[论文笔记]Are Large Language Models All You Need for Task-Oriented Dialogue?
引言
今天带来论文Are Large Language Models All You Need for Task-Oriented Dialogue?的笔记。
主要评估了LLM在完成多轮对话任务以及同外部数据库进行交互的能力。在明确的信念状态跟踪方面,LLMs的表现不及专门的任务特定模型。然而,如果为它们提供了正确的槽值,它们可以通过生成的回复引导对话顺利结束。
1. 总体介绍
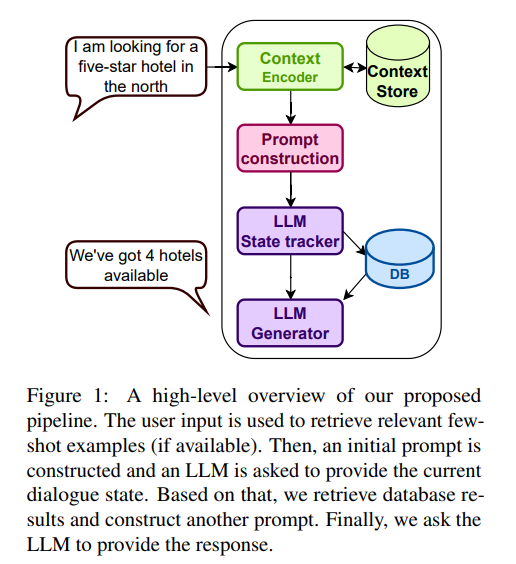
本篇工作在任务导向对话(Task Oriented Dialouge,TOD)上评估LLM的性能。为此引入了基于LLM的TOD对话流水线(图1)。使用状态跟踪和响应生成作为两个主要的步骤,隐含了对话策略的功能。在零样本设定下,模型仅接收领域描述,在少样本设定下,使用了一些检索到的示例。在https://github.com/vojtsek/to-llm-bot上发布了实验代码。
2. 相关工作
介绍了大语言模型和指令微调。 重点是下面两个:
基于语言模型的TOD建模 Zhang等人和Peng等人引入了基于预训练语言模型的任务导向对话建模,他们遵循了Lei等人提出的基于文本的状态编码和两阶段生成方法:首先使用语言模型解码结构化的信念状态,表示为文本。