海量数据处理——bitMap/BloomFilter、hash + 统计 + 堆/归并/快排
前言:海量数据处理是面试中一道常考的问题, 生活中也容易遇到这种问题。 通常就是有一个大文件, 让我们对这个文件进行一系列操作——找出现次数最多的数据、求交集、是否重复出现等等。 因为文件的内容太多, 我们的内存通常是放不下的。这个时候, 我们就要用到一些别的处理手段, 也就是我们的标题——位图, 布隆过滤器以及哈希切分。
本篇内容分为两个板块——第一个板块实现位图以及布隆过滤器; 第二个板块是大概模拟处理几道海量数据相关题。
ps:本篇的主要内容就是海量数据如何进行处理,但是需要使用位图和布隆过滤器的内容。 如果没有学过位图和布隆过滤器的友友们, 自行划到文章后面有位图和布隆过滤器的模拟实现。 已经学过的友友们就可以忽略后半部分的位图和布隆的部分, 只观看前半部分的海量数据处理部分。
海量数据处理
一、已知有100亿个int数据, 现在只有1G内存, 如何在这100个int数据里面找出出现次数为2的那些数据。
解:
整形先考虑位图:100亿个int, 但是这里面隐含了一个条件, 就是整形最多只有四十二亿九千万个。 就是160亿字节。 而10亿个字节为1G。 显然, 如果将所有整形放到内存中是放不下的。 但是我们不需要储存, 只需要查找哪个数据出现次数为2, 那么就可以利用位图和布隆过滤器优化空间。 而且数据类型是int, 那么就可以使用位图——一个整形映射一个比特位。
那么, 我们就要思考, 四十亿个整形可以映射5亿个字节, 也就是500MB。同时, 我们也要思考,位图只能标记出现过或者没有出现过, 但是不能标记出现过几次。 所以要使用两个位图——位图1, 位图2。 我们都知道位图的一个比特位置为1,代表数据出现过; 一个比特位置为0, 代表数据没有出现过。
那么如果有两个位图,我们就可以让这两个比特位合起来使用。 如果位图1的对应比特位为0, 位图2的对应比特位置为1,也就是01, 代表出现一次;如果位图1的对应比特位是1, 位图2的对应比特位是0, 那么就是10, 代表出现过2次。所以两个位图一共可以统计次数最多为3.
而使用两个位图所用空间最多为1G, 空间足够。 所以可是使用两个位图的策略。 具体实现如下:
template<size_t N>class bit_dou {public:void set(size_t x) {if (_bit1.test(x) == false && _bit2.test(x) == false) {_bit1.set(x);}else if (_bit1.test(x) == true && _bit2.test(x) == false) {_bit1.reset(x);_bit2.set(x);}else if (_bit1.test(x) == false && _bit2.test(x) == true) {_bit1.set(x);}}bool test(size_t x) {if (_bit2.test(x) == true) {return true;}else {return false;}}private:bitset<N> _bit1;bitset<N> _bit2;};
二、给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法。
精确策略:这里使用的是hash映射 + 统计(使用哈希map或者map) + (堆/归并/快排)
具体步骤:
假设一个query50字节, 那么100亿个query就是5000亿字节,而10亿字节是1g, 那么5000亿字节就是500G, 所以1G内存不能将这些字符串全部存下来。
这里我们使用的策略是hash + 统计(使用hashmap或者treemap) + 堆排/归并/快排,先使用hash映射将100亿个query划分到500个小文件中, 着500个小文件分别命名为A1、A2、A3……A500——这样能保证平均1个小文件里面有1G内存。
然后将另一个文件也平均分成500个小文件, 这500个小文件命名为B1、B2、B3……B500——其实两个文件可以分的再多一些, 那样就能减少一个小文件映射的query太多的概率, 导致读取文件时内存空间不足。
使用hash映射到500个小文件中, 这时候我们可以确定, 相同的query一定会被映射到同一个文件中。 并且两个大文件中如果有相同的query,那么这个query在两个大文件形成的小文件中的下标一定是相同的。 比如一个q0在第一个大文件哈希映射的文件是A122, 那么他在另一个大文件中哈希映射的文件一定是B122。
那么我们就可以利用这种性质来判断这两组小文件的交集——即A1 和B1寻找交集,寻找出来后将交集放到一个文件中(最好不要放到内存, 因为如果交集很多, 可能导致内存不够。)A2和B2寻找交集后将交集放到一个文件中……A500和B500寻找交集放到一个文件中。
