【建议收藏】逻辑回归面试题,机器学习干货、重点。
.
.
.
.
.
.
.
.
.
.
.纯 干 货
.
.
.
.
.
.
.
.
.
.
.
.今天是机器学习面试题,16大块的内容,124个问题总结的第二期:逻辑回归面试题。
逻辑回归是一种用于解决分类问题的统计学习方法,尤其在二分类问题中非常常见。尽管它的名称中包含"回归"一词,但实际上逻辑回归用于估计某个事物属于某一类别的概率。
逻辑回归有一些关键的点需要深入理解:
-
二分类问题:逻辑回归通常用于解决二分类问题,其中目标是将输入数据分为两个类别,通常表示为0和1。
-
逻辑函数:逻辑回归使用逻辑函数(也称为S形函数)将线性组合的特征转换为概率。这个函数将实数映射到区间[0, 1],使其表示属于某一类别的概率。
-
参数估计:逻辑回归通过最大似然估计来确定模型的参数,以最大化数据的似然函数。通常使用梯度下降等优化算法来找到最佳参数。
-
决策边界:逻辑回归的决策边界是一个超平面,将不同类别的数据分开。在二维空间中,决策边界通常是一条曲线。
-
多类别问题:逻辑回归也可以扩展到多类别问题,如一对一(One-vs-One)和一对其余(One-vs-Rest)策略。
逻辑回归是一种简单而有效的分类方法,适用于许多应用,如垃圾邮件检测、疾病诊断、金融风险评估等。它具有直观的解释性,容易理解和实现
机器学习面试题,一共16大块的内容,124个问题的总结!
本文更新第二期,关于逻辑回归部分的面试题。
逻辑回归面试题 List
1、逻辑回归与线性回归有什么区别?
2、什么是逻辑回归的目标函数(损失函数)?常见的目标函数有哪些?
3、逻辑回归如何处理二分类问题?如何处理多分类问题?
4、什么是Sigmoid函数(逻辑函数)?它在逻辑回归中的作用是什么?
5、逻辑回归模型的参数是什么?如何训练这些参数?
6、什么是正则化在逻辑回归中的作用?L1和L2正则化有什么区别?
7、什么是特征工程,为什么它在逻辑回归中很重要?
8、逻辑回归的预测结果如何?怎样模型的系数(coefficient)?
9、什么是ROC曲线和AUC值?它们用来评估逻辑回归模型的哪些性能?
10、逻辑回归模型可能面临的问题有哪些?如何处理类不平衡问题?
11、什么是交叉验证,为什么在逻辑回归中使用它?
12、逻辑回归在实际应用中的一个例子是什么?描述一个应用场景,并如何使用逻辑回归来解决问题。
下面详细的将各个问题进行详细的阐述~~~~
01
1、逻辑回归与线性回归有什么区别?
逻辑回归(Logistic Regression)与线性回归(Linear Regression)是两种不同的回归方法,主要用于不同类型的问题,具有不同的模型和目标。
它们之间的主要区别,这里通过概念和公式进行对比:
1、应用领域:
-
线性回归通常用于解决回归问题,其中目标是预测一个连续数值输出(如房价、销售量等)。线性回归试图建立一个线性关系,以最小化观测值与模型预测值之间的差异。
-
逻辑回归通常用于解决分类问题,其中目标是将输入数据分为两个或多个类别(如二分类问题中的是/否、多分类问题中的类别1、类别2等)。逻辑回归使用S形函数(逻辑函数)将线性组合的输入映射到概率输出。
2、输出:
-
线性回归的输出是一个连续的数值,可以是任意实数。线性回归模型的公式是:
-
逻辑回归的输出是一个介于 0 和 1 之间的概率值,表示观测数据属于某个类别的概率。逻辑回归使用逻辑函数(也称为 sigmoid 函数)来计算概率,其公式是:
3、模型形式:
-
线性回归建立了一个线性关系,其中模型参数 表示输入特征与输出之间的线性关系。目标是最小化预测值与实际值之间的平方误差。
-
逻辑回归使用逻辑函数对线性组合进行转换,使其落在0到1之间,代表了属于某一类的概率。模型参数 表示对数概率与输入特征之间的线性关系。目标是最大化似然函数,以使观测数据在给定参数下的概率最大化。
4、目标:
-
线性回归的目标是找到一条最佳拟合线,以最小化实际观测值与预测值之间的误差平方和。
-
逻辑回归的目标是找到最佳参数,以最大化观测数据属于正类别或负类别的概率,从而能够进行分类。
线性回归和逻辑回归是两种不同类型的回归模型,用于不同类型的问题。线性回归用于预测连续数值输出,而逻辑回归用于进行二分类或多分类任务,其中输出是概率值。逻辑回归的输出受到逻辑函数的约束,使其适合处理分类问题。
021
2、什么是逻辑回归的目标函数(损失函数)?常见的目标函数有哪些?
逻辑回归的目标函数,通常也称为损失函数或代价函数,用于衡量模型的预测与实际观测值之间的差异。
逻辑回归通常用于二分类问题,其目标是最大化观测数据属于正类别或负类别的概率,从而能够进行分类。
逻辑回归的目标函数通常使用交叉熵损失函数(Cross-Entropy Loss Function)或对数损失函数(Log Loss Function),这两者通常是等价的。
逻辑回归的交叉熵损失函数:
对于二分类问题,逻辑回归的损失函数可以表示为以下形式:
其中:
-
是损失函数。
-
是训练样本数量。
-
是第 个样本的实际类别标签(0或1)。
-
是模型预测第 个样本为正类别的概率。
-
是模型的参数(权重和偏置项)。
这个损失函数的目标是最小化观测数据的负对数似然(negative log-likelihood),从而最大化观测数据属于正类别或负类别的概率。
对于多分类问题,逻辑回归的损失函数可以使用多分类的交叉熵损失函数,如softmax交叉熵损失函数。
其他常见的损失函数包括均方误差损失 和平均绝对误差损失,但这些损失函数通常用于回归问题,而不是分类问题。
在分类问题中,逻辑回归的交叉熵损失函数是最常见和推荐的选择,因为它能够测量分类模型的概率输出与实际标签之间的差异,并且具有良好的数学性质。
03
3、逻辑回归如何处理二分类问题?如何处理多分类问题?
逻辑回归(Logistic Regression)是一种广泛用于处理分类问题的统计学习方法。它可以用于二分类问题和多分类问题。
处理二分类问题
对于二分类问题,逻辑回归的目标是将输入数据分为两个类别,通常表示为"0"和"1"(或"负类"和"正类")。逻辑回归通过使用逻辑函数(也称为sigmoid函数)将线性组合的输入映射到概率输出,并根据概率来进行分类。
处理二分类问题的步骤:
1、数据准备:获取带有标签的训练数据集,其中每个样本都有一个二元类别标签,通常为0或1。
2、特征工程:根据问题的性质选择和提取适当的特征,以作为模型的输入。
3、模型训练:使用逻辑回归模型,建立一个线性组合的模型,然后通过逻辑函数将其映射到[0, 1]范围内的概率。训练模型时,通过最大化似然函数来拟合模型参数。
4、预测和分类:对于新的未标记样本,使用训练好的模型进行预测。通常,模型会输出一个概率值,然后可以根据阈值(通常为0.5)将概率转化为二元类别,例如,如果概率大于阈值,则将样本分为正类别(1),否则分为负类别(0)。
5、评估模型性能:使用适当的性能指标(如准确率、精确度、召回率、F1分数、ROC曲线和AUC)来评估模型的性能。
处理多分类问题
逻辑回归也可以用于多分类问题,其中目标是将输入数据分为三个或更多类别。
有两种主要的方法来处理多分类问题:一对多(One-vs-Rest,OvR)和Softmax回归。
1、一对多(OvR)方法:也称为一对剩余方法。对于有K个类别的问题,使用K个二分类逻辑回归模型。每个模型将一个类别作为正类别,而将其他K-1个类别视为负类别。当需要对新样本进行分类时,每个模型都会产生一个概率,最后选择具有最高概率的类别作为预测结果。
