【大数据 复习】第7章 MapReduce(重中之重)
一、概念
1.MapReduce 设计就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为移动,数据需要大量的网络传输开销。
2.Hadoop MapReduce是分布式并行编程模型MapReduce的开源实现。
3.特点
(1)非共享式,容错性好。
(2)普通PC机,便宜,扩展性好。
(3)只有what,没有how,简单。
(4)使用场景:批处理、非实时、数据密集型。
4.MapReduce 采用“分而治之”策略
一个存储在分布式文件系统中的 大规模数据集,会被切分成许多独立的分片 (split), 这些分片可以被多个Map 任务并行处理。
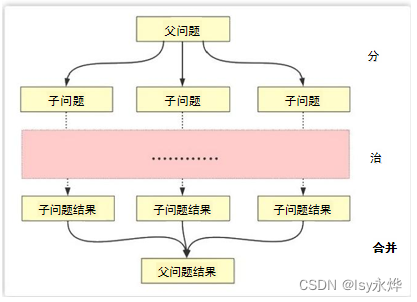
5.MapReduce 1.0体系结构
(1)Hadoop MapReduce采用Master/Slave结构。
Master:是整个集群的唯一的全局管理者,功能是作业管理、状态监控和任务调度等,即MapReduce中的JobTracker。
Slave:负责任务的执行和任务状态的报告,即MapReduce中的TaskTracker。
(2)MapReduce体系结构主要由四个部分组成,分别是: Client 、JobTracker 、TaskTracker 以及Task。
(3)TaskTracker是JobTracker和Task之间的桥梁:
(4)JobTracker负责很多任务:
a.负责资源监控和作业调度
b.监控所有TaskTracker与Job的健康状况
c.跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度(TaskScheduler)。
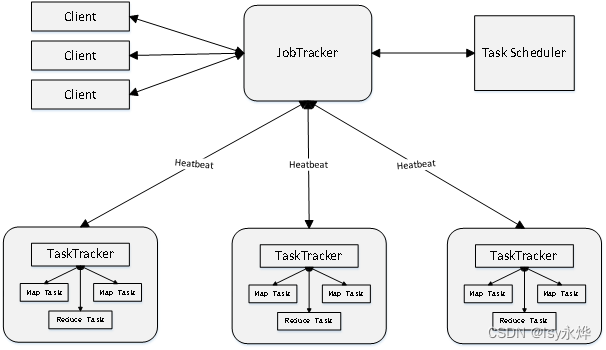
6.map函数和reduce函数:
(1)map接收原始的键值对进行一层处理,然后reduce只接受处理过的键值对,进行二次处理,大致流程如下:
(2)可以连着使用:
Map是映射,负责数据的过滤分法,将原始数据转化为键值对;
Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果。
(3)Map 和Reduce操作需要我们自己定义相应Map 类和Reduce 类,而shuffle则是系统自动帮我们实现的。
(4)shuffle可以简单的理解为map的售后,但是同样是reduce的“售前”。
在map端主要是写入缓存,溢写操作,合并操作。
在reduce端主要是询问“前辈”map任务完成了吗,如果溢写了就帮reduce提前归并好然后发给reduce。
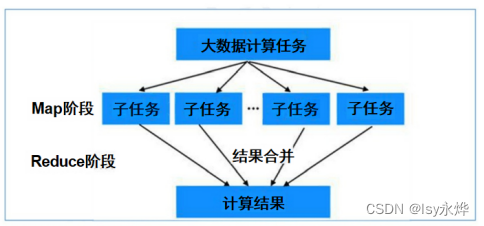
7.slot
(1)是执行 Map 或 Reduce 任务的计算资源单位。
(2)Map slot 用于处理输入数据的切片并生成中间结果,而 Reduce slot 则用于处理中间结果并生成最终输出。
(3)每个节点都有一定数量的 Map slot 和 Reduce slot,它们的数量可以根据集群配置和需求动态分配。
(4)有效地利用这些 slot 可以提升 MapReduce 作业的执行效率和性能。
二、习题
主观题
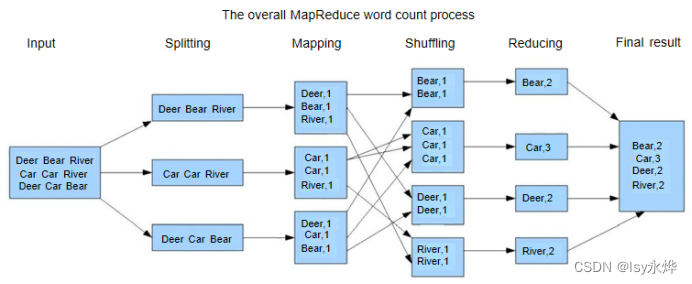
1. 试画出使用MapReduce对英语段落 ”Whatever is worth doing best Whatever is worth doing well”进行单词统计过程
答:
(1)Map阶段:
Mapper将输入的英语段落按照空格分割为单词,并对每个单词生成一个键值对,其中键为单词,值为1。
输入: "Whatever is worth doing best Whatever is worth doing well"
输出中间键值对:
(Whatever, 1), (is, 1), (worth, 1), (doing, 1), (best, 1), (Whatever, 1), (is, 1), (worth, 1), (doing, 1), (well, 1)
