数据结构:栈(stack)详解 c++信息学奥赛基础知识讲解

目录
一、栈的定义
二、栈的操作
三、代码实操
四、栈的实现
1、string实现stack
2、vector实现stack
3、deque实现栈
一、栈的定义
stack是一个比较简单易用的数据结构,stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。遵循的是后进先出的原则、Last In Fist Out,LIFO(跟队列是反的,栈是后进先出)
stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,将特定类作为其底层的,元素特定容器的尾部(即栈顶)被压入和弹出。

如何声明一个栈
stack<储存的类型> 容器名
常规类型栈
- 储存int型数据的栈 stack<int> s;
- 储存double型数据的栈 stack<double> s;
- 储存string型数据的栈 stack<string> s;
- 储存结构体或者类的栈 stack<结构体名> s;
数组栈stack:
- 储存int型数据的栈 stack<int> s[n];
- 储存double型数据的栈 stack<double> s[n];
- 等等,n为数组的大小
二、栈的操作
//其实栈就这几个成员函数
push() //在栈顶增加元素
pop() //移除栈顶元素
top() //返回栈顶元素
empty() //堆栈为空则返回真
size() //返回栈中元素数目
三、代码实操
#include<iostream>//c++标准头文件,可以使用cout,cin等标准库函数
#include<stack>//使用stack时需要的头文件
using namespace std;//命名空间,防止重名给程序带来各种隐患,使用cin,cout,stack,map,set,vector,queue时都要使用
int main(){stack<int> s;//定义一个int类型的stacks.push(1);//往栈里放入一个元素1s.push(2);//往栈里放入一个元素2s.push(3); //往栈里放入一个元素3cout<<"按顺序放入元素1、2、3后,目前栈里的元素:1 2 3" <<endl;cout<<"s.size()="<<s.size()<<endl;//s.size()返回栈内元素的个数 cout<<"s.empty()="<<s.empty()<<endl; //判断栈是否为空,值为1代表空,0代表非空,用s.size()同样可以判断 ,s.size()的值为0就代表空的 cout<<"s.top()="<<s.top()<<endl;//查看栈顶的元素 cout<<endl;s.pop();//弹出栈顶元素 cout<<"s.pop()后,目前栈里的元素:1 2"<<endl;cout<<"s.size()="<<s.size()<<endl;cout<<"s.empty()="<<s.empty()<<endl; cout<<"s.top()="<<s.top()<<endl;cout<<endl;s.pop();cout<<"s.pop()后,目前栈里的元素:1"<<endl;cout<<"s.size()="<<s.size()<<endl;cout<<"s.empty()="<<s.empty()<<endl; cout<<"s.top()="<<s.top()<<endl;cout<<endl;s.pop();cout<<"s.pop()后,目前的栈是空的"<<endl;cout<<"s.size()="<<s.size()<<endl;cout<<"栈是空的就不能用s.top()访问栈顶元素了" <<endl; cout<<"s.empty()="<<s.empty()<<endl; }
运行结果
按顺序放入元素1、2、3后,目前栈里的元素:1 2 3
s.size()=3
s.empty()=0
s.top()=3s.pop()后,目前栈里的元素:1 2
s.size()=2
s.empty()=0
s.top()=2s.pop()后,目前栈里的元素:1
s.size()=1
s.empty()=0
s.top()=1s.pop()后,目前的栈是空的
s.size()=0
栈是空的就不能用s.top()访问栈顶元素了
s.empty()=1
四、栈的实现
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如string、vector和list都可以
1、string实现stack
栈中的数据是不允许随机访问的,就是不能像数组那样用下标访问,也不能遍历栈内的元素,这是很局限的。实际上,我们经常使用的string类型就是一种栈结构,但是我们可以通过下标访问元素,我们可以看看
//string的栈相关的成员函数
empty() //堆栈为空则返回真
pop_back() //移除栈顶元素
push_back() //在栈顶增加元素
size() //返回栈中元素数目
back() //返回栈顶元素 示例代码:
#include<iostream>//c++标准头文件,可以使用cout,cin等标准库函数
#include<string>//string包括了一些字符串操作的库函数,但用string时是不用引入这个头文件的
using namespace std;//命名空间,防止重名给程序带来各种隐患,使用cin,cout,stack,map,set,vector,queue时都要使用
