昇思25天学习打卡营第2天 | 张量Tensor
张量Tensor

张量(Tensor)基础
张量是MindSpore中的基本数据结构的一种,类似于NumPy中数组和矩阵非常相似。它具有以下重要属性:
- 形状(shape)和数据类型(dtype):每个张量都有确定的形状和数据类型,这决定了它在计算中的用途和行为。
- 创建方法:可以通过直接传入数据、从NumPy数组生成、使用初始化器(如One、Normal)或者从其他张量继承属性来创建张量。
- 索引和切片:类似于NumPy,张量支持方便的索引和切片操作,允许按需访问和操作数据元素。
- 运算:支持各种张量之间的数学运算,如加减乘除、取模、整除等,操作与NumPy类似。
import numpy as np
import mindspore
from mindspore import ops
from mindspore import Tensor, CSRTensor, COOTensor
创建张量
张量的创建方式有多种,构造张量时,支持传入Tensor、float、int、bool、tuple、list和numpy.ndarray类型。
-
根据数据直接生成
可以根据数据创建张量,数据类型可以设置或者通过框架自动推断。data = [1, 0, 1, 0] x_data = Tensor(data) print(x_data, x_data.shape, x_data.dtype)代码执行结果:[1 0 1 0] (4,) Int64
-
从NumPy数组生成
可以从NumPy数组创建张量。np_array = np.array(data) x_np = Tensor(np_array) print(x_np, x_np.shape, x_np.dtype)[1 0 1 0] (4,) Int64
-
使用init初始化器构造张量
当使用init初始化器对张量进行初始化时,支持传入的参数有init、shape、dtype。- init: 支持传入initializer的子类。如:下方示例中的 One() 和 Normal()。
- shape: 支持传入 list、tuple、 int。
- dtype: 支持传入mindspore.dtype。
from mindspore.common.initializer import One, Normal# Initialize a tensor with ones tensor1 = mindspore.Tensor(shape=(2, 2), dtype=mindspore.float32, init=One()) # Initialize a tensor from normal distribution tensor2 = mindspore.Tensor(shape=(2, 2), dtype=mindspore.float32, init=Normal())print("tensor1:\n", tensor1) print("tensor2:\n", tensor2)tensor1:
[[1. 1.]
[1. 1.]]
tensor2:
[[-0.00063482 -0.00916224]
[ 0.01324238 -0.0171206 ]] -
继承另一个张量的属性,形成新的张量
from mindspore import opsx_ones = ops.ones_like(x_data) print(f"Ones Tensor: \n {x_ones} \n")x_zeros = ops.zeros_like(x_data) print(f"Zeros Tensor: \n {x_zeros} \n")Ones Tensor:
[1 1 1 1]
Zeros Tensor:
[0 0 0 0]
张量的属性
张量的属性包括形状、数据类型、转置张量、单个元素大小、占用字节数量、维数、元素个数和每一维步长。
-
形状(shape):Tensor的shape,是一个tuple。
-
数据类型(dtype):Tensor的dtype,是MindSpore的一个数据类型。
-
单个元素大小(itemsize): Tensor中每一个元素占用字节数,是一个整数。
-
占用字节数量(nbytes): Tensor占用的总字节数,是一个整数。
-
维数(ndim): Tensor的秩,也就是len(tensor.shape),是一个整数。
-
元素个数(size): Tensor中所有元素的个数,是一个整数。
-
每一维步长(strides): Tensor每一维所需要的字节数,是一个tuple。
x = Tensor(np.array([[1, 2], [3, 4]]), mindspore.int32)print("x_shape:", x.shape)
print("x_dtype:", x.dtype)
print("x_itemsize:", x.itemsize)
print("x_nbytes:", x.nbytes)
print("x_ndim:", x.ndim)
print("x_size:", x.size)
print("x_strides:", x.strides)

