Flink 1.19.1 standalone 集群模式部署及配置
flink 1.19起 conf/flink-conf.yaml 更改为新的 conf/config.yaml

standalone集群: dev001、dev002、dev003
config.yaml: jobmanager address 统一使用 dev001,bind-port 统一改成 0.0.0.0,taskmanager address 分别更改为dev所在host
dev001 config.yaml:
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################# These parameters are required for Java 17 support.
# They can be safely removed when using Java 8/11.
env:java:opts:all: --add-exports=java.base/sun.net.util=ALL-UNNAMED --add-exports=java.rmi/sun.rmi.registry=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED --add-exports=java.security.jgss/sun.security.krb5=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.net=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/java.text=ALL-UNNAMED --add-opens=java.base/java.time=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.util.concurrent=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.atomic=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.locks=ALL-UNNAMED#==============================================================================
# Common
#==============================================================================jobmanager:# The host interface the JobManager will bind to. By default, this is localhost, and will prevent# the JobManager from communicating outside the machine/container it is running on.# On YARN this setting will be ignored if it is set to 'localhost', defaulting to 0.0.0.0.# On Kubernetes this setting will be ignored, defaulting to 0.0.0.0.## To enable this, set the bind-host address to one that has access to an outside facing network# interface, such as 0.0.0.0.bind-host: 0.0.0.0rpc:# The external address of the host on which the JobManager runs and can be# reached by the TaskManagers and any clients which want to connect. This setting# is only used in Standalone mode and may be overwritten on the JobManager side# by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable.# In high availability mode, if you use the bin/start-cluster.sh script and setup# the conf/masters file, this will be taken care of automatically. Yarn# automatically configure the host name based on the hostname of the node where the# JobManager runs.address: dev001# The RPC port where the JobManager is reachable.port: 6123memory:process:# The total process memory size for the JobManager.# Note this accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead.size: 1600mexecution:# The failover strategy, i.e., how the job computation recovers from task failures.# Only restart tasks that may have been affected by the task failure, which typically includes# downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.failover-strategy: regiontaskmanager:# The host interface the TaskManager will bind to. By default, this is localhost, and will prevent# the TaskManager from communicating outside the machine/container it is running on.# On YARN this setting will be ignored if it is set to 'localhost', defaulting to 0.0.0.0.# On Kubernetes this setting will be ignored, defaulting to 0.0.0.0.## To enable this, set the bind-host address to one that has access to an outside facing network# interface, such as 0.0.0.0.bind-host: 0.0.0.0# The address of the host on which the TaskManager runs and can be reached by the JobManager and# other TaskManagers. If not specified, the TaskManager will try different strategies to identify# the address.## Note this address needs to be reachable by the JobManager and forward traffic to one of# the interfaces the TaskManager is bound to (see 'taskmanager.bind-host').## Note also that unless all TaskManagers are running on the same machine, this address needs to be# configured separately for each TaskManager.host: dev001# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.numberOfTaskSlots: 2memory:process:# The total process memory size for the TaskManager.## Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.# To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.# It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.size: 1728mparallelism:# The parallelism used for programs that did not specify and other parallelism.default: 1# # The default file system scheme and authority.
# # By default file paths without scheme are interpreted relative to the local
# # root file system 'file:///'. Use this to override the default and interpret
# # relative paths relative to a different file system,
# # for example 'hdfs://mynamenode:12345'
# fs:
# default-scheme: hdfs://mynamenode:12345#==============================================================================
# High Availability
#==============================================================================# high-availability:
# # The high-availability mode. Possible options are 'NONE' or 'zookeeper'.
# type: zookeeper
# # The path where metadata for master recovery is persisted. While ZooKeeper stores
# # the small ground truth for checkpoint and leader election, this location stores
# # the larger objects, like persisted dataflow graphs.
# #
# # Must be a durable file system that is accessible from all nodes
# # (like HDFS, S3, Ceph, nfs, ...)
# storageDir: hdfs:///flink/ha/
# zookeeper:
# # The list of ZooKeeper quorum peers that coordinate the high-availability
# # setup. This must be a list of the form:
# # "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
# quorum: localhost:2181
# client:
# # ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes
# # It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)
# # The default value is "open" and it can be changed to "creator" if ZK security is enabled
# acl: open#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled. Checkpointing is enabled when execution.checkpointing.interval > 0.# # Execution checkpointing related parameters. Please refer to CheckpointConfig and ExecutionCheckpointingOptions for more details.
# execution:
# checkpointing:
# interval: 3min
# externalized-checkpoint-retention: [DELETE_ON_CANCELLATION, RETAIN_ON_CANCELLATION]
# max-concurrent-checkpoints: 1
# min-pause: 0
# mode: [EXACTLY_ONCE, AT_LEAST_ONCE]
# timeout: 10min
# tolerable-failed-checkpoints: 0
# unaligned: false# state:
# backend:
# # Supported backends are 'hashmap', 'rocksdb', or the
# # <class-name-of-factory>.
# type: hashmap
# # Flag to enable/disable incremental checkpoints for backends that
# # support incremental checkpoints (like the RocksDB state backend).
# incremental: false
# checkpoints:
# # Directory for checkpoints filesystem, when using any of the default bundled
# # state backends.
# dir: hdfs://namenode-host:port/flink-checkpoints
# savepoints:
# # Default target directory for savepoints, optional.
# dir: hdfs://namenode-host:port/flink-savepoints#==============================================================================
# Rest & web frontend
#==============================================================================rest:# The address to which the REST client will connect toaddress: dev001# The address that the REST & web server binds to# By default, this is localhost, which prevents the REST & web server from# being able to communicate outside of the machine/container it is running on.## To enable this, set the bind address to one that has access to outside-facing# network interface, such as 0.0.0.0.bind-address: 0.0.0.0# # The port to which the REST client connects to. If rest.bind-port has# # not been specified, then the server will bind to this port as well.# port: 8081# # Port range for the REST and web server to bind to.# bind-port: 8080-8090# web:
# submit:
# # Flag to specify whether job submission is enabled from the web-based
# # runtime monitor. Uncomment to disable.
# enable: false
# cancel:
# # Flag to specify whether job cancellation is enabled from the web-based
# # runtime monitor. Uncomment to disable.
# enable: false#==============================================================================
# Advanced
#==============================================================================# io:
# tmp:
# # Override the directories for temporary files. If not specified, the
# # system-specific Java temporary directory (java.io.tmpdir property) is taken.
# #
# # For framework setups on Yarn, Flink will automatically pick up the
# # containers' temp directories without any need for configuration.
# #
# # Add a delimited list for multiple directories, using the system directory
# # delimiter (colon ':' on unix) or a comma, e.g.:
# # /data1/tmp:/data2/tmp:/data3/tmp
# #
# # Note: Each directory entry is read from and written to by a different I/O
# # thread. You can include the same directory multiple times in order to create
# # multiple I/O threads against that directory. This is for example relevant for
# # high-throughput RAIDs.
# dirs: /tmp# classloader:
# resolve:
# # The classloading resolve order. Possible values are 'child-first' (Flink's default)
# # and 'parent-first' (Java's default).
# #
# # Child first classloading allows users to use different dependency/library
# # versions in their application than those in the classpath. Switching back
# # to 'parent-first' may help with debugging dependency issues.
# order: child-first# The amount of memory going to the network stack. These numbers usually need
# no tuning. Adjusting them may be necessary in case of an "Insufficient number
# of network buffers" error. The default min is 64MB, the default max is 1GB.
#
# taskmanager:
# memory:
# network:
# fraction: 0.1
# min: 64mb
# max: 1gb#==============================================================================
# Flink Cluster Security Configuration
#==============================================================================# Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -
# may be enabled in four steps:
# 1. configure the local krb5.conf file
# 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)
# 3. make the credentials available to various JAAS login contexts
# 4. configure the connector to use JAAS/SASL# # The below configure how Kerberos credentials are provided. A keytab will be used instead of
# # a ticket cache if the keytab path and principal are set.
# security:
# kerberos:
# login:
# use-ticket-cache: true
# keytab: /path/to/kerberos/keytab
# principal: flink-user
# # The configuration below defines which JAAS login contexts
# contexts: Client,KafkaClient#==============================================================================
# ZK Security Configuration
#==============================================================================# zookeeper:
# sasl:
# # Below configurations are applicable if ZK ensemble is configured for security
# #
# # Override below configuration to provide custom ZK service name if configured
# # zookeeper.sasl.service-name: zookeeper
# #
# # The configuration below must match one of the values set in "security.kerberos.login.contexts"
# login-context-name: Client#==============================================================================
# HistoryServer
#==============================================================================# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
#
# jobmanager:
# archive:
# fs:
# # Directory to upload completed jobs to. Add this directory to the list of
# # monitored directories of the HistoryServer as well (see below).
# dir: hdfs:///completed-jobs/# historyserver:
# web:
# # The address under which the web-based HistoryServer listens.
# address: 0.0.0.0
# # The port under which the web-based HistoryServer listens.
# port: 8082
# archive:
# fs:
# # Comma separated list of directories to monitor for completed jobs.
# dir: hdfs:///completed-jobs/
# # Interval in milliseconds for refreshing the monitored directories.
# fs.refresh-interval: 10000dev002 config.yaml:
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################# These parameters are required for Java 17 support.
# They can be safely removed when using Java 8/11.
env:java:opts:all: --add-exports=java.base/sun.net.util=ALL-UNNAMED --add-exports=java.rmi/sun.rmi.registry=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED --add-exports=java.security.jgss/sun.security.krb5=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.net=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/java.text=ALL-UNNAMED --add-opens=java.base/java.time=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.util.concurrent=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.atomic=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.locks=ALL-UNNAMED#==============================================================================
# Common
#==============================================================================jobmanager:# The host interface the JobManager will bind to. By default, this is localhost, and will prevent# the JobManager from communicating outside the machine/container it is running on.# On YARN this setting will be ignored if it is set to 'localhost', defaulting to 0.0.0.0.# On Kubernetes this setting will be ignored, defaulting to 0.0.0.0.## To enable this, set the bind-host address to one that has access to an outside facing network# interface, such as 0.0.0.0.bind-host: 0.0.0.0rpc:# The external address of the host on which the JobManager runs and can be# reached by the TaskManagers and any clients which want to connect. This setting# is only used in Standalone mode and may be overwritten on the JobManager side# by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable.# In high availability mode, if you use the bin/start-cluster.sh script and setup# the conf/masters file, this will be taken care of automatically. Yarn# automatically configure the host name based on the hostname of the node where the# JobManager runs.address: dev001# The RPC port where the JobManager is reachable.port: 6123memory:process:# The total process memory size for the JobManager.# Note this accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead.size: 1600mexecution:# The failover strategy, i.e., how the job computation recovers from task failures.