Python20 Numpy基础

NumPy(Numerical Python)是一个开源的Python库,广泛用于科学计算。它提供了一个高性能的多维数组对象,以及用于处理这些数组的工具和函数。NumPy是数据分析、机器学习、工程和科学研究中不可或缺的工具之一,因为它提供了简单而高效的数值运算功能。
1.NumPy的主要功能:
-
高效的数组运算:NumPy的数组比Python的内置数据结构更加高效和快速。
-
广播功能:能够处理不同大小数组之间的运算。
-
数学函数:包含大量的数学函数,用于在数组上执行各种数学运算。
-
线性代数、傅里叶变换和随机数生成:提供了丰富的库和API支持。
NumPy的使用广泛,几乎是所有使用Python进行数据科学的项目的基础库之一。
2.NumPy的使用方法
以下是Numpy库的常用方法,以下代码可直接复制到jupyter notebook运行。
生成随机数组:
# 构造4x4的随机数组
from numpy import *
random.rand(4,4)# 输出:
'''
array([[0.99764728, 0.06364547, 0.02182546, 0.16433105],[0.63289943, 0.29763976, 0.58491023, 0.28307729],[0.42512921, 0.27926124, 0.11818588, 0.58845666],[0.07451536, 0.65541451, 0.50638315, 0.27005101]])
'''
将数组转换成矩阵matrix:
# 调用mat函数将数组转换成矩阵matrix
randMat=mat(random.rand(4,4))
randMat
# 输出:
'''
matrix([[0.27496011, 0.9093084 , 0.0018111 , 0.13143669],[0.85885902, 0.94750823, 0.96820938, 0.06107537],[0.67165439, 0.69433003, 0.82237952, 0.25712598],[0.65327732, 0.30190633, 0.65090624, 0.05763251]])
'''
求矩阵的逆矩阵:
# 矩阵求逆运算
randMat.I# 输出:
'''
matrix([[-2.27475911, 1.74370229, 0.3710643 , -0.63203529],[ 1.15524442, 0.27630249, -1.52858325, 1.38871436],[ 2.0517843 , -2.27912633, 0.3015267 , 3.06149341],[ 0.98720611, -0.61572784, 0.95857182, -0.9405201 ]])
'''
矩阵乘法:
# 矩阵乘法
invRandmat=randMat.I
randMat*invRandmat
# 输出:
'''
matrix([[ 1.00000000e+00, 0.00000000e+00, 8.32667268e-17,-1.59594560e-16],[ 0.00000000e+00, 1.00000000e+00, -1.66533454e-16,1.11022302e-16],[-1.11022302e-16, 2.22044605e-16, 1.00000000e+00,1.11022302e-16],[ 0.00000000e+00, 4.51028104e-17, 0.00000000e+00,1.00000000e+00]])
'''
用矩阵与逆矩阵相乘(得到单位阵,实际存在误差):
# 矩阵乘以其逆矩阵应该是单位矩阵
myEye=randMat*invRandmat # 矩阵乘其逆矩阵,结果应为单位阵
myEye-eye(4) # eye(4)将得到一个4阶单位阵
# 输出:
'''
matrix([[ 0.00000000e+00, 0.00000000e+00, 8.32667268e-17,-1.59594560e-16],[ 0.00000000e+00, 0.00000000e+00, -1.66533454e-16,1.11022302e-16],[-1.11022302e-16, 2.22044605e-16, 0.00000000e+00,1.11022302e-16],[ 0.00000000e+00, 4.51028104e-17, 0.00000000e+00,0.00000000e+00]])
'''
shape()函数获得数组的形状:
# shape函数是numpy.core.fromnumeric中的函数,它的功能是读取矩阵的长度,比如shape[0]就是读取矩阵第一维度的长度。
e=eye(3)
e.shape[0]# 输出:
'''
3
'''
x=random.rand(4,3) # 生成一个4x3的数组
x.shape[0]
# 输出:
'''
4
'''
numpy tile方法:numpy.tile(A,B),将重复A数组B次,这里的B可以时int类型也可以是元组类型。
# tile方法
tile([1,2],5) # 列方向重复5次,行默认1次
# 输出:
'''
array([1, 2, 1, 2, 1, 2, 1, 2, 1, 2])
'''
# tile方法
tile([1,2],(2,1)) # 列方向重复2次,行1次
# 输出:
'''
array([[1, 2],[1, 2]])
'''
zeros()函数创建0数组:
# zeros函数
zeros(5)
# 输出:
'''
array([0., 0., 0., 0., 0.])
'''
# zeros函数
zeros([2,3])
# 输出:
'''
array([[0., 0., 0.],[0., 0., 0.]])
'''
3.KNN算法
# kNN算法
from numpy import * # 从NumPy库导入所有功能模块
import operator # 该模块包含一系列对标准运算符的函数化实现例如加法乘法等
def CreateDataSet():group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) # 一个NumPy数组,包含了四个二维坐标点。这些点是数据集中的样本labels=['A','A','B','B'] # 包含了与 group 数组中每个点相对应的类别标签return group,labels # 返回两个值,group数组和labels列表group,labels=CreateDataSet() # 将返回的两个值赋值给group和labels变量
group
# 输出:
'''
array([[1. , 1.1],[1. , 1. ],[0. , 0. ],[0. , 0.1]])
'''
labels
# 输出:
'''
['A', 'A', 'B', 'B']
'''
