Zookeeper 二、Zookeeper环境搭建
Zookeeper安装方式有三种,单机模式和集群模式以及伪集群模式
- 单机模式:Zookeeper只运行在一台服务器上,适合测试环境
- 集群模式:Zookeeper运行于一个集群上,适合生产环境,这个计算机集群被称为一个“集合体”
- 伪集群模式:就是在一台服务器上运行多个Zookeeper实例
1.单机模式搭建
- 下载
下载稳定版本的Zookeeper:
https://zookeeper.apache.org/releases.html
- 上传
下载完成后,将Zookeeper压缩包上传到Linux系统
- 解压压缩包
tar -zxvf apache-zookeeper-3.8.4.tar.gz
- 进入zookeeper-3.8.4 目录,创建data文件夹
cd zookeeper-3.8.4
mkdir data
- 修改配置文件名称
cd conf
mv zoo_sample.cfg zoo.cfg
- 修改zoo.cfg中的data属性
dataDir=/root/zookeeper-3.8.4/data
- zookeeper 服务启动
进入bin目录,启动服务输入命令
./zkServer.sh start
- 相关命令
关闭服务
./zkServer.sh stop
查看状态
./zkServer.sh status
2.伪集群模式
Zookeeper不但可以在单机上允许单机模式Zookeeper,而且可以在单机模拟集群模式Zookeeper的运行,也就是将不同实例运行在同一台机器,用端口进行区分,伪集群模式为我们体验Zookeeper和做一些尝试性的实验提供了很大的便利。比如,我们在测试的时候,可以先使用少量数据在伪集群模式下进行测试。当测试可行的时候,再将数据移植到集群模式进行真是的数据实验。这样不但保证了它的可行性,同时大大提高了实验的效率。这种搭建方式,比较简便,成本比较低,适合测试和学习。
【注】
一台机器上部署了3个server,也就是说单台机器及上运行多个Zookeeper实例。在这种情况下,必须保证每个配置文档的各个端口号不能冲突,除clientPort不同之外,dataDir也不同。另外,还要在dataDir所对应的目录中创建myid文件来指定对应的Zookeeper服务器实例
- clientPort端口
- 如果在1台机器上部署多个server,那么每台机器都要不同的clientPort,比如server1是2181,server2是2182,server3是2183
- dataDir和dataLogDir
- dataDir和dataLogDir也需要区分下,将数据文件和日志文件分开存放,同时每个server的这两变量所对应的路径都是不同的
- server.X和myid
- server.X 这个数字就是对应,data/myid 中的数字。在3个server的myid文件中分别写入了1,2,3,那么每个server中的zoo.cfg都配server.1,server.2,server.3 就行了。因为在同一台机器上,后面连着的2个端口,3个server都不要一样,否则端口冲突
- 下载
下载稳定版本的Zookeeper:
https://zookeeper.apache.org/releases.html
- 上传
下载完成后,将Zookeeper压缩包上传到Linux系统
- 解压压缩包
创建目录zkcluster
mkdir zkcluster
解压zookeeper-3.8.4.tar.gz 到zkcluster目录下
tar -zxvf apache-zookeeper-3.8.4.tar.gz -C /zkcluster
- 改变名称
mv zookeeper-3.8.4 zookeeper01
复制并改名
cp -r zookeeper01/ zookeeper02
cp -r zookeeper01/ zookeeper03
- 分别在zookeeper01、zookeeper02、zookeeper03目录下创建data及logs目录
mkdir data
cd data
mkdir logs
- 修改配置文件名称
cd conf
mv zoo_sample.cfg zoo.cfg
- 配置每一个Zookeeper的dataDir(zoo.cfg)clientPort分别为2181 2182 2183
clientPort=2181
dataDir=/zkcluster/zookeeper01/data
dataLogDir=/zkcluster/zookeeper01/data/logs
clientPort=2182
dataDir=/zkcluster/zookeeper02/data
dataLogDir=/zkcluster/zookeeper02/data/logs
clientPort=2183
dataDir=/zkcluster/zookeeper03/data
dataLogDir=/zkcluster/zookeeper03/data/logs
- 配置集群
在每个zookeeper的data目录下创建一个myid文件内容分别是1,2,3。这个文件就是记录每个服务器的ID
touch myid
在每个zookeeper的zoo.cfg配置客户端访问端口(clientPort)和集群服务器IP列表
server.1=192.168.101.3:2881:3881
server.2=192.168.101.3:2882:3882
server.3=192.168.101.3:2883:3883
#server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
- 启动集群
依次启动三个zk实例
相关文章:

Zookeeper 二、Zookeeper环境搭建
Zookeeper安装方式有三种,单机模式和集群模式以及伪集群模式 单机模式:Zookeeper只运行在一台服务器上,适合测试环境集群模式:Zookeeper运行于一个集群上,适合生产环境,这个计算机集群被称为一个“集合体”…...
Web3 学习
之前学习 web3,走了不少弯路,最近看到了 hackquest,重新刷了一遍以太坊基础,感觉非常nice,而且完全免费,有需要的可以试试,链接hackquest.io。...

Grafana+Prometheus(InfluxDB)+Jmeter使用Nginx代理搭建可视化性能测试监控平台
前言 在这篇博客文章中,将分享JMeter > Prometheus(InfluxDB) > Grafana的集成,以及Nginx端口反向代理各服务的端口。 背景 在JMeter插件库中,有一些后端监听器可供Kafka、ElasticSearch和Azure使用。默认情况下,JMeter支…...
项目总结)
web学习笔记(六十六)项目总结
目录 1. Suspense标签 2.发布订阅者模式 3.pinia的使用 4.在请求过来的数据添数据 5.设置token和取token 6. 实现触底加载 7.导航守卫判断登录状态。 1. Suspense标签 Suspense主要用于用于处理异步组件加载和数据获取。,使用这个标签可以允许你在组件等待数…...
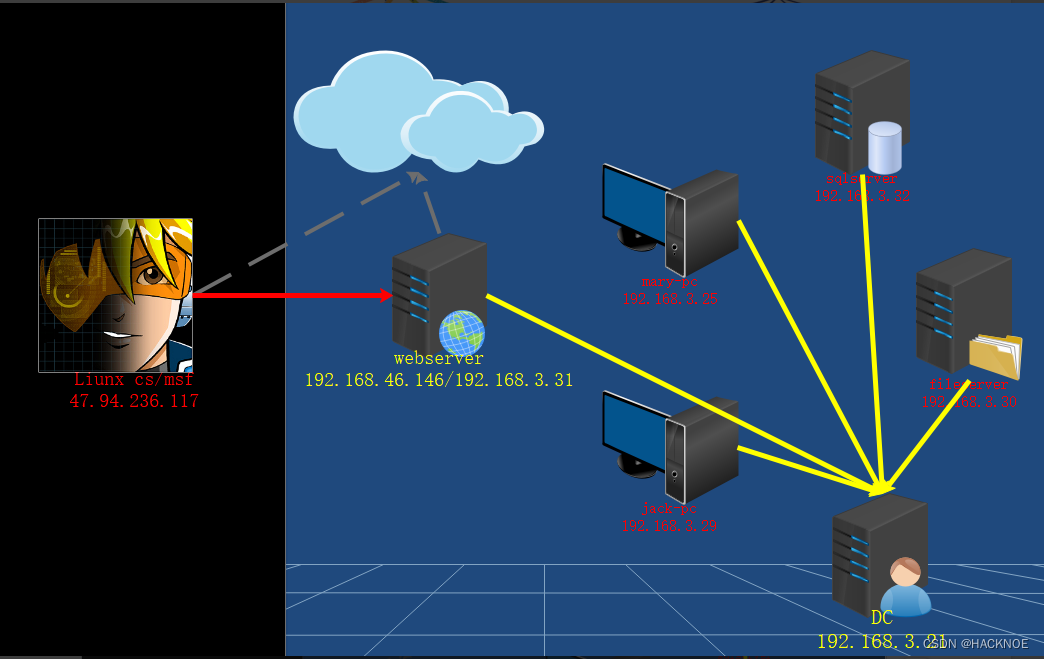
红队内网攻防渗透:内网渗透之内网对抗:横向移动篇域控系统提权NetLogonADCSPACKDC永恒之蓝CVE漏洞
红队内网攻防渗透 1. 内网横向移动1.1 横向移动-域控提权-CVE-2020-1472 NetLogon1.2 横向移动-域控提权-CVE-2021-422871.3 横向移动-域控提权-CVE-2022-269231.4 横向移动-系统漏洞-CVE-2017-01461.5 横向移动-域控提权-CVE-2014-63241. 内网横向移动 1、横向移动-域控提权-…...

