Netty ByteBuf 使用详解
文章目录
- 1.概述
- 2. ByteBuf 分类
- 3. 代码实例
- 3.1 常用方法
- 3.1.1 创建ByteBuf
- 3.1.2 写入字节
- 3.1.3 扩容
- 3.1.2.1 扩容实例
- 3.1.2.2 扩容计算新容量代码
- 3.1.4 读取字节
- 3.1.5 标记回退
- 3.1.6 slice
- 3.1.7 duplicate
- 3.1.8 CompositeByteBuf
- 3.1.9 retain & release
- 3.1.9.1 retain & release
- 3.1.9.2 Netty TailContext release
- 3.2 完整实例
- 4. 参考文献
1.概述
ByteBuf 对字节进行操作
ByteBuf 四个基本属性:
- readerIndex: 读指针,字节数组,读到哪了
- writerIndex: 写指针,字节数组,写到哪了
- maxCapacity:最大容量,字节数组最大容量
- markedReaderIndex:标记读指针,
resetReaderIndex方法可以把readerIndex修改为markedReaderIndex,回退重新读数据 - markedWriterIndex: 标记写指针,
resetReaderIndex方法可以把writerIndex修改为markedWriterIndex,回退重新写数据
public abstract class AbstractByteBuf extends ByteBuf {int readerIndex;int writerIndex;private int markedReaderIndex;private int markedWriterIndex;private int maxCapacity;
}
2. ByteBuf 分类
ByteBuf 分为
- 直接内存或堆内存(Heap/Direct)
- 池化 和 非池化(Pooled/Unpooled)和 操作方式是否安全 (Unsafe/非 Unsafe)
ByteBuf 创建可以基于直接内存或堆内存
- 直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用
- 直接内存对 GC 压力小,因为这部分内存不受 JVM 垃圾回收的管理,但也要注意及时主动释放
ByteBuf 池化 和 非池化
- 没有池化,则每次都得创建新的 ByteBuf 实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 GC 压力
- 有了池化,则可以重用池中 ByteBuf 实例,并且采用了与 jemalloc 类似的内存分配算法提升分配效率
- 高并发时,池化功能更节约内存,减少内存溢出的可能
ByteBuf 操作方式是否安全 (Unsafe/非 Unsafe)
- Unsafe:表示每次调用 JDK 的 Unsafe 对象操作物理内存,依赖 offset + index 的方式操作数据
- 非 Unsafe:则不需要依赖 JDK 的 Unsafe 对象,直接通过数组下标的方式操作数据
3. 代码实例
3.1 常用方法
3.1.1 创建ByteBuf
创建ByteBuf , 默认都是池化的
// 堆内存的ByteBufByteBuf bufferHeap = ByteBufAllocator.DEFAULT.heapBuffer();// 直接内存的ByteBufByteBuf bufferDirect = ByteBufAllocator.DEFAULT.directBuffer();System.out.println(bufferHeap);System.out.println(bufferDirect);

3.1.2 写入字节
bufferHeap.writeBytes(new byte[]{1, 2, 3, 4});bufferDirect.writeBytes(new byte[]{1, 2, 3, 4});print("第一次写入", bufferHeap);print("第一次写入", bufferDirect);

3.1.3 扩容
3.1.2.1 扩容实例
- 默认 256
- 扩容加一倍
- 到了4194304,每次+4194304
for (int i = 0; i < 100; i++) {bufferHeap.writeBytes(new byte[]{1, 2, 3, 4});bufferDirect.writeBytes(new byte[]{1, 2, 3, 4});}print("批量写入&扩容", bufferHeap);print("批量写入&扩容", bufferDirect);

3.1.2.2 扩容计算新容量代码
public int calculateNewCapacity(int minNewCapacity, int maxCapacity) {ObjectUtil.checkPositiveOrZero(minNewCapacity, "minNewCapacity");if (minNewCapacity > maxCapacity) {throw new IllegalArgumentException(String.format("minNewCapacity: %d (expected: not greater than maxCapacity(%d)", minNewCapacity, maxCapacity));} else {int threshold = 4194304;if (minNewCapacity == 4194304) {return 4194304;} else {int newCapacity;if (minNewCapacity > 4194304) {newCapacity = minNewCapacity / 4194304 * 4194304;if (newCapacity > maxCapacity - 4194304) {newCapacity = maxCapacity;} else {newCapacity += 4194304;}return newCapacity;} else {for(newCapacity = 64; newCapacity < minNewCapacity; newCapacity <<= 1) {}return Math.min(newCapacity, maxCapacity);}}}
}
3.1.4 读取字节
readByte(bufferHeap);readByte(bufferDirect);print("读取一个字节", bufferHeap);print("读取一个字节", bufferDirect);

