接字调用接口函数实现通信的整个过程成为一种主流且便捷的方式。在CAPL中,Client需要创建TCP或UDP套接字,绑定自己的IP地址和一个端口号,作为自己的通信端点。 on key c {clientsocket = tcpOpen(ipGetAddressAsNumber("192.16…...

数据资产与用户体验优化:深入挖掘用户数据,精准分析用户需求与行为,优化产品与服务,提升用户体验与满意度,打造卓越的用户体验,赢得市场认可
一、引言 在数字化时代,数据已经成为企业最宝贵的资产之一。通过深入挖掘和分析用户数据,企业能够精准把握用户需求和行为,从而优化产品与服务,提升用户体验和满意度。这不仅有助于企业在激烈的市场竞争中脱颖而出,还…...

基于TCAD与紧凑模型结合方法探究陷阱对AlGaN/GaN HEMTs功率附加效率及线性度的影响
来源:Investigation of Traps Impact on PAE and Linearity of AlGaN/GaN HEMTs Relying on a Combined TCAD–Compact Model Approach(TED 24年) 摘要 本文提出了一种新型建模方法,用于分析GaN HEMTs的微波功率性能。通过结合工…...

具身智能概念
具身智能作为人工智能发展的一个重要分支,伴随着大模型技术的爆发与硬件成本的降低,即软硬件技术走向成熟,正在成为广泛关注的热门,一时之间,具身智能机器人也成为了科技界新的风向标。 什么是具身智能? …...

C++ 43 之 自增运算符的重载
#include <iostream> #include <string> using namespace std;class MyInt{friend ostream& operator<< (ostream& cout , MyInt& int1); public:MyInt(){this->m_num 0;}// 前置自增: 成员函数实现运算符的重载 返回的是 引用&a…...

革命性Figma中文插件:智能汉化让设计界面秒变母语
革命性Figma中文插件:智能汉化让设计界面秒变母语 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?FigmaCN是一款专为中文用户打造…...

别再IO模拟SPI了!STM32F103驱动AD9833信号发生器,库函数SPI配置避坑全记录
STM32硬件SPI驱动AD9833信号发生器的深度避坑指南 在嵌入式开发中,SPI通信是最常用的外设接口之一。许多开发者习惯使用GPIO模拟SPI时序,认为这样更灵活可控。但当我们面对AD9833这类对时序要求严格的芯片时,IO模拟的弊端就会暴露无遗——信号…...

声明式数据转换利器:Refiner 实战指南与架构集成
1. 项目概述与核心价值最近在折腾一个老项目的数据清洗和转换,被一堆格式混乱、结构不一的JSON文件搞得焦头烂额。手动写脚本处理吧,每次需求一变就得重写,维护成本太高;用现成的ETL工具吧,又觉得过于笨重,…...

幸福依赖于抽象的 能力的庖丁解牛
它的本质是:**将幸福的源头从 具体实现类 (Concrete Implementations)(如特定的伴侣、具体的工作、固定的房产)转移到 抽象接口 (Abstract Interfaces)(如爱的能力、创造价值的技能、感知美好的心智)。具体实现是不可控…...

Illustrator智能对象替换引擎:企业级设计自动化的技术杠杆
Illustrator智能对象替换引擎:企业级设计自动化的技术杠杆 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 技术价值宣言 在数字设计工业化时代,品牌资产管理…...

Python 异步HTTP客户端实战:aiohttp深度解析
Python 异步HTTP客户端实战:aiohttp深度解析 引言 在现代Python后端开发中,异步HTTP客户端是构建高性能服务的关键组件。作为一名从Rust转向Python的后端开发者,我深刻体会到异步编程在处理大量并发请求时的优势。aiohttp作为Python生态中最流…...

汉字信息聚合工具开发:从数据可视化到工程实践
1. 项目概述:一个汉字学习者的“浏览器” 如果你是一个对汉字结构、字源、演变历史有浓厚兴趣的学习者,或者是一位从事中文教学、字体设计、文化研究的专业人士,你肯定有过这样的经历:为了查清一个汉字的来龙去脉,你需…...

毕业答辩 PPT,让 AI 替你打工:百考通 AI 如何帮你告别排版内耗与逻辑焦虑
又是一年毕业季,论文写完了,查重过了,导师点头了,你以为可以松口气了? 不,还有一座大山叫“答辩 PPT”。 曾经,我也以为 PPT 只是论文的“精简版”,复制粘贴就能搞定。直到我熬…...

AI开发者实战指南:从工具全景到本地知识库搭建
1. 从Awesome List到实战地图:一份AI开发者工具全景解析如果你是一名AI开发者、研究者,或者只是对构建AI应用充满好奇的技术爱好者,面对浩如烟海的工具、框架和平台,最头疼的恐怕就是“我该从哪里开始?”这个问题。网上…...

qmcdump:3步轻松解锁QQ音乐加密文件,实现跨设备音乐自由
qmcdump:3步轻松解锁QQ音乐加密文件,实现跨设备音乐自由 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdu…...