OpenCV 特征点检测与匹配
一 OpenCV特征场景
①图像搜索,如以图搜图;
②拼图游戏;
③图像拼接,将两长有关联得图拼接到一起;
1 拼图方法
寻找特征
特征是唯一的
可追踪的
能比较的
二 角点
在特征中最重要的是角点
灰度剃度的最大值对应的像素
两条线的角点
极值点(一阶导数最大值,但二阶导数为0)
三 Harris角点
哈里斯角点检测
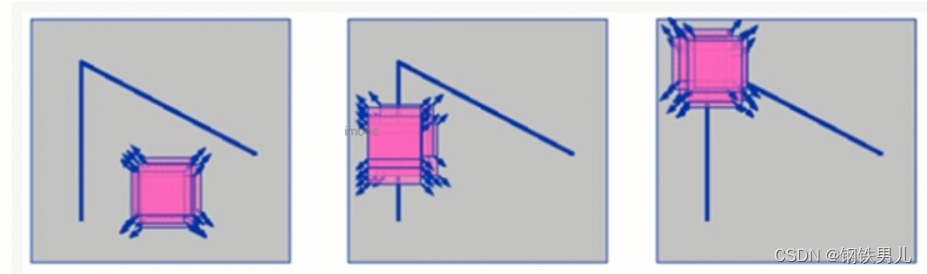
Harris点
① 光滑地区,无论向哪里移动,衡量系数不变;
②边缘地址,垂直边缘移动时,衡量系统变换剧烈;
③在交点处,往哪个方向移动,衡量系统都变化剧烈;
1 Harris角点检测API
cornerHarris(img,dst,blockSize,ksize,k)
blockSize:检测窗口大小
ksize:Sobel的卷积核
k:权重系数,经验值,一般取0.02~0.04之间。
import cv2
import numpy as npblockSize=2ksize=1k=0.04img=cv2.imread('chess.jpg')#灰度化
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#Harris角点检测
dst=cv2.cornerHarris(gray,blockSize,ksize,k)#Harris角点的展示
img[dst>0.04*dst.max()]=[0,0,255]
cv2.imshow('img',img)
cv2.waitKey(0)四 Shi_Tomasi交点检测
Shi-Tomasi是Harris角点检测的改进;
Harris角点检测的稳定性和K有关,而k是个经验值,不好设定最佳值。
1 Shi-Tomasi角点检测API
goodFeaturesToTrack(img,maxCorners,...)
maxCorners:角点的最大数,值为0表示无限制
qualityLevel:小于1.0的正数,一般在0.01~0.1之间
minDistance:角之间最小欧式距离,忽略小于此距离的点。
mask:感兴趣的区域
blockSize:检测窗口
useHarrisDetector:是否使用Harris算法
k:默认是0.04
import cv2
import numpy as npmaxCorners=100
ql=0.01img=cv2.imread('./chess.jpg')
cv2.imshow('img',img)
#灰度化
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)# Shi-Tomasi
corners=cv2.goodFeaturesToTrack(gray,maxCorners,ql,10)
print(corners)
corners=np.int32(corners)
# Shi-Tomasi绘制角点
for i in corners:x,y=i.ravel()cv2.circle(img,(x,y),3,(255,0,0),-1)cv2.imshow('img',img)
cv2.waitKey(0)
五 SIFT(Scale-Invariant Feature Transform)
SIFT出现的原因:
harris 角点具有旋转不变的特性;
但缩放后,原来的角点有可能就不是角点了;
图放大
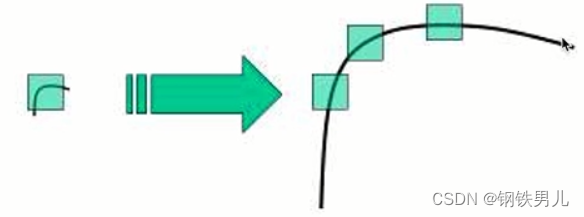
使用SIFT的步骤
①创建SIFT对象
②进行检测,kp=sift.detect(img,…)
③绘制关键点,drawKeypoints(gray,kp,img)
from email.mime import imageimport cv2
import numpy as npimg=cv2.imread('./chess.jpg')gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)sift=cv2.xfeatures2d.SIFT_create()kp=sift.detect(gray,None)cv2.drawKeypoints(gray,kp,img)cv2.imshow('img',img)
cv2.waitKey(0)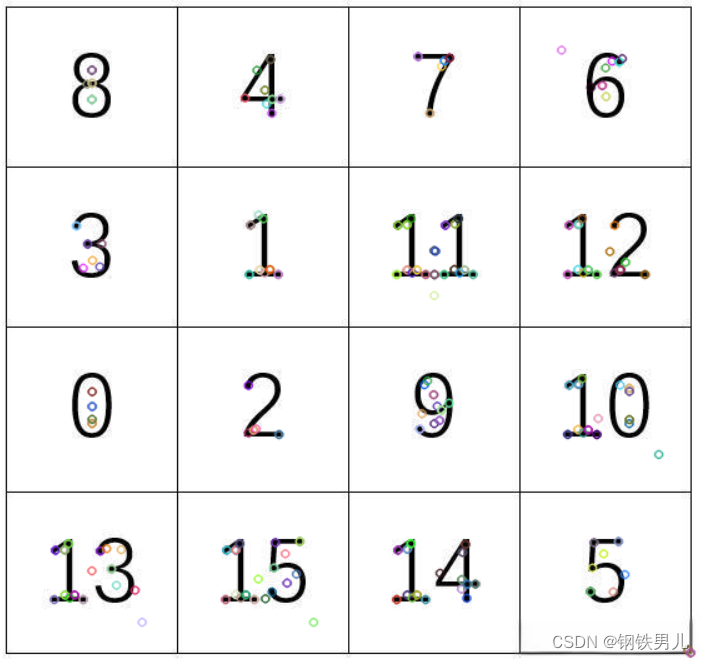
六 SIFT计算描述子
关键点和描述子
关键点:位置,大小和方向
关键点描述子:记录了关键点周围对其有贡献的像素点的一组向量值,其不受仿射变换、光照变换等影响。
计算描述子
kp,des=sift.compute(img,kp)
其作用是进行特征匹配
同时计算关键点和描述
kp,des=sift.detectAndCompute(img,...)
