ES全文检索支持繁简和IK分词检索
ES全文检索支持繁简和IK分词检索
- 1. 前言
- 2. 引入繁简转换插件analysis-stconvert
- 2.1 下载已有作者编译后的包文件
- 2.2 下载源码进行编译
- 2.3 复制解压插件到es安装目录的plugins文件夹下
- 3. 引入ik分词器插件
- 3.1 已有作者编译后的包文件
- 3.2 只有源代码的版本
- 3.3 安装ik分词插件
- 4. 建立IK和繁简集成的es索引
- 5. 新增数据测试检索
1. 前言
在现代信息检索中,处理不同语言的变体和实现高效的全文检索是一个重要的需求。对于中文,特别是需要处理简体和繁体的转换,以及高效的分词处理,这就显得尤为重要。ElasticSearch(ES)作为一个分布式全文搜索引擎,提供了强大的文本搜索和分析能力,但默认情况下并不支持简繁转换和高级的中文分词。因此,我们需要通过一些插件和自定义设置来实现这一功能。
本教程旨在展示如何在ES中引入繁简转换和IK分词插件,使得在检索时无论输入简体还是繁体都能够被检索到。无论用户输入“語法”还是“语法”,检索结果中都能命中包含简体和繁体的相关文档。这种处理方式不仅提升了用户体验,还增强了检索的准确性和全面性。
通过引入分析插件analysis-stconvert和分词插件analysis-ik,并结合自定义的ES配置,我们可以实现这一目标。以下将详细介绍如何下载、编译、安装这些插件,并通过示例展示如何建立支持繁简转换和IK分词的ES索引,最后通过实际数据插入和检索验证配置的效果。
2. 引入繁简转换插件analysis-stconvert
插件地址: https://github.com/infinilabs/analysis-stconvert/releases
2.1 下载已有作者编译后的包文件
如果存在可直接使用的zip文件,选择与自己版本一致的版本
2.2 下载源码进行编译
如果没有下载即可使用的安装包,需要自己下载源码进行编译。下载打开后使用mvn clean install进行打包

如果报错信息如下:
[ERROR] COMPILATION ERROR :
[INFO] -------------------------------------------------------------
[ERROR] /E:/project/PersonalProjects/analysis-stconvert-7.17.11/analysis-stconvert-7.17.11/src/main/java/org/elasticsearch/index/analysis/STConvertAnalyzerProvider.java:[28,9] 无法将类 org.elasticsearch.index.analysis.AbstractIndexA
nalyzerProvider<T>中的构造器 AbstractIndexAnalyzerProvider应用到给定类型;需要: org.elasticsearch.index.IndexSettings,java.lang.String,org.elasticsearch.common.settings.Settings找到: java.lang.String,org.elasticsearch.common.settings.Settings原因: 实际参数列表和形式参数列表长度不同
[ERROR] /E:/project/PersonalProjects/analysis-stconvert-7.17.11/analysis-stconvert-7.17.11/src/main/java/org/elasticsearch/index/analysis/STConvertTokenFilterFactory.java:[31,9] 无法将类 org.elasticsearch.index.analysis.AbstractToke
nFilterFactory中的构造器 AbstractTokenFilterFactory应用到给定类型;需要: org.elasticsearch.index.IndexSettings,java.lang.String,org.elasticsearch.common.settings.Settings找到: java.lang.String,org.elasticsearch.common.settings.Settings原因: 实际参数列表和形式参数列表长度不同
[ERROR] /E:/project/PersonalProjects/analysis-stconvert-7.17.11/analysis-stconvert-7.17.11/src/main/java/org/elasticsearch/index/analysis/STConvertCharFilterFactory.java:[34,9] 无法将类 org.elasticsearch.index.analysis.AbstractCharF
ilterFactory中的构造器 AbstractCharFilterFactory应用到给定类型;需要: org.elasticsearch.index.IndexSettings,java.lang.String找到: java.lang.String原因: 实际参数列表和形式参数列表长度不同
[INFO] 3 errors
[INFO] -------------------------------------------------------------
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
下面类中,增加如下参数,标红报错不需要处理仍可以打包成功

