YOLOv10改进 | Neck | 添加双向特征金字塔BiFPN【含二次独家创新】
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录:《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有40+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进
针对在特征提取过程中,特征信息丢失,特征提取能力不足等问题,研究人员提出了一种加权双向特征金字塔网络(BiFPN),它允许简单快速的多尺度特征融合;可以同时统一缩放所有主干网络、特征网络以及边界框/类别预测网络的分辨率、深度和宽度。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址:YOLOv10入门 + 涨点——持续更新各种涨点方法
目录
1. 原理
2.BiFPN代码实现
2.1 将BiFPN代码添加到YOLOv10种
2.2 更改init.py文件
2.3 添加yaml文件
2.4 在task.py中进行注册
2.5 执行程序
3. 完整代码分享
4. GFLOPs
5. 进阶
6. 总结
1. 原理

论文地址:EfficientDet: Scalable and Efficient Object Detection——点击即可跳转
官方代码:BiFPN官方代码仓库——点击即可跳转
BIFPN,全称为双向特征金字塔网络(Bidirectional Feature Pyramid Network),是一种用于目标检测和图像分割的神经网络架构。它在EfficientDet和其他一些计算机视觉任务中被广泛使用。BIFPN的设计目标是提高特征融合的效率和效果,使得模型在计算资源有限的情况下仍能保持高性能。以下是对BIFPN的详细讲解:
背景
在计算机视觉任务中,特征金字塔网络(FPN)是一种常用的方法,它通过构建不同尺度的特征图来捕获不同尺度的目标。然而,传统的FPN存在一些缺点,如特征融合效率低、信息流通不充分等。BIFPN则通过引入双向的特征融合机制和加权的特征融合方法来克服这些问题。
核心思想
-
双向特征融合: 传统的FPN是单向的,即从高层特征图向低层特征图传递信息。而BIFPN在此基础上增加了反向的信息传递,即从低层特征图向高层特征图传递信息。这种双向的信息流动使得特征图之间的信息融合更加充分。
-
加权特征融合: 在BIFPN中,不同尺度的特征图在融合时会分配不同的权重。这些权重是可学习的参数,模型在训练过程中会自动调整它们,以最优地融合不同尺度的特征。这样一来,模型能够更好地利用每个特征图的信息,提高整体的特征表示能力。
结构细节
BIFPN的结构设计非常灵活,可以适应不同的网络架构和任务需求。以下是BIFPN的几个关键组件:
-
上下文融合层:在上下文融合层中,BIFPN将来自不同尺度的特征图进行融合,采用加权求和的方式。这种加权求和通过学习到的权重来平衡不同特征图的贡献。
-
重复融合模块:BIFPN中通常会堆叠多个融合模块,这些模块会反复进行特征融合,从而进一步增强特征的表达能力。
-
尺度变化处理:BIFPN能够处理不同尺度的特征图,并在融合过程中考虑到这些尺度变化。通过上下采样等操作,BIFPN可以有效地处理不同分辨率的特征图。
优势
-
高效性:通过加权特征融合和重复融合模块,BIFPN能够在保持高效计算的同时,提升特征表示能力。
-
鲁棒性:双向特征融合使得BIFPN对不同尺度目标的检测更加鲁棒,能够更好地应对多尺度问题。
-
灵活性:BIFPN可以方便地集成到不同的神经网络架构中,适应不同的任务需求。
应用
BIFPN被广泛应用于各种计算机视觉任务中,尤其是在目标检测和图像分割方面表现出色。比如,在EfficientDet中,BIFPN作为核心组件之一,通过高效的特征融合机制显著提升了模型的检测性能。
总结
BIFPN通过引入双向特征融合和加权特征融合,克服了传统FPN的局限性,提高了特征融合的效率和效果。其灵活高效的设计使其在计算机视觉任务中得到广泛应用,为提升模型性能提供了有力支持。
2.BiFPN代码实现
2.1 将BiFPN代码添加到YOLOv10种
关键步骤一: 将下面代码粘贴到在/ultralytics/ultralytics/nn/modules/block.py中,并在该文件的__all__中添加“Concat_BiFPN”
class Concat_BiFPN(nn.Module):def __init__(self, dimension=1):super(Concat_BiFPN, self).__init__()self.d = dimensionself.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)self.epsilon = 0.0001def forward(self, x):w = self.wweight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化# Fast normalized fusionx = [weight[0] * x[0], weight[1] * x[1]]return torch.cat(x, self.d)BiFPN的主要流程可以分为以下几个步骤:
-
特征提取:首先,输入图像经过卷积神经网络(如EfficientNet等)进行特征提取,得到一系列特征图,这些特征图包含了不同层级的语义信息。
-
自下而上特征传递:BiFPN从底层开始,利用双线性池化将低分辨率特征图上采样到高分辨率,然后使用双向连接,将上一层的特征图与下一层的上采样特征图进行融合。这种自下而上的特征传递可以帮助从更低层级获取更丰富的信息。
-
自上而下特征传递:接着,BiFPN沿着特征金字塔网络的自上而下路径进行特征传递。在这个过程中,BiFPN利用双向连接,将上一层的特征图与下一层的上采样特征图进行融合,以获得更加丰富和准确的特征表征。
-
多尺度特征融合:BiFPN在每个层级上都进行多尺度特征融合,将不同分辨率的特征图通过双线性池化进行融合,从而提高特征的表征能力和鲁棒性。
-
最终特征输出:最后,BiFPN输出的特征图经过一系列后续处理,如分类器和回归器等,用于目标检测任务中的目标分类和边界框回归等。
通过这样的流程,BiFPN能够充分利用不同层级的特征信息,并通过双向连接和双线性池化等技巧,提高了特征的表征能力和目标检测的性能。
2.2 更改init.py文件
关键步骤二:修改modules文件夹下的__init__.py文件,先导入函数
然后在下面的__all__中声明函数

