【机器学习】从理论到实践:决策树算法在机器学习中的应用与实现

📝个人主页:哈__
期待您的关注

目录
📕引言
⛓决策树的基本原理
1. 决策树的结构
2. 信息增益
熵的计算公式
信息增益的计算公式
3. 基尼指数
4. 决策树的构建
🤖决策树的代码实现
1. 数据准备
2. 决策树模型训练
3. 决策树的可视化
4. 决策树的解释
🍎决策树在机器学习中的应用
1. 分类任务
2.决策树在回归任务中的应用
3. 特征选择
4. 异常检测
🎇决策树的优缺点
优点
缺点
💡决策树的改进方法
剪枝
集成方法
随机森林
梯度提升树
总结
📕引言
决策树是一种广泛应用于分类和回归任务的监督学习算法。它通过将数据集划分成不同的子集来做出决策,直观且易于理解。在本篇文章中,我们将深入剖析决策树的原理,并通过具体的代码实例展示其在机器学习中的应用。
⛓决策树的基本原理
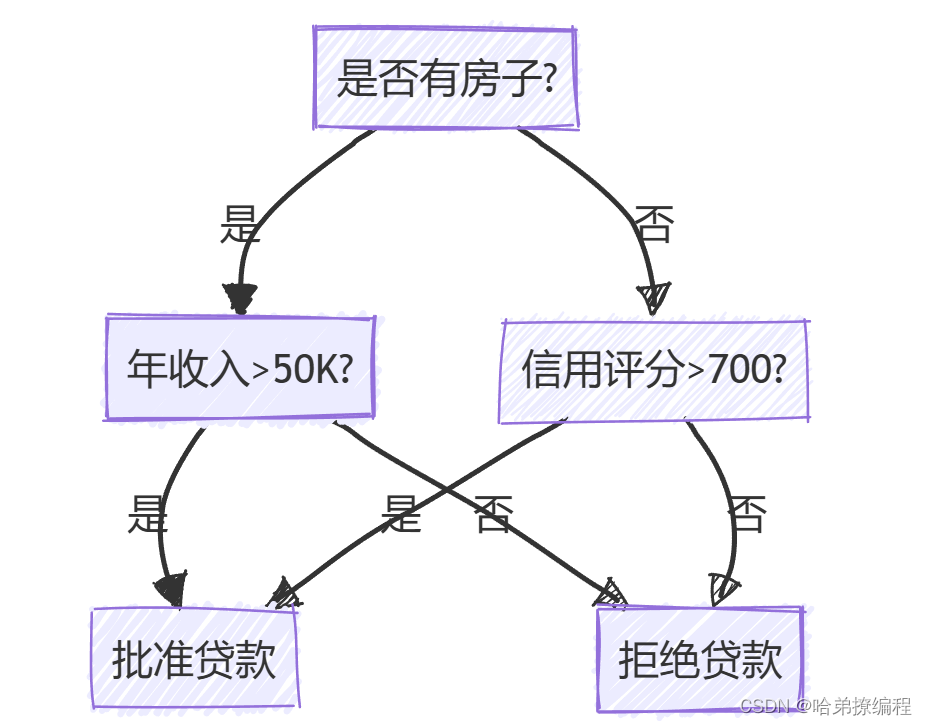
1. 决策树的结构
决策树由节点和边组成,其中每个节点表示数据集的某个特征,每条边表示特征的某个值所对应的分支。决策树的最顶端称为根节点,叶节点代表决策结果。以下是一个简单的决策树示例图:
2. 信息增益
决策树的构建过程依赖于一个重要概念:信息增益。信息增益用于衡量某个特征在划分数据集时所带来的纯度提升。常用的纯度度量包括熵、基尼指数等。
熵的计算公式
熵(Entropy)用于衡量数据集的不确定性,其计算公式为:
其中,
是数据集,
是类别数,
是第
类的概率。
信息增益的计算公式
信息增益(Information Gain)用于衡量选择某个特征进行数据划分时,数据集纯度的提升,其计算公式为:
I
其中,
是特征,
是根据特征
划分的数据子集。
3. 基尼指数
基尼指数(Gini Index)是另一种常用的纯度度量方法,用于衡量数据集的不纯度,其计算公式为:
其中,
4. 决策树的构建
决策树的构建过程可以归纳为以下步骤:
- 选择最佳特征进行数据集划分:选择使得信息增益最大化或基尼指数最小化的特征。
- 根据特征值划分数据集:将数据集根据选定特征的不同取值划分为若干子集。
- 递归构建子树:在每个子集上递归构建子树,直到满足停止条件(如所有样本属于同一类别或特征用尽)。
以下是决策树构建过程的伪代码:
函数 BuildTree(data, features):如果 data 中所有实例属于同一类别:返回该类别如果 features 为空或 data 为空:返回 data 中出现次数最多的类别选择使信息增益最大的特征 A创建节点 node,并将其标记为特征 A对于特征 A 的每个可能取值 v:子数据集 sub_data = 由 data 中特征 A 的值为 v 的实例构成如果 sub_data 为空:在 node 上创建叶节点,标记为 data 中出现次数最多的类别否则:在 node 上创建子节点,并将子节点连接到 BuildTree(sub_data, features \ {A})返回 node
🤖决策树的代码实现
接下来,我们通过具体代码展示如何在Python中实现决策树,并应用于分类任务。
1. 数据准备
我们使用一个简单的数据集来演示决策树的构建过程。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris# 加载Iris数据集 data = load_iris() df = pd.DataFrame(data.data, columns=data.feature_names) df['target'] = data.target# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(df.drop(columns=['target']), df['target'], test_size=0.3, random_state=42)2. 决策树模型训练
我们使用Scikit-Learn中的