要注意的是应该考虑如果划分小文件的时候, 出现单个小文件个数太大。 那么也要分情况讨论:第一种情况就是单个小文件太大,但是其中重复的元素很少, 这个时候需要将元素全部映射到map之中空间不够用, 那么就要重新使用新的哈希函数, 重新映射。另一种情况就是虽然单个小文件很大, 但是其中重复的元素很多, 可以将全部元素映射到map之中。那么就正常读取小文件即可。
上面这种做法叫做哈希切分, 就是利用分治思想: 哈希映射 + hashmap/treemap (+ 堆/归并/快排)。
近似策略:使用布隆过滤器。
近似策略就是使用布隆过滤器, 先将一个大文件中的query映射到布隆过滤器当中, 然后再将另一个大文件的数据一个一个读取, 查找是否在当前布隆过滤器之中已经出现过。 如果出现过, 就保存下来。
最后保存下来的数据, 就是两个文件的交集。
三、给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
这个问题和第一个问题类似,都是使用位图。 100亿个整形其实里面最多只有42亿个不同的整形, 而四十二亿个整形使用位图映射后最多只需要使用400MB, 那么我们就可以使用位图先将一个大文件的数据映射进来, 然后再对另一个文件里面的数据一个一个读取, 查看是否在当前位图映射过。如果映射过, 那么就是交集。
四、给定100亿个整数,设计算法找到只出现一次的整数?
很明显就是使用位图的一个题, 同样的使用两个位图, 建立一个能够统计次数, 最高次数是3的位图(可以叫dou_bitMap)。 那么再统计这100亿个整形, 就能统计他们的出现次数。 最后再从0开始遍历四十二亿的整数, 判断这四十二亿个整数之中哪个出现过1次。
五、给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址? 与上题条件相同,如何找到top K的IP?
log file明显不是整形, 那么这道题hash + 统计(hashmap/treemap) + 堆/归并/快排。
首先将100G的大文件利用hash函数切分成100个小文件。 再利用hashmap或者treemap将每个小文件中的出现最多的那个数据保存到一个文件中。 然后遍历这个文件就能找到出现次数最多的那个ip地址。
然后如何求topk的ip就要从遍历小文件的时候进行。 将每个小文件中的所有数据读到hashmap中统计其中数据出现的个数。 再利用排序将这些数据的出现个数从高到底排。 取出其中前k个ip放到一个文件之中。 所有的小文件都是上面这个操作。 最后使用一个含有k个数据的小堆。 依次遍历整个文件, 只要遇到比堆顶的数据大的, 就将数据放进堆里面。 然后弹出推顶数据, 维护堆的固定个数。最后堆中剩余的ip就是最大的k个ip。而堆顶就是topk的ip。
ps:这里总结的方法其实只有:bloomFilter/bitMap 以及 hash + 统计 + 堆/归并/快排; 另外还有几种处理海量数据的方法——外排序、多层划分、倒排索引等等。 这些博主知识储备不足, 在这里不好讲解, 有兴趣的友友可以按照自己的兴趣以及能力自行学习。
位图
学习位图之前首先要知道的一点就是位图, 布隆过滤器都是利用了哈希的思想。解决的是内存不够的问题。 就是说, 它们可以处理的数据更多。 更能节省空间。 但是也并不是只有优点,位图存在只能处理整形数据的问题。 而布隆过滤器存在不准确的问题。接下来实现位图:
一般的哈希表像哈希桶, 闭散列。 都是利用一块空间来映射数据,同时需要开空间储存数据。如图位哈希桶图:
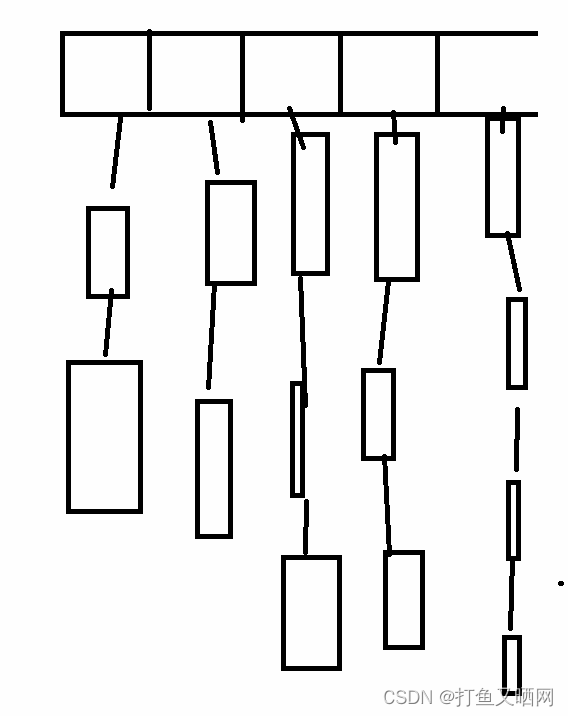
但是位图是利用一个比特位来映射数据,只用来映射, 不进行存储。如果改位置映射过, 就置为1(下图中的红代表1), 没映射过就是0(下图无色, 即默认值)。
//类的定义(要用模板size_t, 因为要指定位图的大小, 参数是几, 说明至少有多少数据, 就要保证最少开几个比特位空间。)
template<size_t n> //模板使用来规定创建的位图大小。 n是几, 就保证最少有几个比特位。class bitset {};//使用整形数组来模拟一块连续的空间
template<size_t n>class bitset {bitset() {//这里要保证开的空间足够, 但是n / 32会消除小数点,开的空间要小于等于需求。 所以要多开一个整形空间。_bits.resize(n / 32 + 1); }private:vector<int> _bits; //使用整型数组来模拟一块连续的空间。};//进行映射时, 如何定位第几个比特位
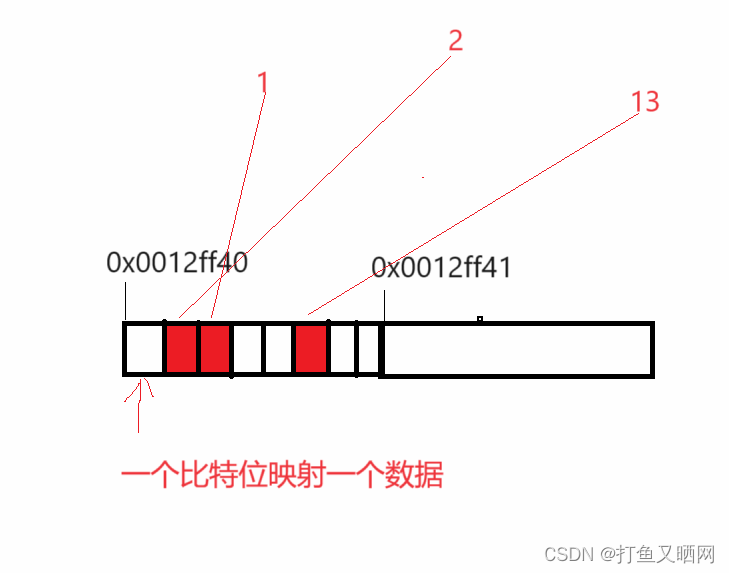
一个整形时4个字节, 32个比特位, 假设当前数据位x。 那么x / 32就是当前需要映射的第几个整形。而x % 32就是当前要映射的这个整形的第几个比特位。