mask:指明对img中哪个区域进行计算
import cv2
import numpy as npimg=cv2.imread('./chess.jpg')gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)sift=cv2.xfeatures2d.SIFT_create()kp,des=sift.detectAndCompute(gray,None)
print(des)
cv2.drawKeypoints(gray,kp,img)cv2.imshow('img',img)
cv2.waitKey(0)
七 SURF特征检测
SURF的优点
SIFT最大的问题是速度慢,因此才有SURF
使用SURF的步骤
surf=cv2.xfeatures2d.SUFR_create()
kp,des=surf.detectAndCompute(img,mask)
import cv2
import numpy as npimg=cv2.imread('./chess.jpg')gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)surf=cv2.xfeatures2d.SURF_create()kp,des=surf.detectAndCompute(gray,None)print(des[0])cv2.drawKeypoints(gray,kp,img)cv2.imshow('img',img)
cv2.waitKey(0)八 ORB(Oriented FAST and Rotated BRIEF)特征检测
1 ORB 优势
①ORB可以做到实时检测
②ORB=Oriented FAST+Rotated BRIEF
2 FAST
可以做到特征点的实时检测
3 BRIEF
BRIEF是对已检测到的特征点进行描述,它加快了特征描述符建立的速度。同时也极大的降低了特征匹配的时间。
3 ORB使用步骤
orb=cv2.ORB_create()
kp,des=orb.detectAndCompute(img,mask)
import cv2
import numpy as npimg=cv2.imread('./chess.jpg')gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)orb=cv2.ORB_create()kp,des=orb.detectAndCompute(gray,None)cv2.drawKeypoints(gray,kp,img)cv2.imshow('img',img)
cv2.waitKey(0)
九 暴力特征匹配
1 特征匹配方法
①BF(Brute-Force),暴力特征匹配方法;
②FLANN最快邻近区特征匹配方法;
它使用第一组中的每个特征的描述子与第二组中的所有特征描述子进行匹配计算它们之间的差距,然后将最接近一个匹配返回。
2 OpenCV特征匹配步骤
创建匹配器,BFMatcher(normType,crossCheck)
进行特征匹配,bf.match(des1,des2)
绘制匹配点,cv2.drawMatches(img1,kp1,img2,k2,...)
BFMatcher
normType:NORM_L1,NORM_L2,HAMMING1....
crossCheck:是否进行交叉匹配,默认为false
Match方法
参数为SIFT,SURF,OBR等计算的描述子
对两幅图的描述子进行计算
drawMatches
搜索img,kp
匹配图img,kp
match()方法返回的匹配结果import cv2
import numpy as npimg=cv2.imread('./opencv_search.png')
img1=cv2.imread('./opencv_orig.png')gray=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray1=cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)sift=cv2.xfeatures2d.SIFT_create()kp1,des1=sift.detectAndCompute(gray,None)
kp2,des2=sift.detectAndCompute(gray1,None)bf=cv2.BFMatcher(cv2.NORM_L1)
match=bf.match(des1,des2)img3=cv2.drawMatches(img,kp1,img1,kp2,match,None)cv2.imshow('img3',img3)
cv2.waitKey(0)