2.3 添加yaml文件
关键步骤三:在/ultralytics/ultralytics/cfg/models/v10下面新建文件yolov10_BiFPN.yaml文件,粘贴下面的内容
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, # [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv10n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, PSA, [1024]] # 10# YOLOv10 head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat_BiFPN, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat_BiFPN, [1]] # cat head P4- [-1, 3, C2f, [512]] # 19 (P4/16-medium)- [-1, 1, SCDown, [512, 3, 2]]- [[-1, 10], 1, Concat_BiFPN, [1]] # cat head P5- [-1, 3, C2fCIB, [1024, True, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
温馨提示:本文只是对yolov10n基础上添加模块,如果要对yolov10n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv10n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple# YOLOv10s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple# YOLOv10l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# YOLOv10m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple# YOLOv10x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.4 在task.py中进行注册
关键步骤四:在parse_model函数中进行注册
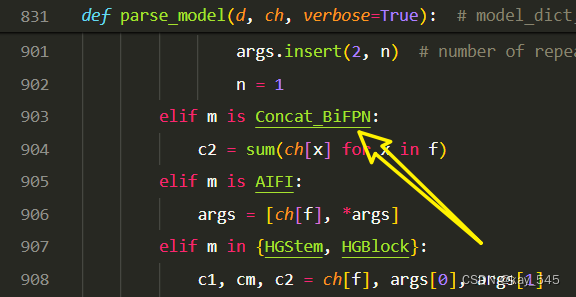
elif m is Concat_BiFPN:c2 = sum(ch[x] for x in f)2.5 执行程序
关键步骤五:在ultralytics文件中新建train.py,将model的参数路径设置为yolov10_BiFPN.yaml的路径即可
from ultralytics import YOLOv10# Load a model
# model = YOLO('yolov8n.yaml') # build a new model from YAML
# model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)model = YOLOv10(r'/projects/yolo/yolov10/ultralytics/cfg/models/v10/yolov10_BiFPN.yaml') # build from YAML and transfer weights# Train the model
model.train(batch=16)建议大家写绝对路径,确保一定能找到
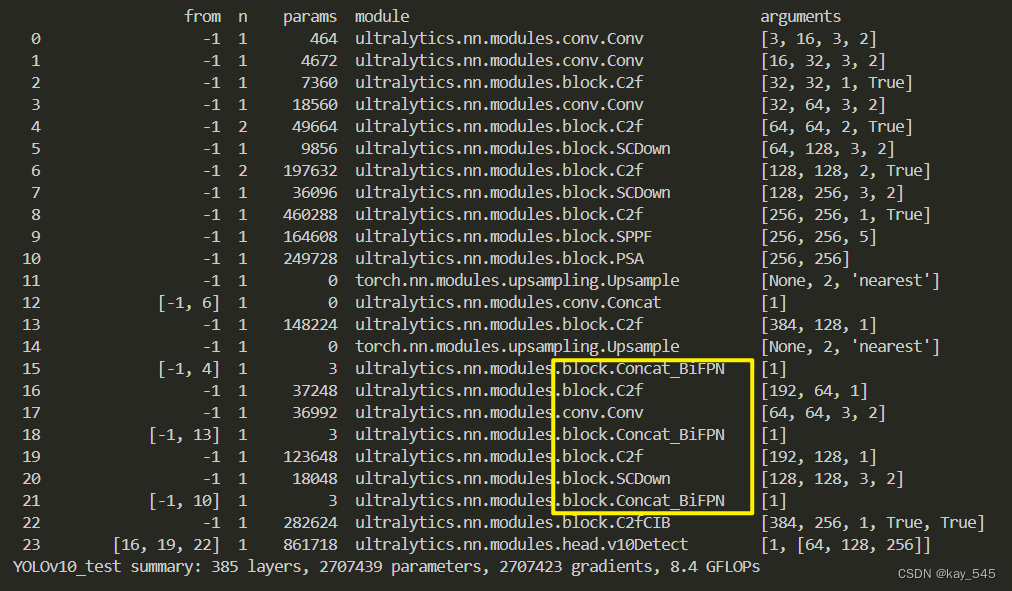
🚀运行程序,如果出现下面的内容则说明添加成功🚀
3. 完整代码分享
https://pan.baidu.com/s/1ZDM2aQ55nXx_aFxqPm9Jgg?pwd=z95u提取码: z95u
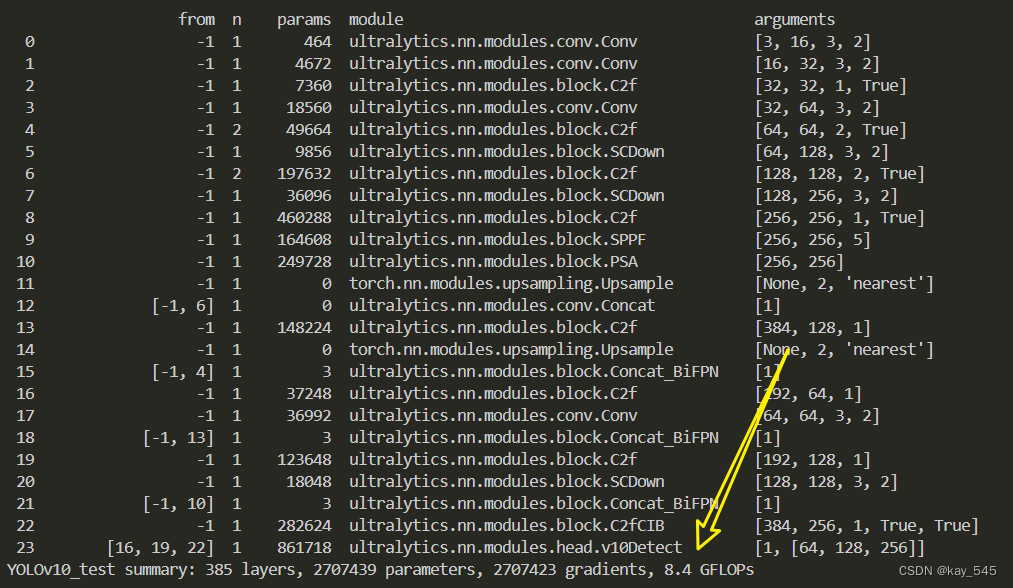
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的YOLOv10nGFLOPs

