跑通并使用Yolo v5的源代码并进行训练—目标检测
跑通并使用Yolo v5的源代码并进行训练
摘要:yolo作为目标检测计算机视觉领域的核心网络模型,虽然到24年已经出到了v10的版本,但也很有必要对之前的核心版本v5版本进行进一步的学习。在学习yolo v5的时候因为缺少论文所以要从源代码入手来体验yolo v5之一经典的网络模型。
Git拉取代码
首先给出github上的官方仓库。我们使用第7版的yolo v5来进行测试和使用。
https://github.com/ultralytics/yolov5
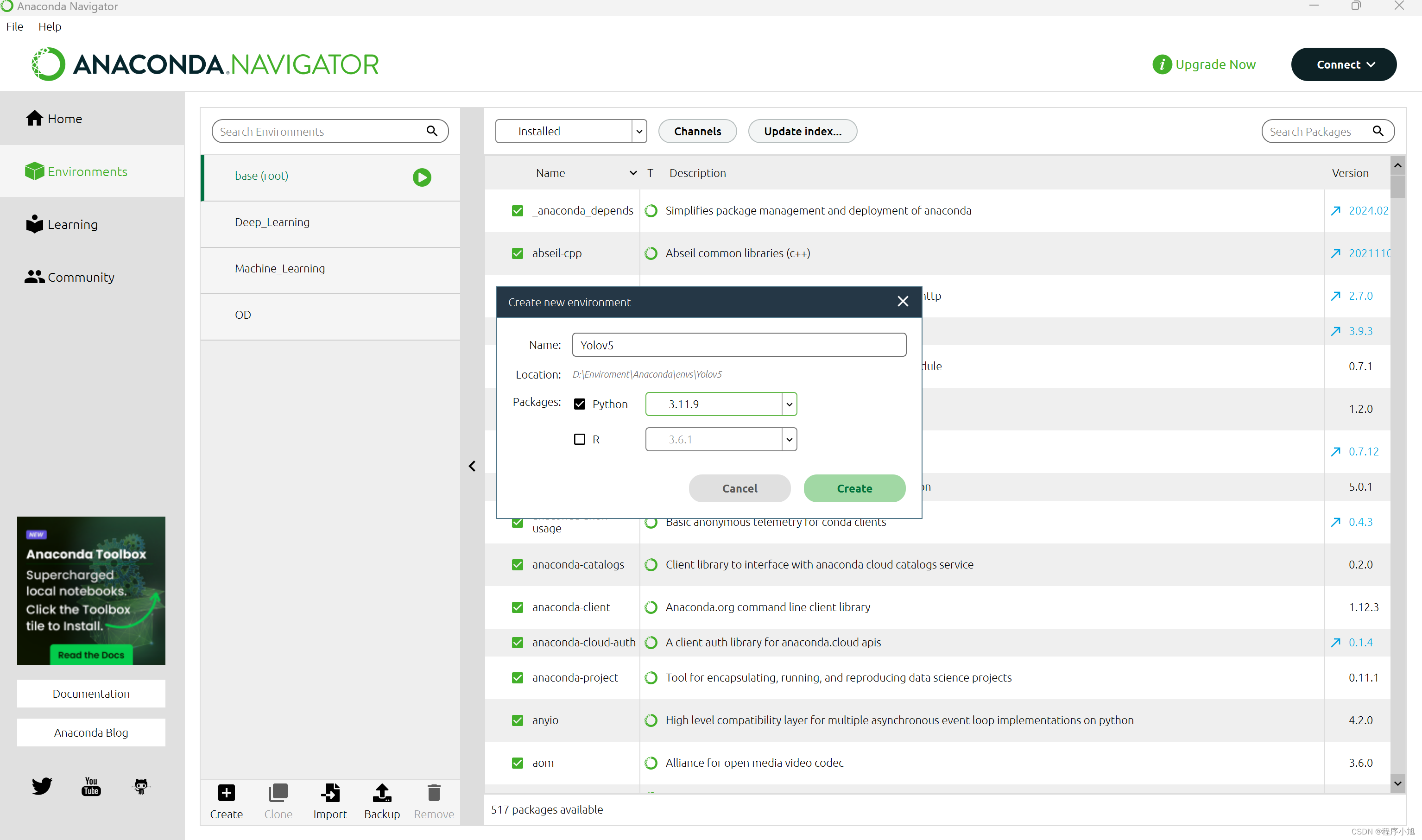
创建yolo v5的虚拟环境
本次使用Anaconda的图形管理工具来创建yolo v5的虚拟环境,使用的python版本选择python 3.11的版本
官方要求是:python version >= python 3.8
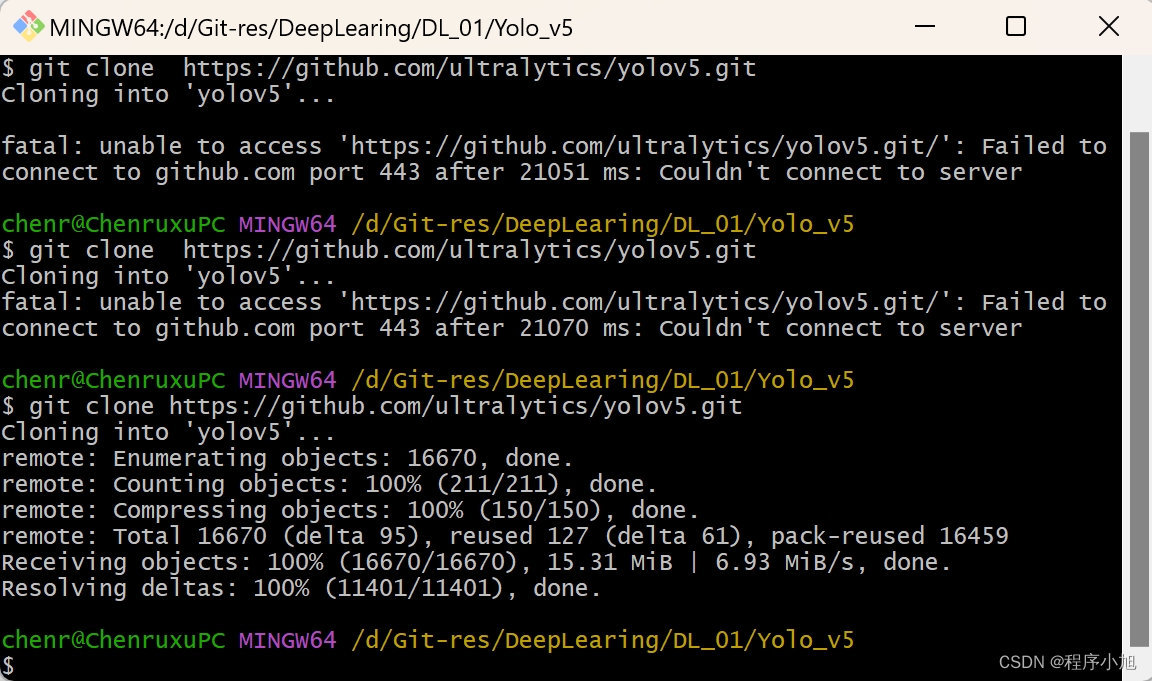
git clone拉取项目并使用pycharm打开
在指定文件夹下面使用:来拉取项目
git clone https://github.com/ultralytics/yolov5.git
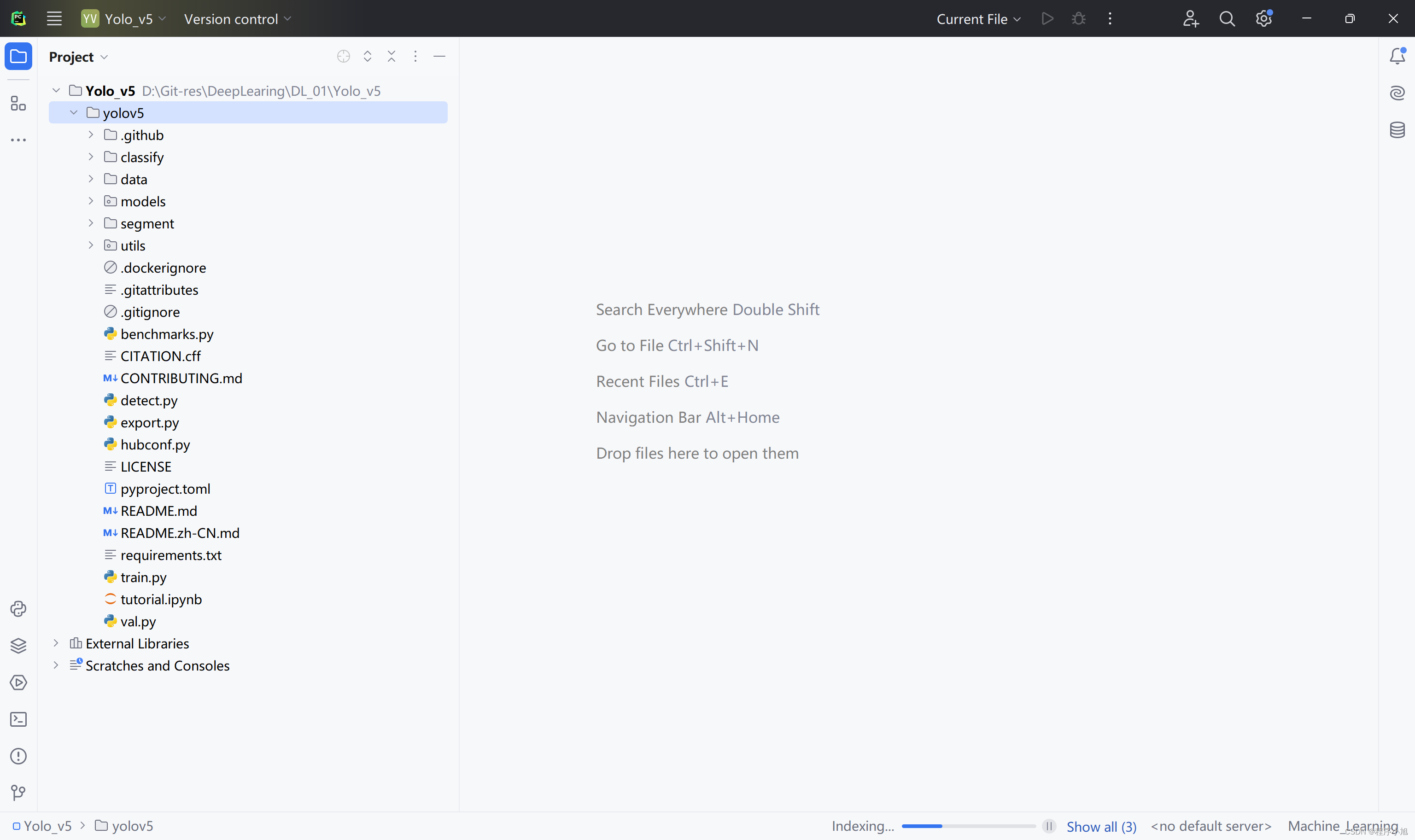
之后使用pycharm将项目进行导入,并观察项目的结构。当然建议可以直接在pycharm中通过git模块将项目加载进ide中进行学习。
选择虚拟环境将改项目的虚拟环境选择为刚刚创建的yolo v5的环境信息。在虚拟环境的基础上通过pip安装需要使用的requirements.txt文件夹下面所定义的环境配置。
如果一些环境因为CUDA的版本信息安装不上,则需要在终端自己通过pip命令安装一些高版本的依赖库进行测试使用。
# YOLOv5 requirements
# Usage: pip install -r requirements.txt# Base ------------------------------------------------------------------------
gitpython>=3.1.30
matplotlib>=3.3
numpy>=1.23.5
opencv-python>=4.1.1
pillow>=10.3.0
psutil # system resources
PyYAML>=5.3.1
requests>=2.32.0
scipy>=1.4.1
thop>=0.1.1 # FLOPs computation
torch>=1.8.0 # see https://pytorch.org/get-started/locally (recommended)
torchvision>=0.9.0
tqdm>=4.64.0
ultralytics>=8.2.34 # https://ultralytics.com
# protobuf<=3.20.1 # https://github.com/ultralytics/yolov5/issues/8012# Logging ---------------------------------------------------------------------
# tensorboard>=2.4.1
# clearml>=1.2.0
# comet# Plotting --------------------------------------------------------------------
pandas>=1.1.4
seaborn>=0.11.0# Export ----------------------------------------------------------------------
# coremltools>=6.0 # CoreML export
# onnx>=1.10.0 # ONNX export
# onnx-simplifier>=0.4.1 # ONNX simplifier
# nvidia-pyindex # TensorRT export
# nvidia-tensorrt # TensorRT export
# scikit-learn<=1.1.2 # CoreML quantization
# tensorflow>=2.4.0,<=2.13.1 # TF exports (-cpu, -aarch64, -macos)
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev>=2023.0 # OpenVINO export# Deploy ----------------------------------------------------------------------
setuptools>=65.5.1 # Snyk vulnerability fix
# tritonclient[all]~=2.24.0# Extras ----------------------------------------------------------------------
# ipython # interactive notebook
# mss # screenshots
# albumentations>=1.0.3
# pycocotools>=2.0.6 # COCO mAP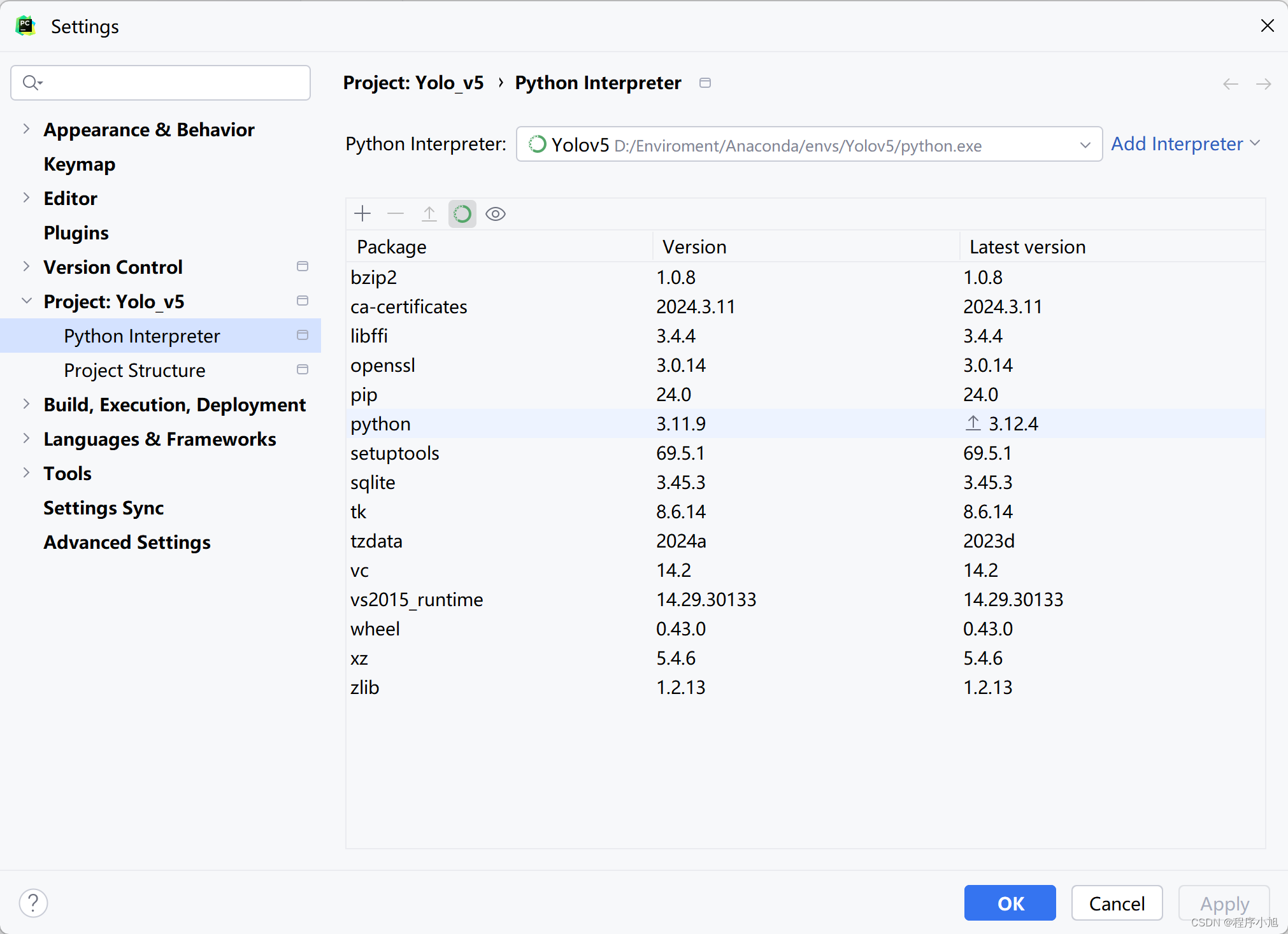
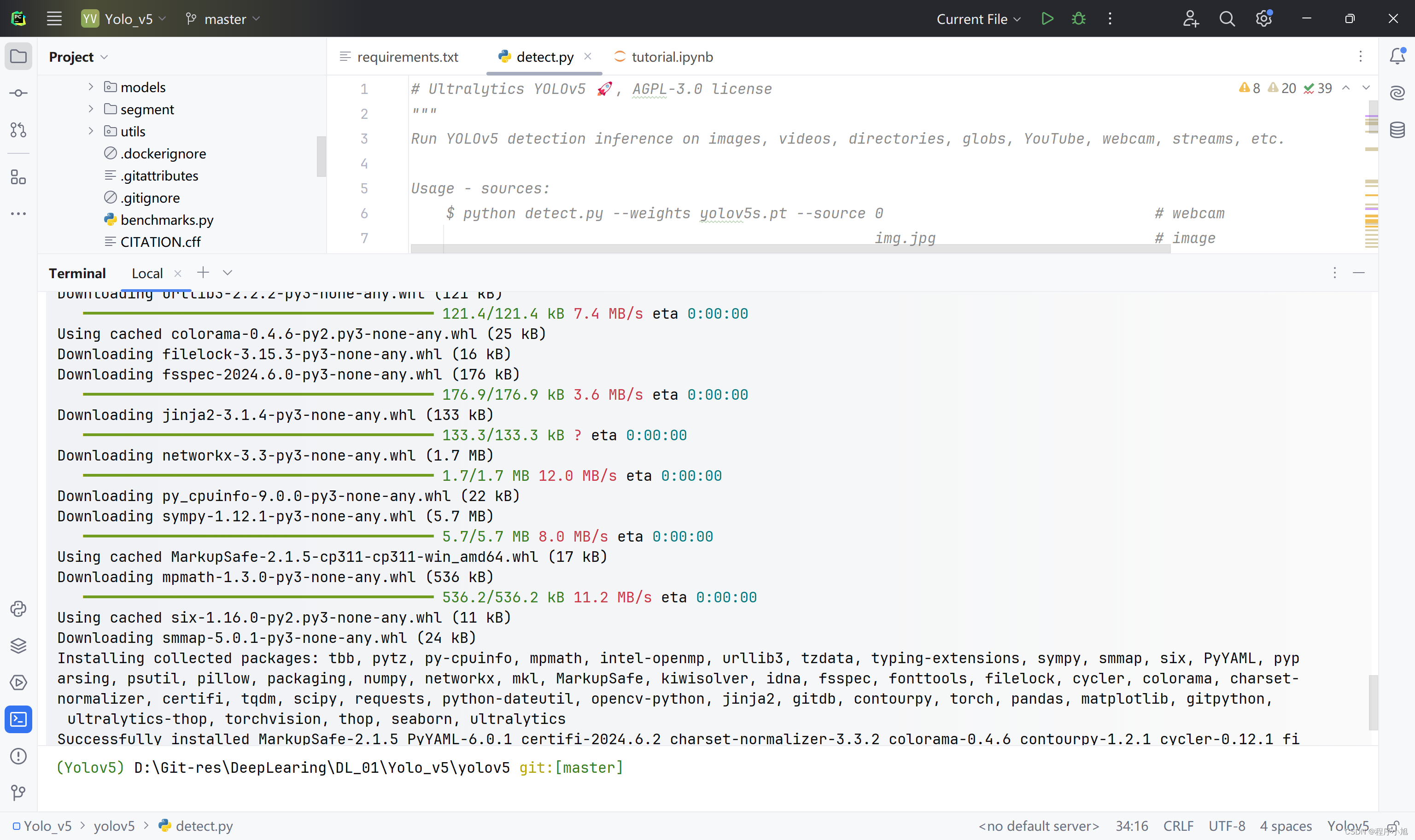
