GBDT算法详解
GBDT算法详解
梯度提升决策树(Gradient Boosting Decision Trees,GBDT)是机器学习中一种强大的集成算法。它通过构建一系列的决策树,并逐步优化模型的预测能力,在各种回归和分类任务中取得了显著的效果。本文将详细介绍GBDT算法的原理,并展示其在实际数据集上的应用。
GBDT算法原理
GBDT是一种集成学习方法,通过逐步建立多个决策树,每棵树都在前一棵树的基础上进行改进。GBDT的基本思想是逐步减少残差(即预测误差),使模型的预测能力不断提高。
算法步骤
- 初始化模型:使用常数模型初始化,比如回归问题中可以用目标值的均值初始化模型。
- 计算残差:计算当前模型的残差,即预测值与真实值之间的差异。
- 拟合残差:用新的决策树拟合残差,并更新模型。
- 更新模型:将新决策树的预测结果加到模型中,以减少残差。
- 重复步骤2-4:直到达到预设的迭代次数或残差足够小。
公式表示
初始化模型:
F 0 ( x ) = arg min γ ∑ i = 1 n L ( y i , γ ) F_0(x) = \arg\min_{\gamma} \sum_{i=1}^{n} L(y_i, \gamma) F0(x)=argγmini=1∑nL(yi,γ)
对于每一次迭代 (m = 1, 2, \ldots, M):
-
计算负梯度(残差): r i m = − [ ∂ L ( y i , F ( x i ) ) ∂ F ( x i ) ] F ( x ) = F m − 1 ( x ) r_{im} = -\left[ \frac{\partial L(y_i, F(x_i))}{\partial F(x_i)} \right]_{F(x) = F_{m-1}(x)} rim=−[∂F(xi)∂L(yi,F(xi))]F(x)=Fm−1(x)
-
拟合一个新的决策树来预测残差: h m ( x ) = arg min h ∑ i = 1 n ( r i m − h ( x i ) ) 2 h_m(x) = \arg\min_{h} \sum_{i=1}^{n} (r_{im} - h(x_i))^2 hm(x)=arghmini=1∑n(rim−h(xi))2
-
更新模型: F m ( x ) = F m − 1 ( x ) + ν h m ( x ) F_m(x) = F_{m-1}(x) + \nu h_m(x) Fm(x)=Fm−1(x)+νhm(x)
其中, ν \nu ν是学习率,控制每棵树对最终模型的贡献。
GBDT算法的特点
- 高准确性:GBDT通过逐步减少残差,不断优化模型,使其在很多任务中具有很高的准确性。
- 灵活性:GBDT可以处理回归和分类任务,并且可以使用各种损失函数。
- 鲁棒性:GBDT对数据的噪声和异常值有一定的鲁棒性。
- 可解释性:决策树本身具有一定的可解释性,通过特征重要性等方法可以解释GBDT模型。
GBDT参数说明
以下是GBDT(Gradient Boosting Decision Trees,梯度提升决策树)常用参数及其详细说明:
| 参数名称 | 描述 | 默认值 | 示例 |
|---|---|---|---|
n_estimators | 树的棵数,提升迭代的次数 | 100 | n_estimators=200 |
learning_rate | 学习率,控制每棵树对最终模型的贡献 | 0.1 | learning_rate=0.05 |
max_depth | 树的最大深度,控制每棵树的复杂度 | 3 | max_depth=4 |
min_samples_split | 分裂一个内部节点需要的最少样本数 | 2 | min_samples_split=5 |
min_samples_leaf | 叶子节点需要的最少样本数 | 1 | min_samples_leaf=3 |
subsample | 样本采样比例,用于训练每棵树 | 1.0 | subsample=0.8 |
max_features | 寻找最佳分割时考虑的最大特征数 | None | max_features='sqrt' |
loss | 要优化的损失函数 | deviance | loss='exponential' |
criterion | 分裂节点的标准 | friedman_mse | criterion='mae' |
init | 初始估计器 | None | init=some_estimator |
random_state | 随机数种子,用于结果复现 | None | random_state=42 |
verbose | 控制训练过程信息的输出频率 | 0 | verbose=1 |
warm_start | 是否使用上次调用的解决方案来初始化训练 | False | warm_start=True |
presort | 是否预排序数据以加快分裂查找 | deprecated | - |
validation_fraction | 用于提前停止训练的验证集比例 | 0.1 | validation_fraction=0.2 |
n_iter_no_change | 如果在若干次迭代内验证集上的损失没有改善,则提前停止训练 | None | n_iter_no_change=10 |