然后使用信念状态检索数据库信息,并再次调用语言模型生成响应,该响应以信念状态和检索到的信息为条件。其他人则提出了生成模型与检索式方法的结合。这些方法都在领域内的数据上进行了微调,和作者采用的纯上下文学习方法形成了对比。
少样本对话建模 是一种专注于从少量领域内样例中学习对话的神经模型的方法之一,最早的这种方法是基于循环神经网络的可训练混合代码网络,其中部分组件采用手工制作。较新的方法利用了预训练Transformer语言模型的能力。Hu等人使用了LLMs和上下文学习来进行信念状态跟踪,将任务制定为SQL查询生成。
3. 方法
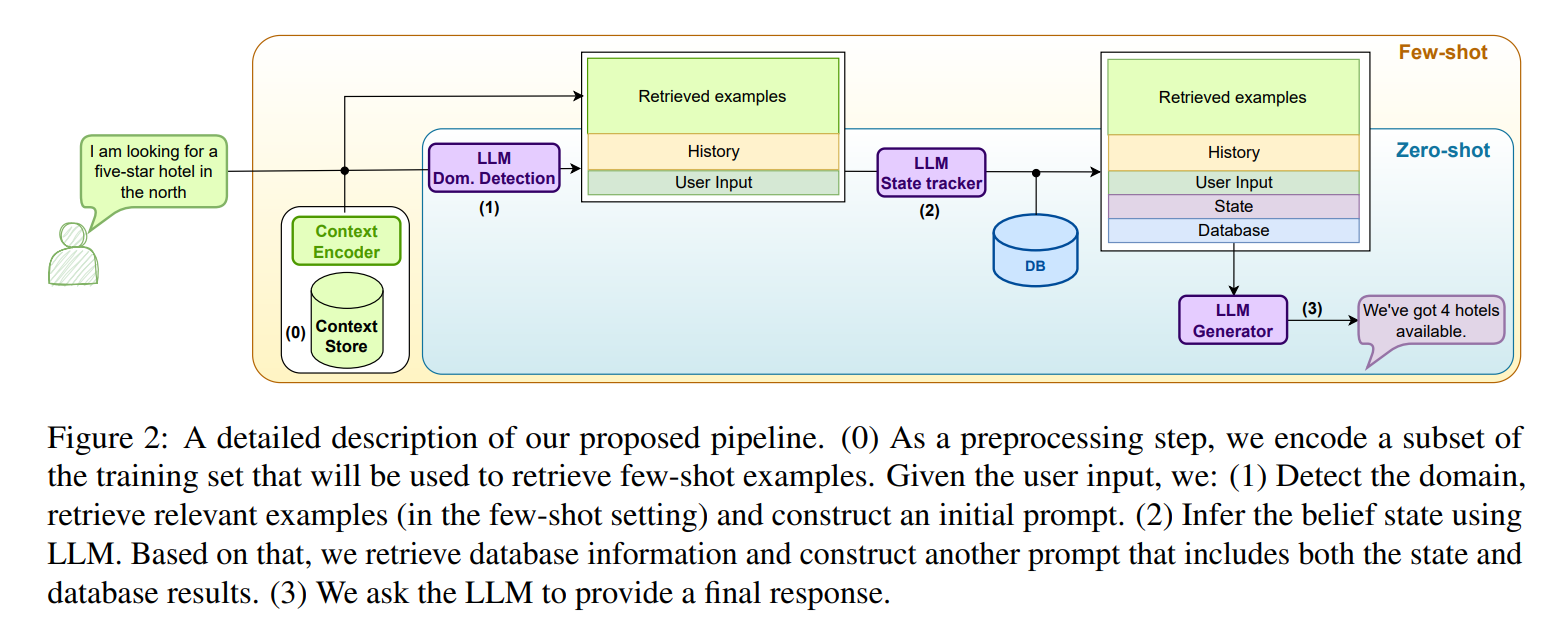
图2显示了所提出的流程的总体描述。系统由预训练的LLM和(可选的)上下文存储在向量数据库中组成。在每个对话轮次中执行三次LLM调用,使用特定的提示。首先,LLM执行领域检测和状态跟踪。更新后的信念状态用于数据库查询,并将查询结果用于后续基于LLM的响应生成步骤。在少样本设置中,上下文存储用于存储训练集中的有限数量的示例,这些示例根据与对话上下文的相似性进行检索,并包含在LLM提示中。
3.1 提示词构建
目标是比较所选LLMs的原始能力,因此作者不关注提示工程技术,并选择在本工作中所有LLMs都使用的通用提示。为所有示例定义一个单一领域检测提示,以及给定数据集中每个领域的一对提示:状态跟踪提示(见表1)和响应提示。

