Python 全栈系列256 异步任务与队列消息控制(填坑)
说明
每个创新都会伴随着一系列的改变。
在使用celery进行异步任务后,产生的一个问题恰好也是因为异步产生的。
内容
1 问题描述
我有一个队列 stream1, 对应的worker1需要周期性的获取数据,对输入的数据进行模式识别后分流。worker1我设施为10秒运行一次。然后我就发现输出队列的数据大约是6~7倍于原始数据。
2 分析
在同步执行的状态下,前面 一个任务没有结束,后面的任务即使到了执行时间也会错过。这个在APS任务里是非常明确的。但由于Celery执行的Worker是异步的,这意味着即使前一个任务没有完成,后一个任务还是会如期启动,另开一个线头。
Worker1之前的模式是采用xrange方式获取数据,在处理完成后才将消息删除。
由于模式识别的过程比较复杂,层层过滤,所以单个worker执行的时间超过了60秒。这样在这批消息删除之前,每次启动的worker都取到了相同的数据,处理后也会输出到结果队列。
3 解决办法
理论上,每次worker的取数应该是采用xfetch比较合理,但是对应的,xfetch会因为worker的中断导致消息残留。所以就要有另一些worker来进行残余消息的检测和处理。结果就是 xfetch worker + residual worker配合,显得麻烦。
过去在同步状态下,我就偷懒,只用一个worker进行xrange,这样只有消息被真实消费才会删除。
xfetch是支持多个worker并行的,而xrange则智能支持单个worker。
所以,本次要做的事就是把xfetch + residual 模式搞一下,以后该用什么模式就什么模式。
4 实践
为每个worker提供一种获取残余消息(residual)的办法,每个小时执行一次即可。普通的worker(fetch)一般是秒级,或者分钟级执行的。
当前的QManager是架在RedisAgent服务上封装的对象,这个对象极大简化了平时的操作。不过之前,并没有完全将QManager与RedisAgent的参数对接,采用了较为简单的方式。
本次需要做的是先使用RedisAgent完成对应的任务,然后将QManager进行升级。
构造测试队列
test_list = [{'doc_id':1, 'content':'first'}, {'doc_id':2, 'content':'ss'}]
qm.ensure_group('test.test.test')
qm.parrallel_write_msg('test.test.test', test_list){'status': True, 'msg': 'ok,add 2 of 2 messages'}
获取消息
qm.xfetch('test.test.test', count=1)
{'data': [{'_msg_id': '1718984345178-0', 'doc_id': '1', 'content': 'first'}],'status': True,'msg': 'ok'}
- 1 判断是否有延误消息
两个关键参数,一个是队列名称,一个是延误时间。如果不写延误时间,就是看所有的延误。
resp = req.post('http://172.17.0.1:24118/get_pending_msg/',json = {'stream_name':'test.test.test' , 'idle_seconds':20}).json()resp = req.post('http://172.17.0.1:24118/get_pending_msg/',json = {'stream_name':'test.test.test','idle_seconds':None }).json(){'status': True,'msg': 'ok','data': [['1718984345178-0', 'consumer1', 36675032, 1]]}
延误时间的最大作用是避免获取短时间内超时的任务(如果任务本身就需要很长时间)
如果data字段长度不为0,那么就会有延误消息,获取最小和最大的id即可。
- 2 根据起止id获取数据
delay_data = resp['data']
start_id = delay_data[0][0]
end_id = delay_data[-1][0]resp = req.post('http://172.17.0.1:24118/xrange/',json = {'stream_name':'test.test.test' , 'start_id': start_id,'end_id':end_id}).json()
{'status': True,'msg': 'ok','data': [{'_msg_id': '1718984345178-0', 'doc_id': '1', 'content': 'first'},{'_msg_id': '1718984345178-1', 'doc_id': '2', 'content': 'ss'}]}
所以相应低,修改QMananger(version1.3)的xrange方法,并增加xpending方法
xrange