2、Softmax回归:也称为多类别逻辑回归或多项式回归。Softmax回归将多个类别之间的关系建模为一个多类别概率分布。它使用Softmax函数来将线性组合的输入映射到K个类别的概率分布,其中K是类别的数量。训练Softmax回归模型时,通常使用交叉熵损失函数。
处理多分类问题时,通常选择Softmax回归方法,因为它可以直接建模多类别之间的关系,并且在一次训练中学习所有类别的参数。一对多方法可能需要更多的模型和更多的训练时间,但在某些情况下也可以有效地处理多分类问题。
无论是处理二分类问题还是多分类问题,逻辑回归都是一个强大且常用的分类算法,可以根据问题的性质和数据集的大小来选择适当的方法。
04
4、什么是Sigmoid函数(逻辑函数)?它在逻辑回归中的作用是什么?
Sigmoid函数,也称为逻辑函数(Logistic Function),是一种常用的S型函数,具有如下的数学形式:
其中, 表示Sigmoid函数, 是自然对数的底数(约等于2.71828), 是实数输入。
Sigmoid函数的作用在于将任何实数输入映射到一个介于0和1之间的概率值。这个映射特性使Sigmoid函数在逻辑回归中非常有用,因为它可以用来建立一个线性模型的输出,该输出表示属于某一类别的概率。
在逻辑回归中,Sigmoid函数的作用如下:
1、将线性组合转化为概率:逻辑回归模型通过将输入特征的线性组合()传递给Sigmoid函数,将其转化为一个介于0和1之间的概率值。这个概率表示样本属于正类别的概率。
2、分类决策:通常,逻辑回归模型会根据Sigmoid函数的输出来做出分类决策。如果概率大于或等于一个阈值(通常是0.5),则样本被分类为正类别;如果概率小于阈值,则样本被分类为负类别。
3、平滑性:Sigmoid函数是光滑的S型曲线,具有连续导数。这使得逻辑回归模型易于优化,可以使用梯度下降等优化算法来找到最佳参数。
4、输出的概率解释:Sigmoid函数的输出可以被解释为一个事件的概率。这使得逻辑回归模型可以提供与概率相关的信息,而不仅仅是类别的预测结果。
Sigmoid函数在逻辑回归中的作用是将线性组合的输入映射到一个概率值,用于表示样本属于正类别的概率,并用于分类决策。这种概率性质使得逻辑回归成为二分类问题的常用算法,并且在很多其他领域中也有广泛应用。
05
5、逻辑回归模型的参数是什么?如何训练这些参数?
逻辑回归模型的参数包括权重(或系数)和截距(或偏置项),这些参数用于建立线性组合并通过Sigmoid函数将其转换为概率值。
具体来说,逻辑回归模型的参数如下:
1、权重(系数):对应于每个输入特征的权重,用于衡量该特征对预测的影响。每个特征都有一个对应的权重参数。
2、截距(偏置项):表示模型的基准输出,即当所有特征的值都为零时,模型的输出值。
训练逻辑回归模型的过程通常涉及以下步骤:
1、数据准备:获取带有标签的训练数据集,其中包括输入特征和相应的类别标签(通常为0或1)。
2、特征工程:选择和提取适当的特征,并进行必要的特征预处理(例如,标准化、缺失值处理等)。
3、模型初始化:初始化模型的权重和截距(通常为零或小随机值)。
4、定义损失函数:通常使用交叉熵损失函数(对数损失函数)来衡量模型预测的概率与实际标签之间的差异。
5、优化算法:选择一个优化算法,通常是梯度下降(Gradient Descent)或其变种,用于最小化损失函数并更新模型的参数(权重和截距)。优化算法会沿着损失函数的梯度方向更新参数,使损失逐渐减小。
6、训练模型:迭代运行优化算法,通过将训练数据传递给模型,计算梯度并更新参数。训练过程通常需要多个迭代轮次,直到收敛到最佳参数。
7、评估模型:使用独立的验证集或测试集来评估模型的性能。通常使用性能指标(如准确率、精确度、召回率、F1分数等)来评估模型的分类性能。
8、调整超参数:根据模型性能进行超参数调优,例如学习率、正则化参数等。
9、模型应用:一旦训练完毕并满意性能,可以使用该模型来进行新样本的分类预测。
10、可解释性分析(可选):根据模型的参数权重,可以进行特征重要性分析,以了解哪些特征对模型的预测最具影响力。
重要的是要理解,逻辑回归的训练过程旨在找到使损失函数最小化的最佳参数组合,以使模型能够正确地估计输入特征与类别标签之间的关系,并进行二分类或多分类预测。这个过程通常使用梯度下降等优化技术来实现。
06
6、什么是正则化在逻辑回归中的作用?L1和L2正则化有什么区别?
逻辑回归中,正则化是一种用于控制模型复杂度的技术,它对模型的参数进行约束,以防止过拟合。正则化通过在损失函数中引入额外的正则化项来实现,这些正则化项对参数的大小进行惩罚。
逻辑回归中常用的正则化方法包括L1正则化和L2正则化,它们的作用是:
1、L1正则化(Lasso正则化):
-
作用:L1正则化通过向损失函数添加参数的绝对值之和来惩罚模型中的大参数,从而促使一些参数变为零。这实现了特征选择,可以使模型更加稀疏,剔除不重要的特征,提高模型的泛化能力。
-
L1正则化项:L1正则化项的形式是 ,其中 是正则化参数, 是模型的参数。这个项在优化过程中导致一些参数 变为零,从而进行特征选择。
-
适用情况:L1正则化适用于高维数据集,或者当你怀疑只有少数几个特征对问题有重要影响时。
2、L2正则化(Ridge正则化):
-
作用:L2正则化通过向损失函数添加参数的平方和来惩罚模型中的大参数,但不会使参数变为零,它只是压缩参数的值。L2正则化有助于减轻多重共线性问题,稳定模型的估计。
-
L2正则化项:L2正则化项的形式是 ,其中 是正则化参数, 是模型的参数。
-
适用情况:L2正则化适用于多重共线性问题,或者当你认为所有特征都对问题有一定影响时,但不希望有过大的参数。
总的来说,L1和L2正则化都有助于控制模型的复杂度,防止过拟合。它们的主要区别在于:
-
L1 正则化倾向于产生稀疏模型,即一些参数变为零,实现了特征选择。
-
L2 正则化不会使参数变为零,而是对参数进行缩小,有助于减轻多重共线性问题。
选择哪种正则化方法通常取决于数据的性质和问题的需求。在某些情况下,可以同时使用L1和L2正则化,称为弹性网络正则化,以综合两者的优点。正则化参数 的选择通常需要通过交叉验证等技术来确定。
07
7、什么是特征工程,为什么它在逻辑回归中很重要?
特征工程是机器学习和数据科学中的关键任务,它涉及选择、转换和创建特征,以便提高模型的性能和效果。
主要目标:将原始数据转化为机器学习模型可以理解和有效利用的特征表示形式。
在逻辑回归以及其他机器学习模型中,特征工程非常重要,因为它直接影响模型的性能和泛化能力。
特征工程包括以下几个方面:
1、特征选择:选择最相关和有用的特征,消除不相关的特征,以减少数据维度并提高模型的解释性。这有助于降低模型的复杂度,减少过拟合的风险。
2、特征变换:对特征进行变换,使其更适合模型的假设。例如,对数变换、标准化、归一化等变换可以使数据更符合线性模型的假设。
3、特征创建:通过组合、交叉或聚合现有特征来创建新的特征。这可以帮助模型捕获更复杂的关系和模式。
4、处理缺失值:选择合适的方法来处理缺失值,如填充缺失值、删除包含缺失值的样本等。
5、处理类别特征:将类别特征(离散型特征)进行编码,如独热编码、标签编码等,以便模型可以处理它们。
在逻辑回归中,特征工程非常重要的原因包括:
-
影响模型性能:逻辑回归的性能很大程度上取决于输入特征的质量和相关性。好的特征工程可以提高模型的准确性和泛化能力。
-
减少过拟合:精心设计的特征工程可以减少模型对训练数据的过拟合风险,从而提高模型对新数据的泛化能力。
-
解释性:逻辑回归通常用于解释性建模,良好的特征工程可以增加模型的可解释性,帮助理解模型的决策依据。
-
计算效率:精简的特征集合可以提高模型的计算效率,减少训练和推理时间。
