ElasticSearch学习笔记(二)文档操作、RestHighLevelClient的使用
文章目录
- 前言
- 3 文档操作
- 3.1 新增文档
- 3.2 查询文档
- 3.3 修改文档
- 3.3.1 全量修改
- 3.3.2 增量修改
- 3.4 删除文档
- 4 RestAPI
- 4.1 创建数据库和表
- 4.2 创建项目
- 4.3 mapping映射分析
- 4.4 初始化客户端
- 4.5 创建索引库
- 4.6 判断索引库是否存在
- 4.7 删除索引库
- 5 RestClient操作文档
- 5.1 准备工作
- 5.2 新增文档
- 5.3 查询文档
前言
ElasticSearch学习笔记(一)倒排索引、ES和Kibana安装、索引操作
3 文档操作
3.1 新增文档
语法:
POST /{索引库名}/_doc/{文档id}
{"字段1": "值1","字段2": "值2","字段3": {"子属性1":"值3","子属性2":"值4"}// ...
}
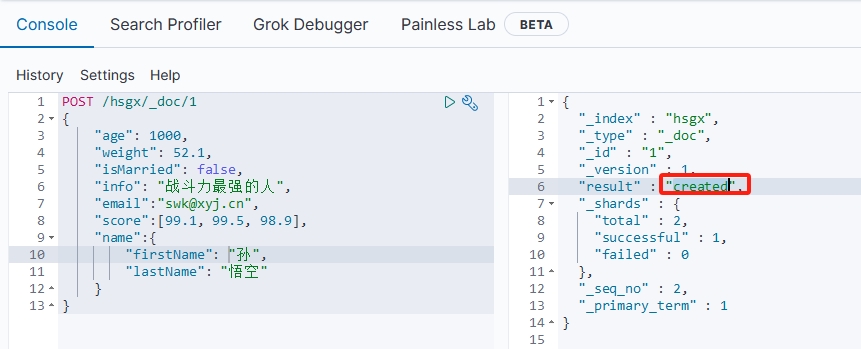