...# 批量获取数据def xrange(self, stream_name, count = None, start_id = '-' , end_id ='+'):cur_count = count or self.batch_size recs_resp = req.post(self.redis_agent_host + 'xrange/',json ={'connection_hash':self.redis_connection_hash, 'stream_name':stream_name,'count':cur_count,'start_id':start_id,'end_id':end_id}).json()return recs_resp
xpending。原来的接口似乎有点小bug:如果队列没有延误,接口查询会失败
...def xpending(self, stream_name,count = None, idle_seconds = 3600):cur_count = count or self.batch_size # 1 确认是否有延误消息:没有延误消息的情况接口会报错try:resp = req.post(self.redis_agent_host + 'get_pending_msg/',json ={'stream_name': stream_name, 'idle_seconds': idle_seconds}).json()# 如果没有数据,直接返回(标准格式)if len(resp['data']) == 0:print('No Pending')return resp except:return {'status':True, 'msg':'query pending fail', 'data':[]}# 2 获取被延误的消息min_id = resp['data'][0][0]max_id = resp['data'][-1][0]return self.xrange(stream_name, count = cur_count, start_id = min_id, end_id = max_id)
Note: 我们对正常执行的任务,感知/容忍的周期为分钟;对延误执行(补漏)的任务,感知/容忍的周期为小时。
来看改造后的QM
# xfetch,但是此时已经无数据可取
qm.xfetch('test.test.test' )
{'status': True, 'msg': 'ok', 'data': []}
# xpending 此时有两条延误较长时间的消息
qm.xpending('test.test.test' , idle_seconds=3600)
{'status': True,'msg': 'ok','data': [{'_msg_id': '1718984345178-0', 'doc_id': '1', 'content': 'first'},{'_msg_id': '1718984345178-1', 'doc_id': '2', 'content': 'ss'}]}
# 用xrange取出,处理
data_list = qm.xpending('test.test.test' , idle_seconds=3600)['data']
[{'_msg_id': '1718984345178-0', 'doc_id': '1', 'content': 'first'},{'_msg_id': '1718984345178-1', 'doc_id': '2', 'content': 'ss'}]# 假设处理完,准备删除消息
data_msg_list = qm.extract_msg_id(data_list)
['1718984345178-0', '1718984345178-1']
qm.xdel('test.test.test', data_msg_list)
{'data': 2, 'status': True, 'msg': 'ok'}# 再次使用xpending
qm.xpending('test.test.test' , idle_seconds=3600)
{'status': True, 'msg': 'no source data', 'data': []}另外,xpending中,即使是把pending的消息处理掉了,仍然可以读到pending信息,所以每次会调用一下xrange查询一个不存在的区间,稍微有点浪费。不过考虑到这是补救型的操作,一个小时才运行一次,就没有关系了。
相关文章:
)
Python 全栈系列256 异步任务与队列消息控制(填坑)
说明 每个创新都会伴随着一系列的改变。 在使用celery进行异步任务后,产生的一个问题恰好也是因为异步产生的。 内容 1 问题描述 我有一个队列 stream1, 对应的worker1需要周期性的获取数据,对输入的数据进行模式识别后分流。worker1我设施为10秒运行…...
从零开始的Ollama指南:部署私域大模型
大模型相关目录 大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容 从0起步,扬帆起航。 大模型应用向开发路径:AI代理工作流大模型应用开发实用开源项目汇总大模…...