DecisionTreeClassifier来训练决策树模型。from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score# 初始化决策树分类器 clf = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=42)# 训练模型 clf.fit(X_train, y_train)# 预测 y_pred = clf.predict(X_test)# 计算准确率 accuracy = accuracy_score(y_test, y_pred) print(f'决策树模型的准确率: {accuracy:.2f}')3. 决策树的可视化
我们可以使用Scikit-Learn的
export_graphviz函数和graphviz库来可视化决策树。from sklearn.tree import export_graphviz import graphviz# 导出决策树 dot_data = export_graphviz(clf, out_file=None, feature_names=data.feature_names, class_names=data.target_names, filled=True, rounded=True, special_characters=True) # 使用graphviz渲染决策树 graph = graphviz.Source(dot_data) graph.render("decision_tree") # 生成决策树的PDF文件4. 决策树的解释
在实际应用中,决策树的解释能力非常重要。我们可以通过以下方式解读决策树的结果:
特征重要性:决策树可以计算每个特征的重要性,反映其在树中进行决策时的重要程度。
import matplotlib.pyplot as plt import numpy as npfeature_importances = clf.feature_importances_ features = data.feature_namesindices = np.argsort(feature_importances)plt.figure(figsize=(10, 6)) plt.title("Feature Importances") plt.barh(range(len(indices)), feature_importances[indices], align="center") plt.yticks(range(len(indices)), [features[i] for i in indices]) plt.xlabel("Relative Importance") plt.show()决策路径:我们可以追踪决策树在做出某个预测时的决策路径。
sample_id = 0 # 样本索引 node_indicator = clf.decision_path(X_test) leaf_id = clf.apply(X_test)sample_path = node_indicator.indices[node_indicator.indptr[sample_id]:node_indicator.indptr[sample_id + 1]] print(f'样本 {sample_id} 的决策路径:') for node_id in sample_path:if leaf_id[sample_id] == node_id:print(f'--> 叶节点 {node_id}')else:print(f'--> 节点 {node_id}, 判断特征:{features[clf.tree_.feature[node_id]]}, 阈值:{clf.tree_.threshold[node_id]:.2f}')
🍎决策树在机器学习中的应用
决策树在机器学习中有广泛的应用,主要体现在以下几个方面:
1. 分类任务
决策树在分类任务中应用广泛,如垃圾邮件分类、疾病诊断等。以下是使用决策树进行分类任务的示例代码:
from sklearn.datasets import load_wine from sklearn.metrics import classification_report# 加载葡萄酒数据集 wine_data = load_wine() X_wine = wine_data.data y_wine = wine_data.target# 划分训练集和测试集 X_train_wine, X_test_wine, y_train_wine, y_test_wine = train_test_split(X_wine, y_wine, test_size=0.3, random_state=42)# 训练决策树分类器 wine_clf = DecisionTreeClassifier(criterion='gini', max_depth=5, random_state=42) wine_clf.fit(X_train_wine, y_train_wine)# 预测 y_pred_wine = wine_clf.predict(X_test_wine)# 评估模型 print(classification_report(y_test_wine, y_pred_wine, target_names=wine_data.target_names))2.决策树在回归任务中的应用
决策树同样适用于回归任务,例如房价预测、股票价格预测等。决策树回归模型通过将数据集划分为若干区域,并对每个区域内的样本进行平均来进行预测。以下是一个使用决策树进行回归任务的示例代码:
from sklearn.datasets import load_boston from sklearn.tree import DecisionTreeRegressor from sklearn.metrics import mean_squared_error# 加载波士顿房价数据集 boston = load_boston() X_boston = boston.data y_boston = boston.target# 划分训练集和测试集 X_train_boston, X_test_boston, y_train_boston, y_test_boston = train_test_split(X_boston, y_boston, test_size=0.3, random_state=42)# 初始化决策树回归器 regressor = DecisionTreeRegressor(criterion='mse', max_depth=5, random_state=42)# 训练模型 regressor.fit(X_train_boston, y_train_boston)# 预测 y_pred_boston = regressor.predict(X_test_boston)# 计算均方误差 mse = mean_squared_error(y_test_boston, y_pred_boston) print(f'决策树回归模型的均方误差: {mse:.2f}')3. 特征选择
决策树可以用于特征选择,通过计算特征的重要性来筛选出对预测结果影响最大的特征。这在高维数据集的处理上尤其有用。
# 计算特征重要性 feature_importances = regressor.feature_importances_ features = boston.feature_names# 打印特征重要性 for name, importance in zip(features, feature_importances):print(f'Feature: {name}, Importance: {importance:.2f}')4. 异常检测
决策树还可以用于异常检测,通过构建深度较大的树来识别数据集中异常点。较深的叶节点通常对应于异常样本。
from sklearn.ensemble import IsolationForest# 初始化隔离森林模型 iso_forest = IsolationForest(n_estimators=100, contamination=0.1, random_state=42)# 训练模型 iso_forest.fit(X_train_boston)# 预测异常 anomalies = iso_forest.predict(X_test_boston) print(f'异常样本数量: {sum(anomalies == -1)}')