张量索引
Tensor索引与Numpy索引类似,索引从0开始编制,负索引表示按倒序编制,冒号:和 …用于对数据进行切片。
tensor = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))print("First row: {}".format(tensor[0]))
print("value of bottom right corner: {}".format(tensor[1, 1]))
print("Last column: {}".format(tensor[:, -1]))
print("First column: {}".format(tensor[..., 0]))
First row: [0. 1.]
value of bottom right corner: 3.0
Last column: [1.3.]
First column: [0. 2.]
张量运算
张量之间有很多运算,包括算术、线性代数、矩阵处理(转置、标引、切片)、采样等,张量运算和NumPy的使用方式类似,下面介绍其中几种操作。
普通算术运算有:加(+)、减(-)、乘(*)、除(/)、取模(%)、整除(//)。
x = Tensor(np.array([1, 2, 3]), mindspore.float32)
y = Tensor(np.array([4, 5, 6]), mindspore.float32)
output_add = x + y
output_sub = x - y
output_mul = x * y
output_div = y / x
output_mod = y % x
output_floordiv = y // x
print("add:", output_add)
print("sub:", output_sub)
print("mul:", output_mul)
print("div:", output_div)
print("mod:", output_mod)
print("floordiv:", output_floordiv)
add: [5. 7. 9.]
sub: [-3. -3. -3.]
mul: [ 4. 10. 18.]
div: [4. 2.5 2.]
mod: [0. 1. 0.]
floordiv: [4. 2. 2.]
concat将给定维度上的一系列张量连接起来。
data1 = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))
data2 = Tensor(np.array([[4, 5], [6, 7]]).astype(np.float32))
output = ops.concat((data1, data2), axis=0)
print(output)
print("shape:\n", output.shape)
[[0. 1.] [2. 3.] [4. 5.] [6. 7.]] shape: (4, 2)
stack则是从另一个维度上将两个张量合并起来。
data1 = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))
data2 = Tensor(np.array([[4, 5], [6, 7]]).astype(np.float32))
output = ops.stack([data1, data2])
print(output)
print("shape:\n", output.shape)
[[[0. 1.] [2. 3.]]
[[4. 5.] [6. 7.]]] shape: (2, 2, 2)
Tensor与NumPy转换
Tensor可以和NumPy进行互相转换。
Tensor转换为NumPy
与张量创建相同,使用 Tensor.asnumpy() 将Tensor变量转换为NumPy变量。
t = Tensor([1., 1., 1., 1., 1.])
print(f"t: {t}", type(t))
n = t.asnumpy()
print(f"n: {n}", type(n))
t: [1. 1. 1. 1. 1.] <class ‘mindspore.common.tensor.Tensor’> n: [1. 1.
- 1.] <class ‘numpy.ndarray’>
NumPy转换为Tensor
使用Tensor()将NumPy变量转换为Tensor变量。
n = np.ones(5)
t = Tensor.from_numpy(n)
np.add(n, 1, out=n)
print(f"n: {n}", type(n))
print(f"t: {t}", type(t))
n: [2. 2. 2. 2. 2.] <class ‘numpy.ndarray’> t: [2. 2. 2. 2. 2.] <class
‘mindspore.common.tensor.Tensor’>
稀疏张量(Sparse Tensor)
稀疏张量是一种优化的数据结构,适用于大部分元素为零的情况,特别是在推荐系统、图神经网络等应用中有重要应用:
- CSR稀疏张量:采用压缩稀疏行(CSR)格式存储数据,通过indptr、indices和values表示非零元素的位置和值。
- COO稀疏张量:采用坐标格式(COO)存储数据,通过indices和values表示非零元素的位置和值,适合表示稀疏的多维数据。