C++类和对象总结
目录 总结 一、引言 二、类的定义 三、对象的创建与初始化 四、访问控制 五、封装 六、继承 七、多态 八、其他特性 九、总结 C类的定义 C对象的创建和初始化 C类的访问控制 总结 一、引言 C是一种面向对象的编程语言,其核心概念是类和对象。类是对现…...
基于PHP的民宿管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的民宿管理系统 一 介绍 此民宿管理系统基于原生PHP开发,数据库mysql,前端jquery.js和echarts.js。系统角色分为用户和管理员。用户可以在线浏览和预订民宿,管理员登录后台进行相关管理等。(在系统…...

ROS中C++、Python完整的目录结构
文章目录 在ROS中,一个典型的C软件包目录结构通常包括以下几个主要目录: include:该目录包含C头文件(.hpp或者.h文件),用于声明类、函数、变量等。通常,这些头文件定义了ROS节点、消息类型、服务…...
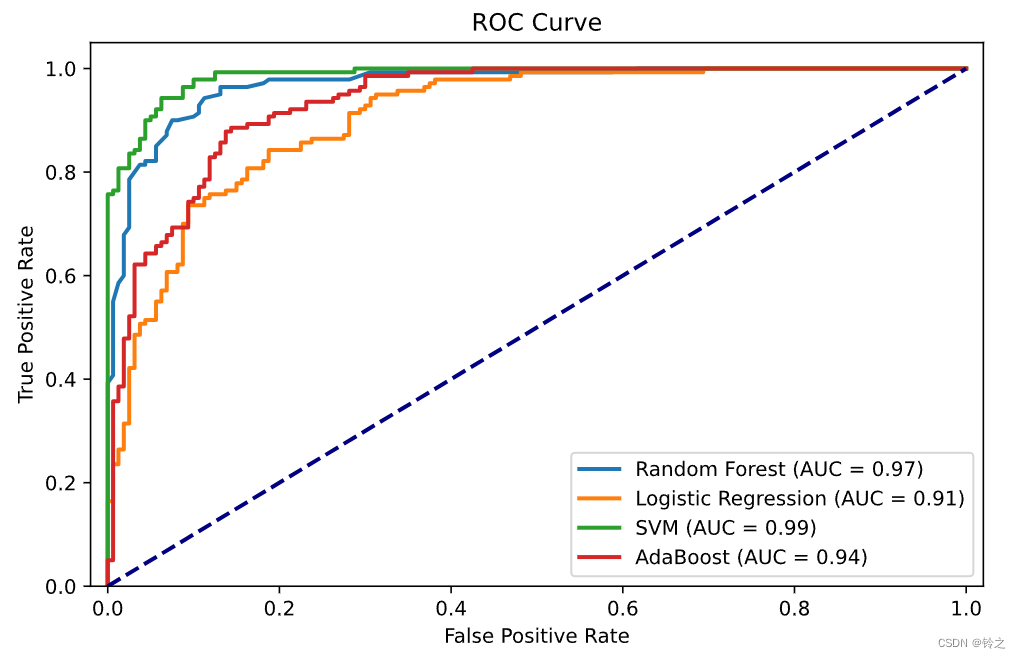
Boosting原理代码实现
1.提升方法是将弱学习算法提升为强学习算法的统计学习方法。在分类学习中,提升方法通过反复修改训练数据的权值分布,构建一系列基本分类器(弱分类器),并将这些基本分类器线性组合,构成一个强分类…...

【Qt基础教程】事件
文章目录 前言事件简介事件示例总结 前言 在开发复杂的图形用户界面(GUI)应用程序时,理解和掌握事件处理是至关重要的。Qt,作为一个强大的跨平台应用程序开发框架,提供了一套完整的事件处理系统。本教程旨在介绍Qt事件处理的基础知识&#x…...

外星人Alienware m15R7 原厂Windows11系统
装后恢复到您开箱的体验界面,包括所有原机所有驱动AWCC、Mydell、office、mcafee等所有预装软件。 最适合您电脑的系统,经厂家手调试最佳状态,性能与功耗直接拉满,体验最原汁原味的系统。 原厂系统下载网址:http://w…...

stata17中java installation not found或java not recognozed的问题
此问题在于stata不知道去哪里找java,因此需要手动的告诉他 方法1: 1.你得保证已经安装并配置好java环境 2.在stata中输入以下内容并重启stata即可 set java_home "D:\Develope\JDk17" 其中java_home后面的""里面的内容是你的jdk安装路径 我的…...

