【R语言】地理探测器模拟及分析(Geographical detector)
地理探测器模拟及分析
- 1. 写在前面
- 2. R语言实现
- 2.1 数据导入
- 2.2 确定数据离散化的最优方法与最优分类
- 2.3 分异及因子探测器(factor detector)
- 2.4 生态探测器(ecological detector)
- 2.5 交互因子探测器(interaction detector)
- 2.6 风险探测器(risk detector)
1. 写在前面
🗺️🔍地理探测器是一种用于探测空间分异性以及揭示其背后驱动因子的统计学方法。它由中国科学院地理科学与资源研究所的王劲峰研究员提出,并已被广泛应用于社会环境因素和自然环境因素的影响机理研究。地理探测器模型的核心思想是,如果某个自变量对某个因变量有重要影响,那么自变量和因变量的空间分布应该具有相似性。通过计算和比较各单因子的q值,可以判断它们对空间分异性的解释力,q值越大表示解释力越强。
在当前的研究进展方面,地理探测器已经被应用于多个领域,包括城市扩张驱动力因素分析、健康与风险因子关系的评估、土壤重金属的空间分异及其影响因素分析、青藏高原多年冻土分布影响因子分析等。此外,地理探测器模型的最优离散化研究也取得了进展,这对于提高模型评估结果的精度具有重要意义。
✨✨地理探测器模型的优势在于它没有过多的假设条件,可以克服传统统计方法处理变量所受的限制,因此在空间分析领域得到了广泛的应用和认可。随着研究的深入,地理探测器模型也在不断地优化和发展,以适应更多领域的研究需求。
当前已有很多的中英文文献涉及到了地理探测器,地理探测器主要包括了因子探测器、交互探测器、风险探测器和生态探测,其中因子探测器和交互探测器使用较为广泛。我个人人为交互探测器可以探测不同环境因子的交互作用,可以更加深刻地认识到环境变量之间的非线性、非对称和动态影响。




