Hive 之 DDL操作
DDL 操作是用于操作对象和对象的属性,这种对象包括数据库本身,以及数据库对象,像:表、视图等等
1. 数据库
1.1 创建数据库
数据库在 HDFS 上的默认存储路径是 /user/hive/warehouse/*.db
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] // 库的注释说明
[LOCATION hdfs_path] // 库在hdfs上的路径
[WITH DBPROPERTIES (property_name=property_value, ...)]; // 库的属性
示例:
create database if not exists mydb2
comment 'this is my db'
location 'hdfs://hadoop1:9000/mydb2'
with dbproperties('ownner'='rose','tel'='12345','department'='development');
1.2 数据库查询
show databases;
show databases like 'db_hive*'; // 过滤
use databases; // 使用数据库
desc database db_hive; // 显示数据库信息
desc database extended db_hive; // 显示数据库详细信息
1.3 修改数据库
alter table 命令可以修改数据库的 DBPROPERTIES 的键值对,但是数据库的元数据信息不可更改,如:数据库名称、所在目录位置:
// 同名的属性值会覆盖,之前没有的属性会新增
alter database mydb2 set dbproperties('ownner'='tom','empid'='10001');// 查询修改
desc database extended mydb2;
1.4 删除数据库
// 删除空数据库,只能删空库
drop database if exists db_hive2;hive> drop database db_hive cascade;
2. 数据表
2.1 表分类
- 管理表:删除操作时,会删除元数据和数据本身
- 外部表:删除操作时,只会删除元数据
- 分区表:在建表时,指定了
PARTITIONED BY,分区的目的是为了就数据,分散到多个子目录中,在执行查询时,可以只选择查询某些子目录中的数据,加快查询效率 - 分桶表:建表时指定了
CLUSTERED BY,区别于分区表,把数据分散到多个文件中。可以结合hive提供的抽样查询,只查询指定桶的数据
2.2 创建表
创建表的时候,hive 会:
- 在
hdfs生成表的路径 - 向
MySQL的metastone库中插入两条表的信息(元数据)
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)] // 字段名称、类型、注释
[COMMENT table_comment] // 表注释
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] // 创建分区表
[CLUSTERED BY (col_name, col_name, ...) // 创建分桶表
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format] // 表中数据每行的格式,定义数据字段的分隔符,集合元素的分隔符等
[STORED AS file_format] //表中的数据要以哪种文件格式来存储,默认为TEXTFILE(文本文件)
[LOCATION hdfs_path] // 指定表在HDFS上的存储位置
可选字段说明
EXTERNAL:创建外部表,在建表的同时指定实际数据路径location,hive创建内部表时,会将数据移动到数据仓库所指向的路径;若是外部表,仅记录数据所在路径,不对数据位置做任何改变。删除表时,内部表元数据、数据都会被删除,而外部表只会删除元数据COMMENT:为表和列添加注释PARTITIONED BY:创建分区表CLUSTERED BY:创建分桶表SORTED BY:排序,不常用ROW FORMAT:数据行格式
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char][MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化。
STORED AS:指定存储文件类型,如:sequencefile、rcfile等,默认textfileLOCATION:指定表在HDFS上的存储位置LIKE允许用户复制已存在的表结构,但是不会复制数据
示例
// 创建表
create table if not exists student2(
id int, name string
)
row format delimited fields terminated by '\t'
stored as textfile
location '/user/hive/warehouse/student2';// 根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student3 as select id, name from student;// 根据已经存在的表结构创建表
create table if not exists student4 like student;// 查看表类型
hive (hive_1)> desc formatted student;
OK
col_name data_type comment
# col_name data_type commentid int
name string# Detailed Table Information
Database: hive_1
Owner: hadoop
CreateTime: Sun Nov 21 18:13:32 CST 2021
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop1:9000/user/hive/warehouse/hive_1.db/student
Table Type: MANAGED_TABLE // 表示为管理表
2.2.1 管理表
管理表也称内部表,默认创建的就是管理表,特点就是 删除表的同时也会删除元数据,与之对应的外部表就只会删除元数据,而不删除数据
2.2.2 外部表
实际生产中使用的大部分是外部表
// 创建一个外部表,有 EXTERNAL 关键字就是外部表
create EXTERNAL table if not exists student2(
id int, name string
)
row format delimited fields terminated by '\t'
stored as textfile
location '/user/hive/warehouse/student2';// 查询表类型
hive (default)> desc formatted dept;
Table Type: EXTERNAL_TABLE
2.2.3 管理表和外部表的相关转换
// 修改内部表 test1 为外部表
alter table test1 set tblproperties('EXTERNAL'='TRUE');// 修改外部表 test1 为内部表
alter table student2 set tblproperties('EXTERNAL'='FALSE');
注意:
'EXTERNAL'='TRUE')和('EXTERNAL'='FALSE')为固定写法,区分大小写!
2.3 分区表
分区表实际是在 hdfs 上创建多个独立的文件夹,hive 的分区即是分目录。将一个大的数据集分隔为多个小的数据集,在查询时通过 where 子句来指定查询分区,而不是全表查询,其目的是为了提高效率。
语法:
// 比普通建表语句多了一个 partitioned by// 一级分区表,其中 month 为分区字段,string 为其类型
create table dept_partition(
deptno int, dname string, loc string
)
partitioned by (month string)
row format delimited fields terminated by '\t';// 多级分区表,有多个分区字段 area、province
create external table if not exists default.deptpart2(
deptno int,
dname string,
loc int
)
PARTITIONED BY(area string, province string)
row format delimited fields terminated by '\t';
注意
- 如果表是个分区表,在导入数据时,必须指定向哪个分区目录导入数据,否则会报错
- 如果表是多级分区表,在导入数据时,数据必须位于最后一级分区的目录
2.3.1 创建分区
- 方法一:
alter table 表名 add partition(分区字段名=分区字段值);- 分区创建成功后,会在
hdfs生成分区路径、也会在partitions表中生成分区的元数据 - 创建多个分区:
alter table dept_partition add partition(month='201705') partition(month='201704');
- 分区创建成功后,会在
- 方法二:
load命令向分区加载数据,若分区不存在,则会自动创建 - 方法三:若数据已上传到
hdfs,可使用修复分区命令的方式来自动生成分区的元数据:msck repair table 表名;