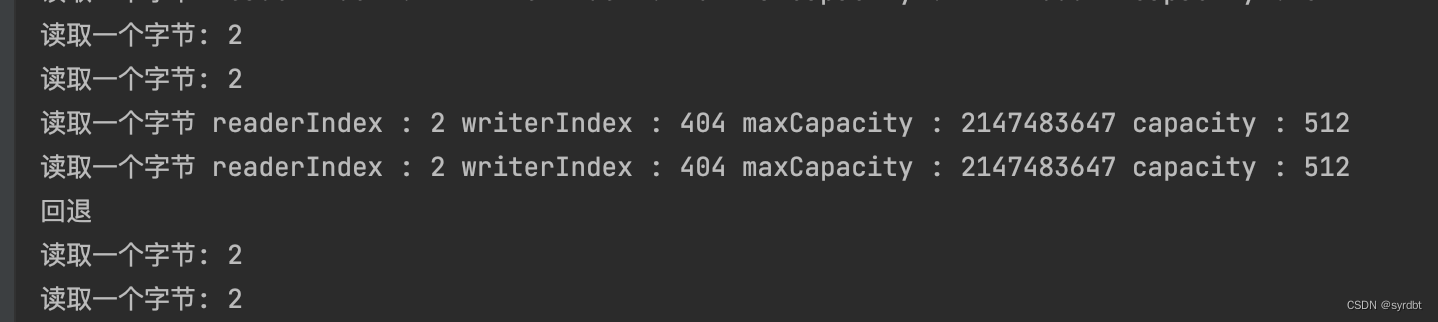
3.1.5 标记回退
bufferHeap.markReaderIndex();bufferDirect.markReaderIndex();readByte(bufferHeap);readByte(bufferDirect);print("读取一个字节", bufferHeap);print("读取一个字节", bufferDirect);System.out.println("回退");bufferHeap.resetReaderIndex();bufferDirect.resetReaderIndex();readByte(bufferHeap);readByte(bufferDirect);print("读取一个字节", bufferHeap);print("读取一个字节", bufferDirect);
3.1.6 slice
// 无参 slice 是从原始 ByteBuf 的 read index 到 write index 之间的内容进行切片// slice 和 bufferHeap 共享一块内存ByteBuf slice = bufferHeap.slice();slice.setByte(0, 9);print("slice", slice);readByte(bufferHeap);

3.1.7 duplicate
// 内存拷贝不共享内存ByteBuf duplicate = bufferHeap.duplicate();print("duplicate", duplicate);print("bufferHeap", bufferHeap);duplicate.writeBytes(new byte[]{5});print("duplicate", duplicate);print("bufferHeap", bufferHeap);

