Hive怎么调整优化Tez引擎的查询?在Tez上优化Hive查询的指南
文章目录
- 在Tez上优化Hive查询的指南
- 调优指南
- 理解Tez中的并行化
- 理解mapper数量
- 理解reducer数量
- 并发
- 案例1:未指定队列名称
- 案例2:指定队列名称
- 并发的指南/建议
- 容器复用和预热容器
- 容器复用
- 预热容器
- 一般Tez调优参数
在Tez上优化Hive查询的指南
在Tez上优化Hive查询无法采用一刀切的方法。查询性能取决于数据的大小、文件类型、查询设计和查询模式。在性能测试过程中,应评估和验证配置参数及任何SQL修改。建议在工作负载的性能测试过程中一次只进行一项更改,并最好在开发环境中评估调优更改的影响,然后再在生产环境中使用。
这里分享一些关于Tez上Hive查询的基本故障排除和调优指南。
调优指南
不同的hive版本,不同执行引擎之间的调优行为有所差异,所以同一条sql可能会有不一样的速度。
一般情况下,我们可以通过以下步骤有助于识别可能导致性能下降的地方。
- 验证和确认YARN容量调度器配置
队列配置错误可能会由于对用户可用资源的任意限制而影响查询性能。验证用户限制因子、最小用户限制百分比和最大容量。
- 检查Hive和HiveServer2配置中的任何安全阀(非默认值)是否相关
移除任何遗留的和过时的属性。
- 识别缓慢的区域,例如mapper任务、reducer任务和连接操作
- 审查Tez引擎和平台的通用调优属性。
- 审查mapper任务并根据需要增加/减少任务数。
- 审查reducer任务并根据需要增加/减少任务数。
- 审查任何并发相关的问题——并发问题分为两种,如下所述:
- 队列内用户间的并发。这可以通过调整YARN队列的用户限制因子进行调优(详细信息参考容量调度器博客)。
- Hive on Tez会话的预热容器之间的并发,详见下文。
理解Tez中的并行化
在更改任何配置之前,必须了解Tez内部的工作机制。例如,这包括了解Tez如何确定正确的mapper和reducer数量。审查Tez架构设计以及有关初始任务并行性和自动reducer并行性的详细信息将有助于优化查询性能。
理解mapper数量
Tez使用作业的初始输入数据确定mapper任务的数量。在Tez中,任务数量由分组拆分决定,这相当于MapReduce作业中输入拆分确定的mapper数量。
tez.grouping.min-size和tez.grouping.max-size决定mapper的数量。min-size的默认值为16 MB,max-size为1 GB。- Tez确定任务数量,使每个任务的数据量符合最大/最小分组大小。
- 减少
tez.grouping.max-size会增加任务/mapper数量。 - 增加
tez.grouping.max-size会减少任务数量。
例如:
- 输入数据(输入碎片/拆分) – 1000个文件(约1.5 MB大小)
- 总数据量约为 – 1000*1.5 MB = ~1.5 GB
- Tez可能尝试使用至少两个任务处理这些数据,因为每个任务的最大数据量可能为1 GB。最终,Tez可能强制将1000个文件(拆分)组合到两个任务中,导致执行时间变慢。
- 如果将
tez.grouping.max-size从1 GB减少到100 MB,mapper数量可能增加到15,从而提供更好的并行性。性能因此提高,因为改进的并行性将工作分散到15个并发任务中。
以上是一个示例场景,然而在生产环境中使用ORC或Parquet等二进制文件格式时,根据存储类型、拆分策略文件或HDFS块边界确定mapper数量可能会变得复杂。
注意:更高程度的并行性(如mapper/reducer数量多)并不总是意味着更好的性能,因为它可能导致每个任务的资源减少以及由于任务开销而导致的资源浪费。
理解reducer数量
Tez使用多种机制和设置确定完成查询所需的reducer数量。
- Tez根据要处理的数据(字节数)自动确定reducer。
- 如果
hive.tez.auto.reducer.parallelism设置为true,Hive会估算数据大小并设置并行性估算值。Tez将在运行时采样源顶点的输出大小并根据需要调整估算值。 - 默认情况下,最大reducer数量设置为1009(
hive.exec.reducers.max)。 - Hive/Tez使用以下公式估算reducer数量,然后调度Tez DAG:
Max(1, Min(hive.exec.reducers.max [1009], ReducerStage estimate/hive.exec.reducers.bytes.per.reducer)) x hive.tez.max.partition.factor [2]
以下三个参数可以调整以增加或减少mapper数量:
hive.exec.reducers.bytes.per.reducer:每个reducer的大小。更改为较小值以增加并行性,或更改为较大值以减少并行性。默认值为256 MB(即如果输入大小为1 GB,则使用4个reducer)。tez.min.partition.factor:默认值为0.25。tez.max.partition.factor:默认值为2.0。增加以增加reducer数量,减少以减少reducer数量。
用户可以使用 mapred.reduce.tasks 手动设置reducer数量。这不推荐使用,应避免使用。
建议:
- 避免手动设置reducer数量。
- 增加reducer数量并不总是能保证更好的性能。
- 根据reducer阶段估算,如果要增加或减少reducer数量,可以调整
hive.exec.reducers.bytes.per.reducer参数到较小或较大值。
并发
我们需要理解和调整Tez上的Hive并发会话,如运行多个Tez AM容器。以下属性有助于理解默认队列和会话数量行为。
hive.server2.tez.default.queues:与YARN队列对应的以逗号分隔的值列表,用于维护Tez会话池。hive.server2.tez.sessions.per.default.queue:每个YARN队列中保持在池中的Tez会话(DAGAppMaster)数量。hive.server2.tez.initialize.default.sessions:如果启用,HiveServer2(HS2)在启动时将启动所有必要的Tez会话以满足sessions.per.default.queue要求。