当进行定位比特位时, 我们就可以这样写:
int i = x / 32; //要映射的第几个整形int j = x % 32; //要映射的第几个整形的第几个比特位。
//将当前比特位标记为1, 如何不修改其他比特位, 只将当前比特位置为1.
标记比特位要使用按位操作。 而按位操作分为按位与‘&’, 按位或'|', 按位异或'^'。 其中‘&’的规则是:有0就是0, 全1才是1; '|'的规则是:有1就是1, 全0才是0; '^'的规则是:相同为0, 相异为1。
这里可以使用'|‘操作, 先将1向高位移动 j 个位置。再让第 i 个整形按位或上1移动后的数。 就是想要的结果, 如图:
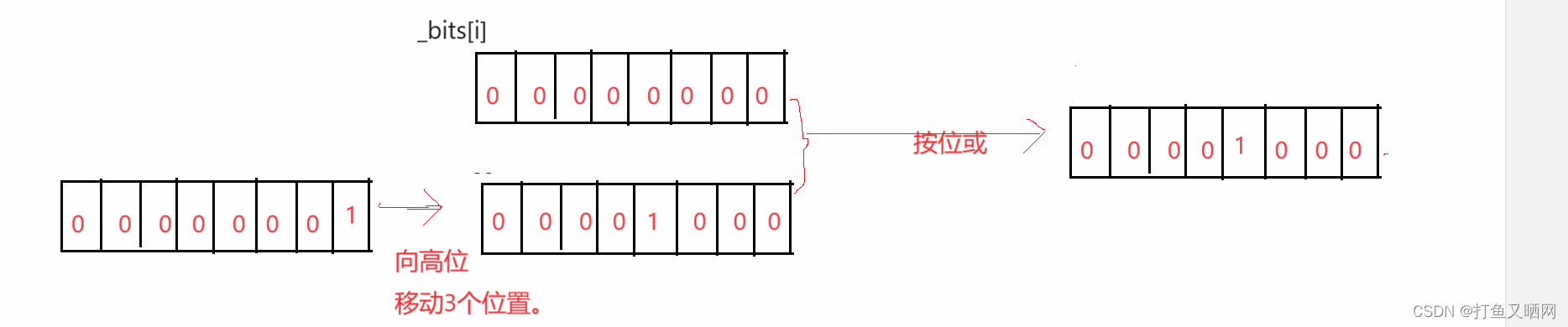
转化为代码就是如下, 这也是第一个接口(位图有三个接口, set, reset, test。该接口是set).
template<size_t n>class bitset {public:bitset() {//这里要保证开的空间足够, 但是n / 32会消除小数点,开的空间要小于等于需求。 所以要多开一个整形空间。_bits.resize(n / 32 + 1); }void set(int x) {int i = x / 32; //要映射的第几个整形int j = x % 32; //要映射的第几个整形的第几个比特位。_bits[i] |= (1 << j); //按位或:有1就是1, 全0才是0.}private:vector<int> _bits; //使用整型数组来模拟一块连续的空间。};//消除某一个比特位的映射(reset接口)
消除某一个位置的映射需要只将某一个比特位置为0, 其他的位置不变。如果是或操作, 就要让其他位置都是0, 但是并不能消除特定位置的1. 所以就要使用与操作, 让其他位置都是1, 特定位置都是0. 就能让特定位置由1变成0. 而其他位置与上1还是它本身, 代码如下:
template<size_t n>class bitset {public:bitset() {//这里要保证开的空间足够, 但是n / 32会消除小数点,开的空间要小于等于需求。 所以要多开一个整形空间。_bits.resize(n / 32 + 1); }void set(int x) {int i = x / 32; //要映射的第几个整形int j = x % 32; //要映射的第几个整形的第几个比特位。_bits[i] |= (1 << j); //按位或:有1就是1, 全0才是0.}void reset(int x) {int i = x / 32;int j = x % 32;_bits[i] &= ~(1 << j);}private:vector<int> _bits; //使用整型数组来模拟一块连续的空间。};//测试某一个数据有没有被映射过, 其实就是看某一个比特位有没有被映射过(test)
测试某一个位置有没有被映射过, 只需要让该位置与上1, 其他位置遇上0即可。 当其他位置与上0, 那么都变成0, 特定位置与上1, 如果这个位置原本是1, 那么结果就是1。 非0就是真, 如果该位置原本是0, 与上0之后也是零, 其他位置也是零。 所以结果就是0, 0为假。 代码如下:
template<size_t n>class bitset {public:bitset() {//这里要保证开的空间足够, 但是n / 32会消除小数点,开的空间要小于等于需求。 所以要多开一个整形空间。_bits.resize((n / 32) + 1, 0); }void set(int x) {int i = x / 32; //要映射的第几个整形int j = x % 32; //要映射的第几个整形的第几个比特位。_bits[i] |= (1 << j); //按位或:有1就是1, 全0才是0.}void reset(int x) {int i = x / 32;int j = x % 32;_bits[i] &= ~(1 << j);}bool test(int x) {int i = x / 32;int j = x % 32;return _bits[i] &= (1 << j);}private:vector<int> _bits; //使用整型数组来模拟一块连续的空间。};布隆过滤器
位图只能用来处理整形, 而布隆过滤器可以用来处理字符串。 弥补了位图只能用来处理整形的缺点。 但是因为字符串的个数太多,(首先长度不确定, ascii码中的字符就有128个。 如果是10位长, 就是128^10) 如果一个字符串可以利用哈希函数转化为一个整形,而字符串的个数远远超过了整形的个数(整型只有四十二亿九千万个)。那么根据鸽巢原理, 就一定会有两个不同的字符串被转化成了相同的整数。 这个时候结果就不准了, 所以布隆过滤器就使用了多个哈希函数, 将一个字符串来映射多个位置。 如图:
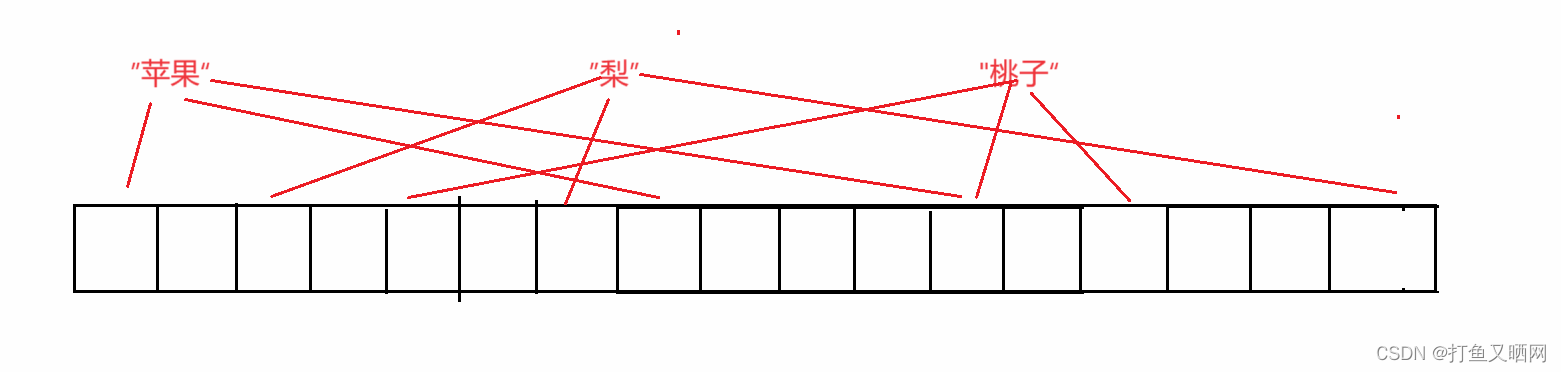
图中有三个字符串——苹果、梨、桃子。 同时每个字符串都有三个映射的位置, 并且苹果和桃子有一个哈希映射的位置相同。 如果这个时候再来一个西瓜, 我们要查找一下西瓜存在不存在。
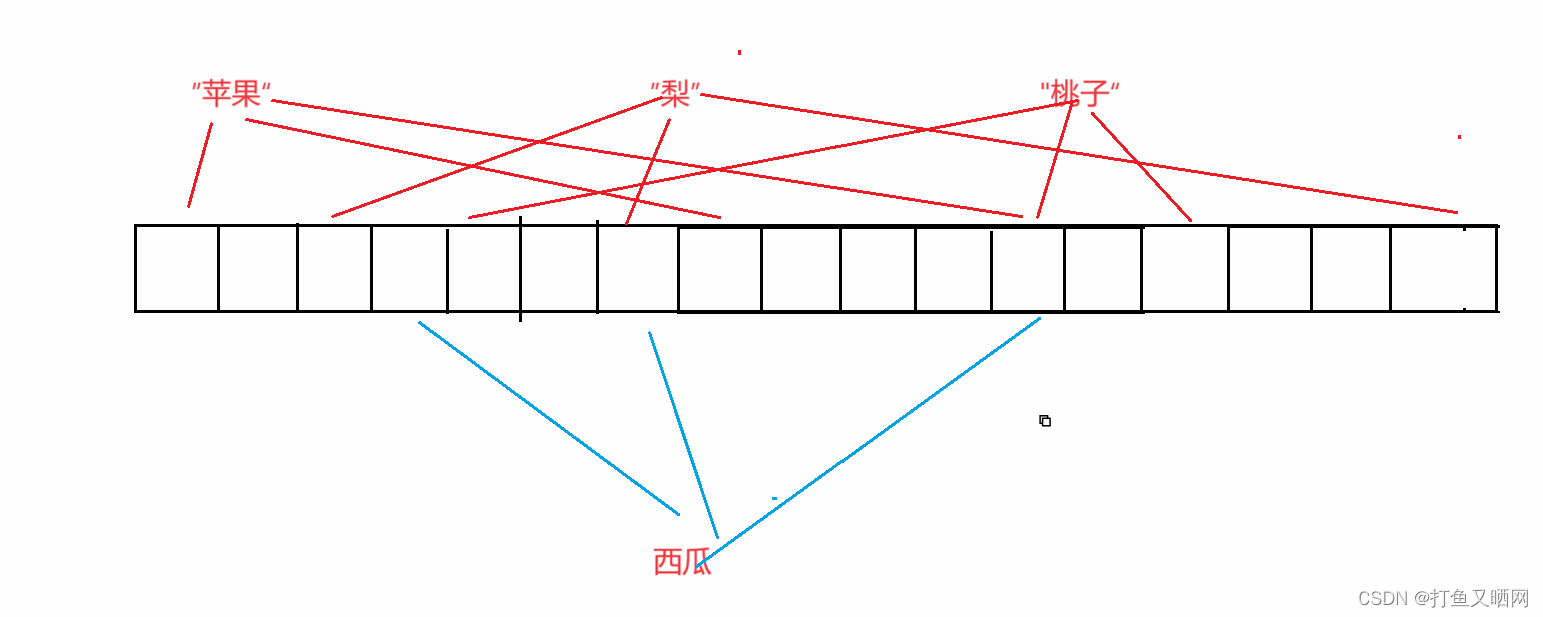 如图, 虽然西瓜有两个哈希函数映射的位置都被标记过了, 但是最左边那个映射的位置没有被标记过, 那么这样就可以看作西瓜没有出现过。 因为如果西瓜出现过。 这三个位置应该都被映射过, 但是现在这三个位置中有一个没有被映射过。 所以说明其他两个位置应该是和其他字符串发生了哈希冲突导致的, 西瓜就没有被映射过——现在, 这种没有被映射过的情况是一定的, 只要判断出一个字符串没有被映射过, 那么结果就是准确的。即:布隆过滤器的没有出现过是准确的。
如图, 虽然西瓜有两个哈希函数映射的位置都被标记过了, 但是最左边那个映射的位置没有被标记过, 那么这样就可以看作西瓜没有出现过。 因为如果西瓜出现过。 这三个位置应该都被映射过, 但是现在这三个位置中有一个没有被映射过。 所以说明其他两个位置应该是和其他字符串发生了哈希冲突导致的, 西瓜就没有被映射过——现在, 这种没有被映射过的情况是一定的, 只要判断出一个字符串没有被映射过, 那么结果就是准确的。即:布隆过滤器的没有出现过是准确的。
那么, 如果西瓜的映射位置不是上面那样了, 变成下图:
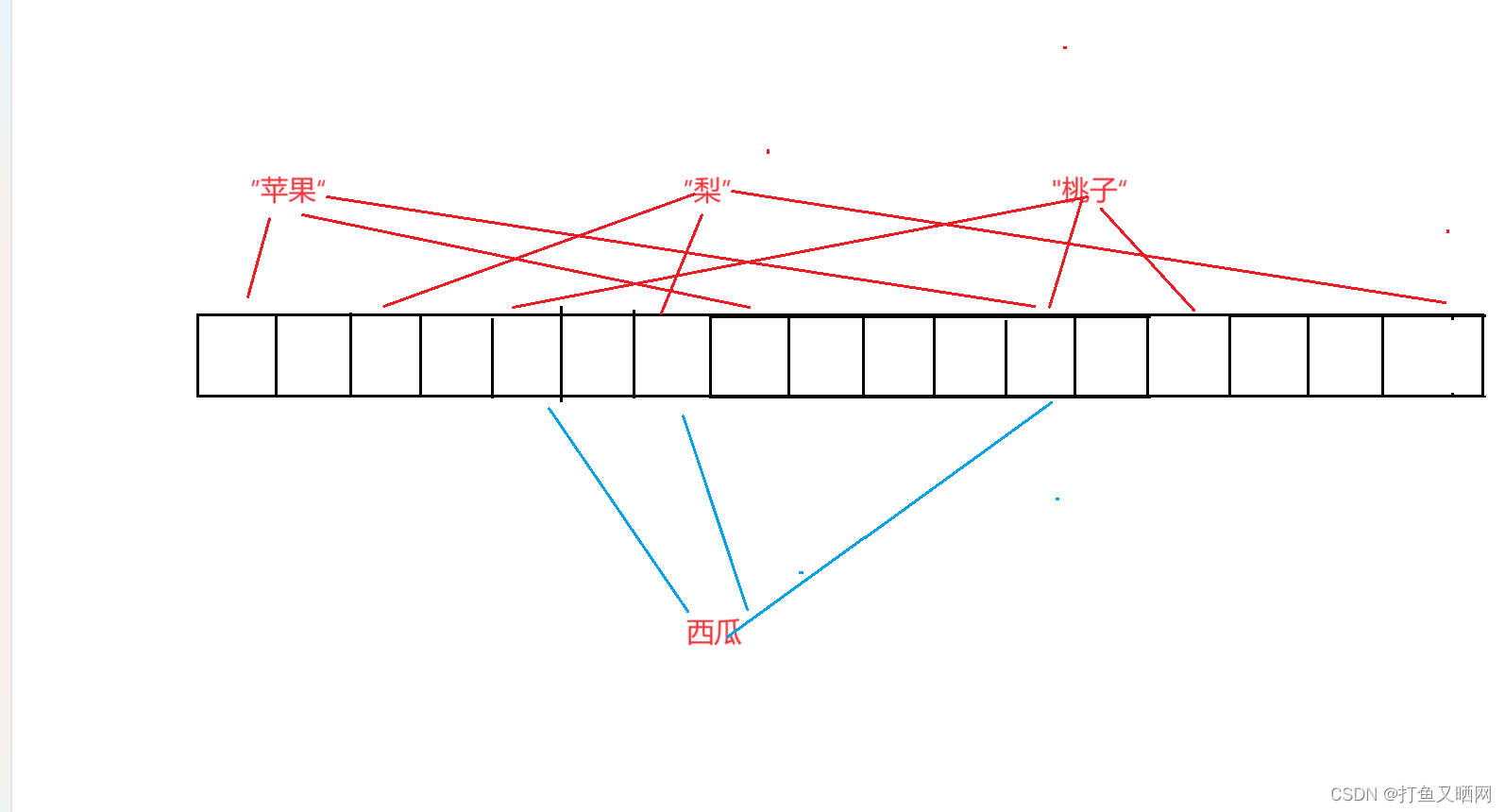
现在, 这三个位置都发生了哈希冲突, 返回的结果告诉我们西瓜出现过。 但是其实习惯并没有出现过, 这就说明如果判断一个字符串, 结果是出现过。 那么结果就是不准确的——现在, 这种被映射过的情况是不准确的。 即:布隆过滤器的出现过是不准确的。
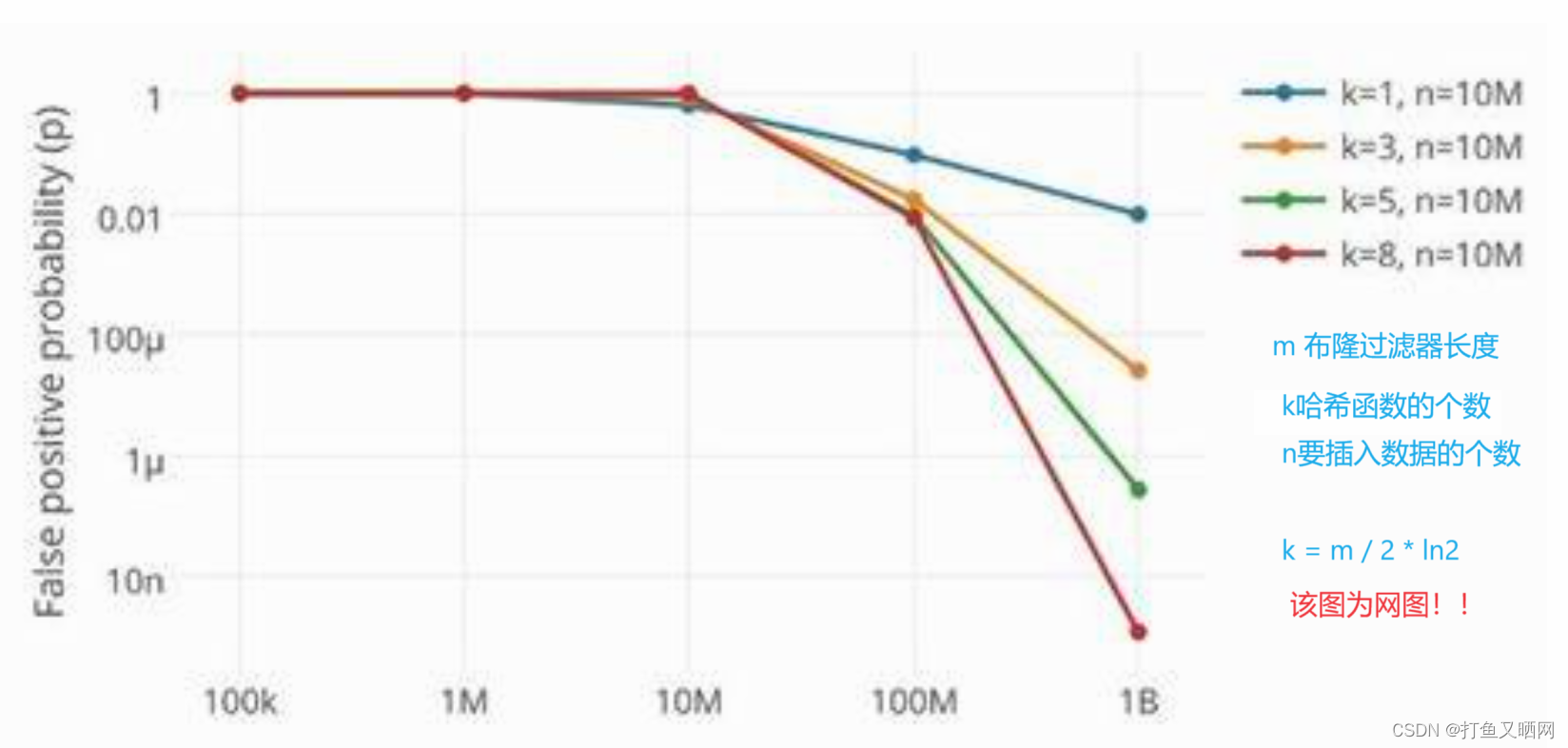
要提升布隆过滤器判断出现过的准确性, 就要增加哈希函数。 从图中我们可以看出来, 如果一个字符串映射的位置越多,那么就越难发生所有位置都冲突的情况。 但是, 另一个需要注意的是, 如果我们的字符串映射的位置太多了, 可能导致空间内大部分空间都被映射过。 那么哈希冲突的概率也会提升, 所以还是不行, 那么就要增加空间。 这就导致了一个问题——如果要提高布隆过滤器判断出现过的准确性, 就要增加哈希函数。 而增加哈希函数, 就要消耗更多的空间。
下面是布隆过滤器的准确性和哈希函数的个数的关系图:
布隆过滤器可以用来处理字符串, 以及其他类型。 只要使用相应的哈希函数即可。 这里使用三个哈希函数来封装布隆过滤器——三个哈希函数分别是:BKDR哈希, DJB哈希, AP哈希
//模版参数有五个, 一个要处理的数据个数, 一个要处理的数据类型, 三个哈希函数。 如图:
template<size_t n, class type = string, class HF1 = BKDRHash<type>, class HF2 = DJBHash<type>, class HF3 = APHash<type>>class BloomFilter {};//三个哈希函数(都可以在网上找到, 这里贴上方便友友使用)
三个哈希函数, 都要有一个关于字符串类型的特化形式。 因为我们使用布隆过滤器使用的最多的就是字符串类类型。 要实现字符串类型的特化就是使用模板的特化机制。如下代码:
//一般先创建一个模板类
template<class t>
class _class
{};
//然后在该模板类后面再跟一模板类,但是这个类里面没有参数, 类名后面跟参数。
template<>//没参数
class _class<string>//类名后跟string
{};
BKDR函数的定义是这样的
//第一个带参数的自行进行修改template<class type>struct BKDRHash{int operator()(const type& key) {return key;}};//字符串处理的特化template<>struct BKDRHash<string>{int operator()(const string& str) {int hash = 0;for (auto& e : str) {hash *= 31;hash += e;}return hash;}};DJB哈希的定义如下:
// //第一个带参数的自行进行修改template<class type>struct DJBHash {int operator()(const type& key) {return key;}};template<>struct DJBHash<string> {int operator()(const string& str){int hash = 0;for (auto& e : str) {hash += (hash << 5) + e;}hash = hash & ~(hash << 31);return hash;}};