3.1.8 CompositeByteBuf
// CompositeByteBuf 是一个组合的 ByteBuf,它内部维护了一个 Component 数组,// 每个 Component 管理一个 ByteBuf,记录了这个 ByteBuf 相对于整体偏移量等信息,代表着整体中某一段的数据。// 优点,对外是一个虚拟视图,组合这些 ByteBuf 不会产生内存复制// 缺点,复杂了很多,多次操作会带来性能的损耗ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer(5);buf1.writeBytes(new byte[]{1, 2, 3, 4, 5});ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer(5);buf2.writeBytes(new byte[]{6, 7, 8, 9, 10});CompositeByteBuf buf3 = ByteBufAllocator.DEFAULT.compositeBuffer();// true 表示增加新的 ByteBuf 自动递增 write index, 否则 write index 会始终为 0buf3.addComponents(true, buf1, buf2);print("buf3", buf3);
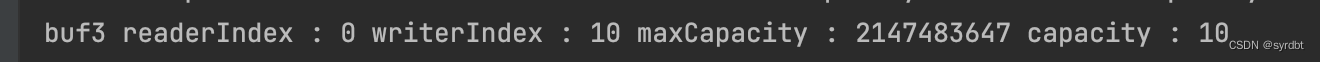
3.1.9 retain & release
3.1.9.1 retain & release
Netty 这里采用了引用计数法来控制回收内存,每个 ByteBuf 都实现了 ReferenceCounted 接口
- 每个 ByteBuf 对象的初始计数为 1
- 调用 release 方法计数减 1,如果计数为 0,ByteBuf 内存被回收
- 调用 retain 方法计数加 1,表示调用者没用完之前,其它 handler 即使调用了 release 也不会造成回收
- 当计数为 0 时,底层内存会被回收,这时即使 ByteBuf 对象还在,其各个方法均无法正常使用
bufferHeap.retain();bufferDirect.retain();bufferHeap.release();bufferDirect.release();print("release bufferHeap", bufferHeap);print("release bufferDirect", bufferDirect);bufferHeap.release();bufferDirect.release();print("release bufferHeap", bufferHeap);print("release bufferDirect", bufferDirect);bufferHeap.release();bufferDirect.release();print("release bufferHeap", bufferHeap);print("release bufferDirect", bufferDirect);

3.1.9.2 Netty TailContext release
io.netty.channel.DefaultChannelPipeline.TailContext
io.netty.channel.DefaultChannelPipeline.TailContext#channelRead
@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) {onUnhandledInboundMessage(ctx, msg);}
io.netty.channel.DefaultChannelPipeline#onUnhandledInboundMessage(ChannelHandlerContext, Object)
protected void onUnhandledInboundMessage(ChannelHandlerContext ctx, Object msg) {onUnhandledInboundMessage(msg);if (logger.isDebugEnabled()) {logger.debug("Discarded message pipeline : {}. Channel : {}.",ctx.pipeline().names(), ctx.channel());}}
3.2 完整实例
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.buffer.CompositeByteBuf;public class ByteBufStudy {public static void main(String[] args) {// 堆内存的ByteBufByteBuf bufferHeap = ByteBufAllocator.DEFAULT.heapBuffer();// 直接内存的ByteBufByteBuf bufferDirect = ByteBufAllocator.DEFAULT.directBuffer();System.out.println(bufferHeap);System.out.println(bufferDirect);bufferHeap.writeBytes(new byte[]{1, 2, 3, 4});bufferDirect.writeBytes(new byte[]{1, 2, 3, 4});print("第一次写入", bufferHeap);print("第一次写入", bufferDirect);for (int i = 0; i < 100; i++) {bufferHeap.writeBytes(new byte[]{1, 2, 3, 4});bufferDirect.writeBytes(new byte[]{1, 2, 3, 4});}print("批量写入&扩容", bufferHeap);print("批量写入&扩容", bufferDirect);readByte(bufferHeap);readByte(bufferDirect);print("读取一个字节", bufferHeap);print("读取一个字节", bufferDirect);bufferHeap.markReaderIndex();bufferDirect.markReaderIndex();readByte(bufferHeap);readByte(bufferDirect);print("读取一个字节", bufferHeap);print("读取一个字节", bufferDirect);System.out.println("回退");bufferHeap.resetReaderIndex();bufferDirect.resetReaderIndex();readByte(bufferHeap);readByte(bufferDirect);print("读取一个字节", bufferHeap);print("读取一个字节", bufferDirect);// 无参 slice 是从原始 ByteBuf 的 read index 到 write index 之间的内容进行切片// slice 和 bufferHeap 共享一块内存ByteBuf slice = bufferHeap.slice();slice.setByte(0, 9);print("slice", slice);readByte(bufferHeap);// 内存拷贝不共享内存ByteBuf duplicate = bufferHeap.duplicate();print("duplicate", duplicate);print("bufferHeap", bufferHeap);duplicate.writeBytes(new byte[]{5});print("duplicate", duplicate);print("bufferHeap", bufferHeap);// CompositeByteBuf 是一个组合的 ByteBuf,它内部维护了一个 Component 数组,// 每个 Component 管理一个 ByteBuf,记录了这个 ByteBuf 相对于整体偏移量等信息,代表着整体中某一段的数据。// 优点,对外是一个虚拟视图,组合这些 ByteBuf 不会产生内存复制// 缺点,复杂了很多,多次操作会带来性能的损耗ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer(5);buf1.writeBytes(new byte[]{1, 2, 3, 4, 5});ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer(5);buf2.writeBytes(new byte[]{6, 7, 8, 9, 10});CompositeByteBuf buf3 = ByteBufAllocator.DEFAULT.compositeBuffer();// true 表示增加新的 ByteBuf 自动递增 write index, 否则 write index 会始终为 0buf3.addComponents(true, buf1, buf2);print("buf3", buf3);bufferHeap.retain();bufferDirect.retain();bufferHeap.release();bufferDirect.release();print("release bufferHeap", bufferHeap);print("release bufferDirect", bufferDirect);bufferHeap.release();bufferDirect.release();print("release bufferHeap", bufferHeap);print("release bufferDirect", bufferDirect);bufferHeap.release();bufferDirect.release();print("release bufferHeap", bufferHeap);print("release bufferDirect", bufferDirect);}public static void print(String prefix, ByteBuf buffer) {System.out.printf("%s readerIndex : %s writerIndex : %s maxCapacity : %s capacity : %s %n",prefix, buffer.readerIndex(), buffer.writerIndex(), buffer.maxCapacity(), buffer.capacity());}public static void readByte(ByteBuf buffer) {System.out.printf("读取一个字节: %s %n", buffer.readByte());}
}
4. 参考文献
- 黑马 Netty教程
- 拉钩教育 Netty课程 若地老师