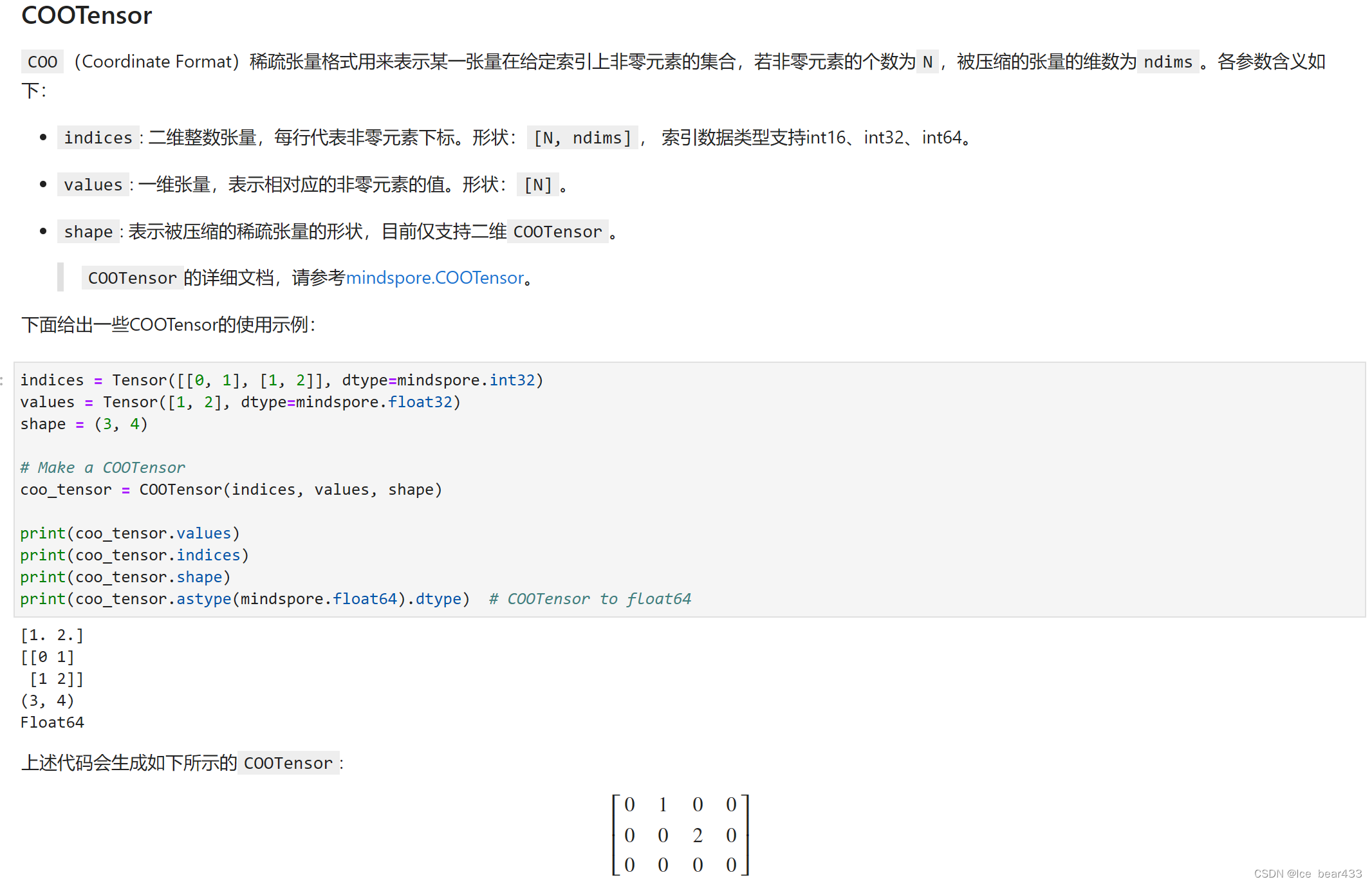
通过学习MindSpore中的张量和稀疏张量,我深入了解了如何有效地管理和操作大规模数据,以及如何利用稀疏数据结构来提升计算效率和节省存储空间。
相关文章:
昇思25天学习打卡营第2天 | 张量Tensor
张量Tensor 张量(Tensor)基础 张量是MindSpore中的基本数据结构的一种,类似于NumPy中数组和矩阵非常相似。它具有以下重要属性: 形状(shape)和数据类型(dtype):每个张量…...

