深度学习训练营之数据增强
深度学习训练营
- 学习内容
- 原文链接
- 环境介绍
- 前置工作
- 设置GPU
- 加载数据
- 创建测试集
- 数据类型查看以及数据归一化
- 数据增强操作
- 使用嵌入model的方法进行数据增强
- 模型训练
- 结果可视化
- 自定义数据增强
- 查看数据增强后的图片
学习内容
在深度学习当中,由于准备数据集本身是一件十分复杂的过程,很难保障每一张图片的学习能力都很高,所以对于同一种图片采用数据增强就显得十分重要了
原文链接
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:365天深度学习训练营-第P10周:实现数据增强
- 🍖 原作者:K同学啊|接辅导、项目定制
环境介绍
- 语言环境:Python3.9.13
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2
- 数据链接:猫和狗数据
前置工作
设置GPU
import matplotlib.pyplot as plt
import numpy as np
#隐藏警告
import warnings
warnings.filterwarnings('ignore')from tensorflow.keras import layers
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")if gpus:tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpus[0]],"GPU")# 打印显卡信息,确认GPU可用
print(gpus)
加载数据
将对应的数据按照不同种类放入到不同文件夹当中,再将数据整合为animal_data
data_dir = "animal_data"
img_height = 224
img_width = 224
batch_size = 32train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.3,subset="training",seed=12,image_size=(img_height, img_width),batch_size=batch_size)
Found 3400 files belonging to 2 classes.
Using 2380 files for training.
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.3,subset="training",seed=12,image_size=(img_height, img_width),batch_size=batch_size)
Found 3400 files belonging to 2 classes.
Using 2380 files for training.
创建测试集
因为数据本身没有设置测试集,这里需要进行手动创建
val_batches = tf.data.experimental.cardinality(val_ds)
test_ds = val_ds.take(val_batches // 5)
val_ds = val_ds.skip(val_batches // 5)print('Number of validation batches: %d' % tf.data.experimental.cardinality(val_ds))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_ds))
运行结构如下
Number of validation batches: 60
Number of test batches: 15
预测的batches和测试batches分别为60和15
数据类型查看以及数据归一化
class_names = train_ds.class_names
print(class_names)
['cat', 'dog']
进行数据归一化操作
AUTOTUNE = tf.data.AUTOTUNEdef preprocess_image(image,label):return (image/255.0,label)# 归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
test_ds = test_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
查看数据集
plt.figure(figsize=(15, 10)) # 图形的宽为15高为10for images, labels in train_ds.take(1):for i in range(8):ax = plt.subplot(5, 8, i + 1) plt.imshow(images[i])plt.title(class_names[labels[i]])plt.axis("off")

数据增强操作
data_augmentation = tf.keras.Sequential([tf.keras.layers.experimental.preprocessing.RandomFlip("horizontal_and_vertical"),tf.keras.layers.experimental.preprocessing.RandomRotation(0.2),
])
#进行随机的水平翻转和垂直翻转
# Add the image to a batch.
image = tf.expand_dims(images[i], 0)
plt.figure(figsize=(8, 8))
for i in range(9):augmented_image = data_augmentation(image)ax = plt.subplot(3, 3, i + 1)plt.imshow(augmented_image[0])plt.axis("off")