tol | 提前停止的阈值 | 1e-4 | tol=1e-3 |
ccp_alpha | 最小成本复杂度修剪参数 | 0.0 | ccp_alpha=0.01 |
通过合理调整这些参数,可以优化GBDT模型在特定任务和数据集上的性能。
GBDT算法在回归问题中的应用
在本节中,我们将使用波士顿房价数据集来展示如何使用GBDT算法进行回归任务。
导入库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error, r2_score加载和预处理数据
# 生成合成回归数据集
X, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=42)# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
训练GBDT模型
# 训练GBDT模型
gbdt = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
gbdt.fit(X_train, y_train)
预测与评估
# 预测
y_pred = gbdt.predict(X_test)# 评估
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Mean Squared Error: {mse:.2f}')
print(f'R^2 Score: {r2:.2f}')
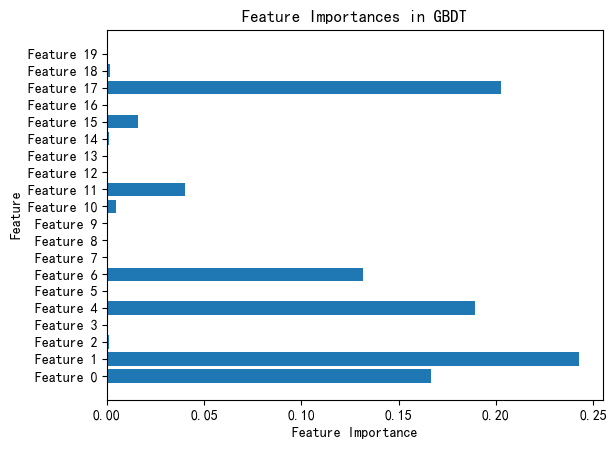
特征重要性
# 特征重要性
# 特征重要性
feature_importances = gbdt.feature_importances_
plt.barh(range(X.shape[1]), feature_importances, align='center')
plt.yticks(np.arange(X.shape[1]), [f'Feature {i}' for i in range(X.shape[1])])
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.title('Feature Importances in GBDT')
plt.show()
GBDT算法在分类问题中的应用
在本节中,我们将使用20类新闻组数据集来展示如何使用GBDT算法进行文本分类任务。
导入库
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report加载和预处理数据
# 生成分类数据集
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=42)# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)训练GBDT模型
# 训练GBDT模型
gbdt = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
gbdt.fit(X_train, y_train)预测与评估
# 预测
y_pred = gbdt.predict(X_test)# 评估
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')# 混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(conf_matrix)# 分类报告
class_report = classification_report(y_test, y_pred)
print('Classification Report:')
print(class_report)结语
本文详细介绍了GBDT算法的原理和特点,并展示了其在回归和分类任务中的应用。首先介绍了GBDT算法的基本思想和公式,然后展示了如何在回归数据集使用GBDT进行回归任务,以及如何在分类数据集上使用GBDT进行文本分类任务。
我的其他同系列博客
支持向量机(SVM算法详解)
knn算法详解
GBDT算法详解
XGBOOST算法详解
CATBOOST算法详解
随机森林算法详解
lightGBM算法详解
对比分析:GBDT、XGBoost、CatBoost和LightGBM
机器学习参数寻优:方法、实例与分析
相关文章:
GBDT算法详解
GBDT算法详解 梯度提升决策树(Gradient Boosting Decision Trees,GBDT)是机器学习中一种强大的集成算法。它通过构建一系列的决策树,并逐步优化模型的预测能力,在各种回归和分类任务中取得了显著的效果。本文将详细介…...
51单片机宏定义的例子
代码 demo.c #include "hardware.h"void delay() {volatile unsigned int n;for(n 0; n < 50000; n); }int main(void) {IO_init();while(1){PINSET(LED);delay();PINCLR(LED);delay();}return 0; }cfg.h #ifndef _CFG_H_ #define _CFG_H_// #define F_CPU …...