时间安排 |规划
计算机网络(记得完成作业本上的习题) 先看王道知识点讲解 然后不懂得看 计算机网络微课堂(有字幕无背景音乐版)_哔哩哔哩_bilibili 最后做本章习题 【乱讲的】《计算机网络》(第8版)课后习题讲解_哔哩…...
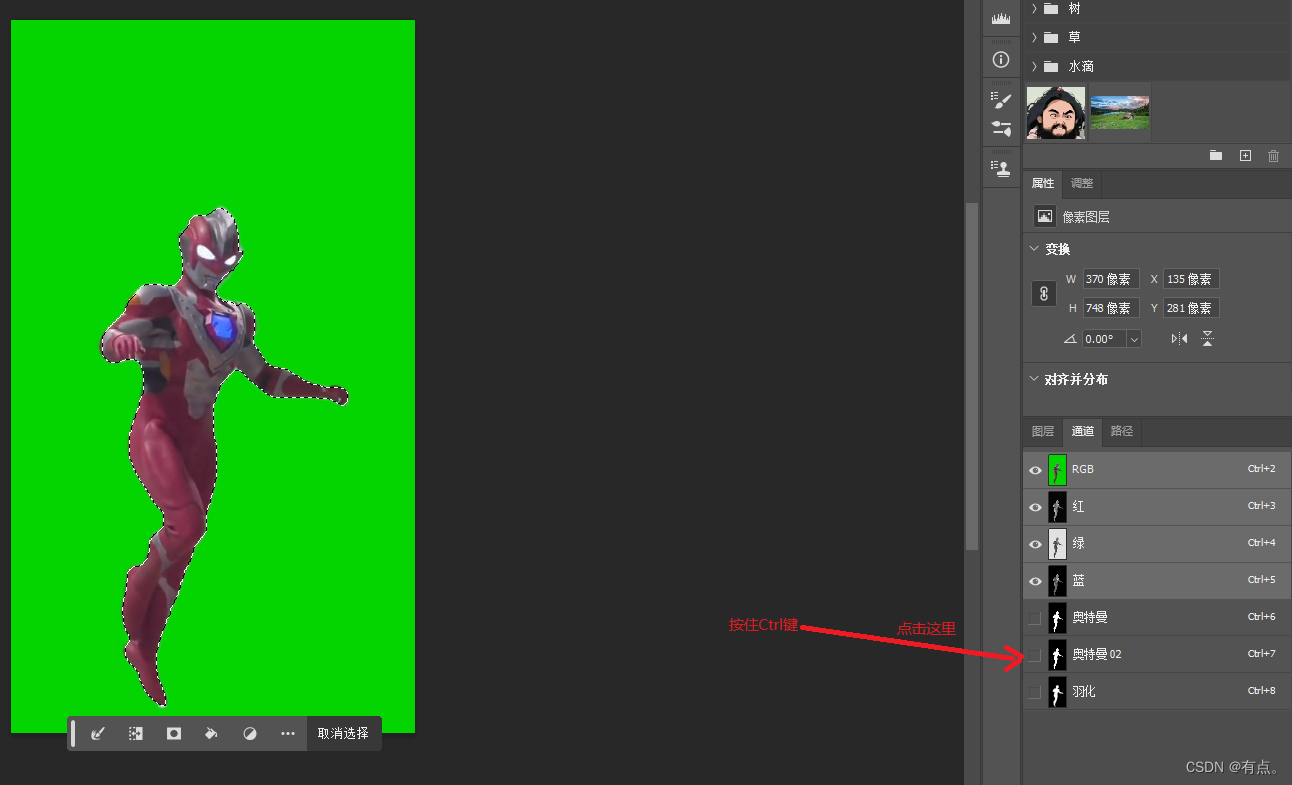
PS系统教程28
Alpha通道(透明通道) 8位的灰度通道,也有256个位置记录图片当中的透明度信息 作用:定义透明、半透明、不透明通道信息。保存、存储选区。 白色不透明区域黑色透明区域灰色半透明区域 案例 为了将我们抠出来的人物方便下次修改…...

如何在web页面下做自动化测试?
自动化测试是在软件开发中非常重要的一环,它可以提高测试效率并减少错误率。在web页面下进行自动化测试,可以帮助我们验证网页的功能和交互,并确保它们在不同浏览器和平台上的一致性。本文将从零开始,详细介绍如何在web页面下进行…...
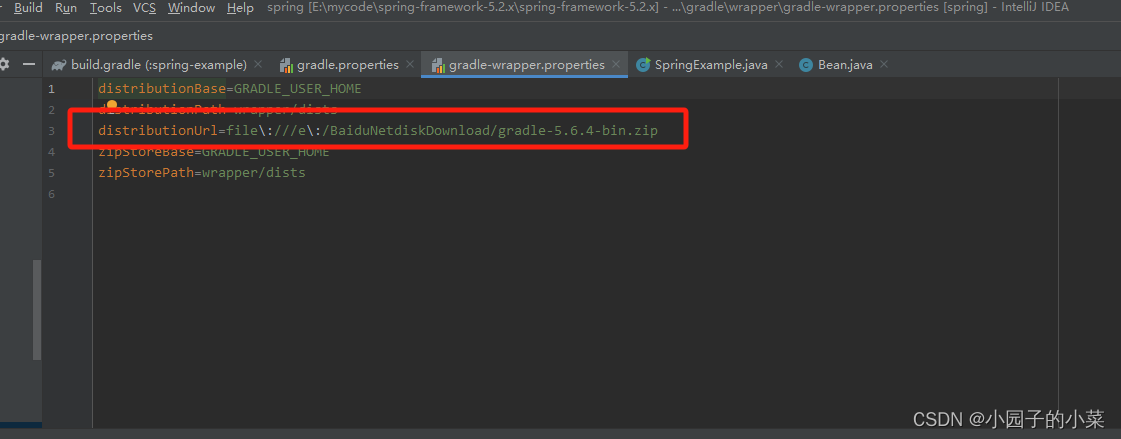
spring源码环境的搭建
为什么要编译spring源码 为了高效调试Spring源码、验证个人猜想,并从开发者的视角深化理解,编译自定义的Spring源码版本显得尤为重要。这样可以避免因缺乏预编译版本而带来的不便,并允许直接在源码上进行注释或修改,以记录学习心…...