改进后的GFLOPs
5. 进阶
只需要更换code和ymal文件,其他的步骤相同
# 结合BiFPN 设置可学习参数 学习不同分支的权重
# 两个分支concat操作
class BiFPN_Concat2(nn.Module):def __init__(self, dimension=1):super(BiFPN_Concat2, self).__init__()self.d = dimensionself.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)self.epsilon = 0.0001def forward(self, x):w = self.wweight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化# Fast normalized fusionx = [weight[0] * x[0], weight[1] * x[1]]return torch.cat(x, self.d)# 三个分支concat操作
class BiFPN_Concat3(nn.Module):def __init__(self, dimension=1):super(BiFPN_Concat3, self).__init__()self.d = dimension# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter# 从而在参数优化的时候可以自动一起优化self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)self.epsilon = 0.0001def forward(self, x):w = self.wweight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化# Fast normalized fusionx = [weight[0] * x[0], weight[1] * x[1], weight[2] * x[2]]return torch.cat(x, self.d)# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, # [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv10n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, PSA, [1024]] # 10# YOLOv10 head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, BiFPN_Concat2, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, BiFPN_Concat3, [1]] # cat head P4- [-1, 3, C2f, [512]] # 19 (P4/16-medium)- [-1, 1, SCDown, [512, 3, 2]]- [[-1, 10], 1, BiFPN_Concat2, [1]] # cat head P5- [-1, 3, C2fCIB, [1024, True, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
6. 总结
BIFPN(双向特征金字塔网络)通过双向特征融合和加权特征融合的创新设计,显著提升了特征金字塔网络(FPN)的性能。其核心思想是将信息在特征金字塔中双向传递,即从高层特征图向低层特征图传递,同时也从低层特征图向高层特征图传递,确保特征信息的充分融合。同时,BIFPN引入了可学习的加权机制,通过在训练过程中自动调整权重,优化不同尺度特征图的融合效果。这种设计不仅提高了特征表示的能力,还保持了计算的高效性,使其在目标检测和图像分割等计算机视觉任务中表现出色,能够更好地应对多尺度问题和不同任务需求。
相关文章:
YOLOv10改进 | Neck | 添加双向特征金字塔BiFPN【含二次独家创新】
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 专栏目录:《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有40篇内容,内含各种Head检测头、损失函数Loss、B…...