2. R语言实现
为了方便,我任意选择了一个数据集,数据内容如下:

其中Y为响应变量(因变量),X为自变量,一共2000个样本。此外,X5、X9和X10为类别型变量(离散变量)。
2.1 数据导入
首先进行相关包和数据导入,这里我们使用了地探测器“GD”包。此外,需要注意的是,read_exce() 函数导入的数据为tibble格式,但是GD中需要数据框格式,否则会报错,因此需要对数据格式进行转换:
library(GD)
library(openxlsx)
library(readxl)
setwd("D:/2007lucc")
data<-read_excel("result.xlsx")
View(data)
str(data)
# 将tibble数据格式转换为data.frame格式
data <- as.data.frame(data)
#class(data) # 查看数据类型,此时应为data.frame
str(data)
数据结构:
> str(data)
'data.frame': 2000 obs. of 11 variables:$ Y : num 97 97 97 97 97 97 97 97 89 105 ...$ X1 : num 17.1 17.6 16.8 16.8 17 ...$ X2 : num -2.45 -2.07 -2.48 -2.43 -2.37 ...$ X3 : num 68 68 69.4 68.4 68.4 ...$ X4 : num 993 1006 858 961 967 ...$ X5 : num 4 4 4 4 4 4 4 4 4 4 ...$ X6 : num 446 306 491 393 331 552 422 482 286 638 ...$ X7 : num 191 148 151 207 286 ...$ X8 : num 5.96 5.19 1.47 2.98 1.04 ...$ X9 : num 4 4 4 4 4 4 4 4 4 4 ...$ X10: num 23111112 23115192 23111112 23110140 23111112 ...
