AI交互及爬虫【数据分析】

 个人主页:在线OJ的阿川
个人主页:在线OJ的阿川
大佬的支持和鼓励,将是我成长路上最大的动力
阿川水平有限,如有错误,欢迎大佬指正


Python 初阶
Python–语言基础与由来介绍
Python–注意事项
Python–语句与众所周知
数据清洗前 基本技能
数据分析—技术栈和开发环境搭建
数据分析—Numpy和Pandas库基本用法及实例
AI交互爬虫前 必看
数据分析—三前奏:获取/ 读取/ 评估数据
数据分析—数据清洗操作及众所周知
数据分析—数据整理操作及众所周知
数据分析—统计学基础及Python具体实现
数据分析—数据可视化Python实现超详解
数据分析—推断统计学及Python实现
数据分析—线性及逻辑回归模型
目录
- AI概述
- AI在编程领域的应用
- 主流AI
- AI注意事项
- 数据分析领域AI作用及爬虫
AI概述
在这个时代 AI 与我们每个人 息息相关
1956年 在美国召开了第一场人工智能研讨会,由此人类开始了对人工智能道路探索。
在这场会议上,纽维尔和西蒙演示了一个名为"逻辑学家"的程序充分展示了机器能做类似推理的工作。在这个会议上人工智能获得了定义。
1978年 国内第一所 人工智能与智能控制研究组在清华大学成立,并且同年招收了第1批硕士生。那时主要以智能机器人作为主要研究方向。
1990年,智能技术与系统国家重点实验室正式建立,标志着中国第1次开始正式开展人工智能相关研究。
时间发展至今,人工智能已经有三个阶段:第一代人工智能,第二代人工智能,第三代人工智能。
从最初的第一代人工智能,让机器像人一样思考,培养从已知知识出发,推出新的结论、新的知识的能力。
第二代人工智能主要基于人工神经网络模拟人脑脑神经网络的工作原理
但是第二代人工智能由于所有训练的数据 均来自客观世界,从而它的识别只能识别不同的物体,并不能真正的认识物体。
第三代人工智能则是依靠模型和算法来支持发展,并在此过程中发展了一系列人工智能理论。
而目前市面上的AI大语言模型,则是将第一代人工智能的知识为驱动,和第二代人工智能的数据以及提炼出的算法和模型以及算力同时运用而成。
大语言模型的大,来自于两个"大"
第1个"大"是大的人工神经网络
人工神经网络可以用来分类学习数据中间的关联关系,也可以用来预测。
第2个"大"是大的文本
由于第1个大的发展,导致所有文本不用经过任何预处理就可以学习,所以文本就由最初的GB量级发展为TB量级。
大模型的局限性
缺乏主动性(依赖于提示工程)且输出质量不可控(会出现计算机"幻觉"), 且AI工具尚不能准确分辨对错,也难以主动进行自我迭代(也需要不断花钱去砸算力)。
但目前人工智能最大的问题是:
即专用人工智能(在 特定 的领域用 特定 的模型完成 特定 的任务)
而接下来人工智能将向通用人工智能进行发展
除此以外,人工智能应要具有身体,所以说必须通过机器人与客观世界连在一起
在未来,越来越多的人学习AI是大势所趋,而学习AI的人要么向各行各业转移,为各行各业进行赋能;要么就和其他技术结合,发展出新的产业。
各位,人工智能对各行各业都有重大影响,但大多数是帮助人类提高工作质量和效率,而非取代人类进行工作。(这里应该放一个链接哈)
送上喜欢的一句话:
"让混沌重生,然后掌握混沌"
未来已来,不因物喜,不以己悲,需要的是坚持不懈的努力,天道酬勤

AI在编程领域的应用
- 解释概念
可用详细且易懂的回答,并且尽可能配合简单的例子对不懂的概念进行解释

- 解决报错
给报错信息进行分析并修正

- 找Bug
可提交自己写的代码及本身预期

- 给知识点出题
可让其提出相应知识点练习并附上答案

- 提示代码质量
提交自己代码并问如何改进.