当定义以下属性时,HiveServer2将为每个默认队列创建一个Tez Application Master(AM),乘以HiveServer2服务启动时的会话数量。因此:
(Tez Sessions)total = HiveServer2instances x (default.queues) x (sessions.per.default.queue)
示例说明:
hive.server2.tez.default.queues= “queue1, queue2”hive.server2.tez.sessions.per.default.queue=2
=>HiveServer2将创建4个Tez AM(queue1两个,queue2两个)。
注意:池中的Tez会话总是运行,即使在空闲集群上。
如果HiveServer2连续使用,这些Tez AM将继续运行,但如果HS2空闲,这些Tez AM将根据 tez.session.am.dag.submit.timeout.secs 定义的超时被终止。
案例1:未指定队列名称
如果查询未指定队列名称(tez.queue.name),则只会使用池中的Tez AM(如上所述初始化)。在这种情况下,HiveServer2将选择一个空闲/可用的Tez AM(队列名称可能是随机选择的)。如果未指定队列名称,则查询将保持在HiveServer2中的挂起状态,直到池中有一个可用的默认Tez AM来处理查询。在JDBC/ODBC客户端或HiveServer2日志文件中不会有任何消息。由于没有消息生成,当查询挂起时,用户可能会认为JDBC/ODBC连接或HiveServer2已断开,但实际上它在等待一个Tez AM执行查询。
案例2:指定队列名称
如果查询指定了队列名称,无论有多少初始化的Tez AM正在使用或空闲,HiveServer2都会为此连接创建一个新的Tez AM,并且查询可以执行(如果队列有可用资源)。
并发的指南/建议
- 对于不希望用户限制在同一个Tez AM池中的用例或查询,将
hive.server2.tez.initialize.default.sessions设置为false。禁用此选项可以减少HiveServer2上的争用并提高查询性能。 - 此外,增加
hive.server2.tez.sessions.per.default.queue的会话数量。 - 如果有需要为每组用户提供单独或专用Tez AM池的用例,需要为每组用户提供专用的HiveServer2服务,每个服务具有相应的默认队列名称和会话数量,并要求每组用户使用各自的HiveServer2。
容器复用和预热容器
容器复用
这是一个优化,可以减少容器的启动时间影响。通过设置 tez.am.container.reuse.enabled 为true来启用此功能。这节省了与YARN交互的时间。还可以保持容器组活跃,快速旋转容器,并跳过YARN队列。
预热容器
容器数量与将附加到每个Tez AM的YARN执行容器数量相关。即使Tez AM空闲(未执行查询),每个AM也会保留相同数量的容器。在某些情况下,这可能会导致太多容器空闲且未释放,因为这里定义的容器将被Tez AM保留,即使它是空闲的。这些空闲容器将继续占用YARN中的资源,其他应用程序可能会利用这些资源。
以下属性用于配置预热容器:
hive.prewarm.enabledhive.prewarm.numcontainers
一般Tez调优参数
在处理Tez上Hive查询的性能下降时,审查以下属性作为一级检查。您可能需要根据查询和数据属性设置或调整其中一些属性。最好在开发和QA环境中评估配置属性,然后根据结果将其推送到生产环境。
-
hive.cbo.enable
将此属性设置为true启用基于成本的优化(CBO)。CBO是Hive查询处理引擎的一部分,由Apache Calcite提供支持。CBO通过检查查询中指定的表和条件生成有效的查询计划,最终减少查询执行时间并提高资源利用率。 -
hive.auto.convert.join
将此属性设置为true允许Hive根据输入文件大小启用将常见连接转换为mapjoin的优化。 -
hive.auto.convert.join.noconditionaltask.size
您将希望在查询中尽可能多地执行mapjoin。此大小配置使用户可以控制表的大小以适应内存。该值表示可以转换为适合内存的哈希表的表的大小总和。建议将其设置为hive.tez.container.size的1/3。 -
tez.runtime.io.sort.mb
输出排序时的排序缓冲区大小。建议将其设置为hive.tez.container.size的40%,最大值为2 GB。通常不需要超过此最大值。 -
tez.runtime.unordered.output.buffer.size-mb
当输出不需要排序时的内存。这是缓冲区的大小,如果不直接写入磁盘。建议将其设置为hive.tez.container.size的10%。 -
hive.exec.parallel
此属性启用Hive查询阶段的并行执行。默认情况下,此属性设置为false。将此属性设置为true有助于并行化独立的查询阶段,从而整体提高性能。 -
hive.vectorized.execution.enabled
矢量化查询执行是Hive的一个功能,它大大减少了典型查询操作(如扫描、过滤、聚合和连接)的CPU使用量。默认情况下,此属性设置为false。将其设置为true。 -
hive.merge.tezfiles
默认情况下,此属性设置为false。将此属性设置为true会合并Tez文件。使用此属性可能会根据数据大小或要合并的文件数量增加或减少查询的执行时间。在使用此属性之前,请在较低环境中评估查询性能。 -
hive.merge.size.per.task
此属性描述作业结束时合并文件的大小。 -
hive.merge.smallfiles.avgsize
当作业的平均输出文件大小小于此数字时,Hive将启动一个额外的map-reduce作业将输出文件合并为更大的文件。默认情况下,此属性设置为16 MB。
文章来源:Hive怎么调整优化Tez引擎的查询?在Tez上优化Hive查询的指南
相关文章:

Hive怎么调整优化Tez引擎的查询?在Tez上优化Hive查询的指南
文章目录 在Tez上优化Hive查询的指南调优指南理解Tez中的并行化理解mapper数量理解reducer数量 并发案例1:未指定队列名称案例2:指定队列名称并发的指南/建议 容器复用和预热容器容器复用预热容器 一般Tez调优参数 在Tez上优化Hive查询的指南 在Tez上优…...

关于小程序内嵌H5页面交互的问题?
有木有遇到?有木有遇到。 小程序内嵌了H5,然后H5某个按钮,需要打开小程序某个页面进行信息完善或登记,登记后要返回H5页面,而H5页面要动态显示刚才在小程序页面登记的信息。 操作流程是这样: 方案1&#…...

Linux下手动查杀木马与Rootkit的实战指南
模拟木马程序的自动运行 黑客可以通过多种方式让木马程序自动运行,包括: 计划任务 (crontab):通过设置定时任务来周期性地执行木马脚本。开机启动:在系统的启动脚本中添加木马程序,确保系统启动时木马也随之运行。替…...
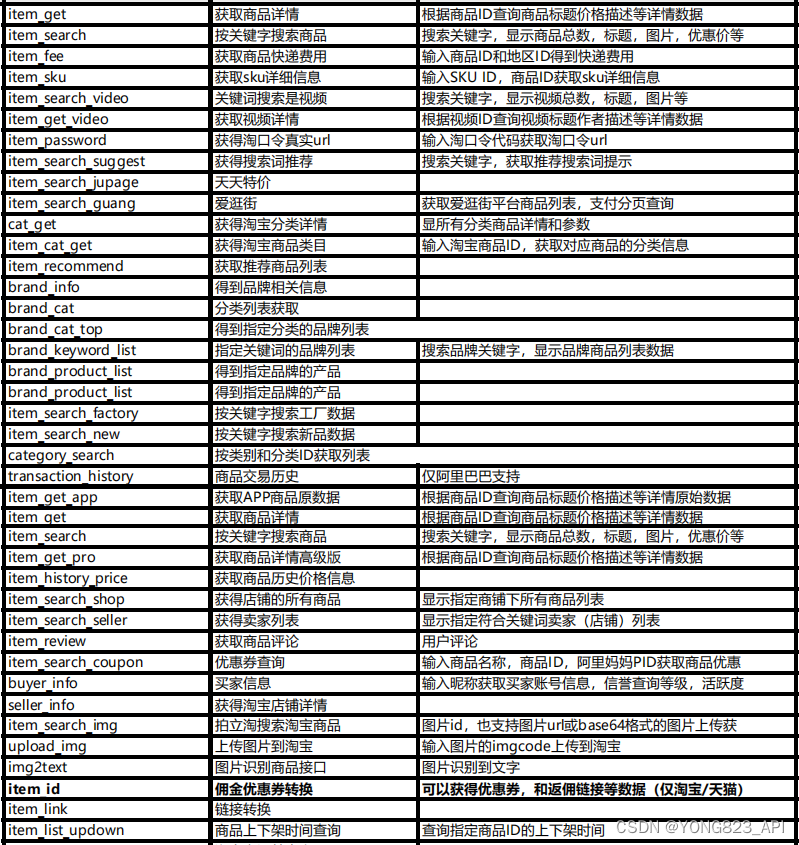
电商爬虫API的定制开发:满足个性化需求的解决方案
一、引言 随着电子商务的蓬勃发展,电商数据成为了企业决策的重要依据。然而,电商数据的获取并非易事,特别是对于拥有个性化需求的企业来说,更是面临诸多挑战。为了满足这些个性化需求,电商爬虫API的定制开发成为了解决…...