2.3.2 其他操作
// 查看分区表有多少分区
show partitions 表名// 查看分区表结构
desc formatted dept_partition;// 删除分区
alter table dept_partition drop partition (month='201704');// 删除多个分区
alter table dept_partition drop partition (month='201705'), partition (month='201706');// 多分区联合查询
select * from dept_partition where month='201709'unionselect * from dept_partition where month='201708'unionselect * from dept_partition where month='201707';
2.3.3 练习一
需求:创建一个一级分区表
1、创建分区表:
create table dept_partition(
deptno int, dname string, loc string
)
partitioned by (area string)
row format delimited fields terminated by '\t';// 查看表描述信息
hive (default)> desc dept_partition;
OK
col_name data_type comment
deptno int
dname string
loc string
area string# Partition Information
# col_name data_type commentarea string
Time taken: 0.398 seconds, Fetched: 9 row(s)// 查看分区信息
hive (default)> show partitions dept_partition;
OK
partition
area=huanan
Time taken: 0.46 seconds, Fetched: 1 row(s)
2、加载数据:
// 将本地数据加载到分区目录 area='huanan',
load data local inpath '/home/hadoop/apps/big_source/files/dept.txt' into table default.dept_partition partition(area='huanan');// hdfs 上数据存储路径
/user/hive/warehouse/dept_partition/area=huanan
3、查询:
// 原本表只有三列,加了分区信息后,变为 4 列,查询时可用 area=huanan 条件来查询
0: jdbc:hive2://hadoop1:10000> select * from dept_partition where area='huanan';
+------------------------+-----------------------+---------------------+----------------------+--+
| dept_partition.deptno | dept_partition.dname | dept_partition.loc | dept_partition.area |
+------------------------+-----------------------+---------------------+----------------------+--+
| 10 | ACCOUNTING | 1700 | huanan |
| 20 | RESEARCH | 1800 | huanan |
| 30 | SALES | 1900 | huanan |
| 40 | OPERATIONS | 1700 | huanan |
+------------------------+-----------------------+---------------------+----------------------+--+
4 rows selected (3.017 seconds)select * from dept_partition where area='huanan'unionselect * from dept_partition where area='huazhong'
2.3.4 练习二 修复分区信息
1、创建 hdfs 目录,并上传数据
// 直接 put,可能会导致修复失败
[hadoop@hadoop1 files]$ hadoop fs -mkdir -p /user/hive/warehouse/dept_partition/area=zhong
[hadoop@hadoop1 files]$ hadoop fs -put dept.txt /user/hive/warehouse/dept_partition/area=zhong// dept.txt
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
2、查看分区信息、修复分区:
0: jdbc:hive2://hadoop1:10000> show partitions dept_partition;
+--------------+--+
| partition |
+--------------+--+
| area=huanan |
+--------------+--+
1 row selected (0.464 seconds)0: jdbc:hive2://hadoop1:10000> msck repair table dept_partition;
No rows affected (0.375 seconds)0: jdbc:hive2://hadoop1:10000> show partitions dept_partition;
+--------------+--+
| partition |
+--------------+--+
| area=huanan |
| area=zhong |
+--------------+--+
2 rows selected (0.436 seconds)0: jdbc:hive2://hadoop1:10000> select * from dept_partition where area='zhong';
+------------------------+-----------------------+---------------------+----------------------+--+
| dept_partition.deptno | dept_partition.dname | dept_partition.loc | dept_partition.area |
+------------------------+-----------------------+---------------------+----------------------+--+
| 10 | ACCOUNTING | 1700 | zhong |
| 20 | RESEARCH | 1800 | zhong |
| 30 | SALES | 1900 | zhong |
| 40 | OPERATIONS | 1700 | zhong |
+------------------------+-----------------------+---------------------+----------------------+--+
4 rows selected (0.454 seconds)
2.4 分桶表
2.4.1 分桶表创建
在建表的时指定 CLUSTERED BY,那么这个表就是分桶表。区别于分区表,分桶表将数据分散到多个文件,可以结合 hive 提供的抽样查询,只查询指定桶的数据,另外还可以提高 join 查询效率
分桶原理跟 MR 中的 HashPartitioner 的原理一模一样:
MR:按照key的hash值去模除以reductTask的个数hive:按照分桶字段的hash值去模除以分桶个数,如:1001、1005、1009的hash值是它本身,三个值对分桶个数取模都是 1,1001/1005/1009 % 4 = 1,那么这三条数据会被分在同一个文件中
// col_name 分桶字段
[CLUSTERED BY (col_name, col_name, ...) 分桶的字段,是从表的普通字段中来取
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
示例
1、创建分桶表:
// 创建 4 个桶
create table stu_buck(id int, name string)
clustered by(id)
SORTED BY (id desc)
into 4 buckets
row format delimited fields terminated by '\t';
2、设置强制分桶、排序(必须):
set hive.enforce.bucketing=true; // 需要打开强制分桶开关
set hive.enforce.sorting=true; // 需要打开强制排序开关
3、加载数据:
// 使用 load 方式加载数据,发现并没有分桶,这是因为向分桶表导入数据时,必须运行MR程序,才能实现分桶操作,需要使用 insert 方式插入数据
load data local inpath '/home/hadoop/apps/big_source/files/student.txt' into table stu_buck;