主流AI
目前市面上主要的AI有:
1. Open AI(官网,访问需翻墙)
2. Meta AI(官网,访问需翻墙)
3. 通义千问
4. 智谱清言
5. 文心一言
6. 讯飞星火
AI注意事项
- 使用AI前 可先给予AI一个身份 帮助更好提高准确回答质量
与此同时 衍生出提示工程prompt(一个庞大的领域【截至2024年6月20日,OpenAI、斯坦福等多所机构筛选出1565篇论文发布大模型《提示技术报告》】(要翻墙哈,若不想翻墙,也想看,可以联系我) 可以帮助提高AI回答质量)


- AI幻觉
AI有些时候会一本正经的胡说八道,应该有自己的分辨能力,所以学习和掌握分析相关的技能去检验生成AI生成的结果(例如:可以将AI生成的Python代码去运行,若成功运行且符合预期则表示成功)

数据分析领域AI作用及爬虫
前言
在Jupyter notebook中内置有专门的Jupyter AI
- 可以直接在写代码的环境中与AI进行交互
安装Jupyter AI(Python版本应高于或等于3.8)
- 输入pip install jupyter_ai

选择AI大模型
安装相应AI大模型Python库

例如:安装gpt4all

具体领域
- 什么具体指标值得分析

-
数据集哪不干净怎么清洗

-
数据集得到什么结论

-
找数据集
- 官方网站可供下载查看的数据集
需查看是否开启了网页浏览模式
若用OpenAI,则先创建OpenAI账户及Open AI密钥和Open AI的Token数量上限
- 官方网站可供下载查看的数据集

- API(A pplication P rogramming Interface 应用程序编程接口) 从官方获取数据
优点:
更可靠(因为通常是官方提供的)
更合规(爬虫可能违反违规)
易解析( API返回数据更易解析 API返回的格式更结构化)
更准确(有些提供的数据比网页上更加全面和准确)
1. **第一步** **确定API端点**(**不同**功能的**API有特定端点**)
2. **第二步** **请求方法**(绝大部分**API是基于HTTP** 即所有要**知道各个端点所对应的HTTP方法**)
GET方法 requests.get
- 获得数据
**PUT方法 requests.put**- **更新数据** **POST方法 requests.post**- **提交数据****DELETE方法 requests.delete**- **删除数据**
-
第三步 查询参数(指定额外的信息) 请求体数据(比查询参数信息包含更多)
-
第四步 响应格式
响应的格式一般是XML和 JSON(常见),用Python实现
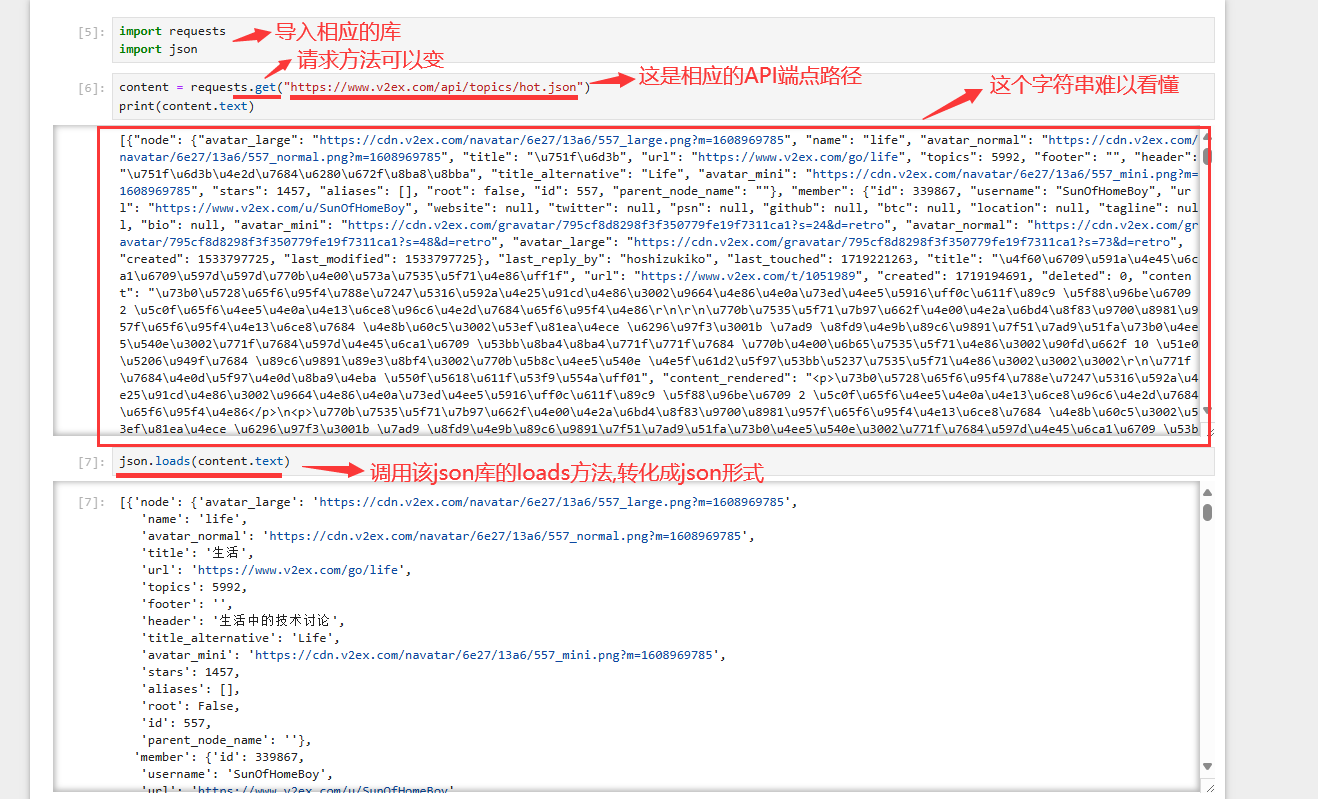
注意有些条件也很关键:是否要求认证信息;是否只有认证通过,有授权的用户才能访问。官方文档会把这些说明清楚,所以搜索和查阅文档是一项很重要的能力
-
网络爬虫 便捷且低成本获取数据
- 第一步:获取网页内容
主要的是Requests库
- 第一步:获取网页内容