nuc马原复习资料
哲学:世界观的理论形态,或者说是系统化、理论化的世界观;世界观和方法论的统一。马克思主义哲学:辩证唯物主义和历史唯物主义,关于自然。社会和思维发展的普遍规律的学说,无产阶级世界观的理论体系。世界观…...

Node.js是什么(基础篇)
前言 Node.js是一个基于Chrome V8 JavaScript引擎的开源、跨平台JavaScript运行时环境,主要用于开发服务器端应用程序。它的特点是非阻塞I/O模型,使其在处理高并发请求时表现出色。 一、Node JS到底是什么 1、Node JS是什么 Node.js不是一种独立的编程…...

淘客返利平台的微服务架构实现
淘客返利平台的微服务架构实现 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨淘客返利平台的微服务架构设计与实现,旨在提高系统的灵…...

【database1】mysql:DDL/DML/DQL,外键约束/多表/子查询,事务/连接池
文章目录 1.mysql安装:存储:集合(内存:临时),IO流(硬盘:持久化)1.1 服务端:双击mysql-installer-community-5.6.22.0.msi1.2 客户端:命令行输入my…...

模拟木马程序自动运行:Linux下的隐蔽攻击技术
模拟木马程序自动运行:Linux下的隐蔽攻击技术 在网络安全领域,木马程序是一种常见的恶意软件,它能够悄无声息地在受害者的系统中建立后门,为攻击者提供远程访问权限。本文将探讨攻击者如何在Linux系统中模拟木马程序的自动运行&a…...