小山菌_代码随想录算法训练营第三十四天| 56. 合并区间、
56. 合并区间 文档讲解:代码随想录.合并区间 视频讲解:贪心算法,合并区间有细节!LeetCode:56.合并区间 状态:已完成 代码实现 class Solution { public:vector<vector<int>> merge(vector<…...
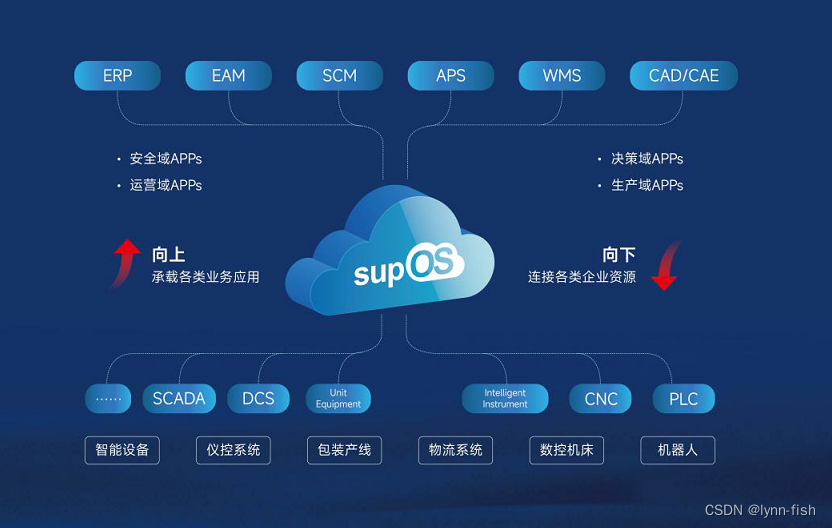
让工厂像手机一样更“聪明”
手机,作为我们日常生活中不可或缺的一部分,以其智能、便捷、高效的特点,彻底改变了我们的沟通、娱乐和工作方式。那么,想象一下,如果工厂能像手机一样便捷,那么生产过程中的每一个环节都将变得触手可及。通…...

vue2与vue3数据响应式对比之检测变化
vue2 由于javascript限制,vue不能检测数组和对象的变化 什么意思呢,举例子来说吧 深入响应式原理 对象 比如说我们在data里面定义了一个info的对象 <template><div id"app"><div>姓名: {{ info.name }}</div><…...
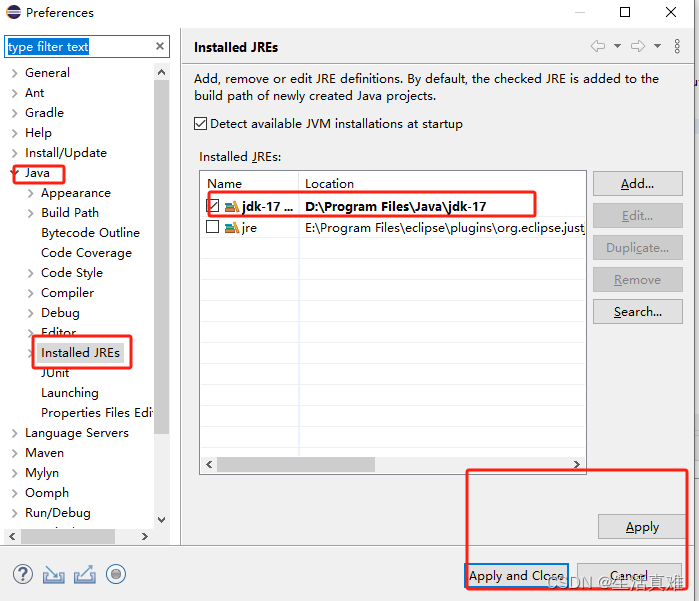
Spring Cloud - 开发环境搭建
1、JDK环境安装 1、下载jdk17:下载地址,在下图中红色框部分进行下载 2、双击安装,基本都是下一步直到完成。 3、设置系统环境变量:参考 4、设置JAVA_HOME环境变量 5、在PATH中添加%JAVA_HOME%/bin 6、在命令行中执行:j…...