3.2 查询文档
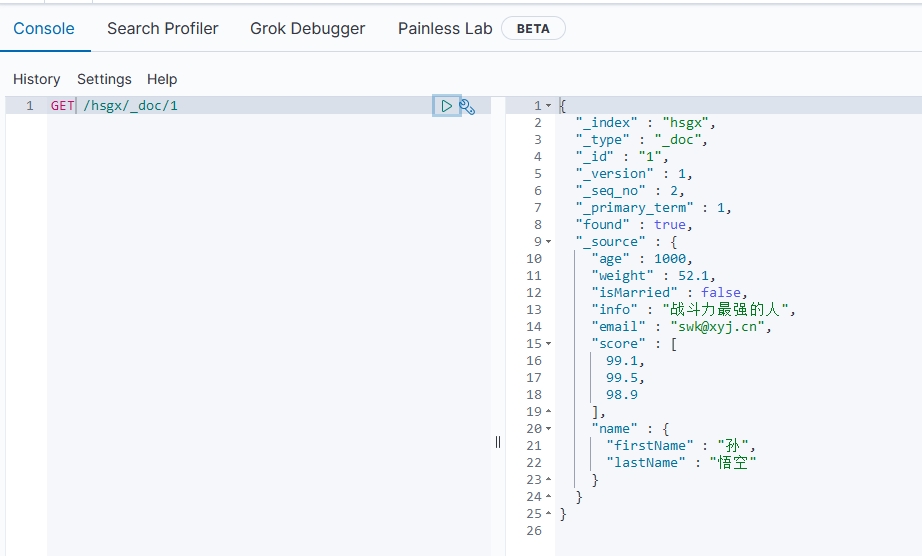
语法:
GET /{索引库名}/_doc/{文档id}
3.3 修改文档
3.3.1 全量修改
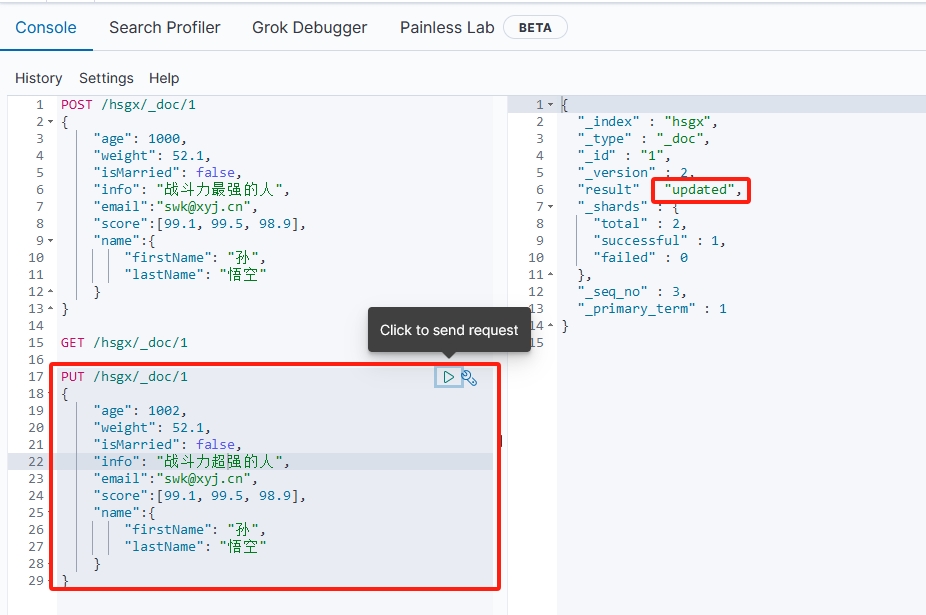
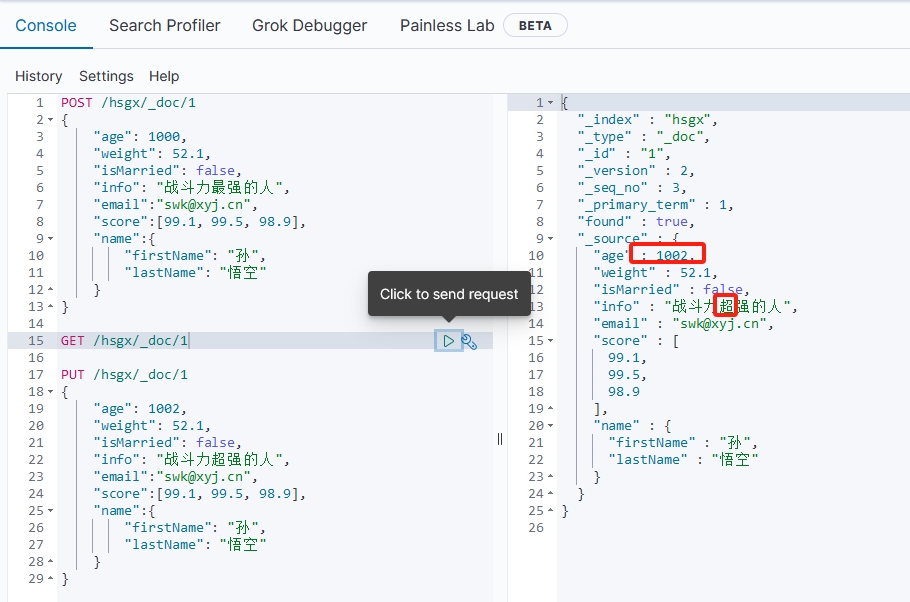
全量修改是覆盖原来的文档,其本质是先根据指定的id删除文档(id对应的文档不存在也可以),再新增一个相同id的文档。
语法:
PUT /{索引库名}/_doc/{文档id}
{"字段1": "值1","字段2": "值2","字段3": {"子属性1":"值3","子属性2":"值4"}// ...
}
3.3.2 增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/{文档id}
{"doc": {"修养修改的字段": "新值"}
}
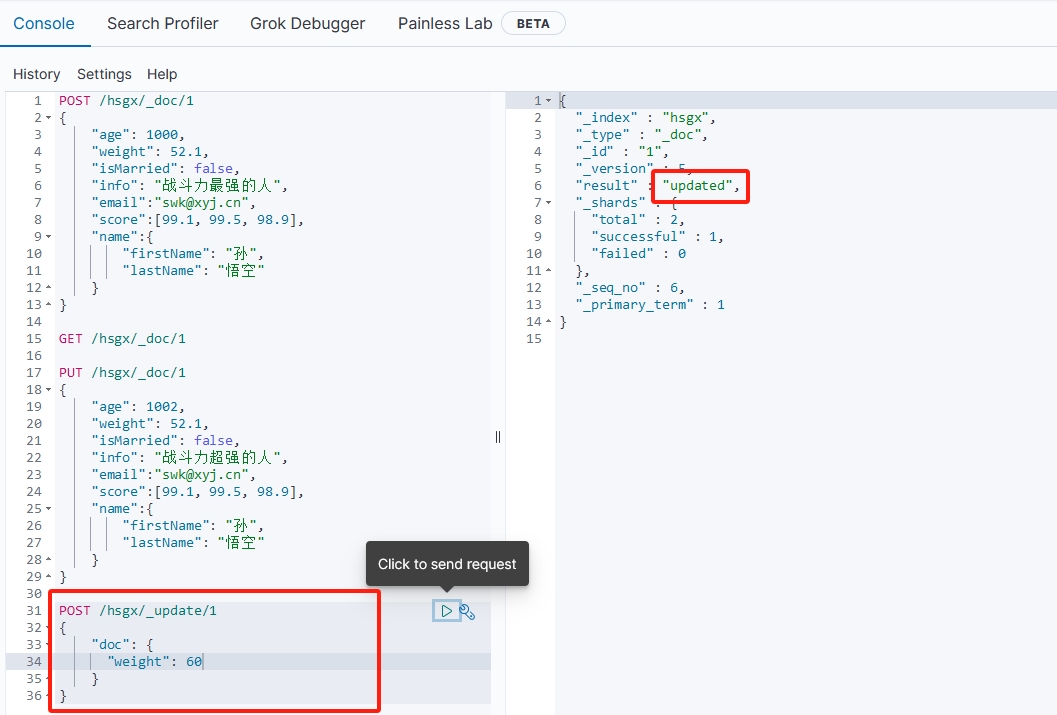

