SQL题:未完成率较高的50%用户近三个月答卷情况
SQL题:未完成率较高的50%用户近三个月答卷情况
这是一道牛客网上SQL进阶图库中的一道困难题目,个人花了近两个小时才通过所有用例。之所以想记录下来是因为这道题算是一个很考验基本功的题目,也不乏一些SQL中的技巧。下面我们逐步分析:
描述
现有用户信息表user_info(uid用户ID,nick_name昵称, achievement成就值, level等级, job职业方向, register_time注册时间):
| id | uid | nick_name | achievement | level | job | register_time |
|---|---|---|---|---|---|---|
| 1 | 1001 | 牛客1号 | 3200 | 7 | 算法 | 2020-01-01 10:00:00 |
| 2 | 1002 | 牛客2号 | 2500 | 6 | 算法 | 2020-01-01 10:00:00 |
| 3 | 1003 | 牛客3号 | 2200 | 5 | 算法 | 2020-01-01 10:00:00 |
试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间):
| id | exam_id | tag | difficulty | duration | release_time |
|---|---|---|---|---|---|
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
| 2 | 9002 | SQL | hard | 80 | 2020-01-01 10:00:00 |
| 3 | 9003 | 算法 | hard | 80 | 2020-01-01 10:00:00 |
| 4 | 9004 | PYTHON | medium | 70 | 2020-01-01 10:00:00 |
试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):
| id | uid | exam_id | start_time | submit_time | score |
|---|---|---|---|---|---|
| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
| 15 | 1002 | 9001 | 2020-01-01 18:01:01 | 2020-01-01 18:59:02 | 90 |
| 13 | 1001 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
| 2 | 1002 | 9001 | 2020-01-20 10:01:01 | ||
| 3 | 1002 | 9001 | 2020-02-01 12:11:01 | ||
| 5 | 1001 | 9001 | 2020-03-01 12:01:01 | ||
| 6 | 1002 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
| 4 | 1003 | 9001 | 2020-03-01 19:01:01 | ||
| 7 | 1002 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 90 |
| 14 | 1001 | 9002 | 2020-01-01 12:11:01 | ||
| 8 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:59:01 | 69 |
| 9 | 1001 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
| 10 | 1002 | 9002 | 2020-02-02 12:01:01 | ||
| 11 | 1002 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:43:01 | 81 |
| 12 | 1002 | 9002 | 2020-03-02 12:11:01 | ||
| 17 | 1001 | 9002 | 2020-05-05 18:01:01 | ||
| 16 | 1002 | 9003 | 2020-05-06 12:01:01 |
请统计SQL试卷上未完成率较高的50%用户中,6级和7级用户在有试卷作答记录的近三个月中,每个月的答卷数目和完成数目。按用户ID、月份升序排序。
由示例数据结果输出如下:
| uid | start_month | total_cnt | complete_cnt |
|---|---|---|---|
| 1002 | 202002 | 3 | 1 |
| 1002 | 202003 | 2 | 1 |
| 1002 | 202005 | 2 | 1 |
解释:各个用户对SQL试卷的未完成数、作答总数、未完成率如下:
| uid | incomplete_cnt | total_cnt | incomplete_rate |
|---|---|---|---|
| 1001 | 3 | 7 | 0.4286 |
| 1002 | 4 | 8 | 0.5000 |
| 1003 | 1 | 1 | 1.0000 |
1001、1002、1003分别排在1.0、0.5、0.0的位置,因此较高的50%用户(排位<=0.5)为1002、1003;
1003不是6级或7级;
有试卷作答记录的近三个月为202005、202003、202002;
这三个月里1002的作答题数分别为3、2、2,完成数目分别为1、1、1。
###解法:
这道题看起来很复杂,需要我们划分多个步骤,进行多次SQL嵌套才能完成。
**步骤一.**首先需要统计各个用户对SQL试卷的未完成数、作答总数、未完成率。其中需要确保试卷是SQL试卷。需要注意的是,这一步需要考虑多增加一列未完成率排名,排名应该使用开窗函数。SQL写法如下:
select exam_record.uid,
sum(case when submit_time is null then 1 else 0 end) incomplete_cnt,
count(1) total_cnt,
round(sum(case when submit_time is null then 1 else 0 end)/(count(1)), 4) incomplete_rate ,
user_info.level,