🎇决策树的优缺点
优点
- 直观易懂:决策树的结构类似于人类的决策过程,易于理解和解释。
- 无需特征缩放:决策树对数据的缩放不敏感,不需要进行特征归一化或标准化。
- 处理缺失值:决策树能够处理数据集中的缺失值。
- 非线性关系:决策树能够捕捉数据中的非线性关系。
缺点
- 容易过拟合:决策树在训练数据上表现良好,但在测试数据上可能表现不佳,需要通过剪枝等方法进行优化。
- 对噪声敏感:决策树对数据中的噪声较为敏感,容易导致模型不稳定。
- 偏向于多值特征:决策树在选择特征时偏向于取值较多的特征,可能导致偏差。
💡决策树的改进方法
剪枝
剪枝是通过删除决策树中的一些节点来减少模型的复杂度,防止过拟合。剪枝方法主要包括预剪枝和后剪枝。
- 预剪枝:在构建决策树的过程中,通过限制树的最大深度、最小样本数等参数来防止树的过度生长。
- 后剪枝:在决策树构建完成后,通过评估子树的重要性来剪除不重要的子树。
集成方法
集成方法通过结合多个决策树的预测结果来提高模型的稳定性和准确性,常见的集成方法包括随机森林和梯度提升树。
随机森林
随机森林通过构建多棵决策树,并对每棵树的预测结果进行投票来获得最终结果,有效减少了单棵决策树的过拟合问题。
from sklearn.ensemble import RandomForestRegressor# 初始化随机森林回归器 rf_regressor = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=42)# 训练模型 rf_regressor.fit(X_train_boston, y_train_boston)# 预测 rf_y_pred = rf_regressor.predict(X_test_boston)# 计算均方误差 rf_mse = mean_squared_error(y_test_boston, rf_y_pred) print(f'随机森林回归模型的均方误差: {rf_mse:.2f}')梯度提升树
梯度提升树通过逐步构建多个决策树,每棵树都在之前所有树的基础上进行改进,从而提高模型的准确性。
from sklearn.ensemble import GradientBoostingRegressor# 初始化梯度提升回归器 gb_regressor = GradientBoostingRegressor(n_estimators=100, max_depth=3, random_state=42)# 训练模型 gb_regressor.fit(X_train_boston, y_train_boston)# 预测 gb_y_pred = gb_regressor.predict(X_test_boston)# 计算均方误差 gb_mse = mean_squared_error(y_test_boston, gb_y_pred) print(f'梯度提升回归模型的均方误差: {gb_mse:.2f}')
总结
本文详细介绍了决策树的基本原理、构建过程及其在机器学习中的应用。通过详细的代码示例,我们展示了如何使用决策树进行分类和回归任务,并探讨了决策树的优缺点及其改进方法。希望通过本文的介绍,读者能够更深入地理解决策树算法,并能在实际应用中灵活运用这一强大的工具。
无论是在特征选择、分类任务、回归任务还是异常检测中,决策树都展现出了其独特的优势和广泛的应用前景。通过不断优化和改进,决策树将在更多的机器学习任务中发挥重要作用。
相关文章:
【机器学习】从理论到实践:决策树算法在机器学习中的应用与实现
📝个人主页:哈__ 期待您的关注 目录 📕引言 ⛓决策树的基本原理 1. 决策树的结构 2. 信息增益 熵的计算公式 信息增益的计算公式 3. 基尼指数 4. 决策树的构建 🤖决策树的代码实现 1. 数据准备 2. 决策树模型训练 3.…...

