Elasticsearch Scroll 报错entity content is too long
2024-06-24 15:22:01:568 ERROR [task-31] (ScrollFetcherProduceAction.java:129) 访问ES出错org.apache.http.ContentTooLongException: entity content is too long [112750110] for the configured buffer limit [104857600]at org.elasticsearch.client.HeapBufferedAsyncResponseConsumer.onEntityEnclosed(HeapBufferedAsyncResponseConsumer.java:76) ~[elasticsearch-rest-client-6.1.1.jar:6.1.1]at org.apache.http.nio.protocol.AbstractAsyncResponseConsumer.responseReceived(AbstractAsyncResponseConsumer.java:137) ~[httpcore-nio-4.4.13.jar:4.4.13]at org.apache.http.impl.nio.client.MainClientExec.responseReceived(MainClientExec.java:315) ~[httpasyncclient-4.1.4.jar:4.1.4]at org.apache.http.impl.nio.client.DefaultClientExchangeHandlerImpl.responseReceived(DefaultClientExchangeHandlerImpl.java:151) ~[httpasyncclient-4.1.4.jar:4.1.4]at org.apache.http.nio.protocol.HttpAsyncRequestExecutor.responseReceived(HttpAsyncRequestExecutor.java:315) ~[httpcore-nio-4.4.13.jar:4.4.13]at org.apache.http.impl.nio.DefaultNHttpClientConnection.consumeInput(DefaultNHttpClientConnection.java:255) ~[httpcore-nio-4.4.13.jar:4.4.13]high-level-rest api 在获取大量数据的时候报了这个错。 之前的解决办法是修改Option 设置heap 大小,但是这次集群是使用的6.1.1 版本,没有这个参数
办法:
在代码中修改Scroll Request的 size() 函数
```
searchRequest.scroll(keepAlive).source().size(2000);
```
在我的程序里用一个参数控制
elastic.sql.fetch.scroll.size: 2000
我默认是5000,把这个改成小一些,一次http请求就不会返回那么多数据就可以解决。
相关文章:

Elasticsearch Scroll 报错entity content is too long
2024-06-24 15:22:01:568 ERROR [task-31] (ScrollFetcherProduceAction.java:129) 访问ES出错org.apache.http.ContentTooLongException: entity content is too long [112750110] for the configured buffer limit [104857600]at org.elasticsearch.client.HeapBufferedAsync…...

Vue iview输入框change事件replace正则替换不生效问题的解决。
// 需求:输入座机号只允许输入数字和"-" onChange(e){this.$nextTick(()>{this.phone e.target.value.replace(/[^0-9-]/g, );}) } 解决:添加**this.$nextTick**即可...

Prestashop跨境电商独立站,外贸B2C网站完整教程
Prestashop是一款来自法国专业的开源电商CMS(内容管理系统)平台,和wordpress一样比较轻量,适合中小网站。Prestashop跨境电商独立站在国内并不是很流行,不过国外是非常火的,从各大平台的Prestashop主题数量就可以看得出来。 最有…...

常用算法及参考算法 (1)累加 (2)累乘 (3)素数 (4)最大公约数 (5)最值问题 (6)迭代法
常用算法及参考算法 (1)累加 (2)累乘 (3)素数 (4)最大公约数 (5)最值问题 (6)迭代法 1. 累加 #include <stdio.h>int main() {…...
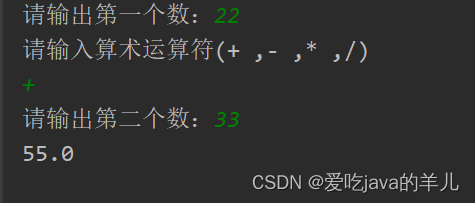
java简易计算器(多种方法)
parseDouble() 方法属于 java.lang.Double 类。它接收一个字符串参数,其中包含要转换的数字表示。如果字符串表示一个有效的 double,它将返回一个 double 值。 应用场景 parseDouble() 方法在以下场景中非常有用: 从用户输入中获取数字&a…...