int main(){string s;//定义一个字符串s.push_back('1');//往栈里放入一个元素1s.push_back('2');//往栈里放入一个元素2s.push_back('3'); //往栈里放入一个元素3cout<<"按顺序放入字符1、2、3后,目前string里的元素:" ;for(int i=0;i<s.size();i++){cout<<s[i]<<' ';}cout<<endl; cout<<"s.pop_back()="<<s.size()<<endl;//s.size()返回string内字符的个数 cout<<"s.empty()="<<s.empty()<<endl; //判断栈是否为空,值为1代表空,0代表非空,用s.size()同样可以判断 ,s.size()的值为0就代表空的 cout<<"s.back()="<<s.back()<<endl;//查看栈顶的元素 cout<<endl;s.pop_back();//弹出栈顶元素 cout<<"s.pop_back()后,目前string里的元素:";for(int i=0;i<s.size();i++){//可以通过下标随机访问元素 cout<<s[i]<<' ';}cout<<endl; cout<<"s.size()="<<s.size()<<endl;cout<<"s.empty()="<<s.empty()<<endl; cout<<"s.back()="<<s.back()<<endl;cout<<endl;s.pop_back();cout<<"s.pop_back()后,目前string里的元素:";for(int i=0;i<s.size();i++){cout<<s[i]<<' ';}cout<<endl; cout<<"s.size()="<<s.size()<<endl;cout<<"s.empty()="<<s.empty()<<endl; cout<<"s.back()="<<s.back()<<endl;cout<<endl;s.pop_back();cout<<"s.pop_back()后,目前的string是空的"<<endl;cout<<"s.size()="<<s.size()<<endl;cout<<"string是空的就不能用s.back()访问栈顶元素了" <<endl; cout<<"s.empty()="<<s.empty()<<endl; }
输出结果:
按顺序放入字符1、2、3后,目前string里的元素:1 2 3
s.pop_back()=3
s.empty()=0
s.back()=3s.pop_back()后,目前string里的元素:1 2
s.size()=2
s.empty()=0
s.back()=2s.pop_back()后,目前string里的元素:1
s.size()=1
s.empty()=0
s.back()=1s.pop_back()后,目前的string是空的
s.size()=0
string是空的就不能用s.back()访问栈顶元素了
s.empty()=12、vector实现stack
vector是stack的升级版,多了很多成员函数,像随机插入函数insert()等等,大家完全可以用vector替代stack的。vector和string不同的是,string只能存储char类型的,而vector能存储所有类型的数据,想int、double、结构体、类等等
//vector的栈相关的成员函数
empty() //堆栈为空则返回真
pop_back() //移除栈顶元素
push_back() //在栈顶增加元素
size() //返回栈中元素数目
back() //返回栈顶元素
示例代码:
#include<iostream>//c++标准头文件,可以使用cout,cin等标准库函数
#include<vector>//使用vector时需要的头文件
using namespace std;//命名空间,防止重名给程序带来各种隐患,使用cin,cout,stack,map,set,vector,queue时都要使用
int main(){vector<int> v;//定义一个int类型的stackv.push_back(1);//往vector里放入一个元素1v.push_back(2);//往vector里放入一个元素2v.push_back(3); //往vector里放入一个元素3cout<<"按顺序放入字符1、2、3后,目前vector里的元素:" ;for(int i=0;i<v.size();i++){//可以通过下标随机访问元素 cout<<v[i]<<' ';}cout<<endl; cout<<"v.pop_back()="<<v.size()<<endl;//v.size()返回vector内元素的个数 cout<<"v.empty()="<<v.empty()<<endl; //判断栈是否为空,值为1代表空,0代表非空,用v.size()同样可以判断 ,v.size()的值为0就代表空的 cout<<"v.back()="<<v.back()<<endl;//查看栈顶的元素 cout<<endl;v.pop_back();//弹出栈顶元素 cout<<"v.pop_back()后,目前vector里的元素:";for(int i=0;i<v.size();i++){cout<<v[i]<<' ';}cout<<endl; cout<<"v.size()="<<v.size()<<endl;cout<<"v.empty()="<<v.empty()<<endl; cout<<"v.back()="<<v.back()<<endl;cout<<endl;v.pop_back();cout<<"v.pop_back()后,目前vector里的元素:";for(int i=0;i<v.size();i++){cout<<v[i]<<' ';}cout<<endl; cout<<"v.size()="<<v.size()<<endl;cout<<"v.empty()="<<v.empty()<<endl; cout<<"v.back()="<<v.back()<<endl;cout<<endl;v.pop_back();cout<<"v.pop_back()后,目前的vector是空的"<<endl;cout<<"v.size()="<<v.size()<<endl;cout<<"vtring是空的就不能用v.back()访问栈顶元素了" <<endl; cout<<"v.empty()="<<v.empty()<<endl;
