【科学计算与可视化】2. pandas 基础
1. 安装 Pandas
首先,确保你已经安装了 Pandas。你可以使用以下命令安装:pip install pandas
2. 导入 Pandas
在开始使用 Pandas 之前,你需要先导入它:import pandas as pd
3. 创建数据结构
Pandas 主要有两种数据结构:Series 和 DataFrame。
3.1 Series
Series 是一个一维的标签数组,类似于 Python 的列表或字典。
import pandas as pd
s = pd.Series([1,2,3, np.nan, 6, 8, None], dtype=np.float32)
print(s)
s2 = pd.Series([100, 200, 300, 400], ["A", "B", "C", "D"]) # pd.Series(data, index) data 与 index 必须都是一维的
print(s2)
s2.to_csv("s2.csv") # 将数据保存为 csvs3 = pd.Series(np.arange(12)) # 从 ndarray 创建
s4 = pd.Series({"a": 1, "b": 2, "c": 3}) # 从字典创建
s5 = pd.Series(5, ["a", "b", "c"]) # 从标量值 创建
print(s5['a']) # Series 中数组的访问 类似于 python 中字典的访问
3.2 DataFrame
DataFrame 是一个二维的标签数据结构,类似于电子表格或 SQL 表格。
# 创建一个 DataFrame
data = {"A": [1, 2, 3, 4, 5],"B": [6, 7, 8, 9, 10],"C": [11, 12, 13, 14, 15]
}
df = pd.DataFrame(data)
print(df)# 使用多个 series 来构建 series 中可以缺少数据
df2 = pd.DataFrame({'name': pd.Series(["Tom", "Nick", "John", "Tom", "John"], index = ["A", "B", "C", "D", "E"]),'age': pd.Series([20, 21, 19, 22,], index = ["A", "B", "C", "D"]),'gender': pd.Series(["M", "M", "M", "F", "F"], index = ["A", "B", "C", "D", "E"])
})
print(df2)# 使用字典来创建 维度需要与 index 对应
df3 = pd.DataFrame({'name': ["Tom", "Nick", "John", "Tom", "John"],'age': [20, 21, 19, 22, 18],'gender': ["M", "M", "M", "F", "F"]
}, index=["A", "B", "C", "D", "E"])
print(df3)
# 访问数据
print(df3["name"]) # 访问列 返回一个对象
print(dict(df3["name"])) # 可以将对象转为数组
print(df3.loc["A"]) # 访问行 返回一个对象
print(df3.iloc[0]) # 访问行 返回一个对象print(df3.loc[["A", "C"], ["name", "age"]]) # 指定 行列 返回 一个 DataFrame 对象
df3[df3['age'] > 20] # 可以指定列条件来筛选
df3[(df3['age'] > 20) & (df3['age'] < 22)] # 可以使用逻辑运算符来拼接多个添加 & |
df3.reset_index() # reset_index用于重置索引,原有的索引存在一个新的 index 列中,新索引从 0 开始
df3.set_index("name") # set_index用于设置索引,原有的索引被替换为新的索引
4. 数据读取和写入
Pandas 支持读取和写入多种文件格式,如 CSV、Excel、SQL 等。
4.1 读取数据
# 读取 CSV 文件
df = pd.read_csv('data.csv')# 读取 Excel 文件
df = pd.read_excel('data.xlsx', sheet_name='Sheet1') # sheet_name 用于指定读取哪一个子表4.2 写入数据
# 写入 CSV 文件
df.to_csv('output.csv', index=False)# 写入 Excel 文件
df.to_excel('output.xlsx', sheet_name='Sheet1', index=False)5. 数据查看和检查
5.1 查看数据
# 显示前几行数据
print(df.head())
# 显示最后几行数据
print(df.tail())5.2 检查数据
# 查看 DataFrame 的形状
print(df.shape)
# 查看列名
print(df.columns)
# 查看数据类型
print(df.dtypes)
# 查看数据信息
print(df.info())
# 查看数据描述性统计信息
print(df.describe())6. 数据选择和过滤
6.1 选择数据
# 选择单列数据
print(df['A'])
# 选择多列数据
print(df[['A', 'B']])6.2 选择行数据