十 FLANN特征匹配
1 FLANN优缺点
在进行批量特征匹配时,FLANN速度更快;
由于它使用的是邻近近似值,所以精度较差;
2 使用FLANN特征匹配的步骤
①创建FLANN匹配器,FlannBasedMatcher(...)
②进行特征匹配,flann.match/knnMatch(...)
③绘制匹配点,cv2.drawMathes/drawMatchesKnn(...)
FlannBasedMathcer
index_params字典:匹配算法KDTREE、LSH
search_params字典:指定KETREE算法中遍历树的次数
KDTREE
index_params=dict(algorithmFLANN_INDEX_KETREE,trees=5)
search_params
search_params=dict(checks=50)
knnMatch方法
参数为SIFT、SURF、ORB等计算的描述子;
k,表示取欧式距离最近的前k个关键点;
返回的是匹配的结果DMatch对象;
DMatch的内容
distance,描述子之间的距离,值越低越好;
queryIdx,第一个图像的描述子索引值;
trainIdx,第二个图的描述子索引值;
imgIdx,第二个图的索引值;drawMatchesKnn
搜索img,kp
匹配图img,kp
match()方法返回的匹配结果
十一 实战FLANN特征匹配
import cv2
import numpy as npimg1=cv2.imread('opencv_search.png')
img2=cv2.imread('opencv_orig.png')gray1=cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
gray2=cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)#创建SIFT特征
sift=cv2.xfeatures2d.SIFT_create()#计算描述子与特征
kp1,des1=sift.detectAndCompute(img1,None)
kp2,des2=sift.detectAndCompute(img2,None)# 创建匹配器
index_params=dict(algorithm=1,trees=5)
search_params=dict(checks=50)
flann=cv2.FlannBasedMatcher(index_params,search_params)#对描述子进行匹配计算
matchs=flann.knnMatch(des1,des2,k=2)good=[]
for i,(m,n)in enumerate(matchs):if m.distance<0.7*n.distance:good.append(m)ret=cv2.drawMatchesKnn(img1,kp1,img2,kp2,[good],None)cv2.imshow('result',ret)
cv2.waitKey(0)
十二 图像查找
1 图像查找
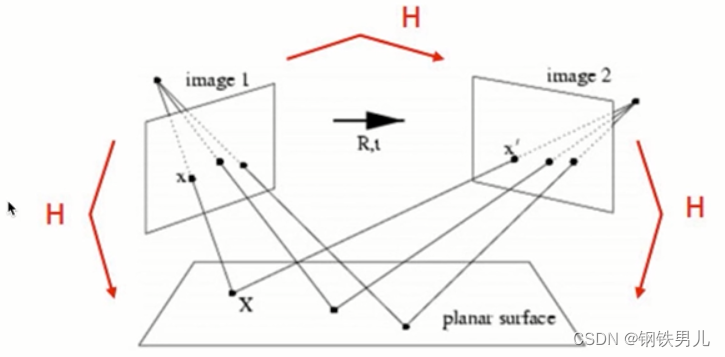
特征匹配+单应性矩阵
什么是单应性矩阵
import cv2
import numpy as npimg1=cv2.imread('opencv_search.png')
img2=cv2.imread('opencv_orig.png')gray1=cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
gray2=cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)#创建SIFT特征
sift=cv2.xfeatures2d.SIFT_create()#计算描述子与特征
kp1,des1=sift.detectAndCompute(img1,None)
kp2,des2=sift.detectAndCompute(img2,None)# 创建匹配器
index_params=dict(algorithm=1,trees=5)
search_params=dict(checks=50)
flann=cv2.FlannBasedMatcher(index_params,search_params)#对描述子进行匹配计算
matchs=flann.knnMatch(des1,des2,k=2)good=[]for i,(m,n) in enumerate(matchs):if m.distance<0.7*n.distance:good.append(m)if len(good)>=4:#print(len(good.trainIdx))srcPts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)dstPts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)H, _ = cv2.findHomography(srcPts, dstPts, cv2.RANSAC, 5.0)h, w = img1.shape[:2]pts = np.float32([[0, 0], [0, h - 1], [w - 1, h - 1], [w - 1, 0]]).reshape(-1, 1, 2)dst = cv2.perspectiveTransform(pts, H)cv2.polylines(img2, [np.int32(dst)], True, (0, 0, 255))
else:print('the number of god is less than 4')exit()ret=cv2.drawMatchesKnn(img1,kp1,img2,kp2,[good],None)cv2.imshow('resutl',ret)cv2.waitKey(0)十三 图像拼接
1 图像合并的步骤
读文件并重置尺寸;
根据特征点和计算描述子,得到单应性矩阵;
图像变换;
图像拼接并输出图像;
import cv2
import numpy as np#第一步 读取文件,将图片设置成一样大小640x640
#第二步 找特征点,描述子,计算单应性矩阵
#第三步 根据单应性矩阵对图像进行变换,然后平移
#第四步 拼接并输出最终结果#读取两张图片
img1=cv2.imread('map1.png')
img2=cv2.imread('map2.png')#将两张同样图片设置成同样大小
img1=cv2.resize(img1,(640,480))
img2=cv2.resize(img2,(640,480))inputs=np.hstack((img1,img2))
cv2.imshow('input img',inputs)
cv2.waitKey(0)
import cv2
import numpy as npdef stitch_image(img1,img2,H):
#获得每张图片的四个角点
#对图片进行变换(单应性矩阵使图进行旋转,平移)
#创建一张大图,将两张图拼接到一起
#将结果输出#获得原始图的高/宽h1,w1=img1.shape[:2]h2,w2=img2.shape[:2]img1_dims=np.float32([[0,0],[0,h1],[w1,h1],[w1,0]]).reshape(-1,1,2)img2_dims=np.float32([[0,0],[0,h2],[w2,h2],[w2,0]]).reshape(-1,1,2)img1_transform=cv2.perspectiveTransform(img1_dims,H)result_dims=np.concatenate((img2_dims,img1_transform),axis=0)[x_min, y_min] = np.int32(result_dims.min(axis=0).ravel() - 0.5)[x_max, y_max] = np.int32(result_dims.max(axis=0).ravel() + 0.5)#平移的距离transform_dist=[-x_min,-y_min]transform_array=np.array([[1,0,transform_dist[0]],[0,1,transform_dist[1]],[0,0,1]])result_img=cv2.warpPerspective(img1,transform_array.dot(H),(x_max-x_min,y_max-y_min))result_img[transform_dist[1]:transform_dist[1]+h2,transform_dist[0]:transform_dist[0]+w2]=img2return result_img#第一步 读取文件,将图片设置成一样大小640x640
#第二步 找特征点,描述子,计算单应性矩阵
#第三步 根据单应性矩阵对图像进行变换,然后平移
#第四步 拼接并输出最终结果def get_homo(img1,img2):
#创建特征转换对象
#通过特征转换对象获得特征点和描述子
#创建特征匹配器
#进行特征匹配
#过滤特征,找出有效的特征匹配点sift=cv2.xfeatures2d.SIFT_create()k1,d1=sift.detectAndCompute(img1,None)k2,d2=sift.detectAndCompute(img2,None)#创建特征匹配bf=cv2.BFMatcher()matches=bf.knnMatch(d1,d2,k=2)
#过滤特征,找出有效的特征匹配点verify_ratio=0.8verify_matches=[]for m1,m2 in matches:if m1.distance<0.8*m2.distance:verify_matches.append(m1)min_matches=8if len(verify_matches)>min_matches:img1_pts=[]img2_pts=[]for m in verify_matches:img1_pts.append(k1[m.queryIdx].pt)img2_pts.append(k2[m.trainIdx].pt)img1_pts=np.float32(img1_pts).reshape(-1,1,2)img2_pts=np.float32(img2_pts).reshape(-1,1,2)H,mask=cv2.findHomography(img1_pts,img2_pts,cv2.RANSAC,5.0)return Helse:print("err:Not enough matches!")exit()
#第一步 读取文件,将图片设置成一样大小640x480
#第二步 找特征点,描述子,计算单应性矩阵
#第三步 根据单应性矩阵对图像进行变换,然后平移
#第四步 拼接并输出最终结果#读取两张图片
img1=cv2.imread('map1.png')
img2=cv2.imread('map2.png')#将两张同样图片设置成同样大小
img1=cv2.resize(img1,(640,480))
img2=cv2.resize(img2,(640,480))inputs=np.hstack((img1,img2))#获得单应性矩阵
H=get_homo(img1,img2)#进行图像拼接
result_image=stitch_image(img1,img2,H)cv2.imshow('input img',inputs)
cv2.waitKey(0)
相关文章:
OpenCV 特征点检测与匹配
一 OpenCV特征场景 ①图像搜索,如以图搜图; ②拼图游戏; ③图像拼接,将两长有关联得图拼接到一起; 1 拼图方法 寻找特征 特征是唯一的 可追踪的 能比较的 二 角点 在特征中最重要的是角点 灰度剃度的最大值对应的…...