Definition: 从关于酒店的对话中提取实体与值。
以冒号分隔的"实体:值"形式呈现。
不要在冒号之间加入空格。
使用连字符分隔不同的"实体:数值"对。
需要提取的数值有:
- "pricerange":酒店的价格[对话历史]
顾客:"我想找一个便宜的住所。"
领域检测提示包括任务描述和两个静态领域检测示例。除了一般指令外,每个状态跟踪提示包含领域描述、相关槽位列表、对话历史记录和当前用户话语。响应提示不包含每个领域的槽位列表,但是代替的它们包含当前的信念状态和数据库结果。在少样本设置中,每个跟踪和响应提示还包含从上下文存储中检索的正例和负例示例。提示示例详见附录的表5和表6。
3.2 领域检测和状态追踪
在状态跟踪过程中,每轮对LM进行两次提示:首先,检测当前活动(active,激活)的领域,然后输出在当前轮次中发生变化或出现的槽值。然后,使用这些输出来更新累积的全局信念状态。
使用两个提示步骤是因为需要模型在多个领域的情况下进行操作,即处理跨多个领域的对话。因此,需要能够检测当前活动的领域。通过首先使用一个领域检测的提示来实现这一点。
一旦获得了活动领域的预测,可以在处理信念状态预测的第二个提示中包含手动设计的领域描述。表1提供了一个用于状态跟踪的提示示例。对于少样本变体,从上下文存储中检索与活动领域相关的少样本示例。
初步实验表明,LLMs很难在每个轮次中始终输出所有活动的槽值。因此,只建模状态更新,采用MinTL方法。在这种方法中,模型只生成在当前轮次中发生变化的槽-值对。然后,使用这些轮次级别的更新来累积全局信念状态。为了获得机器可读的输出,以便用于数据库查询或API调用,在提示中指定模型应该提供JSON格式的输出,并且提供的少样本示例也相应进行了格式化处理。
3.3 响应生成
当前的信念状态用于查询数据库,以找到与活动领域中所有用户指定的槽位匹配的条目。根据信念状态和数据库结果,可以直接生成响应。给定的LLM提示包括对话历史、用户话语、信念状态和数据库结果(以及在少样本设置中检索到的示例),并要求模型提供一个合适的系统响应。
生成去标记化的响应,即用占位符替换槽位值。除了简化模型的任务外,去标记化的输出还使我们能够评估成功率。提示指定模型应将实体值作为去标记化的占位符提供,并相应构建任何少样本示例。
3.4 上下文存储
引入了一个包含编码对话上下文的存储。这个上下文存储是可选的,只在少样本提示变体中需要。使用来自固定长度历史窗口的对话上下文作为要编码到向量数据库中的键。一旦检索到相关示例,将它们包含在提示中以更好地指导模型。一些LLM还依赖于负面(对立地)示例。因此,采用了Peng等的一致性分类任务方法来生成负面示例:采用一些检索到的信念状态示例,通过将一些正确的槽值替换为随机值来破坏它们,并将它们作为负面示例呈现在提示中。
4. 实验设定
5. 实验结果
5.1 领域检测
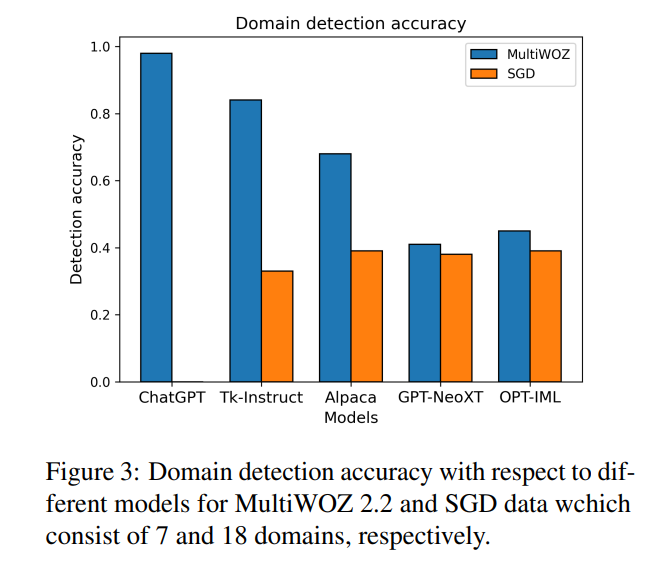
各种模型的领域检测准确率差异很大,这很可能会影响检索到的少样本示例的质量和后续提示的适当性。然而,领域检测是基于轮次的,有一些情况(例如提供地址、道别等)总是以相同的方式处理,即使它们在形式上属于不同的领域。因此,并非所有来自被错误分类的领域的检索示例一定包含无关的上下文。
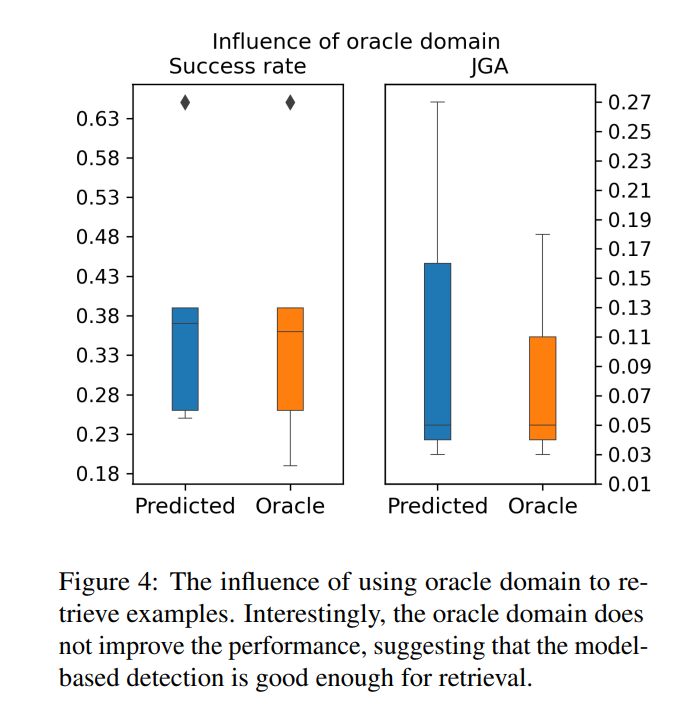
使用理论上正确的领域并没有提高性能,甚至在某些情况下性能变差。这表明模型预测的领域通常已经足够好,并且额外提供领域信息并不会对最终的系统性能产生贡献。
5.2 信念状态跟踪