2.2 确定数据离散化的最优方法与最优分类
在进行地理探测器分析之前,需要对连续变量进行离散化操作,并且找到最佳离散类别,已进行更好的分析模拟。离散化方法主要包括:equal,natural,quantile,geometric和sd,通过optidisc()函数可以自动选择最优离散化方法和类别数。
#多个变量,包括连续变量
discmethod <-c("equal","natural","quantile","geometric","sd")
discitv <-c(3:7) #离散分类的数量,3到7类,建议不要分太多的类别,否则optidisc()函数运行时间过长
dataFin <- data
data.continuous <- dataFin[, c(1:5, 7:9)] # 只对连续变量进行离散化,一共有7个连续变量
#数据离散化
odc1 <-optidisc(Y~., data = data.continuous ,discmethod, discitv) # 这一步比较耗时,大概几分钟到几十分钟
dim(data.continuous)
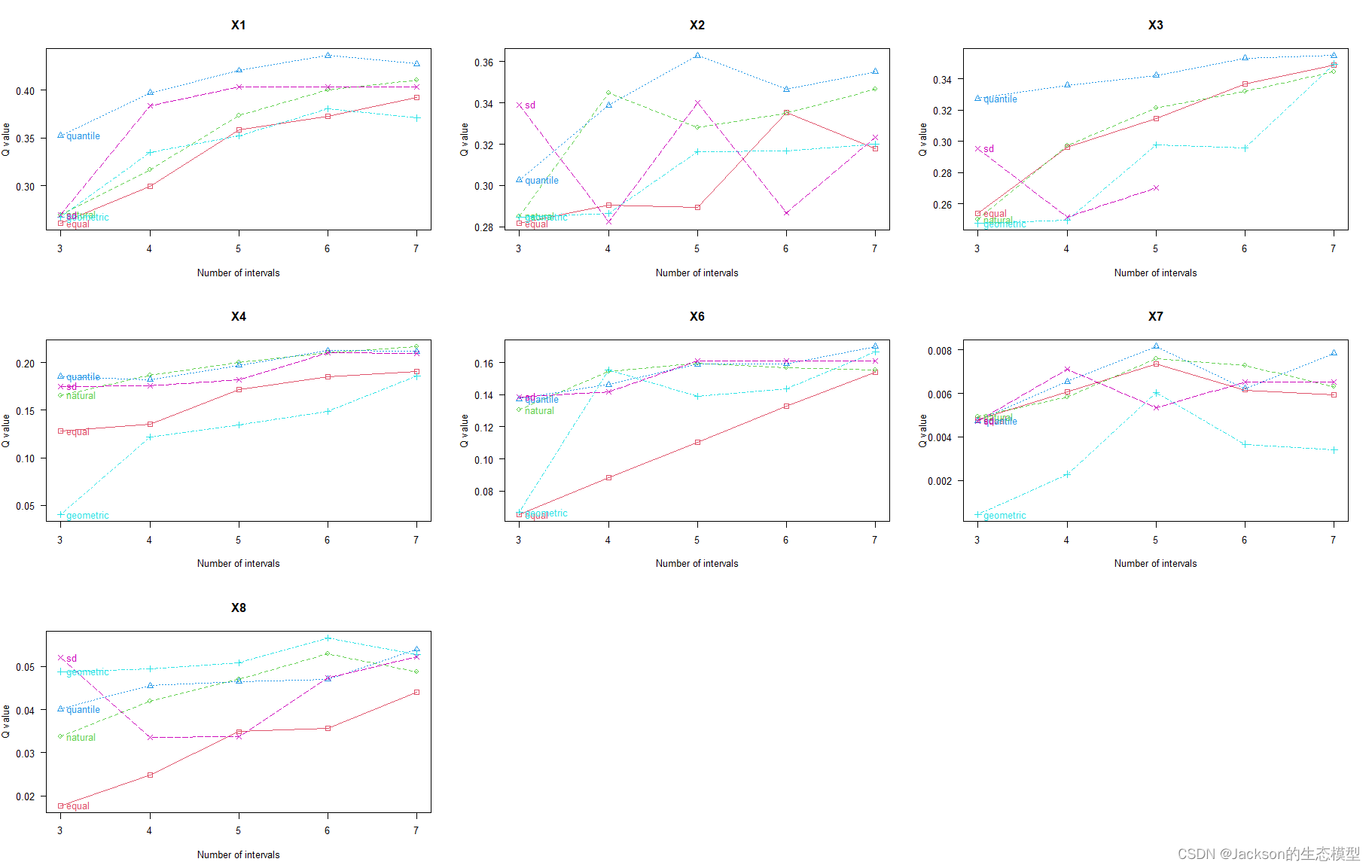
plot(odc1)
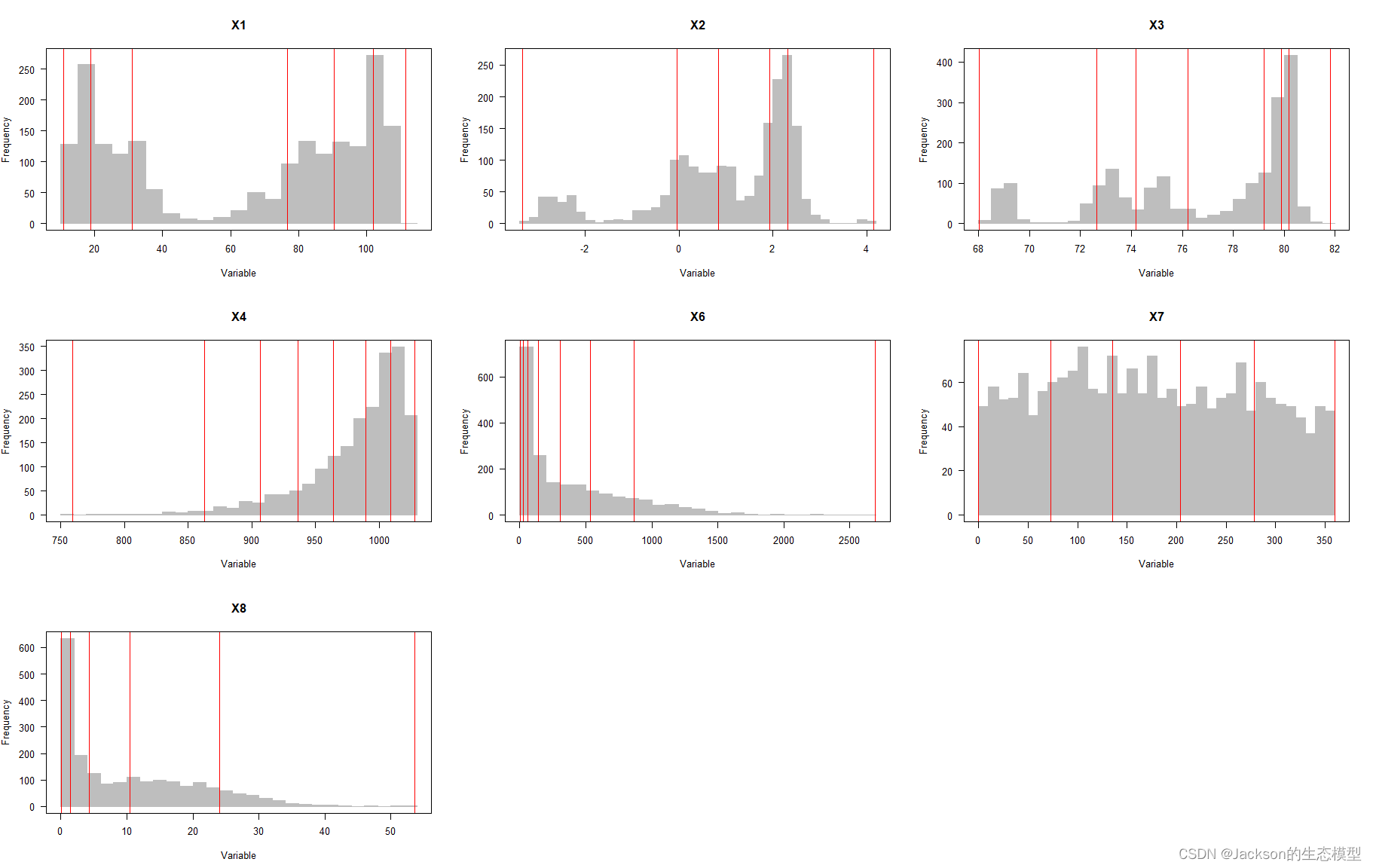
data.continuous <-do.call(cbind,lapply(1:7,function(x)data.frame(cut(data.continuous [, -1][, x],unique(odc1[[x]]$itv),include.lowest =TRUE))))
dataFin[,c(2:5, 7:9)] <-data.continuous
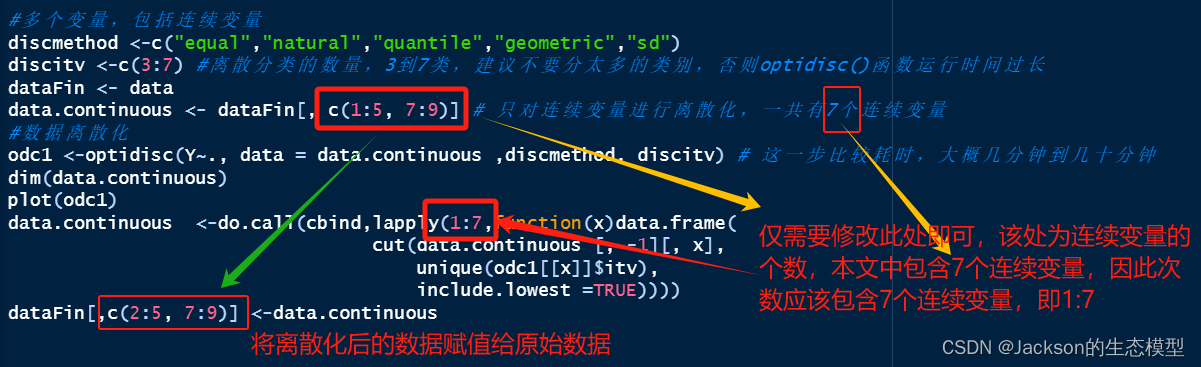
结果展示:
数据准备好之后就可以进行地理探测器(GD)分析了!!!
2.3 分异及因子探测器(factor detector)
分异及因子探测主要用于探测Y的空间分异性;以及探测某因子X多大程度上解释了属性Y的空间分异,用q值度量。简单点来说就是环境变量对因变量的贡献度。