打包成功后可以在项目目录\target\releases看到编译后的压缩包elasticsearch-analysis-stconvert-7.17.11.zip
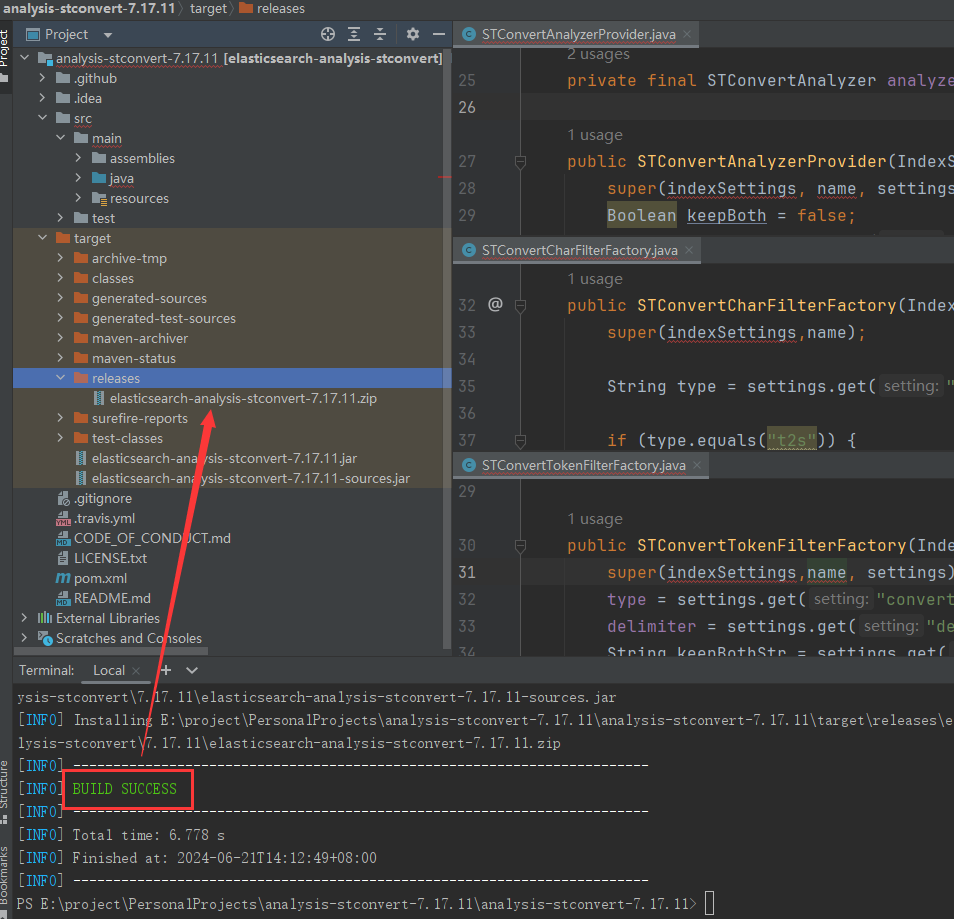
2.3 复制解压插件到es安装目录的plugins文件夹下