(2)Shuffle阶段:
对中间键值对按照键进行排序和分组,以便后续Reduce阶段对同一个键的值进行聚合处理。此处不需要额外的操作,因为Mapper已经按照单词生成了键值对。
(3) Reduce阶段:
Reducer对每个单词的键值对进行聚合,计算每个单词出现的总次数。
输入中间键值对:
(Whatever, [1, 1]), (best, [1]), (doing, [1, 1]), (is, [1, 1]), (well, [1]), (worth, [1, 1])
输出最终结果:
(Whatever, 2), (best, 1), (doing, 2), (is, 2), (well, 1), (worth, 2)
4. 使用MapReduce完成对下表中及格同学的筛选,描述编程设计实现过程(文字描述即可,不用写代码)。
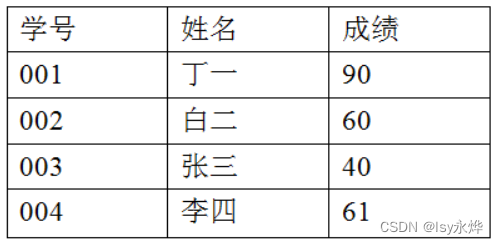
答:
(1)Map阶段:
Mapper函数读取每一行学生记录,将学号和成绩作为输入。
对于每个学生记录,Mapper检查成绩是否及格(大于等于60分)。
如果成绩及格,Mapper输出键值对(学号,成绩)。
(2)Shuffle阶段
中间结果根据学号进行排序和分组,以便后续Reduce阶段对每个学生的成绩进行聚合处理。
(3)Reduce阶段:
Reducer函数接收每个学生的学号和成绩列表作为输入。
对于每个学生,Reducer检查其成绩列表中是否有成绩及格。
如果成绩列表中有成绩及格,Reducer输出该学生的学号和成绩。
总感觉reduce啥也没干。。。。。
7.分析描述Shuffle的执行过程。
答:
(1)Map任务输出:Map任务生成键值对,并根据键的哈希值将其分区。
(2)本地排序:每个分区的键值对在本地磁盘上按键排序。
(3)数据传输:Reduce任务从各个Map任务所在的节点上拉取(pull)属于自己的分区数据。
(4) 数据合并:Reduce任务将拉取到的数据进行合并,准备进行Reduce处理。
单选题
2. Shuffle过程不包括下列哪个过程?()
A. 分区
B. 排序
C. 合并归并
D. 切分
正确答案:D
切分应该是map干的吧,虽然没说
3. Map和Reduce函数都是以( )作为输入。
A. Key
B. Text
C. 键值对
D. 文件块
正确答案:C
5. Reduce函数的任务是()
A. 通过Hash函数对数据进行排序
B. 对数据进行分区
C. 将输入的一系列具有相同Key的键值对以某种方式组合起来,输出处理后的键值对
D. 对数据进行解析得到键值对
正确答案:C
1.MapReduce的核心思想是 ( )
A. 分而治之
B. 流计算
C. 分布式存储
D. 批处理
正确答案: A
2.MapReduce处理海量数据的时候,中间数据存储在()
A. 内存
B. 磁盘
C. ResourceManager
D. Container
正确答案: B
3.属于MapReduce的设计理念的是。()
A. 数据向计算靠拢
B. 自行进行工作调度
C. 计算向数据靠拢
D. 无需负载均衡
正确答案: C
4.Map函数将输入的元素转换成键值对,下列说法不正确的是( )
A. 一个Map函数只能转换出一个键值对
B. Map转换出的键没有唯一性
C. 同一输入元素,可以通过一个Map任务生成具有相同键的多个键值对
D. 键不可以作为输出的身份标识
正确答案: A
5.每个MapReduce程序都需要一个()
A. Task
B. Partitioner
C. Job
D. Combiner
正确答案: C
多选题
6. 编写MapReduce程序时,()。
A. 编写Map处理逻辑
B. 编写Reduce处理逻辑
C. 编写main方法
D. 提前生成输出文件夹
正确答案:A,B,C
相关文章:
【大数据 复习】第7章 MapReduce(重中之重)
一、概念 1.MapReduce 设计就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为移动,数据需要大量的网络传输开销。 2.Hadoop MapReduce是分布式并行编程模型MapReduce的开源实现。 3.特点 (1)非共享式,…...