写论文的时候,尽量将以上原理和公示进行展示和补充。
# 单因子探测器
gd <-gd(Y~., data = dataFin[,c(1, 2:11)])
gd
plot(gd)
> gdvariable qv sig
1 X1 0.43614146 1.387049e-10
2 X2 0.36292021 2.817672e-10
3 X3 0.35501601 8.356258e-10
4 X4 0.21368849 7.493217e-10
5 X5 0.11939089 6.191341e-10
6 X6 0.16985611 2.561658e-10
7 X7 0.00815299 2.947367e-03
8 X8 0.05664708 3.956563e-10
9 X9 0.23192232 3.588341e-10
10 X10 0.35382549 4.703113e-03

2.4 生态探测器(ecological detector)
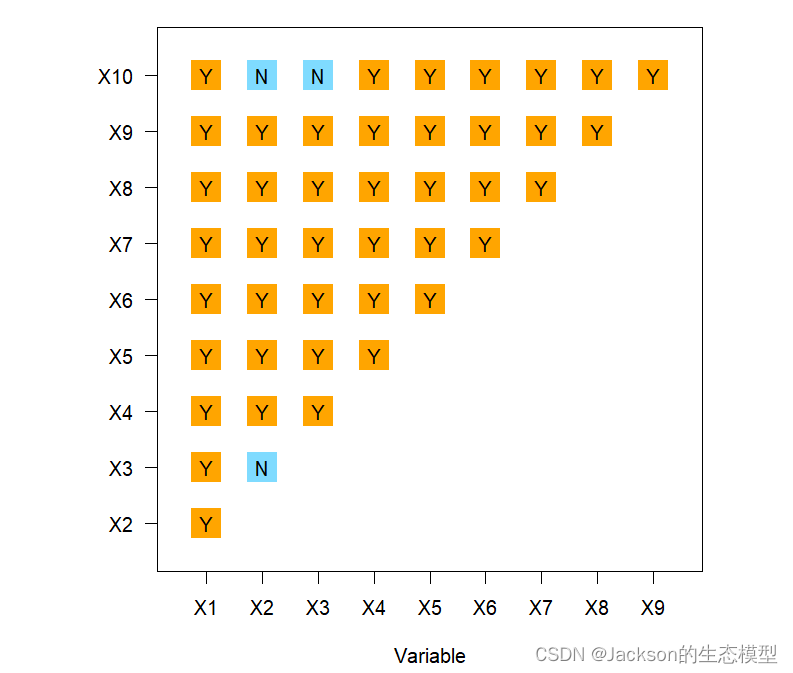
生态探测主要用于比较两因子X1和X2对属性Y的空间分布的影响是否有显著的差异
# 生态探测器
gdeco <-gdeco(Y~., data = dataFin[,c(1, 2:11)])
gdeco
plot(gdeco)
> gdeco
Ecological detector:variable X1 X2 X3 X4 X5 X6 X7 X8 X9 X10
1 X1 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
2 X2 Y <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
3 X3 Y N <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
4 X4 Y Y Y <NA> <NA> <NA> <NA> <NA> <NA> <NA>
5 X5 Y Y Y Y <NA> <NA> <NA> <NA> <NA> <NA>
6 X6 Y Y Y Y Y <NA> <NA> <NA> <NA> <NA>
7 X7 Y Y Y Y Y Y <NA> <NA> <NA> <NA>
8 X8 Y Y Y Y Y Y Y <NA> <NA> <NA>
9 X9 Y Y Y Y Y Y Y Y <NA> <NA>
10 X10 Y N N Y Y Y Y Y Y <NA>
2.5 交互因子探测器(interaction detector)
交互探测器共包含了5种类别,但根据以往的经验,结果以增强或非线性增强作用为主。