}
输出结果:
按顺序放入字符1、2、3后,目前vector里的元素:1 2 3
v.pop_back()=3
v.empty()=0
v.back()=3v.pop_back()后,目前vector里的元素:1 2
v.size()=2
v.empty()=0
v.back()=2v.pop_back()后,目前vector里的元素:1
v.size()=1
v.empty()=0
v.back()=1v.pop_back()后,目前的vector是空的
v.size()=0
vtring是空的就不能用v.back()访问栈顶元素了
v.empty()=1
3、deque实现栈
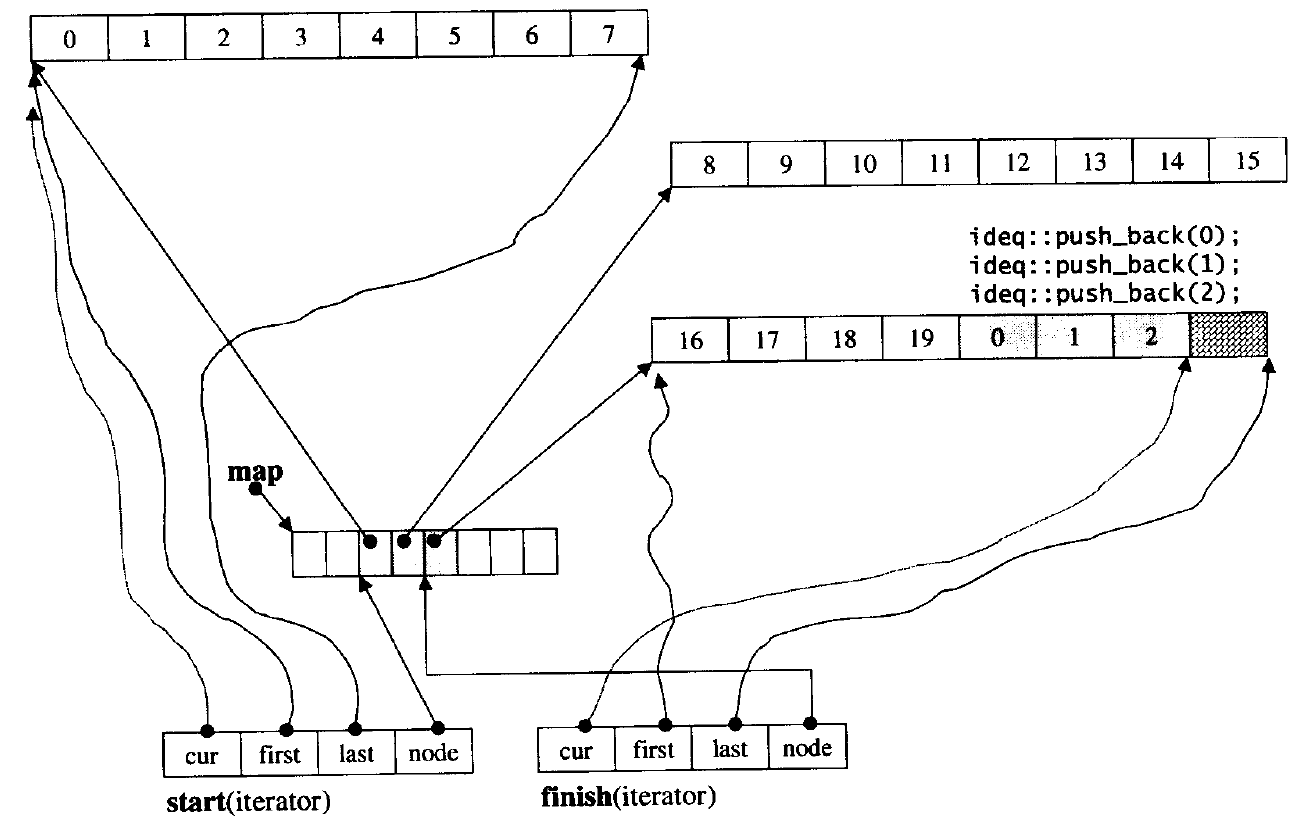
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组,其底层结构如下图所示:
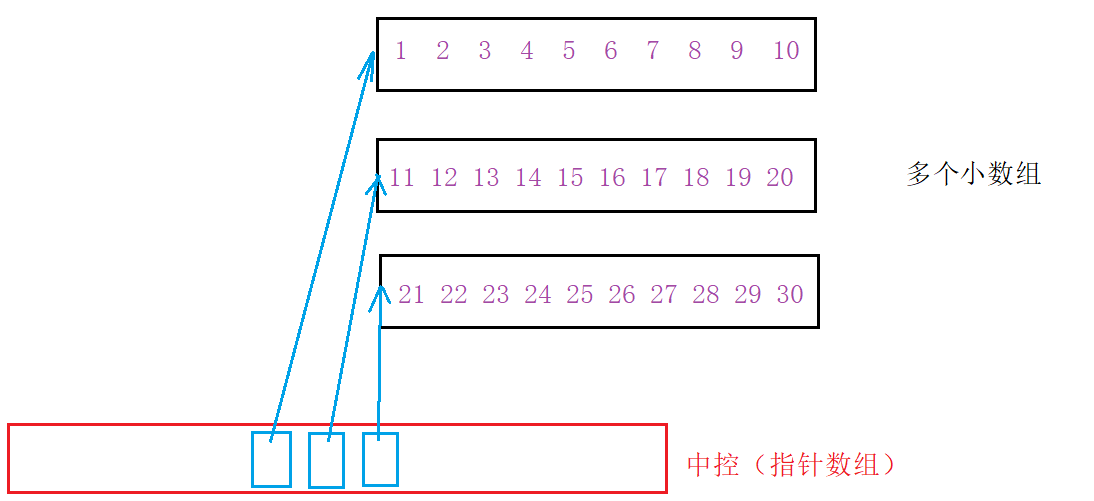
deque 折中了 vector 与 string的结构,使用多个小数组来存储空间,为了管理这些小数组,又开辟了一个叫做中控的指针数组,数组中的指针分别指向这些小数组。
需要注意的是,最开始使用指针是中控指针数组中间位置的指针,当进行头插、尾插的时候,就可以直接使用前一个、后一个指针指向新开辟的空间了:
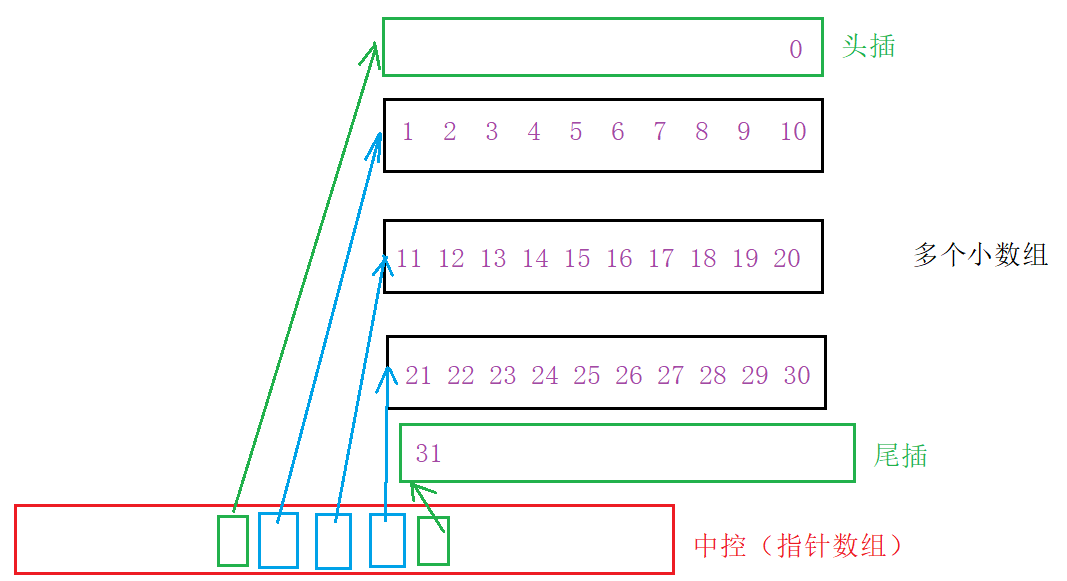
当中控数组满时,只需对中控数组进行扩容就可以了, 而且由于中控数组中存放的都是指针,所以拷贝代价极低。
由以上结构我们可知deque的优点有:
- 相比vector,deque 的扩容代价低
- 头插头删、尾插尾删效率高
- 支持下标随机访问
比如,假设每个小数组的容量为 10 ,我们想要找到下标为 25 的元素,只需要用下标减去第一个数组内元素的个数,再除以每个数组的容量就能找到其所在哪一个小数组。对应到上面我们所画的图中,就是 (25 - 1) / 10 。找到对应元素存在于第 2 个数组后,再用 (25 - 1) % 10 就可以知道对应元素是在该小数组中的第几个。
综上:
- 与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
- 与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构。
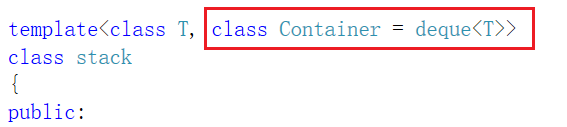
STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
- stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
- 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。结合了deque的优点,而完美的避开了其缺陷。
五、案例实操
题目描述:实现一个MyQueue类,该类用两个栈来实现一个队列。
示例:
MyQueue queue = new MyQueue();queue.push(1);
queue.push(2);
queue.peek(); // 返回 1
queue.pop(); // 返回 1
queue.empty(); // 返回 false说明:
- 你只能使用标准的栈操作 -- 也就是只有
push to top,peek/pop from top,size和is empty操作是合法的。 - 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
- 假设所有操作都是有效的 (例如,一个空的队列不会调用 pop 或者 peek 操作)。
代码实现:
class MyQueue {
private:stack<int> inStack, outStack;//私有成员函数入栈并出栈void in2out() {while (!inStack.empty()) {outStack.push(inStack.top());inStack.pop();}}public:MyQueue() {}//入队void push(int x) {inStack.push(x);}//出队并返回首元素int pop() {if (outStack.empty()) {in2out();}int x = outStack.top();outStack.pop();return x;}//返回队首元素int peek() {if (outStack.empty()) {in2out();}return outStack.top();}//判断队是否为空bool empty() {return inStack.empty() && outStack.empty();}
};相关文章:
数据结构:栈(stack)详解 c++信息学奥赛基础知识讲解
目录 一、栈的定义 二、栈的操作 三、代码实操 四、栈的实现 1、string实现stack 2、vector实现stack 3、deque实现栈 一、栈的定义 stack是一个比较简单易用的数据结构,stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中ÿ…...