使用嵌入model的方法进行数据增强
model = tf.keras.Sequential([data_augmentation,layers.Conv2D(16, 3, padding='same', activation='relu'),layers.MaxPooling2D(),
])
- 这样的操作可以得到
GPU的加速
模型训练
模型开始训练之前都需要进行这个模型的调整
model = tf.keras.Sequential([layers.Conv2D(16, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(32, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(64, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Flatten(),layers.Dense(128, activation='relu'),layers.Dense(len(class_names))
])
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
开始进行正式的训练
epochs=20
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
75/75 [==============================] - 35s 462ms/step - loss: 2.0268e-05 - accuracy: 1.0000 - val_loss: 1.8425e-05 - val_accuracy: 1.0000
Epoch 2/20
75/75 [==============================] - 34s 461ms/step - loss: 1.7937e-05 - accuracy: 1.0000 - val_loss: 1.6272e-05 - val_accuracy: 1.0000
Epoch 3/20
75/75 [==============================] - 35s 461ms/step - loss: 1.5871e-05 - accuracy: 1.0000 - val_loss: 1.4373e-05 - val_accuracy: 1.0000
Epoch 4/20
75/75 [==============================] - 34s 450ms/step - loss: 1.4039e-05 - accuracy: 1.0000 - val_loss: 1.2682e-05 - val_accuracy: 1.0000
Epoch 5/20
75/75 [==============================] - 34s 450ms/step - loss: 1.2429e-05 - accuracy: 1.0000 - val_loss: 1.1195e-05 - val_accuracy: 1.0000
Epoch 6/20
75/75 [==============================] - 35s 462ms/step - loss: 1.1014e-05 - accuracy: 1.0000 - val_loss: 9.8961e-06 - val_accuracy: 1.0000
Epoch 7/20
75/75 [==============================] - 34s 450ms/step - loss: 9.7220e-06 - accuracy: 1.0000 - val_loss: 8.6961e-06 - val_accuracy: 1.0000
Epoch 8/20
75/75 [==============================] - 34s 455ms/step - loss: 8.5416e-06 - accuracy: 1.0000 - val_loss: 7.6252e-06 - val_accuracy: 1.0000
Epoch 9/20
75/75 [==============================] - 34s 459ms/step - loss: 7.5130e-06 - accuracy: 1.0000 - val_loss: 6.7169e-06 - val_accuracy: 1.0000
Epoch 10/20
75/75 [==============================] - 34s 460ms/step - loss: 6.6338e-06 - accuracy: 1.0000 - val_loss: 5.9490e-06 - val_accuracy: 1.0000
Epoch 11/20
75/75 [==============================] - 34s 457ms/step - loss: 5.8835e-06 - accuracy: 1.0000 - val_loss: 5.2946e-06 - val_accuracy: 1.0000
Epoch 12/20
75/75 [==============================] - 34s 456ms/step - loss: 5.2507e-06 - accuracy: 1.0000 - val_loss: 4.7294e-06 - val_accuracy: 1.0000
Epoch 13/20
...
Epoch 19/20
75/75 [==============================] - 34s 449ms/step - loss: 2.5978e-06 - accuracy: 1.0000 - val_loss: 2.3737e-06 - val_accuracy: 1.0000
Epoch 20/20
75/75 [==============================] - 34s 449ms/step - loss: 2.3849e-06 - accuracy: 1.0000 - val_loss: 2.1841e-06 - val_accuracy: 1.0000
这里比较奇怪的是训练的结果准确性很高,loss的值都是很小很小的,和原本博主的相应的内容是不一样的,我觉得很大的可能应该是首先这个数据的内容很大,原本只有几百张图片,但是这里一共有3400张图片,再加上模型训练的增强方式比较简单,导致在结果上面训练看起来很好
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
15/15 [==============================] - 1s 83ms/step - loss: 1.9960e-06 - accuracy: 1.0000
Accuracy 1.0
结果可视化
自定义数据增强
这里主要是可以更改随机数种子的大小
import random
# 这是大家可以自由发挥的一个地方
def aug_img(image):seed = (random.randint(5,10), 0)#设立随机数种植,randint是指在0到9之间进行一个数据的增强# 随机改变图像对比度stateless_random_brightness = tf.image.stateless_random_contrast(image, lower=0.1, upper=1.0, seed=seed)return stateless_random_brightness
查看数据增强后的图片
image = tf.expand_dims(images[3]*255, 0)
print("Min and max pixel values:", image.numpy().min(), image.numpy().max())
Min and max pixel values: 2.4591687 241.47968
plt.figure(figsize=(8, 8))
for i in range(9):augmented_image = aug_img(image)ax = plt.subplot(3, 3, i + 1)plt.imshow(augmented_image[0].numpy().astype("uint8"))plt.axis("off")