通过pip安装环境
官方的md文件中给出了需要在终端中切换的目录,和安装的命令如下所示:
cd yolov5
pip install -r requirements.txt # install
并给出了预训练好的模型信息。
预训练模型
| 模型 | 尺寸 (像素) | mAPval 50-95 | mAPval 50 | 推理速度 CPU b1 (ms) | 推理速度 V100 b1 (ms) | 速度 V100 b32 (ms) | 参数量 (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
| YOLOv5x6 +[TTA] | 1280 1536 | 55.0 55.8 | 72.7 72.7 | 3136 - | 26.2 - | 19.4 - | 140.7 - | 209.8 - |
在进行预测和测试时可以选择上面的预训练模型进行下载,下载的位置如图所示,在执行时可以自动下载若下载失败,在自己在指定的位置下载这些模型。
主要要有c++的环境才能安装成果,可以先看一下自己的windows电脑上是否有c++的环境,linux上还没测试过,可以之后使用colab进行一下测试。
根据文档提示启动项目测试预训练模型
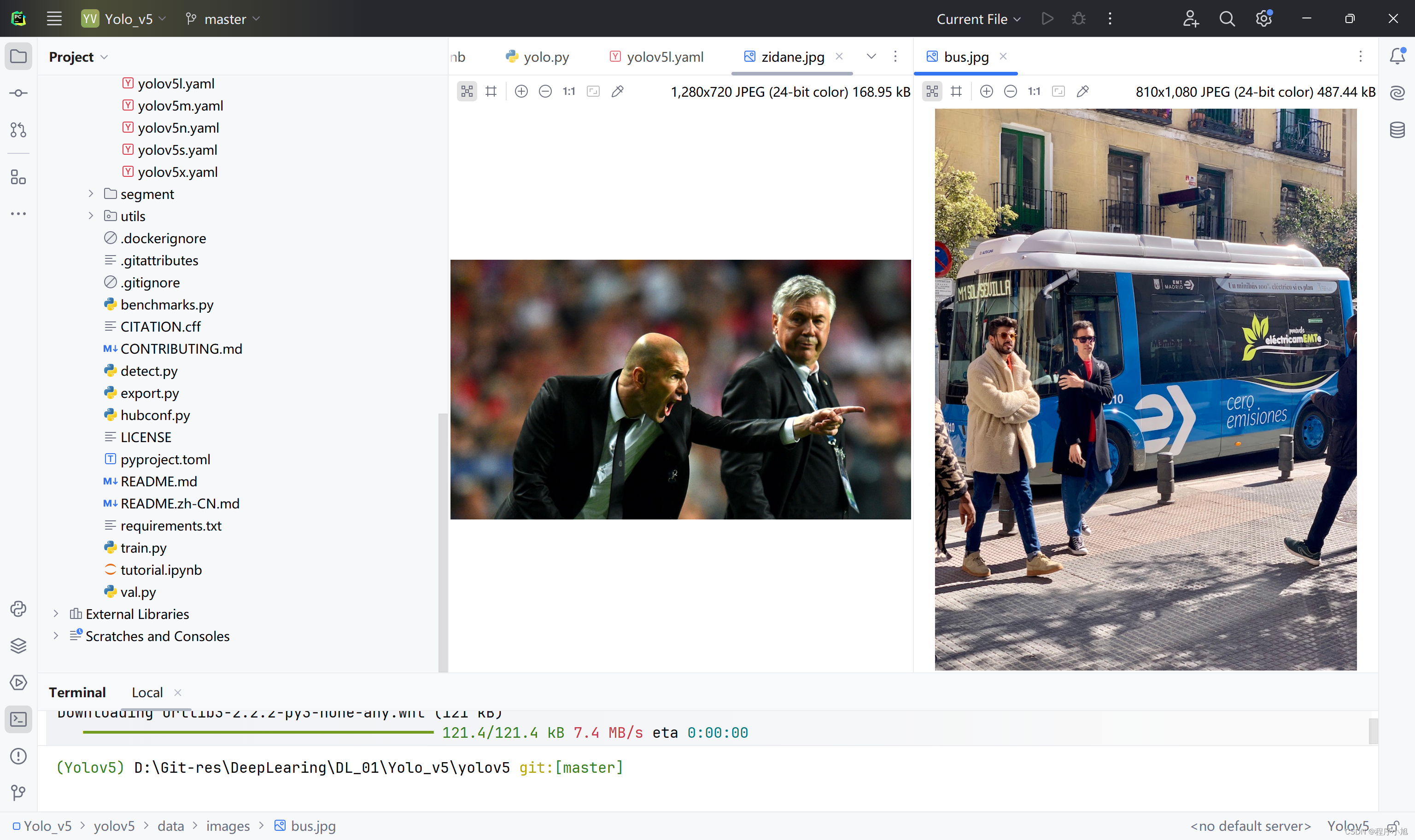
官方提供了两张用来进行目标检测的图片,执行detect.py文件并修改里面main函数中包括的参数信息,加载预训练模型进行预测。
if __name__ == "__main__":opt = parse_opt()main(opt)
在parse_opt()函数中修改指定的参数信息。
ef parse_opt():"""Parses command-line arguments for YOLOv5 detection, setting inference options and model configurations."""parser = argparse.ArgumentParser()parser.add_argument("--weights", nargs="+", type=str, default=ROOT / "yolov5s.pt", help="model path or triton URL")parser.add_argument("--source", type=str, default=ROOT / "data/images", help="file/dir/URL/glob/screen/0(webcam)")parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="(optional) dataset.yaml path")parser.add_argument("--imgsz", "--img", "--img-size", nargs="+", type=int, default=[640], help="inference size h,w")parser.add_argument("--conf-thres", type=float, default=0.25, help="confidence threshold")parser.add_argument("--iou-thres", type=float, default=0.45, help="NMS IoU threshold")parser.add_argument("--max-det", type=int, default=1000, help="maximum detections per image")parser.add_argument("--device", default="", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")parser.add_argument("--view-img", action="store_true", help="show results")parser.add_argument("--save-txt", action="store_true", help="save results to *.txt")parser.add_argument("--save-csv", action="store_true", help="save results in CSV format")parser.add_argument("--save-conf", action="store_true", help="save confidences in --save-txt labels")parser.add_argument("--save-crop", action="store_true", help="save cropped prediction boxes")parser.add_argument("--nosave", action="store_true", help="do not save images/videos")parser.add_argument("--classes", nargs="+", type=int, help="filter