电商返利系统的高并发处理与性能优化
电商返利系统的高并发处理与性能优化 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在电子商务平台中,返利系统是吸引用户和提升用户粘性的重要功…...

NPM 常用命令
NPM 常用命令 NPM(Node Package Manager)是 JavaScript 生态系统中最流行的包管理工具,它不仅可以管理 Node.js 项目的依赖,还提供了丰富的命令来管理和发布你的代码。本文将从不同角度,深入浅出地介绍 NPM 的常用命令…...

C++进修——C++核心编程
内存分区模型 C程序在执行时,将内存大方向划分为4个区域 代码区:存放函数体的二进制编码,由操作系统进行管理全局区:存放全局变量和静态变量以及常量栈区:由编译器自动分配释放,存放函数的参数值ÿ…...

【信息系统项目管理师知识点速记】项目文档管理
19.3 项目文档管理 信息系统相关信息(文档)是指某种数据媒体和其中所记录的数据。文档具有永久性,并可以由人或机器阅读,通常用于描述人工可读的内容。在软件工程中,文档常常用来表示对活动、需求、过程或结果进行描述、定义、规定、报告或认证的任何书面或图示的信息(包…...

服务器硬件,raid配置
文章目录 服务器硬件RAID磁盘阵列RAID 0RAID 1RAID 5RAID 6RAID 10 阵列卡,阵列卡的缓存阵列卡阵列卡的缓存 软RAID磁盘阵列RAID阵列的管理及设备恢复mdadm 服务器硬件 处理器(CPU):服务器的核心组件,负责执行计算和指令操作。服务器常使用多…...

fc-list命令使用指南
fc-list命令使用指南 一、什么是fc-list? fc-list是FontConfig库的一部分,最初为Linux和其他Unix-like系统开发。我们可以用这个命令行快速查询和列出系统中安装的字体。 现在,Windows用户也集成了这个工具,所以我们来讲解一下用法。 二、…...