PostgreSQL源码分析——pg_basebackup
涉及到的代码主要在src/backend/replication以及bin/pg_basebackup中。 我们知道pg_basebackup是一个进行基础备份的工具,除了使用这个工具,还可以用底层API的方式进行基础备份,主要过程如下: 连接到数据库执行select pg_start_…...
QT基础 - 常见图表绘制
目录 零. 前言 一. 添加模块 折线图 三. 树状图 四. 饼图 五. 堆叠柱状图 六. 百分比柱状图 七. 散点图和光滑曲线图 散点图 光滑曲线图 零. 前言 Qt Charts 是 Qt 框架的一个模块,用于创建各种类型的图表和数据可视化。它为开发者提供了一套功能强大的工…...

解释React中的“端口(Portals)”是什么,以及如何使用它来渲染子节点到DOM树以外的部分。
React中的“端口(Portals)”是一种将子节点渲染到DOM****树以外的部分的技术。在React应用中,通常情况下组件的渲染是遵循DOM的层次结构,即子组件会渲染在父组件的DOM节点内部。然而,有些情况下,开发者可能…...
java实现分类下拉树,点击时对应搜索---后端逻辑
一直想做分类下拉,然后选择后搜索的页面,正好做项目有了明确的需求,查找后发现el-tree的构件可满足需求,数据要求为:{ id:1, label:name, childer:[……] }形式的,于是乎,开搞! 一…...
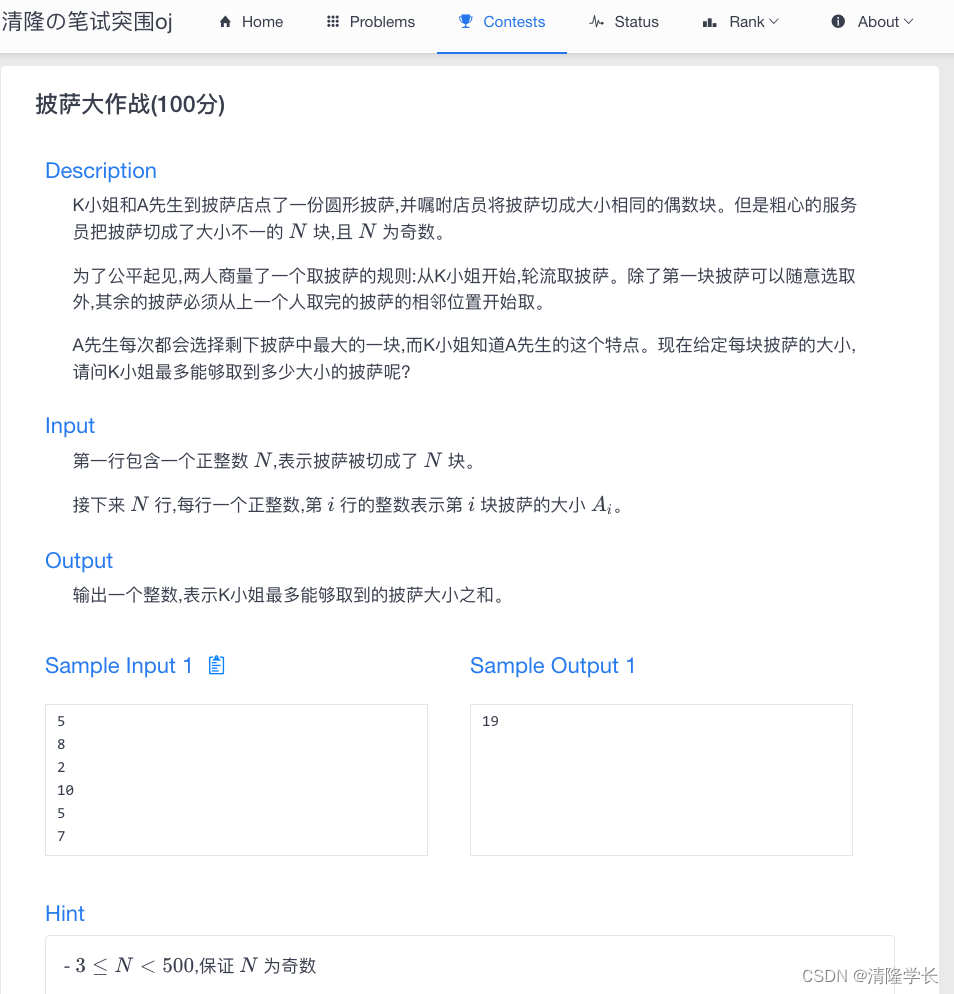
【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 披萨大作战(100分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 …...

