Langchain 如何工作
How does LangChain work?
LangChain是如何工作的?
Let’s consider our initial example where we upload the US Constitution PDF and pose questions to it. In this scenario, LangChain compiles the data from the PDF and organizes it.
让我们考虑我们最初的例子,我们上传美国宪法PDF并向它提出问题。在这个场景中,LangChain编译PDF中的数据并对其进行组织。
Although we’ve mentioned a PDF, the data source could be diverse: a text file, a Microsoft Word document, a YouTube transcript, a website, and more. LangChain collates this data, subsequently dividing it into manageable chunks. Once segmented, these chunks are saved in a vector store.
虽然我们已经提到了PDF,但是数据源可以是多种多样的:文本文件、Microsoft Word文档、YouTube记录、网站等等。LangChain整理这些数据,然后将其分成可管理的块。一旦分割,这些块就保存在矢量存储中。
For illustration, let’s say our PDF contains the text displayed on the left, termed the text corpus. LangChain will segment this text into smaller chunks.
举例来说,假设我们的PDF包含显示在左侧的文本,称为文本语料库。LangChain将此文本分割成更小的块。
For instance, one chunk might read “GPT is a great conversational tool …”, followed by “if you ask ChatGPT about general knowledge …”. These are distinct sections of the chunked text.
例如,一个块可能是“GPT是一个伟大的会话工具……”,然后是“如果你问ChatGPT关于一般知识……”。这些是分块文本的不同部分。
Our large language model (LLM) will then transform this chunked text into embeddings.
然后,我们的大型语言模型(LLM)将把这些分块文本转换为嵌入。
Embeddings are simply numerical representations of the data. The text chunk is rendered into a numerical vector, which is then stored in a vector store/database.
嵌入只是数据的数字表示。文本块被渲染成一个数字向量,然后存储在一个向量存储库/数据库中。
You might question the necessity of this conversion. Data is multifaceted, encompassing text, images, audio, and video. To assign meaningful interpretations to such diverse content forms, they must be translated into numerical vectors.
你可能会质疑这种转换的必要性。数据是多方面的,包括文本、图像、音频和视频。为了给如此多样的内容形式赋予有意义的解释,它们必须被转换成数字载体。
This translation from chunks to embeddings employs various machine learning algorithms. These algorithms categorize the data, and the resultant classifications are saved in the vector database.
这种从块到嵌入的转换使用了各种机器学习算法。这些算法对数据进行分类,并将分类结果保存在向量数据库中。
Querying the Vector Store and Generating a Completion with a LLM.
使用LLM查询Vector Store和生成补全。
When a user poses a question, this inquiry is also converted into an embedding, anumerical vector representation. This vector is juxtaposed with existing vectors in the database to perform a similarity search. The database identifies vectors most akin to the query and retrieves the chunks from which these vectors originated.
当用户提出问题时,该查询也被转换为嵌入的数值向量表示。该向量与数据库中的现有向量并置以执行相似性搜索。数据库识别与查询最相似的向量,并检索这些向量源自的块。
With existing vectors in the database to perform a similarity search. The database identifies vectors most akin to the query and retrieves the chunks from which these vectors originated.
与数据库中已有的向量执行相似度搜索。数据库识别与查询最相似的向量,并检索这些向量源自的块。
After extracting the pertinent chunks taht generated those vectors. We generate a completion with our LLM and subsequently produce a response.
在提取生成这些向量的相关块之后。我们用LLM生成一个完成,然后生成一个响应。
In all, this turns your document into a mini Google search engine, enabling query-based searches.
总之,这将把您的文档变成一个迷你的Google搜索引擎,支持基于查询的搜索。
Overall, LangChain can be harnessed to craft automated apps or workflows.
总的来说,LangChain可以用来制作自动化的应用程序或工作流。
For instance, one could design a YouTube script generator or a medium article script generator, we’ll build one in the next chapter. LangChain can also be employed as a web research tool, capable of summarizing voluminous texts such as documents, articles, research papers, and event books. Moreover, LangChain can be utilized to fashion question-answering systems. By inputting our documents, PDFs, or books, we can solicit answers to our queries.
例如,一个人可以设计一个YouTube脚本生成器或一个中等文章脚本生成器,我们将在下一章中构建一个。LangChain也可以作为一个网络研究工具,能够总结大量的文本,如文件、文章、研究论文和活动记录。此外,还可以利用LangChain来设计问答系统。通过输入我们的文档、pdf文件或书籍,我们可以请求对我们问题的答案。
Envision a scenario where one is perusing legal documents, typically necessitating a lawyer’s expertise. Now, one can input a legal document or even a medical research paper into a LangChain app and pose questions to derive insights.
设想这样一个场景:一个人正在仔细阅读法律文件,通常需要律师的专业知识。现在,人们可以在LangChain应用程序中输入一份法律文件,甚至是一篇医学研究论文,并提出问题以获得见解。
相关文章:

Langchain 如何工作
How does LangChain work? LangChain是如何工作的? Let’s consider our initial example where we upload the US Constitution PDF and pose questions to it. In this scenario, LangChain compiles the data from the PDF and organizes it. 让我们考虑我们最初的例子…...
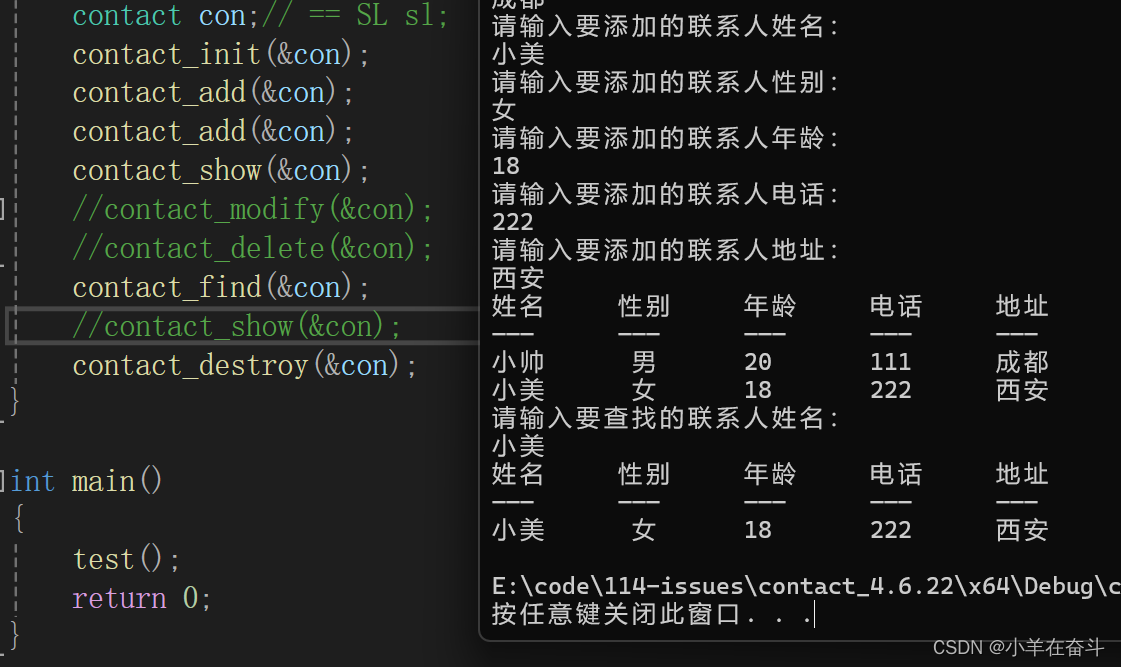
【数据结构】顺序表实操——通讯录项目
Hi~!这里是奋斗的小羊,很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~~ 💥💥个人主页:奋斗的小羊 💥💥所属专栏:C语言 🚀本系列文章为个人学习…...
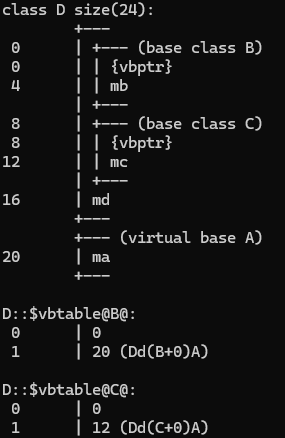
C++继承与多态—多重继承的那些坑该怎么填
课程总目录 文章目录 一、虚基类和虚继承二、菱形继承的问题 一、虚基类和虚继承 虚基类:被虚继承的类,就称为虚基类 virtual作用: virtual修饰成员方法是虚函数可以修饰继承方式,是虚继承,被虚继承的类就称为虚基类…...