css布局之flex应用
/*父 100*/.parent-div {/* 这里添加你想要的属性 */display: flex;flex-direction: row; //行justify-content: space-between; //左右对齐align-items: center;flex-wrap: wrap; //换行}/*中 90 10 */.middle-div {/* 这里添加你想要的属性 */display: flex;flex-direction:…...

树莓派4B设置AP热点步骤
树莓派4B设置AP热点步骤:先进入root模式 预先进行apt-get update 第1步:安装network-manager sudo apt-get install network-manager第2步:安装git apt-get install git apt-get install util-linux procps hostapd iproute2 iw haveged …...
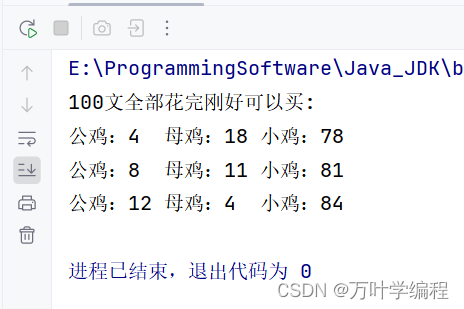
Java程序之百鸡百钱问题
题目: 百钱买百鸡的问题算是一套非常经典的不定方程的问题,题目很简单:公鸡5文钱一只,母鸡3文钱一只,小鸡3只一文钱,用100文钱买一百只鸡,其中公鸡,母鸡,小鸡都必须要有,…...