HTTP(Hypertext Transfer Protocol 超文本传输协议)请求和响应

HTTP请求

User-Agent:

Accept:

常用的两种请求方法
- GET方法
浏览器向网页获取数据
request.get(“完整路径”) HTTP请求
生成一个实例
head={ }
可以自定义传入的HTTP的请求头内容
正常浏览器浏览会发出GTE请求 即会自带浏览器的内容和版本及电脑操作系统等
而正常程序中就不会带有浏览器的内容和版本,则此时一些服务器就会拒绝响应该请求,此时就可以更改这个user-Agent,更改成含有浏览器的内容和版本,从而可以将爬虫程序伪装成正常浏览器

- POST方法
创建数据
注意事项
- 客户端请求数量和频率 不能太多,否则无异于DDOS攻击(发送海量请求让网站资源无法服务正常用户,让用户无法正常访问)
- 若网站有反爬机制,不要去强行突破
- 应该查看网站的robots文件,查看了解可爬取的网页路径范围
- 不要去爬
- 公民隐私 国家事务/国防 尖端科技领域的计算机系统
图5
- 公民隐私 国家事务/国防 尖端科技领域的计算机系统
HTTP响应

状态码主要有
200 OK 客户端请求成功
2表示成功,请求完成
301 Moved Permanently 资源被永久移动到新地址
3表示重定向,需要进一步操作
400 Bad Request 客户端不能被服务器所理解
401 Unauthorized 请求未经授权
403 Forbidden 服务器拒绝提供服务
404 Not Found 请求资源不存在 例如:请求里面有错误 请求的资源无效
4表示客户端错误
500 Internal Server Error 服务器发生不可预期的错误
503 Server Unavailable 服务器当前不能处理客户端的请求 例如:出现问题 正在维修等
5表示服务器错误