3.4 删除文档
语法:
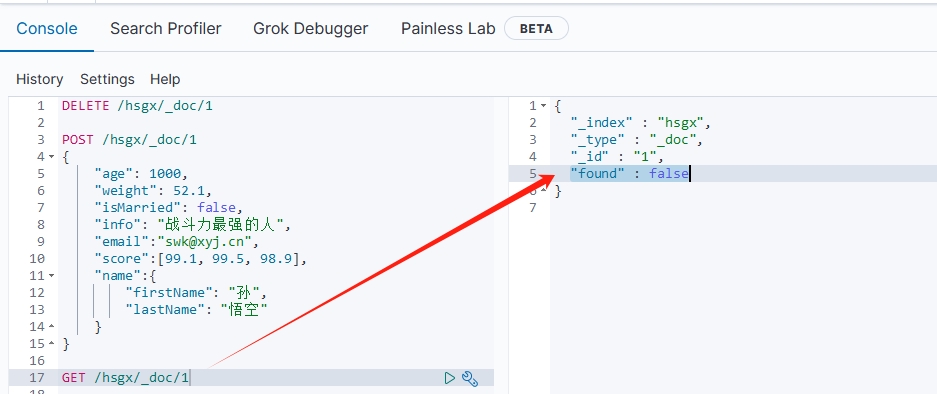
DELETE /{索引库名}/_doc/{文档id}

4 RestAPI
ES官方提供了各种不同语言的客户端用来操作ES,这些客户端的本质是组装DSL语句,通过Http请求发送给ES。其官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html
其中Java语言的客户端分为两种:

本文章学习的是high-level REST client。
4.1 创建数据库和表
CREATE DATABASE hsgx;
USE hsgx;
CREATE TABLE tb_hotel (`id` BIGINT(20) NOT NULL PRIMARY KEY COMMENT '酒店id',`name` VARCHAR(255) NOT NULL COMMENT '酒店名称',`address` VARCHAR(255) NOT NULL COMMENT '酒店地址',`price` INT(10) NOT NULL COMMENT '酒店价格',`score` INT(2) NOT NULL COMMENT '酒店评分',`brand` VARCHAR(32) NOT NULL COMMENT '酒店品牌',`city` VARCHAR(32) NOT NULL COMMENT '所在城市',`star_name` VARCHAR(16) NOT NULL COMMENT '酒店星级',`business` VARCHAR(255) NOT NULL COMMENT '商圈',`latitude` VARCHAR(32) NOT NULL COMMENT '纬度',`longitude` VARCHAR(32) NOT NULL COMMENT '经度',`pic` VARCHAR(255) DEFAULT NULL COMMENT '酒店图片'
);INSERT INTO tb_hotel(`id`, `name`, `address`, `price`, `score`, `brand`, `city`, `star_name`, `business`, `latitude`, `longitude`, `pic`)
VALUES (1, '白天鹅', '中山路', 888, 5, '白天鹅', '广州', '五星', '太古汇', '123.456', '456.748', 'a.png'),
(2, '希尔顿', '南京路', 456, 4.5, '希尔顿', '上海', '四星', '外滩', '123.456', '456.748', 'b.png');
4.2 创建项目
在IDEA中创建一个maven项目,结构如下:
4.3 mapping映射分析
mapping映射分析要考虑的信息包括:
- 字段名:参考表结构。
- 字段数据类型:参考表结构。
- 是否参与搜索:根据具体业务进行判断。
- 是否需要分词:根据具体内容进行判断,如果内容是一个整体就无需分词,反之则要分词。
- 分词器是什么:可以统一使用ik_max_word。
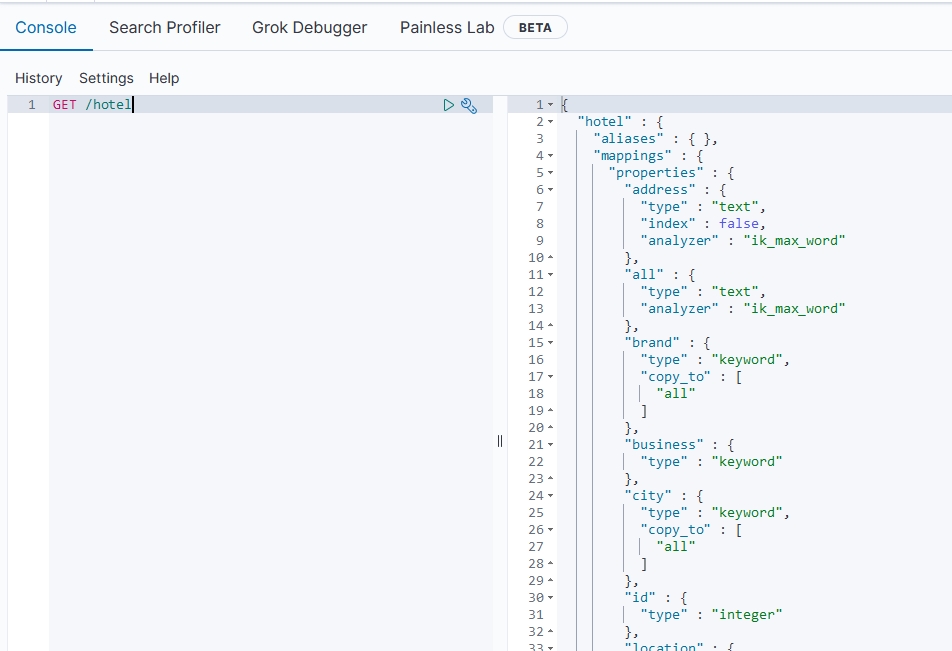
对应到tb_hotel表,我们可以新建如下索引:
PUT /hotel
{"mappings": {"properties": {"id": {"type": "integer"},"name":{"type": "text","analyzer": "ik_max_word","copy_to": "all"},"address":{"type": "text","analyzer": "ik_max_word","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword","copy_to": "all"},"starName":{"type": "keyword"},"business":{"type": "keyword"},"pic":{"type": "keyword","index": false},"location":{"type": "geo_point"},"all":{"type": "text","analyzer": "ik_max_word"}}}
}
其中,有两个比较特殊的字段:
- location:地理坐标,类型是
geo_point,表示由经度(latitude)和纬度(longitude)确定一个点。 - all:一个组合字段,其目的是将多字段的值 利用
copy_to属性合并,提供给用户搜索。在上面的例子中,name、brand、city字段会合并到一起。
4.4 初始化客户端
Java客户端中,与ES一切交互都封装在一个名为RestHighLevelClient的类中,必须先完成这个对象的初始化,建立与ES的连接。主要步骤如下:
- 1)引入依赖,注意版本号和安装的ES版本一致
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.12.1</version>
</dependency>
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>7.12.1</version>
</dependency>
<dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.12.1</version>
</dependency>
- 2)初始化RestHighLevelClient
private RestHighLevelClient client;@Before
void setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.153.128:9200")));
}@After
void close() throws IOException {this.client.close();
}
4.5 创建索引库
private static final String DSL = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"integer\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"index\": false\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"score\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"starName\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"business\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"pic\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"location\":{\n" +" \"type\": \"geo_point\"\n" +" },\n" +" \"all\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";@Test
public void testCreateHotelIndex() throws IOException {// 1.参数为索引库名称CreateIndexRequest createIndexRequest = new CreateIndexRequest("hotel");// 2.设置mapping映射createIndexRequest.source(DSL, XContentType.JSON);// 3.发起创建索引库请求client.indices().create(createIndexRequest, RequestOptions.DEFAULT);
}
由以上代码可知,创建索引库的步骤主要又三步:
- 1)创建Request对象。创建索引库的操作对应的Request对象是CreateIndexRequest。
- 2)设置mapping映射,其实就是DSL的JSON参数部分。因为JSON字符串很长,所以定义了一个静态字符串常量来表示,让代码看起来更加优雅。
- 3)发送创建索引库请求,
client.indices()方法的返回值是IndicesClient类型,封装了所有与索引库操作有关的方法。