row_number() over(order by round(sum(case when submit_time is null then 1 else 0 end)/(count(1)), 4)) r
from exam_record
inner join user_info
on user_info.uid = exam_record.uid
inner join examination_info
on exam_record.exam_id = examination_info.exam_id
where examination_info.tag = 'SQL'
group by exam_record.uid
order by incomplete_rate
下一步则根据上一步所得出的数据筛选出哪些用户未完成率排在前50%且是6级或7级用户,加上将上一步SQL所得出的表命名为表a,可写如下sql进行筛选:
select a.uid from a
where r >= (select floor(count(distinct uid)/2) from exam_record) + 1 and (a.level = 6 or a.level = 7)
此时我们就得出了应该被算入最终统计结果的所有用户uid。
**步骤二.**下一步需要考虑统计用户近三个月的总答题数和完成数。此时需要注意的是需要选出近三个月,因而至少需要一次针对不同用户uid和start_month的排序。代码如下:
select exam_record.uid,
date_format(exam_record.start_time,"%Y%m") start_month,
count(1) over(partition by exam_record.uid, date_format(exam_record.start_time,"%Y%m")) total_cnt,
sum(case when exam_record.submit_time is null then 0 else 1 end) over(partition by exam_record.uid , date_format(exam_record.start_time,"%Y%m")) complete_cnt,
dense_rank() over(partition by exam_record.uid order by date_format(exam_record.start_time,'%Y%m') desc) x
from exam_record
上段代码包含了复杂的开窗,其实主要是针对不同用户uid和start_month进行聚合,统计当月的答题总数total_cnt和当月的总完成数complete_cnt。需要注意的是,我们添加了一次排序使用的是dense_rank()进行排序,目的是同时达到筛选前三个月的数据和去重。将上一个SQL所得出的表命名为表t,SQL写法如下:
select t.uid,t.start_month,t.total_cnt, t.complete_cnt
from t
where t.x <= 3
group by t.uid,t.start_month,t.total_cnt, t.complete_cnt
order by t.uid,t.start_month
以上代码很重要,同时达到去重和选取固定行数的目的,是重要的SQL技巧。
**步骤三.**下面我们将以上两个步骤的所有代码结合起来,得出最终的解:
select t.uid,t.start_month,t.total_cnt, t.complete_cnt /*除去下面注释部分所标注的内容都是步骤二所完成查询*/
from (
select exam_record.uid,
date_format(exam_record.start_time,"%Y%m") start_month,
count(1) over(partition by exam_record.uid , date_format(exam_record.start_time,"%Y%m")) total_cnt,
sum(case when exam_record.submit_time is null then 0 else 1 end) over(partition by exam_record.uid , date_format(exam_record.start_time,"%Y%m")) complete_cnt,
dense_rank() over(partition by exam_record.uid order by date_format(exam_record.start_time,'%Y%m') desc) x
from exam_record
where exam_record.uid in ( /*这里对uid的筛选其实主要是从步骤一中得出的结果中筛选*/
select a.uid from
(
select exam_record.uid,
sum(case when submit_time is null then 1 else 0 end) incomplete_cnt,
count(1) total_cnt,
round(sum(case when submit_time is null then 1 else 0 end)/(count(1)), 4) incomplete_rate ,
user_info.level,
row_number() over(order by round(sum(case when submit_time is null then 1 else 0 end)/(count(1)), 4)) r
from exam_record
inner join user_info
on user_info.uid = exam_record.uid
inner join examination_info
on exam_record.exam_id = examination_info.exam_id
where examination_info.tag = 'SQL'
group by exam_record.uid
order by incomplete_rate
) a
where r >= (select floor(count(distinct uid)/2) from exam_record) + 1 and (a.level = 6 or a.level = 7)
)
) t
where t.x <= 3
group by t.uid,t.start_month,t.total_cnt, t.complete_cnt
order by t.uid,t.start_month
比较复杂,详细查看前两步,才能看懂最终结合的逻辑。
相关文章:

SQL题:未完成率较高的50%用户近三个月答卷情况
SQL题:未完成率较高的50%用户近三个月答卷情况 这是一道牛客网上SQL进阶图库中的一道困难题目,个人花了近两个小时才通过所有用例。之所以想记录下来是因为这道题算是一个很考验基本功的题目,也不乏一些SQL中的技巧。下面我们逐步分析&#…...

挑战与机遇的交织
AI与音乐创作:挑战与机遇的交织 引言 近年来,人工智能技术的迅猛发展使得其在各个领域都展现出了巨大的潜力和影响力,音乐创作领域也不例外。最近上线的音乐大模型,无疑是这一趋势的一个重要节点,它极大地降低了素人…...
Java项目:基于SSM框架实现的精品酒销售管理系统分前后台【ssm+B/S架构+源码+数据库+毕业论文】
一、项目简介 本项目是一套基于SSM框架实现的精品酒销售管理系统 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,eclipse或者idea 确保可以运行! 该系统功能完善、界面美观、操作简单、功…...

[论文笔记]Are Large Language Models All You Need for Task-Oriented Dialogue?
引言 今天带来论文Are Large Language Models All You Need for Task-Oriented Dialogue?的笔记。 主要评估了LLM在完成多轮对话任务以及同外部数据库进行交互的能力。在明确的信念状态跟踪方面,LLMs的表现不及专门的任务特定模型。然而,如果为它们提…...