def classify0(inX,dataSet,labels,k): # inX:需要分类的输入样本;dataSet:训练数据集,包含多个已知分类的点;labels:训练数据集中每个点对应的标签;k:在kNN算法中,决定“邻居”数量的参数dataSetSize=dataSet.shape[0] # 获取数据集的行数即样本数量print(dataSetSize)diffMat=tile(inX,(dataSetSize,1))-dataSet # 将输入的点与训练样本做差,使用 tile 函数将输入向量 inX 复制成与数据集相同大小的矩阵,然后与数据集中的每个点相减,计算输入点与数据集中每个点的差异print("这个是dataSet",dataSet)print("这个是测试的输入向量",tile(inX,(dataSetSize,1)))print("这个是点差",diffMat)sqDiffMat=diffMat**2 # 计算出距离平方print("这个是距离平方",sqDiffMat)sqDistances=sqDiffMat.sum(axis=1) # 计算距离平方和print("这个是距离平方和",sqDistances)distances=sqDistances**2 # 开方得出距离sortedDistIndicies=distances.argsort() # 从小到大排序,返回索引print("距离排序后对应的索引:",sortedDistIndicies)classCount={} # 初始化一字典来存储每个类别的票数for i in range(k): # 遍历最近的 k 个点,并对其类别进行计票voteIlabel=labels[sortedDistIndicies[i]]print(voteIlabel)classCount[voteIlabel]=classCount.get(voteIlabel,0)+1sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) # 根据票数对类别进行排序print(sortedClassCount)return sortedClassCount[0][0]
x=classify0([0,0],group,labels,3)
x# 输出:
'''
4
这个是dataSet [[1. 1.1][1. 1. ][0. 0. ][0. 0.1]]
这个是测试的输入向量 [[0 0][0 0][0 0][0 0]]
这个是点差 [[-1. -1.1][-1. -1. ][ 0. 0. ][ 0. -0.1]]
这个是距离平方 [[1. 1.21][1. 1. ][0. 0. ][0. 0.01]]
这个是距离平方和 [2.21 2. 0. 0.01]
距离排序后对应的索引: [2 3 1 0]
B
B
A
[('B', 2), ('A', 1)]'B'
'''
4.使用k-近邻算法改进约会网站的配对效果
from numpy import zerosdef file2matrix(filename):# 定义标签映射字典label_map = {'largeDoses': 2, 'smallDoses': 1, 'didntLike': 0} # 将字符串标签映射到整数fr = open(filename)arrayOLines = fr.readlines() # 用readlines()方法读取文件中的每一行并存储在列表arrayOLines中fr.close() # 读取完数据后应关闭文件numberOfLines = len(arrayOLines) # 获取行数# 创建返回的NumPy矩阵, 行数为numberOfLines, 列数固定为3returnMat = zeros((numberOfLines, 3))classLabelVector = [] # 初始化标签列表index = 0for line in arrayOLines:line = line.strip() # 去掉每行首尾空白listFromLine = line.split('\t') # 按'\t'分割字符串returnMat[index, :] = listFromLine[0:3] # 前三个元素存入矩阵# 使用映射字典获取标签classLabelVector.append(label_map[listFromLine[-1]])index += 1 # 索引递增,为处理下一行数据做准备return returnMat, classLabelVector # 返回数据矩阵和对应的分类标签# 调用函数示例
filename = r"F:\桌面\python100\files\data\datingTestSet.txt"
datingDataMat, datingLabels = file2matrix(filename)# 输出数据矩阵,查看结果
datingDataMat
# 结果矩阵1-3列分别表示:飞行常客里程数、玩视频游戏所耗时间、每周消费的冰激凌数
'''
array([[4.0920000e+04, 8.3269760e+00, 9.5395200e-01],[1.4488000e+04, 7.1534690e+00, 1.6739040e+00],[2.6052000e+04, 1.4418710e+00, 8.0512400e-01],...,[2.6575000e+04, 1.0650102e+01, 8.6662700e-01],[4.8111000e+04, 9.1345280e+00, 7.2804500e-01],[4.3757000e+04, 7.8826010e+00, 1.3324460e+00]])
'''
结果数据的可视化散点图(取后两维):
# 制作原始数据的散点图
import matplotlib
import matplotlib.pyplot as pltfig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2]) # 取矩阵的第二列(玩视频游戏所耗时间)、第三列数据(每周消费的冰激凌数)
plt.show()
取结果矩阵的后两维特征进行可视化优化:
# 个性化标记散点图上的点
import matplotlib
import matplotlib.pyplot as pltfig=plt.figure() # 创建一个图形实例fig
ax=fig.add_subplot(111) # 向fig添加一个子图 ax,参数 111 表示在一个1x1的网格上创建第一个(也是唯一一个)子图,这是一种快捷方式
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLables),15.0*array(datingLables)) # 将标签数组datingLables转换为NumPy数组,并乘以15.0,目的是让不同的标签对应的点大小有明显区分
plt.show()
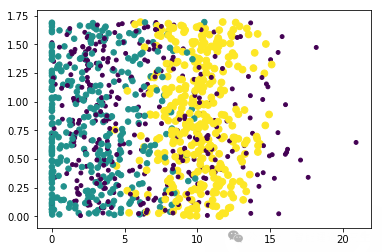
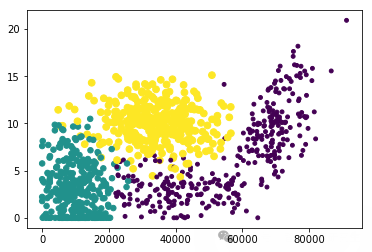
取结果矩阵的前两维特征进行可视化:
# 个性化标记散点图上的点
# 采用列1(飞行常客里程数--x轴)和列2(玩视频游戏时间--y轴)的属性值可以取得更好的效果
import matplotlib
import matplotlib.pyplot as pltfig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(datingDataMat[:,0],datingDataMat[:,1],15.0*array(datingLables),15.0*array(datingLables)) # 分别取数据矩阵的第一列和第二列作为x轴和y轴的数据
plt.show()
以上内容总结自网络,如有帮助欢迎转发,我们下次再见!
相关文章:
Python20 Numpy基础
NumPy(Numerical Python)是一个开源的Python库,广泛用于科学计算。它提供了一个高性能的多维数组对象,以及用于处理这些数组的工具和函数。NumPy是数据分析、机器学习、工程和科学研究中不可或缺的工具之一,因为它提供…...