es数据库启动时会自动加载插件,如下输出即表示引入成功
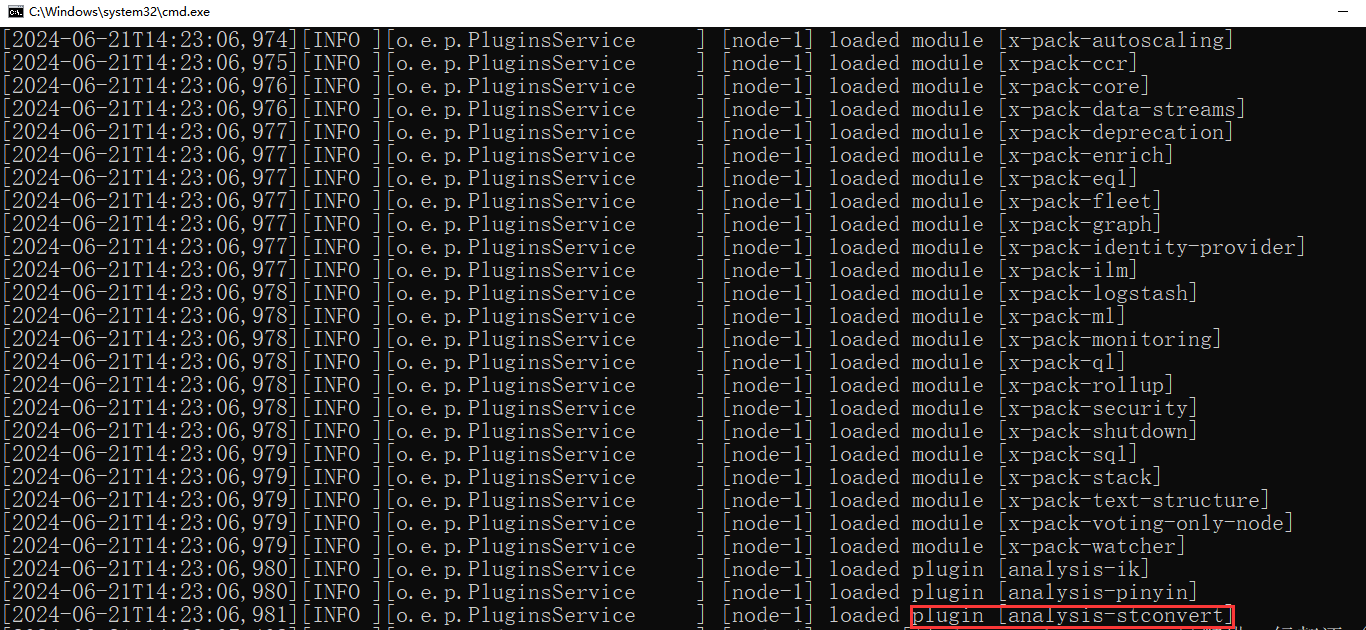
3. 引入ik分词器插件
GitHub下载地址:Releases · infinilabs/analysis-ik · GitHub
3.1 已有作者编译后的包文件
选择与所需es版本相同的ik分词器,下载已经打包后的.zip文件

3.2 只有源代码的版本
首先下载源码解压后使用idea打开,修改es版本与分词器版本相同
使用 mvn clean install 打包时报错:
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.5.1:compile (default-compile) on project elasticsearch-analysis-ik: Compilation failure
[ERROR] /D:/PersonalProjects/analysis-ik-7.17.11/analysis-ik-7.17.11/src/main/java/org/elasticsearch/index/analysis/IkAnalyzerProvider.java:[13,9] 无法将类 org.elasticsearch.index.analysis.AbstractIndexAnalyzerProvider<T>中的构造器
AbstractIndexAnalyzerProvider应用到给定类型;
[ERROR] 需要: org.elasticsearch.index.IndexSettings,java.lang.String,org.elasticsearch.common.settings.Settings
[ERROR] 找到: java.lang.String,org.elasticsearch.common.settings.Settings
修改代码报错部分:增加indexSetting参数到super入参的第一个位置