spring的bean定义和扫描规则
1、bean的基本定义 在Spring框架中,Bean是一个核心概念,它是Spring IoC(Inverse of Control,控制反转)容器管理的一个对象实例。简单来说,Bean就是由Spring容器初始化、配置和管理的对象。这些对象可以是J…...
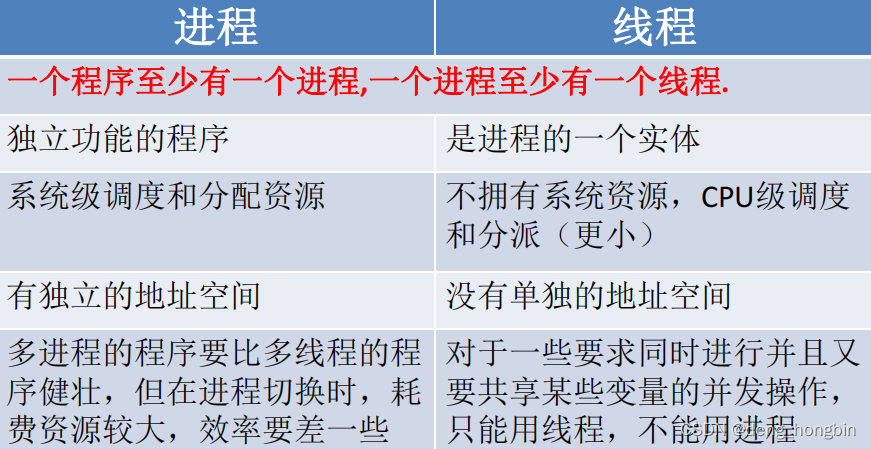
软件工程体系概念
软件工程 软件工程是应用计算机科学、数学及 管理科学等原理开发软件的工程。它借鉴 传统工程的原则、方法,以提高质量,降 低成本为目的。 