APHash
template<class type>struct APHash {int operator()(const type& x) {return x;}};template<>struct APHash<string> {int operator()(const string& str) {int hash = 0;for (int i = 0; i < str.size(); i++) {if (i & 1 == 0){hash ^= ((hash << 7) ^ str[i] ^ (hash >> 3));}else{hash ^= ((hash << 11) ^ str[i] ^ (hash >> 5));}}return hash;}};
//布隆过滤器也是一个比特位,一个比特位进行映射。所以底层可以使用位图, 如下:
template<size_t n, class type = string, class HF1 = BKDRHash<type>, class HF2 = DJBHash<type>, class HF3 = APHash<type>>class BloomFilter {public://不需要构造函数private:bitset<n> _bits;};//布隆过滤器的接口——set(建立映射关系)、test(查看该数据是否存在, 存在不准确, 不存在准确)
template<size_t n, class type = string, class HF1 = BKDRHash<type>, class HF2 = DJBHash<type>, class HF3 = APHash<type>>class BloomFilter{public://不需要构造函数, 自动调用位图的构造函数//set就是利用三个哈希函数, 分别在位图上面映射一次。void set(type x){int hash1 = HF1()(x);int hash2 = HF2()(x);int hash3 = HF3()(x);_bits.set(hash1);_bits.set(hash2);_bits.set(hash3);}bool test(type x) {int hash1 = HF1()(x);int hash2 = HF2()(x);int hash3 = HF3()(x);//只有当三个位置都是映射过的, 这个数据才可能被映射过。但只要有一个没有映射过, 那么这个数据就一定没有映射过 if (_bits.test(hash1) && _bits.test(hash2) && _bits.test(hash3)) return true;return false;}private:bitset<n> _bits;};以上, 就是海量数据处理方面相关的知识点。
相关文章:
海量数据处理——bitMap/BloomFilter、hash + 统计 + 堆/归并/快排
前言:海量数据处理是面试中一道常考的问题, 生活中也容易遇到这种问题。 通常就是有一个大文件, 让我们对这个文件进行一系列操作——找出现次数最多的数据、求交集、是否重复出现等等。 因为文件的内容太多, 我们的内存通常是放不…...
)
TrainingArguments、ModelArguments、DataArguments参数使用(@dataclass)
文章目录 前言一、@dataclass装饰器说明二、transformers.HfArgumentParser参数使用Demo三、field函数四、llava模型参数1、模型参数设置2、数据参数设置3、训练参数设置4、参数解析5、参数传递6、参数添加前言 理解llava相关参数传递方法,有利于我们对模型修改模块使用参数来…...
基于jeecgboot-vue3的Flowable流程-自定义业务表单处理(一)支持同一个业务多个关联流程的选择支持
因为这个项目license问题无法开源,更多技术支持与服务请加入我的知识星球。 这部分先讲讲支持自定义业务表单一个业务服务表单多个流程的支持处理 1、后端mapper部分 如下,修改selectSysCustomFormByServiceName为list对象,以便支持多个 &…...
解决数据丢失问题的MacOS 数据恢复方法
每个人都经历过 Mac 硬盘或 USB 驱动器、数码相机、SD/存储卡等数据丢失的情况。我们中的一些人可能认为已删除或格式化的数据将永远丢失,因此就此作罢。对于 macOS 用户来说,当文件被删除时,垃圾箱已被清空,他们可能不知道如何恢…...