绘制图形
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 在前3节的实例中,我们一直绘制的都是直线,实际上,海龟绘图还可以绘制其他形状的图形,如圆形、多边形等…...
SpringAop实战(xml文件/纯注解两种方式)
AOP的概述 什么是AOP? 在软件业,AOP为Aspect Oriented Programming的缩写,意为:面向切面编程 • AOP是一种编程范式,隶属于软工范畴,指导开发者如何组织程序结构 • AOP最早由AOP联盟的组织提出的,制定了…...
Linux的进程与线程)
(八)Linux的进程与线程
多任务处理是指用户可以在同一时间内运行多个应用程序,每个正在执行的程序被称为一个任务。一个任务包含一个或多个完成独立功能的子任务,其中子任务可以是进程或线程。Linux就是一个支持多任务的操作系统,比起单任务系统它的功能增强许多。 一.进程 进程:一个具有独立功…...
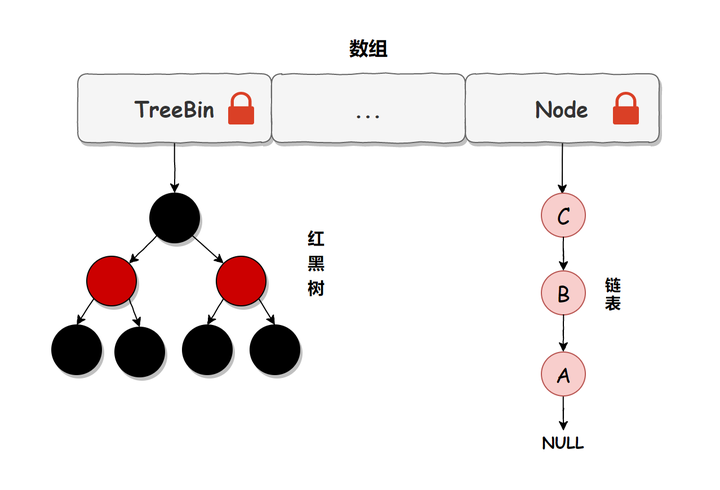
Map-JAVA面试常问
1.HashMap底层实现 底层实现在jdk1.7和jdk1.8是不一样的 jdk1.7采用数组加链表的方式实现 jdk1.8采用数组加链表或者红黑树实现 HashMap中每个元素称之为一个哈希桶(bucket),哈希桶包含的内容有以下4项 hash值(哈希函数计算出来的值) Key value next(…...
prometheus+grafana搭建监控系统
1.prometheus服务端安装 1.1下载包 使用wget下载 (也可以直接去官网下载包Download | Prometheus) wget https://github.com/prometheus/prometheus/releases/download/v2.44.0/prometheus-2.44.0.linux-amd64.tar.gz1.2解压 tar xf prometheus-2.44…...

flink学习-flink sql
动态表 在flink的数据处理中,数据流是源源不断的,是无界的,所以对于flink处理的数据表是一张动态表,所以对于动态表的查询也是持续的,每接收一条新数据会进行一次新的查询。 持续查询 因为数据在一直源源不动的到来…...

高考填报志愿攻略,5个步骤选专业和院校
在高考完毕出成绩的时候,很多人会陷入迷茫中,好像努力了这么多年,却不知道怎么规划好未来。怎么填报志愿合适?在填报志愿方面有几个内容需要弄清楚,按部就班就能找到方向,一起来了解一下正确的步骤吧。 第…...

Kubernetes排错(十)-处理容器数据磁盘被写满
容器数据磁盘被写满造成的危害: 不能创建 Pod (一直 ContainerCreating)不能删除 Pod (一直 Terminating)无法 exec 到容器 如何判断是否被写满? 容器数据目录大多会单独挂数据盘,路径一般是 /var/lib/docker,也可能是 /data/docker 或 /o…...