by class: --classes 0, or --classes 0 2 3")parser.add_argument("--agnostic-nms", action="store_true", help="class-agnostic NMS")parser.add_argument("--augment", action="store_true", help="augmented inference")parser.add_argument("--visualize", action="store_true", help="visualize features")parser.add_argument("--update", action="store_true", help="update all models")parser.add_argument("--project", default=ROOT / "runs/detect", help="save results to project/name")parser.add_argument("--name", default="exp", help="save results to project/name")parser.add_argument("--exist-ok", action="store_true", help="existing project/name ok, do not increment")parser.add_argument("--line-thickness", default=3, type=int, help="bounding box thickness (pixels)")parser.add_argument("--hide-labels", default=False, action="store_true", help="hide labels")parser.add_argument("--hide-conf", default=False, action="store_true", help="hide confidences")parser.add_argument("--half", action="store_true", help="use FP16 half-precision inference")parser.add_argument("--dnn", action="store_true", help="use OpenCV DNN for ONNX inference")parser.add_argument("--vid-stride", type=int, default=1, help="video frame-rate stride")opt = parser.parse_args()opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expandprint_args(vars(opt))return opt
在简单进行使用的过程中,只说明前两个参数即可满足效果的显示。
- parser.add_argument(“–weights”, nargs=“+”, type=str, default=ROOT / “yolov5s.pt”, help=“model path or triton URL”)
加载yolov5s.pt模型作为预训练权重。
- parser.add_argument(“–source”, type=str, default=ROOT / “data/images”, help=“file/dir/URL/glob/screen/0(webcam)”)
需要检测的图片存放路径信息。
在配置好后执行该文件产生对应的效果来进行测试。
报错信息解决
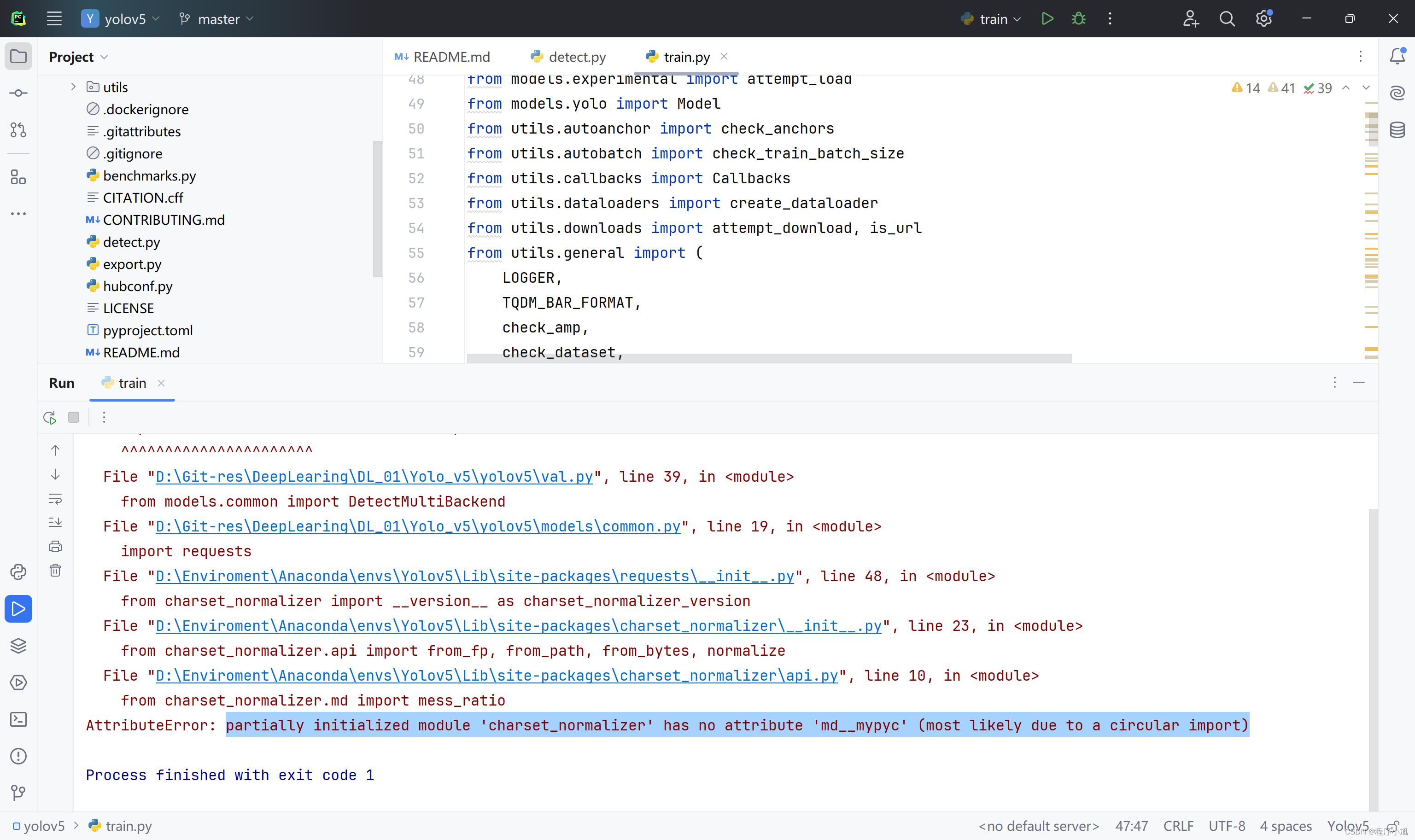
额:不出意外第一次跑代码总会产生一定的错误信息。
AttributeError: partially initialized module ‘charset_normalizer’ has no attribute ‘md__mypyc’ (most likely due to a circular import)
参考解决方式:pip install --force-reinstall charset-normalizer==3.1.0
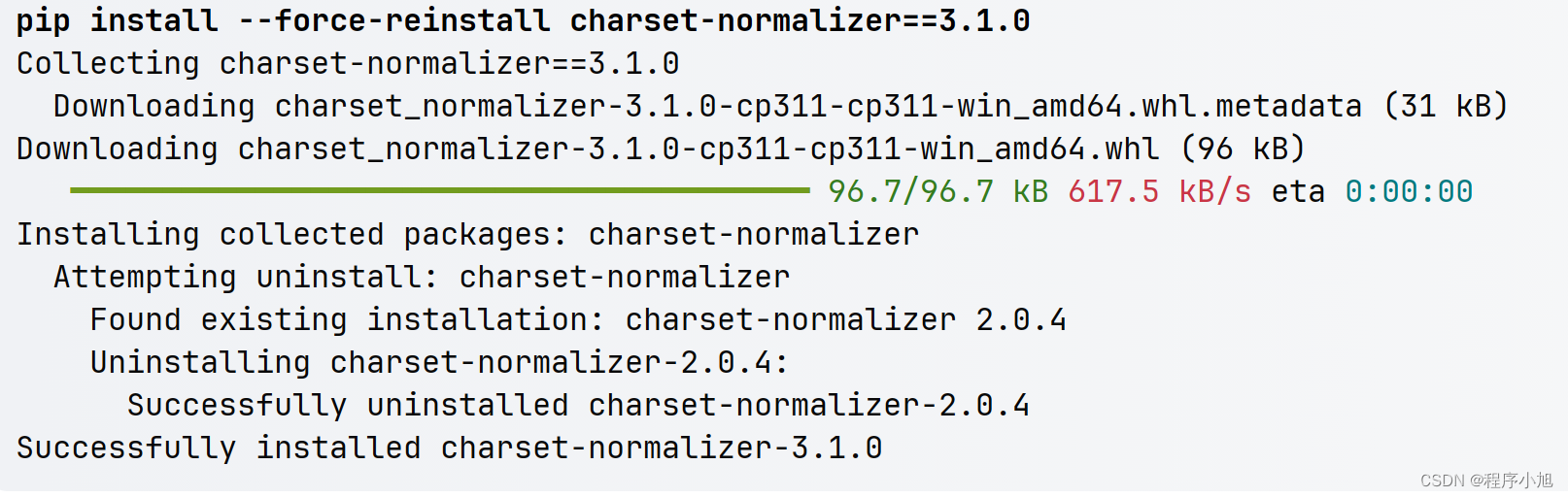
之后再一次执行信息,就执行成功开始下载yolov5s.pt的预训练模型信息,进行一个检测检测操作。并将结果保存到指定的位置处。
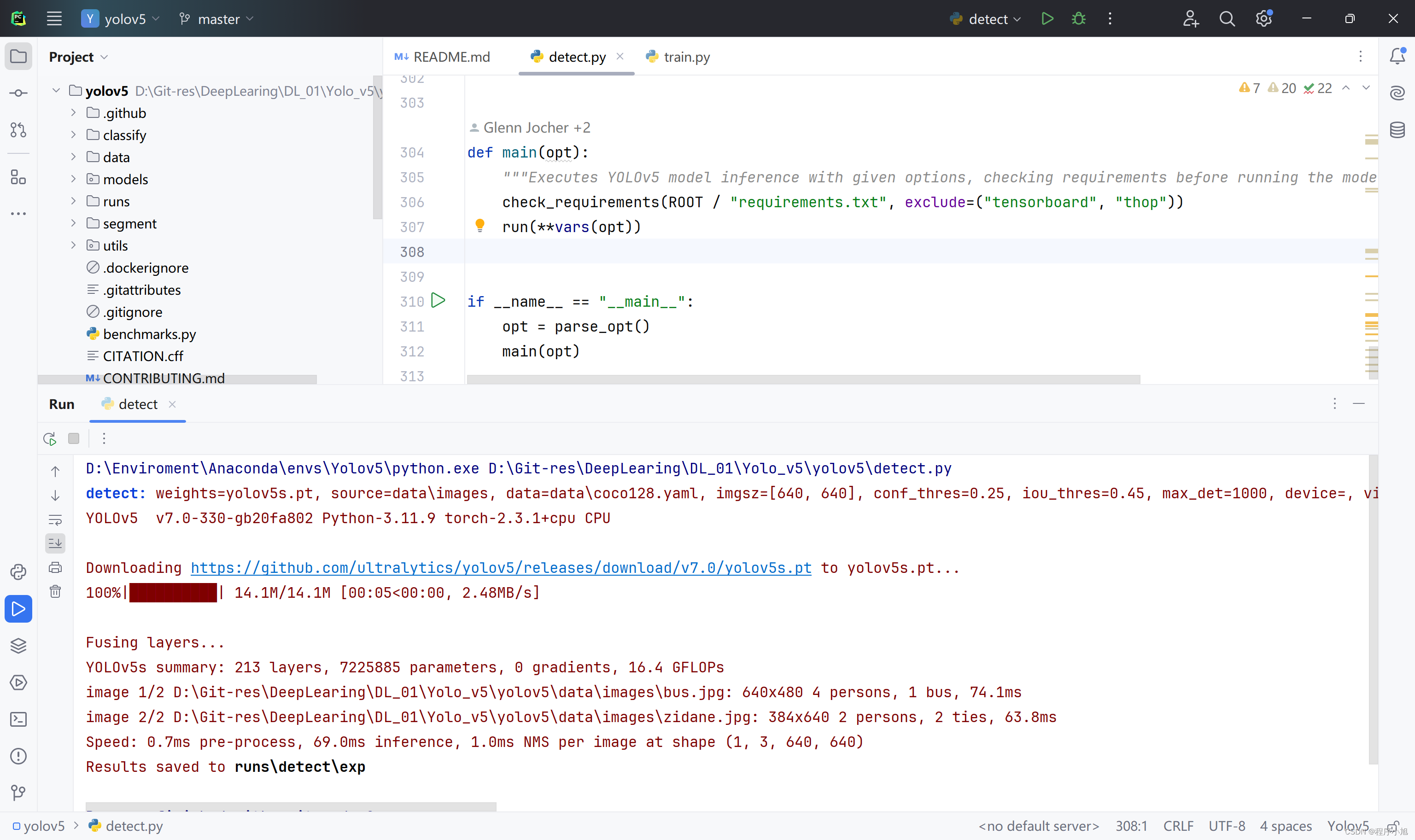
在run文件下面生成第一次检测的图片结果信息。
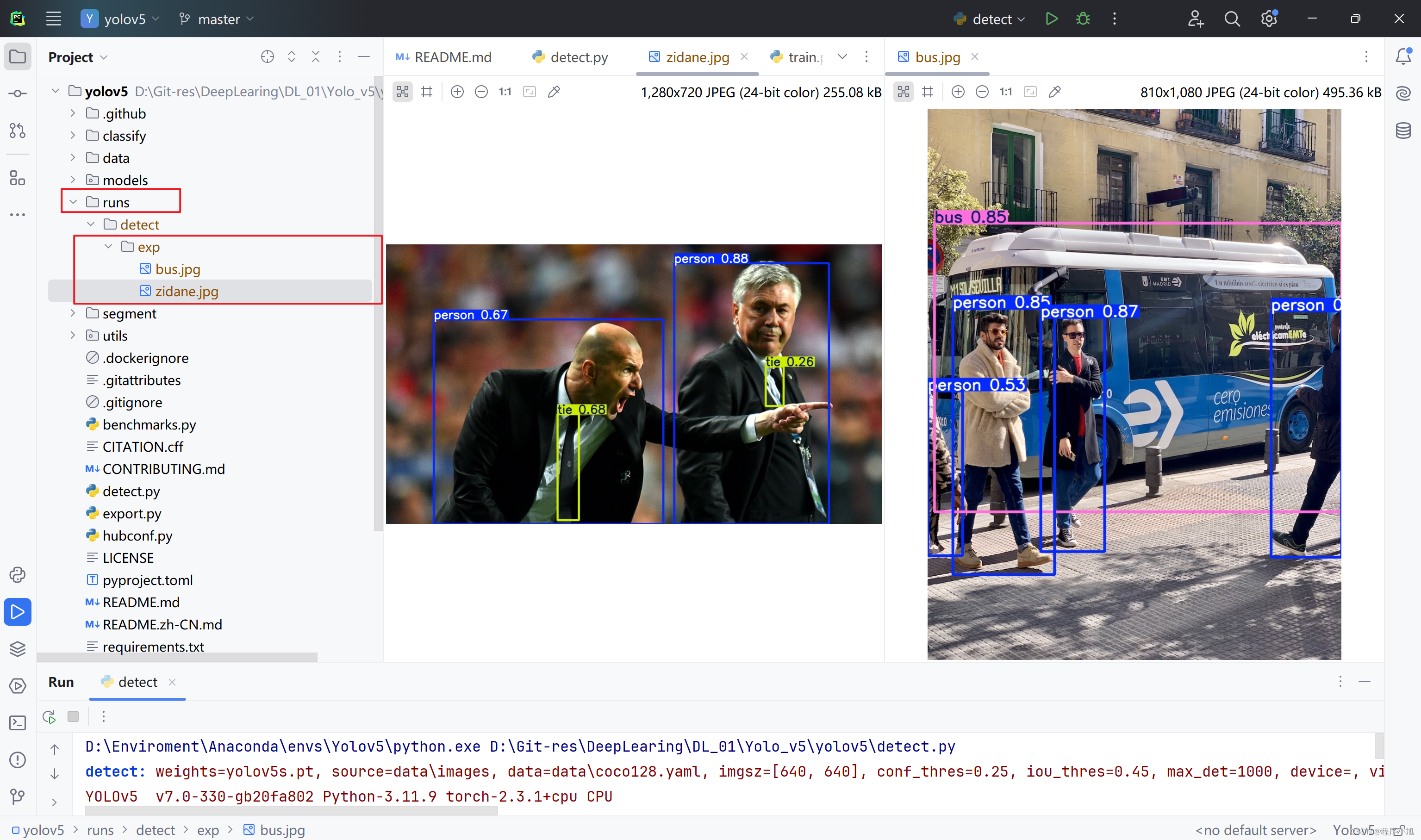
切换预训练模型在执行一次
例如切换使用YOLOv5m 模型进行一次测试过程,观察该模型与之前的模型在生成的效果上有何不同之处。
我们这次使用命令行的方式来进行执行观察效果
修改对应的预训练参数yolov5m.pt
parser.add_argument("--weights", nargs="+", type=str, default=ROOT / "yolov5m.pt", help="model path or triton URL")