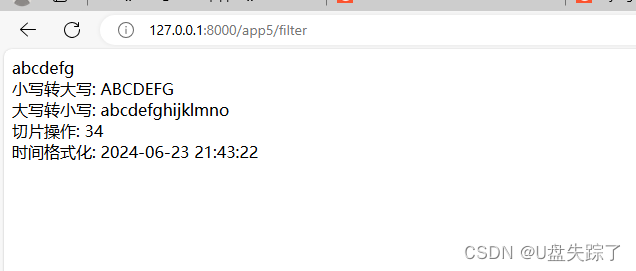
Django 模版过滤器
Django模版过滤器是一个非常有用的功能,它允许我们在模版中处理数据。过滤器看起来像这样:{{ name|lower }},这将把变量name的值转换为小写。 1,创建应用 python manage.py startapp app5 2,注册应用 Test/Test/sett…...
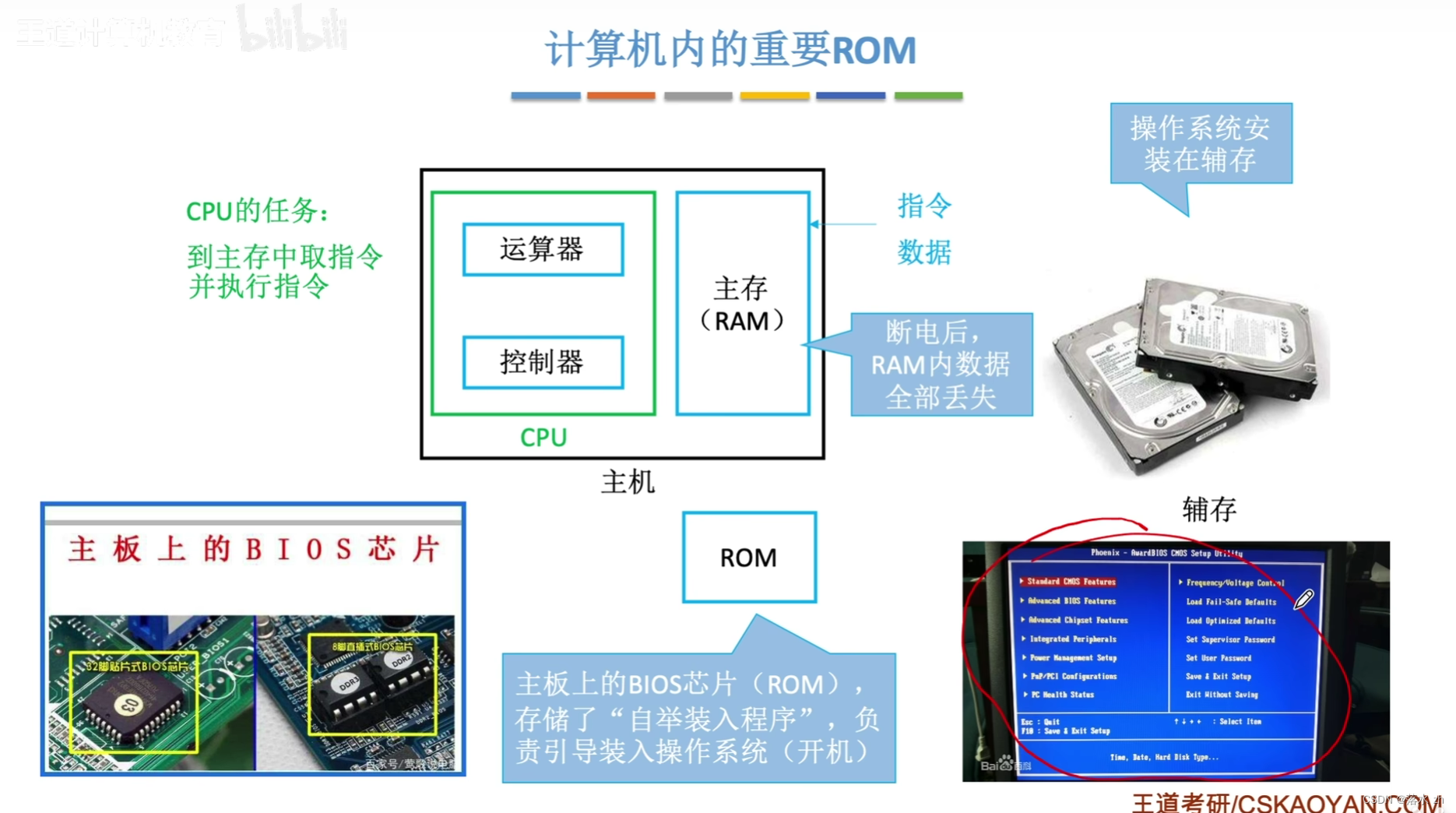
计算机组成原理 —— 存储系统(DRAM和SRAM,ROM)
计算机组成原理 —— 存储系统(DRAM和SRAM) DRAM和SRAMDRAM的刷新DRAM地址复用ROM(Read-Only Memory(只读存储器)) 我们今天来看DRAM和SRAM: DRAM和SRAM DRAM(动态随机存取存储器&…...
第22篇 Intel FPGA Monitor Program的使用<五>
Q:如何用Intel FPGA Monitor Program创建C语言工程并运行呢? A:总体过程与创建汇编语言工程类似,不同的是在指定程序类型时选择C Program。 后续用到DE2-115开发板的硬件如LED、SW和HEX等外设时,还需要将描述定义这些…...

网信办公布第六批深度合成服务算法备案清单,深兰科技大模型入选
6月12日,国家互联网信息办公室发布了第六批深度合成服务算法备案信息,深兰科技硅基知识智能对话多模态大模型算法通过相关审核,成功入选该批次《境内深度合成服务算法备案清单》。同时入选的还有腾讯混元大模型多模态算法、支付宝图像生成算法…...