总之,特征工程是一个关键的环节,可以极大地影响逻辑回归模型的性能和实用性。
在建立逻辑回归模型之前,务必仔细考虑和执行特征工程步骤,以确保模型能够从数据中学到有用的模式和关系。
08
8、逻辑回归的预测结果如何?怎样解释模型的系数(coefficient)?
逻辑回归的预测结果是一个介于0和1之间的概率值,表示给定输入样本属于正类别的概率。具体来说,逻辑回归模型对于输入样本的预测结果可以通过以下步骤获得:
1、线性组合:首先,模型将输入样本的特征与对应的权重(系数)相乘,然后将它们相加,得到一个实数值。这个实数值表示了线性组合的结果。
其中, 是截距(偏置项), 是特征的权重(系数), 是输入特征的值。
2、逻辑函数:然后,模型将线性组合的结果输入到逻辑函数(Sigmoid函数)中,将其映射到[0, 1]范围内的概率值:
预测概率线性组合
这个概率值表示输入样本属于正类别的概率。
3、分类决策:通常,可以将预测概率与一个阈值(通常为0.5)进行比较,以进行最终的分类决策。如果预测概率大于或等于阈值,则将样本分类为正类别(1),否则分类为负类别(0)。
模型的系数(权重,coefficient) 表示了每个特征对于预测结果的影响程度。系数的正负和大小告诉了我们特征对于预测是正向还是负向的影响,以及影响的相对强度。正系数表示增加该特征的值将增加样本属于正类别的概率,负系数表示增加该特征的值将减少样本属于正类别的概率。
模型的系数通常在训练过程中通过最大似然估计 或 其他优化算法来学习。系数的值可以提供有关特征的重要性和影响的信息,可以用于特征选择、可解释性分析和模型解释。系数的绝对值越大,表示对应特征的影响越显著。
09
9、什么是ROC曲线和AUC值?它们用来评估逻辑回归模型的哪些性能?
ROC曲线(Receiver Operating Characteristic Curve)和AUC值(Area Under the ROC Curve)是用于评估二分类模型性能的常用工具。
1、ROC曲线:
-
ROC曲线是一种图形化工具,用于可视化二分类模型的性能。它以不同的分类阈值为横轴,以真正例率(True Positive Rate,也称为召回率)为纵轴,绘制出模型在不同阈值下的性能表现。
-
ROC曲线的横轴表示模型的假正例率(False Positive Rate),计算方式为:假正例率 = 1 - 特异度(True Negative Rate)。
-
ROC曲线图中的每个点对应于不同的分类阈值,根据阈值的变化,计算真正例率和假正例率,然后绘制出曲线。ROC曲线越靠近左上角,模型性能越好。
-
ROC曲线的优点是不受类别不平衡问题的影响,能够展示模型在各种不同阈值下的性能表现。
2、AUC值:
-
AUC是ROC曲线下方的面积,被称为"Area Under the ROC Curve"。AUC值的范围通常在0.5和1之间,其中0.5表示模型的性能等同于随机猜测,1表示完美分类器。
-
AUC值提供了一种单一的数值度量,用于总结ROC曲线的整体性能。通常情况下,AUC值越接近1,模型的性能越好。
-
AUC值有一个重要的性质:如果随机选择一个正类别样本和一个负类别样本,分类器的预测概率对正负样本的排序是正确的概率(即正类别样本的预测概率大于负类别样本的预测概率)。
ROC曲线和AUC值是用于评估二分类模型性能的重要工具。它们不仅可以帮助你理解模型的表现,还可以用于比较不同模型的性能。当需要在不同分类阈值下权衡召回率和假正例率时,ROC曲线很有用。而AUC值则提供了一种简洁的方式来总结模型的性能,对于大多数分类问题都是一个有用的评估指标。
ROC曲线和AUC值用来评估逻辑回归模型在二分类问题中的以下性能方面:
1、分类准确度:虽然ROC曲线和AUC值本身并不提供分类准确度的度量,但它们可以帮助你了解模型在不同阈值下的性能表现,从而帮助你调整阈值以满足特定的分类准确度要求。通过查看ROC曲线,你可以选择一个阈值,使模型在召回率和假正例率之间达到平衡,从而满足你的分类准确度需求。
2、召回率和假正例率:ROC曲线以不同的分类阈值为横轴,分别显示了模型的召回率(True Positive Rate,也称为敏感性)和假正例率(False Positive Rate)。这对于评估模型的敏感性和特异性非常有用。高召回率表示模型能够识别出较多的正类别样本,而低假正例率表示模型能够有效控制误报。
3、模型性能比较:ROC曲线和AUC值可用于比较不同模型的性能。如果一个模型的ROC曲线位于另一个模型的上方,并且具有更高的AUC值,那么通常可以认为它在分类任务中具有更好的性能。
4、模型稳定性:通过观察ROC曲线,你可以评估模型在不同阈值下的性能稳定性。如果曲线变化不大,说明模型在不同分类阈值下都表现良好,具有稳定性。
总之,ROC曲线和AUC值是用来综合评估逻辑回归模型的分类性能、敏感性、特异性和模型稳定性的工具。它们可以帮助你理解模型在不同情境下的性能,并支持模型选择和调整分类阈值以满足特定需求。
10
10、逻辑回归模型可能面临的问题有哪些?如何处理类不平衡问题?
逻辑回归模型可能面临的一些问题包括:
1、类不平衡问题:当正类别和负类别的样本数量差异很大时,模型可能倾向于偏向于多数类,而忽略少数类。这会导致模型的性能不均衡,对少数类的识别能力较弱。
2、多重共线性:当特征之间存在高度相关性时,逻辑回归模型的参数估计可能变得不稳定,导致难以解释的结果。
3、过拟合:如果模型过于复杂或特征数量过多,逻辑回归模型可能过拟合训练数据,表现良好的泛化能力较差。
4、特征选择:选择合适的特征对模型性能至关重要。错误的特征选择可能导致模型性能下降。
5、阈值选择:逻辑回归模型的输出是一个概率值,需要选择合适的阈值来进行分类决策,不同的阈值可能导致不同的性能表现。
如何处理类不平衡问题:
处理类不平衡问题是逻辑回归模型常见的挑战之一。
以下是一些处理类不平衡问题的方法:
1、重采样:
-
过采样:增加少数类的样本数量,可以通过复制已有的少数类样本或生成合成样本来实现。
-
欠采样:减少多数类的样本数量,可以通过删除一些多数类样本来实现。
-
合成采样:结合过采样和欠采样策略,以平衡样本分布。
2、使用不同的类权重:
-
通过设置类别权重参数,赋予不同类别的样本不同的权重,以便模型更关注少数类。在许多机器学习框架中,可以使用参数来调整类别权重。
3、生成合成样本:
-
利用生成对抗网络(GANs)或其他合成数据生成方法,生成合成的少数类样本,以平衡类别分布。
4、集成方法:
-
使用集成方法如随机森林、梯度提升树等,这些方法对类不平衡问题具有较强的鲁棒性。
5、改变阈值:
-
调整分类阈值,以便更好地适应类别不平衡问题。通常情况下,减小阈值可以增加对少数类的识别能力。
6、使用不同的评估指标:
-
使用类别不平衡问题友好的评估指标,如准确率、精确度、召回率、F1分数、ROC曲线和AUC值等,以更全面地评估模型性能。
最佳的处理类不平衡问题的方法取决于具体情况和数据集的性质。通常,需要尝试不同的方法并评估它们的效果,以找到最适合特定问题的方法。
11
11、什么是交叉验证,为什么在逻辑回归中使用它?
交叉验证是一种评估机器学习模型性能的统计技术。它将数据集分成训练集和测试集的多个子集,然后多次训练和测试模型,以便更全面地评估模型在不同数据子集上的性能表现。
交叉验证的主要目的是:
1、评估模型泛化能力:交叉验证可以帮助我们评估模型在未见过的数据上的性能,而不仅仅是在训练数据上的性能。这有助于检测模型是否过拟合或欠拟合。
2、减少随机性:将数据集分成多个子集并多次训练模型,有助于减少随机性对性能评估的影响。这使得我们能够更可靠地评估模型的性能。