Zookeeper:节点
文章目录 一、节点类型二、监听器及节点删除三、创建节点四、监听节点变化五、判断节点是否存在 一、节点类型 持久(Persistent):客户端和服务器端断开连接后,创建的节点不删除。 持久化目录节点:客户端与Zookeeper断…...

生产级别的 vue
生产级别的 vue 拆分组件的标识更好的组织你的目录如何解决 props-base 设计的问题transparent component (透明组件)可减缓上述问题provide 和 inject vue-meta 在路由中的使用如何确保用户导航到某个路由自己都重新渲染?测试最佳实践如何制…...
spring-kafka(1)集成方法)
kafka(五)spring-kafka(1)集成方法
一、集成 1、pom依赖 <!--kafka--><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artif…...

Java中的设计模式深度解析
Java中的设计模式深度解析 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在软件开发领域,设计模式是一种被广泛应用的经验总结和解决方案&#x…...
鸿蒙 HarmonyOS NEXT星河版APP应用开发—上篇
一、鸿蒙开发环境搭建 DevEco Studio安装 下载 访问官网:https://developer.huawei.com/consumer/cn/deveco-studio/选择操作系统版本后并注册登录华为账号既可下载安装包 安装 建议:软件和依赖安装目录不要使用中文字符软件安装包下载完成后࿰…...
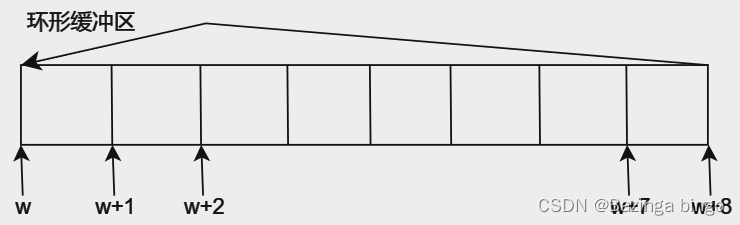
[FreeRTOS 基础知识] 互斥访问与回环队列 概念
文章目录 为什么需要互斥访问?使用队列实现互斥访问休眠和唤醒机制环形缓冲区 为什么需要互斥访问? 在裸机中,假设有两个函数(func_A, func_B)都要修改a的值(a),那么将a定义为全局变…...
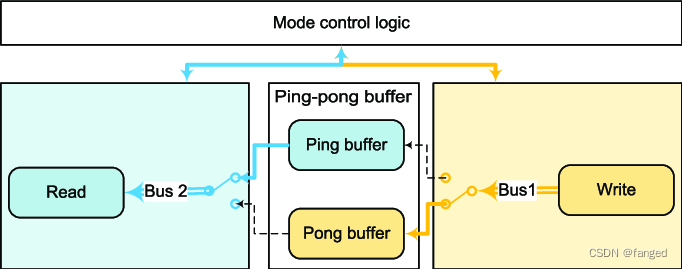
音视频的Buffer处理
最近在做安卓下UVC的一个案子。正好之前搞过ST方案的开机广告,这个也是我少数最后没搞成功的项目。当时也有点客观原因,当时ST要退出机顶盒市场,所以一切的支持都停了,当时啃他家播放器几十万行的代码,而且几乎没有文档…...

【总结】攻击 AI 模型的方法
数据投毒 污染训练数据 后门攻击 通过设计隐蔽的触发器,使得模型在正常测试时无异常,而面对触发器样本时被操纵输出。后门攻击可以看作是特殊的数据投毒,但是也可以通过修改模型参数来实现 对抗样本 只对输入做微小的改动,使模型…...
Linux配置中文环境
文章目录 前言中文语言包中文输入法中文字体 前言 在Linux系统中修改为中文环境,通常涉及以下几个步骤: 中文语言包 更新源列表: 更新系统的软件源列表和语言环境设置,确保可以安装所需的语言包。 sudo apt update sudo apt ins…...