探索Facebook对世界各地文化的影响
随着数字化时代的到来,社交媒体已成为连接世界各地人们的重要平台之一。而在这个领域的巨头之一,Facebook不仅是人们沟通交流的场所,更是一座桥梁,将不同地域、文化的人们联系在一起。本文将探索Facebook对世界各地文化的影响&…...

导出requirements.txt
文章目录 requirements.txt导出环境中所有包导出当前项目的包可能遇到的问题 requirements.txt 在Python项目中,通常使用requirements.txt文件来列出所有需要的第三方库和模块。这个文件通常位于项目的根目录下,并且在安装Python项目时,可以…...
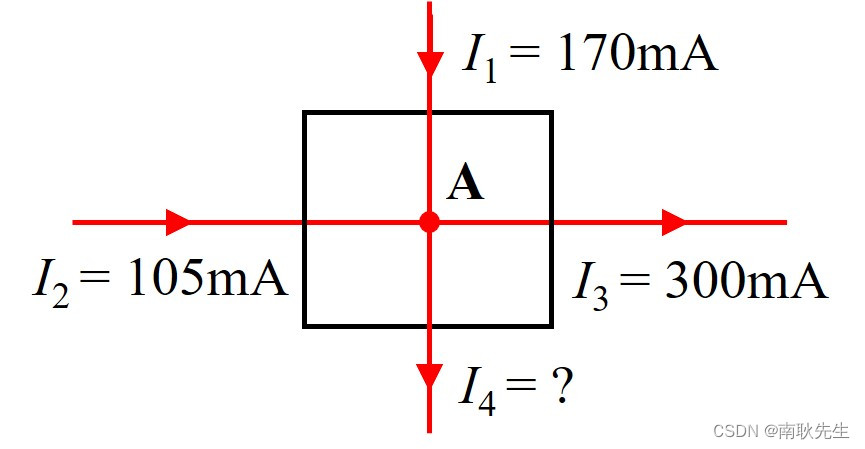
我主编的电子技术实验手册(09)——并联电路
本专栏是笔者主编教材(图0所示)的电子版,依托简易的元器件和仪表安排了30多个实验,主要面向经费不太充足的中高职院校。每个实验都安排了必不可少的【预习知识】,精心设计的【实验步骤】,全面丰富的【思考习…...