VMware Workstation安装Windows Server2019系统详细操作步骤
虚拟机版本 VMware Workstation 16 Prp 16.2.5 build-20904516 实现操作 创建虚拟机 创建新的虚拟机 自定义->下一步 默认即可,下一步 稍后安装操作系统->下一步 按照图下所示选择好系统->下一步 设置好虚拟机名称和位置->下一步 默认即可࿰…...
HTML5【新特性总结】
HTML5【新特性总结】 HTML5 的新增特性主要是针对于以前的不足,增加了一些新的标签、新的表单和新的表单属性等。 这些新特性都有兼容性问题,基本是 IE9 以上版本的浏览器才支持,如果不考虑兼容性问题,可以大量使用这些新特性。…...

【面试题】面试官:判断图是否有环?_数据结构复试问题 有向图是否有环
type: NODE;name: string;[x: string]: any; }; [x: string]: any;}; export type Data Node | Edge; 复制代码 * 测试数据如下const data: Data[] [ { id: ‘1’, data: { type: ‘NODE’, name: ‘节点1’ } }, { id: ‘2’, data: { type: ‘NODE’, name: ‘节点2’ } },…...

办理北京公司注册地址异常变更要求和流程
在北京注册公司时选择注册地址是非常重要的一环,注册地址不仅体现在营业执照上,在网上也有公示信息,一般选用的是商用地址和商住两用地址,在公司经营过程中,因为经营需要变更注册地址,也要依法变更…...
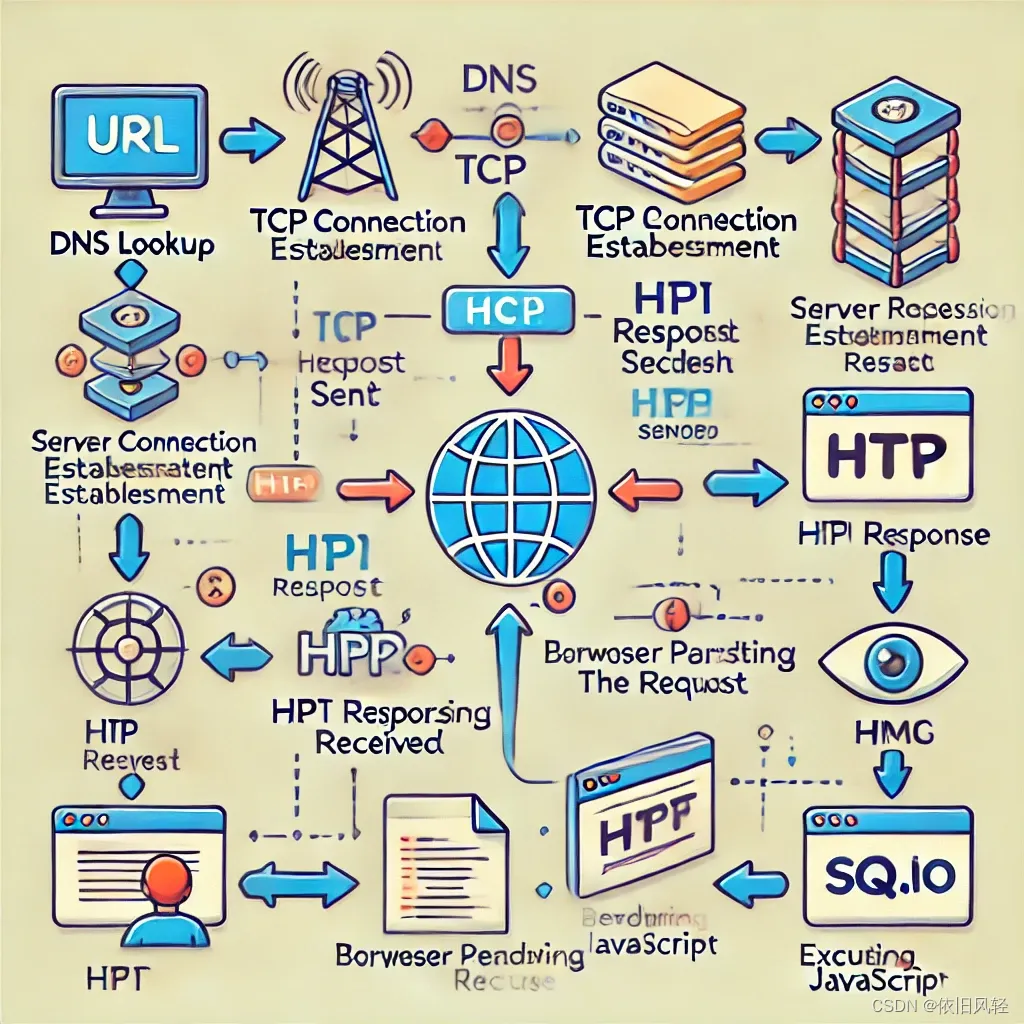
当你在浏览器输入一个地址
你在浏览器中输出了一个地址,回车后,一直到显示页面,中间经历了哪些过程 ? 1. 用户输入 URL 并按下回车 用户在浏览器的地址栏中输入一个 URL(例如 http://example.com)并按下回车键。 2. DNS 解析 浏览…...
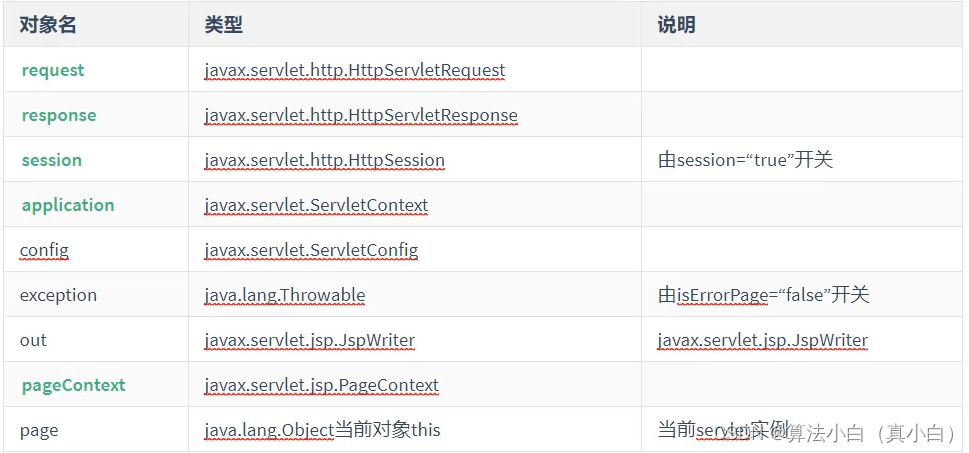
JSP基础知识概述
目录 JSP一、什么是JSP1.1 概念1.2 创建JSP1.3 JSP编写Java代码1.4 JSP实现原理 二、JSP与HTML集成2.1 普通脚本2.2 声明脚本2.3 输出脚本2.4 JSP指令2.5 动作标签 三、内置对象3.1 四大域对象 JSP 一、什么是JSP 1.1 概念 简化的Servlet设计,在HTMl标签中嵌套Jav…...