Mybatis——动态sql
if标签 用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接sql。 <where>标签用于识别语句是否需要连接词and,识别sql语句。 package com.t0.maybatisc.mapper;import com.t0.maybatisc.pojo.Emp; import org.a…...

可视化大屏开发系列——页面布局
页面布局是可视化大屏的基础,想要拥有一个基本美观的大屏,就得考虑页面整体模块的宽高自适应,我们自然就会想到具有强大灵活性flex布局,再借助百分比布局来辅助。至此,大屏页面布局问题即可得到解决。 可视化大屏开发系…...

Python statistics 模块
Python 的 statistics 模块提供了一组用于执行各种统计计算的函数,包括平均值、中位数、标准差、方差以及其他统计量。让我来简单介绍一下。 首先,你可以使用以下方式导入 statistics 模块: python import statistics 接下来,…...

wireshark常见使用表达式
目录 1. 捕获过滤器 (Capture Filters)基本捕获过滤器组合捕获过滤器 2. 显示过滤器 (Display Filters)基本显示过滤器复杂显示过滤器协议特定显示过滤器 3. 进阶显示过滤器技巧使用函数和操作符逻辑操作符 4. 常见网络协议过滤表达式示例HTTP 协议HTTPS 协议DNS 协议DHCP 协议…...