[ARM-2D 专题]3. ##运算符
C语言的宏系统相当强大,它允许使用##符号来处理预处理期的文本替换。这种用法被称为标记连接(token pasting)操作,其结果是将两个标记紧紧地连接在一起,而省略掉它们之间的所有空格。在复杂的宏定义中,运用…...
基于语音识别的智能电子病历(五)电子病历编辑器
前言 首先我们要明确一个概念:很多电子病历的编辑器,在输入文字的地方,有个麦克风按钮,点击一下,可以进行录音,然后识别的文字会自动输入到电子病历中,这种方式其实不能称为“基于语音识别的智…...
云计算技术高速发展,优势凸显
云计算是一种分布式计算技术,其特点是通过网络“云”将巨大的数据计算处理程序分解成无数个小程序,并通过多部服务器组成的系统进行处理和分析这些小程序,最后将结果返回给用户。它融合了分布式计算、效用计算、负载均衡、并行计算、网络存储…...
文本三剑客其二
文本三剑客其二 sed和awk grep就是查找文本当中的内容,扩展正则表达式。 sed 对文本内容进行增删改查 sed是一种流编辑器,一次处理一行内容。 如果只是展示,会放在缓冲区(模式空间),展示结束之后&…...

【达梦数据库】typeorm+node.js+达梦数据库返回自增列值
1.配置环境,下载依赖包 typeorm init --name test22 --database mysql typeorm-dm,uuid,typeorm2,修改连接信息 修改src/ data-source.ts 文件 连接dm,可参考刚刚安装typeorm-dm 模块中的 README.md 3.修改自增信息 /* 修改前*/PrimaryGen…...