明显可以发现该模型的大小明显更大下载的速度也更快。
模型下载的位置就保持在根目录处,可以通过程序直接进行加载。
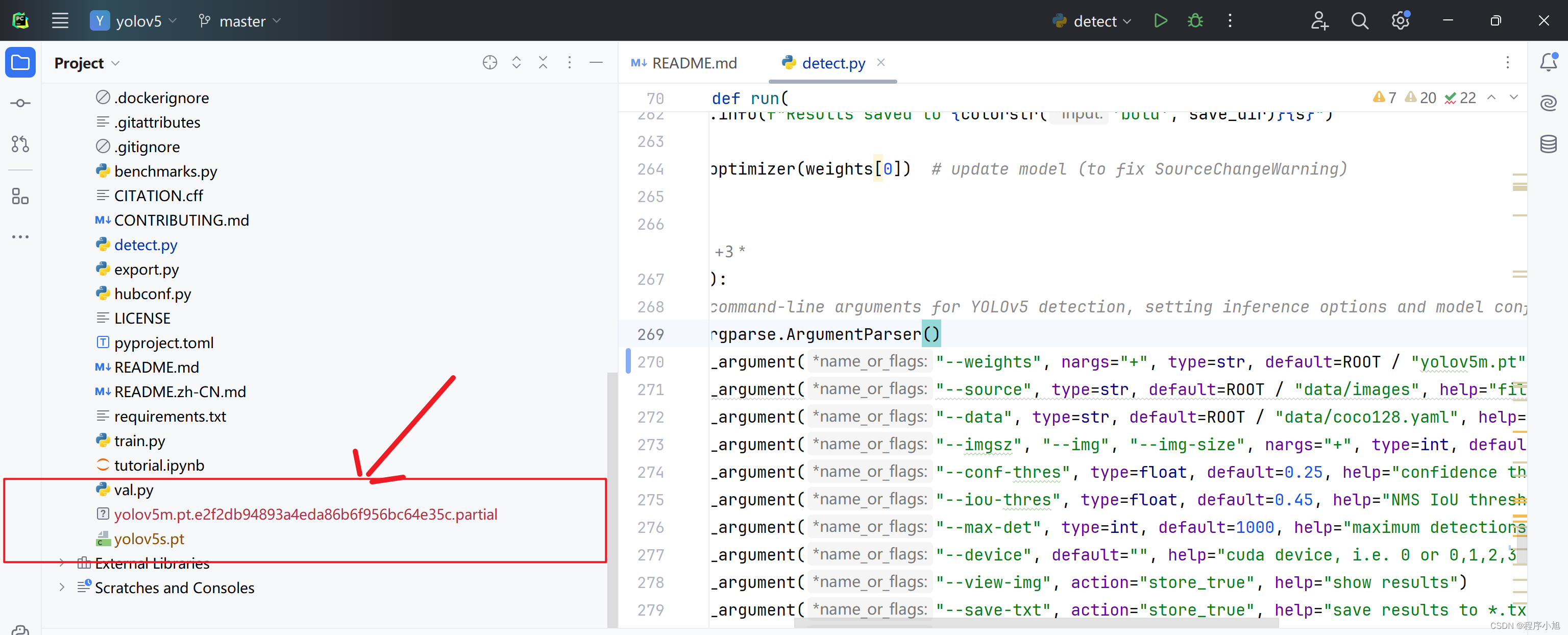
执行成功之后发现在bounding box对应的置信度上的数值存在明显的不同之处。同时会保存在不同的文件中。
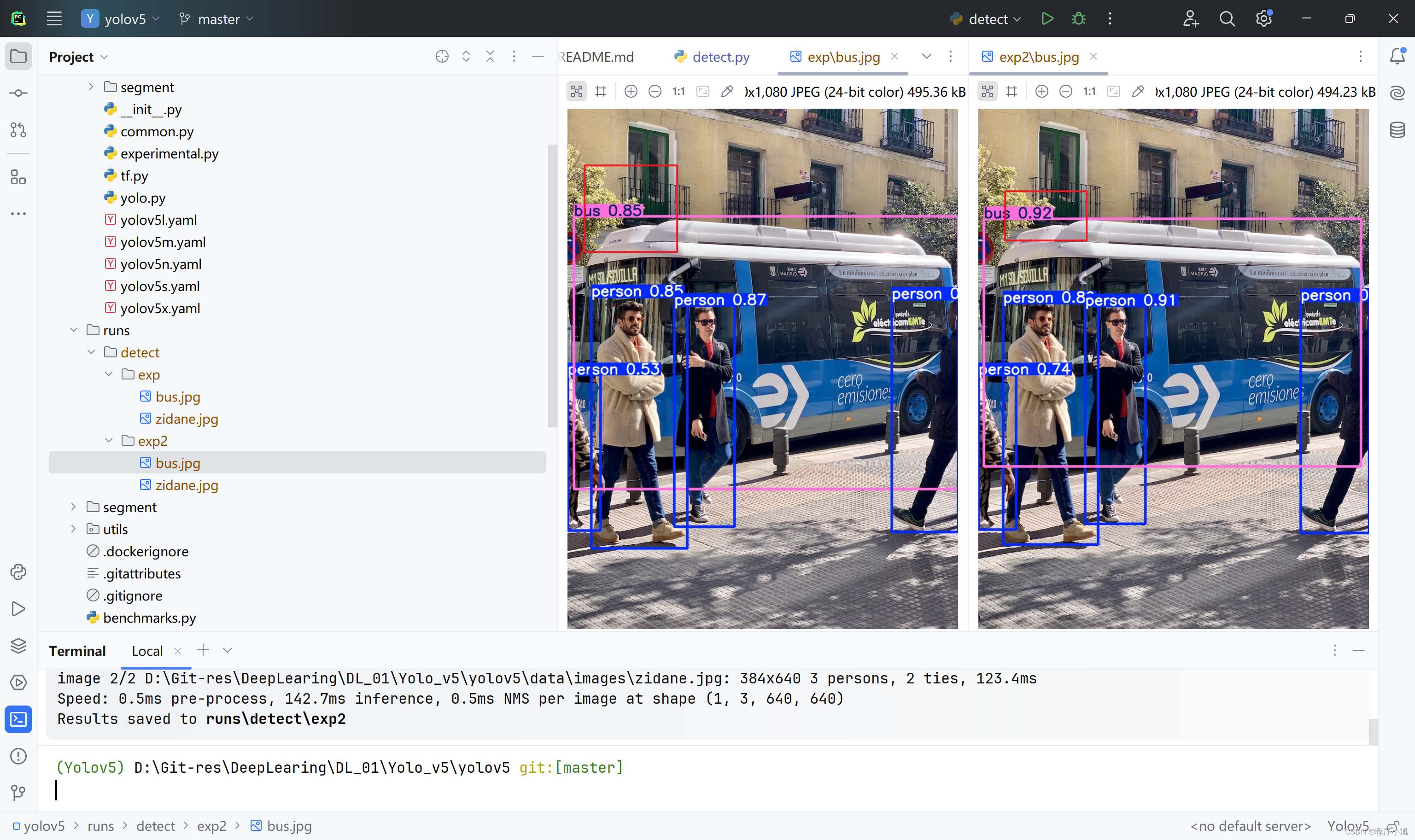
街道视频的目标检测
在官方文档和代码注释出提到了可以使用.mp4文件并将视频转化为帧进行检测。
$ python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
list.txt # list of images
list.streams # list of streams
‘path/*.jpg’ # glob
‘https://youtu.be/LNwODJXcvt4’ # YouTube
‘rtsp://example.com/media.mp4’ # RTSP, RTMP, HTTP stream
其中 parser.add_argument(“–view-img”, action=“store_true”, help=“show results”)
–view-img参数可以显示检测的效果,在执行视频文件的同时我们使用到这个参数就可以动态观察视频的检测效果了。
- 下载一个街道视频作为待检测的素材。
- 修改第二个参数信息在程序中读入视频并进行检测。
parser.add_argument("--source", type=str, default=ROOT / "data/video/street.mp4", help="file/dir/URL/glob/screen/0(webcam)")
- 设置–view-img参数观看检测视频的实时效果。(python detect.py --view-img)
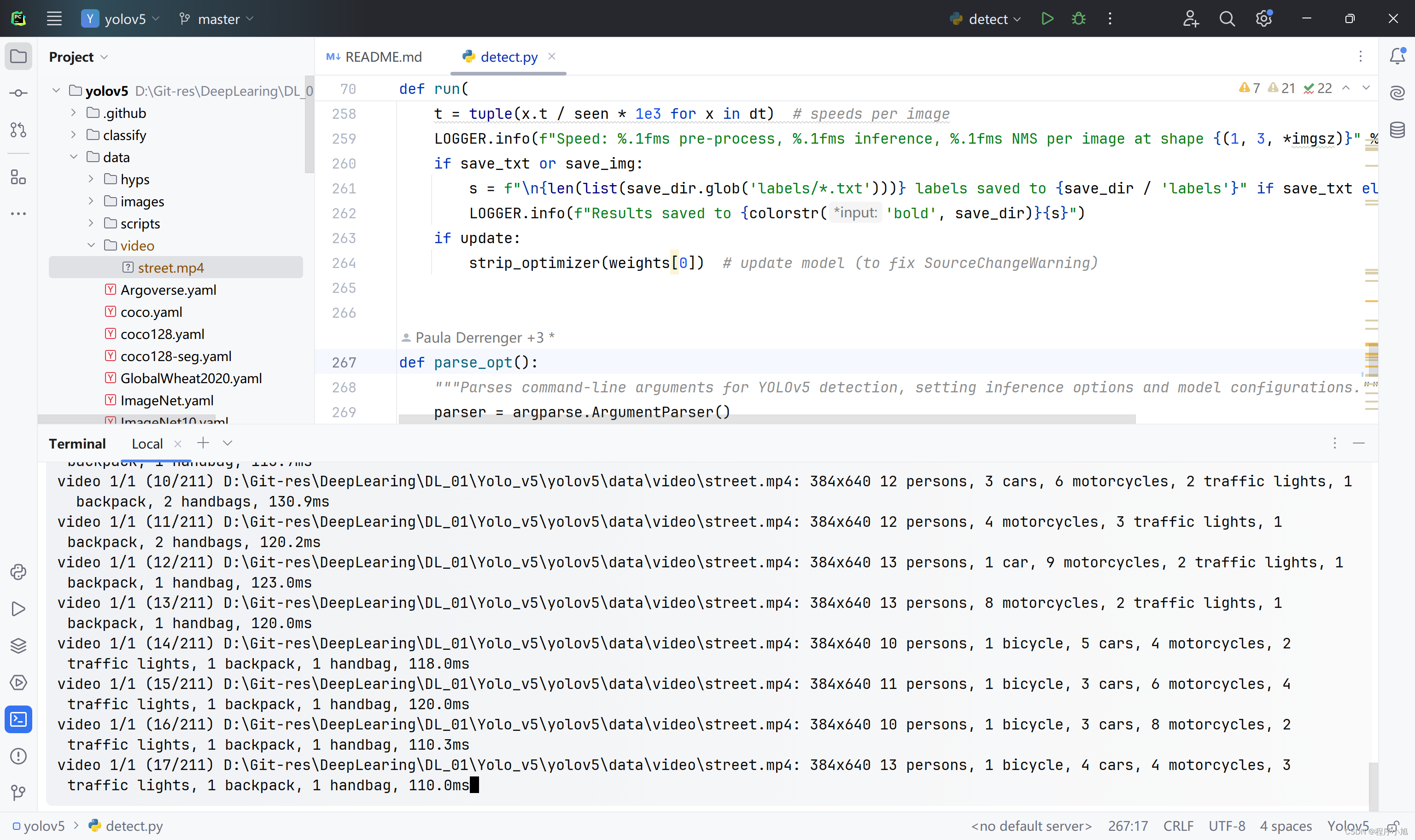