在比较各个模型的结果时,ChatGPT明显优于其他模型。少样本与零样本设置似乎并不对结果产生很大影响,除了GPT-NeoXT模型。
5.3 响应生成
总体而言,BLEU分数较低,远低于监督式最先进模型。Tk-Instruct和ChatGPT在这方面是最强的,并且表现大致相当。
5.4 对话级表现
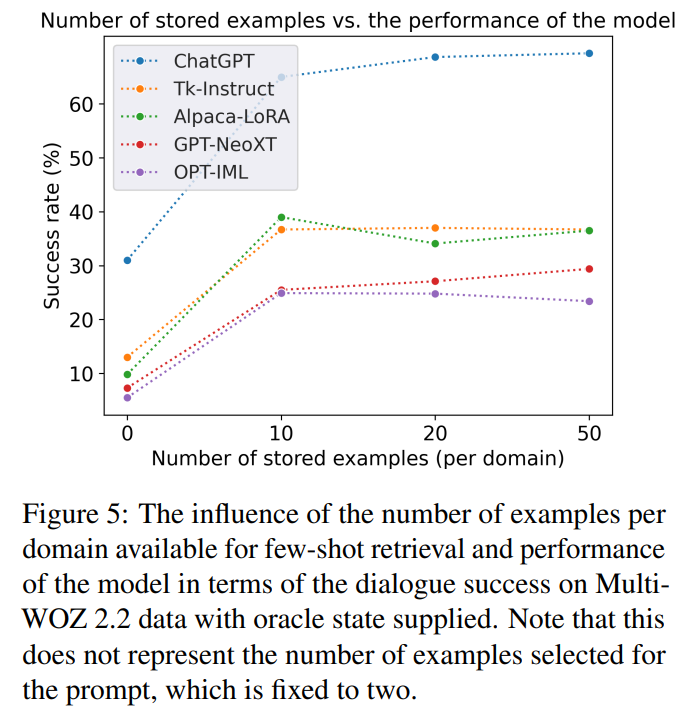
对话成功的结果在表2中提供,LLMs和监督式自定义模型的性能之间存在较大差距。ChatGPT似乎优于其他模型,与状态跟踪类似。然而,在零样本设置中,差异并不那么明显。在大多数情况下,添加检索到的少样本示例是有帮助的。当提供理论上正确的信念状态时,检索示例的贡献更为明显,这种情况下对于所有模型都有帮助。图5探讨了上下文存储大小对对话成功率的影响。似乎通过仅提供少量示例而不是零样本提示可以实现最大的改进,但增加用于检索的示例池的大小并不会带来进一步的性能提升。
6 模型分析
介绍了人工评估和错误分析。
错误行为可以分为可恢复的提示错误和固有错误,前者可以通过提示工程修复,后者属于不容易通过提示工程修复的错误,比如幻觉和不相关的内容。
7 结论
即使在提供上下文中的少样本示例的情况下,LLM在信念状态跟踪方面表现不佳。如果提供正确的信念状态,模型可以成功地与用户进行交互,提供有用的信息并满足用户的需求。因此,精心选择代表性示例并将LLM与领域内的信念跟踪器结合起来,可以成为任务导向型对话流程中可行的选择。
8. 限制
模型对特定提示的选择很敏感。具体而言,信念状态的期望格式在模型之间有所变化,并且存在一些模型特定的指令。
A 提示词构建