暴雨虐长沙,生灵受煎熬
今天,“湖南长沙市遭遇强降雨,一小时的降雨量足够注满54个西湖”这消息,终于登上互联网社交平台热搜榜。 截图:来源社交网站 综合多家媒体消息概述如下。 昨(24日)天,湖南长沙市遭遇强降雨,一…...

iptables(5)常用扩展模块iprange、string、time、connlimit、limit
简介 之前我们已经介绍过扩展模块的简单使用,比如使用-m tcp/udp ,-m multiport参数通过--dports,--sports可以设置连续和非连续的端口范围。那么我们如何匹配其他的一些参数呢,比如源地址范围,目的地址范围,时间范围等,这就是我们这篇文章介绍的内容。 iprange扩展模块…...

Mars3d实现汽车尾气粒子效果从汽车屁股开始发射效果
本身的汽车尾气粒子效果:在汽车模型的中间发射的↓↓↓↓↓↓↓↓↓↓↓ Mars3d实例中是使用transY偏移值实现汽车尾气粒子效果从汽车屁股开始发射效果: // 动态运行车辆的尾气粒子效果 function addDemoGraphic4(graphicLayer) {const fixedRoute new…...

01_RISC-V 入门及指令集学习
参考文档 risc-v入门:https://blog.csdn.net/bebebug/article/details/128039038RISC-V OS:https://blog.csdn.net/bebebug/article/details/130551378riscv-spec文档:https://riscv.org/wp-content/uploads/2019/12/riscv-spec-20191213.pd…...

