昇思25天学习打卡营第3天|数据集Dataset

一、简介:
数据是深度学习的基础,高质量的数据输入将在整个深度神经网络中起到积极作用。有一种说法是模型最终训练的结果,10%受到算法影响,剩下的90%都是由训练的数据质量决定。(doge)
MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。其中Dataset是Pipeline的起始,用于加载原始数据。MindSpore自带的mindspore.dataset方法提供了内置的文本、图像、音频等数据集加载接口,并提供了自定义数据集加载接口。此外MindSpore的领域开发库也提供了大量的预加载数据集,可以使用API一键下载使用。
下面开始我们的实践打卡吧!
二、环境准备:
在开始之前我们先导入下面数据集处理所需的相关依赖包:
import numpy as np
import time
from mindspore.dataset import vision
from mindspore.dataset import MnistDataset, GeneratorDataset
import matplotlib.pyplot as plt如果没有下载Mindspore包的宝子,可以看我的昇思25天学习打卡营第1天|快速入门-CSDN博客,按照我的过程走一遍(和pytorch的下载几乎一样)。
三、数据集准备:
1、数据集下载:
使用download方法从开源数据集上下载mnist数据集,并保存在本地的notebook/datasets/目录下
from download import downloadurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())), "VertexGeek")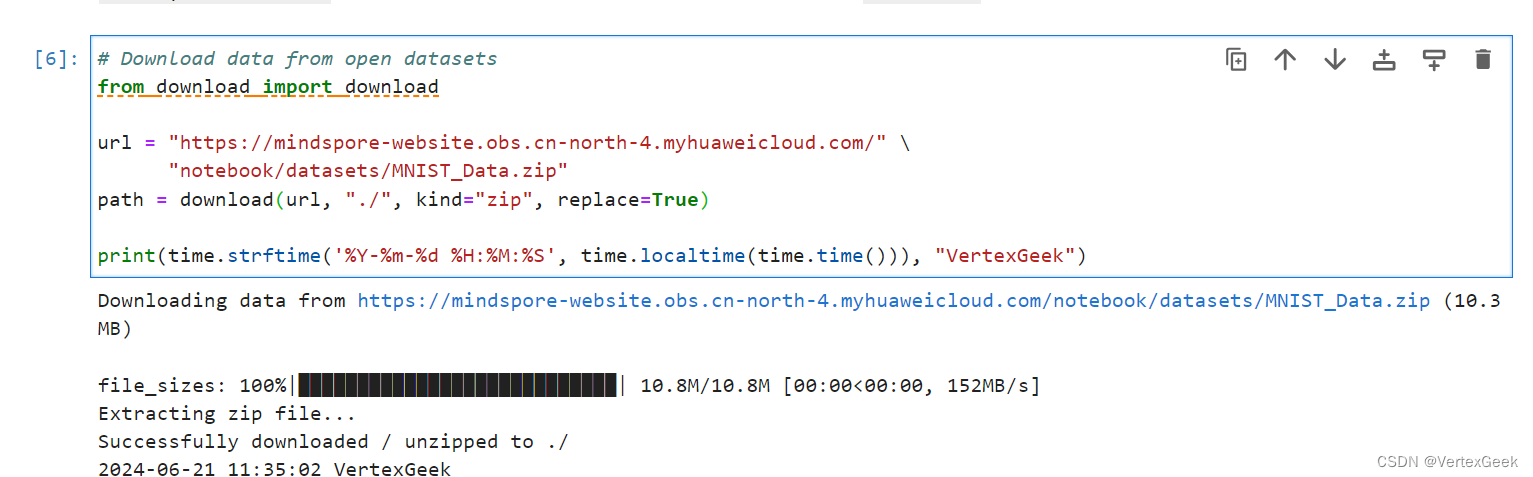
2、数据集迭代:
数据集加载后,一般以迭代方式获取数据,然后送入神经网络中进行训练。我们可以使用create_tuple_iterator(元组)和create_dict_iterator(字典)接口创建数据迭代器,迭代访问数据。访问的数据类型默认为Tensor;若设置output_numpy=Ture,访问的数据类型为Numpy。
# 使用matplotlib构建一个可视化的画布
def visualize(dataset):figure = plt.figure(figsize=(4, 4))cols, rows = 3, 3plt.subplots_adjust(wspace=0.5, hspace=0.5)for idx, (image, label) in enumerate(dataset.create_tuple_iterator()):figure.add_subplot(rows, cols, idx + 1)plt.title(int(label))plt.axis("off")plt.imshow(image.asnumpy().squeeze(), cmap="gray")if idx == cols * rows - 1:breakplt.show()visualize(train_dataset)
print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())), "VertexGeek") figure = plt.figure(figsize=(4, 4)): 这行创建了一个新的图形对象 figure,并设置了图形的大小为 4x4 英寸。
cols, rows = 3, 3 :这行设置了图形中的列数和行数为 3,这意味着函数将显示一个 3x3 的图像网格。
plt.subplots_adjust(wspace=0.5, hspace=0.5): 这行设置了子图之间的水平和垂直间距分别为0.5。
plt.axis("off"):这行关闭了子图的坐标轴,以便只显示图像。plt.imshow(image.asnumpy().squeeze(), cmap="gray"):这行将图像数据 image 显示在子图上。asnumpy() 可能是一个方法,用于将图像数据转换为 NumPy 数组,以便 Matplotlib 可以处理它。squeeze() 用于移除数组中的单一维度。cmap="gray" 指定了使用灰度颜色映射来显示图像。