Harbor本地仓库搭建003_Harbor常见错误解决_以及各功能使用介绍_镜像推送和拉取---分布式云原生部署架构搭建003
首先我们去登录一下harbor,但是可以看到,用户名密码没有错,但是登录不上去 是因为,我们用了负债均衡,nginx会把,负载均衡进行,随机分配,访问的 是harbora,还是harborb机器. loadbalancer中 解决方案,去loadbalance那个机器中,然后 这里就是25机器,我们登录25机器 然后去配置…...
怎样搭建serveru ftp个人服务器
首先说说什么是ftp? FTP协议是专门针对在两个系统之间传输大的文件这种应用开发出来的,它是TCP/IP协议的一部分。FTP的意思就是文件传输协议,用来管理TCP/IP网络上大型文件的快速传输。FTP早也是在Unix上开发出来的,并且很长一段…...

SEO是什么?SEO相关发展历史
一、SEO是什么意思? SEO(Search Engine Optimization),翻译成中文就是“搜索引擎优化”。简单来讲,seo是指自然搜索结果下获得的网站流量的技术,是可以不用花钱就可以让自己的网站有好的排名,也…...

android之WindowManager悬浮框
文章目录 阐述悬浮框的实现AndroidManifest配置使用方法 阐述 Window的类型大致分为三种: Application Window 应用程序窗口、Sub Window 子窗口、System Window 系统窗口 窗口类型图层值(type)Application Window1~99Sub Windo…...

注解详解系列 - @Scope:定义Bean的作用范围
注解简介 在今天的注解详解系列中,我们将探讨Scope注解。Scope是Spring框架中的一个重要注解,用于定义bean的作用范围。通过Scope注解,可以控制Spring容器中bean的生命周期和实例化方式。 注解定义 Scope注解用于定义Spring bean的作用范围…...
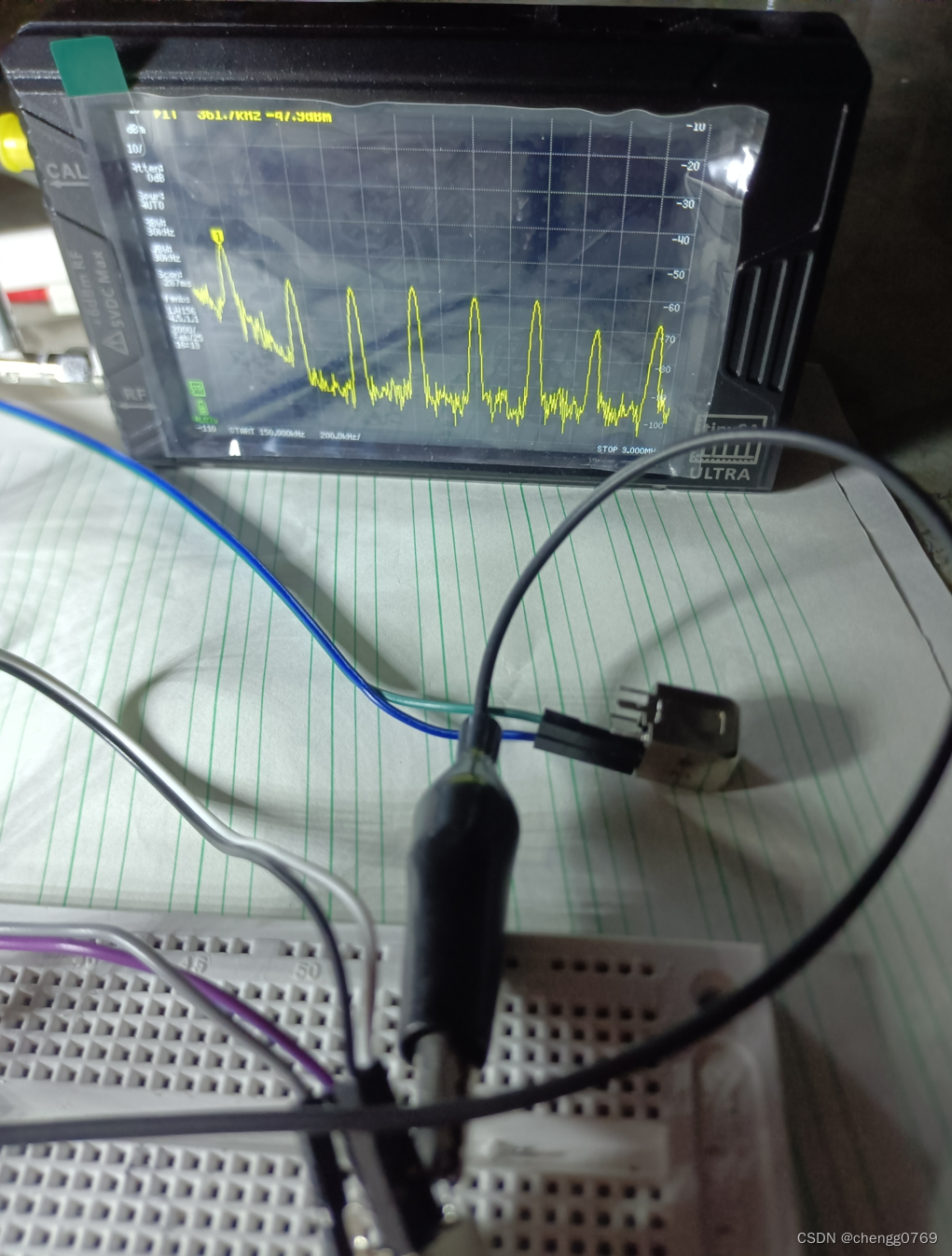
仿中波本振电路的LC振荡器电路实验
手里正好有一套中波收音机套件的中周。用它来测试一下LC振荡器,电路如下: 用的是两只中频放大的中周,初步测试是用的中周自带的瓷管电容,他们应该都是谐振在465k附近。后续测试再更换电容测试。 静态电流,0.5到1mA。下…...