get实例.status_code 返回回答的编码
get实例.Ok 属性可看请求是否成功
get实例.text 以字符串形式储存内容

- 第二步:解析网页内容 HTML网页结构
主要是BeautifulSoup库
pip install bs4 BeautifulSoup 安装BeautifulSoup库

from bs4 import BeautifulSoup 导入相应的模板

一个网页有三大技术要素:
-
CSS 定义网页的格式(可以增加美观度)
-
JavaScript 定义用户和网页的交互逻辑
- 前两大技术非数据分析重点,这里不加以赘述
-
HTML 定义网页的结构和信息
- 写HTML一般使用Pycharm和Vscode等主流编辑器,我这里采用Vscode编辑器(打开速度很快)
若将vscode的编辑器改成中文字体:


- 写HTML一般使用Pycharm和Vscode等主流编辑器,我这里采用Vscode编辑器(打开速度很快)
HTML 格式
- < !DOCTYPE HTML> 告知浏览器该文件类型为HTML
- < html> html文件起始 表示开始(是HTML文档的根)
- < /html> html文件闭合 表示结束
- < head>…< /head> html标题
- 一般放 < title>…< /title> 定义HTML网页页面标题
- < body>…< /body> html主体
- 一般放html标签


HTML 标签
层级类标签
< h1>…< /h1> < h2>…< /h2> < h3>…< /h3> …… < h6>…< /h6> 表示文本层级

换行类标签
< p>…< /p> 默认换行
< br> 在文本段落中强制换行 且只有起始标签,没有闭合标签

顺序类标签
< ol>…< /ol> 表示有序列表的标签
< ul>…< /ul> 表示无序列表的标签
- < li>…< /li> 与有序或者无序搭配使用,表示顺序

文字类标签
< b>…< /b> 进行文字加粗
< i>…< /i> 将文字变成斜体
< u>…< /u> 将文字加下划线

图片类标签
< img src=" 图片路径"> 添加图片
- width=" " 图片宽度
- height=" " 图片高度

表格类标签
< table> …< /table> 表示表格
- border=“数字” 该参数表示表格边框的大小 默认为0,即没有边框
- < thead>…< /thead> 表示表格头部
- < tbody>…< /tbody> 表示表格主体
- < tr>…< /tr> 定义表格行
- < td> 定义表格数据

链接类标签
< a href=“路径”>自定义输出 文字 < /a> 添加超链接
- target=" " 该参数指定窗口打开方式
- _self 表示在当前页面打开窗口
- _blank 表示在新页面打开窗口

class属性
- 定义元素的类名称,从而帮助分组
例如:
< pclass=“content”>给岁月以文明< /p>
< pclass=“content”>而不是给文明以岁月< /p>
< pclass=“review”>好评!< /p>

容器类标签
容器 本身不包含任何内容
< div>…< /div> 块级元素,独占自己的一块,一行最多一个< div>作为其中子元素
< span>…< /span> 内联元素,不会独占一块,一行可以多个span元素

HTML元素类型很多
可以在浏览器里点击右键(显示网页源代码)

或者
可以在浏览器点击右键(检查,再点一下窗口左上角小箭头,这样点击页面任何一个东西都会显示其元素)


BeautifulSoup函数(get实例,“html.parser”)
- "html.parser" 为解析器
- 会生成BeautifulSoup实例
该实例包含特别多的方法和属性
例如:
BeautifulSoup实例.p 获取html第1个p元素
BeautifulSoup实例.img 获取htm还有一个img图片元素

soup.fillAII() 能根据标签属性等方法找出所有符合要求的元素
- (“标签”,attrs={“想找的属性”:" 想找的值"}) 返回可迭代对象
- 可迭代对象.string属性 将标签包围的文字返回 还可以使用切片[ : ]
find() 可获取第一个对象

爬虫技术要求,要随机应变,爬取自己想要的信息,爬虫总需要我们跟网站斗智斗勇
- 第三步 储存式分析数据(由于具体需求具体处理,这里不加以赘述)
若要收集数据集 则将数据储存进数据库
若要分析数据趋势 则将数据进行可视化
若要舆情监控 则将AI文本情绪分析