创建临时表,通过查询临时表的方式向分桶表插入数据:
// 1. 从 hdfs 或本地磁盘中 load 数据,导入中间表
create table stu_buck_tmp(id int, name string)
row format delimited fields terminated by '\t';load data local inpath '/home/hadoop/apps/big_source/files/student.txt' into table stu_buck_tmp;// 通过从中间表查询的方式的完成数据导入
insert into table stu_buck select id, name from stu_buck_tmp;
总结
-
向分桶表插入数据会运行
mr程序,需要使用insert来插入数据 -
创建分桶表时,需要打开强制分桶的开关
-
需要确保
reduce的数量与表中的bucket数量一致,有两种方式- 让
hive强制分桶,自动按照分桶表的bucket进行分桶(推荐) - 手动指定
reduce数量,并在SELECT后增加CLUSTER BY语句
set mapreduce.job.reduces = num; set mapreduce.reduce.tasks = num; - 让
2.4.2 抽样查询
对于一个大的数据集来说,有时并不需要查询全部,而是抽样部分有代表性的结果即可
格式:
select * from 分桶表 tablesample(bucket x out of y on 分桶表分桶字段);
参数详解:
-
y:必须是table总bucket(即桶)数目的倍数或者因子,hive会根据y的大小来决定抽样的比例。如:bucket=4,当y=2时,表示抽取(4/2)个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据 -
x:表示从第几个bucket开始抽取,如:bucket=4,tablesample(bucket 1 out of 2),表示总共抽取(4/2=)2个bucket的数据,抽取第1(x)个和第3(x+y)个bucket的数据。
翻译过来就是:从第 x 桶开始抽样,每间隔 y 桶抽一桶,知道抽满 bucket/y 桶
// 从第1桶(0号桶)开始抽,抽第x+y*(n-1),一共抽2桶:0、2 号桶
0: jdbc:hive2://hadoop1:10000> select * from stu_buck tablesample(bucket 1 out of 2 on id);
+--------------+----------------+--+
| stu_buck.id | stu_buck.name |
+--------------+----------------+--+
| 1016 | ss16 |
| 1012 | ss12 |
| 1008 | ss8 |
| 1004 | ss4 |
| 1014 | ss14 |
| 1010 | ss10 |
| 1006 | ss6 |
| 1002 | ss2 |
+--------------+----------------+--+// 从第 1 桶开始抽,抽 4 桶:0、1、2、3 桶
0: jdbc:hive2://hadoop1:10000> select * from stu_buck tablesample(bucket 1 out of 1 on id);
+--------------+----------------+--+
| stu_buck.id | stu_buck.name |
+--------------+----------------+--+
| 1016 | ss16 |
| 1012 | ss12 |
| 1008 | ss8 |
| 1004 | ss4 |
| 1013 | ss13 |
| 1009 | ss9 |
| 1005 | ss5 |
| 1001 | ss1 |
| 1014 | ss14 |
| 1010 | ss10 |
| 1006 | ss6 |
| 1002 | ss2 |
| 1015 | ss15 |
| 1011 | ss11 |
| 1007 | ss7 |
| 1003 | ss3 |
+--------------+----------------+--+// 从第 2 桶开始抽,抽 1 桶,即第 2 桶
0: jdbc:hive2://hadoop1:10000> select * from stu_buck tablesample(bucket 2 out of 4 on id);
+--------------+----------------+--+
| stu_buck.id | stu_buck.name |
+--------------+----------------+--+
| 1013 | ss13 |
| 1009 | ss9 |
| 1005 | ss5 |
| 1001 | ss1 |
+--------------+----------------+--+// 从第 2 桶开始抽,抽 0.5 桶
0: jdbc:hive2://hadoop1:10000> select * from stu_buck tablesample(bucket 2 out of 8 on id);
+--------------+----------------+--+
| stu_buck.id | stu_buck.name |
+--------------+----------------+--+
| 1009 | ss9 |
| 1001 | ss1 |
+--------------+----------------+--+
以下为 4 个桶数据分布:
// 第 1 桶
[hadoop@hadoop1 apps]$ hadoop fs -cat /user/hive/warehouse/stu_buck/000000_0
1016 ss16
1012 ss12
1008 ss8
1004 ss4// 第 2 桶
[hadoop@hadoop1 apps]$ hadoop fs -cat /user/hive/warehouse/stu_buck/000001_0
1013 ss13
1009 ss9
1005 ss5
1001 ss1// 第 3 桶
[hadoop@hadoop1 apps]$ hadoop fs -cat /user/hive/warehouse/stu_buck/000002_0
1014 ss14
1010 ss10
1006 ss6
1002 ss2// 第 4 桶
[hadoop@hadoop1 apps]$ hadoop fs -cat /user/hive/warehouse/stu_buck/000003_0
1015 ss15
1011 ss11
1007 ss7
1003 ss3
注意:x 的值必须小于等于 y 的值
2.5 修改表 & 删除表
重命名表:
ALTER TABLE table_name RENAME TO new_table_name
增加/修改/替换列信息:
// 更新列
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]// 替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...) // 添加一列
alter table dept_partition add columns(deptdesc string);// 更新列
alter table dept_partition change column deptdesc desc int;// 替换列
alter table dept_partition replace columns(deptno string, dname string, loc string);// 改表的属性
alter table 表名 set tblproperties(属性名=属性值)
删除表:
drop table tableName;
truncate table tableName // 清空管理表,只清空数据
3. 错误集锦
1、启动 hive 报错 org.apache.tez.dag.api.SessionNotRunning: TezSession has already shutdown. Application
- 背景:使用
insert往分桶表插入数据时报以上错误 - 原因:
hadoop内存不足 - 解决:调整内存,修改
yarn-site.xml,重启ResourceManager和NodeManager
<property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>3.0</value>
</property>
参考:
- 启动hive报错 org.apache.tez.dag.api.SessionNotRunning: TezSession has already shutdown. Application
- org.apache.tez.dag.api.SessionNotRunning: TezSession has already shutdown. Application application_1
2、更换 tez 引擎后,insert 数据时报错:org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container.
- 原因:
namenode、datanode时间同步问题 - 解决:
datanode与namenode进行时间同步,每个节点都需要执行
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
ntpdate pool.ntp.org
相关文章:

Hive 之 DDL操作
DDL 操作是用于操作对象和对象的属性,这种对象包括数据库本身,以及数据库对象,像:表、视图等等 1. 数据库 1.1 创建数据库 数据库在 HDFS 上的默认存储路径是 /user/hive/warehouse/*.db CREATE (DATABASE|SCHEMA) [IF NOT EX…...
2. SpringMVC 请求与响应
文章目录1. 请求映射路径2. 请求参数2.1 get 请求发送普通参数2.2 post 请求发送普通参数2.3 五种类型的参数传递2.4.1 普通参数2.4.2 POJO 数据类型2.4.3 嵌套 POJO 类型参数2.4.4 数组类型参数2.4.5 集合类型参数3. json 数据传输参数(重点)3.1 传输 j…...

leaflet 读取上传的geojson文件,转换为wkt文件(057)
第057个 点击查看专栏目录 本示例的目的是介绍演示如何在vue+leaflet中上传geojson文件,解析geojson文件并转换为WKT,并在地图上显示图片。 直接复制下面的 vue+openlayers源代码,操作2分钟即可运行实现效果. 文章目录 示例效果配置方式示例源代码(共128行)安装 @terraf…...
)
面试题-前端开发Vue篇(答案超详细)
文章目录 如何实现跨域?JSONP原理和缺点谈谈你对DOM的理解及常用的DOM API说说你对 Vue 的理解说说 Vue 的优缺点什么是虚拟 DOM请描述下 vue 的生命周期是什么vue 如何监听键盘事件?watch 怎么深度监听对象变化删除数组用 delete 和 Vue.delete 有什么区别watch 和计算属性有…...
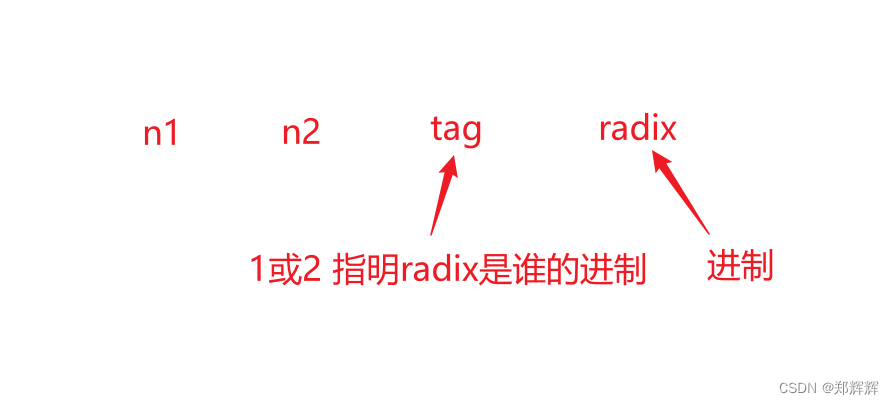
PTA甲级-1010 Radix c++
文章目录Input Specification:Output Specification:Sample Input 1:Sample Output 1:Sample Input 2:Sample Output 2:一、题干大意二、题解要点三、具体实现总结Given a…...