vuex的配置主要内容
1、state 作用:负责存储数据; 2、getters 作用:state计算属性(有缓存); 3、mutaions 作用:负责同步更新state数据 mutaions是唯一可以修改state数据的方式; 4、actions 作用:负责异步操作&a…...
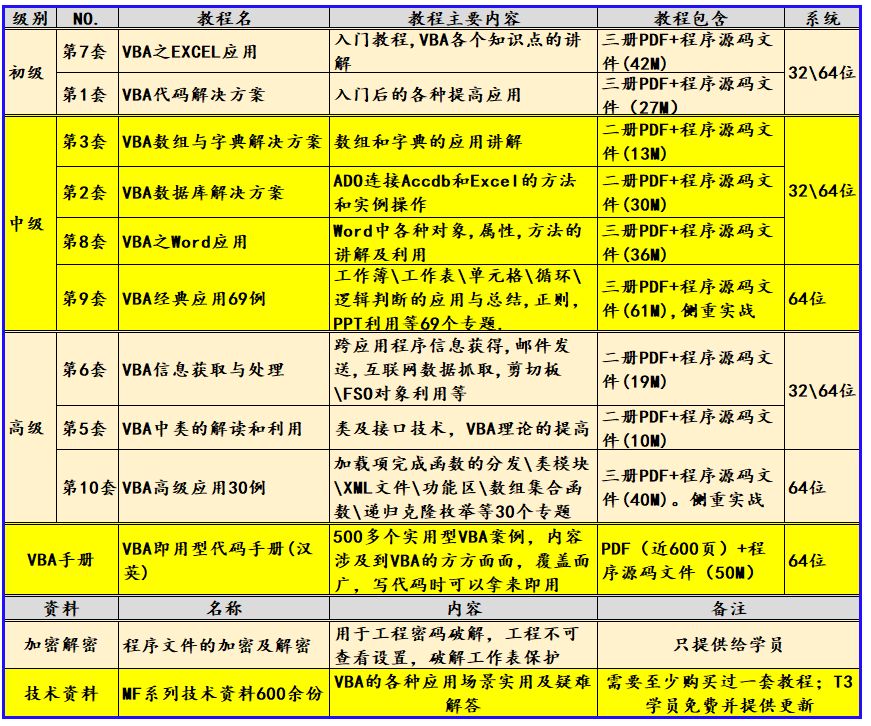
VBA技术资料MF164:列出文件夹中的所有文件和创建日期
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。“VBA语言専攻”提供的教程一共九套,分为初级、中级、高级三大部分,教程是对VBA的系统讲解&#…...
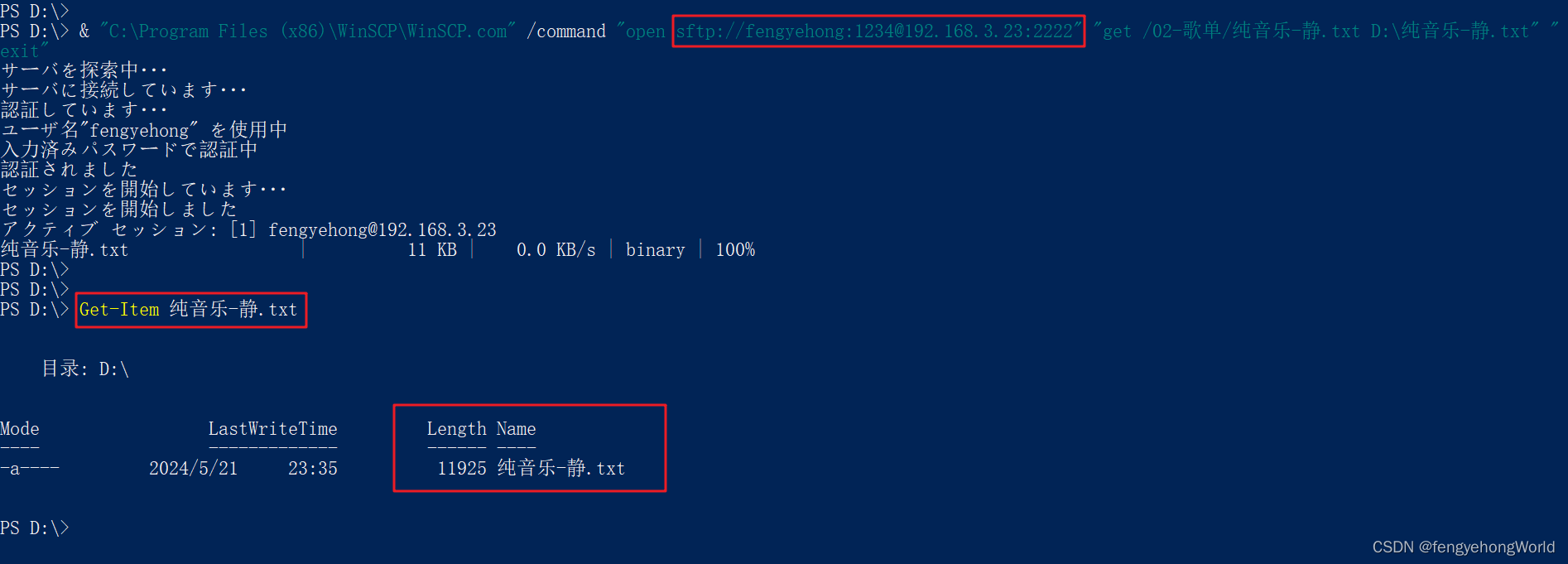
linux 简单使用 sftp 和 lftp命令
目录 一. 环境准备二. sftp命令连接到SFTP服务器三. lftp命令3.1 连接FTP和SFTP服务器3.2 将文件从sftp服务器下载到本地指定目录 四. 通过WinSCP命令行从SFTP服务器获取文件到Windows 一. 环境准备 ⏹在安卓手机上下载个MiXplorer,用作SFTP和FTP服务器 官网: htt…...

2.超声波测距模块
1.简介 2.超声波的时序图 3.基于51单片机实现的代码 #include "reg52.h" #include "intrins.h" sbit led1P3^7;//小于10,led1亮,led2灭 sbit led2P3^6;//否则,led1灭,led2亮 sbit trigP1^5; sbit echo…...