3、常用操作:
对数据集进行处理,以适应深度学习模型的训练和测试要求:
(1)Shuffle:
shuffle用于打乱数据集中的元素排列,以消除数据排列造成的分布不均问题。
mindspore.dataset()提供了在加载数据集中shuffle数据的快捷方法:
train_dataset = train_dataset.shuffle(buffer_size=64)visualize(train_dataset)print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())), "VertexGeek")
(2)Map:
map是数据处理的关键操作之一,可以针对数据集指定的列(当然也可以不指定)进行数据变换,并将数据变换应用于该列数据的每个元素,并返回包含变换后元素的新数据集。
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)# 对Mnist数据集做数据缩放处理,将图像统一除以255,数据类型由uint8转为了float32
train_dataset = train_dataset.map(vision.Rescale(1.0 / 255.0, 0), input_columns='image')image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())), "VertexGeek")
(3) Batch:
这是在算力有限的情况下,将数据集进行划分成数个批次,每次只训练一个批次,以节约硬件资源和提升硬件使用效率。
train_dataset = train_dataset.batch(batch_size=32)image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())), "VertexGeek")
四、自定义数据集:
mindspore.dataset()提供了一些常用的公开数据集和标准数据集的加载API,MindSpore暂时不支持直接加载数据集,可以构造自定义数据加载类或自定义数据集生成函数的方式来生成数据集,然后通过GeneratorDataset接口实现自定义方式的数据集加载(比pytorch略显复杂)。GeneratorDataset支持通过可随机访问数据集对象、可迭代数据集对象和生成器(generator)构造自定义数据集。
1、可随机访问数据集:
可随机访问数据集是指实现了__getitem__和__len__方法的数据集,即可以通过索引/键直接访问对应位置的数据样本。
# 生成一个可随机访问数据集以便下面的实践:
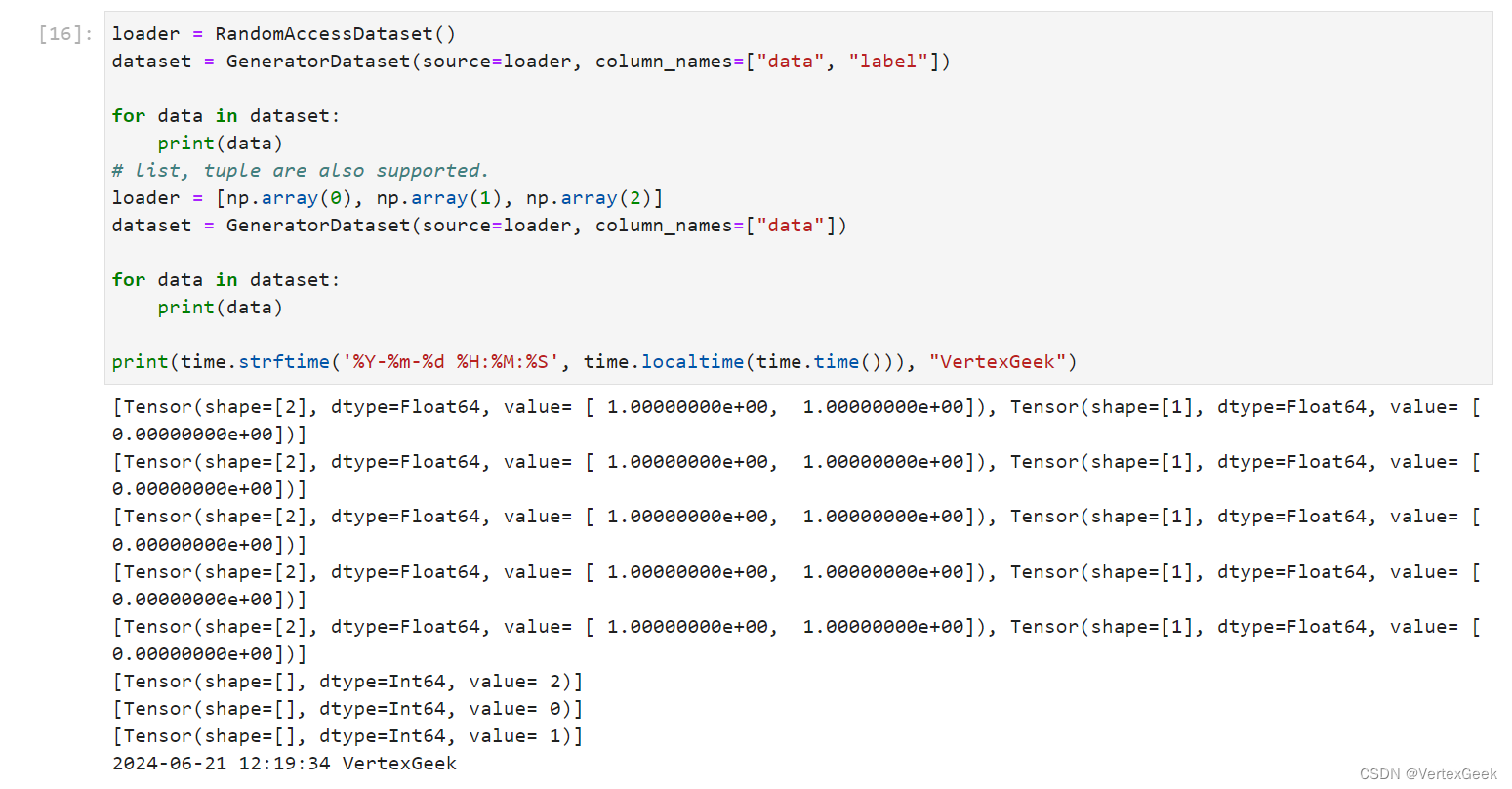
class RandomAccessDataset:def __init__(self):self._data = np.ones((5, 2))self._label = np.zeros((5, 1))def __getitem__(self, index):return self._data[index], self._label[index]def __len__(self):return len(self._data)loader = RandomAccessDataset()