【项目重构】第1次思考
回顾与反思 2022年~至今(2023年2月),一共重构了2个项目。 第1个项目在重构的时候,总是想着把别人的代码copy过来,改一改,这就算重构好了。这样做效率太低,原因是前人写的代码不一定有很多注释…...
Java:SpringMVC的使用(2)
目录第十二章 REST风格CRUD练习12.1 搭建环境12.2 实现功能思路第十三章 SpringMVC消息转换器13.1 消息转换器概述13.2 使用消息转换器处理请求报文(1) 使用RequestBody获取请求体(2) 使用HttpEntity\<T>获取请求体及请求头13.3 使用消息转换器处理响应报文(1) 使用Respo…...
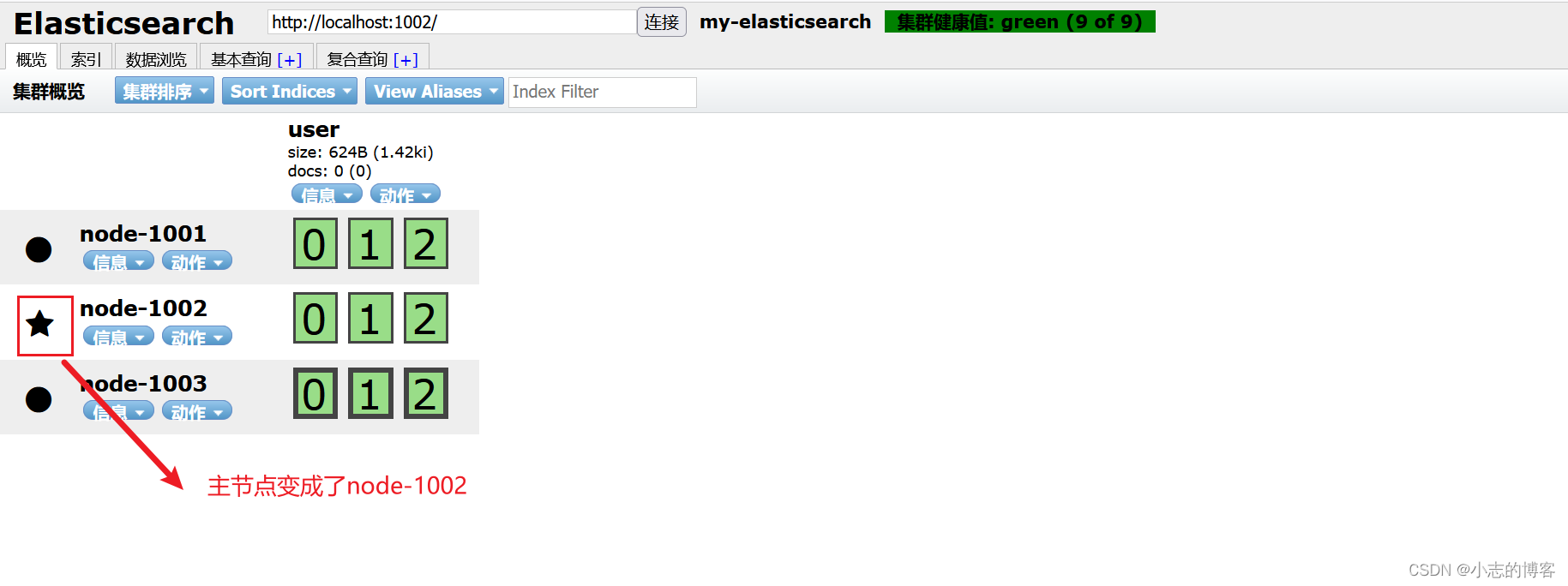
Elasticsearch7.8.0版本进阶——分布式集群(应对故障)
目录一、Elasticsearch集群的安装1.1、Elasticsearch集群的安装(win10环境)1.2、Elasticsearch集群的安装(linux环境)二、应对故障(win10环境集群演示)2.1、启动集群(三个节点)2.2、…...
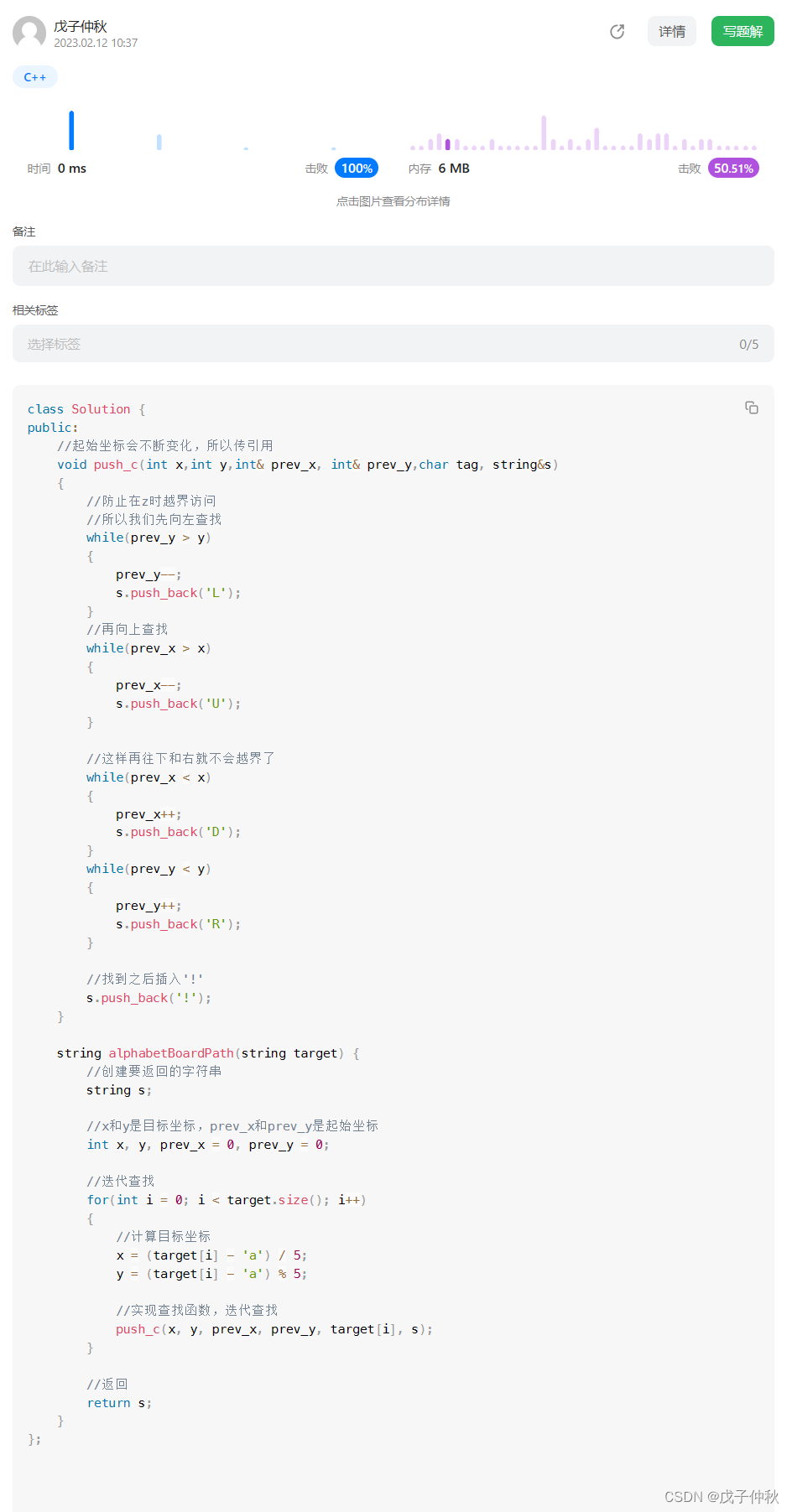
【LeetCode】每日一题(2)
目录 题目:1138. 字母板上的路径 - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 写在最后: 题目:1138. 字母板上的路径 - 力扣&am…...