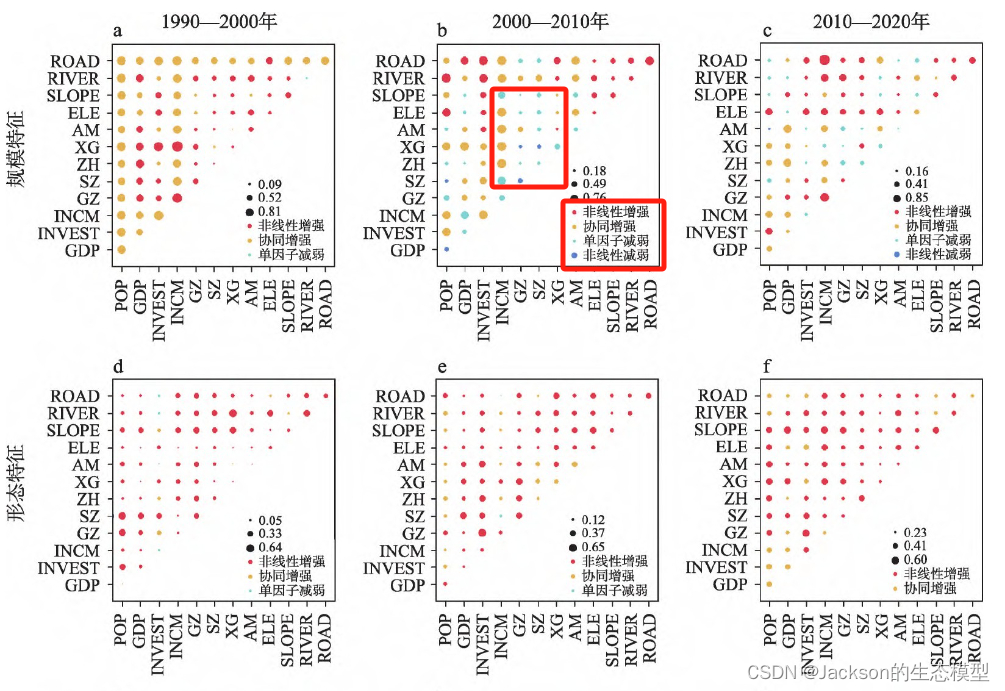
这里我选择了一篇论文的交互作用的结果,其中包含了4种类别的交互作用结果。
# 交互作用探测器
gdint <-gdinteract(Y~., data = dataFin[,c(1, 2:11)])
gdint
plot(gdint)
> gdint
Interaction detector:variable X1 X2 X3 X4 X5 X6 X7 X8 X9 X10
1 X1 NA NA NA NA NA NA NA NA NA NA
2 X2 0.4821 NA NA NA NA NA NA NA NA NA
3 X3 0.4750 0.4374 NA NA NA NA NA NA NA NA
4 X4 0.4675 0.4335 0.4599 NA NA NA NA NA NA NA
5 X5 0.4491 0.3925 0.3918 0.3180 NA NA NA NA NA NA
6 X6 0.4755 0.4038 0.4377 0.3242 0.3044 NA NA NA NA NA
7 X7 0.4476 0.3737 0.3636 0.2254 0.1277 0.1890 NA NA NA NA
8 X8 0.4573 0.3837 0.4029 0.2505 0.1910 0.1989 0.0693 NA NA NA
9 X9 0.4697 0.4158 0.3823 0.3602 0.2698 0.3462 0.2394 0.2902 NA NA
10 X10 0.5265 0.4758 0.4726 0.4445 0.3775 0.4457 0.3770 0.4073 0.4016 NA

总体而言,因子交互作用的结果表现为增强或者非线性增强。
2.6 风险探测器(risk detector)
判断两个子区域间的属性均值是否有显著的差别。若为N,则表示不显著,即两个子区域内属性均值无差别。若为Y,则有显著差别。
## 风险因子探测器
# 显著性
gdrisk <-gdrisk(Y~X1+X2+X3+X9, data = dataFin[,c(1, 2:11)])
gdrisk
plot(gdrisk)
# 风险探测(平均风险)
riskmean <- riskmean(Y~X1+X2+X3+X9, data = dataFin[,c(1, 2:11)])
riskmean
plot(riskmean)
相关文章:
【R语言】地理探测器模拟及分析(Geographical detector)
地理探测器模拟及分析 1. 写在前面2. R语言实现2.1 数据导入2.2 确定数据离散化的最优方法与最优分类2.3 分异及因子探测器(factor detector)2.4 生态探测器(ecological detector)2.5 交互因子探测器(interaction dete…...
深入理解Qt属性系统[Q_PROPERTY]
Qt 属性系统是 Qt 框架中一个非常核心和强大的部分,它提供了一种标准化的方法来访问对象的属性。这一系统不仅使得开发者能够以一致的方式处理各种数据类型,还为动态属性的管理提供了支持,并与 Qt 的元对象系统紧密集成。在这篇文章中&#x…...