dataset = GeneratorDataset(source=loader, column_names=["data", "label"])for data in dataset:print(data)
# 支持其他类型的数据
loader = [np.array(0), np.array(1), np.array(2)]
dataset = GeneratorDataset(source=loader, column_names=["data"])for data in dataset:print(data)print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())), "VertexGeek") __getitem__ 方法使得类的实例可以被索引。当对象被当作函数调用,并且传入一个索引 index 时,这个方法返回对应索引的数据和标签。在机器学习中,这通常用于获取单个数据样本及其对应的标签。
__len__方法用于返回数据的长度。
2、可迭代数据集对象:
可迭代的数据集是实现了__iter__和__next__方法的数据集,表示可以通过迭代的方式逐步获取数据样本。这种类型的数据集特别适用于随机访问成本太高或者不可行的情况。
class IterableDataset():def __init__(self, start, end):'''init the class object to hold the data'''self.start = startself.end = enddef __next__(self):'''iter one data and return'''return next(self.data)def __iter__(self):'''reset the iter'''self.data = iter(range(self.start, self.end))return self
loader = IterableDataset(1, 4)
dataset = GeneratorDataset(source=loader, column_names=["data"])for data in dataset:print(data)print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())), "VertexGeek")
3、生成器:
生成器也属于可迭代的数据集类型,其直接依赖Python的生成器类型generator返回数据,直至生成器抛出StopIteration异常。
def my_generator(start, end):for i in range(start, end):yield idataset = GeneratorDataset(source=lambda: my_generator(3, 6), column_names=["data"])for d in dataset:print(d)print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())), "VertexGeek")
相关文章:
昇思25天学习打卡营第3天|数据集Dataset
一、简介: 数据是深度学习的基础,高质量的数据输入将在整个深度神经网络中起到积极作用。有一种说法是模型最终训练的结果,10%受到算法影响,剩下的90%都是由训练的数据质量决定。(doge) MindSpore提供基于…...