好的,到此为止啦,祝您变得更强
想说的话
实不相瞒,写的这篇博客写了13个小时以上(加上自己学习(反复学习了5遍)和纸质笔记(写了满满的6页),共十五小时吧),很累,希望大佬支持

| 道阻且长 行则将至 |
|---|
个人主页:在线OJ的阿川大佬的支持和鼓励,将是我成长路上最大的动力 
相关文章:
AI交互及爬虫【数据分析】
各位大佬好 ,这里是阿川的博客,祝您变得更强 个人主页:在线OJ的阿川 大佬的支持和鼓励,将是我成长路上最大的动力 阿川水平有限,如有错误,欢迎大佬指正 Python 初阶 Python–语言基础与由来介绍 Python–…...

001、DM8安装
参照:https://eco.dameng.com/document/dm/zh-cn/pm/install-uninstall.html 1. 准备工作 操作系统查看 [rootora19c ~]# cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core)新建用户 [rootora19c ~]# groupadd dinstall -g 2001 [rootora19c ~]# …...

SEO之关键词趋势波动和预测
初创企业搭建网站的朋友看1号文章;想学习云计算,怎么入门看2号文章谢谢支持: 1、我给不会敲代码又想搭建网站的人建议 2、新手上云 前面研究关键词搜索次数时,通常只看一段时间的搜索次数,比如一个月之内。但绝大多数关…...
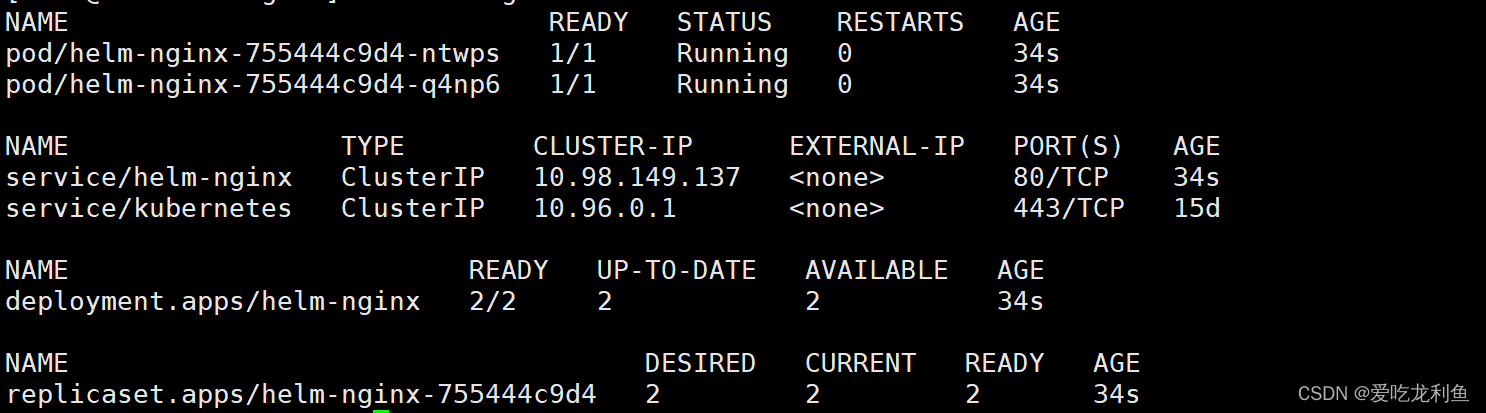
k8s学习--chart包开发(创建chart包)
文章目录 chart包应用环境一、安装helm客户端工具二、chart包目录结构三、创建不可配置的chart1.创建目录和chart.yaml2.创建deployment.yaml3.创建service.yaml4.使用chart安装应用5.查看和验证 四、创建可配置的Chart1.官方的预定义变量2.新增values.yaml文件3.配置deploy引用…...

【STM32】中断应用概述
前面我们知道在手册中有一个中断向量表,初步了解了中断的概念。 1.NVIC简介 NVIC是嵌套向量中断控制器,控制着整个芯片中断相关的功能,它跟内核紧密耦合,是内核里面的一个外设。 在固件库中,NVIC的结构体定义可谓是…...