执行以上单元测试,在DevTools工具中查询该索引库:
4.6 判断索引库是否存在
判断索引库是否存在,本质是使用GET命令查询索引库,因此它对应的Request对象是GetIndexRequest。
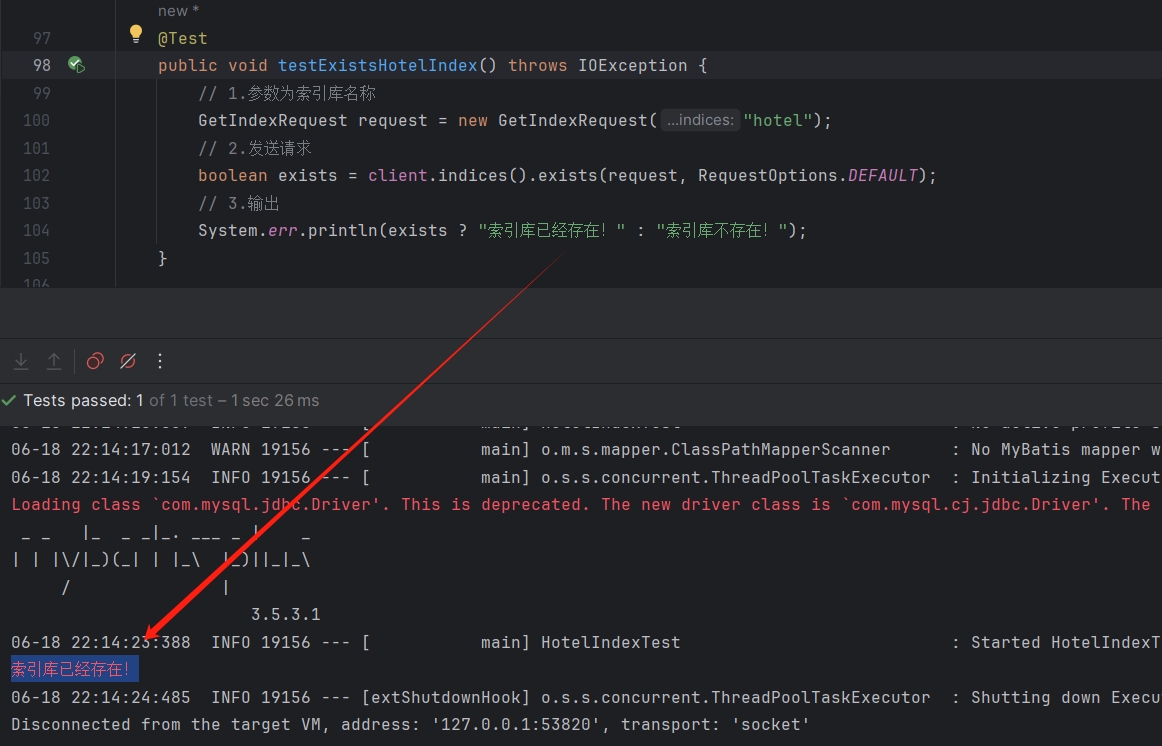
@Test
public void testExistsHotelIndex() throws IOException {// 1.参数为索引库名称GetIndexRequest request = new GetIndexRequest("hotel");// 2.发送请求boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);// 3.输出System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");
}
执行以上单元测试,结果如下:
4.7 删除索引库
删除索引库对应的Request对象是DeleteIndexRequest。
@Test
public void testDeleteHotelIndex() throws IOException {// 1.参数为索引库名称DeleteIndexRequest request = new DeleteIndexRequest("hotel");// 2.发送请求client.indices().delete(request, RequestOptions.DEFAULT);
}
执行以上单元测试,在DevTools工具中查询该索引库:

5 RestClient操作文档
5.1 准备工作
由于上文定义的索引库hotel的mapping映射与数据库表结构有一些差异,因此还需要定义一个新的实体类,与索引库的mapping映射对应起来:
@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();}
}
主要的区别在于,将latitude、longitude两个字段合并为location一个字段。
5.2 新增文档
新增文档的DSL语句示例如下:
POST /hotel/_doc/1
{"name": "白天鹅","score": 5
}
对应的Java代码如下:
@Test
public void testCreateDocIndex() throws IOException {// 1.POST /hotel/_doc/1 { "name": "白天鹅", "score": 5 }IndexRequest request = new IndexRequest("hotel").id("1");request.source("{\"name\": \"白天鹅\", \"score\": 5}", XContentType.JSON)// 2.发送请求client.index(request, RequestOptions.DEFAULT);
}
执行以上单元测试,在DevTools工具中查询该文档:

下面实现把数据库tb_hotel表的数据读取出来,并保存到ES中:
@Test
public void testSaveHotel() throws IOException {// 1.根据id查询酒店数据Hotel hotel = hotelService.getById(2);// 2.转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);// 3.将HotelDoc转jsonString json = JSON.toJSONString(hotelDoc);// 4.准备Request对象IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());// 5.准备Json文档request.source(json, XContentType.JSON);// 6.发送请求client.index(request, RequestOptions.DEFAULT);
}
执行以上单元测试,在DevTools工具中查询该文档:

5.3 查询文档
新增文档的DSL语句示例如下:
GET /hotel/_doc/2
对应的Java代码如下:
@Test
public void testQueryHotelDoc() throws IOException {// 1.创建Request对象GetRequest request = new GetRequest("hotel", "2");// 2.发送请求GetResponse response = client.get(request, RequestOptions.DEFAULT);// 3.解析结果String json = response.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println(hotelDoc);
}
执行以上单元测试,结果如下:

…
本节完,更多内容请查阅分类专栏:微服务学习笔记
感兴趣的读者还可以查阅我的另外几个专栏:
- SpringBoot源码解读与原理分析
- MyBatis3源码深度解析
- Redis从入门到精通
- MyBatisPlus详解
- SpringCloud学习笔记
相关文章:
ElasticSearch学习笔记(二)文档操作、RestHighLevelClient的使用
文章目录 前言3 文档操作3.1 新增文档3.2 查询文档3.3 修改文档3.3.1 全量修改3.3.2 增量修改 3.4 删除文档 4 RestAPI4.1 创建数据库和表4.2 创建项目4.3 mapping映射分析4.4 初始化客户端4.5 创建索引库4.6 判断索引库是否存在4.7 删除索引库 5 RestClient操作文档5.1 准备工…...

python离线安装第三方库、及其依赖库(单个安装,非批量移植)
文章目录 1.外网下载第三方库、依赖库2.内网安装第三方库3.补充附录内网中离线安装python第三方库,这时候只能去外网手动下载第三方库,再传回内网进行安装。 问题是python第三方库往往有其前置依赖包,你很难清楚某个第三方库依赖的是哪些依赖包,更难受的是依赖包可能还有其…...

昨天发的 npm 包,却因为 registry 同步问题无法安装使用
用过 HBuilderX 云打包的都知道,云上面的 Android 环境很有限,其实并不能覆盖 uniapp 生态所有的版本,甚至说只能覆盖最新的一两个版本。 如果你需要用到 HBuilderX 安卓云打包,就必须及时跟进 HBuilderX 的版本更新,…...

Redis 数据恢复及持久化策略分析
在分布式系统中,Redis作为高性能的键值存储数据库,广泛应用于缓存、会话管理、消息队列等场景。对于Redis数据的可靠性,持久化是至关重要的一环。当Redis宕机时,如何恢复数据成为一个关键问题。这篇文章将详细分析Redis的数据恢复…...

vscode 快捷键侧边栏
_____ 配置 vscode 快捷键 visual studio code - open explorer and close sidebar with the same key - Stack Overflow { "key": "ctrlshifte", // when Explorer not open // "command": "workbench.view.explorer", // either…...