一、软件生命周期 二、软件开发模型 1.传统模型 瀑布模型、V模型、W模型、X 模型、H 模型 (1)瀑布模型 瀑布…...
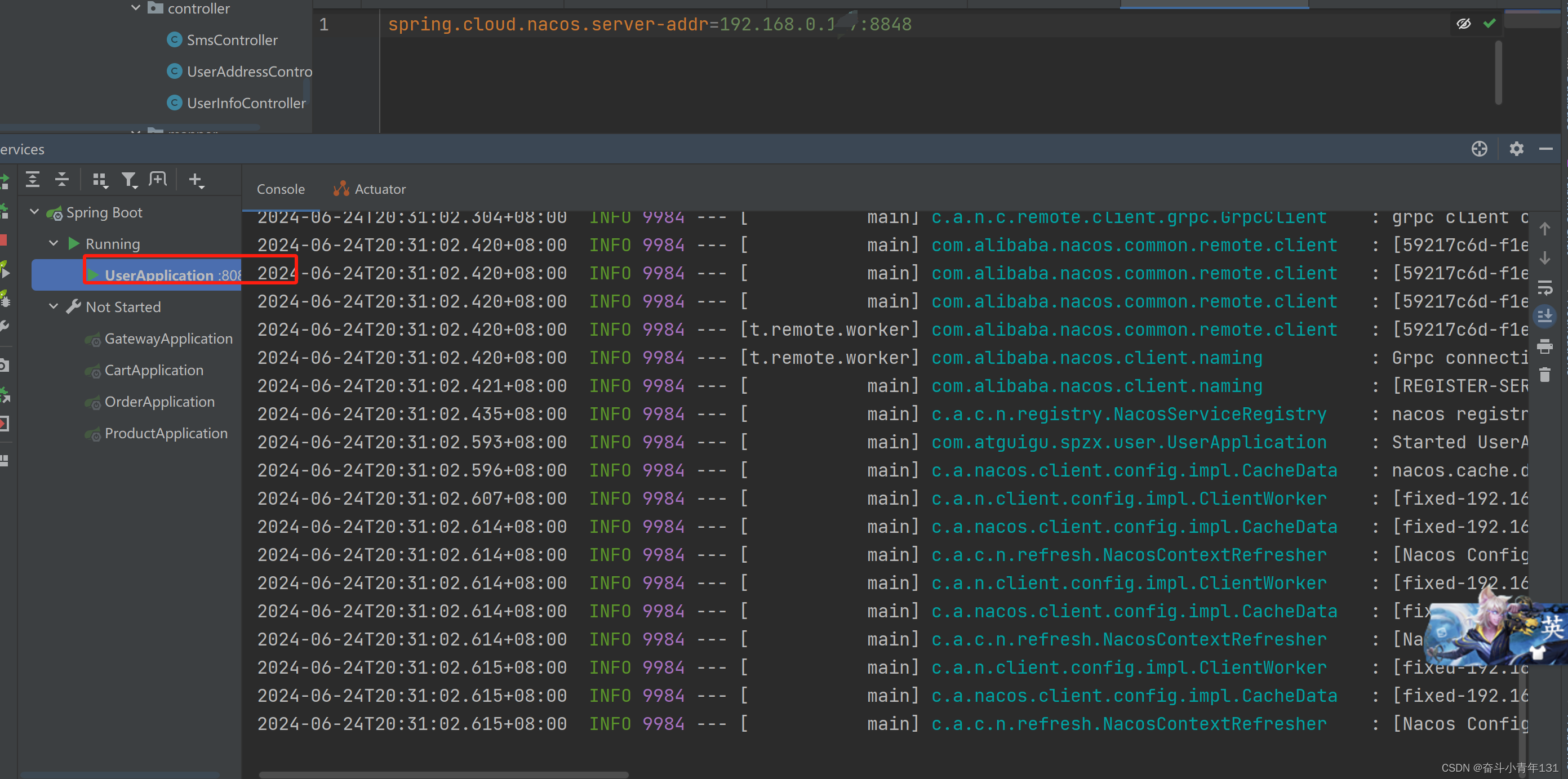
史上最全整合nacos单机模式整合哈哈哈哈哈
Nacos 是阿里巴巴推出的一个新开源项目,它主要是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。 Nacos提供了一组简单易用的特性集,帮助用户快速实现动态服务发现、服务配置、服务元数据及流量管理。 Nacos 的关键特性包括&#x…...