在逻辑回归中使用交叉验证的原因包括:
1、模型选择:交叉验证可以帮助选择逻辑回归模型的超参数,如正则化参数(如L1或L2正则化的强度)。通过在不同的数据子集上进行验证,可以找到使模型性能最优的参数配置。
2、性能评估:交叉验证提供了一个更准确的模型性能评估方法,以便在不同数据子集上评估模型的性能。这有助于识别模型是否具有一般化能力,以及是否需要进一步改进。
3、处理数据不平衡:如果数据集中存在类不平衡问题,交叉验证可以确保在每个数据子集上都有足够的正类别和负类别样本,从而更准确地评估模型的性能。
4、可解释性:逻辑回归通常用于可解释性建模,而交叉验证可以帮助确定哪些特征对模型性能具有重要影响,从而增强了模型的可解释性。
常见的交叉验证方法包括k折交叉验证(k-fold cross-validation)、留一交叉验证(leave-one-out cross-validation,LOOCV)等。k折交叉验证将数据集分成k个子集,其中k-1个子集用于训练,剩余的1个子集用于测试,这一过程重复k次,每个子集都有机会充当测试集。最后,计算k次测试的平均性能来评估模型。交叉验证通常是在机器学习中评估模型性能的重要步骤,有助于更可靠地了解模型的表现。
咱们详细说下k折交叉验证。
k折交叉验证用于评估机器学习模型的性能。它将数据集分成k个近似相等的子集(通常是5或10),然后进行k次模型训练和性能评估,每次选择一个子集作为验证集,其余子集用于训练模型。这个过程的目标是确保每个子集都充当过验证集,以便全面评估模型的性能。
以下是使用Python的Scikit-Learn库来执行k折交叉验证的示例:
from sklearn.model_selection import cross_val_score, KFold
from sklearn.linear_model import LogisticRegression# 创建一个逻辑回归模型
model = LogisticRegression()# 创建k折交叉验证对象,这里设置k=5
kfold = KFold(n_splits=5, shuffle=True, random_state=42)# 使用cross_val_score执行交叉验证并评估模型性能
scores = cross_val_score(model, X, y, cv=kfold, scoring='accuracy')# 打印每次交叉验证的准确度分数
print("Cross-Validation Scores:", scores)# 打印平均准确度分数
print("Average Accuracy:", scores.mean())上述代码中,首先创建了一个逻辑回归模型(LogisticRegression),然后创建了一个k折交叉验证对象(KFold),将数据分为5个子集,并在每次交叉验证中随机打乱数据(shuffle=True)。接下来,我们使用cross_val_score函数执行交叉验证,评估模型的性能,并将每次交叉验证的准确度分数存储在scores数组中。最后,计算并打印平均准确度分数。
使用k折交叉验证可以更全面地了解模型在不同数据子集上的性能表现,有助于检测模型是否过拟合或欠拟合,以及确定模型的稳定性。这是模型选择和调优的重要步骤之一。
12
12、逻辑回归在实际应用中的一个例子是什么?描述一个应用场景,并如何使用逻辑回归来解决问题。
逻辑回归在实际应用中有许多用途,其中一个典型的应用是二分类问题,如信用风险评估。
下面咱们举一个信用风险评估的应用场景,并描述如何使用逻辑回归来解决问题。
应用场景:信用风险评估
问题描述:一家银行想要评估客户申请信用卡的风险,以决定是否批准他们的信用卡申请。银行需要预测每位申请者是否会在未来的一年内违约(无法按时偿还信用卡债务)。这是一个典型的二分类问题,其中正类别表示违约,负类别表示未违约。
解决方法:
1、数据收集:首先,银行需要收集历史客户的数据,包括客户的个人信息(如年龄、性别、婚姻状况等)、财务信息(如收入、支出、债务等)、以及与信用卡使用相关的数据(如信用卡账户余额、信用额度、逾期次数等)。
2、数据预处理:对数据进行清洗和预处理,包括处理缺失值、异常值、类别特征的编码等。还需要进行特征选择,选择与信用风险相关的特征。
3、数据划分:将数据集分为训练集和测试集。通常,将大部分数据用于训练模型,剩余的一部分用于评估模型性能。
4、建立逻辑回归模型:使用训练数据建立逻辑回归模型。模型的输入特征是客户的个人和财务信息,输出是二分类的违约/未违约标签。
5、模型训练:通过训练数据对逻辑回归模型的参数进行估计,通常使用最大似然估计等方法来完成。
6、模型评估:使用测试数据来评估模型的性能。可以使用各种评估指标如准确率、召回率、F1分数、ROC曲线和AUC值来衡量模型的性能。
7、阈值选择:根据业务需求,选择合适的分类阈值,以平衡风险和收益。不同的阈值会影响模型的预测结果。
8、模型部署:一旦满足性能要求,可以将逻辑回归模型部署到生产环境中,用于自动评估信用卡申请的风险。
9、持续监控和改进:定期监控模型的性能,根据新的数据和反馈进行模型的改进和更新,以确保其持续有效。
逻辑回归在信用风险评估中的应用是一个典型的二分类问题,它可以帮助银行自动化信用卡申请的批准过程,提高风险管理效率,并减少不良债务的风险。这是逻辑回归在金融领域中的一个实际应用示例。
以下是一个简单的Python案例,演示如何使用逻辑回归模型来解决信用风险评估问题。这个案例使用了Scikit-Learn库中的示例数据集,用于预测信用卡申请者是否具有高风险。
数据集:在「公众号:深夜努力写Python」后台回复“数据集”可获取~
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 读取数据集
data = pd.read_csv('credit_data.csv') # 假设数据集以CSV格式存在# 处理NaN值,使用特征列的均值填充NaN值
data.fillna(data.mean(), inplace=True)# 分割特征和标签
X = data.iloc[:, :-1] # 特征
y = data.iloc[:, -1] # 标签# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 建立逻辑回归模型
model = LogisticRegression()# 模型训练
model.fit(X_train, y_train)# 模型预测
y_pred = model.predict(X_test)# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
confusion = confusion_matrix(y_test, y_pred)
classification_report_str = classification_report(y_test, y_pred)# 打印模型性能指标
print("Accuracy:", accuracy)
print("Confusion Matrix:\n", confusion)
print("Classification Report:\n", classification_report_str)
代码中,首先加载示例数据集(名为credit_data.csv的数据集),然后进行数据预处理,包括特征标准化。接下来,我们将数据集分为训练集和测试集,然后建立逻辑回归模型,对模型进行训练,并用测试集进行模型评估。最后,我们打印了模型的准确度、混淆矩阵和分类报告。
相关文章:

【建议收藏】逻辑回归面试题,机器学习干货、重点。
. . . . . . . . . . .纯 干 货 . . . . . . . . . . . .今天是机器学习面试题,16大块的内容,124个问题总结的第二期:逻辑回归面试题。 逻辑回归是一种用于解决分类问题的统计学习方法,尤其在二分类…...
C++使用教程
目录 一、软件使用 二、C基础规则补充 关键字 整型取值范围 浮点型取值范围 字符型使用规则 字符串型使用规则 布尔类型 常用的转义移字符 三、数组、函数、指针、结构体补充 1.数组 2.函数 声明: 分文件编写: 值传递: 3.指…...
k8s volcano + deepspeed多机训练 + RDMA ROCE+ 用户权限安全方案【建议收藏】
前提:nvidia、cuda、nvidia-fabricmanager等相关的组件已经在宿主机正确安装,如果没有安装可以参考我之前发的文章GPU A800 A100系列NVIDIA环境和PyTorch2.0基础环境配置【建议收藏】_a800多卡运行环境配置-CSDN博客文章浏览阅读1.1k次,点赞8…...
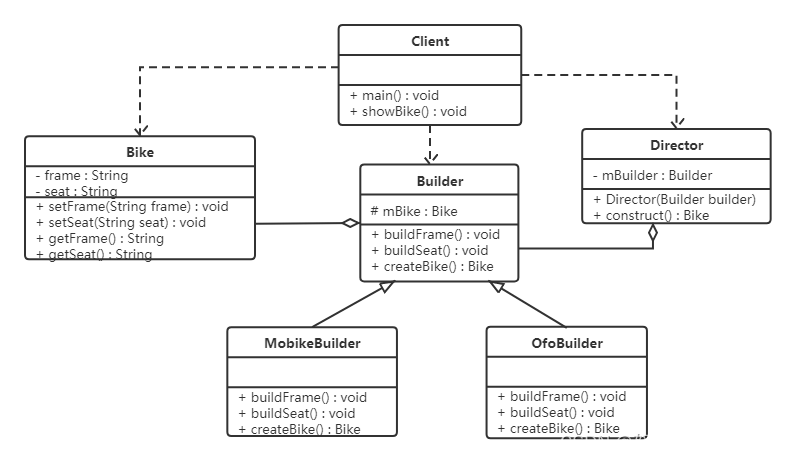
设计模式(七)创建者模式之建造者模式
这里写目录标题 概述需求需求类图BikeBuilderMobikeBuilderOfoBuilderDirectorClientClient优缺点使用场景 模式扩展ComputerClient创建者模式对比工厂方法模式VS建造者模式抽象工厂模式VS建造者模式 总结 概述 建造者模式又叫生成器模式,是一种对象构建模式。它可…...