总结
⭐ 作者测试了基于LLM做领域识别、状态追踪和响应生成。但是状态追踪的效果不好,如果想用LLM做TOD需要额外加入状态追踪逻辑。
相关文章:
[论文笔记]Are Large Language Models All You Need for Task-Oriented Dialogue?
引言 今天带来论文Are Large Language Models All You Need for Task-Oriented Dialogue?的笔记。 主要评估了LLM在完成多轮对话任务以及同外部数据库进行交互的能力。在明确的信念状态跟踪方面,LLMs的表现不及专门的任务特定模型。然而,如果为它们提…...
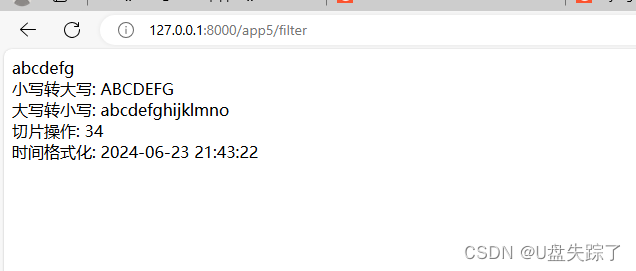
Django 模版过滤器
Django模版过滤器是一个非常有用的功能,它允许我们在模版中处理数据。过滤器看起来像这样:{{ name|lower }},这将把变量name的值转换为小写。 1,创建应用 python manage.py startapp app5 2,注册应用 Test/Test/sett…...
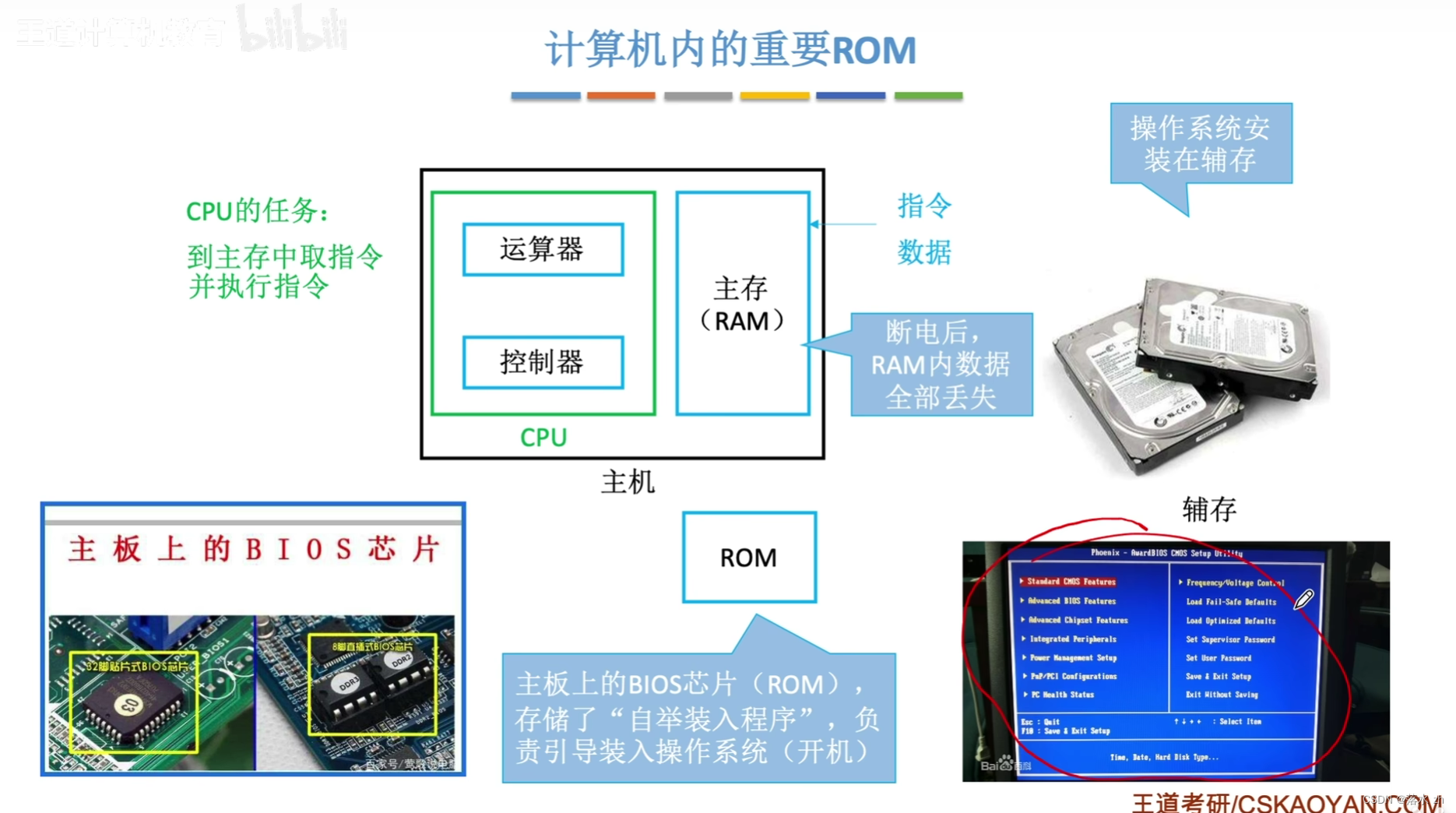
计算机组成原理 —— 存储系统(DRAM和SRAM,ROM)
计算机组成原理 —— 存储系统(DRAM和SRAM) DRAM和SRAMDRAM的刷新DRAM地址复用ROM(Read-Only Memory(只读存储器)) 我们今天来看DRAM和SRAM: DRAM和SRAM DRAM(动态随机存取存储器&…...
第22篇 Intel FPGA Monitor Program的使用<五>
Q:如何用Intel FPGA Monitor Program创建C语言工程并运行呢? A:总体过程与创建汇编语言工程类似,不同的是在指定程序类型时选择C Program。 后续用到DE2-115开发板的硬件如LED、SW和HEX等外设时,还需要将描述定义这些…...