Facebook与地方文化:数字平台的多元表达
在当今数字化时代,社交媒体不仅仅是人们交流的工具,更是促进地方文化传播和表达的重要平台。作为全球最大的社交网络之一,Facebook在连接世界各地用户的同时,也成为了地方文化多元表达的重要舞台。本文将深入探讨Facebook如何通过…...

ArmSoM-Sige7/5/1 和树莓派5规格比较
引言 在当今快速发展的嵌入式系统领域,选择一款性能强大、功能丰富的开发板对于项目的成功至关重要。本文将介绍并比较 Sige7、Sige5、Raspberry Pi 5 和 Sige1 这四款开发板的关键规格和特性,帮助开发者和爱好者选择最适合其需求的平台。 ArmSoM-Sige…...

创建App
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 在Django项目中,推荐使用App来完成不同模块的任务,通过执行如下命令可以启用一个应用程序。 python manage.py startapp app…...
2024年6月上半月30篇大语言模型的论文推荐
大语言模型(LLMs)在近年来取得了快速发展。本文总结了2024年6月上半月发布的一些最重要的LLM论文,可以让你及时了解最新进展。 LLM进展与基准测试 1、WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild Wi…...
Chromium下载
https://chromium.woolyss.com/download/ https://www.chromium.org/getting-involved/download-chromium/...

【Linux】彻底理解---环境变量(什么是环境变量,环境变量有什么作用?)
目录 一、前言 二、什么是环境变量? 三、如何添加环境变量? 四、如何获取环境变量? 💧环境变量相关的命令💧 💧测试HOME与USER💧 🔥环境变量的获取方式🔥 ① en…...
VMware完美安装Ubuntu20.04
一、官网下载Ubuntu20.04 下载地址为:https://releases.ubuntu.com/https://releases.ubuntu.com/ 下载完后镜像为ubuntu-20.04.4-desktop-amd64.iso 二、Ubuntu安装 2.1、打开VMware player,并创建新虚拟机。 2.2、点击浏览按钮选择需要安装的镜像 2…...

使用Spring Boot作为CMS系统的后台,Nuxt.js作为前台的分析
在现代Web开发中,前后端分离架构越来越受欢迎。Spring Boot和Nuxt.js的组合为构建内容管理系统(CMS)提供了一个强大的解决方案。本文将分析这种组合的优势、挑战以及应用场景。 1. 技术概述 1.1 Spring Boot Spring Boot是基于Java的框架&…...
Spring Boot整合Druid:轻松实现SQL监控和数据库密码加密
文章目录 1 引言1.1 简介1.2 Druid的功能1.3 竞品对比 2 准备工作2.1 项目环境 3 集成Druid3.1 添加依赖3.2 配置Druid3.3 编写测试类测试3.4 访问控制台3.5 测试SQL监控3.6 数据库密码加密3.6.1 执行命令加密数据库密码3.6.2 配置参数3.6.3 测试 4 总结 1 引言 1.1 简介 Dru…...
推荐一款好用的编辑工具——onlyoffice桌面编辑器8.1
读者大大们好呀!!!☀️☀️☀️ 🔥 欢迎来到我的博客 👀期待大大的关注哦❗️❗️❗️ 🚀欢迎收看我的主页文章➡️寻至善的主页 文章目录 🔥前言🚀版本更新概览🚗文档编辑PDF编辑器…...

C++ | Leetcode C++题解之第188题买卖股票的最佳时机IV
题目: 题解: class Solution { public:int maxProfit(int k, vector<int>& prices) {if (prices.empty()) {return 0;}int n prices.size();k min(k, n / 2);vector<int> buy(k 1);vector<int> sell(k 1);buy[0] -prices[0]…...

操作系统实训复习笔记(2)
目录 Linux操作系统(认识记忆) (1)Linux 文件系统是树形层次结构 (2)Linux 用户介绍 (3)Linux 常用命令介绍 (4)ls命令 (5)Linu…...

北邮《计算机网络》英文选择题课堂小测
课堂小测验及答疑汇总 2020年 5 月 12 日 Q1. Which is the network address after aggregation of following 3 networks: 200.2.50.0/23, 200.2.52.0/22 and 200.2.56.0/22? A. 200.2.48.0/20 B. 200.2.50.0/20 C. 200.2.48.0/21 D. 200.2.50.0/21 Answer: A Q…...

kafka 集群安全认证机制的设计实现
kafka 集群安全认证机制的实现 Kafka 提供了多种安全认证机制来保护数据传输的安全性,包括加密、身份认证和授权。这些机制确保 了 Kafka 集群的通信安全和数据访问控制。以下是 Kafka 安全认证机制的实现和配置指南。 1. 安全认证机制概述 Kafka 支持以下几种主要的安全机…...

pandas保存成CSV格式时数据换行:SQL的REPLACE函数过滤掉数据的回车符
在使用Pandas保存数据到CSV文件时,如果数据中包含换行符(例如\n),这可能会导致数据在CSV文件中被分割成多行,影响数据的完整性和可读性。为了解决这个问题,你可以在保存CSV之前使用Pandas的replace函数来替…...