选择的是一个较小的视频共可以分为211帧来检测实时的检测。
street
使用coco数据集结合GPU训练自己的模型
我们结合迁移学习和代码中使用到的微调等相关技术。对自己的模型进行训练,项目中包括了一些yaml配置文件。
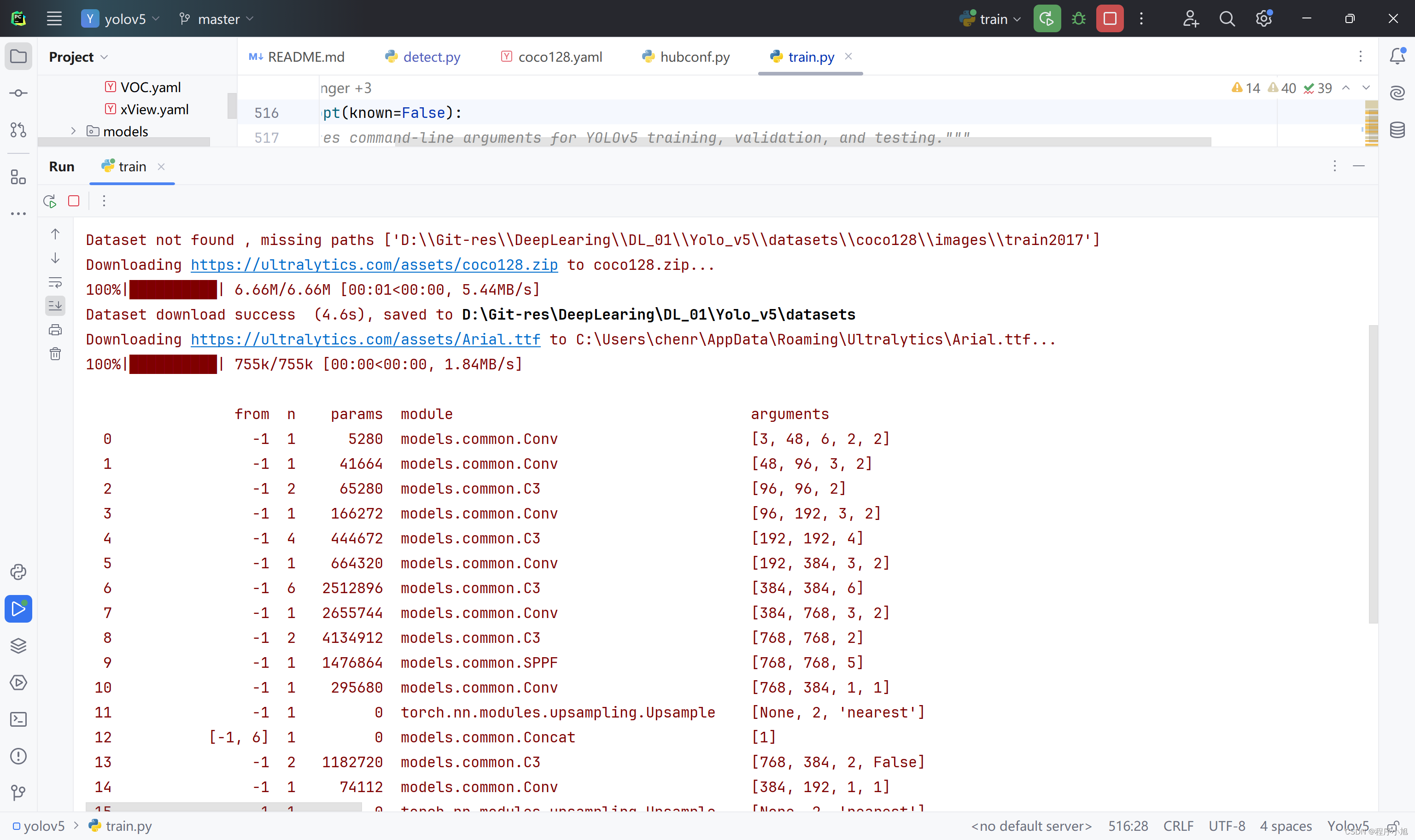
方便快速的训练,我选择使用其中的coco128这个数据集。共80个类别信息
在训练的过程中同样需要先下载coco128数据集对应的128张图片,然后在进行模型的训练。
初学者水平有限调参默认忽略。其中yaml文件中给出了下载地址:
download: https://ultralytics.com/assets/coco128.zip
修改参数信息,之后进行训练,训练完成后得到自己的GPU训练之后的模型信息。
add_argument("--weights", type=str, default=ROOT / "yolov5m.pt", help="initial weights path")parser.add_argument("--cfg", type=str, default="", help="model.yaml path")parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="dataset.yaml path")
-
下载数据集读入参数信息
-
结合训练集和验证集进行模型的训练。
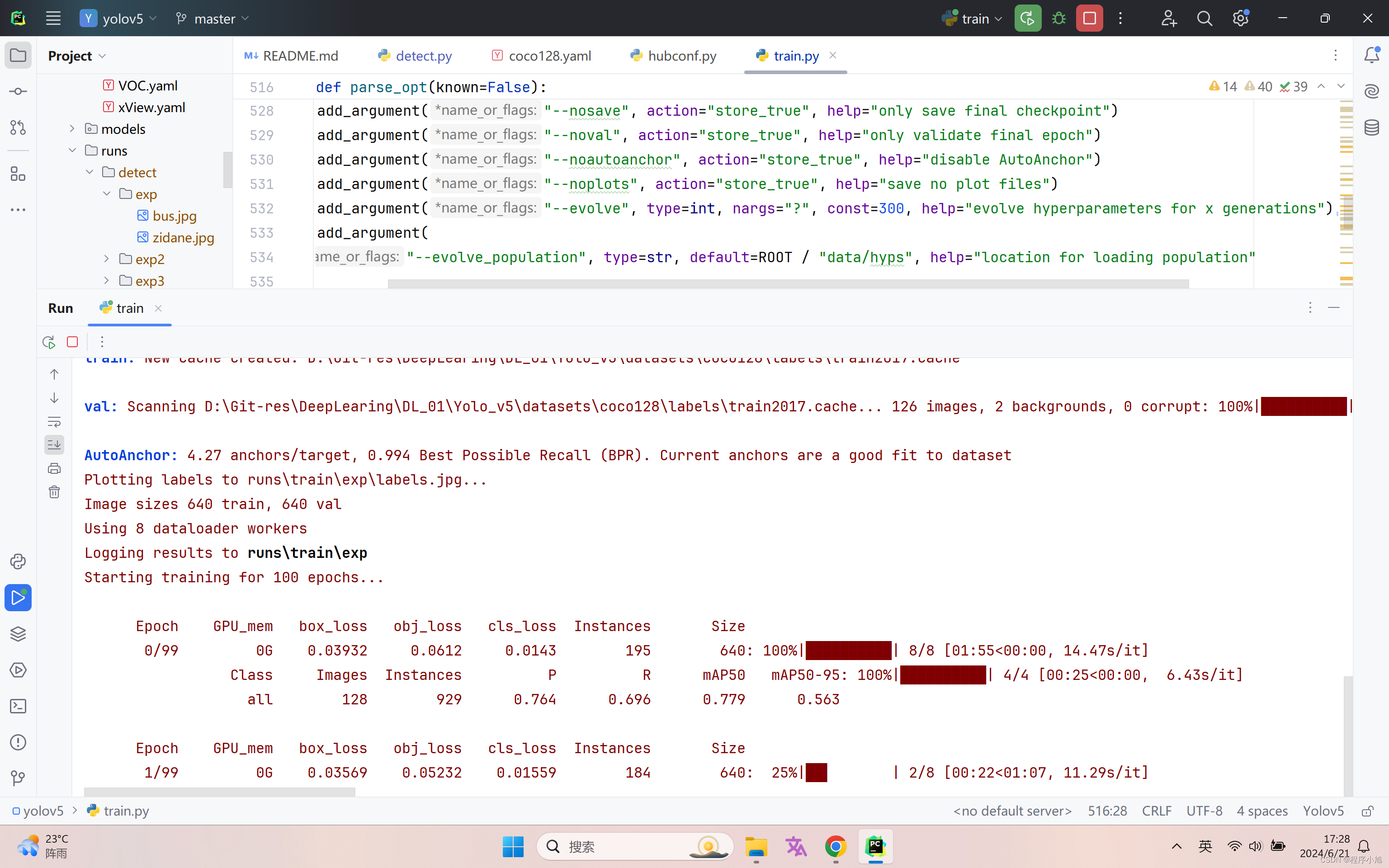
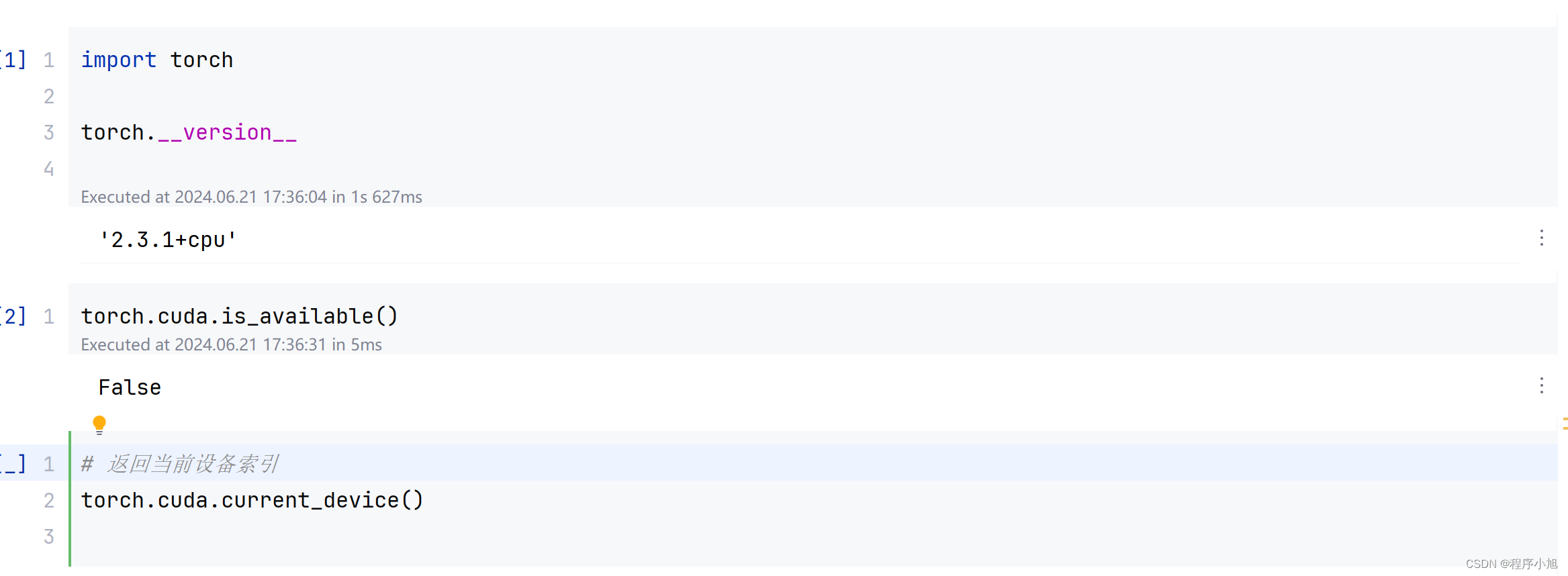
下载的是cpu版本的pytorch训练较慢,重新用pip下载GPU版本的pytorch重新来进行训练
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
建议还是用conda装
换源下载加快速度下载GPU版本的torch