Zookeeper 集群节点故障剔除、切换、恢复原理
Zookeeper 集群节点故障剔除、切换、恢复原理 zookeeper 集群节点故障时,如何剔除节点,如果为领导节点如何处理,如何进行故障恢 复的,实现原理? 在 Zookeeper 集群中,当节点故障时,集群需要自动剔除故障节点并进行故障恢复,确保集群的高 可用性和一致性。具体来说,…...

解决帝国cms栏目管理拼音乱码的问题
帝国CMS7.5版本utf-8版网站后台增加栏目生成乱码的问题怎么解决 1、需要改一个函数,并且增加一个处理文件,方法如下: 修改e/class/connect.php文件,找到ReturnPinyinFun函数,如未修改文件在4533-4547行,将…...

Git快速入门
一 快速使用 1.1 初始化 什么是版本库呢?版本库又名仓库,可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改、删除,Git都能跟踪,以便任何时刻都可以追踪历史࿰…...

【18.0】JavaScript---事件案例
【18.0】JavaScript—事件案例 【一】开关灯事件 【介绍】设置一个按钮,按下按钮触发事件,来回切换圆形图片的颜色 【分析】 图片设置:设置成圆形的图片背景颜色:设置红绿两个颜色,来回切换按钮设置:点击…...
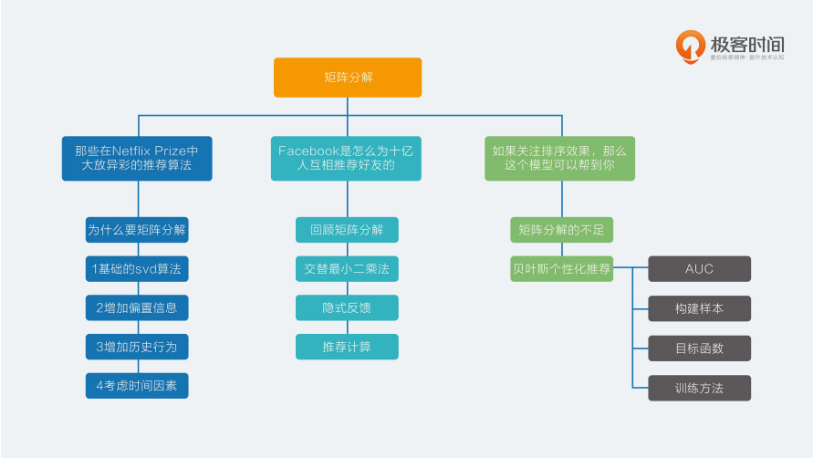
推荐系统三十六式学习笔记:原理篇.矩阵分解12|如果关注排序效果,那么这个模型可以帮到你
目录 矩阵分解的不足贝叶斯个性化排序AUC构造样本目标函数训练方法 总结 矩阵分解在推荐系统中的地位非常崇高。它既有协同过滤的血统,又有机器学习的基因,可以说是非常优秀了;但即便如此,传统的矩阵分解无论是在处理显式反馈&…...

Kafka之ISR机制的理解
文章目录 Kafka的基本概念什么是ISRISR的维护机制ISR的作用ISR相关配置参数同步过程示例代码总结 Kafka中的ISR(In-Sync Replicas同步副本)机制是确保数据高可用性和一致性的核心组件。 Kafka的基本概念 在Kafka中,数据被组织成主题…...
如何设计一个点赞系统
首先我们定义出一个点赞系统需要对外提供哪些接口: 1.用户对特定的消息进行点赞; 2.用户查看自己发布的某条消息点赞数量以及被哪些人赞过; 3.用户查看自己给哪些消息点赞过; 这里假设每条消息都有一个message_id, 每一个用户都…...

对象存储测试工具-s3cmd
一、环境安装 官网:https://s3tools.org/s3cmd 下载安装包:https://s3tools.org/download GitHub:https://github.com/s3tools/s3cmd/releases 本文安装包:https://github.com/s3tools/s3cmd/releases/download/v2.0.2/s3cmd-2.0…...

OpenCV--图像色彩空间及转换
图像色彩空间及转换 python代码和笔记 python代码和笔记 import cv2 色彩空间,基础:RGB或BGR OpenCV中: 一、HSV(HSB):用的最多, Hue:色相-色彩(0-360),红色:0,绿色&…...

RIP解决不连续子网问题
#交换设备 RIP解决不连续子网问题 一、不连续子网的概念 相同主网下的子网,被另一个主网分割,例如下面实验拓扑在某公司的网络整改项目中,原先R1 和RS 属于同一主网络 10.0.0.0/8,现被 R2、R3、R4 分离,整网采用了 …...

动态轮换代理IP是什么?有什么用?
如果您要处理多个在线帐户,选择正确的代理类型对于实现流畅的性能至关重要。但最适合这项工作的代理类型是什么? 为了更好地管理不同平台上的多个账户并优化成本,动态住宅代理IP通常作用在此。 一、什么是轮换代理? 轮换代理充当…...

MAC配置VScode中C++项目debug环境
文章目录 配置步骤问题解决Unable to start debugging. LLDB exited unexpectedly with exit code 137 (0x89). 配置步骤 在Mac上配置VS Code以进行C调试涉及几个步骤: 安装必要的工具: 确保您已经安装了Visual Studio Code和C插件。 检查是否安装了Clang…...

PostgreSQL源码分析——CREATE CAST
CREATE CAST源码分析 CREATE CAST用法 CREATE CAST —— 定义一个用户自定义的类型转换 用法如下: CREATE CAST (source_type AS target_type)WITH FUNCTION function_name [ (argument_type [, ...]) ][ AS ASSIGNMENT | AS IMPLICIT ]CREATE CAST (source_type…...