# 按行号选择
print(df.iloc[0])
# 按标签选择
print(df.loc[0])6.3 条件选择
# 选择满足条件的行
print(df[df['A'] > 2])
7. 数据清洗
7.1 处理缺失值
# 检查缺失值
print(df.isnull())
# 删除包含缺失值的行
df = df.dropna()
# 填充缺失值
df = df.fillna(0)7.2 处理重复值
# 检查重复值
print(df.duplicated())
# 删除重复值
df = df.drop_duplicates()
8. 数据操作
8.1 增加数据
df4 = pd.DataFrame(np.arange(12).reshape(3,4), index=["A", "B", "C"], columns=["A", "B", "C", "D"])
# 通过运算增加新列
df4["E"] = df4["A"] + df4["D"]
print(df4)# 使用 series创建
df4["F"] = pd.Series(["F", "F", "F"], index=["A", "B", "C"])
print(df4)# 增加行 concat 函数
new_row = pd.DataFrame({"A": [20],"B": [21],"C": [22],"D": [23]
})
df4 = pd.concat([df4, new_row], ignore_index=True)
8.2 删除数据
df4.drop("F", axis=1) # axis = 1 删除列 axis 不填 默认为 1
df4.drop("A", axis=0) # axis = 0 删除行
# drop默认不会改变原有 DataFrame 对象,而是返回一个新的 DataFrame 对象, 当我们需要改变原有对象的时候 我们可以添加 inplace=True 的参数df4.drop("F", axis=1, inplace=True)
8.3 数据排序
# 按单列排序
df = df.sort_values(by='A')# 按多列排序
df = df.sort_values(by=['A', 'B'], ascending=[True, False])9. 数据分组和聚合
9.1 分组
分组通常使用 groupby 方法来实现 这个方法允许你将数据分成不同的组,然后对每个组独立地进行操作
import pandas as pd# 创建一个 DataFrame
df = pd.DataFrame({'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C': [1, 3, 2, 5, 4, 1, 2, 3],'D': [4, 2, 5, 5, 6, 1, 2, 3]
})
print(df)# 按列 'A' 进行分组
grouped = df.groupby('A')# 显示分组
for name, group in grouped:print(name)print(group)9.2 聚合
# 计算每个分组中 “C" 列的平均值
print(grouped['C'].mean())
‘’‘
A
bar 3.0
foo 2.4
’‘’
# 对 grouped 的每一列求和
print(grouped.sum())
‘’‘
A B C D
bar onethreetwo 9 8
foo onetwotwoonethree 12 20
’‘’# 使用 agg 应用多个聚合函数
aggregated = grouped['C'].agg(['sum', 'mean'])
print(aggregated)#也可以使用多个 key 作为键
# 使用多个列作为分组键
grouped = df.groupby(['A', 'B'])# 显示分组
for (name1, name2), group in grouped:print((name1, name2))print(group)
10. 数据可视化
Pandas 集成了 Matplotlib,可以很方便地进行数据可视化。 关于数据可视化将在后续博客更新
import matplotlib.pyplot as plt# 创建一个简单的折线图
df.plot()
plt.show()# 创建一个柱状图
df.plot(kind='bar')
plt.show()11. 高级操作
11.1 合并数据
df1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value': [1, 2, 3]})
df2 = pd.DataFrame({'key': ['A', 'B', 'D'], 'value': [4, 5, 6]})# 内连接只保留两个 DataFrame 中都有的键(‘key’ 列)的行
merged_df = pd.merge(df1, df2, on='key', how='inner')
print(merged_df)# 外连接会保留两个 DataFrame 中所有的键。如果某个键只在一个 DataFrame 中存在,那么结果中该键的对应行会在另一个 DataFrame 的列上填充 NaN(表示缺失值)。
merged_df = pd.merge(df1, df2, on='key', how='outer')
print(merged_df)
11.2 应用函数
# 对列应用函数
df['A'] = df['A'].apply(np.sqrt)相关文章:

【科学计算与可视化】2. pandas 基础
1. 安装 Pandas 首先,确保你已经安装了 Pandas。你可以使用以下命令安装:pip install pandas 2. 导入 Pandas 在开始使用 Pandas 之前,你需要先导入它:import pandas as pd 3. 创建数据结构 Pandas 主要有两种数据结构&#…...

医学记录 --- 腋下异味
逻辑图地址 症状 病因 汗液分泌旺盛:由于天气炎热、活动出汗、肥胖等因素导致汗液分泌旺盛,可引起腋下有异味表现。在这种情况下,建议保持身体清洁,特别是在炎热和潮湿的环境下。可以使用抗菌洗液、喷雾或霜剂来帮助减少细菌滋…...
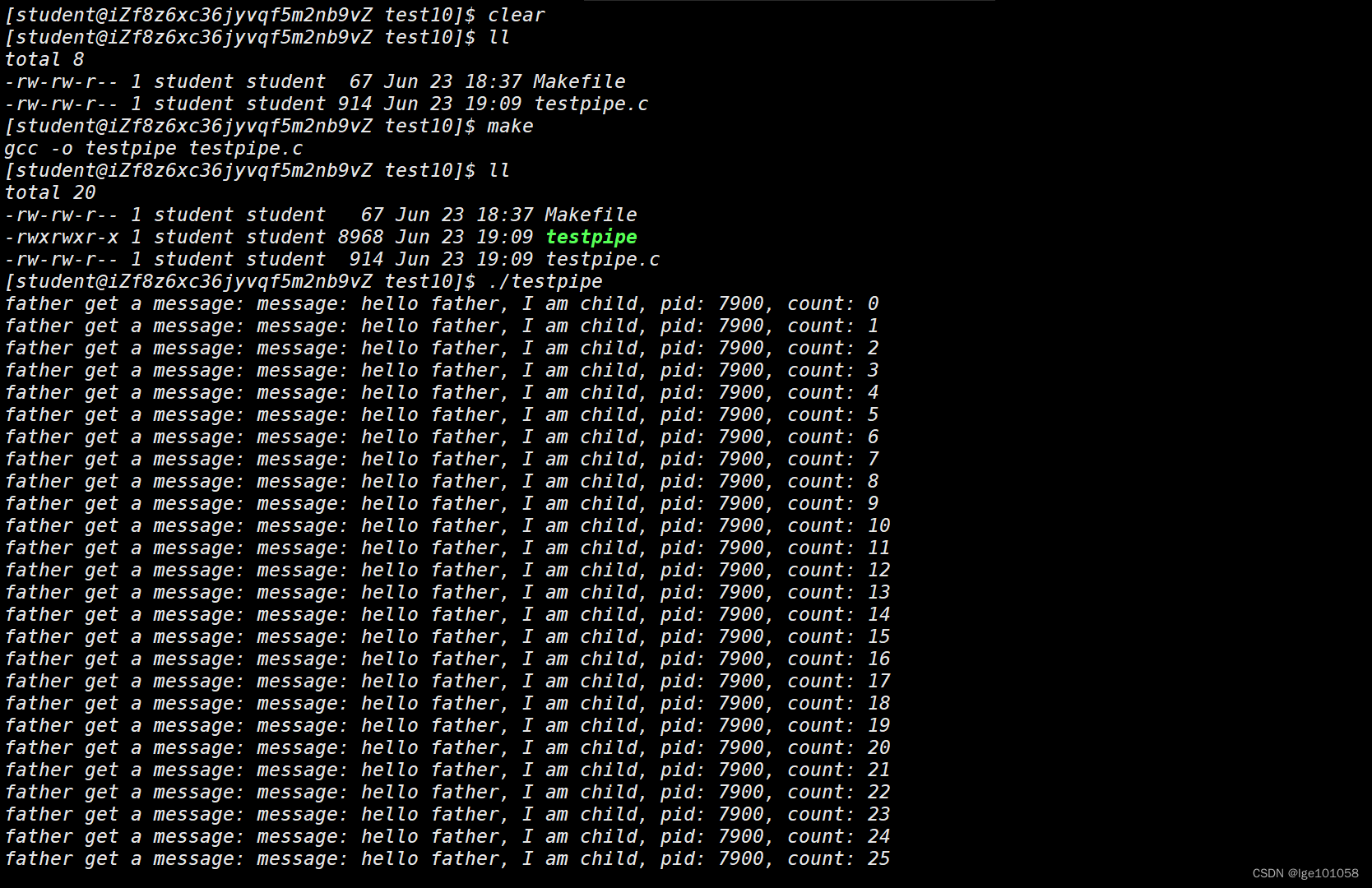
【Linux】进程间通信_1
文章目录 七、进程间通信1. 进程间通信分类管道 未完待续 七、进程间通信 进程间由于 进程具有独立性 ,所以不可以直接进行数据传递。但是我们通常需要多个进程协同,共同完成一件事,所以我们需要进程间通信的手段。进程间通信的本质就是先让…...
 5.6 在kernel 中实现系统复位和系统关机驱动)
Linux Kernel入门到精通系列讲解(RV-Kernel 篇) 5.6 在kernel 中实现系统复位和系统关机驱动
1. 概述 上一章节Qemu篇我们已经实现了我们SOC的power reset和 power down 寄存器,本章节我们就在Linux driver中去实现它。 2. Linux kernel 访问其他节点 Linux kernel中有一种机制,就是在driver中访问其它设备树节点的信息,了解设备树的应该都知道,每个设备节点都有一…...