数据结构_二叉树
目录 一、树型结构 二、二叉树 2.1 概念 2.2 特殊的二叉树 2.3 二叉树的性质 2.4 二叉树的存储 2.5 遍历二叉树 2.6 操作二叉树 总结 一、树型结构 树是一种非线性的数据结构,它是由 n(n>0) 个有限结点组成一个具有层次关系的集合,一棵 n 个…...

Java线程池七个参数详解
ThreadPoolExecutor 是JDK中的线程池实现,这个类实现了一个线程池需要的各个方法,它提供了任务提交、线程管理、监控等方法 下面是 ThreadPoolExecutor 类的构造方法源码,其他创建线程池的方法最终都会导向这个构造方法,共有7个参…...
产品Web3D交互展示有什么优势?如何快速制作?
智能互联网时代,传统的图片、文字、视频等产品展示方式,因为缺少互动性,很难引起用户的兴趣,已经逐渐失去了宣传优势。 Web3D交互展示技术的出现,让众多品牌和企业找到了新的方向,线上产品展示不在枯燥无趣…...

Python | Leetcode Python题解之第171题Excel列表序号
题目: 题解: class Solution:def titleToNumber(self, columnTitle: str) -> int:number, multiple 0, 1for i in range(len(columnTitle) - 1, -1, -1):k ord(columnTitle[i]) - ord("A") 1number k * multiplemultiple * 26return n…...
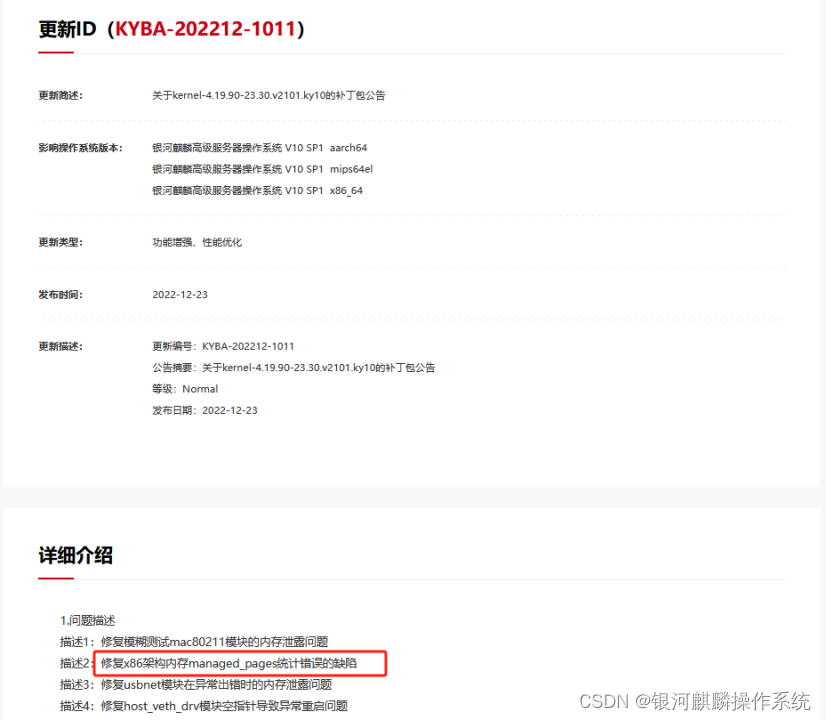
【银河麒麟】高可用触发服务器异常重启,处理机制详解
1.服务器环境以及配置 【机型】物理机 处理器: Intel 内存: 126G 【内核版本】 4.19.90-25.16.v2101.ky10.x86_64 【银河麒麟操作系统镜像版本】 Kylin-Server-10-SP2-Release-Shenzhen-Metro-x86-Build01-20220619 Kylin-HA-10-SP2-Release-S…...
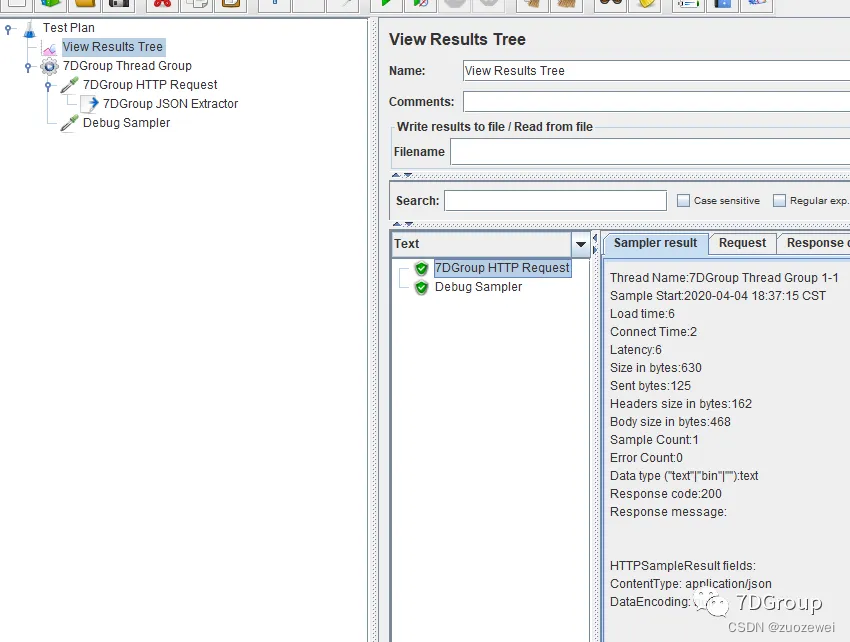
性能工具之 JMeter 常用组件介绍(七)
文章目录 一、后置处理器1、Regular Expression Extractor(正则表达式提取器)2、JSON Extractor(JSON表达式提取器)3、Regular Expression Extractor(正则表达式提取器) 二、小结 本文主要介绍JMeter主流后置处理器的功能 一、后置处理器 从上面可以看出后置处理可以插件挺多&a…...
Python学习笔记15:进阶篇(四)文件的读写。
文件操作 学习编程操作中,我觉得文件操作是必不可少的一部分。不管是读书的时候学习的c,c,工作的前学的java,现在学的Python,没学过的php和go,都有文件操作的模块以及库的支持,重要性毫无疑问。…...