相关文章:
深度学习训练营之数据增强
深度学习训练营学习内容原文链接环境介绍前置工作设置GPU加载数据创建测试集数据类型查看以及数据归一化数据增强操作使用嵌入model的方法进行数据增强模型训练结果可视化自定义数据增强查看数据增强后的图片学习内容 在深度学习当中,由于准备数据集本身是一件十分复杂的过程,…...
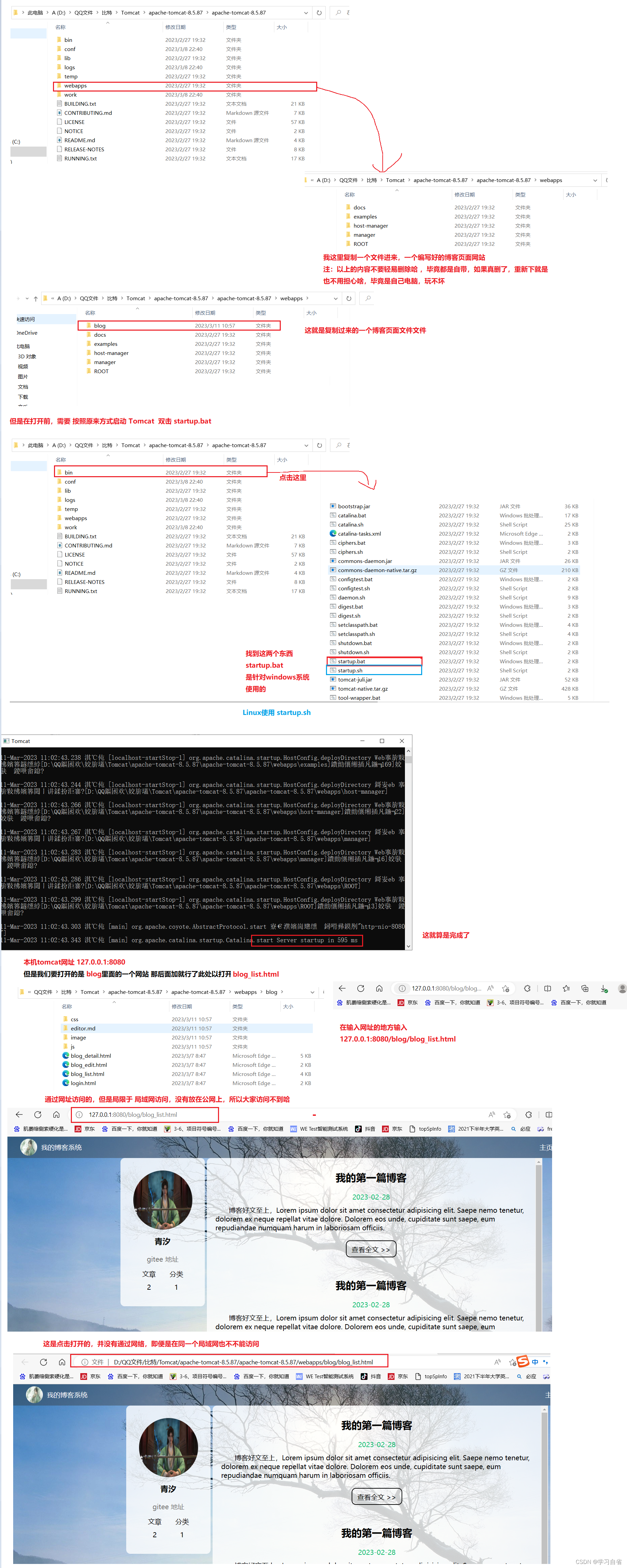
Tomcat安装及启动
日升时奋斗,日落时自省 目录 1、Tomcat下载 2、JDK安装及配置环境 3、Tomcat配置环境 4、启动Tomcat 5、部署演示 1、Tomcat下载 直接入主题,下载Tomcat 首先就是别下错了,直接找官方如何看是不是广告,或者造假 搜索Tomc…...

【专项训练】排序算法
排序算法 非比较类的排序,基本上就是放在一个数组里面,统计每个数出现的次序 最重要的排序是比较类排序! O(nlogn)的3个排序,必须要会!即:堆排序、快速排序、归并排序! 快速排序:分治 经典快排 def quickSort1(arr...

Android压测测试事件行为参数对照表
执行参数参数说明颗粒度指标基础参数--throttle <ms> 用于指定用户操作间的时延。 -s 随机数种子,用于指定伪随机数生成器的seed值,如果seed值相同,则产生的时间序列也相同。多用于重测、复现问题。 -v 指定输出日志的级别,…...

【观察】亚信科技:“飞轮效应”背后的数智化创新“延长线”
著名管理学家吉姆柯林斯在《从优秀到卓越》一书中提出“飞轮效应”,它指的是为了使静止的飞轮转动起来,一开始必须使很大的力气,每转一圈都很费力,但达到某一临界点后,飞轮的重力和冲力就会成为推动力的一部分…...