如何在Java中进行单元测试?
如何在Java中进行单元测试? 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨如何在Java中进行单元测试,这是一项确保代码质…...

代码随想录训练营Day32
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、买卖股票的最佳时机2二、跳跃游戏三、跳跃游戏2四、K次取反后最大化的数组和 前言 今天是跟着代码随想录刷题的第32天,主要是学了买卖股票的最…...

代码随想录训练营Day31
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、分发饼干二、摆动序列三、最大子树组合 前言 今天是跟着代码随想录刷题的第31天,主要学习了分发饼干,摆动序列和最大子树组合这三个…...

Docker 多阶段构建
多阶段构建 目录 尝试创建 Dockerfile构建容器镜像运行 Spring Boot 应用程序使用多阶段构建额外资源 在传统构建中,所有构建指令都在一个构建容器中顺序执行:下载依赖项、编译代码、打包应用程序。所有这些层最终都在你的最终镜像中。这种方法虽然可行…...
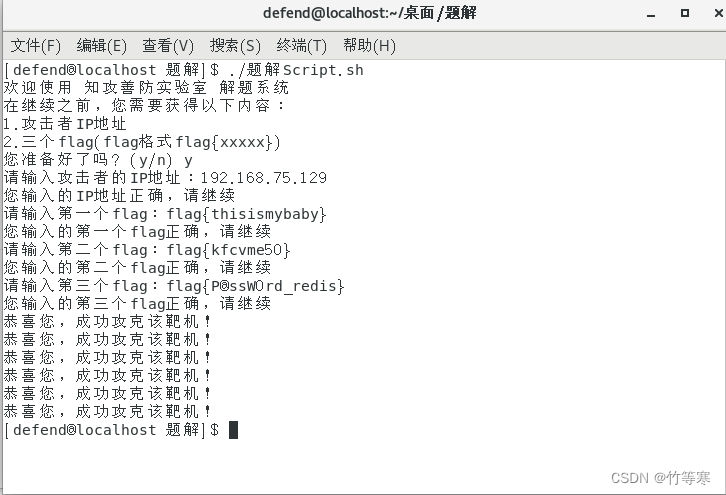
Linux应急响应——知攻善防应急靶场-Linux(1)
文章目录 查看history历史指令查看开机自启动项异常连接和端口异常进程定时任务异常服务日志分析账户排查总结 靶场出处是知攻善防 Linux应急响应靶机 1 前景需要: 小王急匆匆地找到小张,小王说"李哥,我dev服务器被黑了",快救救我&…...

基于CDMA的多用户水下无线光通信(1)——背景介绍
研究生期间做多用户水下无线光通信(Underwater Optical Wireless Communication,UOWC),写几篇博客分享一下学的内容。导师给了大方向,让我用直接序列码分多址(Direct Sequence Code Division Multiple Acce…...

基于springboot websocket和okhttp实现消息中转
1、业务介绍 消息源服务的消息不能直接推给用户侧,用户与中间服务建立websocket连接,中间服务再与源服务建立websocket连接,源服务的消息推给中间服务,中间服务再将消息推送给用户。流程如下图: 此例中我们定义中间服…...

@PostConstruct 注解的方法用于资源的初始化
PostConstruct 是 Java EE 5 引入的一个注解,主要用于依赖注入完成之后,需要执行的方法上。这个注解的方法会在依赖注入完成后自动被容器(如 EJB 容器或 Spring 容器)调用,并且只会被调用一次。 PostConstruct 注解的…...
SvelteKit教程:hello world)
(一)SvelteKit教程:hello world
(一)SvelteKit教程:hello world sveltekit 的官方教程,在这里:Creating a project • Docs • SvelteKitCreating a project • Docs • SvelteKit 我们可以按照如下的步骤来创建一个项目: npm create s…...