NAS安全存储怎样实现更精细的数据权限管控?
NAS存储,即网络附属存储(Network Attached Storage),是一种专用数据存储服务器,其核心特点在于将数据存储设备与网络相连,实现集中管理数据的功能。 NAS存储具有以下明显优势,而被全球范围内的企…...
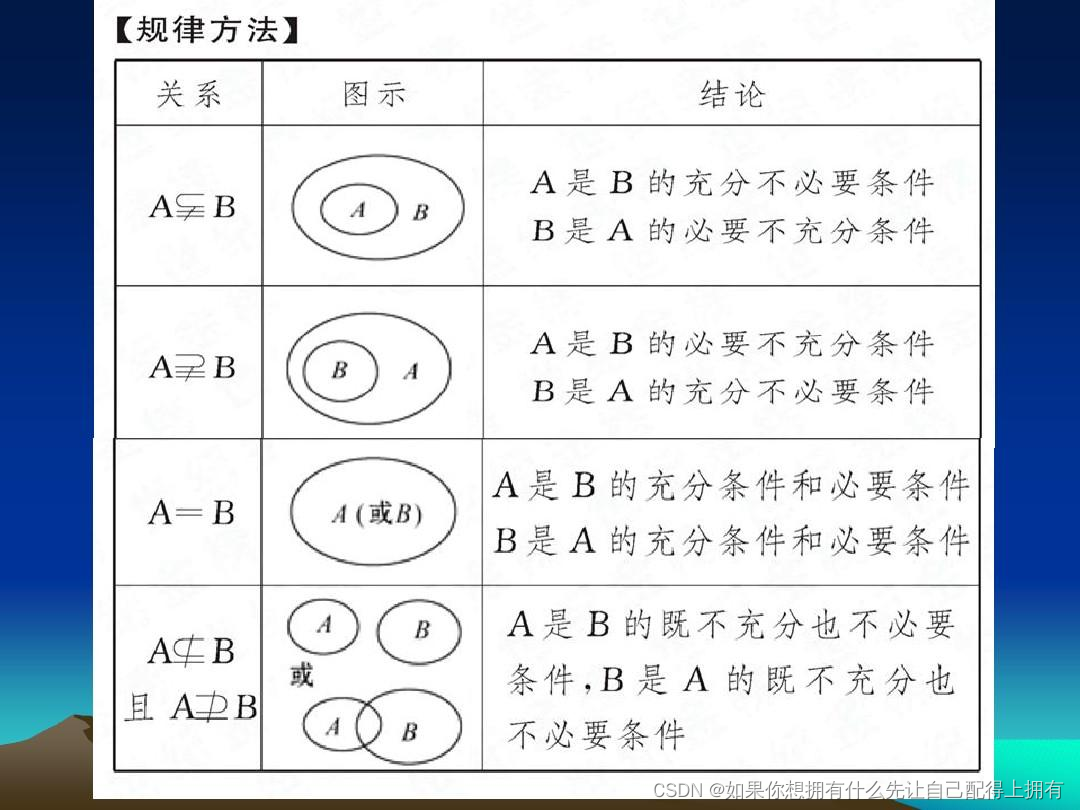
第三十篇——等价性:如何从等价信息里找答案?
目录 一、背景介绍二、思路&方案三、过程1.思维导图2.文章中经典的句子理解3.学习之后对于投资市场的理解4.通过这篇文章结合我知道的东西我能想到什么? 四、总结五、升华 一、背景介绍 知道了等价性的逻辑,通过等价性去衡量事物,像是给…...
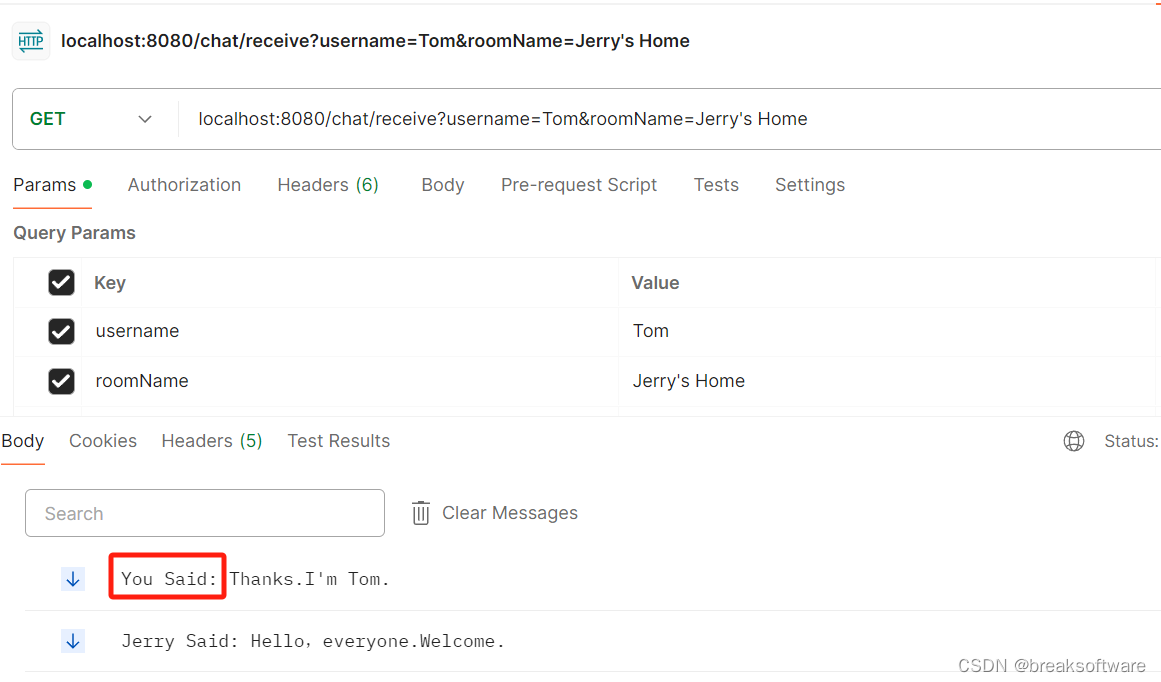
RabbitMQ实践——搭建多人聊天服务