使用mvn clean install进行打包,注意我们所需的是/target/release目录下的.zip压缩包

3.3 安装ik分词插件
将下载或者编译后的.zip文件解压到es的安装目录下的plugins目录下,并重命名为ik
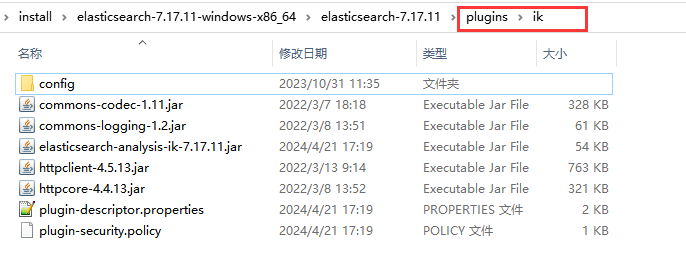
然后启动es,查看日志可发现已经加载的ik分词器
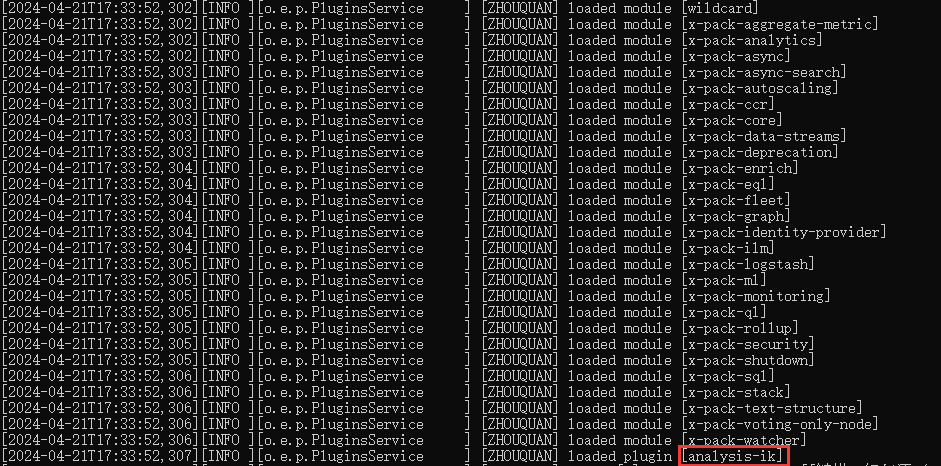
常规的最常用的使用方式就是,数据插入存储时用 ik_max_word模式分词,而检索时,用ik_smart模式分词,即:索引时最大化的将文章内容分词,搜索时更精确的搜索到想要的结果。
4. 建立IK和繁简集成的es索引
PUT http://localhost:9200/test/
{"aliases": {},"settings": {"index": {"refresh_interval": "3s","number_of_shards": "3","number_of_replicas": "1","max_inner_result_window": "10000","max_result_window": "20000","analysis": {"analyzer": {"ik_max_word_convert": {"type": "custom","char_filter": ["tsconvert","stconvert"],"tokenizer": "ik_max_word","filter": ["lowercase"]},"ik_smart_convert": {"type": "custom","char_filter": ["tsconvert","stconvert"],"tokenizer": "ik_smart","filter": ["lowercase"]}}}}},"mappings": {"properties": {"otherTitle": {"type": "text","analyzer": "ik_max_word_convert","search_analyzer": "ik_smart_convert"}}}
}
analysis部分定义了自定义分析器:
- ik_max_word_convert:
- type:
"custom":定义一个自定义分析器。 - char_filter:
tsconvert: 自定义字符过滤器(用于繁体到简体转换)。stconvert: 自定义字符过滤器(用于简体到繁体转换)。
- tokenizer:
"ik_max_word"- 使用IK分析器的最大词语分割。 - filter:
["lowercase"]- 将所有字符转换为小写。
- type:
- ik_smart_convert:
- type:
"custom" - char_filter:
tsconvertstconvert
- tokenizer:
"ik_smart" - filter:
["lowercase"]
- type:
5. 新增数据测试检索
新增测试数据
PUT /test/_doc/2
{"nickName":"語法講義"
} PUT /test/_doc/3
{"nickName":"语法讲义"
}
中文简写查询
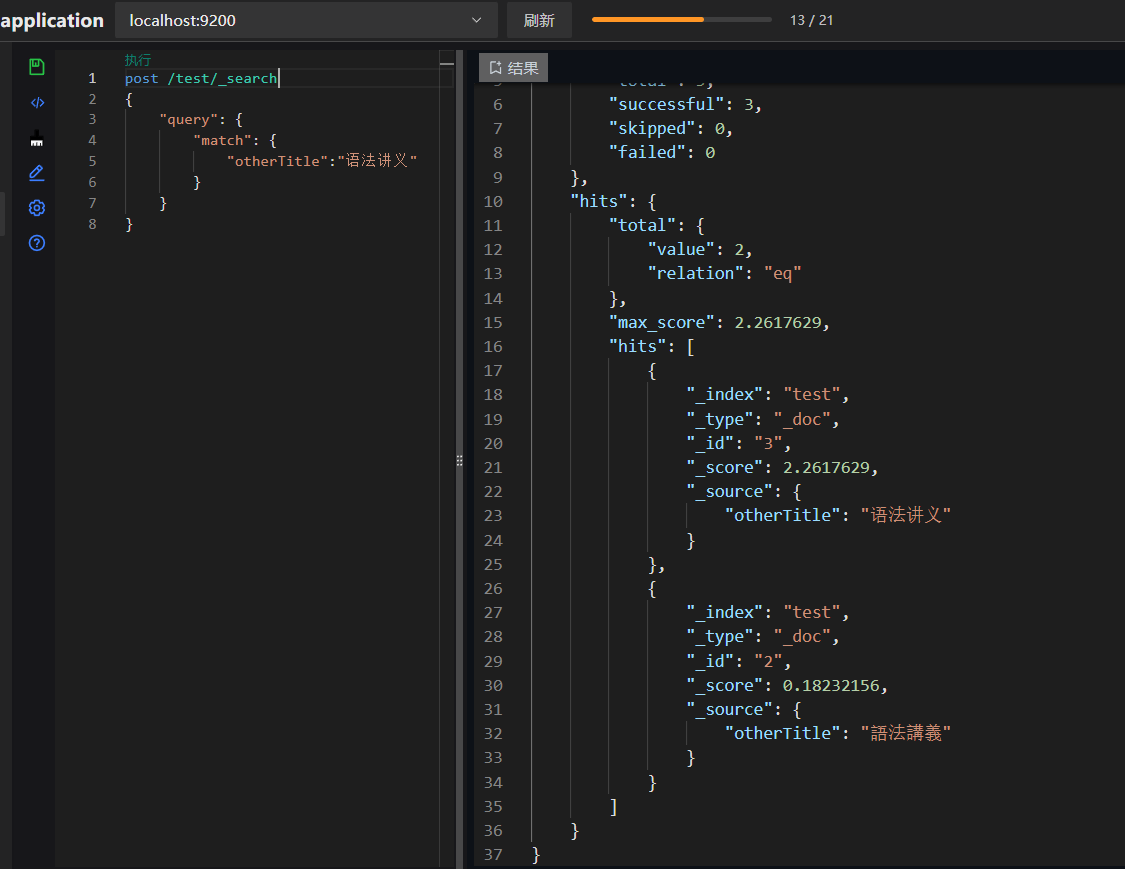
中文繁体查询