用Java获取键盘输入数的个十百位数
这段Java代码是一个简单的程序,用于接收用户输入的一个三位数,并将其分解为个位、十位和百位数字,然后分别打印出来。下面是代码的详细解释: 导入所需类库: import java.util.Scanner;:导入Scanner类,用于从…...

第10章 启动过程组 (制定项目章程)
第10章 启动过程组 9.1制定项目章程,在第三版教材第356~360页; 文字图片音频方式 视频12 第一个知识点:主要输出 1、项目章程(重要知识点) 项目目的 为了稳定与发展公司的客户群(抽象,非具体) 可测量的项目…...
html侧导航栏客服栏
ico 替换 ICO <html xmlns"http://www.w3.org/1999/xhtml"><head><meta http-equiv"Content-Type" content"text/html; charsetutf-8"><title>返回顶部</title><script src"js/jquery-2.0.3.min.js"…...
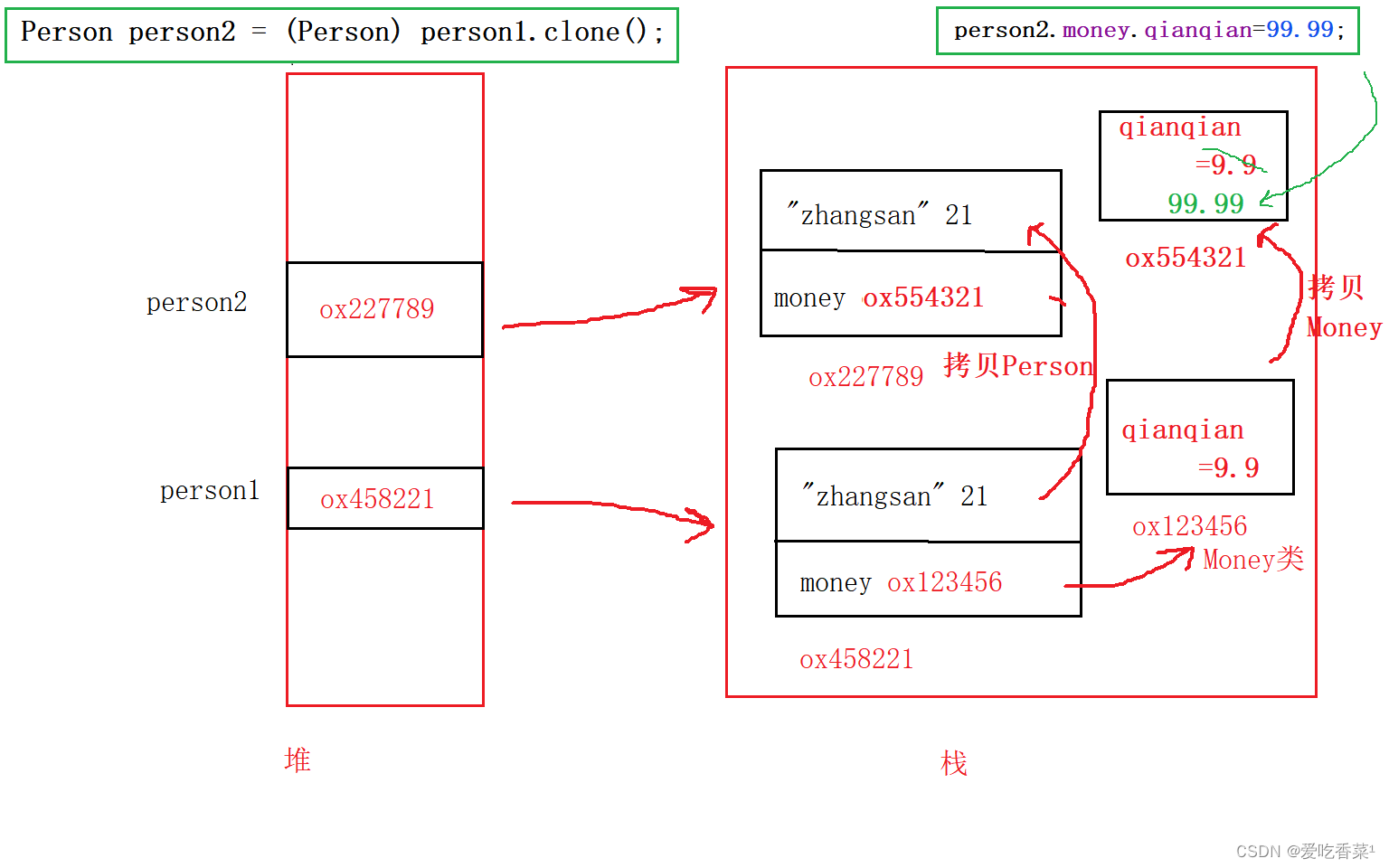
Clonable接口和拷贝
Hello~小伙伴们!本篇学习Clonable接口与深拷贝,一起往下看吧~(画图水平有限,两张图,,我真的画了巨久,求路过的朋友来个3连~阿阿阿~~~) 目录 1、Clonable接口概念 2、拷贝 2、1浅拷贝 2、2深拷贝 1、Clon…...