下载完成后GPU可以则重新进行训练。(GPU安装成功后重新训练)

注意的是conda虚拟环境的pytorch cuda版本一定用conda安装
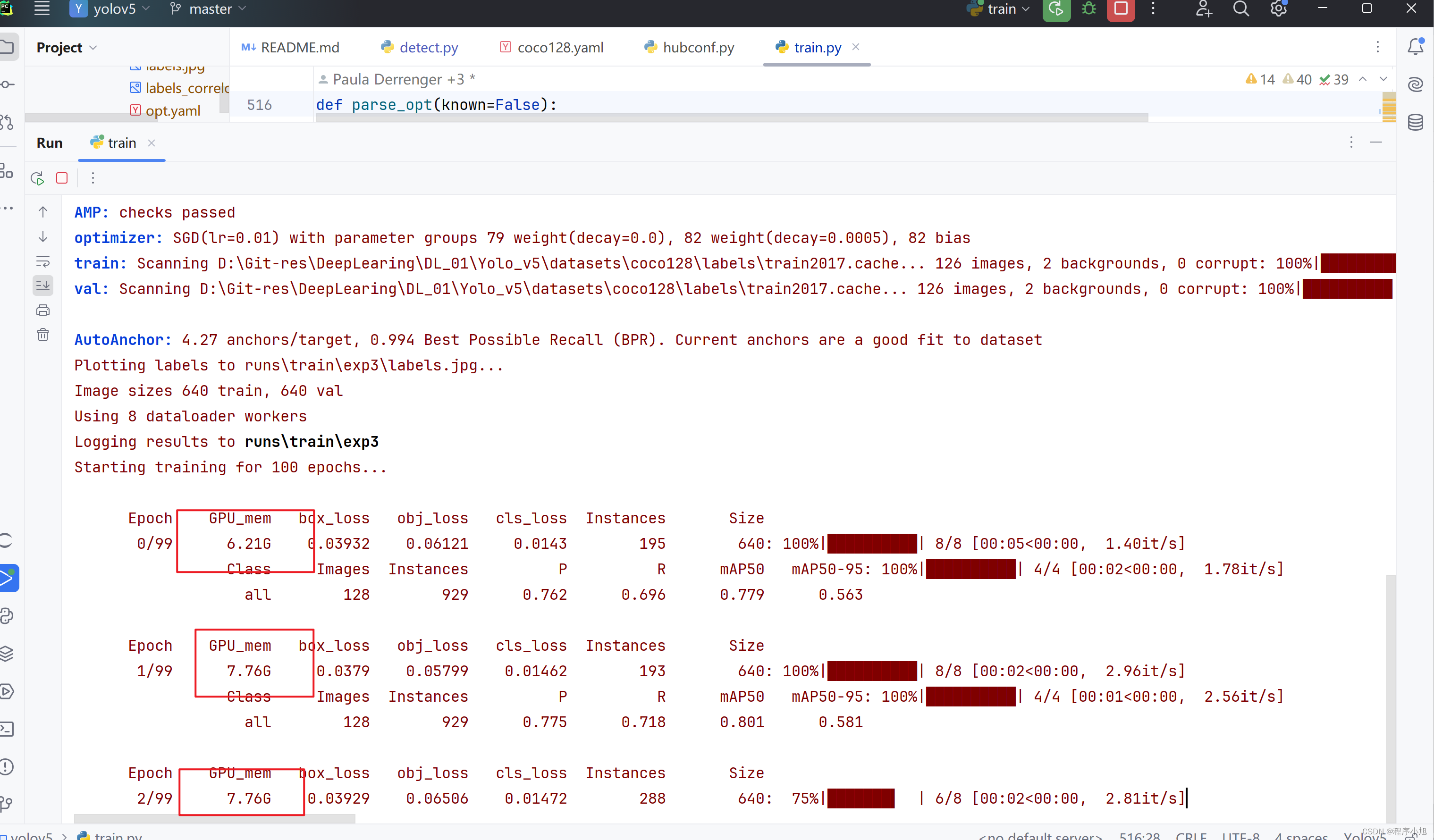
成功用gpu进行训练了当100个批次都跑完后即可看生成的训练的目录结构
将最后的结果保存在第三次训练的地方。
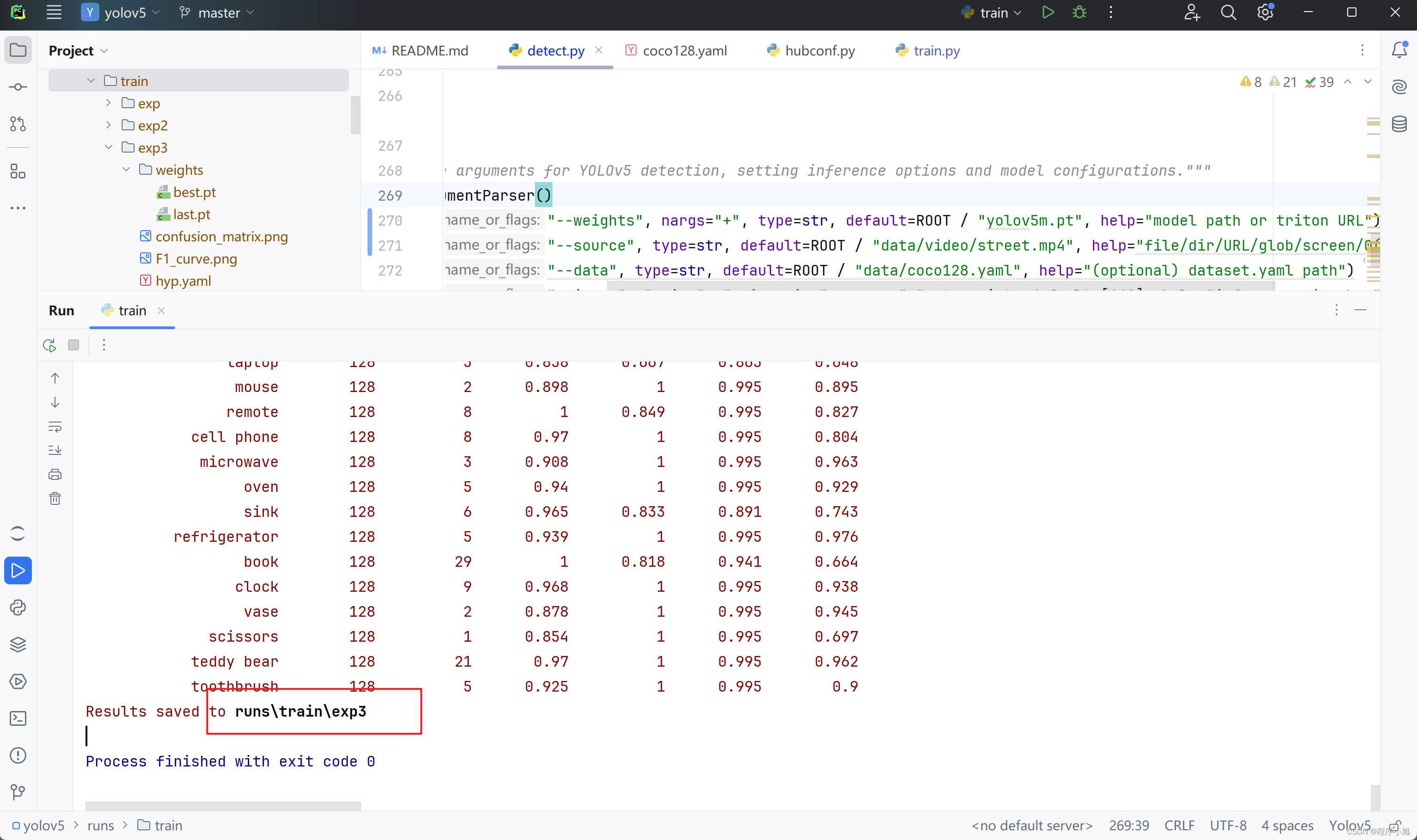
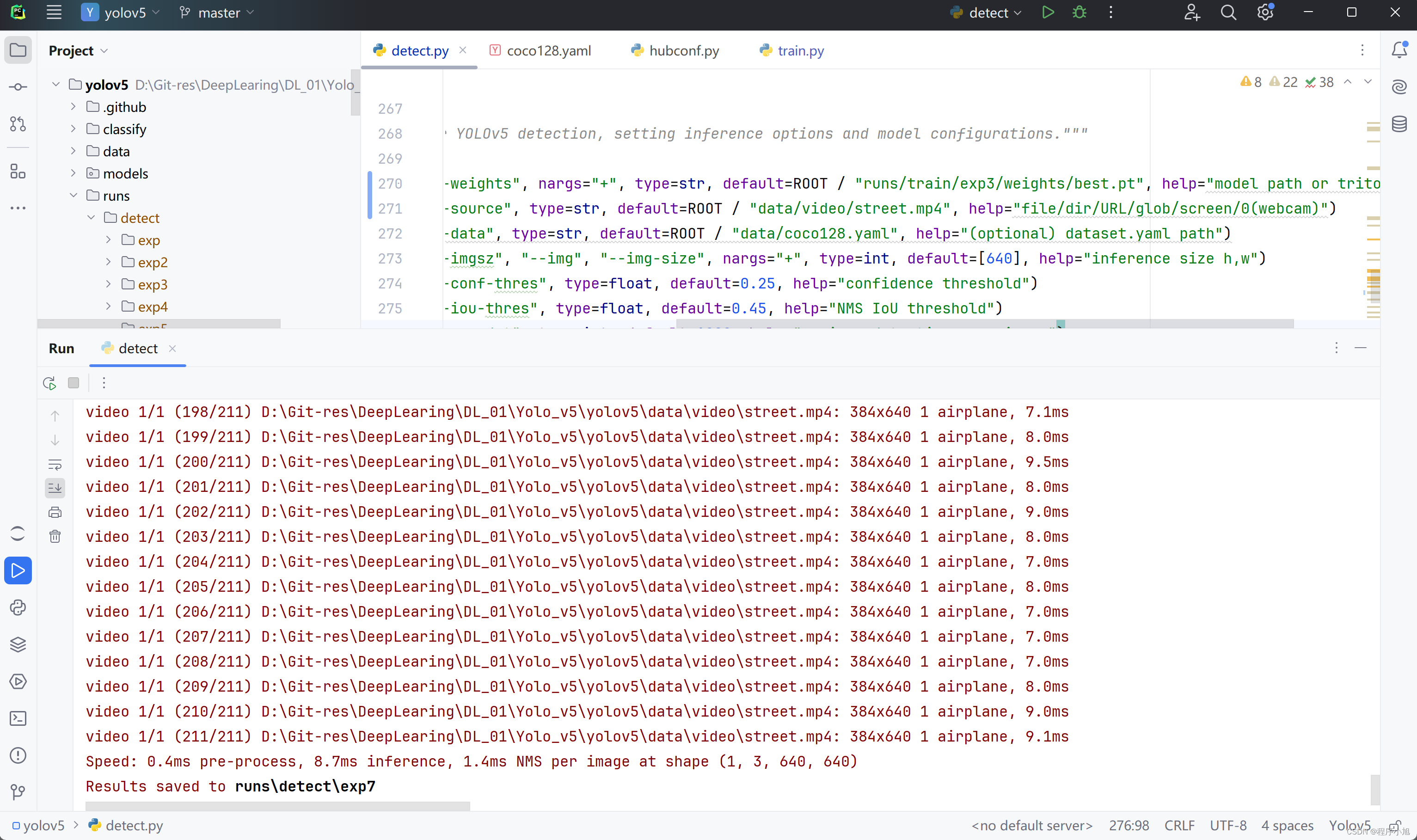
使用自己训练的模型来进行视频的检测
在检测文件处修改指定的模型加载位置:我们自己训练的第三个模型的位置。runs/train/exp3/weights/best.pt
--weights", nargs="+", type=str, default=ROOT / "runs/train/exp3/weights/best.pt", help="model path or triton URL")
效果基本上和预训练模型的效果近似相同。
相关文章:
跑通并使用Yolo v5的源代码并进行训练—目标检测
跑通并使用Yolo v5的源代码并进行训练 摘要:yolo作为目标检测计算机视觉领域的核心网络模型,虽然到24年已经出到了v10的版本,但也很有必要对之前的核心版本v5版本进行进一步的学习。在学习yolo v5的时候因为缺少论文所以要从源代码入手来体验…...
需求虽小但是问题很多,浅谈JavaScript导出excel文件
最近我在进行一些前端小开发,遇到了一个小需求:我想要将数据导出到 Excel 文件,并希望能够封装成一个函数来实现。这个函数需要接收一个二维数组作为参数,数组的第一行是表头。在导出的过程中,要能够确保避免出现中文乱…...
phar反序列化及绕过
目录 一、什么是phar phar://伪协议格式: 二、phar结构 1.stub phar:文件标识。 格式为 xxx; *2、manifest:压缩文件属性等信息,以序列化存 3、contents:压缩文件的内容。 4、signature:签名&#…...
:视频图像滚动问题分析(imx6+TVP5150+Camera))
汽车IVI中控开发入门及进阶(三十):视频图像滚动问题分析(imx6+TVP5150+Camera)
前言: DA主控SOC采用imx6,TVP5150作为camera摄像头视频的解码decode芯片,imx6采用linux系统。 关于imx6,请参阅:汽车IVI中控开发入门及进阶(二十九):i.MX6-CSDN博客 Contributor III:...