通过上述配置和测试,我们可以看到无论是简体输入还是繁体输入,ES都能正确检索到相关文档。这证明了我们引入的繁简转换和IK分词插件的有效性,以及自定义分析器配置的正确性
相关文章:
ES全文检索支持繁简和IK分词检索
ES全文检索支持繁简和IK分词检索 1. 前言2. 引入繁简转换插件analysis-stconvert2.1 下载已有作者编译后的包文件2.2 下载源码进行编译2.3 复制解压插件到es安装目录的plugins文件夹下 3. 引入ik分词器插件3.1 已有作者编译后的包文件3.2 只有源代码的版本3.3 安装ik分词插件 4…...

解决Visual Studio Code在Ubuntu上崩溃的问题
解决Visual Studio Code在Ubuntu上崩溃的问题 我正在使用Ubuntu系统,每次打开Visual Studio Code时,只能短暂打开一秒钟,然后就会崩溃。当通过终端使用code --verbose命令启动Visual Studio Code时,出现以下错误信息:…...
)】)
【OpenGauss源码学习 —— (ALTER TABLE(SET attribute_option))】
ALTER TABLE(SET attribute_option) ATExecSetOptions 函数 声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。…...
Elasticsearch 数据提取 - 最适合这项工作的工具是什么?
作者:来自 Elastic Josh Asres 了解在 Elasticsearch 中为你的搜索用例提取数据的所有不同方式。 对于搜索用例,高效采集和处理来自各种来源的数据的能力至关重要。无论你处理的是 SQL 数据库、CRM 还是任何自定义数据源,选择正确的数据采集…...

‘浔川画板v5.1’即将上线!——浔川python社
1 简介: 浔川画板是一款专业的数字绘画和漫画创作软件,它为艺术家和设计师提供了丰富的绘画工具、色彩管理功能以及易于使用的界面。用户可以使用浔川画板进行手绘风格的绘画、精细的素描、漫画分格、UI设计等多种创作。该软件支持多种笔刷和特效&#…...
RockChip Android12 System之Datetime
一:概述 本文将针对Android12 Settings二级菜单System中Date&time的UI修改进行说明。 二:Date&Time 1、Activity packages/apps/Settings/AndroidManifest.xml <activityandroid:name="Settings$DateTimeSettingsActivity"android:label="@stri…...