软件设计师教程(六)计算机系统知识-操作系统知识
软件设计师教程 软件设计师教程(一)计算机系统知识-计算机系统基础知识 软件设计师教程(二)计算机系统知识-计算机体系结构 软件设计师教程(三)计算机系统知识-计算机体系结构 软件设计师教程(…...

Zookeeper下载安装与集群搭建
Zookeeper下载安装与集群搭建1.下载安装1.1 下载安装1.2 配置启动2.集群搭建2.1 搭建要求2.2 准备工作2.3 配置集群2.4 启动集群2.5 模拟集群异常1.下载安装 1.1 下载安装 1、环境准备 ZooKeeper服务器是用Java创建的,它运行在JVM之上。需要安装JDK 7或更高版本。…...
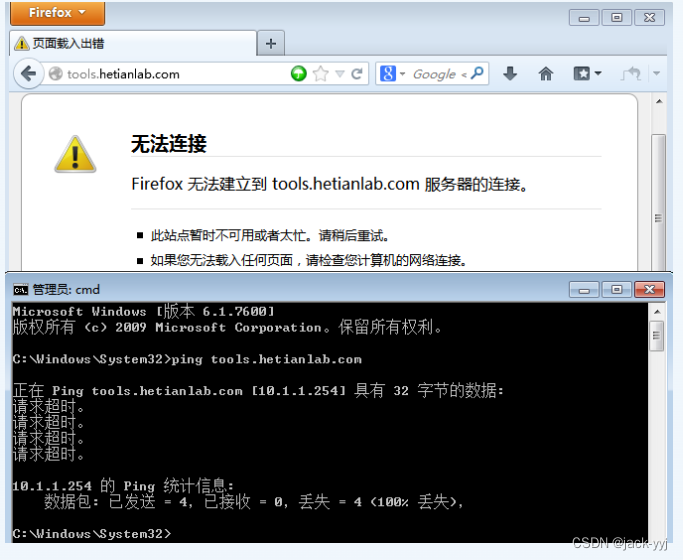
Filter防火墙(8)
实验目的 1、了解个人防火墙的基本工作原理; 2、掌握Filter防火墙的配置。 预备知识防火墙 防火墙(Firewall)是一项协助确保信息安全的设备,会依照特定的规则,允许或是限制传输的数据通过。防火墙可以是一台专属的硬…...