SpringCloud 服务调用 spring-cloud-starter-openfeign
在Spring Cloud中,spring-cloud-starter-openfeign 是一个用于声明式Web服务客户端(例如REST客户端)的启动器。它使得在Spring Cloud应用中调用其他HTTP服务变得非常简单,只需创建一个接口并使用注解来定义服务调用的细节。 以下…...

基于Elementui组件,在vue中实现多种省市区前端静态JSON数据展示并支持与后端交互功能,提供后端名称label和id
基于Elementui组件,在vue中实现多种省市区前端静态数据(本地JSON数据)展示并支持与后端交互功能,提供后端名称label和id 话不多说,先上图 1.支持传递给后端选中省市区的id和名称,示例非常完整,…...
基于DPU的云原生裸金属网络解决方案
1. 方案背景和挑战 裸金属服务器是云上资源的重要部分,其网络需要与云上的虚拟机和容器互在同一个VPC下,并且能够像容器和虚拟机一样使用云的网络功能和能力。 传统的裸金属服务器使用开源的 OpenStack Ironic 组件,配合 OpenStack Neutron…...
)
pip install镜像源(更新和换源)
pip install镜像源(更新和换源) 1.pip安装依赖包默认访问的源: 因为服务器架设在国外的缘故,很多时候不好用网速不行,这时候就需要选择国内的一些安装源安装相应的包 https://pypi.Python.org/simple/2.设置默认源 …...

基础语法——组合与继承
继承 定义派生类,即继承的一般语法结构如下 class 派生类名 : [继承方式] 基类名 { }; 例如 class Point{int x, y; public:Point(int a0, int b0): x(a), y(b){}virtual double area() {return 0.0; };virtual double volume() { return 0.0; } }; class Circl…...

openGauss开发者大会、华为云HDC大会举行; PostgreSQL中国技术大会7月杭州开启
重要更新 1. openGauss Developer Day本周五于北京举行,大会聚集了相关行业专家、用户、伙伴和开发者,分享给予openGauss的联合创新成果和实践案例。([2] ) ;华为云 HDC 2024本周五于东莞松山湖举行,主题演讲主要覆盖鸿蒙、AI ([3…...

编译报错:No rule to make target xx/libcam.halmemory_intermediates/export_includes
问题现象: make: *** No rule to make target ‘out/target/product/testdd6737m_35g_m0/obj/STATIC_LIBRARIES/libcam.halmemory_intermediates/export_includes’, needed by ‘out/target/product/testdd6737m_35g_m0/obj/SHARED_LIBRARIES/libcam_platform_inte…...

【备考指南】CDA Level Ⅰ 最全备考攻略
很多考生朋友在报名前后,一直不知道需要怎么备考,这里给大家盘点一下最全的备考攻略,希望对你有用: 1、需要准备好之后再报名吗? 不需要,CDA认证考试是报名后自行预约考试的,您可以先报名同时…...
【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 5G基站光纤连接问题(200分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 …...
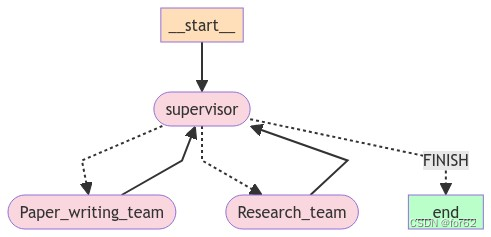
分层Agent
分层Teams 分层Agent创建tool研究团队工具文档编写团队工具 通用能力定义Agent团队研究团队文档编写团队 添加图层 分层Agent 在前面的示例(Agent管理)中,我们引入了单个管理节点的概念,用于在不同工作节点之间路由工作。 但是&a…...