【C语言课程设计】员工信息管理系统
员工信息管理系统 在日常的企业管理中,员工信息的管理显得尤为重要。为了提高员工信息管理的效率,我们设计并实现了一个简单的员工信息管理系统。该系统主要使用C语言编写,具备输入、显示、查询、更新(增加、删除、修改ÿ…...
「动态规划」如何求最长递增子序列的长度?
300. 最长递增子序列https://leetcode.cn/problems/longest-increasing-subsequence/description/ 给你一个整数数组nums,找到其中最长严格递增子序列的长度。子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其…...

深度神经网络DNN概念科普
深度神经网络DNN概念科普 深度神经网络(Deep Neural Network, DNN)是机器学习领域中一类具有多层结构的神经网络模型,它能够通过学习数据中的复杂模式来解决非线性问题。下面是对深度神经网络的详细解析: 基本组成部分 输入层&…...
Tomcat WEB站点部署
目录 1、使用war包部署web站点 2、自定义默认网站目录 3、部署开源站点(jspgou商城) 对主机192.168.226.22操作 对主机192.168.226.20操作 上线的代码有两种方式: 第一种方式是直接将程序目录放在webapps目录下面,这种方式…...

IPv6 中 MAC 33:33 的由来
一、33:33 由来 1. RFC9542 - 2024-05-02 Note IANA allocates addresses under the IANA OUI (00-00-5E) as explained in [RFC9542]. Unicast addresses under the IANA OUI start with 00-00-5E, while multicast addresses under the IANA OUI start with 01-00-5E. In t…...
告别手动邮件处理:使用imbox库轻松管理你的收件箱
imbox库简介: imbox是一个强大的Python库,专为与IMAP服务器交互而设计.IMAP(Internet Message Access Protocol)是一种用于电子邮件的标准协议,允许用户在远程服务器上管理邮件.imbox库通过IMAP协议与邮件服务器通信,帮助用户轻松地读取、搜索…...
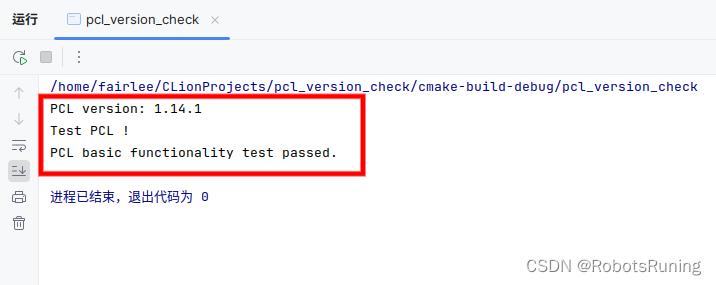
Ubuntu 18.04 安装 PCL 1.14.1
在进行科研项目时,我们常常需要将 C 和 Python 结合起来编程。然而,每次将 PCL(Point Cloud Library)的内容添加到 CMakeLists.txt 文件中时都会报错。在深入分析后,我们推测可能是当前使用的 PCL 1.8 版本与现有程序不…...
公司logo设计大全怎么找?直接帮你设计logo
公司logo设计大全怎么找?在品牌塑造的过程中,Logo无疑是至关重要的一环。一个优秀的Logo不仅能够有效传达公司的核心理念和品牌形象,还能在消费者心中留下深刻的印象。然而,对于许多初创公司或小型企业来说,制作出适合…...