Java 面试题:谈谈 final、finally、 finalize 有什么不同?
在 Java 编程中,final、finally 和 finalize 是三个看似相似但用途截然不同的关键字和方法。理解它们的区别对于编写高质量和健壮的代码至关重要。 final 关键字可用于声明常量、方法和类。用在变量上表示变量不可变,用在方法上表示方法不能被重写&#…...

45、基于深度学习的螃蟹性别分类(matlab)
1、基于深度学习的螃蟹性别分类原理及流程 基于深度学习的螃蟹性别分类原理是利用深度学习模型对螃蟹的图像进行训练和识别,从而实现对螃蟹性别的自动分类。整个流程可以分为数据准备、模型构建、模型训练和性别分类四个步骤。 数据准备: 首先需要收集包…...

mongodb嵌套聚合
db.order.aggregate([{$match: {// 下单时间"createTime": {$gte: ISODate("2024-05-01T00:00:00Z"),$lte: ISODate("2024-05-31T23:59:59Z")}// 商品名称,"goods.productName": /美国皓齿/,//订单状态 2:待发货 3:已发货 4:交易成功…...
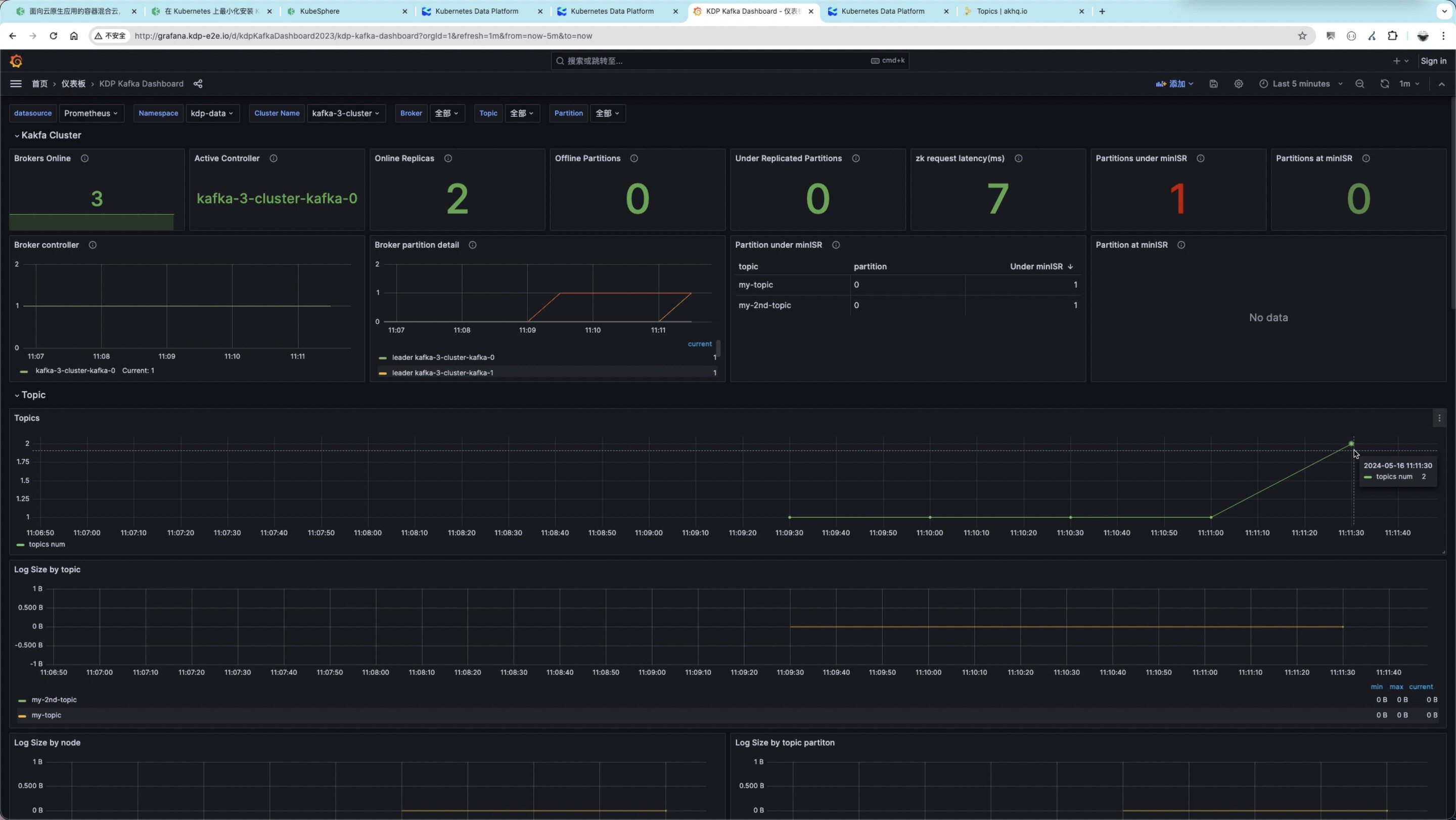
在 KubeSphere 上快速安装和使用 KDP 云原生数据平台
作者简介:金津,智领云高级研发经理,华中科技大学计算机系硕士。加入智领云 8 余年,长期从事云原生、容器化编排领域研发工作,主导了智领云自研的 BDOS 应用云平台、云原生大数据平台 KDP 等产品的开发,并在…...
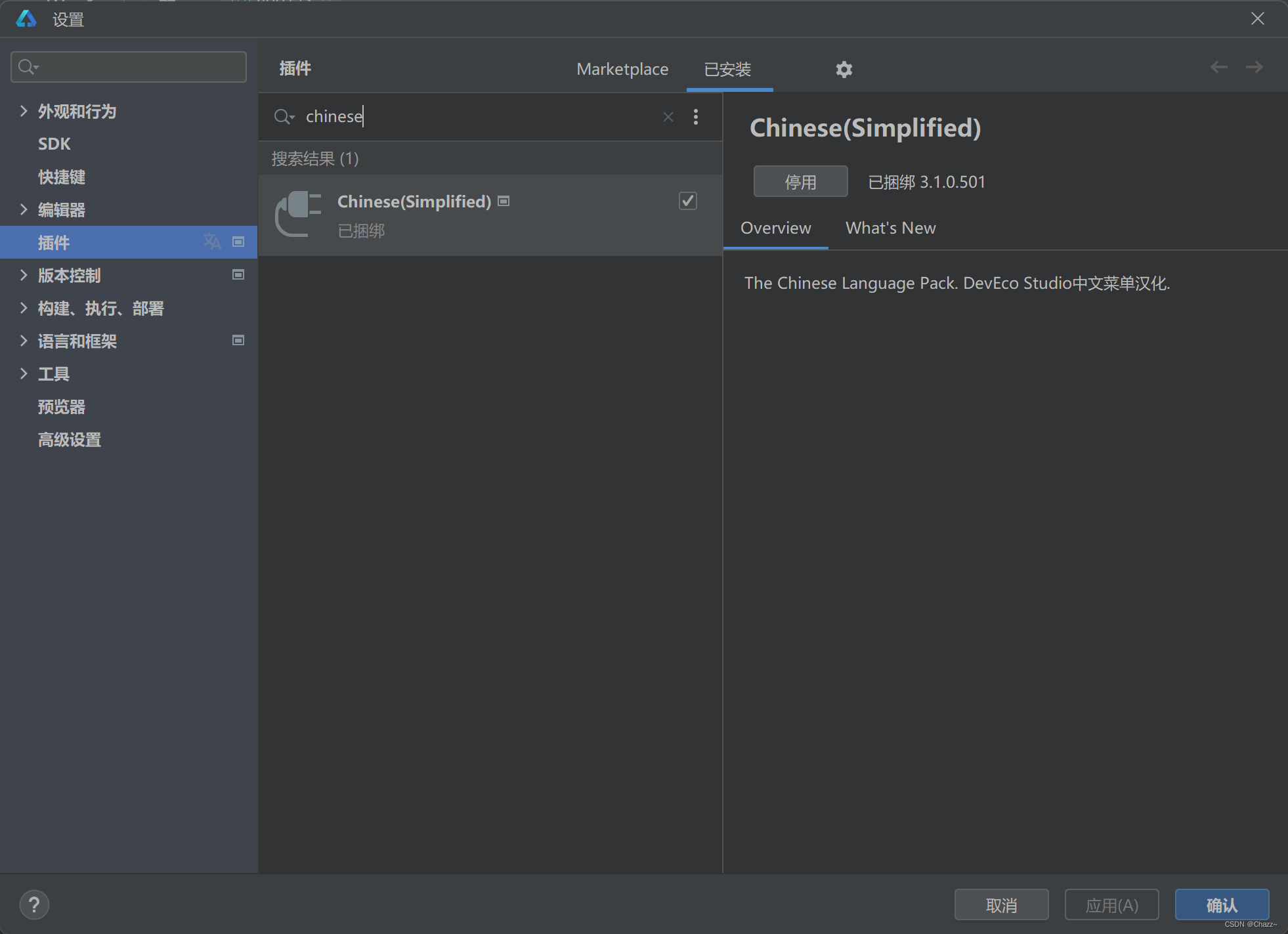
Dev Eco Studio设置中文界面
Settings-Plugins-installed-搜索Chinese...