华为Atlas NPU ffmpeg 编译安装
处理器:鲲鹏920 NPU:昇腾 310P3 操作系统:Kylin Linux Advanced Server V10 CANN:Ascend-cann-toolkit_8.0.RC1_linux-aarch64.run FFmpeg:AscendFFmpegPlugin(不要用AscendFFmpeg) AscendFFmpegPlugin下载地址&…...
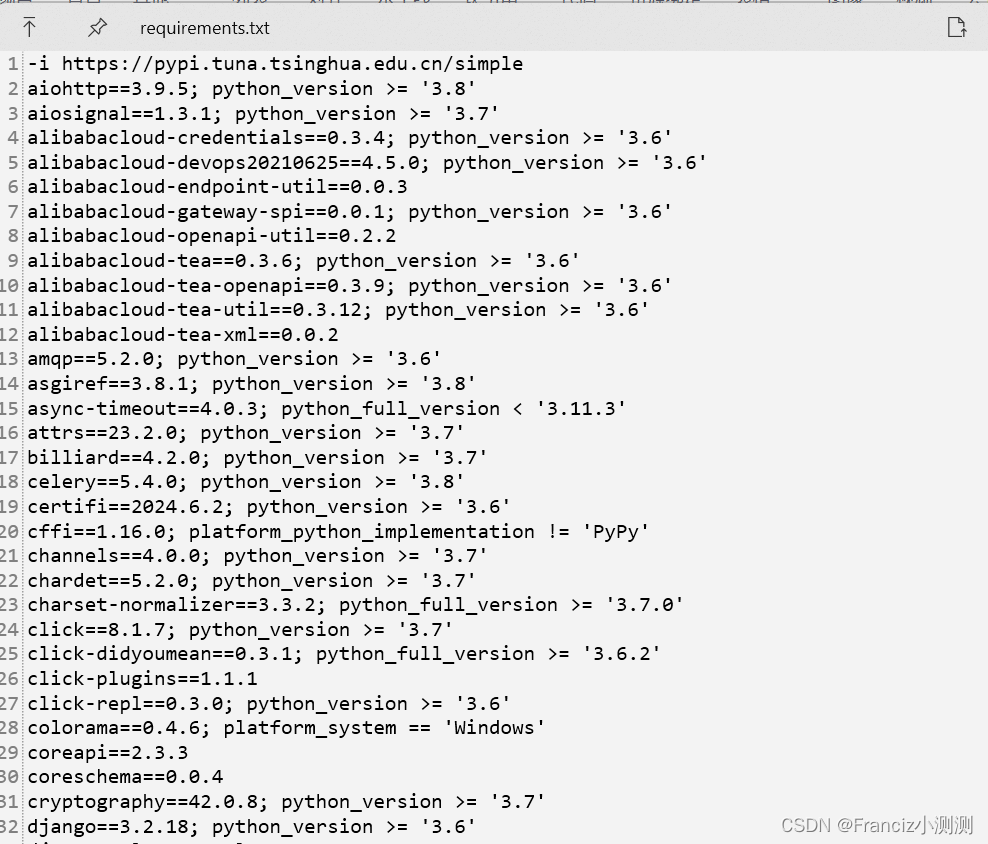
Python 虚拟环境 requirements.txt 文件生成 ;pipenv导出pip安装文件
搜索关键词: Python 虚拟环境Pipenv requirements.txt 文件生成;Pipenv 导出 pip requirements.txt安装文件 本文基于python版本 >3.9 文章内容有效日期2023年01月开始(因为此方法从这个时间开始是完全ok的) 上述为pipenv的演示版本 使用以下命令可精准生成requirement…...

Less与Sass的区别
1. 功能和工具: Sass:提供了更多的功能和内置方法,如条件语句、循环、数学函数等。Sass 也支持更复杂的操作和逻辑构建。 Less:功能也很强大,但相比之下,Sass 在功能上更为丰富和成熟。 2、编译环境&…...