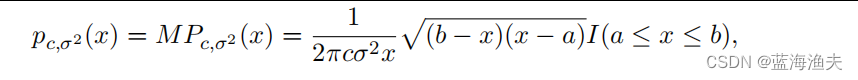
论文阅读:基于谱分析的全新早停策略
来自JMLR的一篇论文,https://www.jmlr.org/papers/volume24/21-1441/21-1441.pdf 这篇文章试图通过分析模型权重矩阵的频谱来解释模型,并在此基础上提出了一种用于早停的频谱标准。 1,分类难度对权重矩阵谱的影响 1.1 相关研究 在最近针对…...
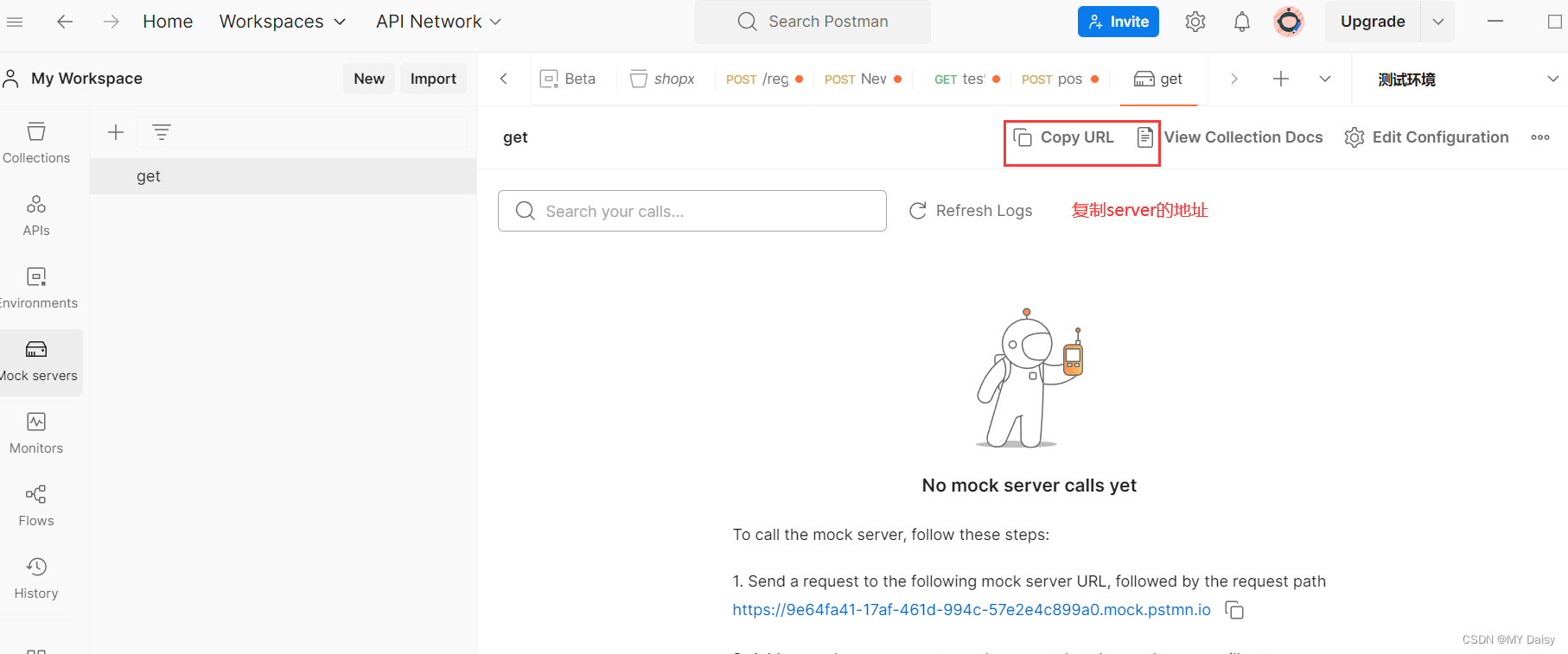
1.接口测试-postman学习
目录 1.接口相关概念2.接口测试流程3.postman基本使用-创建请求(1)环境(2)新建项目集合Collections(3)新建collection(4)新建模块(5)构建请求请求URLheader设…...
)
2024年码蹄杯本科院校赛道初赛(省赛)
赛时所写题,简单写一下思路,qwq 第一题: 输出严格次小值, //#pragma GCC optimize(2)#include <iostream> #include <cstring> #include <algorithm> #include <vector> #include <queue> #incl…...