如何调整C#中数组的大小
前言 数组存储多个相同类型的一种非常常用的数据结构。它长度是固定,也就是数组一旦创建大小就固定了。C# 数组不支持动态长度。那在C#中是否有方法可以调整数组大小呢?本文将通过示例介绍一种调整一维数组大小的方法。 方法 数组实例是从 System.Arr…...
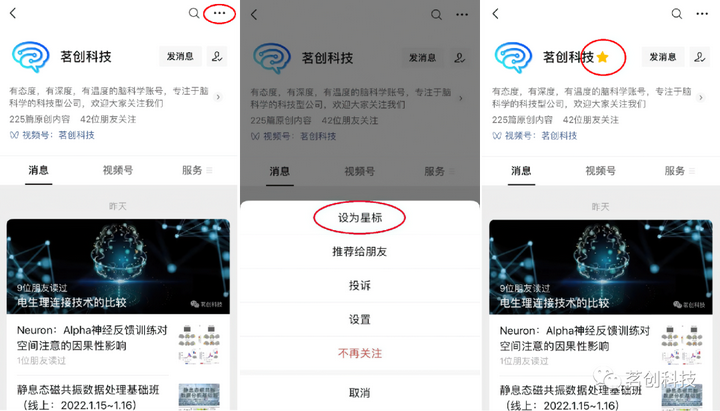
通过言语和非言语检索线索描绘睡眠中的记忆再激活茗创科技茗创科技
摘要 睡眠通过重新激活新形成的记忆痕迹来巩固记忆。研究睡眠中记忆再激活的一种方法是让睡眠中的大脑再次暴露于听觉检索线索(定向记忆再激活范式)。然而,记忆线索的声学特性在多大程度上影响定向记忆再激活的有效性,目前还没有得到充分探索。本研究通…...

MDPI旗下SSCI最新影响因子目录出炉!“水刊“Sustainability表现如何?
本周投稿推荐 SSCI • 1区,4.0-5.0(无需返修,提交可录) EI • 各领域沾边均可(2天录用) CNKI • 7天录用-检索(急录友好) SCI&EI • 4区生物医学类,0.1-0.5&…...

Matlab基础篇:数据输入输出
前言 数据输入和输出是 Matlab 数据分析和处理的核心部分。良好的数据输入输出能够提高工作效率,并确保数据处理的准确性。本文将详细介绍 Matlab 数据输入输出的各种方法,包括导入和导出数据、数据处理和数据可视化。 一、导入数据 Matlab 提供了多种方…...
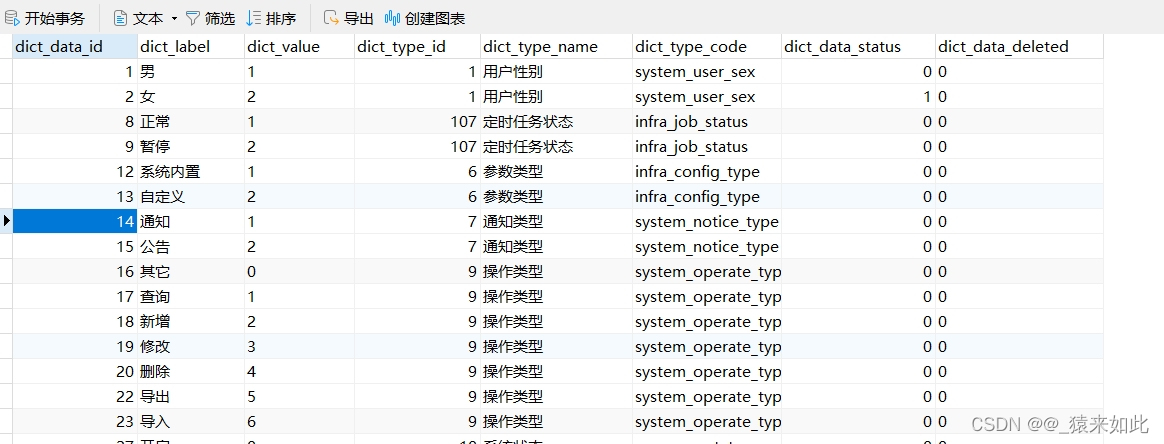
MySQL字典数据库设计与实现 ---项目实战
软件准备✍:Mysql与Navicat可视化命令大全 ----项目实战 文章前言部分 目录 一.摘要 二.设计内容 三.项目实现 一.摘要 本项目关注于字典数据库表结构的设计和数据管理。通过现有的sql文件,实现system_dict_type和system_dict_data两个数据表。随后…...

python数据分析——数据预处理
数据预处理 前言一、查看数据数据表的基本信息查看info()示例 查看数据表的大小shape()示例 数据格式的查看type()dtype()dtypes()示例一示例二 查看具体的数据分布describe()示例 二…...
【Python】使用matplotlib绘制图形(曲线图、条形图、饼图等)
文章目录 一、什么是matplotlib二、matplotlib 支持的图形三、如何使用matplotlib1. 安装matplotlib2. 导入matplotlib.pyplot3. 准备数据4. 绘制图形5. 定制图形6. 显示或保存图形7. (可选)使用subplots创建多个子图注意事项: 四、常见图形使…...

vue下载本地xls模版静态文件
需求导入的下载模版不想放在服务器放在前端本地下载静态资源最简单的方式直接访问 public 文件夹下的文件 方法一:使用静态文件路径 将文件放在 public 文件夹中: 把你的文件从 src/assets 移动到 public 文件夹。例如:public/template.xls。…...