Spring事务的传播级别——包你一文通
文章目录一、简单说明二、具体案例描述2.1.PROPAGATION_REQUIRED2.2.PROPAGATION_REQUIRED_NEW2.3.PROPAGATION_SUPPORTS2.4.PROPAGATION_NOT_SUPPORTED2.5.PROPAGATION_MANDATORY2.6.PROPAGATION_NEVER2.7.PROPAGATION_NESTED三、总结3.1、PROPAGATION_REQUIRED3.2、PROPAGATI…...

C语言(C预编译指令)
目录 1.undef 2.条件编译#ifdef,#else和#endif 3.#ifndef 4.#if和#elif 5.预定义宏 6.#line和#error 7.#pragma 1.undef #undef指令用于取消已定义的#define指令 #define LIMIT 400 #undef LIMIT 如果想使用一个名称但又不确定之前是否已经用过,为了安全起…...

JMeter 接口测试/并发测试/性能测试
Jmter工具设计之初是用于做性能测试的,它在实现对各种接口的调用方面已经做的比较成熟,因此,本次直接使用Jmeter工具来完成对Http接口的测试。因为再做接口测试时可以设置线程组,所以也可做接口性能测试。本篇使用JMeter完成了一个…...
大家心心念念的RocketMQ5.x入门手册来喽
1、前言 为了更好的拥抱云原生,RocketMQ5.x架构进行了大的重构,提出了存储与计算分离的设计架构,架构设计图如下所示: RocketMQ5.x提供了一套非常建议的消息发送、消费API,并统一放在Apache顶级开源项目rocketmq-clie…...
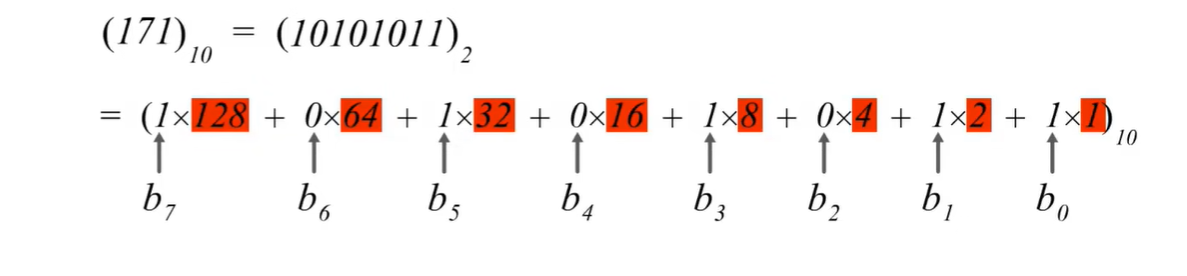
(考研湖科大教书匠计算机网络)第四章网络层-第三节1:IPv4地址概述
获取pdf:密码7281专栏目录首页:【专栏必读】考研湖科大教书匠计算机网络笔记导航 文章目录一:IPv4地址概述二:IPv4地址表示方法(1)概述(2)8位无符号二进制数转十进制正整数ÿ…...