相关文章:
Netty ByteBuf 使用详解
文章目录 1.概述2. ByteBuf 分类3. 代码实例3.1 常用方法3.1.1 创建ByteBuf3.1.2 写入字节3.1.3 扩容3.1.2.1 扩容实例3.1.2.2 扩容计算新容量代码 3.1.4 读取字节3.1.5 标记回退3.1.6 slice3.1.7 duplicate3.1.8 CompositeByteBuf3.1.9 retain & release3.1.9.1 retain &a…...

怎样去掉卷子上的答案并打印
当面对试卷答案的问题时,一个高效而简单的方法是利用图片编辑软件中的“消除笔”功能。这种方法要求我们首先将试卷拍摄成照片,然后利用该功能轻松擦除答案。尽管这一方法可能需要些许时间和耐心,但它确实为我们提供了一个可行的解决途径。 然…...

海思SS928/SD3403开发笔记1——使用串口调试开发板
该板子使用串口可以调试,下面是win11 调试 该板子步骤 1、给板子接入鼠标、键盘、usb转串口 2、下载SecureCRT,并科学使用 下载地址: 链接:https://pan.baidu.com/s/11dIkZVstvHQUhE8uS1YO0Q 提取码:vinv 3、安装c…...

JSON数据操作艺术
在现代Web开发和数据交换场景中,JSON(JavaScript Object Notation)作为一种轻量级的数据交换格式,扮演着至关重要的角色。它以易于阅读的文本形式存储和传输数据对象,而这些对象的核心便是由属性名(键&…...

如何验证Rust中的字符串变量在超出作用域时自动释放内存?
讲动人的故事,写懂人的代码 在公司内部的Rust培训课上,讲师贾克强比较了 Rust、Java 和 C++ 三种编程语言在变量越过作用域时自动释放堆内存的不同特性。 Rust 通过所有权系统和借用检查,实现了内存安全和自动管理,从而避免了大部分内存泄漏。Rust 自动管理标准库中数据类…...

55.Python pip install 安装失败的一个情况Requirement already satisfied
1.问题 以前使用Pycharm 社区版开发的一个项目,今天使用PyCharm 专业版打开,原项目的虚拟环境从venv更换为.venv,然后重新安装插件。安装时,提示Requirement already satisfied: qt_material in c:\tools\python37\lib\site-packa…...

Axios进阶
目录 axios实例 axios请求配置 拦截器 请求拦截器 响应拦截器 取消请求 axios不仅仅是简单的用基础请求用法的形式向服务器请求数据,一旦请求的端口与次数变多之后,简单的请求用法会有些许麻烦。所以,axios允许我们进行创建axios实例、ax…...