PHP蜜语翻译器在线文字转码解码源码
源码介绍 PHP蜜语翻译器在线文字转码解码源码 文字加密通话、一键转换、蜜语密码 无需数据库,可以将文字、字母、数字、代码、表情、标点符号等内容转换成新的文字形式,通过简单的文字以不同的排列顺序来表达不同的内容!支持在线加密解密 有多种加密展示…...

安卓浏览器区分启动、打开、分享
搞了几个钟头,终于全兼容了,分享有2种类型! void getDataFromIntent(Intent intent) {if (intent.getAction().equals(Intent.ACTION_VIEW)) {urln intent.getDataString();if (urln ! null) {if (urln.contains("\n"))urln url…...
C/C++ 数组负数下标
一 概述 在 C 中,数组是一块连续的内存空间,数组的下标通常用来定位这段内存中的特定元素。下标通常从 0 开始,最大到数组长度减 1。例如,一个有 10 个元素的数组,其有效下标范围是从 0 到 9。 当你尝试使用负数下标来…...
)
钓鱼网站开发原理(社会工程学)
钓鱼网站开发原理(社会工程学) 一、课程简介1、课程大纲2、课程目标3、知识储备 二、钓鱼网站简介1、什么是钓鱼网站2、开发&原理 三、PHP环境搭建1、简介2、自动安装MySQL/apache/PHP3、安装navicat 四、PDO表单入库案例1、语法2、显示登录表单3、入…...

如何优雅地使用 console.log 打印数组或对象
一、背景 使用 console.log 在控制台中打印数组或者对象时,很多时候它们的字段都是默认关闭的,需要手动一个个的点开,非常不直观且麻烦。 二、解决方案 使用 JSON.stringify() 的第三个参数 我们来看一下官方对于 JSON.stringify 的介绍 三、…...

模式分解的概念(下)-无损连接分解的与保持函数依赖分解的定义和判断、损失分解
一、无损连接分解 1、定义 2、检验一个分解是否是无损连接分解的算法 输入与输出 输入: 关系模式R(U,F),F是最小函数依赖集 R上的一个分解 输出: 判断分解是否为无损连接分解 (1&#x…...

vue3父组件获取子组件的实例对象
一,ref 在父组件的模板里,对子组件的标签定义ref属性,并且设置属性值,在方法里获取ref()获取实例对象。 父组件: <template><div ><div>我是父组件</div><<SonCom ref"sonComRe…...

主流框架选择:React、Angular、Vue的详细比较
目前前端小伙伴经常使用三种广泛使用的开发框架:React、Angular、Vue - 来设计网站 Reactjs:效率和多功能性而闻名 Angularjs:创建复杂的应用程序提供了完整的解决方案,紧凑且易于使用的框架 Vuejs:注重灵活性和可重用…...

交易者的意义是什么?
按照阿德勒的说法:人生的意义就是为社会创造价值,推动整个人类社会的发展进步。 我认同且秉持这种观点。 而在交易中,你是否直接或者间接为社会做贡献了呢?这个还真不好说。 但是做为职业交易者,你的存在价值&#…...

io_uring
转:[译] Linux 异步 I_O 框架 io_uring:基本原理、程序示例与性能压测(2020) 新一代异步IO框架 io_uring | 得物技术 干翻 nio ,王炸 io_uring 来了 !!(图解史上最全&a…...

构建高并发Web应用:基于Gunicorn、Flask和Docker的部署指南
目录 一 理解基础组件 什么是Flask? 什么是Gunicorn? 什么是Docker? 二 环境准备 三 构建Flask应用 创建项目结构 编写Flask应用 app/views.py 四 使用Gunicorn部署Flask应用 配置Gunicorn Gunicorn配置文件 五 使用Docker进行容器化部署 编写Dockerfile 构建…...

【Ruby简单脚本02】双色球系统
# frozen_string_literal: true require date # 生成中奖号码的工具 # 红球 1-32 篮球 1-15 def create_num nums [] 6.times do while true num rand(1..32) unless nums.include?(num) nums << num break end end end blue rand(1..15) nums…...

Netty ByteBuf 使用详解
文章目录 1.概述2. ByteBuf 分类3. 代码实例3.1 常用方法3.1.1 创建ByteBuf3.1.2 写入字节3.1.3 扩容3.1.2.1 扩容实例3.1.2.2 扩容计算新容量代码 3.1.4 读取字节3.1.5 标记回退3.1.6 slice3.1.7 duplicate3.1.8 CompositeByteBuf3.1.9 retain & release3.1.9.1 retain &a…...

怎样去掉卷子上的答案并打印
当面对试卷答案的问题时,一个高效而简单的方法是利用图片编辑软件中的“消除笔”功能。这种方法要求我们首先将试卷拍摄成照片,然后利用该功能轻松擦除答案。尽管这一方法可能需要些许时间和耐心,但它确实为我们提供了一个可行的解决途径。 然…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...
之(六) ——通用对象池总结(核心))
怎么开发一个网络协议模块(C语言框架)之(六) ——通用对象池总结(核心)
+---------------------------+ | operEntryTbl[] | ← 操作对象池 (对象数组) +---------------------------+ | 0 | 1 | 2 | ... | N-1 | +---------------------------+↓ 初始化时全部加入 +------------------------+ +-------------------------+ | …...