QT编程从入门到精通之十四:“第五章:Qt GUI应用程序设计”之“5.1 UI文件设计与运行机制”之“5.1.1 项目文件组成”
目录 第五章:Qt GUI应用程序设计 5.1 UI文件设计与运行机制 5.1.1 项目文件组成 第五章:Qt GUI应用程序设计...
730. 机器人跳跃问题)
(二分)730. 机器人跳跃问题
目录 题目链接 一些话 切入点 流程 套路 ac代码 题目链接 AcWing 730. 机器人跳跃问题 - AcWing 一些话 // 向上取整 mid的表示要写成l r 1 >> 1即可,向下取整 mid l r >> 1 // 这里我用了浮点二分,mid (l r) / 2,最…...
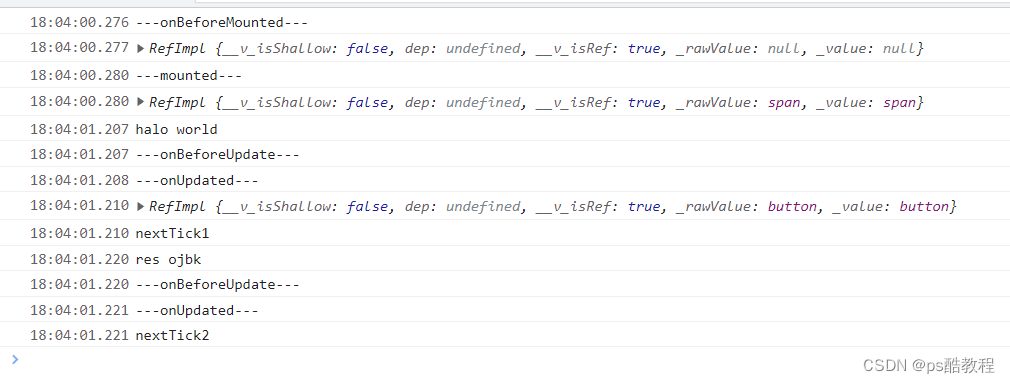
vue3使用nextTick
发现nextTick必须放在修改一个响应式数据之后,才会在onUpdated之后被调用,如果nextTick是放在所有对响应式数据修改之前,则nextTick里面的回调函数会在onBeforeUpdate方法执行前就被调用了。可是nextTick必须等到onUpdated执行完成之后执行&a…...

传统图像处理之颜色特征
博主简介 博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,…...

GPS问题调试—MobileLog中有关GPS关键LOG的释义
GPS问题调试—MobileLog中有关GPS关键LOG的释义 [DESCRIPTION] 在mobile log中,有很多GPS相关的log出现在main log和kernel log、properties文件中,他们的意思是什么,通过这篇文档进行总结,以便在处理GPS 问题时,能够根据这些log快速的收敛问题。 [SOLUTION] 特别先提醒…...

【企业管理】你真的理解向下管理吗?
导读:拜读陈老师一篇文章《不会向下负责,你凭什么做管理者?》,引发不少共鸣,“很多管理者有一种错误的观念,认为管理是向下管理,向上负责。其实应该反过来,是向上管理,向…...

Centos7 硬盘挂载流程
1、添加硬盘到Linux,添加后重启系统2、查看添加的硬盘,lsblksdb 8:16020G 0disk3、分区fdisk /dev/sdbmnw其余默认,直接回车再次查看分区情况,lsblksdb1 8:17 0 20G 0 part4、格式化mkfs -t ext4 /dev/sdb15、挂载mkdir /home/new…...

认识vite_vue3 初始化项目到打包
从0到1创建vite_vue3的项目背景效果vite介绍(对比和vuecli的区别)使用npm创建vitevitevuie3创建安装antdesignvite自动按需引入(vite亮点)请求代理proxy打包背景 vue2在使用过程中对象的响应式不好用新增属性的使用$set才能实现效…...

【Go】cron时间格式
【Go】cron时间格式 Minutes:分钟,取值范围[0-59],支持特殊字符* / , -;Hours:小时,取值范围[0-23],支持特殊字符* / , -;Day of month:每月的第几天,取值范…...
leetcode 55. 跳跃游戏
给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。 数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标。 示例 1: 输入:nums [2,3,1,1,4] 输出:true 解释:可以先跳 1 …...

