Elasticsearch:使用 Llamaindex 的 RAG 与 Elastic 和 Llama3
这篇文章是对之前的文章 “使用 Llama 3 开源和 Elastic 构建 RAG” 的一个补充。我们可以在本地部署 Elasticsearch,并进行展示。我们将一步一步地来进行配置并展示。你还可以参考我之前的另外一篇文章 “Elasticsearch:使用在本地计算机上运行的 LLM 以及 Ollama 和 Langchain 构建 RAG 应用程序”。

安装
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的链接来进行安装:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Kibana:如何在 Linux,MacOS 及 Windows上安装 Elastic 栈中的 Kibana
在安装的时候,我们选择 Elastic Stack 8.x 来进行安装。特别值得指出的是:ES|QL 只在 Elastic Stack 8.11 及以后得版本中才有。你需要下载 Elastic Stack 8.11 及以后得版本来进行安装。
在首次启动 Elasticsearch 的时候,我们可以看到如下的输出:
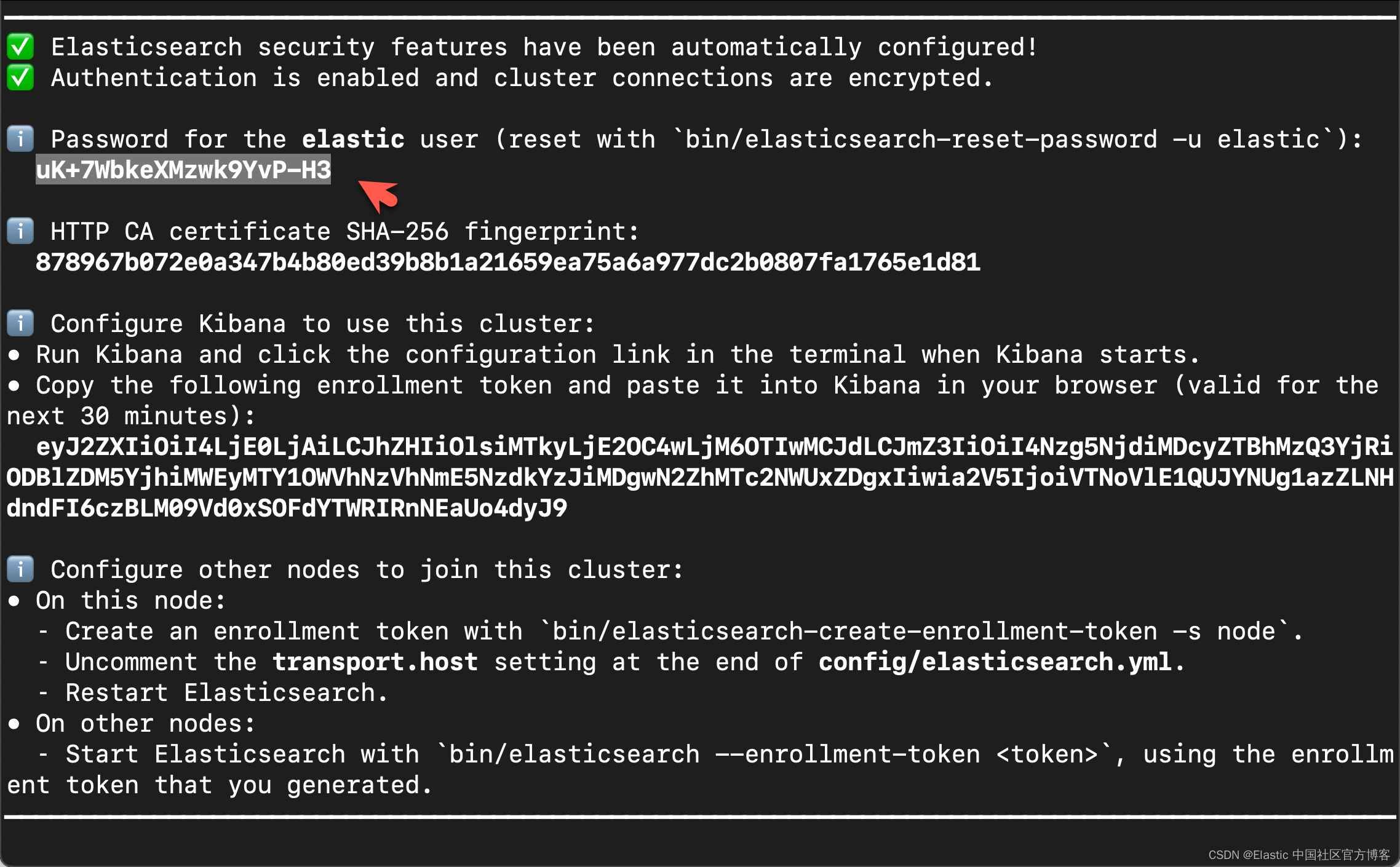
在上面,我们可以看到 elastic 超级用户的密码。我们记下它,并将在下面的代码中进行使用。
我们还可以在安装 Elasticsearch 目录中找到 Elasticsearch 的访问证书:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.14.1/config/certs
$ ls
http.p12 http_ca.crt transport.p12在上面,http_ca.crt 是我们需要用来访问 Elasticsearch 的证书。
我们首先克隆已经写好的代码:
git clone https://github.com/liu-xiao-guo/elasticsearch-labs我们然后进入到该项目的根目录下:
$ pwd
/Users/liuxg/python/elasticsearch-labs/notebooks/integrations/llama3
$ ls
README.md rag-elastic-llama3-elser.ipynb rag-elastic-llama3.ipynb
如上所示,rag-elastic-llama3.ipynb 就是我们今天想要工作的 notebook。
我们通过如下的命令来拷贝所需要的证书:
$ pwd
/Users/liuxg/python/elasticsearch-labs/notebooks/integrations/llama3