# Only restart tasks that may have been affected by the task failure, which typically includes# downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.failover-strategy: regiontaskmanager:# The host interface the TaskManager will bind to. By default, this is localhost, and will prevent# the TaskManager from communicating outside the machine/container it is running on.# On YARN this setting will be ignored if it is set to 'localhost', defaulting to 0.0.0.0.# On Kubernetes this setting will be ignored, defaulting to 0.0.0.0.## To enable this, set the bind-host address to one that has access to an outside facing network# interface, such as 0.0.0.0.bind-host: 0.0.0.0# The address of the host on which the TaskManager runs and can be reached by the JobManager and# other TaskManagers. If not specified, the TaskManager will try different strategies to identify# the address.## Note this address needs to be reachable by the JobManager and forward traffic to one of# the interfaces the TaskManager is bound to (see 'taskmanager.bind-host').## Note also that unless all TaskManagers are running on the same machine, this address needs to be# configured separately for each TaskManager.host: dev002# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.numberOfTaskSlots: 2memory:process:# The total process memory size for the TaskManager.## Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.# To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.# It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.size: 1728mparallelism:# The parallelism used for programs that did not specify and other parallelism.default: 1# # The default file system scheme and authority.
# # By default file paths without scheme are interpreted relative to the local
# # root file system 'file:///'. Use this to override the default and interpret
# # relative paths relative to a different file system,
# # for example 'hdfs://mynamenode:12345'
# fs:
# default-scheme: hdfs://mynamenode:12345#==============================================================================
# High Availability
#==============================================================================# high-availability:
# # The high-availability mode. Possible options are 'NONE' or 'zookeeper'.
# type: zookeeper
# # The path where metadata for master recovery is persisted. While ZooKeeper stores
# # the small ground truth for checkpoint and leader election, this location stores
# # the larger objects, like persisted dataflow graphs.
# #
# # Must be a durable file system that is accessible from all nodes
# # (like HDFS, S3, Ceph, nfs, ...)
# storageDir: hdfs:///flink/ha/
# zookeeper:
# # The list of ZooKeeper quorum peers that coordinate the high-availability
# # setup. This must be a list of the form:
# # "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
# quorum: localhost:2181
# client:
# # ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes
# # It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)
# # The default value is "open" and it can be changed to "creator" if ZK security is enabled
# acl: open#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled. Checkpointing is enabled when execution.checkpointing.interval > 0.# # Execution checkpointing related parameters. Please refer to CheckpointConfig and ExecutionCheckpointingOptions for more details.
# execution:
# checkpointing:
# interval: 3min
# externalized-checkpoint-retention: [DELETE_ON_CANCELLATION, RETAIN_ON_CANCELLATION]
# max-concurrent-checkpoints: 1
# min-pause: 0
# mode: [EXACTLY_ONCE, AT_LEAST_ONCE]
# timeout: 10min
# tolerable-failed-checkpoints: 0
# unaligned: false# state:
# backend:
# # Supported backends are 'hashmap', 'rocksdb', or the
# # <class-name-of-factory>.
# type: hashmap
# # Flag to enable/disable incremental checkpoints for backends that
# # support incremental checkpoints (like the RocksDB state backend).
# incremental: false
# checkpoints:
# # Directory for checkpoints filesystem, when using any of the default bundled
# # state backends.
# dir: hdfs://namenode-host:port/flink-checkpoints
# savepoints:
# # Default target directory for savepoints, optional.
# dir: hdfs://namenode-host:port/flink-savepoints#==============================================================================
# Rest & web frontend
#==============================================================================rest:# The address to which the REST client will connect toaddress: dev002# The address that the REST & web server binds to# By default, this is localhost, which prevents the REST & web server from# being able to communicate outside of the machine/container it is running on.## To enable this, set the bind address to one that has access to outside-facing# network interface, such as 0.0.0.0.bind-address: 0.0.0.0# # The port to which the REST client connects to. If rest.bind-port has# # not been specified, then the server will bind to this port as well.# port: 8081# # Port range for the REST and web server to bind to.# bind-port: 8080-8090# web:
# submit:
# # Flag to specify whether job submission is enabled from the web-based
# # runtime monitor. Uncomment to disable.
# enable: false
# cancel:
# # Flag to specify whether job cancellation is enabled from the web-based
# # runtime monitor. Uncomment to disable.
# enable: false#==============================================================================
# Advanced
#==============================================================================# io:
# tmp:
# # Override the directories for temporary files. If not specified, the
# # system-specific Java temporary directory (java.io.tmpdir property) is taken.
# #
# # For framework setups on Yarn, Flink will automatically pick up the
# # containers' temp directories without any need for configuration.
# #
# # Add a delimited list for multiple directories, using the system directory
# # delimiter (colon ':' on unix) or a comma, e.g.:
# # /data1/tmp:/data2/tmp:/data3/tmp
# #
# # Note: Each directory entry is read from and written to by a different I/O
# # thread. You can include the same directory multiple times in order to create
# # multiple I/O threads against that directory. This is for example relevant for
# # high-throughput RAIDs.
# dirs: /tmp# classloader:
# resolve:
# # The classloading resolve order. Possible values are 'child-first' (Flink's default)
# # and 'parent-first' (Java's default).
# #
# # Child first classloading allows users to use different dependency/library
# # versions in their application than those in the classpath. Switching back
# # to 'parent-first' may help with debugging dependency issues.
# order: child-first# The amount of memory going to the network stack. These numbers usually need
# no tuning. Adjusting them may be necessary in case of an "Insufficient number
# of network buffers" error. The default min is 64MB, the default max is 1GB.
#
# taskmanager:
# memory:
# network:
# fraction: 0.1
# min: 64mb
# max: 1gb#==============================================================================
# Flink Cluster Security Configuration
#==============================================================================# Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -
# may be enabled in four steps:
# 1. configure the local krb5.conf file
# 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)
# 3. make the credentials available to various JAAS login contexts
# 4. configure the connector to use JAAS/SASL# # The below configure how Kerberos credentials are provided. A keytab will be used instead of
# # a ticket cache if the keytab path and principal are set.
# security:
# kerberos:
# login:
# use-ticket-cache: true
# keytab: /path/to/kerberos/keytab
# principal: flink-user
# # The configuration below defines which JAAS login contexts
# contexts: Client,KafkaClient#==============================================================================
# ZK Security Configuration
#==============================================================================# zookeeper:
# sasl:
# # Below configurations are applicable if ZK ensemble is configured for security
# #
# # Override below configuration to provide custom ZK service name if configured
# # zookeeper.sasl.service-name: zookeeper
# #
# # The configuration below must match one of the values set in "security.kerberos.login.contexts"
# login-context-name: Client#==============================================================================
# HistoryServer
#==============================================================================# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
#
# jobmanager:
# archive:
# fs:
# # Directory to upload completed jobs to. Add this directory to the list of
# # monitored directories of the HistoryServer as well (see below).
# dir: hdfs:///completed-jobs/# historyserver:
# web:
# # The address under which the web-based HistoryServer listens.
# address: 0.0.0.0
# # The port under which the web-based HistoryServer listens.
# port: 8082
# archive:
# fs:
# # Comma separated list of directories to monitor for completed jobs.
# dir: hdfs:///completed-jobs/
# # Interval in milliseconds for refreshing the monitored directories.
# fs.refresh-interval: 10000dev003 config.yaml:
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################# These parameters are required for Java 17 support.
# They can be safely removed when using Java 8/11.
env:java:opts:all: --add-exports=java.base/sun.net.util=ALL-UNNAMED --add-exports=java.rmi/sun.rmi.registry=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED --add-exports=java.security.jgss/sun.security.krb5=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.net=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/java.text=ALL-UNNAMED --add-opens=java.base/java.time=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.util.concurrent=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.atomic=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.locks=ALL-UNNAMED#==============================================================================
# Common
#==============================================================================jobmanager:# The host interface the JobManager will bind to. By default, this is localhost, and will prevent# the JobManager from communicating outside the machine/container it is running on.# On YARN this setting will be ignored if it is set to 'localhost', defaulting to 0.0.0.0.# On Kubernetes this setting will be ignored, defaulting to 0.0.0.0.## To enable this, set the bind-host address to one that has access to an outside facing network# interface, such as 0.0.0.0.bind-host: 0.0.0.0rpc:# The external address of the host on which the JobManager runs and can be# reached by the TaskManagers and any clients which want to connect. This setting# is only used in Standalone mode and may be overwritten on the JobManager side# by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable.# In high availability mode, if you use the bin/start-cluster.sh script and setup# the conf/masters file, this will be taken care of automatically. Yarn# automatically configure the host name based on the hostname of the node where the# JobManager runs.address: dev001# The RPC port where the JobManager is reachable.port: 6123memory:process:# The total process memory size for the JobManager.# Note this accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead.size: 1600mexecution:# The failover strategy, i.e., how the job computation recovers from task failures.# Only restart tasks that may have been affected by the task failure, which typically includes# downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.failover-strategy: regiontaskmanager:# The host interface the TaskManager will bind to. By default, this is localhost, and will prevent# the TaskManager from communicating outside the machine/container it is running on.# On YARN this setting will be ignored if it is set to 'localhost', defaulting to 0.0.0.0.# On Kubernetes this setting will be ignored, defaulting to 0.0.0.0.## To enable this, set the bind-host address to one that has access to an outside facing network# interface, such as 0.0.0.0.bind-host: 0.0.0.0# The address of the host on which the TaskManager runs and can be reached by the JobManager and# other TaskManagers. If not specified, the TaskManager will try different strategies to identify# the address.## Note this address needs to be reachable by the JobManager and forward traffic to one of# the interfaces the TaskManager is bound to (see 'taskmanager.bind-host').## Note also that unless all TaskManagers are running on the same machine, this address needs to be# configured separately for each TaskManager.host: dev003# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.numberOfTaskSlots: 2memory:process:# The total process memory size for the TaskManager.## Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.# To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.# It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.size: 1728mparallelism:# The parallelism used for programs that did not specify and other parallelism.default: 1# # The default file system scheme and authority.
# # By default file paths without scheme are interpreted relative to the local
# # root file system 'file:///'. Use this to override the default and interpret
# # relative paths relative to a different file system,
# # for example 'hdfs://mynamenode:12345'
# fs:
# default-scheme: hdfs://mynamenode:12345#==============================================================================
# High Availability
#==============================================================================# high-availability:
# # The high-availability mode. Possible options are 'NONE' or 'zookeeper'.
# type: zookeeper
# # The path where metadata for master recovery is persisted. While ZooKeeper stores
# # the small ground truth for checkpoint and leader election, this location stores
# # the larger objects, like persisted dataflow graphs.
# #
# # Must be a durable file system that is accessible from all nodes
# # (like HDFS, S3, Ceph, nfs, ...)
# storageDir: hdfs:///flink/ha/
# zookeeper:
# # The list of ZooKeeper quorum peers that coordinate the high-availability
# # setup. This must be a list of the form:
# # "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
# quorum: localhost:2181
# client:
# # ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes
# # It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)
# # The default value is "open" and it can be changed to "creator" if ZK security is enabled
# acl: open#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled. Checkpointing is enabled when execution.checkpointing.interval > 0.# # Execution checkpointing related parameters. Please refer to CheckpointConfig and ExecutionCheckpointingOptions for more details.
# execution:
# checkpointing:
# interval: 3min
# externalized-checkpoint-retention: [DELETE_ON_CANCELLATION, RETAIN_ON_CANCELLATION]
# max-concurrent-checkpoints: 1
# min-pause: 0
# mode: [EXACTLY_ONCE, AT_LEAST_ONCE]
# timeout: 10min
# tolerable-failed-checkpoints: 0
# unaligned: false# state:
# backend:
# # Supported backends are 'hashmap', 'rocksdb', or the
# # <class-name-of-factory>.
# type: hashmap
# # Flag to enable/disable incremental checkpoints for backends that
# # support incremental checkpoints (like the RocksDB state backend).
# incremental: false
# checkpoints:
# # Directory for checkpoints filesystem, when using any of the default bundled
# # state backends.
# dir: hdfs://namenode-host:port/flink-checkpoints
# savepoints:
# # Default target directory for savepoints, optional.
# dir: hdfs://namenode-host:port/flink-savepoints#==============================================================================
# Rest & web frontend
#==============================================================================rest:# The address to which the REST client will connect toaddress: dev003# The address that the REST & web server binds to# By default, this is localhost, which prevents the REST & web server from# being able to communicate outside of the machine/container it is running on.## To enable this, set the bind address to one that has access to outside-facing# network interface, such as 0.0.0.0.bind-address: 0.0.0.0# # The port to which the REST client connects to. If rest.bind-port has# # not been specified, then the server will bind to this port as well.# port: 8081# # Port range for the REST and web server to bind to.# bind-port: 8080-8090# web:
# submit:
# # Flag to specify whether job submission is enabled from the web-based
# # runtime monitor. Uncomment to disable.
# enable: false
# cancel:
# # Flag to specify whether job cancellation is enabled from the web-based
# # runtime monitor. Uncomment to disable.
# enable: false#==============================================================================
# Advanced
#==============================================================================# io:
# tmp:
# # Override the directories for temporary files. If not specified, the
# # system-specific Java temporary directory (java.io.tmpdir property) is taken.
# #
# # For framework setups on Yarn, Flink will automatically pick up the
# # containers' temp directories without any need for configuration.
# #
# # Add a delimited list for multiple directories, using the system directory
# # delimiter (colon ':' on unix) or a comma, e.g.:
# # /data1/tmp:/data2/tmp:/data3/tmp
# #
# # Note: Each directory entry is read from and written to by a different I/O
# # thread. You can include the same directory multiple times in order to create
# # multiple I/O threads against that directory. This is for example relevant for
# # high-throughput RAIDs.
# dirs: /tmp# classloader:
# resolve:
# # The classloading resolve order. Possible values are 'child-first' (Flink's default)
# # and 'parent-first' (Java's default).
# #
# # Child first classloading allows users to use different dependency/library
# # versions in their application than those in the classpath. Switching back
# # to 'parent-first' may help with debugging dependency issues.
# order: child-first# The amount of memory going to the network stack. These numbers usually need
# no tuning. Adjusting them may be necessary in case of an "Insufficient number
# of network buffers" error. The default min is 64MB, the default max is 1GB.
#
# taskmanager:
# memory:
# network:
# fraction: 0.1
# min: 64mb
# max: 1gb#==============================================================================
# Flink Cluster Security Configuration
#==============================================================================# Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -
# may be enabled in four steps:
# 1. configure the local krb5.conf file
# 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)
# 3. make the credentials available to various JAAS login contexts
# 4. configure the connector to use JAAS/SASL# # The below configure how Kerberos credentials are provided. A keytab will be used instead of
# # a ticket cache if the keytab path and principal are set.
# security:
# kerberos:
# login:
# use-ticket-cache: true
# keytab: /path/to/kerberos/keytab
# principal: flink-user
# # The configuration below defines which JAAS login contexts
# contexts: Client,KafkaClient#==============================================================================
# ZK Security Configuration
#==============================================================================# zookeeper:
# sasl:
# # Below configurations are applicable if ZK ensemble is configured for security
# #
# # Override below configuration to provide custom ZK service name if configured
# # zookeeper.sasl.service-name: zookeeper
# #
# # The configuration below must match one of the values set in "security.kerberos.login.contexts"
# login-context-name: Client#==============================================================================
# HistoryServer
#==============================================================================# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
#
# jobmanager:
# archive:
# fs:
# # Directory to upload completed jobs to. Add this directory to the list of
# # monitored directories of the HistoryServer as well (see below).
# dir: hdfs:///completed-jobs/# historyserver:
# web:
# # The address under which the web-based HistoryServer listens.
# address: 0.0.0.0
# # The port under which the web-based HistoryServer listens.
# port: 8082
# archive:
# fs:
# # Comma separated list of directories to monitor for completed jobs.
# dir: hdfs:///completed-jobs/
# # Interval in milliseconds for refreshing the monitored directories.
# fs.refresh-interval: 10000conf/masters 及 conf/works 使用 xsync 同步分发命令 分发到各机器节点即可:
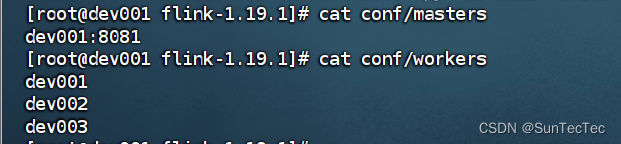
-- masters
dev001:8081-- workers
dev001
dev002
dev003
补充:
linux 查看port是否被占用:nestat -apn|grep 8081
linux 查看各节点flink任务:jps
相关文章:
Flink 1.19.1 standalone 集群模式部署及配置
flink 1.19起 conf/flink-conf.yaml 更改为新的 conf/config.yaml standalone集群: dev001、dev002、dev003 config.yaml: jobmanager address 统一使用 dev001,bind-port 统一改成 0.0.0.0,taskmanager address 分别更改为dev所在host dev001 config.…...
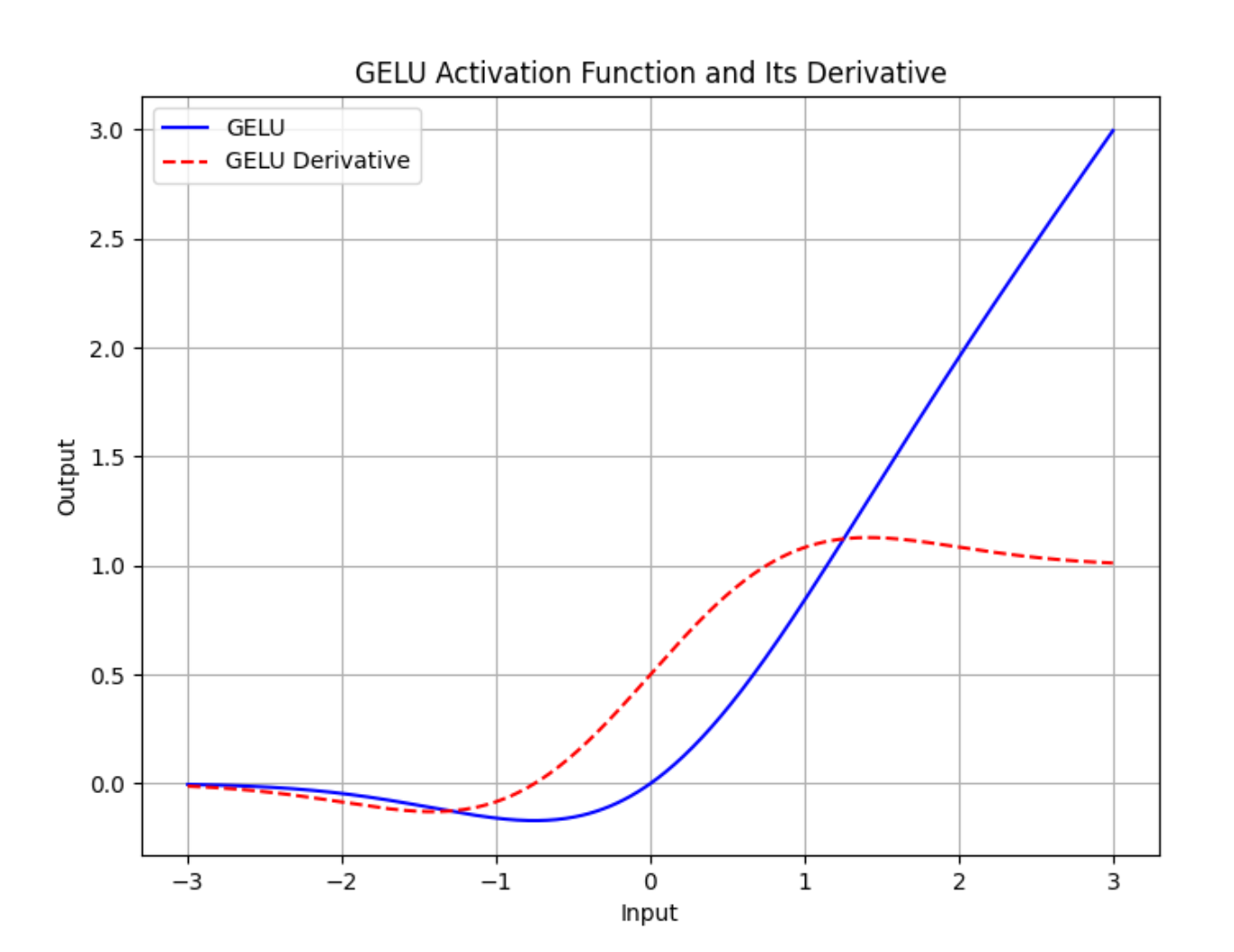
【深度学习】GELU激活函数是什么?
torch.nn.GELU 模块在 PyTorch 中实现了高斯误差线性单元(GELU)激活函数。GELU 被用于许多深度学习模型中,包括Transformer,因为它相比传统的 ReLU(整流线性单元)函数能够更好地近似神经元的真实激活行为。…...