详解 ClickHouse 的副本机制
一、简介 副本功能只支持 MergeTree Family 的表引擎,参考文档:https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/replication/ ClickHouse 副本的目的主要是保障数据的高可用性,即使一台 ClickHouse 节点宕机&#…...

速卖通测评成本低见效快,自养号测评的实操指南,快速积累销量和好评
对于初入速卖通的新卖家而言,销量和评价的积累显得尤为关键。由于新店铺往往难以获得平台活动的青睐,因此流量的获取成为了一大挑战。在这样的背景下,进行产品测评以积累正面的用户反馈和销售记录,成为了提升店铺信誉和吸引潜在顾…...
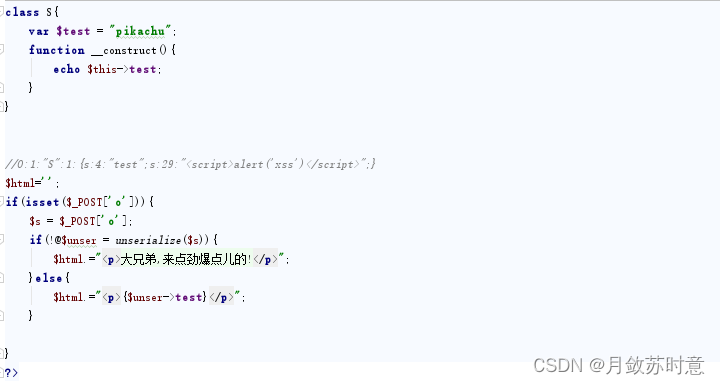
php反序列化漏洞简介
目录 php序列化和反序列化简介 序列化 反序列化 类中定义的属性 序列化实例 反序列化实例 反序列化漏洞 序列化返回的字符串格式 魔术方法和反序列化利用 绕过wakeup 靶场实战 修复方法 php序列化和反序列化简介 序列化 将对象状态转换为可保持或可传输的格式的…...

力扣随机一题 模拟+字符串
博客主页:誓则盟约系列专栏:IT竞赛 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 1910.删除一个字符串中所有出现的给定子字符串【中等】 题目: …...

java-正则表达式 1
Java中的正则表达式 1. 正则表达式的基本概念 正则表达式(Regular Expression, regex)是一种用于匹配字符串中字符组合的模式。正则表达式广泛应用于字符串搜索、替换和解析。Java通过java.util.regex包提供了对正则表达式的支持,该包包含两…...

Python xlrd库:读excel表格
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...

开发中遇到的一个bug
遇到的报错信息是这样的: java: Annotation processing is not supported for module cycles. Please ensure that all modules from cycle [hm-api,hm-common,hm-service] are excluded from annotation processing 翻译过来就是存在循环引用的情况,导…...
及其适用场景)
Java面试题:对比不同的垃圾收集器(如Serial、Parallel、CMS、G1)及其适用场景
Java虚拟机(JVM)提供了多种垃圾收集器,每种垃圾收集器在性能和适用场景上各有不同。以下是对几种常见垃圾收集器(Serial、Parallel、CMS、G1)的对比及其适用场景的详细介绍: 1. Serial 垃圾收集器 Serial…...

每日一题——冒泡排序
C语言——冒泡排序 冒泡排序练习 前言:CSDN的小伙伴们,大家好!今天我来给大家分享一种解题思想——冒泡排序。 冒泡排序 冒泡法的核心思想:两两相邻的元素进行比较 2.冒泡排序的算法描述如下。 (1)比较相邻的元素。如果第一 个比…...

javascript浏览器对象模型
BOM对象: BOM 是浏览器对象模型的简称。JavaScript 将整个浏览器窗口按照实现的功能不同拆分成若干个对象; 包含:window 对象、history 对象、location 对象和 document 对象等 window对象: 常用方法: 1.prompt();…...