香港云服务器怎么处理高并发和突发流量?
处理香港云服务器的高并发和突发流量需要综合考虑多种因素,包括服务器配置优化、负载均衡、缓存策略、CDN加速以及监控和自动化调整等措施。以下是处理高并发和突发流量的一些关键步骤和建议: 1. 优化服务器配置 选择高性能实例:根据预期的并…...

c,c++,qt从入门到地狱
前言 1 你所能用的正与你手写的效率相同2 你不需要为你没有用到的特性付出 (无脑的调用函数or公式的空壳人类请出门右转)c 001 scanf and strcpy "_s"bug? 微软官方说明1 Visual Studio 库中的许多函数、成员函数、函数模板和全局变量已弃用,改用微软新增的强化函数…...
iptables(6)扩展匹配条件--tcp-flags、icmp
简介 前面我们已经介绍了不少的扩展模块,例如multiport、iprange、string、time、connlimit模块,但是在tcp扩展模块中只介绍了tcp扩展模块中的”--sport”与--dport”选项,并没有介绍”--tcp-flags”选项,那么这篇文章,我们就来认识一下tcp扩展模块中的”--tcp-flags”和i…...

C#-Json文件的读写
文章速览 命名空间读取Json核心代码示例 写入Json核心代码示例 坚持记录实属不易,希望友善多金的码友能够随手点一个赞。 共同创建氛围更加良好的开发者社区! 谢谢~ 命名空间 using Newtonsoft.Json;读取Json 核心代码 //核心代码using (StreamReader…...

【2023级研究生《人工智能》课程考试说明】
一.试题范围 考试题共包括4道大题: 第一大题:分类和回归----(8选1) 第二大题:降维和聚类----(7选1) 第三大题:API调用(课程中学习过的所有云平台)…...

C语言队列操作及其安全问题
在C语言中,队列是一种常用的数据结构,特别适用于嵌入式开发中的任务调度、缓冲区管理等场景。下面是一个简单的循环队列的模板代码,它使用数组来实现队列,并提供了基本的入队(enqueue)和出队(de…...
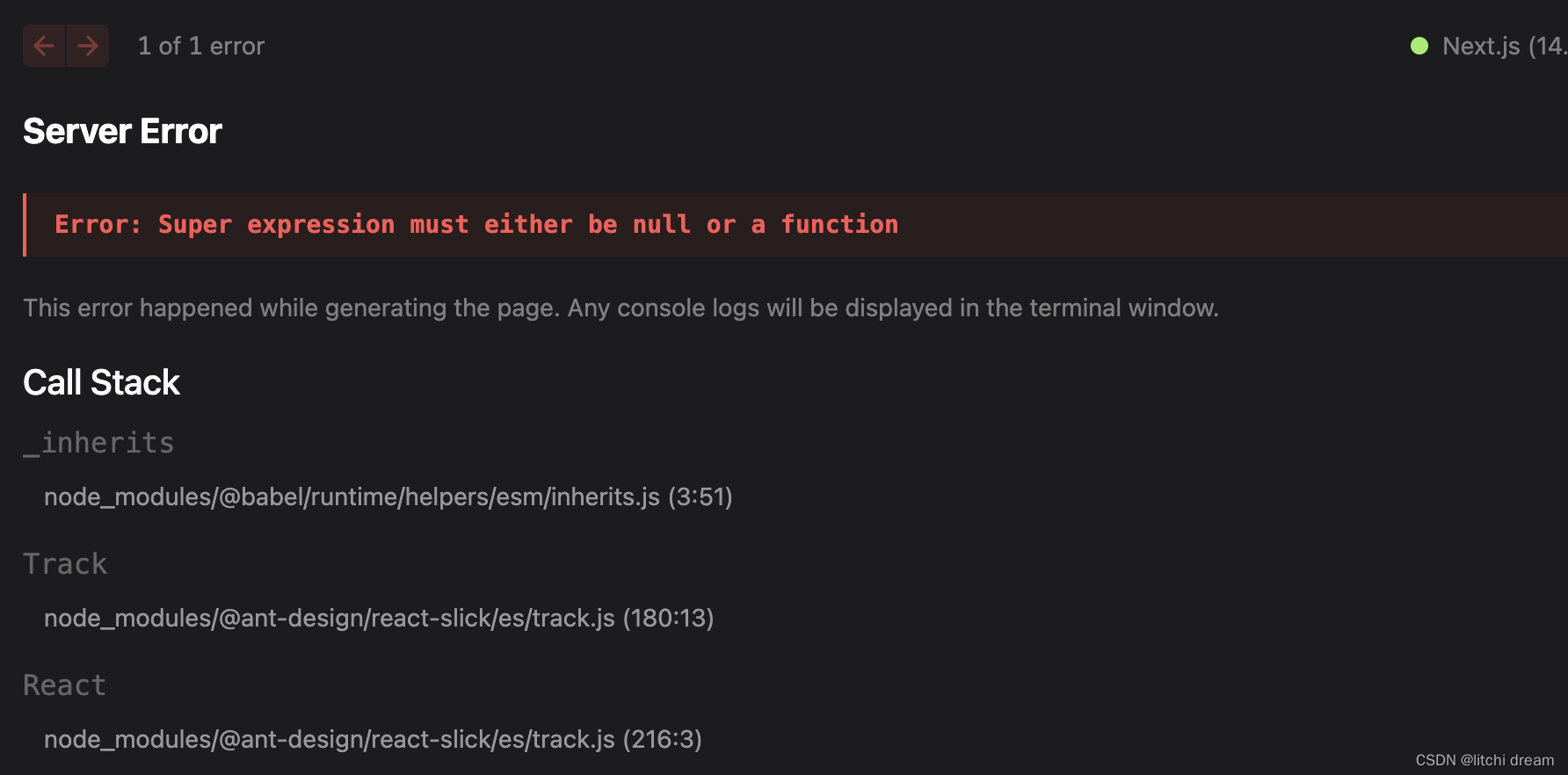
next.js v14 升级全步骤|迁移 pages Router 到 App Router
【概括】本文升级整体按照官网文档指引进行,在迁移 pages Router 前先看了官网的实操视频。 【注意】文章内对 .babel.ts、next.config.js 进行了多次更改,最终配置可见 报错3: Server Error ReferenceError: React is not defined 一、升级 Next.js 版…...