如何编译和运行您的第一个Java程序
如何编译和运行您的第一个Java程序 让我们从一个简单的java程序开始。 简单的Java程序 这是一个非常基本的java程序,它会打印一条消息“这是我在java中的第一个程序”。 public class FirstJavaProgram {public static void main(String[] args){System.…...

vscode用vue框架写一个登陆页面
目录 一、创建登录页面 二、构建好登陆页面的路由 三、编写登录页代码 1.添加基础结构 2.给登录页添加背景 3.解决填充不满问题 4.我们把背景的红颜色替换成背景图: 5.在页面中央添加一个卡片来显示登录页面 6.设置中间卡片页面的左侧 7.设置右侧的样式及…...

腾讯云API安全保障措施?有哪些调用限制?
腾讯云API的调用效率如何优化?怎么使用API接口发信? 腾讯云API作为腾讯云提供的核心服务之一,广泛应用于各行各业。然而,随着API应用的普及,API安全问题也日益突出。AokSend将详细探讨腾讯云API的安全保障措施&#x…...

在建设工程合同争议案件中,如何来认定“竣工验收”?
在建设工程合同争议案件中,如何来认定“竣工验收”? 建设工程的最终竣工验收,既涉及在建设单位组织下的五方单位验收,又需政府质量管理部门的监督验收以及竣工验收备案,工程档案还需递交工程所在地的工程档案馆归档。…...
Linux:多线程中的互斥与同步
多线程 线程互斥互斥锁互斥锁实现的原理封装原生线程库封装互斥锁 死锁避免死锁的四种方法 线程同步条件变量 线程互斥 在多线程中,如果存在有一个全局变量,那么这个全局变量会被所有执行流所共享。但是,资源共享就会存在一种问题࿱…...