【ARMv8/ARMv9 硬件加速系列 2.1 -- ARM NEON 向量寄存器单个元素赋值】
文章目录 NEON 向量寄存器单个元素赋值对 v0.4s中的一个元素赋值对 v1.16b 中的一个元素赋值MOVI (Move Immediate)NEON 向量寄存器单个元素赋值 在ARMv8架构中,你可以使用特定的指令来对v0.4s和v1.16b中的单个元素赋值。这通常通过使用MOV(Move)指令的变种实现,具体取决于…...
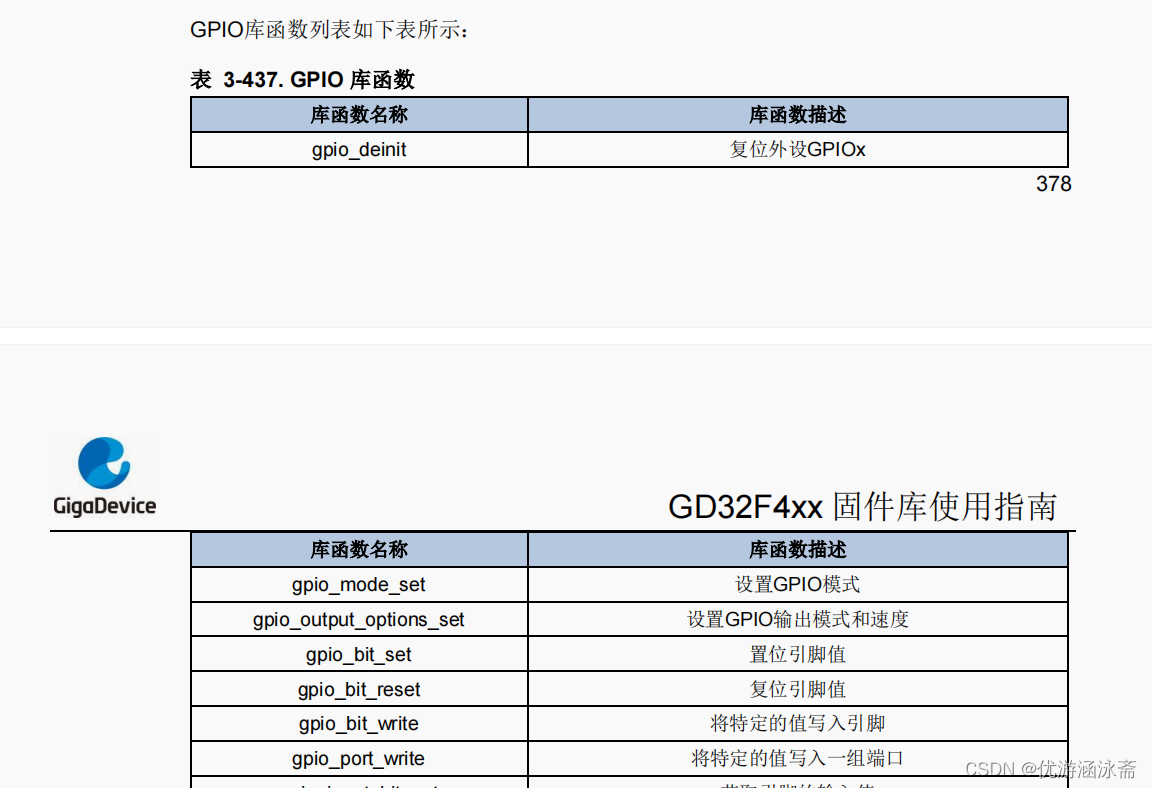
GD32学习
参考视频13.立创开发板GD32教程:串口配置_哔哩哔哩_bilibili 固件库跟用户手册基本上差不多,只不过用用户手册编写程序的话会更加的底层,固件库的话就是把一些函数封装起来,用的时候拿过来即可,目前我还没有找到固件库…...
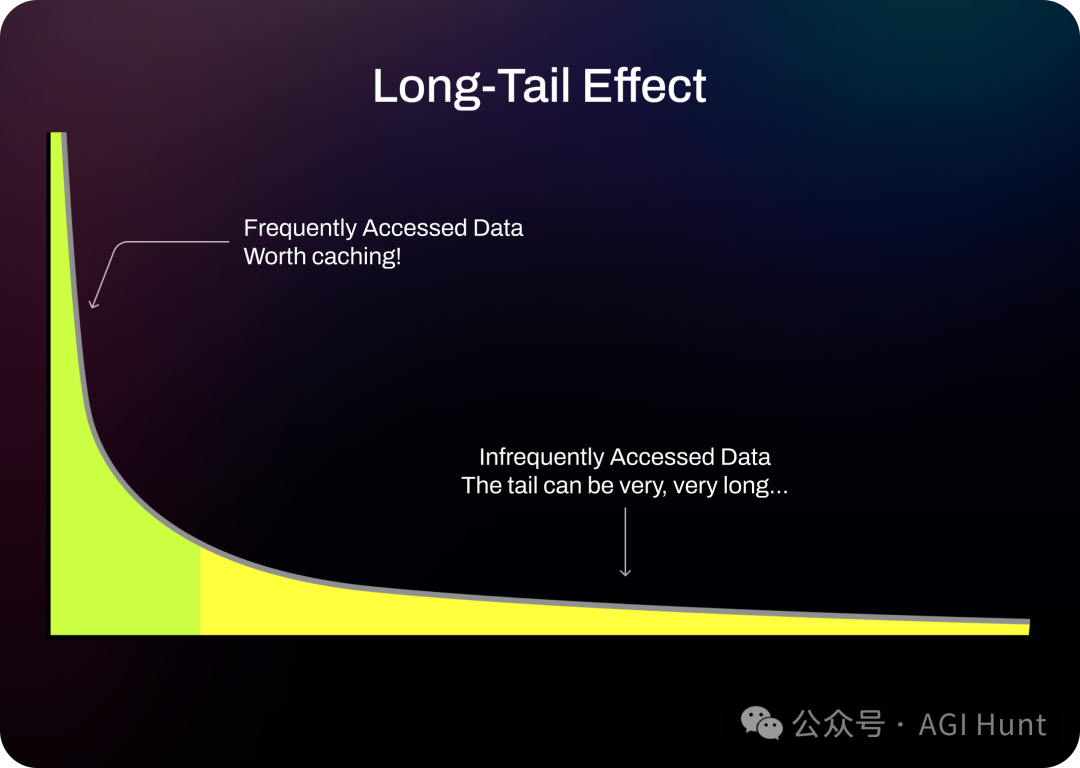
LangChain:如何高效管理 LLM 聊天历史记录?
LangChain 团队发布了一篇关于使用 Dragonfly DB 来有效管理 LangChain 应用程序聊天历史记录的教程。 该教程旨在解决用户在使用 LangChain 应用程序时普遍遇到的一个问题:如何高效地管理聊天历史记录。 LangChain 团队在推文中强调了 Dragonfly DB 在管理聊天历…...