ES 8.14 向量搜索优化
参考:https://blog.csdn.net/UbuntuTouch/article/details/139502650 检索器(standard、kNN 和 RRF) 检索器(retrievers)是搜索 API 中的一种新抽象概念,用于描述如何检索一组顶级文档。检索器被设计为可以…...

查看 MAC 的 shell 配置文件
在Mac上,shell的配置文件主要取决于您当前使用的shell。从macOS Catalina开始,Mac使用zsh作为默认登录Shell和交互式Shell。以下是关于Mac上zsh shell配置文件的一些详细信息: 查看当前使用的shell: 要查看当前正在使用的shell&am…...
前端下载文件流,axios设置responseType: arraybuffer/blob无效
项目中调用后端下载文件接口,设置responseType: arraybuffer,实际拿到的数据data是字符串 axios({method: post,url: /api/v1/records/recording-file/play,// 如果有需要发送的数据,可以放在这里data: { uuid: 06e7075d-4ce0-476f-88cb-87fb0a1b4844 }…...
代码实践 -卷积神经网络-14模型构造)
动手学深度学习(Pytorch版)代码实践 -卷积神经网络-14模型构造
14模型构造 import torch from torch import nn from torch.nn import functional as F#通过实例化nn.Sequential来构建我们的模型, 层的执行顺序是作为参数传递的 net1 nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256,10)) """ nn.…...
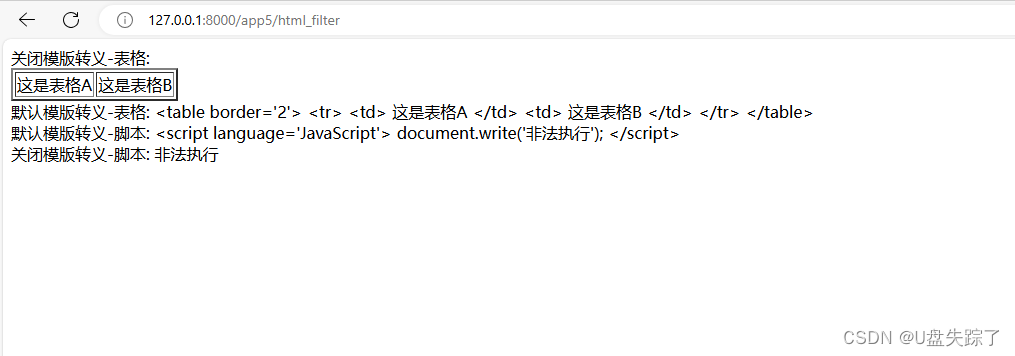
Django 模版转义
1,模版转义的作用 Django模版系统默认会自动转义所有变量。这意味着,如果你在模版中输出一个变量,它的内容会被转义,以防止跨站脚本攻击(XSS)。例如,如果你的变量包含HTML标签,这些…...
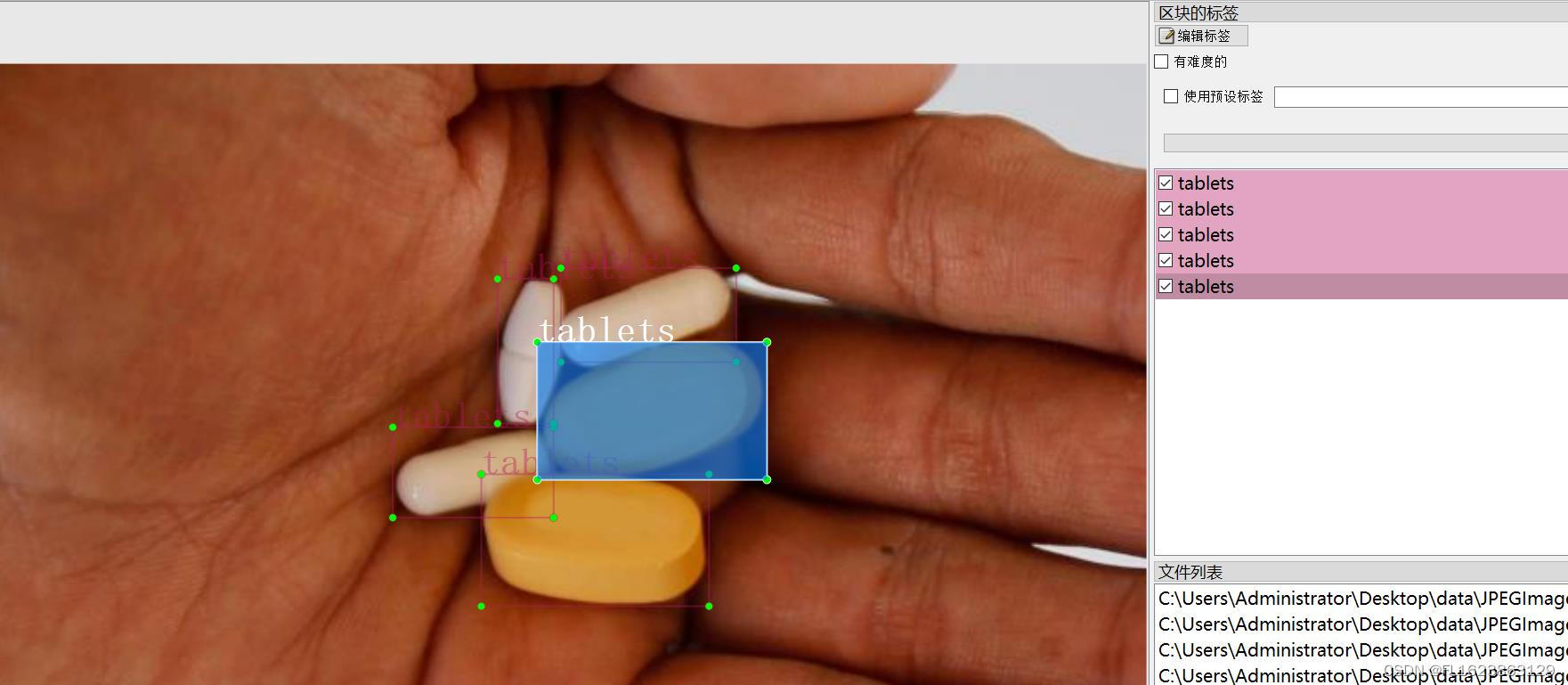
[数据集][目标检测]药片药丸检测数据集VOC+YOLO格式152张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):152 标注数量(xml文件个数):152 标注数量(txt文件个数):152 标注类别…...
)
Android SurfaceFlinger——HWC图层合成器加载(四)
在前面文章中的 Android.bp 文件中,我们可以看到里面加载了图层合成器和图形内存分配器的 HAL 服务,这里篇我们就来详细介绍一下其中的图层合成器——HWC。 一、HWC简介 HWC,全称为 Hardware Composer,是 Android 系统中一个至关重要的组件,位于硬件抽象层(HAL)。它的主…...