数据仓库之主题域
数据仓库的主题域(Subject Area)是按照特定业务领域或主题对数据进行分类和组织的方式。每个主题域集中反映一个特定的业务方面,使得数据分析和查询更加清晰和高效。主题域通常与企业的关键业务过程相关,能够帮助用户在数据仓库中…...

【简易版tinySTL】 vector容器
文章目录 基本概念功能思路代码实现vector.htest.cpp 代码详解变量构造函数析构函数拷贝构造operatorpush_backoperator[]insertprintElements 本实现版本 和 C STL标准库实现版本的区别: 基本概念 vector数据结构和数组非常相似,也称为单端数组vector与…...
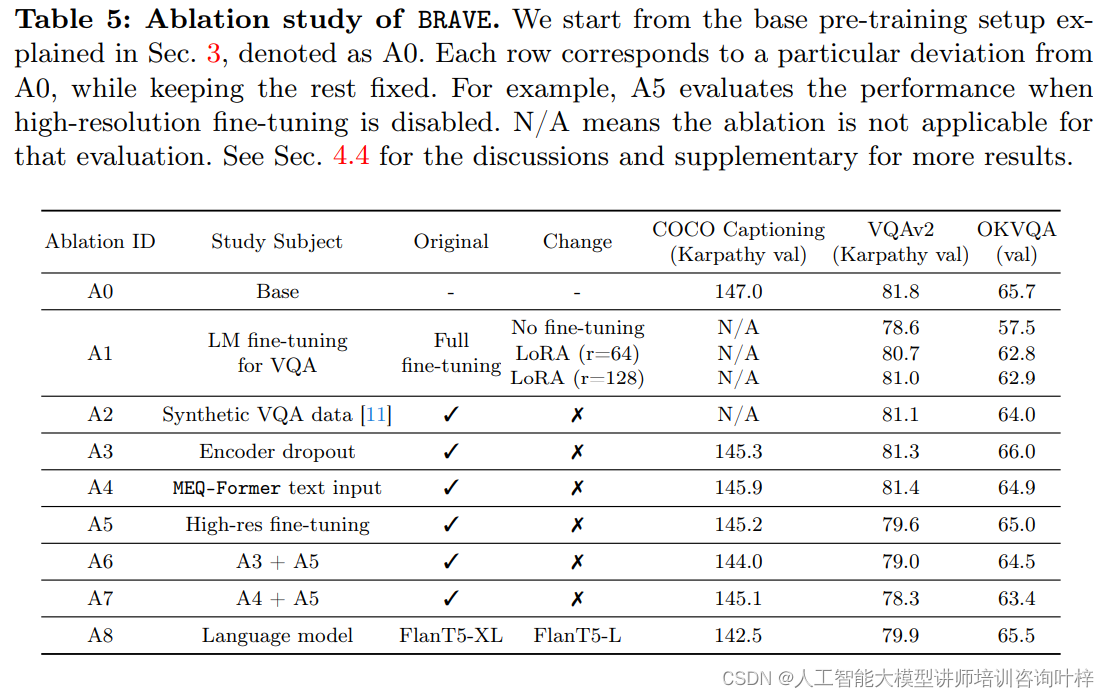
BRAVE:扩展视觉编码能力,推动视觉-语言模型发展
视觉-语言模型(VLMs)在理解和生成涉及视觉与文本的任务上取得了显著进展,它们在理解和生成结合视觉与文本信息的任务中扮演着重要角色。然而,这些模型的性能往往受限于其视觉编码器的能力。例如,现有的一些模型可能对某…...

使用 Verdaccio 建立私有npm库
网上有很多方法,但很多没标注nginx的版本所以踩了一些坑,下方这个文档是完善后的,对linux不是很熟练,所以不懂linux不会搭建的跟着做就可以了 搭建方法 首先需要一台云服务器 以139.196.226.123为例登录云服务器 下载node cd /usr/local/lib下载node 解压 下载 wget https://…...
)
个人职业规划(含前端职业+技术线路)
1. 了解自己的兴趣与长处 喜欢擅长的事 职业方向 2. 设定长期目标(5年) 目标内容 建立自己的品牌建立自己的社交网络 适量参加社交活动,认识更多志同道合的小伙伴寻求导师指导 建立自己的作品集 注意事项 每年元旦进行审视和调整永葆积极…...
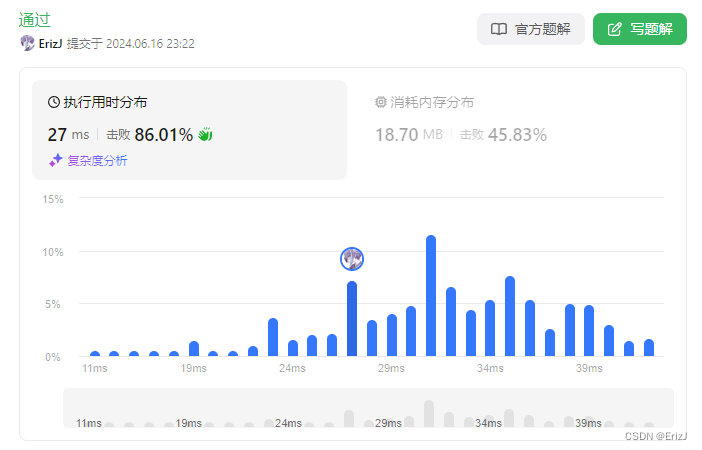
LeetCode | 344.反转字符串
设置头尾两个指针,依靠中间变量temp交换头尾指针所指元素,头指针后移,尾指针前移,直到头尾指针重合或者头指针在尾指针后面一个元素 class Solution(object):def reverseString(self, s):""":type s: List[str]:r…...