Python应用开发——30天学习Streamlit Python包进行APP的构建(9)
st.area_chart 显示区域图。 这是围绕 st.altair_chart 的语法糖。主要区别在于该命令使用数据自身的列和指数来计算图表的 Altair 规格。因此,在许多 "只需绘制此图 "的情况下,该命令更易于使用,但可定制性较差。 如果 st.area_chart 无法正确猜测数据规格,请…...

智慧园区数字化能源云平台的多元化应用场景,您知道哪些?
智慧园区数字化能源云平台的多元化应用场景,您知道哪些? 智慧园区数字化能源云平台,作为新一代信息技术与传统能源管理深度融合的典范,正引领着产业园区向智慧化、绿色化转型的浪潮。该平台依托于大数据、云计算及人工智能等前沿…...

操作系统入门 -- 死锁
操作系统入门 – 死锁 1.什么是死锁、死锁产生的条件 1.1 死锁 在两个或多个并发进程中,如果每个进程都持有某种资源,并且正在等待其他进程释放它或进程都保持资源,在当前状态下无法推进。通俗来说就是两个或多个进程进入无限期阻塞、互相…...

结合Boosting理论与深度ResNet:ICML2018论文代码详解与实现
代码见:JordanAsh/boostresnet: A PyTorch implementation of BoostResNet 原始论文:Huang F, Ash J, Langford J, et al. Learning deep resnet blocks sequentially using boosting theory[C]//International Conference on Machine Learning. PMLR, 2…...