【React】useState 更新延迟的原因是什么,怎么解决?
useState 更新延迟的原因 异步更新:React 中的 useState 更新是异步的,这意味着当你调用更新函数(如 setData)时,React 并不立即同步更新状态,而是将其放入一个待处理的队列中,稍后在适当的时候(如在下一次渲染之前)进行处理。因此,如果你尝试在调用更新函数后立即读…...

非关系型数据库NoSQL数据层解决方案 之 redis springboot整合与读写操作 2024详解以及window版redis5.0.14下载百度网盘
redis下载安装以及基本使用 下载地址 链接:百度网盘 请输入提取码 提取码:0410 一个名对应一个数值 内存级 在内存里进行操作 准备启动 我们现在就有一个redis客户端的服务器了 我们再启动一个cmd 操作redis数据库 redis里面的基本数据类型有五种 …...

jigdo无法下载的文件
问题描述 用jigdo下载Debian的iso镜像,剩下最后一个文件下载不了,提示信息: Found 0 of the 1 files required by the template Copied input files to temporary file debian-12.5.0-amd64-DLBD-2.iso.tmp - repeat command and supply mo…...

C#面:C# 类的执行顺序?
C# 类的执行顺序可以分为以下几个步骤: 静态字段初始化:在类的第一次使用之前,静态字段会被初始化。静态字段的初始化顺序是按照它们在代码中的声明顺序进行的。静态构造函数:如果类中定义了静态构造函数,它会在类的第…...

昇思25天学习打卡营第3天|数据集Dataset
一、简介: 数据是深度学习的基础,高质量的数据输入将在整个深度神经网络中起到积极作用。有一种说法是模型最终训练的结果,10%受到算法影响,剩下的90%都是由训练的数据质量决定。(doge) MindSpore提供基于…...

SpringCloud 服务调用 spring-cloud-starter-openfeign
在Spring Cloud中,spring-cloud-starter-openfeign 是一个用于声明式Web服务客户端(例如REST客户端)的启动器。它使得在Spring Cloud应用中调用其他HTTP服务变得非常简单,只需创建一个接口并使用注解来定义服务调用的细节。 以下…...

基于Elementui组件,在vue中实现多种省市区前端静态JSON数据展示并支持与后端交互功能,提供后端名称label和id
基于Elementui组件,在vue中实现多种省市区前端静态数据(本地JSON数据)展示并支持与后端交互功能,提供后端名称label和id 话不多说,先上图 1.支持传递给后端选中省市区的id和名称,示例非常完整,…...
基于DPU的云原生裸金属网络解决方案
1. 方案背景和挑战 裸金属服务器是云上资源的重要部分,其网络需要与云上的虚拟机和容器互在同一个VPC下,并且能够像容器和虚拟机一样使用云的网络功能和能力。 传统的裸金属服务器使用开源的 OpenStack Ironic 组件,配合 OpenStack Neutron…...

基于Arduino与GPS的物联网数据采集器:从硬件搭建到地图可视化
1. 项目概述:一个硬件极客的万圣节“寻宝图” 又到万圣节了,除了琢磨穿什么奇装异服,你是不是也在头疼怎么规划“不给糖就捣蛋”的路线?每年都像开盲盒,有的门口堆满南瓜灯的人家只给了一根棒棒糖,而某个其…...

手把手教你学Simulink——基于 PWM 加相移混合控制的双向 DC-DC 变换器仿真
目录 手把手教你学Simulink——基于 PWM 加相移混合控制的双向 DC-DC 变换器仿真 摘要 Abstract 1. 引言 1.1 研究背景 1.2 本文目标 2. 混合控制机理 2.1 拓扑选择:双有源桥(DAB) 2.2 混合控制自由度 3. Simulink 主电路建模 3.1…...

如何一键下载推特上的所有媒体资源?X-Spider帮你轻松解决内容收集难题
如何一键下载推特上的所有媒体资源?X-Spider帮你轻松解决内容收集难题 【免费下载链接】x-spider A spider for X (Twitter) 项目地址: https://gitcode.com/gh_mirrors/xs/x-spider 你是否曾遇到过这种情况:在推特上看到了精美的图片、有趣的视频…...

OpenSpire:开源贡献者协作平台的设计理念与实战指南
1. 项目概述:一个面向开源贡献者的协作平台最近在和一些刚接触开源的朋友交流时,发现一个挺普遍的现象:很多人对参与开源项目充满热情,但第一步“如何找到合适的项目并上手”就卡住了。GitHub上项目浩如烟海,一个新手面…...

使用mcp-maker快速构建AI工具调用服务器:从协议原理到工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给大语言模型(LLM)装上更强大的“手脚”,让它能直接操作我电脑上的各种软件和工具。这听起来很酷,对吧?但实际操作起来,你会发现一个核心痛…...

Claw框架数据库迁移工具claw-migrate:原理、实践与团队协作指南
1. 项目概述:一个专为Claw设计的迁移工具最近在折腾一个叫Claw的开源项目,它本身是一个轻量级的Web框架,用起来挺顺手。但项目迭代过程中,难免会遇到数据库结构变更、数据迁移这类“脏活累活”。手动写SQL脚本?太原始&…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...

如何为深信服超融合平台上的应用快速接入大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为深信服超融合平台上的应用快速接入大模型能力 对于在深信服超融合平台上部署业务应用的企业开发团队而言,集成智…...

Simulink模型到汽车控制器:基于模型开发的完整路径
Simulink模型到汽车控制器:基于模型开发的完整路径 一辆智能电动汽车的"灵魂",通常写在300万行以上的嵌入式代码里。但如果每一行代码都要工程师手写,开发周期会从18个月变成……永远完成不了。 一个真实的问题 2023年,…...

氛围驱动开发:数据化提升开发者效率与团队协作的实践指南
1. 项目概述:当开发节奏遇上“氛围感”最近在GitHub上看到一个挺有意思的项目,叫“vibe-driven-dev”。光看名字,你可能会有点摸不着头脑——“氛围驱动开发”?这听起来不像是一个传统的技术框架或工具库。没错,它确实…...