B站Python与OpenCV人脸识别项目超详细记录(对图片、视频、摄像头人脸的检测)
课程来源:一天搞定人脸识别项目!学不会up直接下跪!(pythonopencv)_哔哩哔哩_bilibili 图片来源:感谢王鹤棣先生友情出镜~ 环境配置详见: 在conda虚拟环境中安装OpenCv并在pycharm中使用_cond…...

【Node.js实战】一文带你开发博客项目之Koa2重构(实现session、开发路由、联调、日志)
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,也会涉及到服务端 📃个人状态: 在校大学生一枚,已拿多个前端 offer(秋招) 🚀未…...
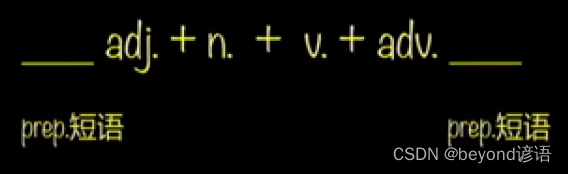
第一部分:简单句——第二章:简单句的补充
简单句的核心构成:一主一谓 主语/宾语/表语 可以变成名词/代词/doing/to do 谓语动词有四种核心变化:三态 一否 时态语态情态否定 简单句的核心:将简单句给写对 简单句的补充:将简单句给写的更好、更充分 简单句的补充 1、限定…...

MicroClaw:跨平台智能体运行时,统一AI助手部署与管理
1. 项目概述:一个跨平台的智能体运行时如果你曾经尝试过在不同的聊天平台上部署AI助手,比如在Telegram上搞一个,又在Discord上搞一个,你大概率会感到头疼。每个平台都有自己的一套API、认证方式和消息格式,这意味着你几…...

ML:SARSA 的基本原理与实现
在强化学习中,智能体(Agent)并不是一次性从已有标签中学习答案,而是在环境(Environment)中不断尝试动作、观察结果、获得奖励,并根据经验逐步调整行为策略。在 Q 学习中,智能体可以通…...

Arm CoreLink CMN-600硬件错误解析与解决方案
1. Arm CoreLink CMN-600硬件错误深度解析在复杂SoC设计中,互连架构的质量直接决定整个系统的稳定性和性能。作为Arm Neoverse平台的核心组件,CoreLink CMN-600(Coherent Mesh Network)承担着处理器集群、内存控制器和I/O设备之间…...

Claude Code与Cursor CLI集成:AI辅助编程工作流优化实践
1. 项目概述:Claude Code与Cursor CLI的桥梁如果你和我一样,日常开发中同时使用Claude Code和Cursor,并且对Composer 2的执行速度印象深刻,那么你很可能也面临过这样的困境:Claude Code在规划、分析和代码审查方面表现…...

信息学奥赛经典回溯:八皇后问题深度解析与OpenJudge实战
1. 八皇后问题:从棋盘游戏到算法经典 第一次接触八皇后问题时,我正在准备信息学奥赛的选拔考试。当时觉得这不过是个棋盘游戏,直到真正动手编码时,才发现其中蕴含的算法智慧远比想象中丰富。这个问题要求在一个8x8的国际象棋棋盘上…...

中国行政区划数据生成器:开发者的地理数据基础设施解决方案
中国行政区划数据生成器:开发者的地理数据基础设施解决方案 【免费下载链接】chinese-address-generator 中国地址生成器 - 三级地址 四级地址 随机生成完整地址 项目地址: https://gitcode.com/gh_mirrors/ch/chinese-address-generator 在现代软件开发过程…...

别再死记公式了!用复平面几何法直观理解Biquad滤波器设计
用复平面几何法直观理解Biquad滤波器设计 当你第一次接触数字滤波器时,那些复杂的差分方程和z变换公式是否让你望而生畏?作为音频处理领域的入门者,我曾花了整整两周时间试图理解一个简单的二阶滤波器公式,直到发现了复平面几何法…...

如何利用WinRAR分卷压缩,轻松突破大文件传输限制
1. 为什么需要分卷压缩? 在日常工作和生活中,我们经常会遇到需要传输大文件的情况。比如设计师要发送PSD源文件给客户,程序员要分享开发环境的镜像,或者普通用户想通过邮件发送高清视频给亲友。但几乎所有主流传输平台都对单个文件…...

容器化技术从入门到精通:Docker与Kubernetes实战指南
1. 项目概述:从零到一构建容器化认知体系最近在技术社区里,经常看到有朋友在讨论“stephrobert/containers-training”这个项目。乍一看,这像是一个关于容器技术的培训或学习资料库。作为一个在云原生和容器化领域摸爬滚打了多年的从业者&…...

避开这些坑:在MATLAB中用DQN做LKA时,我的并行训练为什么失败了?
避开这些坑:在MATLAB中用DQN做LKA时,我的并行训练为什么失败了? 当你第一次在MATLAB中启用UseParalleltrue选项时,可能满怀期待地以为训练速度会直线上升。但现实往往很骨感——要么直接报错终止,要么训练效率反而比串…...