深入解析 iOS 应用启动过程:main() 函数前的四大步骤
深入解析 iOS 应用启动过程:main() 函数前的四大步骤 背景描述:使用 Objective-C 开发的 iOS 或者 MacOS 应用 在开发 iOS 应用时,我们通常会关注 main() 函数及其之后的执行逻辑,但在 main() 函数之前,系统已经为我们…...

textarea标签改写为富文本框编辑器KindEditor
下载 - KindEditor - 在线HTML编辑器 KindEditor的简单使用-CSDN博客 一、 Maven需要的依赖: 如果依赖无法下载,可以多添加几个私服地址: 在Maven框架中加入镜像私服 <mirrors><!-- mirror| Specifies a repository mirror site to…...
高通安卓12-Input子系统
1.Input输入子系统架构 Input Driver(Input设备驱动层)->Input core(输入子系统核心层)->Event handler(事件处理层)->User space(用户空间) 2.getevent获取Input事件的用法 getevent 指令用于获取android系统中 input 输入事件,比如获取按键上报信息、获…...

HTML 事件
HTML 事件 HTML 事件是发生在 HTML 元素上的交互瞬间,它们可以由用户的行为(如点击、按键、鼠标移动等)或浏览器自身的行为(如页面加载完成、图片加载失败等)触发。在 HTML 和 JavaScript 的交互中,事件扮演着核心角色,允许开发者创建动态和响应式的网页。 常见的 HTM…...

Mysql 官方提供的公共测试数据集 Example Databases
数据集:GitHub - datacharmer/test_db: A sample MySQL database with an integrated test suite, used to test your applications and database servers 下载 test_db: https://github.com/datacharmer/test_db/releases/download/v1.0.7/test_db-1.0.7.tar.gz …...
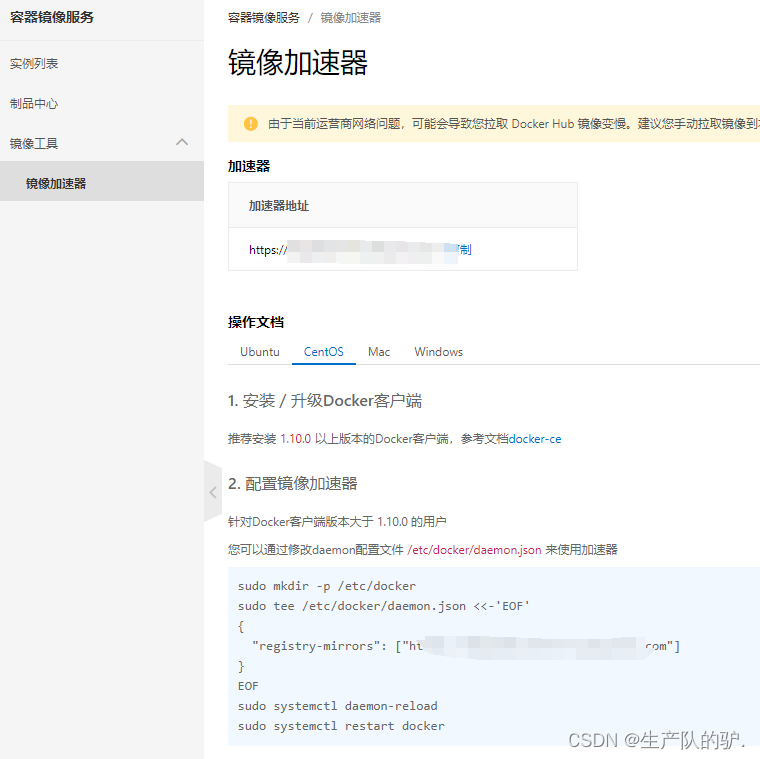
Docker 下载与安装以及配置
安装yum工具 yum install -y yum-ulits配置yum源 阿里云源 yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo安装Docker 17.03后为两个版本: 社区版(Community Edition,缩写为 CE&#x…...

Java中的集合框架详解:List、Set、Map的使用场景
Java中的集合框架详解:List、Set、Map的使用场景 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在Java编程中,集合框架是一个非常重要…...
[Django学习]前端+后端两种方式处理图片流数据
方式1:数据库存放图片地址,图片存放在Django项目文件中 1.首先,我们现在models.py文件中定义模型来存放该图片数据,前端传来的数据都会存放在Django项目文件里的images文件夹下 from django.db import modelsclass Image(models.Model):title models.C…...