国产编程—— 仓颉
应用 仓颉编程语言是一款由华为主导设计和实现的面向全场景智能的编程语言,主要应用于以下领域: 中文字符编码和文本数据处理:仓颉编程语言充分利用汉字的结构特点来设计编码,为开发者提供了一种高效的方式来编码、存储和处理中…...
)
0X JavaSE-并发编程(锁)
1...
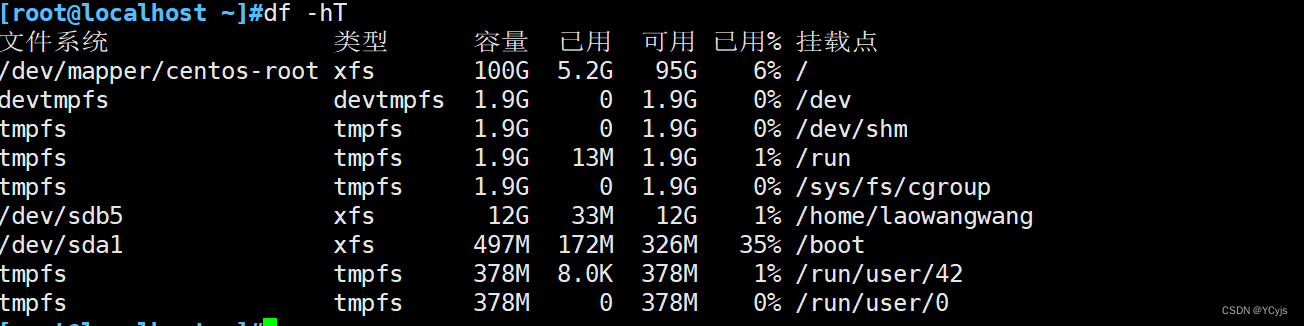
云计算【第一阶段(18)】磁盘管理与文件系统 分区格式挂载(一)
目录 一、磁盘基础 二、磁盘结构 2.1、机械硬盘 2.2、固态硬盘 2.3、扩展移动硬盘 2.4、机械磁盘的一些计算(了解) 2.5、磁盘接口类型 二、Linux 中使用的文件系统类型 2.1、磁盘分区的表示 2.1.1、主引导记录(MBR) 2.1.2、Linux中将硬盘、分…...

Flask-cache
Flask-cache 目录 Flask-cache基本使用配置可用参数SimpleCacheNullCacheFileSystemCacheRedisCacheRedisSentinelCacheRedisClusterCacheMemcachedCacheSASLMemcachedCacheUWSGICache Flask-Cache是一个强大的缓存库,为基于Flask的应用提供了简单易用的API和多种缓…...
【面试题】面试小技巧:如果有人问你 xxx 技术是什么?_面试问你对什么技术特别了解
前端工程越来越大,前面几种方案不能很好的支持单元测试。 在这样的背景下,React 诞生了。React 带来了新的思维模式,UI fn(props),React 中一个组件就是一个函数或者一个类,一个函数或者一个类就是一个基础单位&…...
)
简单分享Python语言(发现其实并不难)
一. Python基础 Python是一种解释型语言,这意味着开发者可以在代码被编写后立即执行它们,而无需编译。Python的基本语法简单明了,以下是一些基础知识点: 变量和数据类型:Python支持多种数据类型,包括整型&…...
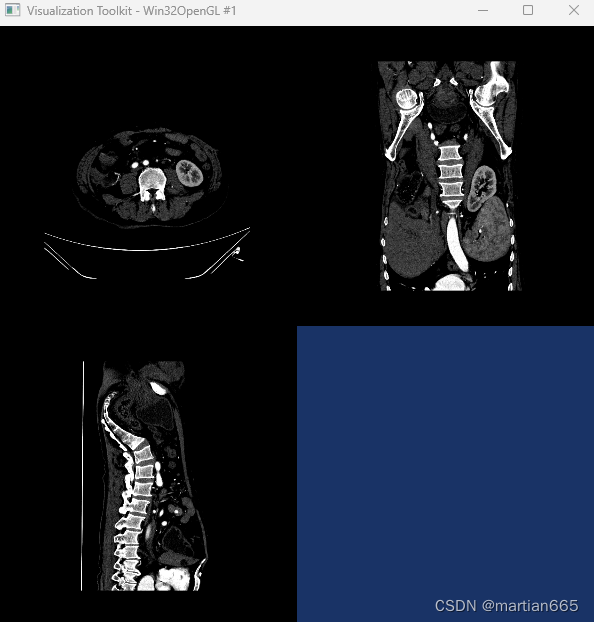
基于VTK9.3.0+Visual Studio2017 c++实现DICOM影像MPR多平面重建
开源库:VTK9.3.0 开发工具:Visual Studio2017 开发语言:C 实现过程: void initImageActor(double* Matrix, double* center, vtkSmartPointer<vtkImageCast> pImageCast,vtkSmartPointer<vtkImageReslice> imageRe…...

【论文精读】ViM: Out-Of-Distribution with Virtual-logit Matching 使用虚拟分对数匹配的分布外检测
文章目录 一、文章概览(一)问题来源(二)文章的主要工作(三)相关研究 二、动机:Logits 中缺失的信息(一)logits(三)基于零空间的 OOD 评分…...