如何在Ubuntu上安装WordPress
如何在Ubuntu上安装WordPress 执行系统更新 apt update && apt upgrade第一步 安装 Apache apt install apache2确认 Apache 安装是否成功. systemctl status apache2安装成功后 打开浏览器输入 http://server-ip-address 第二步 安装 MySQL apt install mariad…...

处理导入Excel文件过大导致Zip bomb detected的问题
处理导入Excel文件过大导致Zip bomb detected的问题 处理导入Excel文件过大导致Zip bomb detected的问题解决方案完整示例代码处理内存溢出问题优化处理大文件的策略 处理导入Excel文件过大导致Zip bomb detected的问题 在Java应用中导入Excel文件时,可能会遇到文件…...

【FFmpeg】AVIOContext结构体
【FFmpeg】AVIOContext结构体 1.AVIOContext结构体的定义 参考: FFMPEG结构体分析:AVIOContext 示例工程: 【FFmpeg】调用ffmpeg库实现264软编 【FFmpeg】调用ffmpeg库实现264软解 【FFmpeg】调用ffmpeg库进行RTMP推流和拉流 【FFmpeg】调用…...
Python控制结构
文章目录 控制结构1. 条件语句1.1 if语句1.2 elif语句1.3 else 语句 2. 循环语句2.1 for循环2.2 while循环 控制循环的语句3.1 break语句3.2 continue语句3.3 else语句与循环配合 控制结构 Python中的控制结构是指管理代码执行流程的语句和机制,包括条件语句、循环…...

OpenCV--图形轮廓
图形轮廓 图像轮廓查找轮廓绘制轮廓计算轮廓的面积和周长多边形逼近与凸包外接矩形 图像轮廓 import cv2 import numpy as np""" 图形轮廓--具有相同颜色或灰度的连续点的曲线 用于图形分析和物体的识别和检测 注意:为了检测的准确性,必…...

MYSQL通过EXPLAIN关键字来分析SQL查询的执行计划,判断是否命中了索引
在MySQL中,你可以通过EXPLAIN关键字来分析SQL查询的执行计划,从而判断是否命中了索引。 准备查询语句: 首先,你需要一个带有WHERE子句的SELECT查询,因为WHERE子句中的条件通常与索引相关联。例如: SELECT …...
)
clean code-代码整洁之道 阅读笔记(第十二章)
第十二章 系统 12.1 通过选进设计达到整洁目的 Kent Beck关于简单设计的四条规则,对于创建具有良好设计的软件有着莫大的帮助。 据Kent所述,只要遵循以下规则,设计就能变得"简单":运行所有测试;不可重复&…...