使用QtGui显示QImage的几种方法
问题描述 我是一名刚学习Qt的新手,正在尝试创建一个简单的GUI应用程序。当点击一个按钮时,显示一张图片。我可以使用QImage对象读取图片,但是否有简单的方法调用一个Qt函数,将QImage作为输入并显示它? 方法一:使用QLabel显示QImage 最简单的方式是将QImage添加到QLabe…...

C++ lamda
1 lamada 的函数指针存在哪里?需要通过分析编译后的二进制; 2 捕获了什么? 为什么捕获?捕获的范围是什么? 捕获的生命周期是什么? lambda 定义匿名函数,使得代码更加灵活简洁; lam…...
Linux_应用篇(27) CMake 入门与进阶
在前面章节内容中,我们编写了很多示例程序,但这些示例程序都只有一个.c 源文件,非常简单。 所以,编译这些示例代码其实都非常简单,直接使用 GCC 编译器编译即可,连 Makefile 都不需要。但是,在实…...

Adobe-GenP完整指南:5步轻松激活Adobe全系列软件
Adobe-GenP完整指南:5步轻松激活Adobe全系列软件 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP是一款专为Adobe Creative Cloud用户设计的通…...

企业内如何构建基于Taotoken的标准化AI能力中台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内如何构建基于Taotoken的标准化AI能力中台 随着大模型技术在企业内部的应用日益广泛,如何高效、安全、可控地管理…...

快速上手Highlighter:终极网页高亮工具完整指南
快速上手Highlighter:终极网页高亮工具完整指南 【免费下载链接】highlighter A Chrome extension to highlight text and keep it all saved 项目地址: https://gitcode.com/gh_mirrors/hig/highlighter 作为一名经常浏览网页的用户,你是否曾为无…...

从蓝牙4.2到5.4:广播包格式的‘进化史’与向后兼容那些坑
蓝牙广播协议演进史:从4.2到5.4的兼容性实战指南 当你的智能手表突然无法被旧款手机发现,或者工业传感器在新版本固件下出现广播丢包——这些看似简单的连接问题背后,往往隐藏着蓝牙协议版本迭代带来的兼容性暗礁。作为无线通信领域的"毛…...

DDR的硬件拓扑与ODT匹配技术
前言 本文覆盖DDR信号时延偏差成因、DDR1~DDR5历代核心差异、全代ODT阻值/挂载总线/控制逻辑、多颗粒组网ODT启闭规则、主控有无片内ODT、末端反射影响、反射波回流泄放逻辑、DDR2地址控制线无ODT原因、DQ与CA拓扑严格区分、T型/Fly-by拓扑终端匹配方案、读写匹配不对称底层硬件…...

双机并联自适应虚拟阻抗下垂控制仿真模型附Simulink仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

[安全攻防实验] 环境变量:Set-UID程序中的隐形攻击向量
1. 环境变量与Set-UID程序的安全隐患 在Linux系统中,环境变量就像是一个随身携带的"工具箱",里面装着各种程序运行时需要的信息。但你可能不知道,这个看似普通的工具箱,在遇到Set-UID程序时,可能会变成黑客…...

CLI集成AI:Gemini命令行工具实战指南与工作流优化
1. 项目概述:当命令行遇上AI,一个高效工作流的诞生如果你和我一样,每天有大量时间泡在终端里,那么“如何让命令行更智能”可能是一个持续困扰你的问题。传统的CLI工具虽然高效,但面对复杂查询、代码解释、文档生成或数…...

穿越机老鸟踩坑实录:MPU6000传感器在F4飞控上的IMU方向“玄学”配置
穿越机IMU方向配置实战:从MPU6000异常自旋到飞控底层校准 当你的穿越机在通电瞬间像被无形大手狠狠抽了一记耳光般疯狂自旋,而Betaflight地面站里陀螺仪数据却显示"一切正常"时,这往往意味着你正遭遇IMU方向配置的"量子纠缠态…...

城通网盘解析工具:3步获取高速直连下载地址的终极方案
城通网盘解析工具:3步获取高速直连下载地址的终极方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否还在为城通网盘的蜗牛下载速度而烦恼?每次下载大文件都要经历漫长的…...