Python使用策略模式绘制图片分析多组数据
趋势分析:折线图静态比较:条形图分布分析:箱线图离散情况:散点图 import matplotlib.pylab as plt from abc import ABC, abstractmethod import seaborn as sns import pandas as pd import plotly.graph_objects as go import p…...
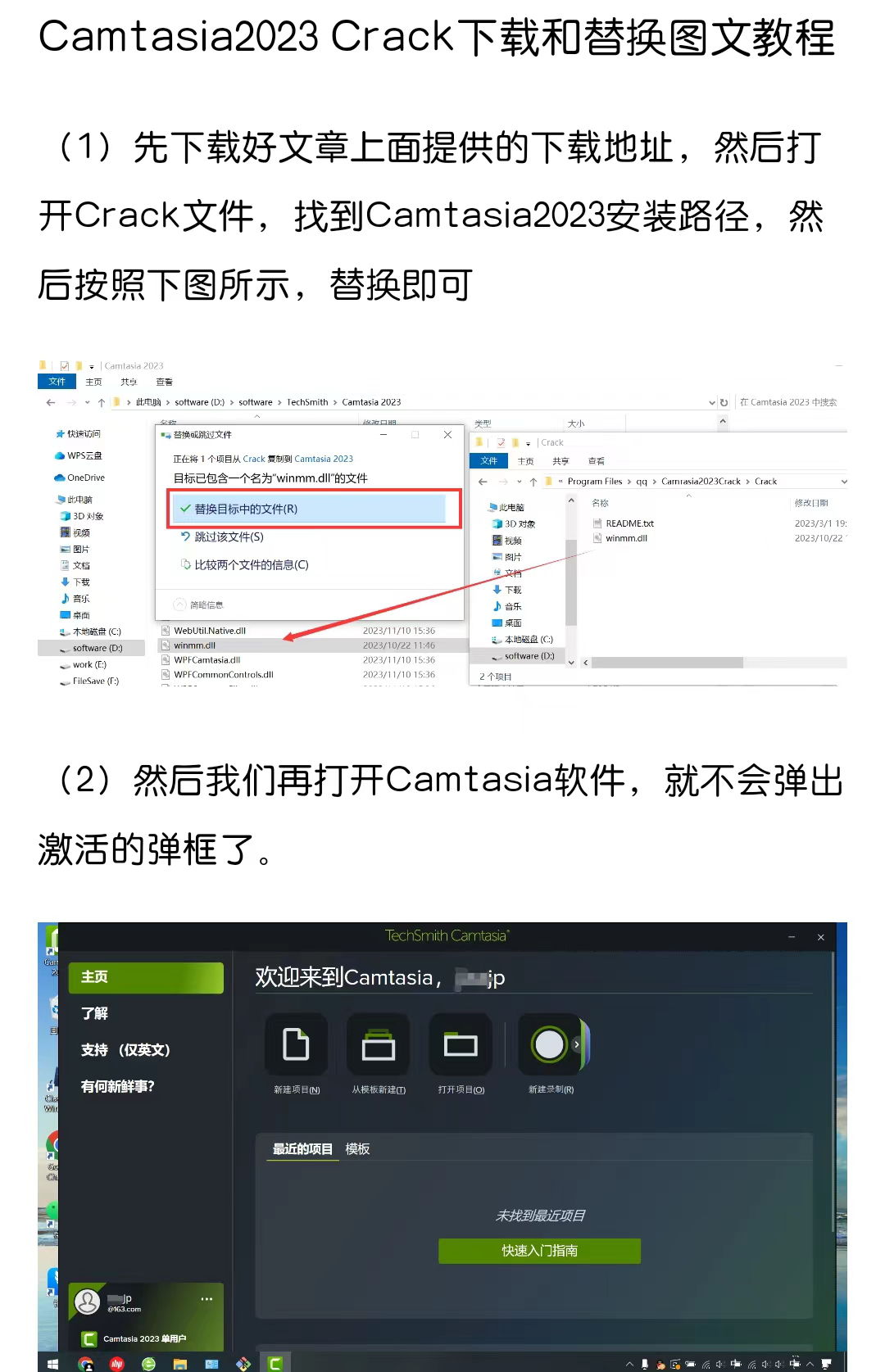
【软件下载】Camtasia Studio 2024详细安装教程视频
习惯上来说Camtasia Studio是一款简单易用的高清录屏和视频编辑软件,拥有录制屏幕和配音、视频的剪辑和过场动画片、添加说明字幕和水印、制作视频封面和菜单、视频压缩和播放。不得不说Camtasia是一款屏幕录制和视频剪辑软件,教授课程,培训他…...
爬虫笔记15——爬取网页数据并使用redis数据库set类型去重存入,以爬取芒果踢V为例
下载redis数据库 首先需要下载redis数据库,可以直接去Redis官网下载。或者可以看这里下载过程。 pycharm项目文件下载redis库 > pip install redis 然后在程序中连接redis服务: from redis import RedisredisObj Redis(host127.0.0.1, port6379)…...
我是如何在markdown编辑器中完成视频的插入和播放的
如果你有更好用的编辑器组件,请一定推荐给我!!!(最好附带使用说明🤓️) 介绍 在开发一个社区页面的时候,需要完成发帖、浏览帖子的能力。这里考虑接入markdown编辑器进行开发,也符合大多数用户的习惯。 …...
Ltv 数据粘包处理
测试数据包的生成 校验程序处理结果和原始的日志保温解析是否一致 程序粘包分解正常...

银联支付,你竟然还不知道它怎么工作?
银联支付咱都用过,微信和支付宝没这么“横行”的时侯,我们取款、转账、付款时用的ATM机、POS机,都是银联支付完成的。 今天,就让咱们了解一下银行卡支付的工作原型。 首先,说说中国银联 中国银联(China U…...

查找程序中隐藏界面的思路
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动 某些程序,它会有管理员界面(比如棋牌游戏,它一般会有一个控制端界面,用来控制发牌、换牌),但是这种界…...

umount
umount命令用于卸载文件系统,使得挂载点的文件和目录变为不可访问。 基本用法: umount [选项] 设备或文件夹 常见选项: -f:强制卸载,即使文件系统处于忙碌状态(在某些情况下使用,如网络文件…...

electron录制应用-自由画板功能
功能 录屏过程中的涂画功能允许用户在录制屏幕操作的同时,实时添加注释和高亮显示,以增强信息的传达和观众的理解。 效果 electron录制-添加画布 代码实现 1、利用HTML5的Canvas元素实现一个自由涂画的功能,允许用户在网页上进行手绘创作。…...