C语言之链表以及单链表的实现
一:链表的引入 1:从数组的缺陷说起 (1)数组有两个缺陷。一个是数组中所有元素类型必须一致,第二是数组的元素个数必须事先指定并且一旦指定后不能更改 (2)如何解决数组的两个缺陷:数…...
AI在线免费视频工具2:视频配声音;图片说话hedra
1、视频配声音 https://deepmind.google/discover/blog/generating-audio-for-video/ https://www.videotosoundeffects.com/ (免费在线使用) 2、图片说话在线图片生成播报hedra hedra 上传音频与图片即可合成 https://www.hedra.com/ https://www.…...
)
Elastic字段映射(_source,doc_value,fileddata,index,store)
Elastic字段映射(_source,doc_value,filed_data,index,store) _source: source 字段用于存储 post 到 ES 的原始 json 文档。为什么要存储原始文档呢?因为 ES 采用倒排索引对文本进行搜索,而倒排索引无法存储原始输入…...

kotlin空类型安全 !! ?. ?:
1、定义可空类型 fun main(){// 定义可空类型var x:String? "hello"x null } 2、!! 强转类型 定义可空类型之后,如果使用其内置方法,编译不会通过,因为值有可能为null,可以使用 !! 把类型强转为不可空:…...

SC4541SKTRT 2MHz 2.9V~22V升/降压单线LED驱动器Semtech电子元器件IC芯片
SC4541SKTRT是Semtech(升特)推出的高频LED驱动器芯片,该器件集升压与降压拓扑于一体,支持2.9V至22V超宽输入电压并具备25V输出电压能力,利用内置肖特基二极管和功率开关,将外部电路减至最少,实现…...

选型避坑指南:W25Q64JVSIQ vs GD25Q128CYSIG,你的项目到底该用哪颗SPI Flash?
W25Q64JVSIQ与GD25Q128CYSIG深度对比:工程师实战选型指南 在物联网设备和消费电子产品设计中,SPI Flash的选择往往被低估其重要性——直到量产阶段出现兼容性问题或突发缺货才追悔莫及。作为硬件研发团队的技术决策者,我们不仅要关注芯片的基…...

TPS5430玩点不一样的:15V输入如何生成一个干净的-12V电源?电路设计与极性电容防炸指南
TPS5430负压生成实战:从15V到-12V的电路设计精要 在模拟电路设计中,双电源供电系统(如12V)是音频设备、运算放大器和高精度ADC的常见需求。然而,当系统仅提供单路正电压输入时,如何高效生成稳定的负电压轨成…...

Spring AI + Ollama 深度实战:从 RAG 问答到 Graph Agent 全流程指南
场景 Spring AI RAG 检索增强生成:概念、实战与完整代码: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/161055108 基于上面的基础,实现Graph工作流编排的简单示例。 大语言模型(LLM)在实际应用中面…...

从U-net到U-net++:探索跳跃连接的演进与优化
1. U-net的跳跃连接:从基础原理到核心价值 我第一次接触U-net是在处理医学影像分割项目时。当时试遍了各种模型,直到发现这个结构简洁却效果惊人的网络,才真正体会到跳跃连接(Skip Connection)的魔力。简单来说&#x…...

如何成为年薪百万的AI算法工程师?字节跳动AI Lab的内部指南
一、破局:软件测试从业者的AI算法工程师转型契机 在AI技术浪潮的席卷下,软件测试行业正经历着深刻变革,同时也为从业者打开了通往AI算法工程师领域的大门。2026年数据显示,AI在测试行业的渗透率已超40%,新发AI测试岗位…...

从电压模到COT:DC-DC降压转换器控制模式演进与选型指南
1. DC-DC降压转换器控制模式概述 第一次接触电源设计时,我被各种控制模式搞得晕头转向。电压模、电流模、迟滞控制、COT...这些专业名词就像天书一样。后来在实际项目中摸爬滚打多年,才发现理解这些控制模式的关键在于抓住它们的"性格特点"——…...

独立开发者如何利用 Taotoken 模型广场低成本试错选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 模型广场低成本试错选型 对于资源有限的独立开发者或小型团队而言,在产品开发初期选择合…...
基于ESP32与NeoPixel的智能灯光控制系统:从硬件选型到Web控制全解析
1. 项目概述:打造你的专属智能光效中心几年前,我为了给家里的节日装饰增添点科技感,琢磨着怎么让一串普通的LED灯带变得“听话”——能从手机或电脑上随意切换颜色和动画。当时市面上成品的智能灯带要么价格不菲,要么功能受限&…...

在自动化部署流程中集成 TaoToken 大模型 API 调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化部署流程中集成 TaoToken 大模型 API 调用 将大模型能力融入自动化部署流程,正成为提升 DevOps 效率的新范式。…...