FFmpeg YUV编码为H264
使用FFmpeg库把YUV420P文件编码为H264文件,FFmpeg版本为4.4.2-0。 需要yuv测试文件的,可以从我上传的MP4文件中用ffmpeg提取,命令如下: ffmpeg -i <input.mp4> -pix_fmt yuv420p <output.yuv> 代码如下:…...

【C语言】顺序表(上卷)
什么是数据结构? 数据结构是由“数据”和“结构”两词组合而来的。 数据需要管理。数据结构就是计算机存储、组织数据的方式。比如一个班级就是一个结构,管理的就是班级里的学生。如果我们要找三年2班的同学李华,就可以直接去三年2班找而不…...
Luma AI如何注册:文生视频领域的新星
文章目录 Luma AI如何注册:文生视频领域的新星一、Luma 注册方式二、Luma 的效果三、Luma 的优势四、Luma 的功能总结 Luma AI如何注册:文生视频领域的新星 近年来,Luma AI 凭借其在文生视频领域的创新技术,逐渐成为行业的新星。…...

一站式实时数仓Hologres整体能力介绍
讲师:阿里云Hologres PD丁烨 一、产品定位 随着技术的进步,大数据正从规模化转向实时化处理。用户对传统的T1分析已不满足,期望获得更高时效性的计算和分析能力。例如实时大屏,城市大脑的交通监控、风控和实时的个性化推荐&…...

5分钟掌握飞书文档高效转换:开源浏览器扩展的完整解决方案
5分钟掌握飞书文档高效转换:开源浏览器扩展的完整解决方案 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 还在为飞书文档格式转换而头疼吗?复…...

构建个人技能知识库:从Markdown管理到自动化实践
1. 项目概述:一个技能库的诞生与价值最近在整理个人知识体系时,我一直在思考一个问题:如何将那些零散的、跨领域的“技能点”系统化地管理起来,形成一个可以持续迭代、随时取用的个人工具箱?这不仅仅是写一份简历上的技…...

TEdit地图编辑器:从零开始掌握泰拉瑞亚世界创作
TEdit地图编辑器:从零开始掌握泰拉瑞亚世界创作 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you change w…...

Taotoken API密钥的精细权限管理与操作审计日志在安全运维中的作用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API密钥的精细权限管理与操作审计日志在安全运维中的作用 对于负责技术基础设施安全与合规的团队而言,引入新…...

地铁站内人员危险情况检测人员跌倒检测数据集VOC+YOLO格式4369张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):4369 标注数量(xml文件个数):4369 标注数量(txt文件个数):4369 …...

从NLP基础到LLM实战:手把手构建大模型全栈能力
1. 从NLP到LLM:为什么你需要一个坚实的“地基” 最近几年,大语言模型(LLM)的火爆程度有目共睹,ChatGPT、Claude、文心一言这些名字几乎成了日常谈资。很多开发者,尤其是刚入行的朋友,可能一上来…...

从零构建开源语音AI交互中枢:EchoKit Server部署与调优指南
1. 项目概述:构建你自己的语音AI交互中枢 如果你对智能音箱、语音助手这类设备感兴趣,但又觉得市面上的产品要么功能封闭,要么隐私堪忧,那么今天聊的这个项目——EchoKit Server,可能会让你眼前一亮。简单来说&#x…...

基于Fabric.js与Next.js的浏览器端视频编辑器开发实战
1. 从零到一:在浏览器里造一个视频编辑器几年前,当我第一次尝试在网页上做视频剪辑时,感觉就像在用瑞士军刀盖房子——工具很多,但都不趁手。市面上的在线编辑器要么功能简陋,要么就是“黑盒”操作,你根本不…...

MTKClient终极指南:解锁联发科设备的完整刷机与调试解决方案
MTKClient终极指南:解锁联发科设备的完整刷机与调试解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient 你是否曾经遇到过联发科设备变砖无法启动的困境?或者想…...

从“能用”到“可靠”:基于SonarQube与Jenkins的代码质量防线构建实战
当测试覆盖率不再只是一串数字,而是合并代码前的“一票否决权” 1. 为什么你的“质量门禁”只是个摆设? 在很多团队的CI/CD流水线中,SonarQube的集成往往停留在“能跑就行”的阶段。流水线里确实有代码扫描这一步,日志里也打印出…...