大纲 用户登录创建聊天室监听Stream(聊天室)发送消息实验登录Tom侧Jerry侧 创建聊天室Jerry侧Tom侧 进入聊天室Jerry侧Tom侧 发送消息Jerry发送消息Jerry侧聊天室Tom侧聊天室 Tom发送消息Jerry侧聊天室Tom侧聊天室 代码工程参考资料 在《RabbitMQ实践——…...
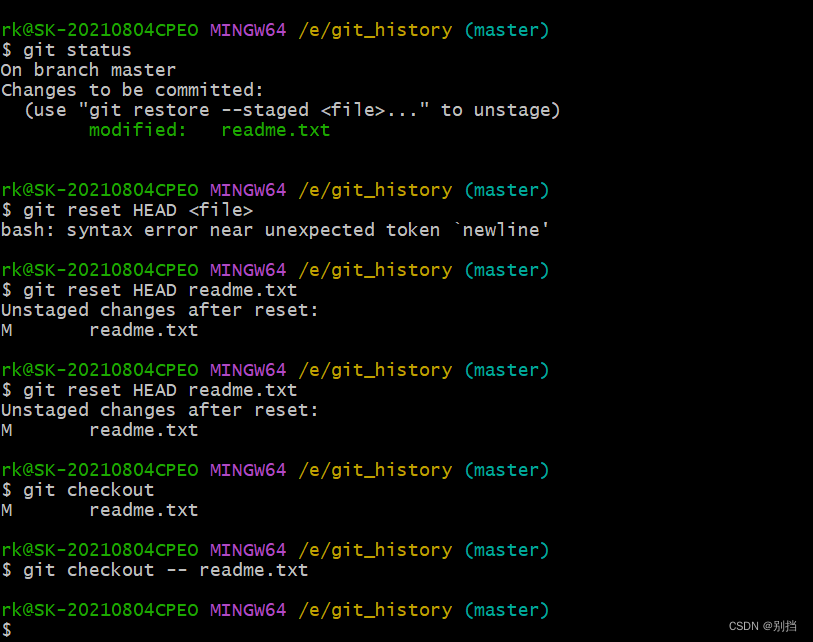
git分布式版本控制系统
Git - Downloads (git-scm.com) gitee教程(超全,超详细,超长)-CSDN博客 Git教程 - 廖雪峰的官方网站 (liaoxuefeng.com) 所有的版本控制系统,其实只能跟踪文本文件改动,比如TXT文件,网页&…...
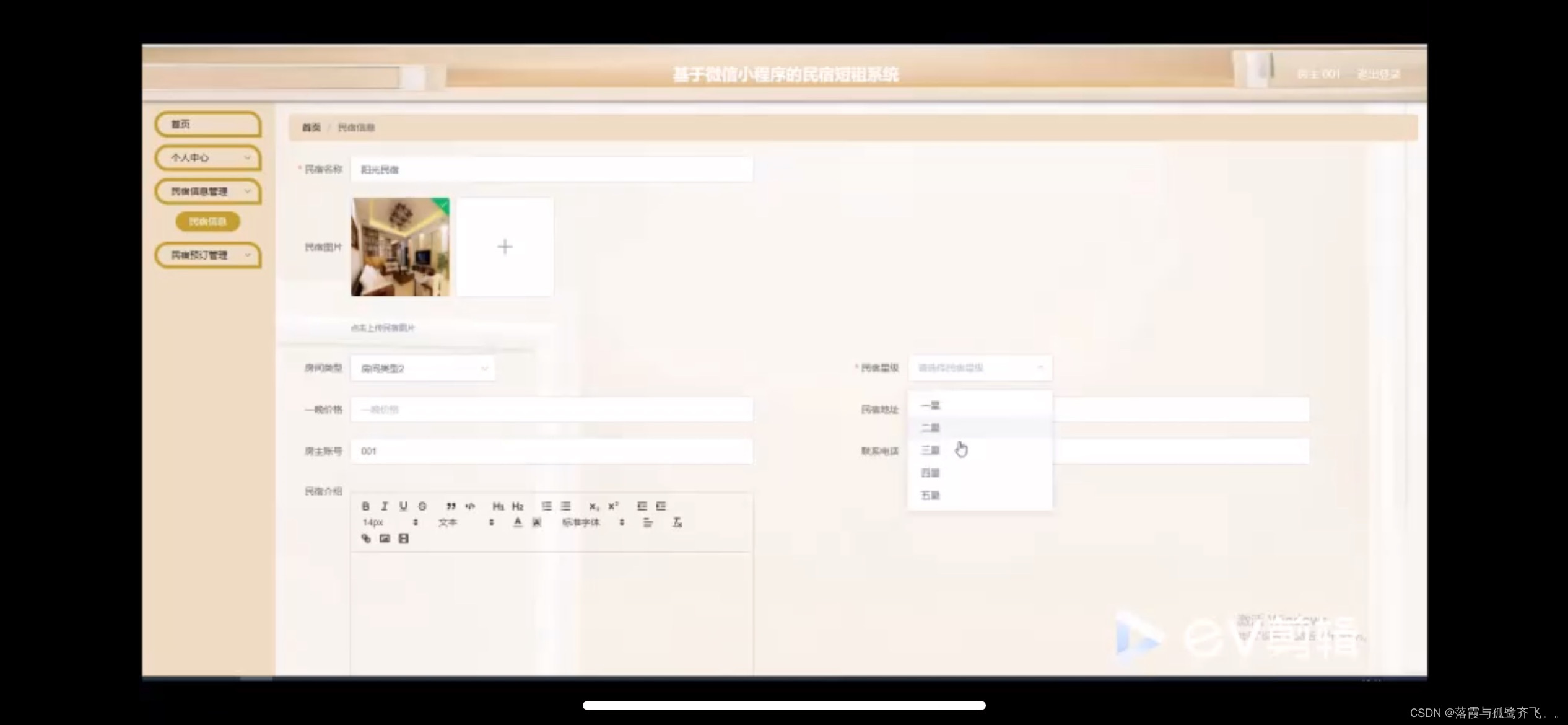
基于weixin小程序的民宿短租系统的设计与实现
管理员账户功能包括:系统首页,个人中心,房主管理,房间类型管理,用户管理,民宿信息管理,民宿预订管理,系统管理 小程序功能包括:系统首页,民宿信息,…...