Python xml.dom.minidom 读取XML元素
哈喽,大家好,我是木头左! 什么是 XML? XML(可扩展标记语言)是一种用于描述数据结构和交换数据的标记语言。它被广泛用于 Web 应用程序中,用于存储和传输数据。XML 具有自描述性,因此可以很容易地理解和处理。 Python 中的 xml.dom.minidom Python 提供了一个内置的库…...

【Python/Pytorch 】-- K-means聚类算法
文章目录 文章目录 00 写在前面01 基于Python版本的K-means代码02 X-means方法03 最小二乘法简单理解04 贝叶斯信息准则 00 写在前面 时间演变聚类算法:将时间演变聚类算法用在去噪上,基本思想是,具有相似信号演化的体素具有相似的模型参数…...

【Eureka】介绍与基本使用
Eureka介绍与基本使用 一个简单的Eureka服务器的设置方法:1 在pom.xml中添加Eureka服务器依赖:2 在application.properties或application.yml中添加Eureka服务器配置:3 创建启动类,使用EnableEurekaServer注解启用Eureka服务器&am…...
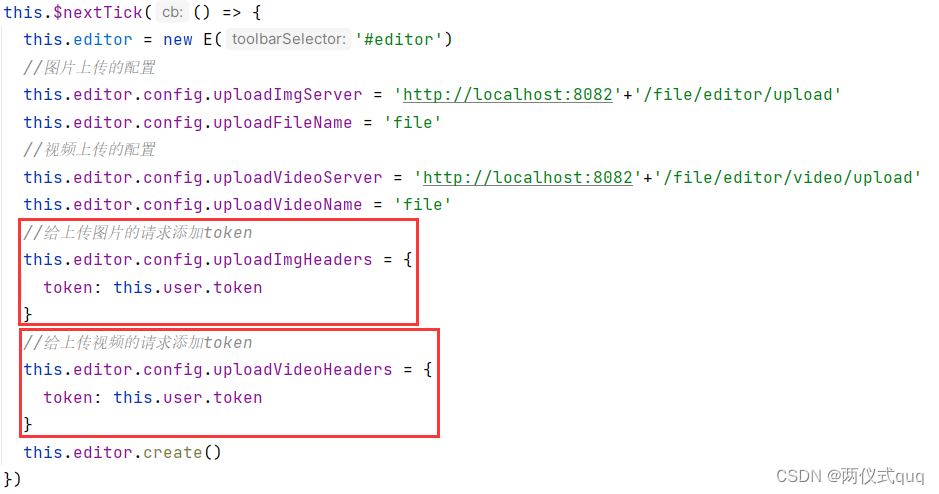
SpringBoot+Vue集成富文本编辑器
1.引入 我们常常在各种网页软件中编写文档的时候,常常会有富文本编辑器,就比如csdn写博客的这个页面,包含了富文本编辑器,那么怎么实现呢?下面来详细的介绍! 2.安装wangeditor插件 在Vue工程中,…...

React@16.x(34)动画(中)
目录 3,SwitchTransition3.1,原理3.1.2,key3.1.2,mode 3.2,举例3.3,结合 animate.css 4,TransitionGroup4.1,其他属性4.1.2,appear4.1.2,component4.1.3&…...

ONLYOFFICE 8.1:全面升级,PDF编辑与本地化加强版
目录 📘 前言 📟 一、什么是 ONLYOFFICE 桌面编辑器? 📟 二、ONLYOFFICE 8.1版本新增了那些特别的实用模块? 2.1. 轻松编辑器 PDF 文件 2.2. 用幻灯片版式快速修改幻灯片 2.3. 无缝切换文档编辑、审阅和查…...

C++ 入门
前言 c的发展史: C的起源可以追溯到1979年,当时Bjarne Stroustrup在贝尔实验室开始开发一种名为“C with Classes”的语言。以下是C发展的几个关键阶段: 1979年:Bjarne Stroustrup在贝尔实验室开始开发“C with Classes”。1983…...

GPT-5发布倒计时:AI智能从高中生到博士生的跨越
嘿,小伙伴们!最近有个大新闻,OpenAI的首席技术官米拉穆拉蒂在一次采访中透露,GPT-5将在一年半后发布。她把这个升级比作从聪明的高中生到博学的博士生的飞跃,听起来是不是很酷? 现在GPT-4o还有不少功能没上…...

Docker 拉取镜像失败处理 配置使用代理拉取
解决方案 1、在 /etc/systemd/system/docker.service.d/http-proxy.conf 配置文件中添加代理信息 2、重启docker服务 具体操作如下: 创建 dockerd 相关的 systemd 目录,这个目录下的配置将覆盖 dockerd 的默认配置 代码语言:javascript 复…...

视频汇聚安防综合管理系统EasyCVR平台GB28181设备注册未上线的原因排查与解决
视频汇聚安防综合管理平台EasyCVR视频监控系统基于云边端架构,可支持海量视频汇聚集中管理,能提供视频监控直播、云端录像、云存储、录像检索与回看、告警(协议告警/智能告警/1400视图库告警)、平台级联、AI智能分析接入等视频能力…...
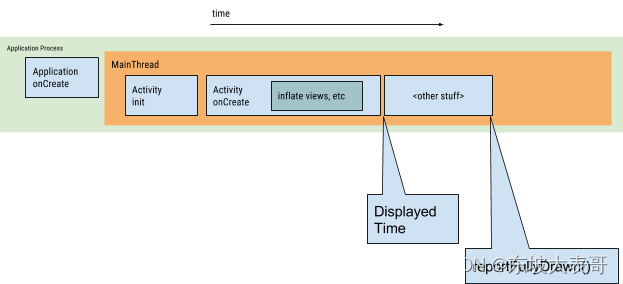
【性能优化】Android冷启动优化
文章目录 常见现象APP的启动流程计算启动时间Displayed Timeadb dump 启动优化具体策略总结参考链接 常见现象 各种第三方工具初始化和大量业务逻辑初始化,影响启动时间,导致应用启动延迟、卡顿等现象 APP的启动流程 加载和启动应用程序; …...