# class中的__call__方法解析
class中的__call__方法解析 文章目录 class中的__call__方法解析1. 为什么要有call,什么情况下用call?1.1 为什么要有 __call__ 方法1.2 没有 __call__ 方法是否可以1.3 使用 __call__ 方法的典型场景1.3.1 示例1:简单函数对象1.3.2 示例2&am…...

React逻辑复用的方式都有哪些
在日常开发中,能够优雅的复用组件和逻辑,是优秀开发者的职责。在react中,复用逻辑的方式有很多,可以适用于不同的业务场景。今天说三个比较有代表性的,Render Props、HOC、Hooks Render Props 创建一个接受函数作为其…...

【LinuxC语言】线程重入
文章目录 前言线程重入是什么线程重入实现示例代码总结前言 在并发编程中,我们经常需要处理多个线程同时访问和修改共享资源的问题。这可能会导致数据竞争和状态不一致,从而使程序的行为变得不可预测。为了解决这个问题,我们引入了一种称为“线程重入”的机制。线程重入,或…...

【Streamlit学习笔记】Streamlit-ECharts箱型图添加均值和最值label
Streamlit-ECharts Streamlit-ECharts是一个Streamlit组件,用于在Python应用程序中展示ECharts图表。ECharts是一个由百度开发的JavaScript数据可视化库Apache ECharts 安装模块库 pip install streamlitpip install streamlit-echarts绘制箱型图展示 在基础箱型…...