网信办公布第六批深度合成服务算法备案清单,深兰科技大模型入选
6月12日,国家互联网信息办公室发布了第六批深度合成服务算法备案信息,深兰科技硅基知识智能对话多模态大模型算法通过相关审核,成功入选该批次《境内深度合成服务算法备案清单》。同时入选的还有腾讯混元大模型多模态算法、支付宝图像生成算法…...

ES 8.14 向量搜索优化
参考:https://blog.csdn.net/UbuntuTouch/article/details/139502650 检索器(standard、kNN 和 RRF) 检索器(retrievers)是搜索 API 中的一种新抽象概念,用于描述如何检索一组顶级文档。检索器被设计为可以…...

查看 MAC 的 shell 配置文件
在Mac上,shell的配置文件主要取决于您当前使用的shell。从macOS Catalina开始,Mac使用zsh作为默认登录Shell和交互式Shell。以下是关于Mac上zsh shell配置文件的一些详细信息: 查看当前使用的shell: 要查看当前正在使用的shell&am…...
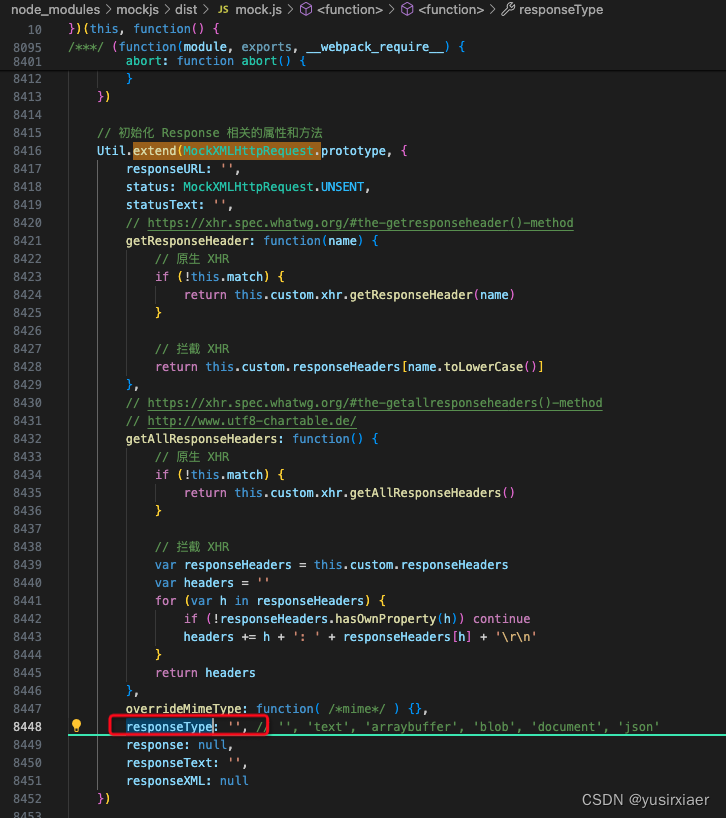
前端下载文件流,axios设置responseType: arraybuffer/blob无效
项目中调用后端下载文件接口,设置responseType: arraybuffer,实际拿到的数据data是字符串 axios({method: post,url: /api/v1/records/recording-file/play,// 如果有需要发送的数据,可以放在这里data: { uuid: 06e7075d-4ce0-476f-88cb-87fb0a1b4844 }…...
代码实践 -卷积神经网络-14模型构造)