角度调制与解调电路
music! (黄佳庆老师可爱捏) 调角 角度调制有较好的抗噪性能。 调相 相位变化的频率变化的微分,频率变化是相位变化的积分 相位的变化率就是频率 调频 调相与调频的关系 大F是输入信号的频率,大Ω是输入信号的角频率 …...
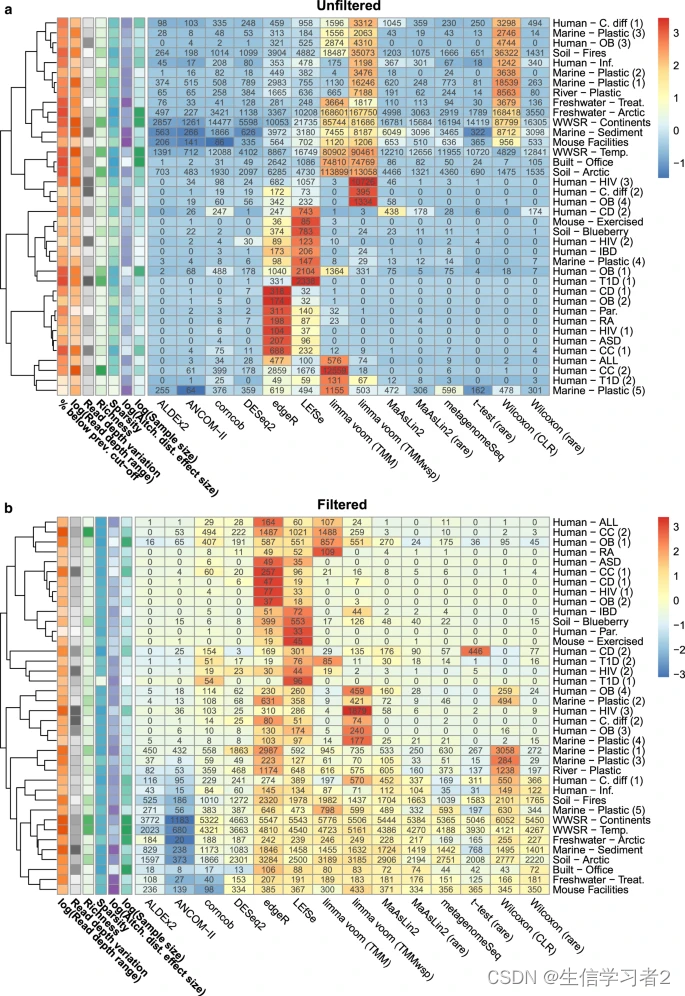
数据分析:微生物组差异丰度方法汇总
欢迎大家关注全网生信学习者系列: WX公zhong号:生信学习者Xiao hong书:生信学习者知hu:生信学习者CDSN:生信学习者2 介绍 微生物数据具有一下的特点,这使得在做差异分析的时候需要考虑到更多的问题&…...