解锁5G新营销:视频短信的优势与全方位推广策略
随着5G时代的全面来临,企业的数字化转型步伐日益加快,视频短信作为新兴的数字营销工具,正逐步展现出其巨大的潜力。视频短信群发以其独特的形式和内容,将图片、文字、视频、声音融为一体,为用户带来全新的直观感受&…...

视频监控平台功能:国外的硬盘录像机NVR通过ISUP协议(原ehome协议)接入AS-V1000视频平台
目录 一、背景说明 二、ISUP协议介绍 1、海康ISUP协议概述 2、ISUP协议支持主码流和子码流切换 (1)灵活配置和个性化 (2)适应不同网络带宽,提高使用体验 3、海康ehome相关文章 三、ISUP协议接入说明 1、平台侧…...

PostgreSQL查询用户
在 PostgreSQL 中,可以通过查询系统表来确定当前用户是否是超级管理员(超级用户)。具体来说,可以使用 pg_roles 系统表,该表包含数据库中所有角色的信息。 以下是查询当前用户是否是超级用户的 SQL 语句: …...

力扣1539.第k个缺失的正整数
力扣1539.第k个缺失的正整数 占位运算 只要n<k ,k;最终k就是结果 class Solution {public:int findKthPositive(vector<int>& arr, int k) {for(int n : arr){if(n < k) k ;else break;}return k;}};...

如何快速解决屏幕适配问题
下面将利用postcss插件快速解决屏幕适配问题。仅用少量代码,新手均可快速使用。 Step1. 安装 npm install postcss-px-to-viewport-8-plugin --save-dev Step2. 新建 postcss.config.js 文件,做基础配置 module.exports {plugins: {postcss-px-to-v…...
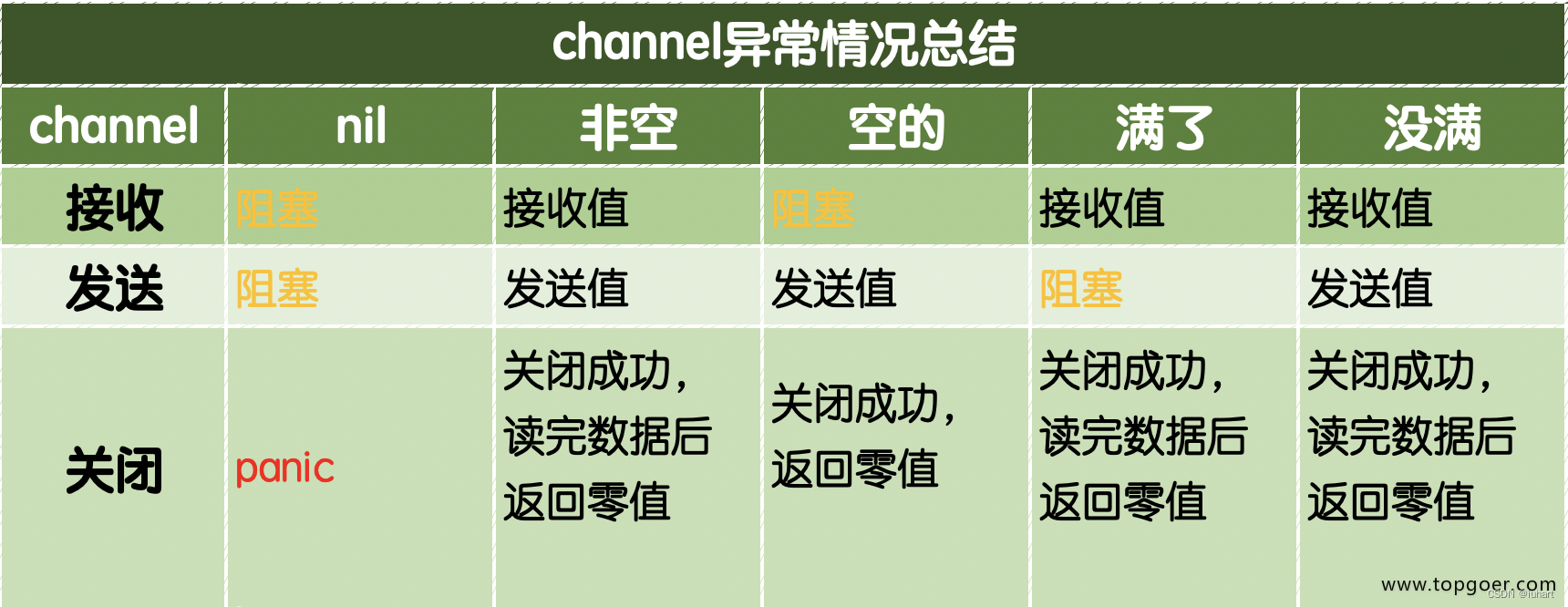
Go基础编程 - 09 - 通道(channel)
通道(channel) 1. 声明2. channel的操作3. 无缓冲通道4. 有缓冲通道5. 如何优雅的从通道循环取值6. 单向通道7. 异常总结 上一篇:结构体 Go语言的并发模式:不要通过共享内存来通信,而应该通过通信来共享内存。 Go语言…...