Docker镜像仓库:存储与分发Docker镜像的中央仓库
探索Docker镜像仓库:存储与分发Docker镜像的中央仓库 如果你是Docker的新手,或者已经在使用Docker但还不太了解Docker镜像仓库,那么这篇博客将是你的最佳指南。我们将从基础概念开始,逐步深入,帮助你全面掌握Docker注…...

FreeRTOS必考面试题及参考答案
什么是RTOS?FreeRTOS是什么?它主要应用于哪些领域? RTOS,即实时操作系统(Real-Time Operating System),是一种专门为实时应用程序设计的操作系统,它强调的是对外部事件的快速响应和可预测性。实时系统通常要求在严格的时限内完成关键任务,因此RTOS具备优先级调度、确…...

面试题2:从浏览器输入一个URL,到最终展示前端页面这一过程,会发生什么?
这是一个高频的面试题目。 题目答案是开放性的,一般以后端开发的角度回答。 当地址栏输入一个 URL 后: 一、首先会进行 DNS 域名解析 DNS 域名解析:网络上的设备都是通过 IP 地址,作为身份标识的。但是由于点分十进制的 IP 地址 …...

<Rust><iced><resvg>基于rust使用iced构建GUI实例:使用resvg库实现svg转png
前言 本文是使用rust库resvg来将svg图片转为png图片。 环境配置 系统:windows 平台:visual studio code 语言:rust 库:resvg 代码分析 resvg是一个基于rust的svg渲染库,其官方地址: An SVG rendering li…...

面试突击:Java 中的泛型
本文已收录于:https://github.com/danmuking/all-in-one(持续更新) 前言 哈喽,大家好,我是 DanMu。今天想和大家聊聊 Java 中的泛型。 什么是泛型? Java 泛型(Generics) 是 JDK 5…...

3_2、MFC常用控件用法:组合框、滚动条和图片控件
MFC控件用法 1、组合框1.1 简介1.2 创建CComboBox类的主要成员函数 1.3 实例 2、滚动条控件2.1 简介2.2 创建CScrollBar类的主要成员函数 2.3 实例 3、图片控件3.1 简介3.2 创建图片控件静态加载图片图片控件动态加载图片 1、组合框 1.1 简介 组合框其实就是把一个编辑框和一…...