C语言之常用标准库介绍
文章目录 1 标准库1.1 诊断assert.h1.2 字符类别测试ctype.h1.3 错误处理errno.h1.4 整型常量limits.h1.5 地域环境locale.h1.6 数学函数math.h1.7 非局部跳转setjmp.h1.8 可变参数表stdarg.h1.9 公共定义stddef.h1.10 输入输出stdio.h1.11 实用函数stdlib.h1.12 日期与时间函数…...

Spring响应式编程之Reactor核心接口
响应式流的核心接口 核心接口包括:Publisher<T>、Subscriber<T>、Subscription 和 Processo<T,R> (1)Publisher<T> Publisher接口代表数据流的生产者,根据收到的请求向Subscriber发布数据。接口定义如…...

【HTTPS云证书部署】SpingBoot部署证书
这里以华为云证书为例。 1. 下载证书 2. 解压 3. 选择.top_Tomcat复制到SpringBoot的Resource/source下 4. 在.properties文件中进行配置 修改key-store和key-store-password...

React的状态提升和组合
React的状态提升 通常,多个组件需要反映相同的变化数据,这时我们建议将共享状态提升到最近的共同父组件中去 示例: 我们写一个关于热水沸腾的组件,当我们在输入框输入的温度大于100度时,文字会显示热水沸腾。这样有…...
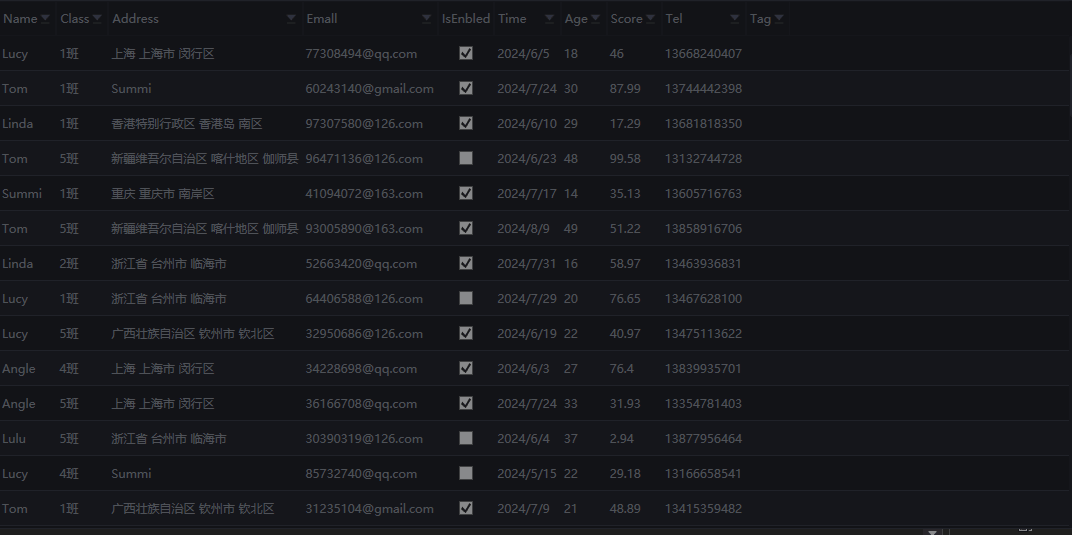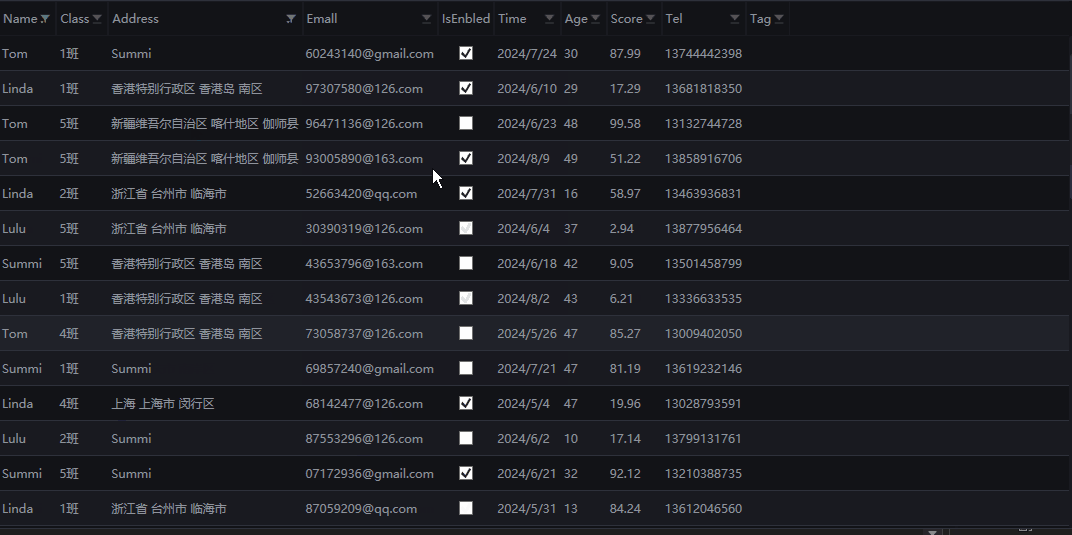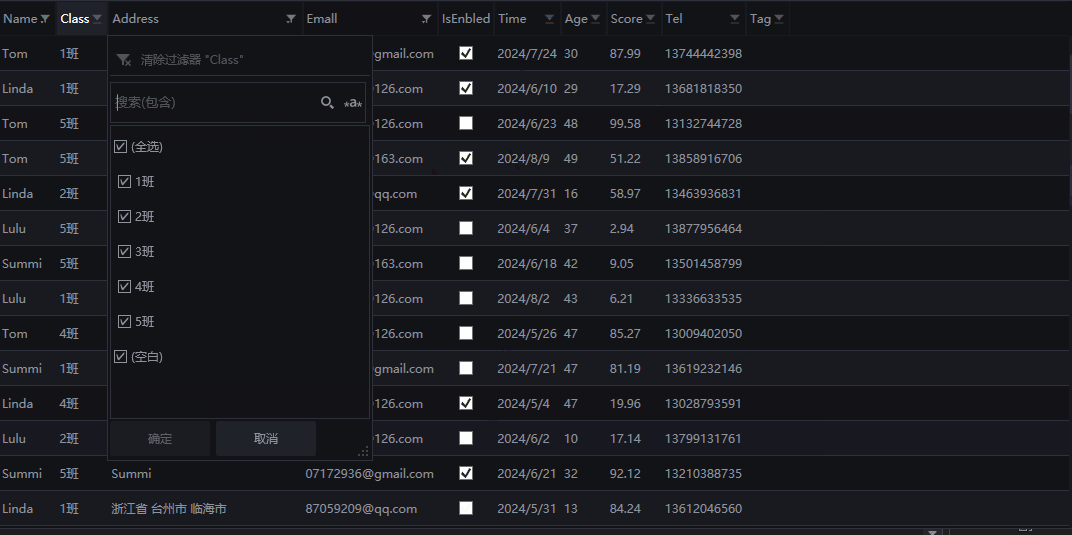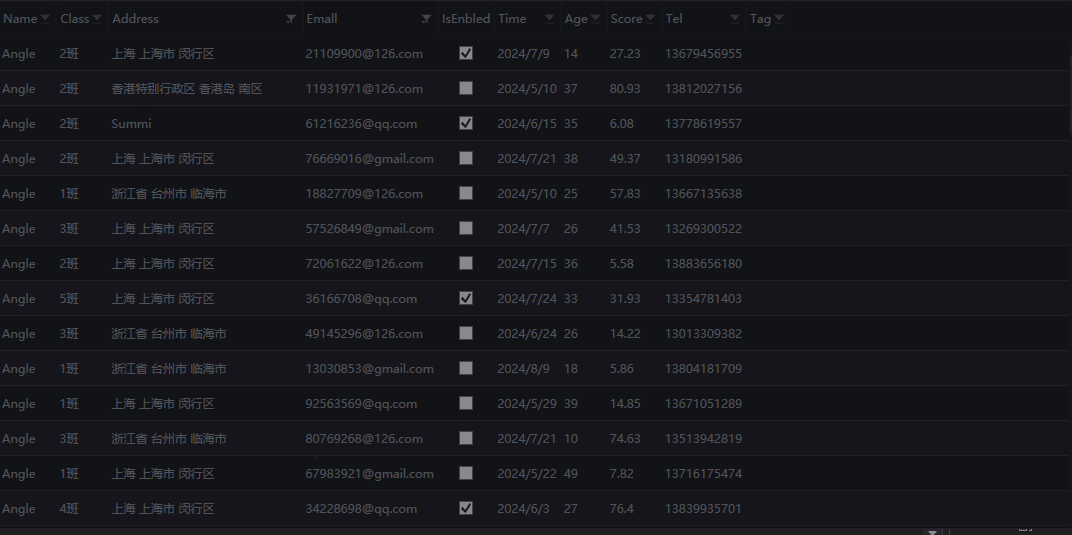
示例:推荐一个基于第三方开源控件库DataGridFilter封装的FilterColumnDataGrid,可以像Excel拥有列头筛选器
一、目的:基于第三方开源控件库DataGridFilter封装的FilterColumnDataGrid,可以像Excel拥有列头筛选器,感兴趣的可以去下方链接地址查看开源控件库地址。本控件封装的目的在于将第三方库的皮肤和样式封装到皮肤库中可统一设置样式,…...