力扣-2663
题目 如果一个字符串满足以下条件,则称其为 美丽字符串 : 它由英语小写字母表的前 k 个字母组成。它不包含任何长度为 2 或更长的回文子字符串。 给你一个长度为 n 的美丽字符串 s 和一个正整数 k 。 请你找出并返回一个长度为 n 的美丽字符串&#…...

CausalMMM:基于因果结构学习的营销组合建模
1. 摘要 在线广告中,营销组合建模(Marketing Mix Modeling,MMM) 被用于预测广告商家的总商品交易量(GMV),并帮助决策者调整各种广告渠道的预算分配。传统的基于回归技术的MMM方法在复杂营销场景…...

编译 CUDA 程序的基本知识和步骤
基本工具 NVCC(NVIDIA CUDA Compiler): nvcc 是 NVIDIA 提供的 CUDA 编译器,用于将 CUDA 源代码(.cu 文件)编译成可执行文件或库。它可以处理 CUDA 和主机代码(例如 C)的混合编译。nvcc 调用底层…...

复旦微FMQL平台:memorytest工程实战指南与DDR稳定性验证
1. 从Procise导出memorytest工程 第一次接触复旦微FMQL平台时,我也被各种工程文件搞得晕头转向。memorytest工程作为内存测试的基础工具,其实导出过程比想象中简单得多。在Procise界面中找到memtest选项,就像在Windows资源管理器里找文件夹一…...

Comsol锂离子电池热管理模型
Comsol锂离子电池热管理模型 电化学热耦合模型: 风冷换热方形电池 绝热软包电池 石蜡相变换热圆柱电池模型 21700圆柱电池热失控模型(附带说明文档)一、引言随着电动汽车、储能系统等领域的快速发展,锂离子电池的应用越来越广泛。…...

永磁同步电机多电机同步控制仿真:改进与对比的奇妙之旅
永磁同步电机多电机同步控制仿真,含改进对比在电机控制领域,永磁同步电机(PMSM)凭借其高效、节能等诸多优点,广泛应用于工业生产、电动汽车等多个重要领域。而当涉及多个永磁同步电机协同工作时,实现同步控…...

2025届学术党必备的五大AI写作网站解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek DeepSeek身为新一代人工智能辅助写作工具,于学术论文撰写的整个流程里࿰…...

量子计算入门捷径:在快马平台用qorder实现第一个纠缠态实验
量子计算听起来很高深,但有了合适的工具和平台,入门其实比想象中简单。最近我在InsCode(快马)平台上尝试用qorder框架做了第一个量子纠缠实验,发现整个过程就像搭积木一样直观。下面分享我的学习笔记,希望能帮到同样想入门的朋友。…...

马年市场快报分析:欧美组合式一氧化碳及可燃气体报警器指南
马年市场快报分析:欧美组合式一氧化碳及可燃气体报警器指南根据您提供的快报内容,我将从专业角度逐步分析欧美组合式一氧化碳(CO)及可燃气体报警器的关键信息,包括安全标准、风险因素、探测器区别、安装建议以及相关产…...
集成方案)
PyTorch 2.8镜像实战落地:教育机构AI教学平台(图文+视频+LLM)集成方案
PyTorch 2.8镜像实战落地:教育机构AI教学平台(图文视频LLM)集成方案 1. 教育AI平台的技术挑战与解决方案 现代教育机构在构建AI教学平台时面临三大技术难题:多模态内容生成、算力资源管理和教学场景适配。PyTorch 2.8深度学习镜…...

终极指南:如何让2012-2015年老款Mac安装最新macOS系统
终极指南:如何让2012-2015年老款Mac安装最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 您的2012-2015年老款Mac是否已被苹果官方抛…...

【个人推荐】一些好用的录音转写工具
因为助教课备课的缘故,需要录制讲座的音频以整理知识点。一次讲座的音频内容很长,即使3x速快进播放依然很耗费时间,因此录音转写的需求浮现了出来。于是闲暇之余探索了下市面上的录音转写工具,浅浅记录下体验。 下面主要推荐三款…...

前端测试的学习阶段,由基础到进阶的过程认识.....
前言:突然想起刚入行的学习感悟,一个知识点不懂的背后,是整个知识体系的欠缺, 那会从后端转入前端(非科班)有时候一个报错不知道从何找起,一、单元测试 【已经案例和知识相结合,可看…...