一步一步用numpy实现神经网络各种层
1. 首先准备一下数据 if __name__ "__main__":data np.array([[2, 1, 0],[2, 2, 0],[5, 4, 1],[4, 5, 1],[2, 3, 0],[3, 2, 0],[6, 5, 1],[4, 1, 0],[6, 3, 1],[7, 4, 1]])x data[:, :-1]y data[:, -1]for epoch in range(1000):...2. 实现SoftmaxCrossEntropy层…...
)
vue学习(二)
9.vue中的数据代理 通过vm对象来代理data对象中的属性操作(读写),目的是为了更加方便操作data中的数据 基本原理:通过Object.defineProperty()把data对象所有属性添加到vm上,为每一个添加到vm上的属性,都增…...
Maven 介绍
Maven open in new window 官方文档是这样介绍的 Maven 的: Apache Maven is a software project management and comprehension tool. Based on the concept of a project object model (POM), Maven can manage a projects build, reporting and documentation fr…...

QT截图程序三-截取自定义多边形
上一篇文章QT截图程序,可多屏幕截图二,增加调整截图区域功能-CSDN博客描述了如何截取,具备调整边缘功能后已经方便使用了,但是与系统自带的程序相比,似乎没有什么特别,只能截取矩形区域。 如果可以按照自己…...

Unity的三种Update方法
1、FixedUpdate 物理作用——处理物理引擎相关的计算和刚体的移动 (1) 调用时机:在固定的时间间隔内,而不是每一帧被调用 (2) 作用:用于处理物理引擎的计算,例如刚体的移动和碰撞检测 (3) 特点:能更准确地处理物理…...
[Python学习篇] Python字典
字典是一种可变的、无序的键值对(key-value)集合。字典在许多编程(Java中的HashMap)任务中非常有用,因为它们允许快速查找、添加和删除元素。字典使用花括号 {} 表示。字典是可变类型。 语法: 变量 {key1…...

react项目中如何书写css
一:问题: 在 vue 项目中,我们书写css的方式很简单,就是在 .vue文件中写style标签,然后加上scope属性,就可以隔离当前组件的样式,但是在react中,是没有这个东西的,如果直…...

Windows热键冲突终极指南:如何用Hotkey Detective一键精准定位占用程序
Windows热键冲突终极指南:如何用Hotkey Detective一键精准定位占用程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detecti…...

3步搞定显卡风扇异常:用FanControl彻底解决NVIDIA风扇噪音和转速问题
3步搞定显卡风扇异常:用FanControl彻底解决NVIDIA风扇噪音和转速问题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitH…...

终极指南:如何用文字描述快速生成专业CAD图纸
终极指南:如何用文字描述快速生成专业CAD图纸 【免费下载链接】text-to-cad-ui A lightweight UI for interacting with the Zoo Text-to-CAD API. 项目地址: https://gitcode.com/gh_mirrors/te/text-to-cad-ui 还在为复杂的CAD软件界面感到困惑吗ÿ…...

【函数栈帧的创建和销毁:一文看懂 C/C++ 函数调用的底层秘密】
本文适合:被“局部变量为什么是随机值”、“函数怎么传参”、“返回值怎么带回来”这些问题困扰过的初学者。 文末会解释:为什么返回局部变量的引用有时能打印出正确值,但依然是错的?Hello,大家好呀,这里是小J,函数栈帧…...

NoFences:免费开源的Windows桌面整理神器,让杂乱图标瞬间归位
NoFences:免费开源的Windows桌面整理神器,让杂乱图标瞬间归位 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为Windows桌面上堆积如山的图标而烦…...

萨科微宋仕强“华强北山寨手机”研究
萨科微宋仕强“华强北山寨手机”研究(十六),手机的灰色产业链。华强北每个手机柜台背后都有灰色供应链支撑。如香港手机比华强北便宜,就通过各种渠道从香港走私过来。沙头角的中英街两边分属于香港和深圳,香港一侧的走…...

讲讲IO复用三个函数的底层逻辑
在 Linux 网络编程中,IO 复用是高并发服务的核心基石。我们熟知的 Nginx、Redis、日志服务、后端网关,全部都是基于 IO 复用实现高并发。很多同学只会用 select / poll / epoll 这三个函数,但完全不懂内核底层到底发生了什么,遇到…...

OpenRGB:终结RGB灯光管理混乱的终极免费方案
OpenRGB:终结RGB灯光管理混乱的终极免费方案 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcProgrammer1/OpenRGB. Releases can be…...

Unlock Music终极指南:5分钟掌握音乐格式转换的隐藏技巧
Unlock Music终极指南:5分钟掌握音乐格式转换的隐藏技巧 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: htt…...

云厂商AI基础设施争夺战:Bedrock、Azure AI Studio与Vertex AI深度对比
1. 项目概述:一场没有硝烟的AI基础设施争夺战你打开云厂商控制台,发现“Bedrock”“Azure AI Studio”“Vertex AI”这些名字突然变得比以前更醒目;你翻看技术团队的采购清单,GPU实例价格单旁多了一行加粗标注:“含专属…...