动手学深度学习(Pytorch版)代码实践 -卷积神经网络-14模型构造
14模型构造 import torch from torch import nn from torch.nn import functional as F#通过实例化nn.Sequential来构建我们的模型, 层的执行顺序是作为参数传递的 net1 nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256,10)) """ nn.…...
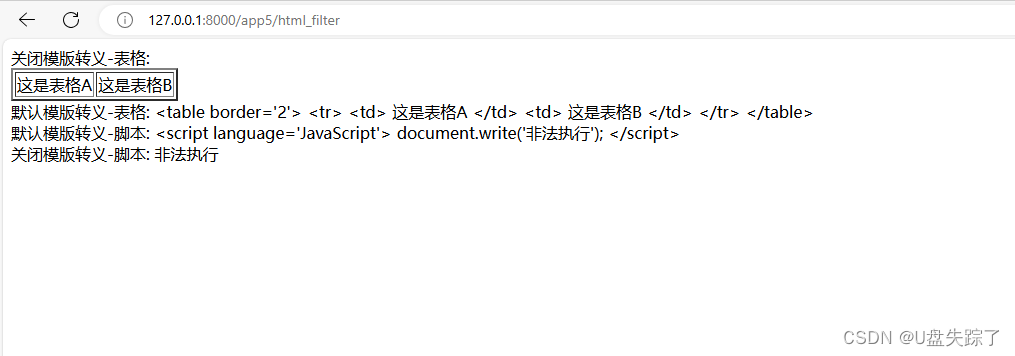
Django 模版转义
1,模版转义的作用 Django模版系统默认会自动转义所有变量。这意味着,如果你在模版中输出一个变量,它的内容会被转义,以防止跨站脚本攻击(XSS)。例如,如果你的变量包含HTML标签,这些…...
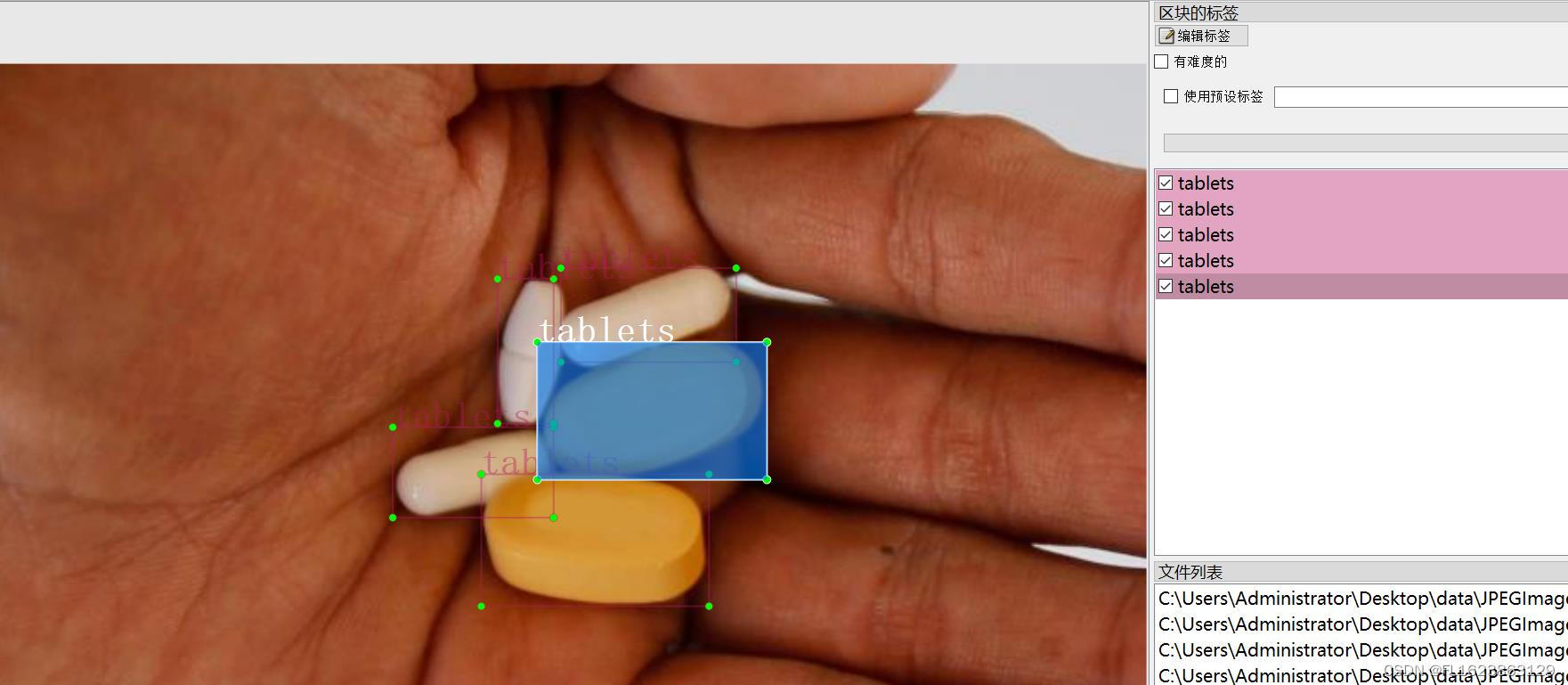
[数据集][目标检测]药片药丸检测数据集VOC+YOLO格式152张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):152 标注数量(xml文件个数):152 标注数量(txt文件个数):152 标注类别…...
)
Android SurfaceFlinger——HWC图层合成器加载(四)
在前面文章中的 Android.bp 文件中,我们可以看到里面加载了图层合成器和图形内存分配器的 HAL 服务,这里篇我们就来详细介绍一下其中的图层合成器——HWC。 一、HWC简介 HWC,全称为 Hardware Composer,是 Android 系统中一个至关重要的组件,位于硬件抽象层(HAL)。它的主…...