C++ 丑数
描述 把只包含质因子2、3和5的数称作丑数(Ugly Number)。例如6、8都是丑数,但14不是,因为它包含质因子7。 习惯上我们把1当做是第一个丑数。求按从小到大的顺序的第 n个丑数。 数据范围:0≤𝑛≤20000≤n≤…...

小山菌_代码随想录算法训练营第三十天|122.买卖股票的最佳时机II、55. 跳跃游戏 、45.跳跃游戏II、1005.K次取反后最大化的数组和
122.买卖股票的最佳时机II 文档讲解:代码随想录.买卖股票的最佳时机II 视频讲解:贪心算法也能解决股票问题!LeetCode:122.买卖股票最佳时机II 状态:已完成 代码实现 class Solution { public:int maxProfit(vector<…...

SpringMVC系列七: 手动实现SpringMVC底层机制-上
手动实现SpringMVC底层机制 博客的技术栈分析 🛠️具体实现细节总结 🐟准备工作🍍搭建SpringMVC底层机制开发环境 实现任务阶段一🍍开发ZzwDispatcherServlet🥦说明: 编写ZzwDispatcherServlet充当原生的DispatcherSer…...
嵌入式web 服务器boa的编译和移植
编译环境:虚拟机 ubuntu 18.04 目标开发板:飞凌OKA40i-C开发板, Linux3.10 操作系统 开发板本身已经移植了boa服务器,但是在使用过程中发现POST方法传输大文件时对数据量有限制,超过1M字节就无法传输,这是…...

什么是js?特点是什么?组成部分?
Js是一种直译式脚本语言,一种动态类型,弱类型,基于原型的高级语言。 直译式:js程序运行过程中直接编译成机器语言。 脚本语言:在程序运行过程中逐行进行解释说明,不需要预编译。 动态类型:js…...

Java 面试题:如何保证集合是线程安全的? ConcurrentHashMap 如何实现高效地线程安全?
在多线程编程中,保证集合的线程安全是一个常见而又重要的问题。线程安全意味着多个线程可以同时访问集合而不会导致数据不一致或程序崩溃。在 Java 中,确保集合线程安全的方法有多种,包括使用同步包装类、锁机制以及并发集合类。 最简单的方法…...

打工人的PPT救星来了!用这款AI工具,10秒生成您的专属PPT
今天帮同事解决了一个代码合并的问题。其实问题不复杂,要把1的代码合到2的位置: 这个处理方式其实很简单,使用 “git cherry-pick hash值” 就可以。 同事直接对我赞许有加,不曾想被领导看到了,对我说了一句ÿ…...

GIT 合拼
合拼有多种方式: 1)合拼分支: git merge [source-branch] 2)合拼提交 : git cherry-pick [commit-hash] 3)合拼单个文件: git checkout [source-branch] – [file] 以上合拼,比如将分…...

利用 Python 和 AI 技术制作智能问答机器人
利用 Python 和 AI 技术制作智能问答机器人 引言 在人工智能的浪潮下,智能问答机器人成为了一种非常实用的技术。它们能够处理大量的查询,提供即时的反馈,并且可以通过机器学习技术不断优化自身的性能。本文将介绍如何使用 Python 来开发一…...
调用dll)
electron系列(一)调用dll
用electron的目的,其实很简单。就是web架构要直接使用前端电脑的资源,但是浏览器限制了使用,所以用electron来达到这个目的。其中调用dll是一个非常基本的操作。 安装 ffi-napi 和 ref-napi 包: npm install ffi-napi ref-napi main.js&…...

VUE3实现个人网站模板源码
文章目录 1.设计来源1.1 网站首页页面1.2 个人工具页面1.3 个人日志页面1.4 个人相册页面1.5 给我留言页面 2.效果和源码2.1 动态效果2.2 目录结构 源码下载万套模板,程序开发,在线开发,在线沟通 作者:xcLeigh 文章地址࿱…...

C语言 | Leetcode C语言题解之第162题寻找峰值
题目: 题解: int findPeakElement(int* nums, int numsSize) {int ls_max0;for(int i1;i<numsSize;i){if(nums[ls_max]>nums[i]);else{ls_maxi;}}return ls_max; }...