Linux:文件流指针 与 文件描述符
目录一、文件描述符二、文件流指针三、缓冲区之前讲解过了IO库函数和IO接口,库函数是对系统调用接口的封装,也就是说实际上在库函数内部是通过调用系统调用接口来完成最终功能的。 库函数通过文件流指针操作文件,系统调用接口通过文件描述符操…...
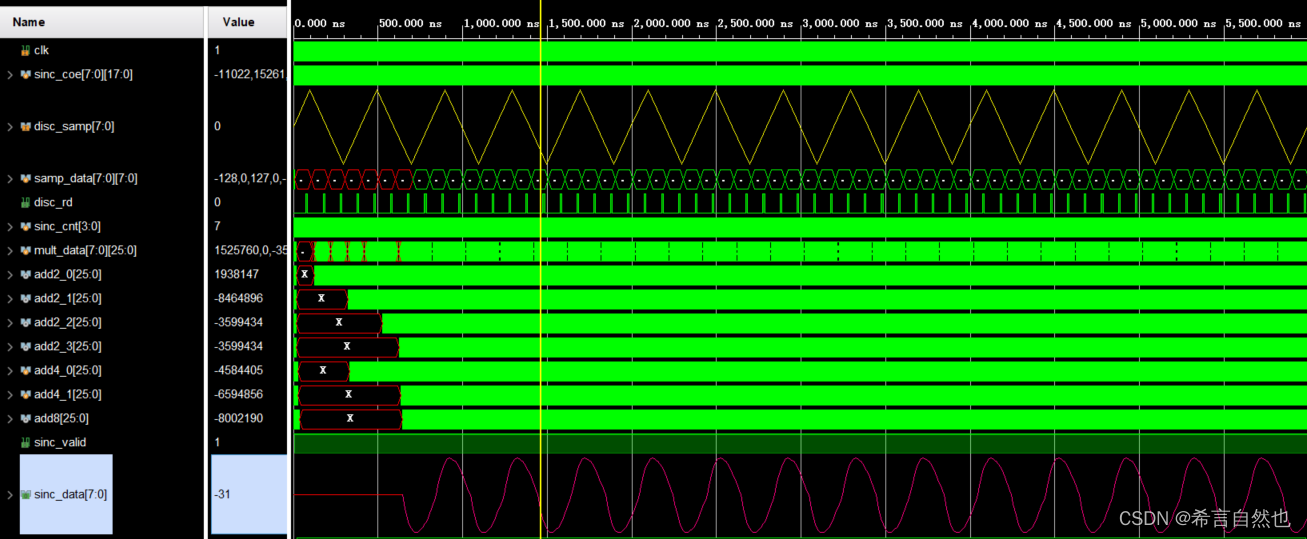
基于FPGA实现正弦插值算法
1、正弦插值的算法分析 1.1 信号在时域与频域的映射关系 在进行正弦算法分析之前,我们回顾一下《数字信号处理》课程中,对于信号在时域与频域之间的映射关系,如下图。 对于上图中的原始信号x(t),使用ADC对信号进行采样࿰…...

JavaWeb_会话技术
文章目录会话跟踪技术的概述Cookie概念Cookie工作流程Cookie基本使用发送Cookie获取CookieCookie原理分析Cookie的使用细节Cookie的存活时间Cookie存储中文SessionSession的基本使用概念工作流程Session的基本使用Session的原理分析Session的使用细节Session的钝化与活化Sessio…...

Reactor响应式流的核心机制——背压机制
响应式流是什么? 响应式流旨在为无阻塞异步流处理提供一个标准。它旨在解决处理元素流的问题——如何将元素流从发布者传递到订阅者,而不需要发布者阻塞,或订阅者有无限制的缓冲区或丢弃。 响应式流模型存在两种基本的实现机制。一种就是传统…...
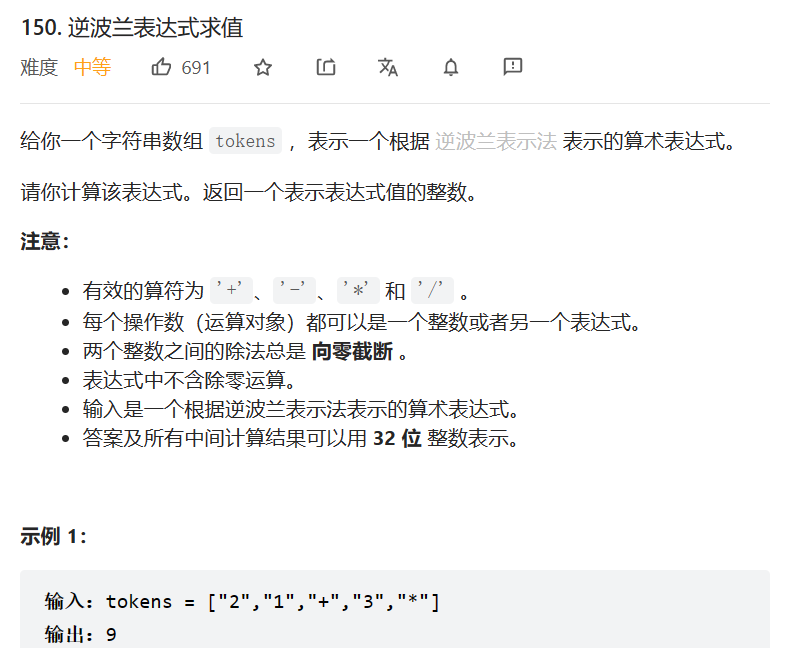
[数据结构]栈的深入学习-java实现
CSDN的各位uu们你们好,今天千泽带来了栈的深入学习,我们会简单的用代码实现一下栈, 接下来让我们一起进入栈的神奇小世界吧!0.速览文章一、栈的定义1. 栈的概念2. 栈的图解二、栈的模拟实现三.栈的经典使用场景-逆波兰表达式总结一、栈的定义 1. 栈的概念 栈:一种…...