Python: create object
# encoding: utf-8 # 版权所有 2024 涂聚文有限公司 # 许可信息查看: # 描述: # Author : geovindu,Geovin Du 涂聚文. # IDE : PyCharm 2023.1 python 3.11 # Datetime : 2024/6/15 18:59 # User : geovindu # Product : PyCharm # Pr…...

OpenSSL命令手册
正文共:999 字 10 图,预估阅读时间:1 分钟 我们前面编译安装了OpenSSL命令工具(CentOS编译安装OpenSSL 3.3.1),这是一个强大的安全套接字层密码库,可以用于实现各种加密和认证协议,如…...

基于React的记忆管理UI组件库:openclaw-memory-ui实战指南
1. 项目概述:一个为记忆管理而生的开源UI组件库最近在折腾一个需要处理大量结构化记忆数据的项目,比如知识库、笔记应用或者智能助手的历史对话管理。这类应用的核心痛点在于,数据本身是复杂的、多维的,但传统的列表或表格展示方式…...

016、Git版本控制与协作开发流程
016 Git版本控制与协作开发流程 一个让我熬夜到凌晨三点的.gitignore 去年做一款基于STM32U5的TinyML手势识别项目,团队四个人,代码库从第一天就开始膨胀。第三天晚上,我习惯性git push,然后去睡觉。凌晨三点被手机震醒——同事在群里@我:“你push了个啥?编译不过了。”…...

避坑指南:uniapp在微信小程序中调用相机和人脸识别的权限与兼容性问题
Uniapp微信小程序相机与人脸识别开发避坑指南 微信小程序作为轻量级应用平台,其相机与人脸识别功能在金融、社交、教育等领域应用广泛。然而,当开发者使用Uniapp这一跨平台框架进行微信小程序开发时,往往会遇到各种兼容性和权限问题。本文将深…...

本地可控 AI 助手搭建|Windows 一键安装 OpenClaw 操作指南
OpenClaw(小龙虾)Windows 一键部署保姆级教程|10 分钟搭建专属数字员工 前言 2026 年备受关注的开源 AI 智能体 OpenClaw(昵称小龙虾),在 GitHub 收获大量关注,凭借本地运行、零代码操作、自动…...

Minecraft物品堆叠架构深度解析:突破64限制的技术实现方案
Minecraft物品堆叠架构深度解析:突破64限制的技术实现方案 【免费下载链接】UltimateStack A Minecraft mod,can modify ur item MaxStackSize (more then 64) 项目地址: https://gitcode.com/gh_mirrors/ul/UltimateStack 在Minecraft模组开发领域…...

边缘计算赋能工业智能化:重大危险源监测+产线控制+视觉分析一体化解决方案
在工业 4.0 与智能制造深度融合的今天,工业现场产生的数据量呈指数级增长。传统的 "云端集中式" 数据处理架构在面对毫秒级实时控制、海量视觉数据传输、高危场景 724 小时不间断监测等需求时,逐渐暴露出延迟高、带宽成本大、网络依赖强、数据…...

容器镜像深度解析与生产级部署实战指南
1. 项目概述:从容器镜像名到高效部署实践的深度解析最近在梳理内部容器镜像仓库时,一个名为containers/ramalama的镜像引起了我的注意。这个名字乍一看有些无厘头,甚至带点戏谑,但在容器化部署的实践中,这类看似随意的…...

百度网盘Mac版破解插件:免费解锁SVIP高速下载的终极指南
百度网盘Mac版破解插件:免费解锁SVIP高速下载的终极指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘Mac版的龟速下载而烦…...

Cadence Allegro铺铜实战:从动态避让到静态优化,我的多层板效率提升心得
Cadence Allegro铺铜实战:从动态避让到静态优化,我的多层板效率提升心得 在高速PCB设计领域,Cadence Allegro作为行业标准工具,其铺铜功能直接影响设计效率与产品质量。当板层超过8层、元件密度突破500pin/inch时,动态…...

Spring Data Redis入门指南:5分钟快速搭建你的第一个Redis应用
Spring Data Redis入门指南:5分钟快速搭建你的第一个Redis应用 【免费下载链接】spring-data-redis Provides support to increase developer productivity in Java when using Redis, a key-value store. Uses familiar Spring concepts such as a template classe…...