FreeRTOS:1、任务通知vTaskNotifyGiveFromISR保证实时性
文章目录 背景解释意义 背景 首先,我们看以下代码: #include "FreeRTOS.h" #include "task.h"TaskHandle_t s_task_handle NULL;void vTaskFunction(void *pvParameters) {for (;;) {// 等待通知ulTaskNotifyTake(pdTRUE, portMA…...

监督学习:从数据中学习预测模型的艺术与科学
目录 引言 一、监督学习的基本概念 1、数据集 2、特征 3、标签 4、模型 二、监督学习的原理和方法 1、基本原理 2、常用方法 三、监督学习的定义与分类 1、 定义 2.、分类 四、为什么是监督学习? 1、 明确的学习目标 2、高准确率 3、易于评估 4、 …...
中的垃圾回收器)
深入理解Java虚拟机(JVM)中的垃圾回收器
垃圾回收(Garbage Collection, GC)是现代编程语言中用于管理内存的重要机制,特别是在Java虚拟机(JVM)中。 它的基本原理是自动检测和释放不再被程序使用的内存,以避免内存泄漏和提高程序执行效率。 1.GC的基…...

视频集市新增支持多格式流媒体拉流预览
流媒体除了常用实时流外还有大部分是以文件的形式存在,做融合预览必须要考虑多种兼容性能力,借用现有的ffmpeg生态可以迅速实现多种格式的支持,现在我们将按需拉流预览功能进行了拓展,正式支持了ffmpeg的功能,可快捷方…...

定时器-前端使用定时器3s轮询状态接口,2min为接口超时
背景 众所周知,后端是处理不了复杂的任务的,所以经过人家的技术讨论之后,把业务放在前端来实现。记录一下这次的离大谱需求吧。 如图所示,这个页面有5个列表,默认加载计划列表。但是由于后端的种种原因,这…...
: 类和对象)
python实践笔记(二): 类和对象
1. 写在前面 最近在重构之前的后端代码,借着这个机会又重新补充了关于python的一些知识, 学习到了一些高效编写代码的方法和心得,比如构建大项目来讲,要明确捕捉异常机制的重要性, 学会使用try...except..finally&…...

指定GPU跑模型
加上一个CUDA_VISIBLE_DEVICES0,2就行了,使用0卡和2卡跑模型,注意多卡有时候比单卡慢,4090无NVlink,数据似乎是通过串行的方式传输到多个gpu的,只不过单个gpu是并行计算,数据在gpu与gpu之间似乎是串行传输的…...

Windows桌面运维----第五天
1、华为路由怎们配置IP、划分vlan、互通: 1、用户模式→系统模式; 2、进入相关端口,配置IP地址; 3、开通相应vlan,设置vlanX、IP地址; 4、绑定相关端口,设置端口类型; 5、电脑设置IP&#…...
)
bash和dash的区别(及示例)
什么是bash、dash Bash(GNU Bourne-Again Shell)是许多Linux平台的内定Shell,事实上,还有许多传统UNIX上用的Shell,像tcsh、csh、ash、bsh、ksh等等。 GNU/Linux 操作系统中的 /bin/sh 本是 bash (Bourne-Again Shell) 的符号链接࿰…...

Java基础入门day65
day65 web项目 页面设计 仿照小米官网,将首页保存到本地为一个html页面,再将html页面保存为jsp页面,在项目中的web.xml文件中配置了欢迎页 <welcome-file-list><welcome-file>TypesServlet</welcome-file> </welcome-…...

解密制度的规定和解密工作的具体流程
解密制度是指对于某些敏感的文件或资料,经过一定的时间后,根据相关规定和程序,可以进行解密,解除文件的保密状态,使其可以被公众查阅或利用。解密制度的目的在于确保涉密信息的保密等级与其重要程度相适应,防止涉密信息的泄露和使用不当,同时促进信息公开、传播历史知识…...

实际中常用的网络相关命令
一、ping命令 ping是个使用频率极高的实用程序,主要用于确定网络的连通性。这对确定网络是否正确连接,以及网络连接的状况十分有用。 简单的说,ping就是一个测试程序,如果ping运行正确,大体上就可以排除网络访问层、网…...