3大核心功能深度解析:如何用FanControl打造个性化静音散热系统
3大核心功能深度解析:如何用FanControl打造个性化静音散热系统 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tre…...

B站缓存视频拯救指南:如何用m4s-converter快速解锁被封存的数字记忆
B站缓存视频拯救指南:如何用m4s-converter快速解锁被封存的数字记忆 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾在深夜缓…...

3分钟掌握FSearch:Linux系统文件搜索效率提升300%的终极方案
3分钟掌握FSearch:Linux系统文件搜索效率提升300%的终极方案 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 还在为Linux系统中寻找文件而烦恼吗ÿ…...

VideoDownloadHelper终极指南:三分钟掌握免费视频下载插件
VideoDownloadHelper终极指南:三分钟掌握免费视频下载插件 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper VideoDownloadHelper是…...

在 Vue 2 与 Vue 3 中使用 markdown-it-vue 渲染 Markdown 和数学公式
markdown-it-vue 是一个功能强大的 Markdown 渲染 Vue 组件,它基于 markdown-it 解析引擎,集成了多种插件,开箱即用地支持GitHub风格的Markdown、代码高亮、图表(Mermaid, ECharts)、表情符号(emoji&#x…...

如何高效配置阅读APP书源:完整指南助你轻松获取全网小说资源
如何高效配置阅读APP书源:完整指南助你轻松获取全网小说资源 【免费下载链接】Yuedu 📚「阅读」自用书源分享 项目地址: https://gitcode.com/gh_mirrors/yu/Yuedu 还在为找不到心仪的小说而烦恼吗?想要打造属于自己的个性化阅读环境吗…...

问卷星 vs 腾讯问卷 vs 金数据:2026主流问卷工具AI开放能力最新横评
作为问卷调研行业的深度观察者,老N近期注意到调研工具链正在发生一场静悄悄的革命。最近,问卷星正式上线了AI工具包(wjx-ai-kit),其CLI(命令行工具)支持多达67个子命令,并适配了Clau…...

Rusted PackFile Manager:全面战争模组制作的新手入门完全指南
Rusted PackFile Manager:全面战争模组制作的新手入门完全指南 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: htt…...

贪吃蛇游戏开发实战:从基础架构到错误监控与性能优化
1. 项目概述:一个“会说话”的贪吃蛇游戏最近在GitHub上看到一个挺有意思的项目,叫“BugSplat-Git/snake-game”。初看标题,你可能觉得这不就是个经典的贪吃蛇游戏吗?从诺基亚时代玩到现在的玩意儿,还能有什么新花样&a…...

Faust高级特性:窗口聚合与状态管理完整教程
Faust高级特性:窗口聚合与状态管理完整教程 【免费下载链接】faust Python Stream Processing. A Faust fork 项目地址: https://gitcode.com/gh_mirrors/faus/faust 掌握Faust的窗口聚合与状态管理功能,构建高效的Python流处理应用!&…...