OpenCV--图像金字塔
图像金字塔 图像金字塔高斯金字塔拉普拉斯金字塔 图像金字塔 import cv2""" 图像金字塔:同一图像不同分辨率的子图合集 主要用于图像分割 """高斯金字塔 """ 高斯金字塔:通过高斯平滑和亚采样(采样后图像…...

创意产业如何应对AI的挑战。
最近的一个月,音乐领域迎来了一个革命性的变化。一系列音乐大模型轮番上线,它们以惊人的创作能力,将素人生产音乐的门槛降到了最低。这些AI音乐模型的出现,引发了关于AI是否会彻底颠覆音乐圈的讨论。然而,短暂的兴奋过…...

设计模式——工厂方法模式
文章目录 工厂方法模式简介工厂方法模式的组成部分工厂方法模式的结构Factory和Method的含义工厂方法模式的应用场景工厂方法模式的示例1. 文档生成器2. 数据库连接 工厂方法模式简介 工厂方法模式(Factory Method Pattern)是一种创建型设计模式&#x…...

apksigner jarsigner.md
关于作者:CSDN内容合伙人、技术专家, 从零开始做日活千万级APP。 专注于分享各领域原创系列文章 ,擅长java后端、移动开发、商业变现、人工智能等,希望大家多多支持。 目录 一、导读二、概览三、apksigner3.2 为 APK 签名3.3 验证…...

在SQL中使用explode函数展开数组的详细指南
目录 简介示例1:简单数组展开示例2:展开嵌套数组示例3:与其他函数结合使用处理结构体数组示例:展开包含结构体的数组示例2:展开嵌套结构体数组 总结 简介 在处理SQL中的数组数据时,explode函数非常有用。它…...

JavaScript 预编译与执行机制解析
在深入探讨JavaScript预编译与执行机制之前,我们首先需要明确几个基本概念:声明提升、函数执行上下文、全局执行上下文以及调用栈。这些概念共同构成了JavaScript运行时环境的核心组成部分,对于理解代码的执行流程至关重要。本文将围绕这些核…...
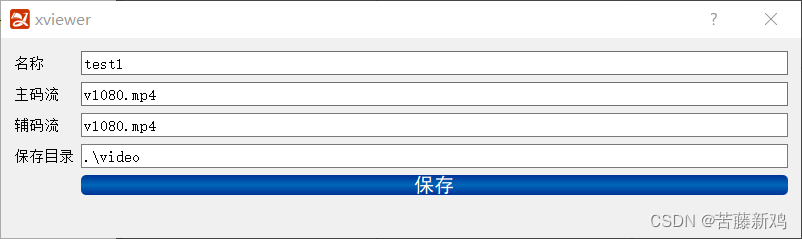
多路h265监控录放开发-(12)完成全部开始录制和全部停止录制代码
xviewer.h 新增 public: void StartRecord();//126 开始全部摄像头录制 void StopRecord();//126 停止全部摄像头录制 xviewer.cpp 新增 //视频录制 static vector<XCameraRecord*> records;//126void XViewer::StartRecord() //开始全部摄像头录制 126 {StopRecord…...

Redis源码学习:Redis对象和5种数据类型的工作原理
Redis 提供 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(哈希)、Zset(有序集合),这些数据类型可以供用户直接使用…...

BG3ModManager:博德之门3模组管理终极解决方案
BG3ModManager:博德之门3模组管理终极解决方案 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 你是否曾经为《博德之门3》的模组管理而烦…...

如何用applera1n免费绕过iOS激活锁:完整指南与操作教程
如何用applera1n免费绕过iOS激活锁:完整指南与操作教程 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否购买了一部二手iPhone或iPad,却发现设备被原主人的Apple ID锁定&a…...
)
用Python复现FAST天眼数学建模:从坐标变换到促动器伸缩量计算(附完整代码)
用Python复现FAST天眼数学建模:从坐标变换到促动器伸缩量计算(附完整代码) 中国天眼FAST作为全球最大单口径射电望远镜,其主动反射面调节系统堪称现代工程奇迹。当观测不同方位天体时,需要通过促动器精确控制4450块反射…...

Wand-Enhancer:零成本解锁WeMod高级功能的完整指南
Wand-Enhancer:零成本解锁WeMod高级功能的完整指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费用而犹豫不决吗…...

5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南
5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

如何快速解密网易云NCM文件:终极免费转换工具指南
如何快速解密网易云NCM文件:终极免费转换工具指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲,…...

Windows Cleaner终极指南:3分钟彻底解决C盘爆红问题!
Windows Cleaner终极指南:3分钟彻底解决C盘爆红问题! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统越用越慢而烦恼吗&…...

Scarab空洞骑士模组管理器:2024年最完整的安装与使用指南
Scarab空洞骑士模组管理器:2024年最完整的安装与使用指南 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在为空洞骑士模组安装的复杂流程而烦恼吗?…...

AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型
AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型 各位产品同行、AI从业者,大家好!我是连续3年深耕AI工具Agent产品、从C端信息流(今日头条/抖音生态)PM成功转型AI原生垂直工具PM的张小白——过去两年&am…...

Ash印相渲染失败率骤升47%?紧急预警:V6.2更新后Gamma 2.2→2.4迁移引发的印相断层危机
更多请点击: https://intelliparadigm.com 第一章:Ash印相渲染失败率骤升47%的全局现象与危机定性 近期,全球多个采用 Ash 印相引擎(v3.8.2)的影像处理平台集中报告渲染任务异常终止、输出空白或超时中断。监控数据显…...