版本控制工具-git分支管理
目录 前言一、git分支管理基本命令1.1 基本命令2.1 实例 二、git分支合并冲突解决三、git merge命令与git rebase命令对比 前言 本篇文章介绍git分支管理的基本命令,并说明如何解决git分支合并冲突,最后说明git merge命令与git rebase命令的区别。 一、…...
医卫医学试题及答案,分享几个实用搜题和学习工具 #学习方法#知识分享#经验分享
可以说是搜题软件里面题库较为齐全的一个了,收录国内高校常见的计算机类、资格类、学历类、外语类、工程类、建筑类等多种类型的题目。它可以拍照解题、拍照答疑、智能解题,并支持每日一练、章节练习、错题重做等特色功能,在帮助大家解答疑惑…...

从 Palantir Ontology 到企业 AI 决策系统
这几年,大模型把企业 AI 的想象空间一下子拉高了。很多公司都已经能做聊天、做问答、做检索、做 Copilot,甚至做一些初步的 Agent。但真正往生产里推,很快就会撞到几个老问题:模型能说,却未必真懂业务;能总…...

LZ4与ZSTD压缩算法在LLM内存优化中的硬件实现对比
1. 项目概述:压缩算法在LLM内存优化中的关键作用 在大型语言模型(LLM)推理过程中,内存带宽和容量一直是制约性能的关键瓶颈。特别是随着模型规模的不断扩大,KV缓存(Key-Value Cache)所占用的内存…...

基于Claude API构建本地化智能对话应用栈:从架构设计到生产部署
1. 项目概述与核心价值最近在尝试构建一个基于Claude API的本地化应用栈时,我发现了dtannen的claude-stacks项目。这本质上不是一个单一的应用程序,而是一个精心设计的、模块化的技术栈蓝图。它旨在为开发者提供一个快速启动和运行Claude API应用的完整解…...

快速上手Redis
一、认识Redis Redis 是一个内存数据库,常用于缓存和高性能数据存储。特点: 数据存储在内存,读写速度快(毫秒级甚至微秒级)支持多种数据结构:String、Hash、List、Set、Sorted Set(ZSet&#…...

JAVA练习:单一职责原则重构
问题背景原始Login类同时承担界面展示、登录校验、数据库连接、用户查询、程序入口多重职责,功能高度耦合,违反单一职责原则(一个类只负责一类功能),修改某部分功能易影响其他模块。重构思路按职责拆分,分为…...

5分钟掌握网盘直链解析神器:彻底告别下载限速烦恼
5分钟掌握网盘直链解析神器:彻底告别下载限速烦恼 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

5分钟学会用ASCII字符绘制专业流程图:告别复杂设计软件
5分钟学会用ASCII字符绘制专业流程图:告别复杂设计软件 【免费下载链接】asciiflow ASCIIFlow 项目地址: https://gitcode.com/gh_mirrors/as/asciiflow 你是否曾为绘制简单的流程图而打开臃肿的设计软件?或者需要在代码注释中嵌入清晰的流程说明…...

被论文压到喘不过气?Paperxie 本科论文功能,把你的毕业节奏拉回正轨
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ai/dissertationhttps://www.paperxie.cn/ai/dissertation 毕业季的焦虑,一半来自答辩,一半来自毕业论文。选题卡壳、文献找不全、格式改到崩溃、写了…...

S19|MCP 与插件:多 Agent 平台 —— 外部能力总线,让外部工具安全接入
在前十八章,我们的 Agent 已经拥有完整的内部能力体系:循环、工具、计划、子代理、技能、压缩、权限、Hook、记忆、提示词流水线、错误恢复、任务系统、后台任务、定时调度、多 Agent 团队、团队协议、自主代理、Worktree 隔离,所有工具都写在…...

优化sVLM 的计算效率:轻量级注意力机制
在 sVLM 中,轻量级注意力机制的核心目标不是简单把模型做小,而是减少多模态推理中最贵的部分: 1. 视觉 token 太多 2. 图像 token 进入 LLM 后参与自注意力 3. 自注意力复杂度随序列长度近似 O(N) 4. 小模型虽然参数少,但视觉 tok…...