关于小蛋の编程和小蛋编程为同一作者的说明
小蛋の编程和小蛋编程的作品为同一人制作,因前者为父母的手机号进行注册,现用本人手机号注册了新账号小蛋编程,后续文章将在新账号小蛋编程上进行刊登,同时在小蛋编程上对原账号文章进行转载。此账号不再发布帖子,请大…...

大数据平台之Spark
Apache Spark 是一个开源的分布式计算系统,主要用于大规模数据处理和分析。它由UC Berkeley AMPLab开发,并由Apache Software Foundation维护。Spark旨在提供比Hadoop MapReduce更快的处理速度和更丰富的功能,特别是在处理迭代算法和交互式数…...

How to use ModelSim
How to use ModelSim These are all written by a robot Remember, you can only simulate tb files....

【专业英语 复习】第8章 Communications and Networks
1. 单选题 One of the most dramatic changes in connectivity and communications in the past few years has been ____. A. widespread use of mobile devices with wireless Internet connectivity B. chat rooms C. satellite uplinks D. running programs on rem…...

运行vue3项目相关报错
1. VSCode打开TSVue3项目很多地方报错 报错内容 几乎所有文件都会出现未知飘红 error Delete CR prettier/prettier报错原因 插件冲突,Windows系统回车换行符与MAC不一致(所以这个问题Windows系统才会出现) 解决 需要安装Vue - Official…...
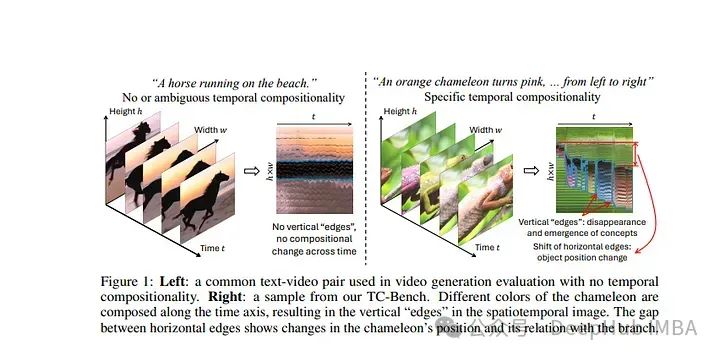
2024年6月计算机视觉论文推荐:扩散模型、视觉语言模型、视频生成等
6月还有一周就要结束了,我们今天来总结2024年6月上半月发表的最重要的论文,重点介绍了计算机视觉领域的最新研究和进展。 Diffusion Models 1、Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation LlamaGen,是一个…...
Centos Stream9 和Centos Stream10的下载网址
Index of /https://mirror.stream.centos.org/...
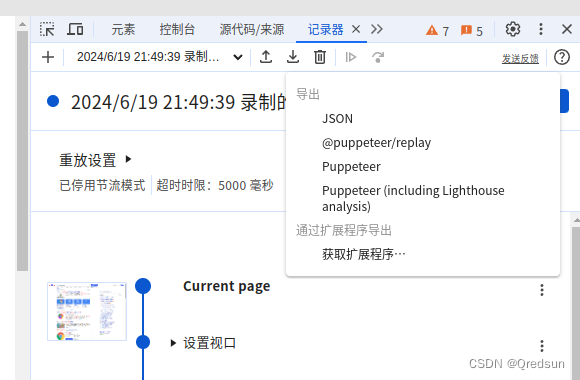
chrome 录制器及性能分析工具的使用
需求背景: 对比不同VPN方案网络延迟的差异。 验证工具: chrome浏览器自带的录制器、性能插件可以完美的解决这个问题。 注意:录制的操作都在当前页面,不存在新开标签页的场景 解决方案: 使用chrome录制器…...