2024-06-22力扣每日一题
链接: 2663. 字典序最小的美丽字符串 题意 略 解: 要求字符串内不存在任何长度为 2 或更长的回文子字符串,则在任意位置不存在aa或aba形式 由于要被给定字符串字典序大,且找到符合条件的字典序最小字符串,则竟可…...
S_LOVE多端恋爱小站小程序源码 uniapp多端
S_LOVE多端恋爱小站小程序源码,采用uniapp多端开发框架进行开发,目前已适配H5、微信小程序版本。 源码下载:https://download.csdn.net/download/m0_66047725/89421726 更多资源下载:关注我。...

如何避免MySQL的死锁或性能下降
1、按顺序访问数据 确保多个线程或事务在访问多个表或行时,按照相同的顺序进行。这可以避免循环等待和资源竞争,从而降低死锁的风险。 2、避免长时间持有锁 尽量缩短事务的执行时间,避免长时间持有锁。长时间持有锁会增加其他事务等待的时…...
《C语言》编译和链接
文章目录 一、翻译环境1、预处理2、编译3、汇编4、链接 二、运行环境 一、翻译环境 在使用编译器编写代码时,编写的代码是高级语言,机器无法直接识别和运行,在编译器内部会翻译成机器可执行的机器语言。 编译环境由编译和链接两大过程组成。 …...

group by和select的兼容性问题
group by和select的兼容性问题 在标准的SQL语法中,GROUP BY 和 SELECT 之间不存在兼容性问题,因为它们是 SQL 查询语句的基本组成部分,而且它们的使用方式是相互兼容的。 SELECT 子句和 GROUP BY 子句的关系: SELECT 子句&#…...