如何配置IOMMU或者SWIOTLB
1. 前言 这篇文章说明了如何在Linux内核中启用和配置IOMMU和SWOTLB。 当今的计算或者嵌入设备使用一种内存分区的方法进行外设的管理,如显卡、PCI设备或USB设备,都将设备映射为一段内存,用于设备的读写。 传统意义上的IOMMU用于内存映射&a…...
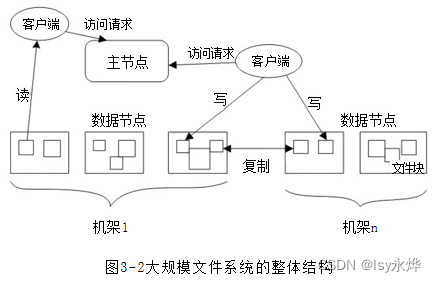
【大数据 复习】第3章 分布式文件系统HDFS(重中之重)
一、概念 1.分布式文件系统把文件分布存储到多个计算机节点上,通过网络实现、文件在多台主机上进行分布式存储的文件系统。(就是你的电脑存a,我的电脑存pple) 2.降低了硬件开销: 与之前使用多个处理器和专用高级硬件的并行化处理装…...
)
别再为RS485上下拉头疼了!手把手教你搞定RK3568开发板上的ttyS7口(附Qt调试工具源码)
RK3568开发板RS485接口调试实战:从硬件配置到Qt工具开发全解析 在嵌入式系统开发中,RS485通信接口因其抗干扰能力强、传输距离远等优势,被广泛应用于工业自动化、智能家居等领域。然而,许多开发者在RK3568平台上调试RS485接口时&a…...

2个实测免费的AI简历神器,简历回复率翻3倍,顺利过ATS机筛!
当前的求职市场,投简历简直像往海里扔石头。很多同学吐槽:明明自己挺优秀,投了100份简历却连一个面试邀请都没有。 其实,大厂HR第一轮根本不看简历,全是靠ATS(简历筛选系统)关键词过滤。如果你…...

GPU-CPU混合向量检索框架的技术突破与应用
1. 项目概述:GPU-CPU混合向量检索框架的技术突破在当今大规模信息检索和推荐系统领域,向量相似度计算已成为核心瓶颈。传统方案通常面临两难选择:要么完全依赖CPU导致响应延迟居高不下,要么全量使用GPU造成资源严重浪费。VECTORLI…...

前后端分离项目避坑指南:为什么你的网关CORS配置了还是报跨域错误?
前后端分离项目避坑指南:为什么你的网关CORS配置了还是报跨域错误? 在前后端分离架构中,跨域资源共享(CORS)问题一直是开发者绕不开的"拦路虎"。即便在网关层正确配置了CORS规则,开发者仍可能遇到…...

Apache RocketMQ 5.0 架构解析:如何基于云原生架构支撑多元化场景
本文将从技术角度了解 RocketMQ 的云原生架构,了解 RocketMQ 如何基于一套统一的架构支撑多元化的场景。 文章主要包含三部分内容。首先介绍 RocketMQ 5.0 的核心概念和架构概览;然后从集群角度出发,从宏观视角学习 RocketMQ 的管控链路、数…...

事件相机技术原理与应用全解析
1. 事件相机技术概述事件相机(Event Camera)是一种革命性的视觉传感器,它彻底改变了传统相机的图像采集方式。与普通相机不同,事件相机不会以固定帧率捕获完整的图像帧,而是异步检测每个像素的亮度变化。当某个像素位置…...

如何成为年薪百万的AI算法工程师?字节跳动AI Lab的内部指南
一、破局:软件测试从业者的AI算法工程师转型契机 在AI技术浪潮的席卷下,软件测试行业正经历着深刻变革,同时也为从业者打开了通往AI算法工程师领域的大门。2026年数据显示,AI在测试行业的渗透率已超40%,新发AI测试岗位…...

HLS技术解析:从原理到FPGA开发实战
1. HLS技术概述与评估背景高等级综合(High-Level Synthesis, HLS)技术正在重塑FPGA开发范式。作为从业十年的硬件加速工程师,我见证了这项技术从实验室走向工业界的全过程。传统RTL开发需要手动编写每一行寄存器传输级代码,而HLS允许开发者用C等高级语言…...

锂离子动力电池机理建模与系统状态评估【附代码】
✨ 长期致力于新能源汽车、动力电池系统、状态监测与评估、Matlab/Simulink研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)全阶电化学-热耦合模型的有…...

<数据集>yolo 易拉罐识别<目标检测>
数据集下载链接https://download.csdn.net/download/qq_53332949/92882375数据集格式:VOCYOLO格式 图片数量:3253张 标注数量(xml文件个数):3253 标注数量(txt文件个数):3253 标注类别数:1 标注类别名称ÿ…...