利用pickle保存和加载对象
使用 pickle.dump 保存下来的文件可以使用 pickle.load 打开和读取。以下是一个示例,展示了如何使用 pickle 模块保存和加载对象: 保存对象 import pickle# 假设有一个对象 obj obj {"key": "value"}# 将对象保存到文件 with ope…...

Anno 1800模组加载器完全掌握指南:从安装到创意开发
Anno 1800模组加载器完全掌握指南:从安装到创意开发 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com/gh_mirrors/an/an…...
表现)
Z-Image-Turbo镜像效果展示:孙珍妮LoRA在不同画幅(1:1/4:3/9:16)表现
Z-Image-Turbo镜像效果展示:孙珍妮LoRA在不同画幅(1:1/4:3/9:16)表现 1. 引言:当AI遇见明星肖像生成 你是否曾经想过,用AI技术生成自己喜欢的明星肖像?今天我们要展示的Z-Image-Turbo镜像,正是…...

5步搞定Jimeng LoRA部署:轻量文生图测试系统快速上手
5步搞定Jimeng LoRA部署:轻量文生图测试系统快速上手 1. 项目概述与核心优势 Jimeng LoRA是一款专为LoRA模型测试优化的轻量化文本生成图像系统。基于Z-Image-Turbo底座构建,它实现了单次底座加载、动态LoRA热切换的创新功能,大幅提升了模型…...

vLLM-v0.17.1镜像部署实战:从零开始搭建大模型推理服务
vLLM-v0.17.1镜像部署实战:从零开始搭建大模型推理服务 1. vLLM框架简介 vLLM是一个专为大型语言模型(LLM)设计的高性能推理和服务库,它通过创新的内存管理和批处理技术,显著提升了LLM的推理效率和服务吞吐量。这个项目最初由加州大学伯克利…...
)
Cisco Packet Tracer新手必看:5分钟搞定路由器静态路由配置(附避坑指南)
Cisco Packet Tracer静态路由配置实战:从零到精通的完整指南 刚接触网络工程的朋友们,第一次在Cisco Packet Tracer中配置静态路由时,是不是经常遇到"网络不通"的困扰?作为网络通信的基础技能,静态路由配置看…...

在AutoDL上从零部署YOLO训练环境:新手避坑指南
1. 为什么选择AutoDL部署YOLO训练环境 第一次接触目标检测任务时,我和大多数新手一样被各种环境配置问题折磨得够呛。本地显卡跑不动YOLOv5,租用云服务器又担心操作复杂,直到发现了AutoDL这个宝藏平台。它最大的优势就是把复杂的GPU实例管理简…...

Infiniband网络排错指南:从`ibstatus`异常到OpenSM日志分析,一次搞定常见连接问题
Infiniband网络排错实战:从基础诊断到高级调优的全链路指南 当40Gbps的Infiniband链路突然降速到10Gbps,或者关键节点的OpenSM服务频繁崩溃时,每个运维工程师都能体会到那种指尖发凉的焦虑。本文将带你穿越Infiniband故障迷雾,构建…...

UniHacker终极指南:免费解锁Unity全平台专业功能的完整方案
UniHacker终极指南:免费解锁Unity全平台专业功能的完整方案 【免费下载链接】UniHacker 为Windows、MacOS、Linux和Docker修补所有版本的Unity3D和UnityHub 项目地址: https://gitcode.com/GitHub_Trending/un/UniHacker 作为一名Unity开发者,你是…...

嵌入式系统调试常见问题与解决方案
嵌入式系统调试中的典型问题分析与解决策略1. 常见调试问题案例分析1.1 程序文件版本错误在嵌入式开发过程中,一个常见的低级错误是使用了错误的程序文件版本。某工程师在调试时发现单片机完全不执行程序,即使是最基本的GPIO控制也无法实现。经过以下排查…...

在六亩半,春天不是日历上的数字,而是泥土间的青草香
当城市里的春天还停留在气温起伏的天气预报里,六亩半手作文创园的春意,早已从土地深处探出头来。那是荠菜嫩芽拱开泥土的力道,是柳条抽出新绿的柔软,是孩子们蹲在田埂上、指尖沾满青草汁液的鲜活记忆。在这里,春天不是…...