Linux驱动开发(二)--字符设备驱动开发提升 LED驱动开发实验
1、地址映射 在编写驱动之前,需要知道MMU,也就是内存管理单元,在老版本的 Linux 中要求处理器必须有 MMU,但是现在Linux 内核已经支持无 MMU 的处理器了。 MMU的功能如下: 完成虚拟空间到物理空间的映射 内存保护&…...
钡铼BL101网关助力智慧城市路灯远程智能管控
在迈向智慧城市的征途中,基础设施的智能化改造是关键一环,而路灯作为城市脉络的照明灯塔,其智能化升级对于节能减排、提升城市管理效率具有重要意义。钡铼BL101网关,作为Modbus转MQTT的专业桥梁,正以其卓越的性能和广泛…...

手动测试射频放大器P1dB:原理、步骤与校准实战指南
1. 项目概述:为什么我们需要手动测试P1dB?在射频放大器、混频器乃至整个收发链路的设计与验证中,1dB增益压缩点(P1dB)是一个绕不开的核心指标。它直观地告诉工程师,你的器件在多大功率下开始“力不从心”—…...

番茄小说下载器终极指南:如何轻松构建个人离线图书馆
番茄小说下载器终极指南:如何轻松构建个人离线图书馆 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否经常在地铁、高铁或飞机上想要阅读番茄小说,…...

魔百盒M301H-ZN代工_HI3798MV300H芯片_8822CS无线模块-深度定制与刷机实战指南
1. 魔百盒M301H-ZN硬件拆解与芯片解析 第一次拿到魔百盒M301H-ZN时,我差点被它朴实无华的外表骗了。拆开底部四颗螺丝后,内部布局清晰地展现在眼前:HI3798MV300H主控芯片位于主板中央,右上角是8822CS无线模块,存储芯片…...

掌握Superpowers Skills
Superpowers 是一套面向开发过程的插件化技能系统,旨在帮助个人开发者与团队更高效地完成从需求探索到代码交付的全流程。其内置的十余项技能覆盖了软件开发生命周期的各个关键节点,并且可以按照自然的工作流顺序进行分组与调用。 本文将基于 Superpower…...

shein armortoken/smdeviceid/anti/x-gw-auth算法分析
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包 内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!侵权通过头像私信或名字简介叫我删除博…...

从句实战指南:从三大从句到地道英文写作
1. 从句的本质:让句子"活"起来的秘密武器 第一次接触英语从句时,我盯着课本上那句"That the earth is round is true"发呆了十分钟。主谓宾在哪?为什么that后面跟着完整句子?这种困惑持续到我发现从句就像乐高…...

从2018到2023:Unity WebGL内存管理变迁史与你的2G内存墙突破指南
Unity WebGL内存管理演进与2G内存墙突破实战 引言 2018年的某个深夜,当我第一次在Chrome控制台看到"Out of Memory"的红色警告时,完全没意识到这会成为接下来五年与Unity WebGL缠斗的开端。那个使用Unity 2017.3构建的医疗可视化项目ÿ…...

长期使用Taotoken的Token Plan套餐带来的月度成本变化观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken的Token Plan套餐带来的月度成本变化观察 对于需要持续调用大模型API的开发者或团队而言,成本的可预测…...

【信息科学与工程学】【制造工程】【通信工程】第一百零一篇 2nm 200Tbps+核心交换机全尺度参数宇宙构建框架05
围绕芯片、单板、交换网卡等层级,重点扩展“信息处理”中的“内存/存储器”子系统相关参数,并覆盖其他关键方面。 衬底、互连、介质,但光刻胶、清洗液、研磨液、封装胶、键合线、TIM材料、探针卡、载带、保护涂层、清洗溶剂、掺杂剂、气体、抗反射涂层、对准标记、硅化物、…...

让你的电脑静下来:FanControl风扇智能控制完全指南
让你的电脑静下来:FanControl风扇智能控制完全指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fa…...