如何使用gprof对程序进行性能分析
如何使用gprof对程序进行性能分析 目录 1 gprof概述 2 gprof原理简述 3 gprof使用 3.1 gprof使用简述 3.2 gprof使用示例 4 小结 1 gprof概述 gprof 是 一个 GNU 的程序性能分析工具,可以用于分析C\C程序的执行性能。gprof工具可以统计出各个函数的调用次数、执…...

四川汇聚荣科技有限公司靠谱吗?
在如今这个信息爆炸的时代,了解一家公司是否靠谱对于消费者和合作伙伴来说至关重要。四川汇聚荣科技有限公司作为一家位于中国西部地区的企业,自然也受到了人们的关注。那么,这家公司究竟如何呢?接下来,我们将从多个角度进行深入…...

可灵王炸更新,图生视频、视频续写,最长可达3分钟!Runway 不香了 ...
现在视频大模型有多卷? Runway 刚在6月17号 发布Gen3 ,坐上王座没几天; 可灵就在6月21日中午,重新夺回了王座!发布了图生视频功能,视频续写功能! 一张图概括: 二师兄和团队老师第一…...

oracle中使用临时表GLOBAL TEMPORARY TABLE
需要在存储过程中返回一个临时结果集,这个结果集又是多个语句通过循环查询出来的,这时候就想到了将结果插入到临时表中,然后返回临时表的数据的思路,于是有了以下操作: 1.创建临时表 -- Create table create global …...
Gradio入门—快速开始
目录 安装构建您的第一个演示分享您的演示核心 Gradio 课程聊天机器人gr.ChatInterface自定义演示gr.BlocksGradio Python 和 JavaScript 生态系统 Gradio 是一个开源 Python 软件包,可让您快速为机器学习模型、API 或任何任意 Python 函数构建演示或 Web 应用程序。…...

AOP应用之系统操作日志
本文演示下如何使用AOP,去实现系统操作日志功能。 实现步骤 引入AOP包 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId><version>2.6.6</version></de…...

某高校学生考微软MOS认证加学分
临近毕业季,到底是谁的学分还没有修够?微软MOS认证证书也可以加学分,每天学习两个小时,一周就可以完成考试,当天就出证书!📌关于难度选择版本难度:2016 < 2019 < 365ÿ…...

OpenClaw浏览器自动化:nanobot镜像实现定时抢购与价格监控
OpenClaw浏览器自动化:nanobot镜像实现定时抢购与价格监控 1. 为什么选择OpenClaw实现浏览器自动化 去年双十一期间,我为了抢购某款显卡,连续三天凌晨守着电脑刷新页面,结果还是错过了补货。这种经历让我开始寻找自动化解决方案…...
)
MambaAD实战:5分钟搞定工业缺陷检测的SoTA模型部署(附代码)
MambaAD工业缺陷检测实战:从模型原理到产线部署全指南 引言:当状态空间模型遇见工业质检 在液晶面板生产线上,一个0.1mm的亮点缺陷可能导致整批产品报废;在汽车零部件铸造车间,细微的表面裂纹可能引发严重的安全隐患。…...

RK3588开发板跑YOLOv5视频流demo,遇到Segmentation fault别慌!保姆级core文件生成与调试指南
RK3588开发板YOLOv5视频流推理崩溃排查:从Segmentation fault到精准调试全攻略 当你在RK3588开发板上满心期待地运行YOLOv5视频流推理demo时,屏幕上突然闪现的"Segmentation fault (core dumped)"就像一盆冷水浇灭了热情。这种崩溃提示信息量极…...

Display Driver Uninstaller深度清理实战指南
Display Driver Uninstaller深度清理实战指南 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uninstaller 当你遭遇游戏帧…...

医药行业用友 YonSuite 一体化管理方案
医保新规 4 月 1 日落地|医药企业破局:数智化 合规 精细化,活下去且活得好2026 年 4 月 1 日,医保新规全面执行,集采深化、价格严控、全链路监管,医药行业正式告别高毛利、粗放式、渠道为王的旧时代&…...

半导体仿真进阶:如何用Silvaco DOPING语句精确控制掺杂分布
半导体仿真进阶:如何用Silvaco DOPING语句精确控制掺杂分布 在半导体器件设计与工艺开发中,精确控制掺杂分布是决定器件性能的关键因素之一。Silvaco TCAD工具链中的DOPING语句,为工程师提供了从简单均匀掺杂到复杂梯度分布的灵活控制能力。…...
)
麒麟V10系统下国产海量数据库安装全攻略(含内核参数优化与避坑指南)
麒麟V10系统下国产海量数据库安装全攻略(含内核参数优化与避坑指南) 在国产化技术快速发展的今天,越来越多的企业和机构开始采用国产操作系统和数据库产品。麒麟V10作为国产操作系统的代表之一,其稳定性和安全性得到了广泛认可。而…...

AOP 失效的 7 种死法与复活指南
还是那句话,知识是一个返回的过程,追一句:时间出真知今天我们要聊的是一个“灵异事件”频发的领域——Spring AOP 失效。你是不是也经历过这种崩溃:“明明加了 Transactional,为什么数据库报错不回滚?” “…...

从GTS-800到GTS-400:手把手教你移植C#点胶机程序到不同固高控制卡
从GTS-800到GTS-400:工业点胶系统迁移实战指南 当生产线上的点胶机控制卡需要从GTS-800更换为GTS-400时,许多工程师会发现"使用方法类似"这个说法背后隐藏着大量细节差异。去年我们团队完成了一个医疗设备点胶系统的迁移项目,原计划…...