如何高效使用Windows键盘记录工具:开源监控解决方案
如何高效使用Windows键盘记录工具:开源监控解决方案 【免费下载链接】keylogger Keylogger for Windows. 项目地址: https://gitcode.com/gh_mirrors/keylogg/keylogger Windows键盘记录工具Keylogger for Windows是一款专为系统管理员和安全研究人员设计的开…...

如何高效为离线音乐库批量下载同步歌词:LRCGET工具全解析
如何高效为离线音乐库批量下载同步歌词:LRCGET工具全解析 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否拥有大量本地音乐文件却苦于…...

快速学C语言——第19章:C语言常用开发库
第19章:C语言常用开发库 C语言的标准库提供了丰富的函数来帮助开发者完成各种常见任务。掌握这些标准库的使用可以大大提高编程效率。 ⚠️本章只给出日常开发中常用的函数! 19.1 标准输入输出库(stdio.h) stdio.h 是最常用的库&a…...

OpenAEON:从AI Agent到自主认知引擎的架构解析与实战
1. 项目概述:从“智能助手”到“自主认知引擎”的跃迁 如果你和我一样,在AI Agent领域摸爬滚打了几年,从早期的简单聊天机器人框架,到后来的工具调用(Function Calling)和RAG(检索增强生成&…...

ARM PMU性能监控单元架构与PMEVTYPER寄存器详解
1. ARM PMU性能监控单元架构解析性能监控单元(Performance Monitoring Unit, PMU)是现代ARM处理器中用于硬件级性能分析的关键组件。作为芯片上的专用硬件计数器,PMU能够在不显著影响程序执行效率的前提下,实时捕获各类微架构事件。与软件层面的性能分析…...

让你的自定义结构体也能被qDebug优雅打印:Qt运算符重载的妙用与避坑指南
让自定义结构体与qDebug完美融合:Qt运算符重载实战解析 在Qt开发中,调试信息输出是日常开发不可或缺的环节。当项目规模扩大,自定义数据结构变得复杂时,如何优雅地输出这些结构体的调试信息就成了开发者面临的现实挑战。本文将深入…...

感应照明技术:从工业到家用,一场技术降维的工程冒险
1. 项目概述:当感应照明技术走进寻常百姓家最近在整理一些老旧的行业资料时,翻到了2014年的一则新闻,讲的是当时一家初创公司“Finally Light Bulb Company”宣布要推出一款售价低于10美元的感应灯泡,用来替代传统的白炽灯。这让我…...

AI智能体如何利用德国铁路实时数据与历史预测优化出行决策
1. 项目概述:一个为AI智能体打造的德国铁路工具箱如果你经常在德国乘坐火车,并且对DB Navigator(德国铁路官方App)的实时信息、延误预测有需求,那么你很可能已经习惯了在出行前反复刷新App,手动计算换乘时间…...

百度网盘直链解析:打破速度限制的智能解决方案
百度网盘直链解析:打破速度限制的智能解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾经面对百度网盘的缓慢下载速度感到无奈?等待一个…...

Standard计划突然限速?揭秘MJ v6.1后台配额算法变更,3步绕过队列延迟,今日生效
更多请点击: https://intelliparadigm.com 第一章:Standard计划限速事件的全貌还原 2024年Q2,Standard计划在多个云原生生产环境中突发性触发API速率限制(Rate Limiting),导致下游服务批量超时与重试风暴。…...