别再手动贴图了!LOD1.3建模的智能纹理库怎么用?手把手教你配置大势智慧材质模板
LOD1.3建模革命:智能纹理库的实战配置指南 当清晨的第一缕阳光透过窗户洒在建模师的工作台上,那些曾经需要数小时手动贴图的建筑模型,如今只需几分钟就能自动完成纹理匹配。这不是未来场景,而是LOD1.3建模中智能纹理库技术带来的…...
项目推荐:深入理解与掌握正交频分复用技术)
OFDM仿真(Matlab)项目推荐:深入理解与掌握正交频分复用技术
OFDM仿真(Matlab)项目推荐:深入理解与掌握正交频分复用技术 【下载地址】OFDM仿真matlab完整可运行 本资源提供了一个完整的OFDM(正交频分复用)仿真代码,基于Matlab平台开发。该仿真代码包含了OFDM系统中的多个关键模块࿰…...

别再一段段拼了!用UE4蓝图+Spline Component一键生成连续管道/道路模型
UE4蓝图Spline Component自动化生成复杂路径模型实战指南 在游戏开发中,创建蜿蜒的管道、复杂的赛道或是连绵的城墙往往需要耗费大量时间。传统的手动拼接SplineMesh组件的方式不仅效率低下,而且难以保证模型的连续性和一致性。本文将深入探讨如何利用UE…...

可定制尺寸的工业烤盘公司
江苏台烁是专注为大中型食品生产企业提供可定制尺寸全品类工业烤盘的专业厂商,核心竞争优势为全尺寸高精度定制能力搭配智能生产体系,可提供节能耐用、适配产线的工业化烘焙器具解决方案。核心优势与关键数据生产与资质基础:拥有4.8万㎡智能工…...

第1章:AI Agent认知与全景图
本章你将收获:AI Agent的核心概念与演变历程;主流框架(LangChain、AutoGPT、CrewAI)的深度对比与选型指南;5个真实Agent应用案例的拆解;一套评估项目是否需要引入Agent的决策方法论;以及可运行的Agent代码示例(含免费API)。 📌 本章导读 2024年以来,“AI Agent”成…...

如何选择适合的贴片机:关键因素与选择指南
引言在现代电子制造业中,贴片机(Surface Mount Technology,简称SMT)作为核心设备之一,扮演着至关重要的角色。随着电子元器件的不断小型化和生产工艺的不断进步,选择一款合适的贴片机已经成为确保生产效率、…...

为AI智能体项目选择稳定且多模型的后端API供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为AI智能体项目选择稳定且多模型的后端API供应商 在开发AI智能体或自动化工作流时,工程师们面临的核心挑战之一是如何为…...
)
别光看代码!聊聊51单片机做计算器时,那些新手容易踩的坑(键盘消抖、变量溢出、显示刷新)
51单片机计算器开发进阶指南:从功能实现到工程优化的深度解析 第一次在51单片机上实现计算器功能时,那种按下按键能看到数码管显示正确结果的兴奋感至今难忘。但真正投入实际使用后,各种问题接踵而至——按键偶尔失灵、大数运算出错、显示闪烁…...

JPEG2000在Matlab中的实现源码
JPEG2000在Matlab中的实现源码 【下载地址】JPEG2000在Matlab中的实现源码 JPEG2000在Matlab中的实现源码欢迎来到JPEG2000的Matlab实现资源页面 项目地址: https://gitcode.com/open-source-toolkit/0665cd 欢迎来到JPEG2000的Matlab实现资源页面。本资源旨在提供一套完…...

【免费下载】 让您的无线网络更稳定:Realtek 8188GU 无线网卡驱动推荐
让您的无线网络更稳定:Realtek 8188GU 无线网卡驱动推荐 【下载地址】Realtek8188GU无线网卡驱动 本仓库提供适用于Windows系统的Realtek 8188GU无线网卡驱动程序。该驱动程序旨在帮助用户解决无线网卡无法正常工作的问题,确保您的设备能够稳定连接到无线…...