Taotoken平台在持续高并发调用下的稳定性与容灾能力观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台在持续高并发调用下的稳定性与容灾能力观察 在构建依赖大模型能力的应用时,服务的稳定性是开发者关心的核…...
的第一个步骤是**识别问题域中的对象和类**(也称为“识别对象与类”或“确定问题域中的概念类”))
面向对象分析(OOA)的第一个步骤是**识别问题域中的对象和类**(也称为“识别对象与类”或“确定问题域中的概念类”)
面向对象分析(OOA)的第一个步骤是识别问题域中的对象和类(也称为“识别对象与类”或“确定问题域中的概念类”)。 这一步要求分析师深入理解用户需求和现实世界的问题背景,通过用例分析、领域建模、名词提取等方法&…...

3步高效解决Krita AI Diffusion插件IP-Adapter缺失问题
3步高效解决Krita AI Diffusion插件IP-Adapter缺失问题 【免费下载链接】krita-ai-diffusion Streamlined interface for generating images with AI in Krita. Inpaint and outpaint with optional text prompt, no tweaking required. 项目地址: https://gitcode.com/gh_mi…...

技能图谱:构建结构化知识体系,实现高效学习与成长
1. 项目概述:一个技能图谱的诞生与价值在技术社区里,我们经常看到各种“Awesome List”——那些按领域整理的工具、库和资源清单。它们很有用,但总感觉缺了点什么。直到我偶然在 GitHub 上看到了tenequm/skills这个仓库,它给我带来…...

手把手调优:如何榨干寒武纪MLU370系列卡的每一份算力?
寒武纪MLU370算力压榨实战:从芯片架构到BANG编程的深度调优指南 当一张价值数十万元的AI加速卡在数据中心里以30%的利用率运行时,每个周期都在烧掉本该属于企业的利润。寒武纪MLU370系列作为国产AI加速卡的代表作,其真实算力潜力往往被大多数…...

算力基石:CPU、GPU与嵌入式AI的技术逻辑与融合发展
在人工智能全面普及的时代,算力已经成为数字产业发展的核心驱动力。从日常使用的智能手机、家用电脑,到云端大模型、智能汽车、工业传感设备,各类智能终端的运转都离不开处理器的算力支撑。其中,CPU作为通用计算核心、GPU作为并行…...
)
你的嵌入式数据记录仪方案:基于STM32CubeMX+FATFS+SD卡存储传感器数据(CSV格式实战)
嵌入式数据记录仪实战:STM32CubeMXFATFSSD卡构建工业级CSV存储方案 在工业物联网和智能硬件开发中,可靠的数据记录功能往往是产品核心价值所在。想象一下温室大棚的环境监控系统需要连续记录温湿度数据三个月,或者电力设备振动监测装置要在无…...

从FFT到CZT:解锁频谱细化的精准分析新维度
1. 为什么我们需要频谱细化? 在信号处理的世界里,傅里叶变换(FFT)就像是一把瑞士军刀,几乎每个工程师都会用它来分析信号的频率成分。但当你面对两个频率非常接近的信号时,FFT就显得力不从心了。我曾在一次…...

2026年小程序多少钱:8款高口碑产品排行榜解锁最优选择
导读:2026年,小程序开发已成为企业数字化运营的核心工具,其成本结构受功能复杂度、平台选择及服务商专业度等多因素影响。市场调研显示,基础展示型小程序报价集中在5000-15000元,而定制化多功能方案可达5万元以上。行业…...

vibe coding效率高:一个新mcp server已经试运行尚可
下面是文档: judicial-doc-quality-mcp v0.1.0 司法裁判文书质量评估 MCP 服务器 — 桥接架构,零 LLM 调用 English | 中文 概述 judicial-doc-quality-mcp 是一个基于 Model Context Protocol (MCP) 的裁判文书质量评估服务器,采用**桥接…...