OpenCV--图像金字塔
图像金字塔 图像金字塔高斯金字塔拉普拉斯金字塔 图像金字塔 import cv2""" 图像金字塔:同一图像不同分辨率的子图合集 主要用于图像分割 """高斯金字塔 """ 高斯金字塔:通过高斯平滑和亚采样(采样后图像…...

创意产业如何应对AI的挑战。
最近的一个月,音乐领域迎来了一个革命性的变化。一系列音乐大模型轮番上线,它们以惊人的创作能力,将素人生产音乐的门槛降到了最低。这些AI音乐模型的出现,引发了关于AI是否会彻底颠覆音乐圈的讨论。然而,短暂的兴奋过…...

设计模式——工厂方法模式
文章目录 工厂方法模式简介工厂方法模式的组成部分工厂方法模式的结构Factory和Method的含义工厂方法模式的应用场景工厂方法模式的示例1. 文档生成器2. 数据库连接 工厂方法模式简介 工厂方法模式(Factory Method Pattern)是一种创建型设计模式&#x…...

apksigner jarsigner.md
关于作者:CSDN内容合伙人、技术专家, 从零开始做日活千万级APP。 专注于分享各领域原创系列文章 ,擅长java后端、移动开发、商业变现、人工智能等,希望大家多多支持。 目录 一、导读二、概览三、apksigner3.2 为 APK 签名3.3 验证…...

在SQL中使用explode函数展开数组的详细指南
目录 简介示例1:简单数组展开示例2:展开嵌套数组示例3:与其他函数结合使用处理结构体数组示例:展开包含结构体的数组示例2:展开嵌套结构体数组 总结 简介 在处理SQL中的数组数据时,explode函数非常有用。它…...

如何免费解锁WeMod专业版:2026年终极完整指南
如何免费解锁WeMod专业版:2026年终极完整指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂费用而烦恼吗…...

Wand-Enhancer:免费解锁WeMod专业版功能的终极本地增强工具
Wand-Enhancer:免费解锁WeMod专业版功能的终极本地增强工具 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂订阅费用…...

3倍效率提升:Gofile批量下载工具实战指南
3倍效率提升:Gofile批量下载工具实战指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 您是否曾为Gofile平台的文件下载效率低下而烦恼?当面对大文…...

Cursor IDE事件日志分析工具:Python实现开发者行为可视化与效率洞察
1. 项目概述:一个为开发者“把脉”的智能分析工具如果你是一名开发者,尤其是深度使用Cursor这类AI编程助手的开发者,你肯定有过这样的体验:面对一个复杂的项目,你向AI助手提了无数个问题,生成了大量代码片段…...

阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程
阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师自动化脚本OAS是一款专门为《阴阳师》游戏设计的智能自动…...

AI驱动的Web可访问性审查:LLM如何成为你的自动化无障碍专家
1. 项目概述:一个为AI智能体而生,却意外照亮了所有人的可访问性审查工具 最近在折腾AI智能体(AI Agent)的开发,一个老问题又浮上水面:怎么确保我造出来的这个“数字员工”,能真正服务好所有人&…...

【ElevenLabs情绪模拟技术白皮书】:基于2,147小时情感语音标注数据集的11类基础情绪迁移模型验证报告
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术白皮书概述 ElevenLabs的情绪模拟技术并非简单调节音高或语速,而是基于多模态情感表征学习(Multimodal Affective Representation Learning, MARL&#x…...

从零打造会“看”的电子眼:Teensy与OLED的嵌入式图形与传感器实践
1. 项目概述:打造一个会“看”的电子生命体几年前,我第一次在创客社区看到“Uncanny Eyes”项目时就被深深吸引了。一个微小的OLED屏幕,在代码驱动下,竟然能呈现出如此逼真、灵动的眼球运动,那种介于生命与机械之间的诡…...

Kubernetes部署Valheim游戏服务器:云原生技术赋能游戏运维实践
1. 项目概述:当维京英灵殿遇上容器编排如果你和我一样,既沉迷于《英灵神殿》(Valheim)里与好友共建家园、挑战上古巨兽的乐趣,又恰好是一名整天和Kubernetes(k8s)打交道的开发者或运维ÿ…...
架构与实现)
基于RAG与向量数据库的智能信息管理系统(IIMS)架构与实现
1. 项目概述:当AI成为你的“第二大脑”最近在折腾一个挺有意思的项目,叫“IIMS-By-AI”。乍一看这个标题,可能有点摸不着头脑,但拆解一下就能明白它的野心:IntelligentInformationManagementSystem, By AI。…...