机器学习补充
一、数据抽样 数据预处理阶段:对数据集进行抽样可以帮助减少数据量,加快模型训练的速度/减少计算资源的消耗,特别是当数据集非常庞大时,比如设置sample_rate0.8.平衡数据集:通过抽样平衡正负样本,提升模型…...
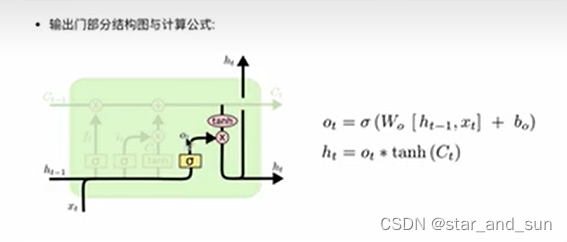
机器学习——RNN、LSTM
RNN 特点:输入层是层层相关联的,输入包括上一个隐藏层的输出h1和外界输入x2,然后融合一个张量,通过全连接得到h2,重复 优点:结构简单,参数总量少,在短序列任务上性能好 缺点&#x…...
Java项目学习(员工管理)
新增、员工列表、编辑员工整体代码流程与登录基本一致。 1、新增员工 RestController RequestMapping("/admin/employee")EmployeeController 类中使用了注解 RestController 用于构建 RESTful 风格的 API,其中每个方法的返回值会直接序列化为 JSON 或…...

FanControl终极指南:Windows电脑风扇智能控制软件完全解析
FanControl终极指南:Windows电脑风扇智能控制软件完全解析 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

AI系统可观测性:从数据漂移到模型性能的全面监控实践
1. 项目概述:为什么AI系统需要独立的可观测性体系?最近几年,我参与和主导了不下十个所谓的“AI驱动”或“智能”系统的构建与运维。从最初的兴奋到后来的头疼,一个深刻的体会是:传统的监控和日志体系,在AI系…...

CSS如何实现一致的圆角半径设计_通过CSS变量存储border-radius
能,但需注意变量作用域、fallback机制及单位完整性;推荐:root定义基础值并用var(--radius-md, 8px),避免嵌套覆盖与无单位变量,旧浏览器需前置静态值。border-radius 用 CSS 变量统一管理,真能省事?能&…...

RO-ViT:区域感知预训练如何革新开放词汇目标检测
1. 项目概述:从“闭门造车”到“开箱即用”的视觉检测新范式在计算机视觉领域,目标检测一直是个硬骨头。传统的检测模型,比如我们熟悉的Faster R-CNN、YOLO系列,都遵循一个“闭集”范式:模型在训练时见过多少类物体&am…...

Slurm集群GPU资源管理实战:如何用`--gres=gpu`参数正确调度你的GTX1080Ti?
Slurm集群GPU资源管理实战:如何用--gresgpu参数正确调度你的GTX1080Ti? 在AI研究与数据科学领域,GPU资源的高效利用直接关系到模型训练与实验的成败。许多团队虽然配备了GTX1080Ti等高性能显卡,却常因Slurm集群调度不当导致资源闲…...

AI技能学习路径全解析:从数学基础到RAG实战与项目构建
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“HieuNghi-AI-Skills”。光看这个名字,你可能会有点摸不着头脑,这到底是做什么的?是教AI新技能,还是整理AI工具的使用技巧?点进去之后&…...

全方位降本增效,Captain AI重构OZON运营成本结构
当前OZON市场竞争日趋激烈,人力、物流、广告、库存等各项运营成本持续攀升,利润空间不断压缩,“降本”与“增效”成为商家生存发展的核心命题。不同于单一工具仅能优化某一项成本,Captain AI立足OZON商家全运营场景,以…...

RISC-V汽车电子开发:功能安全认证工具链的挑战与实践
1. 项目概述:RISC-V在汽车领域的破局与挑战最近和几个在主机厂和Tier 1做嵌入式开发的老朋友聊天,话题总绕不开芯片选型和开发工具。大家普遍的感觉是,传统的Arm架构虽然生态成熟,但在追求极致能效比和定制化的今天,成…...

SAP Fiori Launchpad Designer保姆级教程:手把手教你为ME29N采购订单审批创建自定义磁贴
SAP Fiori Launchpad Designer保姆级教程:手把手教你为ME29N采购订单审批创建自定义磁贴 当你所在的企业尚未部署HR模块,却需要快速启用ME29N采购订单审批功能时,SAP Fiori Launchpad Designer(FLPD_CUST)将成为你的得…...

New-API数据导出功能:轻松管理AI模型使用记录与账单数据
New-API数据导出功能:轻松管理AI模型使用记录与账单数据 【免费下载链接】new-api A unified AI model hub for aggregation & distribution. It supports cross-converting various LLMs into OpenAI-compatible, Claude-compatible, or Gemini-compatible for…...