如何用OpenWebRTC实现音视频通话:完整开发教程
如何用OpenWebRTC实现音视频通话:完整开发教程 【免费下载链接】openwebrtc A cross-platform WebRTC client framework based on GStreamer 项目地址: https://gitcode.com/gh_mirrors/op/openwebrtc OpenWebRTC是一个基于GStreamer的跨平台WebRTC客户端框架…...
)
告别默认视图:5个CloudCompare点云可视化高级技巧(颜色映射、尺寸分级、OpenGL优化)
告别默认视图:5个CloudCompare点云可视化高级技巧(颜色映射、尺寸分级、OpenGL优化) 在三维点云处理领域,可视化效果直接影响数据分析的深度与决策效率。CloudCompare作为开源点云处理利器,其默认视图设置往往难以满足…...

紫光同创PGL22G开发板DDR3读写实验:从IP核安装到上板验证的保姆级避坑指南
紫光同创PGL22G开发板DDR3读写实验全流程实战解析 第一次接触国产FPGA平台进行DDR3内存控制实验时,很多开发者都会遇到各种"坑"。本文将基于紫光同创PGL22G开发板,从IP核安装到最终上板验证,手把手带你避开那些容易出错的关键环节。…...

如何快速制作专业演示文稿?终极免费开源在线PPT工具PPTist完整指南
如何快速制作专业演示文稿?终极免费开源在线PPT工具PPTist完整指南 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint,…...

联想拯救者工具箱:让游戏本性能释放更自由的开源神器
联想拯救者工具箱:让游戏本性能释放更自由的开源神器 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit 联想拯救者…...

Linux驱动调试利器:debugfs接口设计与实现详解
1. 项目概述:为什么我们需要debugfs?在Linux内核驱动的开发与调试过程中,我们常常面临一个核心痛点:如何在不重启系统、不重新编译驱动、甚至不借助复杂外部工具的情况下,实时地窥探驱动内部的状态、修改关键参数&…...

Cream开发者进阶指南:深入理解架构搜索算法
Cream开发者进阶指南:深入理解架构搜索算法 【免费下载链接】Cream This is a collection of our NAS and Vision Transformer work. 项目地址: https://gitcode.com/gh_mirrors/cr/Cream 在深度学习模型设计领域,神经架构搜索(NAS&am…...

PowerShdll源码深度分析:从DLL导出到控制台劫持的完整实现原理
PowerShdll源码深度分析:从DLL导出到控制台劫持的完整实现原理 【免费下载链接】PowerShdll Run PowerShell with rundll32. Bypass software restrictions. 项目地址: https://gitcode.com/gh_mirrors/po/PowerShdll PowerShdll是一个创新的PowerShell绕过工…...
)
Linux蓝牙SPP连接保姆级教程:从手机App到开发板双向通信实战(Android/iOS)
Linux蓝牙SPP连接实战:手机与开发板双向通信全指南 当智能家居控制面板需要无线接收手机指令,或是工业传感器数据要通过移动设备实时查看时,蓝牙串口协议(SPP)便成为最便捷的桥梁。不同于常见的蓝牙音频传输,SPP提供了稳定的数据通…...
动态加载)
PyQt5开发避坑:别再手动编译.ui文件了,试试uic.loadUi()动态加载
PyQt5高效开发:uic.loadUi()动态加载技术深度解析 在快速迭代的GUI开发过程中,PyQt5开发者常陷入一个效率陷阱——每次修改界面后都需要手动执行pyuic编译命令。这种重复性操作不仅打断开发流状态,还会在频繁调整阶段浪费大量时间。本文将揭示…...