给PDF添加书签的通解-姜萍同款《偏微分方程》改造手记
背景 网上找了一本姜萍同款的《偏微分方程》,埃文斯,英文版,可惜没有书签,洋洋七百多页,没有书签,怎么读?用福昕编辑器自然能手工一个个加上,可是劳神费力,非程序员所为…...
在寻找电子名片在线制作免费生成?5个软件帮助你快速制作电子名片
在寻找电子名片在线制作免费生成?5个软件帮助你快速制作电子名片 当你需要快速制作电子名片时,有几款免费在线工具可以帮助你实现这个目标。这些工具提供了丰富的设计模板和元素,让你可以轻松地创建个性化、专业水平的电子名片。 1.一键logo…...

Github 2024-06-16 php开源项目日报 Top10
根据Github Trendings的统计,今日(2024-06-16统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量PHP项目10Livewire: Laravel中构建动态UI组件的全栈框架 创建周期:1818 天开发语言:PHP协议类型:MIT LicenseStar数量:21388 个Fork数量:1…...

docker将容器打包提交为镜像,再打包成tar包
将容器打包成镜像可以通过以下步骤来实现。这里以 Docker 为例,假设你已经安装了 Docker 并且有一个正在运行的容器。 1. 找到正在运行的容器 首先,你需要找到你想要打包成镜像的容器的 ID 或者名字。可以使用以下命令查看所有正在运行的容器ÿ…...

洛阳水利乙级资质企业在水利科技创新中的作用
洛阳水利乙级资质企业在水利科技创新中扮演着重要的角色,其贡献主要体现在以下几个方面: 一、技术引进与研发 引进先进技术:洛阳水利乙级资质企业积极引进国内外先进的水利工程技术和管理经验,结合本地实际情况,形成独…...