【面试题】前端 移动端自适应?_前端移动端适配面试题
设备像素比 设备像素比 (DevicePixelRatio) 指的是设备物理像素和逻辑像素的比例 。比如 iPhone6 的 DPR 是2。 设备像素比 物理像素 / 逻辑像素。可通过 window.devicePixelRatio 获取,CSS 媒体查询代码如下 media (-webkit-min-device-pixel-ratio: 3), (min-…...
【Transformer系列】从One-Hot到Embedding:构建AI语言理解的基石
1. 从One-Hot编码说起:AI的第一堂语言课 想象你正在教一个外星人认识汉字。你拿出一本字典说:"这里有10万个字,每个字对应一个编号,猫是第12345号,狗是第67890号。"这就是最原始的One-Hot编码思想——用一串…...

【模块化设计-10】UART1 驱动 + 环形 FIFO 实现高效串口数据收发
在嵌入式开发中,串口(UART)是最常用的通信接口之一,而直接采用中断 缓冲区的方式处理串口数据,能有效避免数据丢失、提升收发效率。本文将基于实际项目代码,详解UART1 驱动与环形 FIFO(ring_fi…...

Parabolic:简单高效的免费视频下载工具,yt-dlp图形界面终极方案
Parabolic:简单高效的免费视频下载工具,yt-dlp图形界面终极方案 【免费下载链接】Parabolic Download web video and audio 项目地址: https://gitcode.com/GitHub_Trending/pa/Parabolic 还在为寻找一款既强大又易用的视频下载工具而烦恼吗&…...

TinyGPT-V 和 MiniGPT-4 在架构设计上的主要区别
MiniGPT-4 是“大 LLM 冻结视觉编码器 单层线性投影”的经典桥接式 MLLM;TinyGPT-V 是“小 LLM 视觉模块 更复杂 mapping / norm / LoRA 训练策略”的轻量化 sVLM。1. 总体架构对比对比项MiniGPT-4TinyGPT-V设计目标验证强 LLM 接入视觉后可涌现 GPT-4V 类多模态…...

Arm架构在中国市场的机遇、挑战与实战指南
1. 项目概述:Arm架构的“中国故事”与我的观察最近几年,在技术圈和投资圈里,“Arm架构”和“中国市场”这两个词的组合热度一直居高不下。作为一名长期关注处理器架构和产业生态的从业者,我几乎每周都能在行业交流、客户会议甚至供…...

JetBrains IDE试用期重置工具:30天免费试用无限续杯指南
JetBrains IDE试用期重置工具:30天免费试用无限续杯指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否遇到过JetBrains IDE试用期到期,却还没准备好购买许可证的困扰?i…...

手机上的Linux:用Termux 0.118.0打造Python 3.10.4爬虫环境,实测下载‘拷贝漫画’全流程
在安卓手机上构建Python爬虫环境:Termux实战指南 你是否遇到过这样的场景:在地铁上突然想到一个绝妙的爬虫点子,但手边只有一部手机?或者想在平板上直接下载漫画却苦于没有合适的工具?Termux正是解决这些痛点的神器。这…...

GitHub星标6.6k+的WindTerm,除了快还有这些隐藏技巧:自动补全、锁屏密码重置、主题切换
GitHub星标6.6k的WindTerm高阶技巧:解锁专业级终端体验 当大多数用户还在用默认配置与终端工具"和平共处"时,真正的效率追求者早已开始挖掘那些藏在菜单深处的生产力加速器。作为GitHub上获得6.6k星标的现象级终端工具,WindTerm的…...

基于大语言模型的智能BI工具:从自然语言到SQL与可视化的工程实践
1. 项目概述:一个开源的商业智能对话工具最近在折腾数据分析和可视化,发现一个挺有意思的开源项目,叫openchatbi。简单来说,它就是一个能让你用自然语言跟数据库“聊天”的工具。你不需要写复杂的 SQL 语句,直接问“上…...

QModMaster终极指南:5分钟掌握开源ModBus调试神器
QModMaster终极指南:5分钟掌握开源ModBus调试神器 【免费下载链接】qModbusMaster Fork of QModMaster (https://sourceforge.net/p/qmodmaster/code/ci/default/tree/) 项目地址: https://gitcode.com/gh_mirrors/qm/qModbusMaster QModMaster是一款完全免费…...