Git拉完整代码缺少某个类
已找到具体问题,对比之后发现应该是拉去的文件名字字符太长导致! 使用 Git LFS Git LFS(Large File Storage)是 Git 的一个扩展,它可以帮助管理大型文件,包括长文件名。如果你的项目包含大量的大型文件或长…...

面向对象_昂瑞微_作者观点仅供参考
C 语言面向对象编程实例解析 选自 OnMicro OM6626 BLE SDK 中的 DFU(Device Firmware Upgrade)模块。 适合有一定 C 基础、想理解"如何在 C 中实现面向对象"的初级工程师。 一、先看最终效果:调用方完全不关心底层实现 在 onmicro…...

考公学习追踪器:用数据驱动备考,打造个人学习仪表盘
1. 项目概述:一个为“考公”学子量身定制的学习追踪器如果你正在准备公务员考试,或者身边有朋友在“考公”,那你一定对那种“学了忘,忘了学”的循环深有体会。行测的题海、申论的素材、时政的热点,每天的学习任务像一座…...

raylib终极指南:3天从零到一的游戏开发快速入门
raylib终极指南:3天从零到一的游戏开发快速入门 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib raylib是一款专为游戏开发设计的轻量级跨平台框架&am…...
开源清理工具OpenClearn:透明可控的数字垃圾管理方案
1. 项目概述:一个开源的“清洁工”如何重塑你的数字生活如果你和我一样,是个在数字世界里摸爬滚打了十几年的老鸟,那你电脑里肯定也有一堆“数字垃圾”。这些垃圾不是指那些过时的文件,而是那些你明明已经删除了,但操作…...

别再只会用Matplotlib画基础热力图了!这5个高级定制技巧让你的图表瞬间专业
解锁Matplotlib热力图的5个高阶美学密码:从基础图表到专业可视化 当你第一次用Matplotlib画出热力图时,那种成就感就像解开了数据分析的第一道密码。但随着项目复杂度的提升,那些默认参数生成的图表开始显得单薄——颜色映射不够精准、标注信…...

VR-Reversal终极指南:免费将3D VR视频转换为2D播放的完整方案
VR-Reversal终极指南:免费将3D VR视频转换为2D播放的完整方案 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.co…...

终端工作空间新选择:从 tmux 到 Zellij 的迁移与实战
1. 为什么需要从 tmux 迁移到 Zellij 作为一个用了五年 tmux 的老用户,我最初对 Zellij 这个"新玩具"是持怀疑态度的。直到有一次在远程服务器上调试时,tmux 的窗格突然卡死,所有工作进度瞬间归零,我才开始认真寻找替代…...

React Styleguidist权限控制终极指南:如何实现私有组件文档访问限制
React Styleguidist权限控制终极指南:如何实现私有组件文档访问限制 【免费下载链接】react-styleguidist Isolated React component development environment with a living style guide 项目地址: https://gitcode.com/gh_mirrors/re/react-styleguidist R…...

ARM CoreSight ROM Tables解析与调试实践
1. ARM CoreSight ROM Tables基础解析在嵌入式调试领域,ARM CoreSight架构提供了一套完整的调试与追踪解决方案。作为该架构的关键组成部分,ROM Tables扮演着系统调试资源的"目录"角色。想象一下走进一个巨大的图书馆,ROM Tables就…...

避坑指南:用MOT17训练YOLOv7检测器时,为什么你的mAP上不去?可能是数据划分的锅
MOT17数据集划分陷阱:为什么你的YOLOv7检测器性能不达标? 当你在MOT17数据集上训练YOLOv7检测器时,是否遇到过这样的困境:损失曲线看起来完美,训练集准确率节节攀升,但验证集mAP却始终徘徊在低水平…...