OS复习笔记ch11-1
外围设备的管理和磁盘调度 外围设备 从CPU的角度来看,外设有几个比较重要的I/O接口(interfaces) 状态reg:向CPU报告设备的状态(忙碌/空闲)命令reg:接收CPU命令,存储 CPU 需要执行的…...

Docker Compose 使用
一、简介 Docker Compose 是一个工具,用于定义和运行多容器 Docker 应用程序。它允许用户使用 YAML 文件来配置应用程序需要的所有服务,然后使用一个命令来从 YAML 文件配置中创建并启动所有服务。其主要目的是为了简化了多容器 Docker 应用程序的部署和…...

KEIL5.39 5.40 fromelf 不能生成HEX bug
使用AC6 编译,只要勾选了生成HEX。 结果报如下错误 暂时没有好的解决办法 1.替换法 2.在编译完后用命令生成HEX...

mongosh 和mongo 命令行连接MongoDB
Mongoshell MongoDB的Shell工具mongosh是一个全功能的JavaScript和Node.js的14.x REPL与MongoDB的部署交互环境。我们通过它可以直接对数据库进行查询和操作。这个工具是需要在安装玩MongoDB后单独安装的。 与传统的mongo方式连接MongoDB更加丰富。 官网 https://www.mongodb.…...

DOM 改变节点
DOM 改变节点 文档对象模型(DOM)是 HTML 和 XML 文档的编程接口。它提供了对文档的结构化表示,并定义了一种方式,允许程序和脚本动态地访问和更新文档的内容、结构和样式。在网页开发中,DOM 操作是核心技能之一&#…...

【面试题分享】重现 string.h 库常用的函数
文章目录 【面试题分享】重现 string.h 库常用的函数一、字符串复制1. strcpy(复制字符串直到遇到 null 终止符)2. strncpy(复制固定长度的字符串) 二、字符串连接1. strcat(将一个字符串连接到另一个字符串的末尾&…...
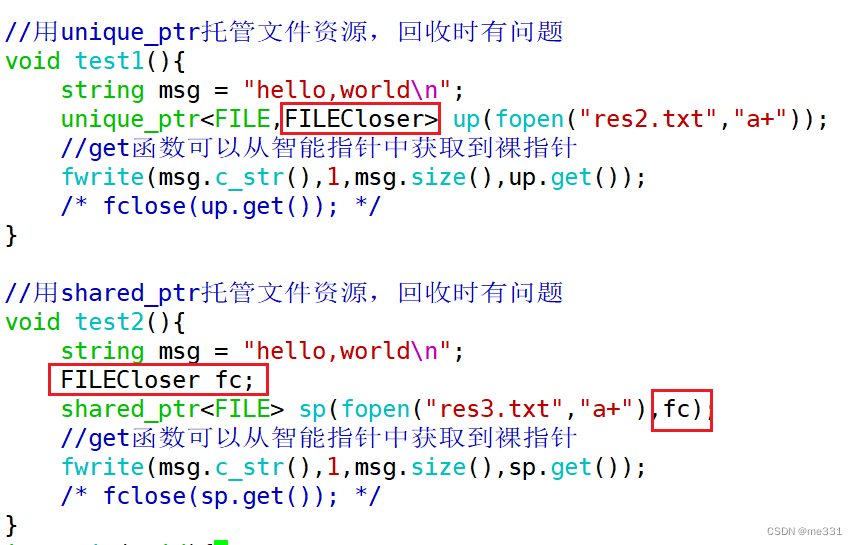
6.21 移动语义与智能指针
//先构造,再拷贝构造//利用"hello"这个字符串创建了一个临时对象//并复制给了s3//这一步实际上new了两次String s3 "hello"; 背景需求: 这个隐式创建的字符串出了该行就直接销毁掉,效率比较低 可以让_pstr指向这个空间…...