切面aspect处理fegin调用转本地调用
切面处理fegin调用转本地调用 问题:原fegin调用转本地调用详细描述方案代码实现总结问题:原fegin调用转本地调用 项目原来是微服务项目服务与服务之间是通过fegin进行交互的,但是现在微服务项目要重构为单体项目,原fegin调用的方法要给为本地调用 详细描述 zyy-aiot │ …...
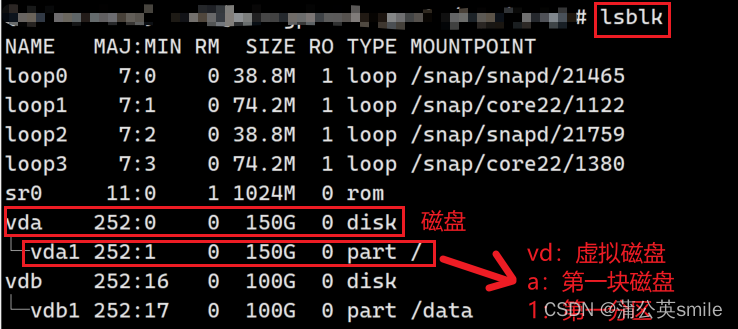
Linux 磁盘挂载与分区
Linux 磁盘挂载与分区 vda1: 其中vd表示虚拟磁盘,a表示第一块磁盘,b表示第二块磁盘,1表示第一块磁盘的第一分区(显然两块磁盘都只有一个分区)图中可以看到,vda1磁盘只有一个分区,且全部挂载到根…...

Open3D 将ShapeNet数据集txt转pcd
目录 一、概述 二、代码实现 三、实现效果 一、概述 ShapeNet 数据集是一个广泛使用的三维物体数据集,主要用于计算机视觉、计算机图形学、机器人学和机器学习等领域的研究。它包含大量的三维物体模型,并附有丰富的标注信息。ShapeNet 数据集由普林斯…...

终极CoreCycler教程:简单三步完成CPU稳定性测试与优化
终极CoreCycler教程:简单三步完成CPU稳定性测试与优化 【免费下载链接】corecycler Script to test single core stability, e.g. for PBO & Curve Optimizer on AMD Ryzen or overclocking/undervolting on Intel processors 项目地址: https://gitcode.com/…...

Linuxbonding链路生产排障流程
Linuxbonding链路生产排障流程这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...

如何免费高效优化电脑性能:UXTU终极调优指南
如何免费高效优化电脑性能:UXTU终极调优指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility Universal x86 Tuning…...

AI原生代码库OpenCode:从代码生成到项目级协同的开发新范式
1. 项目概述:一个面向开发者的AI原生代码库最近在GitHub上看到一个挺有意思的项目,叫opencode-ai/opencode。光看名字,你可能会觉得这又是一个“AI写代码”的工具,或者是一个AI模型的代码仓库。但如果你点进去仔细研究一下&#x…...

ARM架构寄存器与参数管理核心技术解析
1. ARM架构寄存器与参数管理基础解析 在ARM架构的底层开发中,寄存器与参数管理是系统控制和调试的核心机制。作为嵌入式开发者,我经常需要与这两种资源打交道,它们虽然都用于存储数据,但在使用场景和特性上存在本质差异。 寄存器…...
基于BLE与UriBeacon标准,打造低成本物理网页信标实践指南
1. 项目概述:从蓝牙信标到物理网页的进化 几年前,当我第一次接触iBeacon时,就被这种“静默广播、主动感知”的物联网交互模式吸引了。一个小小的硬件,不用配对,就能让周围的手机知道它的存在,并触发相应的…...

探索Mod Assistant:Beat Saber模组管理工具的高效解决方案
探索Mod Assistant:Beat Saber模组管理工具的高效解决方案 【免费下载链接】ModAssistant Simple Beat Saber Mod Installer 项目地址: https://gitcode.com/gh_mirrors/mo/ModAssistant Beat Saber模组管理工具Mod Assistant是一款专为PC版Beat Saber设计的…...

【ElevenLabs卡纳达文语音实战指南】:2024年唯一经生产环境验证的7步本地化部署方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs卡纳达文语音技术概览与生产价值定位 ElevenLabs 作为全球领先的文本转语音(TTS)平台,自2023年Q4起正式支持卡纳达语(Kannada)&…...

大模型涌现能力:从原理到工程实践的探索与分类
1. 项目概述:从“玄学”到“科学”的涌现能力探索最近和几个做模型研发的朋友聊天,大家不约而同地提到了一个词:“涌现能力”。这个词听起来有点玄乎,像是某种不可预测的“魔法”,但当我们深入讨论时,发现它…...

避坑指南:ENVI5.6在Win10/Win11系统下的常见安装失败问题与解决
ENVI5.6安装避坑实战:从报错排查到系统级调优 当你在Windows 10/11系统上双击ENVI5.6安装程序时,可能没想到这个看似标准的安装过程会变成一场技术冒险。不同于常规教程只展示理想路径,我们将直面那些让科研工作者抓狂的"安装已终止&quo…...