手机开热点,里面的WPA2-Personal和WPA3-Personal的区别
WPA2-Personal和WPA3-Personal这两种协议都是用来保护无线网络安全的,但它们在加密强度和安全性方面有所不同。 WPA2-Personal (Wi-Fi Protected Access 2) WPA2是目前最广泛使用的Wi-Fi安全标准之一。它使用AES(Advanced Encryption Standard…...

算法课程笔记——点积叉积
算法课程笔记——点积叉积...

OpenClaw AVP:构建统一音视频协议栈,实现多协议流媒体处理
1. 项目概述:一个面向音视频处理的协议栈最近在整理一些音视频项目时,又翻到了avp-protocol/openclaw-avp这个仓库。对于从事流媒体、实时通信或者音视频编解码开发的工程师来说,看到avp这个缩写,第一反应多半是 “Audio-Video Pr…...

别再熬大夜改论文了!okbiye AI 写作,把毕业论文从选题到终稿焊在及格线以上
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 打开电脑,对着空白的 Word 文档发呆,开题报告和初稿大纲改了又改,导师的红批注比正文还长,格…...

Java Agent全链路追踪:无侵入分布式系统监控实战
1. 项目概述:一个面向分布式系统的全链路数据采集探针最近在跟几个做微服务架构的朋友聊天,大家都在头疼同一个问题:线上系统出点性能瓶颈或者偶发性错误,排查起来简直像大海捞针。服务A调用服务B,B又调用了C和D&#…...

AI驱动编辑预设生成:从风格迁移到创意工作流的自动化实践
1. 项目概述:AI驱动的编辑预设库最近在折腾视频和图片后期,发现一个挺有意思的项目,叫kaushalrao/ai-editor-presets。这名字听起来有点技术范儿,但说白了,它就是一个用人工智能技术来生成和优化各类编辑软件预设文件的…...

Svelte动态光标实现:提升Web应用交互体验的完整方案
1. 项目概述:一个为Svelte应用注入灵魂的交互光标在Web应用的世界里,细节决定体验。我们早已习惯了那个千篇一律的箭头指针,它精准、高效,但缺乏情感和上下文。当用户点击一个按钮、悬停在一个链接上,或者在一个可拖拽…...

从零解析ST电机库FOC:核心算法与工程实现
1. FOC技术基础:从三相电流到旋转磁场 我第一次接触FOC(Field Oriented Control)时,被那些复杂的数学公式搞得头晕目眩。直到有一天,我把无刷电机想象成小时候玩的磁铁小车,突然就明白了其中的奥妙。FOC本质…...

终极简单指南:如何用Seraphine英雄联盟助手快速提升排位胜率
终极简单指南:如何用Seraphine英雄联盟助手快速提升排位胜率 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 想象一下这样的场景:排位赛开始前,你正手忙脚乱地查询对手战绩…...

FPGA串行FIR滤波器设计:Verilog实现与资源优化实战
1. 项目概述在数字信号处理(DSP)的硬件实现领域,FIR(有限脉冲响应)滤波器因其绝对稳定性和线性相位特性,成为工程师们手中的一把利器。无论是通信系统的信道均衡,还是音频处理中的噪声抑制&…...

Amphenol ICC RJE1Y62A8327E401线束解析
在工业自动化、通信系统和高端电子设备中,线束组件不仅是连接器件的基础,更是保证系统信号完整性、电源稳定性和长期可靠运行的关键部件。今天,我们深度解析Amphenol ICC (Commercial Products)旗下的工业级线束型号RJE1Y62A8327E401…...

Arm Neoverse CMN-650架构与缓存一致性协议解析
1. Arm Neoverse CMN-650架构概述在现代多核处理器设计中,缓存一致性互连网络是决定系统扩展性和性能的关键组件。Arm Neoverse CMN-650作为第二代Coherent Mesh Network解决方案,采用了创新的分布式目录协议和优化的传输机制,能够支持多达12…...