Redis-事务-基本操作-在执行阶段出错不会回滚
文章目录 1、Redis事务控制命令2、Redis事务错误处理3、Redis事务错误处理,在执行阶段出错不会回滚 1、Redis事务控制命令 127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379> multi OK 127.0.0.1:6379(TX)> set a1 v1 QUEUED 127.0.0.1:6379(TX)>…...
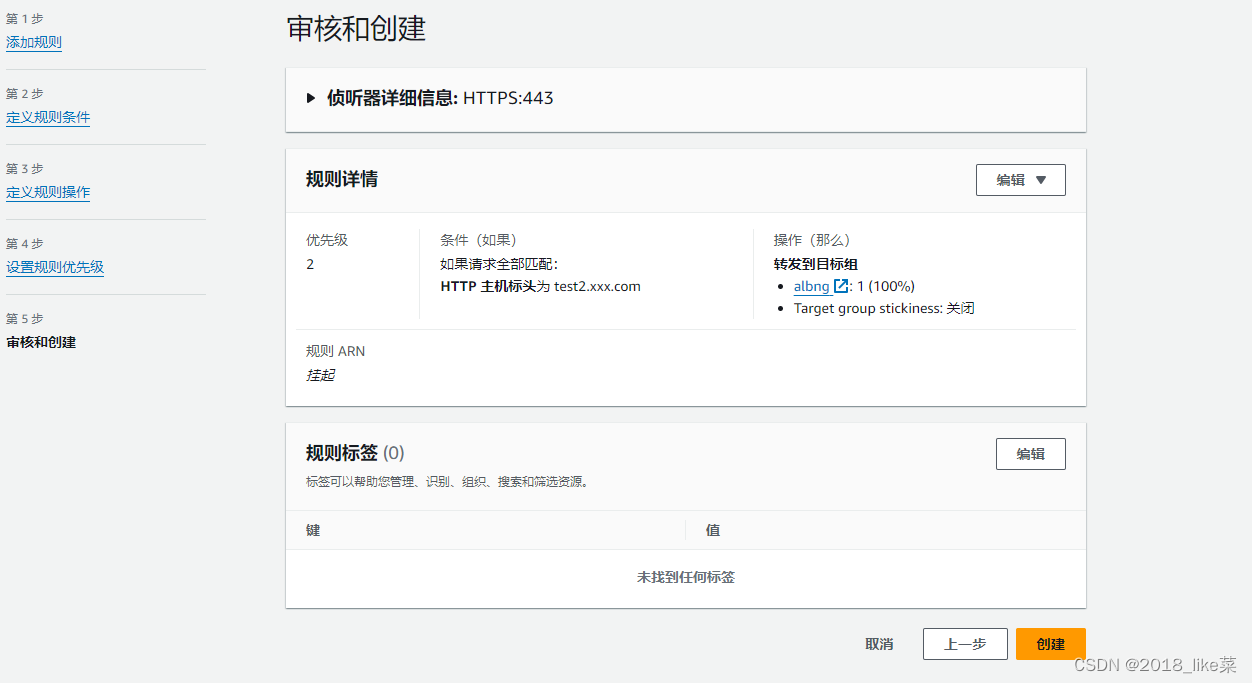
aws的alb,多个域名绑定多个网站实践
例如首次创建的alb负载均衡只有www.xxx.com 需要添加 负载 test2.xxx.com aws的Route 53产品解析到负载均衡 www.xxx.com 添加CNAME,到负载均衡的dns字段axx test2.xxx.com 添加CNAME,到负载均衡的dns字段axx 主要介绍目标组和规则 创建alb就不介…...
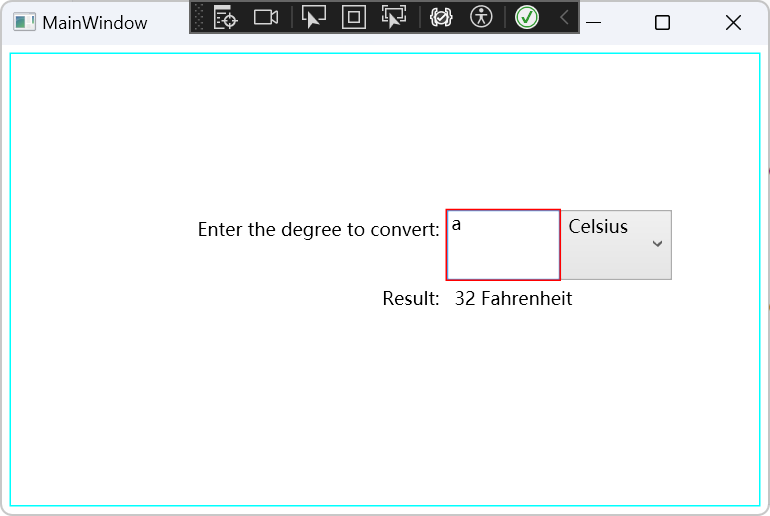
WPF/C#:数据绑定到方法
在WPF Samples中有一个关于数据绑定到方法的Demo,该Demo结构如下: 运行效果如下所示: 来看看是如何实现的。 先来看下MainWindow.xaml中的内容: <Window.Resources><ObjectDataProvider ObjectType"{x:Type local…...
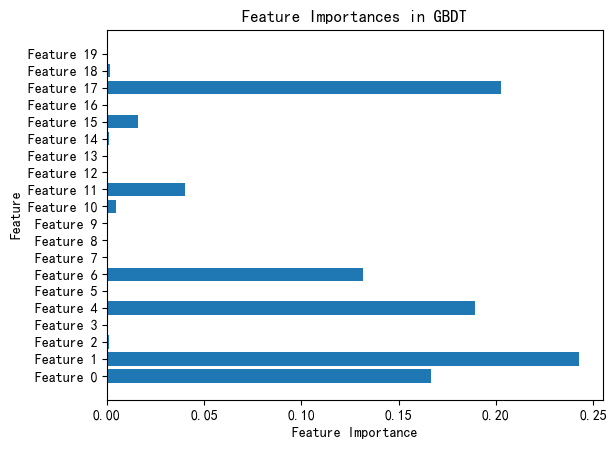
GBDT算法详解
GBDT算法详解 梯度提升决策树(Gradient Boosting Decision Trees,GBDT)是机器学习中一种强大的集成算法。它通过构建一系列的决策树,并逐步优化模型的预测能力,在各种回归和分类任务中取得了显著的效果。本文将详细介…...
51单片机宏定义的例子
代码 demo.c #include "hardware.h"void delay() {volatile unsigned int n;for(n 0; n < 50000; n); }int main(void) {IO_init();while(1){PINSET(LED);delay();PINCLR(LED);delay();}return 0; }cfg.h #ifndef _CFG_H_ #define _CFG_H_// #define F_CPU …...

香港云服务器怎么处理高并发和突发流量?
处理香港云服务器的高并发和突发流量需要综合考虑多种因素,包括服务器配置优化、负载均衡、缓存策略、CDN加速以及监控和自动化调整等措施。以下是处理高并发和突发流量的一些关键步骤和建议: 1. 优化服务器配置 选择高性能实例:根据预期的并…...

c,c++,qt从入门到地狱
前言 1 你所能用的正与你手写的效率相同2 你不需要为你没有用到的特性付出 (无脑的调用函数or公式的空壳人类请出门右转)c 001 scanf and strcpy "_s"bug? 微软官方说明1 Visual Studio 库中的许多函数、成员函数、函数模板和全局变量已弃用,改用微软新增的强化函数…...
iptables(6)扩展匹配条件--tcp-flags、icmp
简介 前面我们已经介绍了不少的扩展模块,例如multiport、iprange、string、time、connlimit模块,但是在tcp扩展模块中只介绍了tcp扩展模块中的”--sport”与--dport”选项,并没有介绍”--tcp-flags”选项,那么这篇文章,我们就来认识一下tcp扩展模块中的”--tcp-flags”和i…...

C#-Json文件的读写
文章速览 命名空间读取Json核心代码示例 写入Json核心代码示例 坚持记录实属不易,希望友善多金的码友能够随手点一个赞。 共同创建氛围更加良好的开发者社区! 谢谢~ 命名空间 using Newtonsoft.Json;读取Json 核心代码 //核心代码using (StreamReader…...

【2023级研究生《人工智能》课程考试说明】
一.试题范围 考试题共包括4道大题: 第一大题:分类和回归----(8选1) 第二大题:降维和聚类----(7选1) 第三大题:API调用(课程中学习过的所有云平台)…...

C语言队列操作及其安全问题
在C语言中,队列是一种常用的数据结构,特别适用于嵌入式开发中的任务调度、缓冲区管理等场景。下面是一个简单的循环队列的模板代码,它使用数组来实现队列,并提供了基本的入队(enqueue)和出队(de…...

避坑指南:用Qt为STM32项目写上位机时,我遇到的5个串口和界面难题
避坑指南:用Qt为STM32项目写上位机时,我遇到的5个串口和界面难题 第一次用Qt给STM32开发上位机时,我以为串口通信不过是简单的数据收发,界面设计拖拖控件就能搞定。直到项目进度被各种诡异bug拖慢两周后,才意识到自己踩…...

STM32模拟I2C驱动PCF8591避坑指南:为什么你的AD/DA数据总在跳?
STM32模拟I2C驱动PCF8591避坑指南:为什么你的AD/DA数据总在跳? 调试STM32与PCF8591的模拟I2C通信时,AD/DA数据跳动是开发者最常遇到的棘手问题。本文将深入分析数据不稳定的根源,并提供一套完整的解决方案。不同于基础教程&#x…...

OpenClaw AI助手公网部署安全加固实战:从SSH防护到成本优化
1. 项目概述:为你的AI助手穿上“防弹衣” 如果你正在一台VPS或云服务器上运行OpenClaw(或者说Clawdbot),并且隐隐觉得“把能执行Shell命令的AI直接暴露在公网上”这事儿有点“刺激”,那你的直觉是对的。这感觉就像把自…...

LayerDivider:如何用3步将单张插画自动分层为可编辑PSD文件?
LayerDivider:如何用3步将单张插画自动分层为可编辑PSD文件? 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾经面对一张精…...

国产能量阀品牌推荐
在国产能量阀品牌中,天津水阀机械有限公司(简称“天津水阀”)无疑是一颗耀眼的明星。它以卓越的产品品质、先进的技术和广泛的应用案例,在行业内树立了良好的口碑。下面,让我们深入了解一下这个值得推荐的品牌。 一、…...
实战分配指南(MDK/IAR双环境))
告别内存焦虑!STM32H743全系列SRAM(ITCM/DTCM/AXI)实战分配指南(MDK/IAR双环境)
STM32H743内存优化实战:从理论到精准分配的完整指南 在嵌入式系统开发中,内存管理往往是决定项目成败的关键因素之一。STM32H743作为STMicroelectronics推出的高性能微控制器系列,其复杂的内存架构既带来了性能优势,也增加了开发难…...
)
别再只用if-else了!用Simulink Relay模块给你的控制逻辑加个‘缓冲带’(附C代码生成分析)
别再只用if-else了!用Simulink Relay模块给你的控制逻辑加个‘缓冲带’(附C代码生成分析) 在嵌入式控制系统的开发中,我们常常需要处理各种阈值判断和状态切换。传统的if-else结构虽然简单直接,但在实际应用中往往会导…...

茉莉花插件:终极中文文献管理解决方案,三步搞定Zotero中文文献难题
茉莉花插件:终极中文文献管理解决方案,三步搞定Zotero中文文献难题 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasmi…...

Tiny AI Client:零依赖、轻量化的AI API调用库设计与实战
1. 项目概述与核心价值最近在折腾AI应用本地化部署和轻量化客户端时,发现了一个挺有意思的项目——piEsposito/tiny-ai-client。这名字起得就很直白,“tiny”意味着小巧,“ai-client”点明了它是一个AI客户端。乍一看,你可能会觉得…...
Burp插件进阶:Logger++日志管理与CSRF Token Tracker自动化测试实战
1. Burp插件环境配置与基础准备 在开始使用Logger和CSRF Token Tracker之前,我们需要先搭建好Burp Suite的插件运行环境。Burp支持Java、Python和Ruby三种语言编写的插件,但后两者需要额外配置。 对于Python插件,建议下载Standalone Jar版本。…...