Kimi还能对学术论文进行润色?我来教你!
学境思源,一键生成论文初稿: AcademicIdeas - 学境思源AI论文写作 一、引言 在学术界,论文的质量往往决定了研究的可信度和影响力。Kimi作为一款人工智能助手,可以为学术论文的润色提供有效的帮助。本文将详细介绍如何利用Kimi进…...

智汇云舟成为中煤集团中煤智能创新联盟成员单位
6月21日,第八届世界智能产业博览会平行会议暨中煤智能创新联盟交流会在天津水游城丽筠酒店顺利举行。智汇云舟受邀参与,并由中国中煤能源集团授予荣誉证书,正式成为中煤智能创新联盟成员单位。会议上,清华大学、中国矿业大学&…...

Hackintool:黑苹果配置不再复杂,这款工具让你轻松搞定所有难题
Hackintool:黑苹果配置不再复杂,这款工具让你轻松搞定所有难题 【免费下载链接】Hackintool The Swiss army knife of vanilla Hackintoshing 项目地址: https://gitcode.com/gh_mirrors/ha/Hackintool 还在为黑苹果的配置问题头疼吗?…...

从碎片化到知识体系:微信读书笔记助手如何重塑你的数字阅读体验
从碎片化到知识体系:微信读书笔记助手如何重塑你的数字阅读体验 【免费下载链接】wereader 一个浏览器扩展:主要用于微信读书做笔记,对常使用 Markdown 做笔记的读者比较有帮助。 项目地址: https://gitcode.com/gh_mirrors/wer/wereader …...

大模型推理引擎概述
“推理引擎”(Inference Engine)是人工智能系统中专门负责运行(执行)已训练好的模型,对新输入数据进行预测或生成结果的软件组件。 你可以把它理解为: “模型的发动机”——训练好的模型是“设计图纸”&am…...

DLSS Swapper终极指南:一键切换游戏超采样版本,免费提升帧率30%+
DLSS Swapper终极指南:一键切换游戏超采样版本,免费提升帧率30% 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否曾羡慕别人在《赛博朋克2077》里享受丝滑流畅的画面,而你的游戏…...

Netgear路由器急救指南:nmrpflash如何让变砖设备重获新生
Netgear路由器急救指南:nmrpflash如何让变砖设备重获新生 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你心爱的Netgear路由器因为固件升级失败、意外断电或其他原因变成一块"砖头&q…...

Nix构建确定性AI编程环境:解决Cursor编辑器依赖冲突难题
1. 项目概述:当代码编辑器遇上Nix的确定性魔法 最近在折腾开发环境时,我遇到了一个老生常谈但又无比头疼的问题:团队里新来的同事怎么也跑不起来我本地运行得好好的一个代码辅助工具链。依赖版本冲突、系统库路径不对、甚至是因为他用的macO…...

如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南
如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾在寻找百度网盘资源时,被一个小小的提取码卡住,不得不花费…...
.name()到可读类型名)
C++运行时类型识别实战:从typeid().name()到可读类型名
1. 为什么我们需要关心运行时类型识别? 在C开发中,我们经常会遇到需要知道某个变量或表达式具体类型的情况。特别是在调试复杂代码、编写泛型程序或进行元编程时,能够准确获取类型信息就显得尤为重要。想象一下,当你看到一个日志输…...

Apache Burr框架:构建可观测有状态数据应用的核心原理与实践
1. 项目概述:一个用于构建和评估数据产品的Python框架如果你正在处理数据密集型应用,比如推荐系统、个性化广告或者任何需要根据用户行为实时调整策略的场景,你肯定遇到过这样的困境:模型训练和离线评估做得再好,一旦上…...

手把手带你激活Matlab2016b:Windows 64位系统下的完整许可配置指南
1. 准备工作:确保激活环境完整 在开始激活Matlab2016b之前,我们需要做好充分的准备工作。首先确认你已经按照官方流程完成了基础安装,并且安装目录下存在完整的文件结构。我遇到过不少朋友因为安装不完整导致后续激活失败的情况,所…...