$ cp ~/elastic/elasticsearch-8.14.1/config/certs/http_ca.crt .
$ ls
README.md rag-elastic-llama3-elser.ipynb
http_ca.crt rag-elastic-llama3.ipynb安装所需要的 python 依赖包
pip3 install llama-index llama-index-cli llama-index-core llama-index-embeddings-elasticsearch llama-index-embeddings-ollama llama-index-legacy llama-index-llms-ollama llama-index-readers-elasticsearch llama-index-readers-file llama-index-vector-stores-elasticsearch llamaindex-py-client python-dotenv elasticsearch[async]我们可以通过如下的命令来查看 elasticsearch 安装包的版本:
$ pip3 list | grep elasticsearch
elasticsearch 8.14.0
llama-index-embeddings-elasticsearch 0.1.2
llama-index-readers-elasticsearch 0.1.4
llama-index-vector-stores-elasticsearch 0.2.0创建环境变量
为了能够使得下面的应用顺利执行,在项目当前的目录下运行如下的命令:
export ES_ENDPOINT="localhost"
export ES_USER="elastic"
export ES_PASSWORD="uK+7WbkeXMzwk9YvP-H3"配置 Ollama 和 Llama3
由于我们使用 Llama 3 8B 参数大小模型,我们将使用 Ollama 运行该模型。按照以下步骤安装 Ollama。
- 浏览到 URL https://ollama.com/download 以根据你的平台下载 Ollama 安装程序。
在我的电脑上,我使用 macOS 来进行安装。你也可以仿照文章 “Elasticsearch:使用在本地计算机上运行的 LLM 以及 Ollama 和 Langchain 构建 RAG 应用程序” 在 docker 里进行安装。
- 按照说明为你的操作系统安装和运行 Ollama。
- 安装后,按照以下命令下载 Llama3 模型。
点击上面的 “Finish” 按钮,并按照上面的提示在 terminal 中运行:
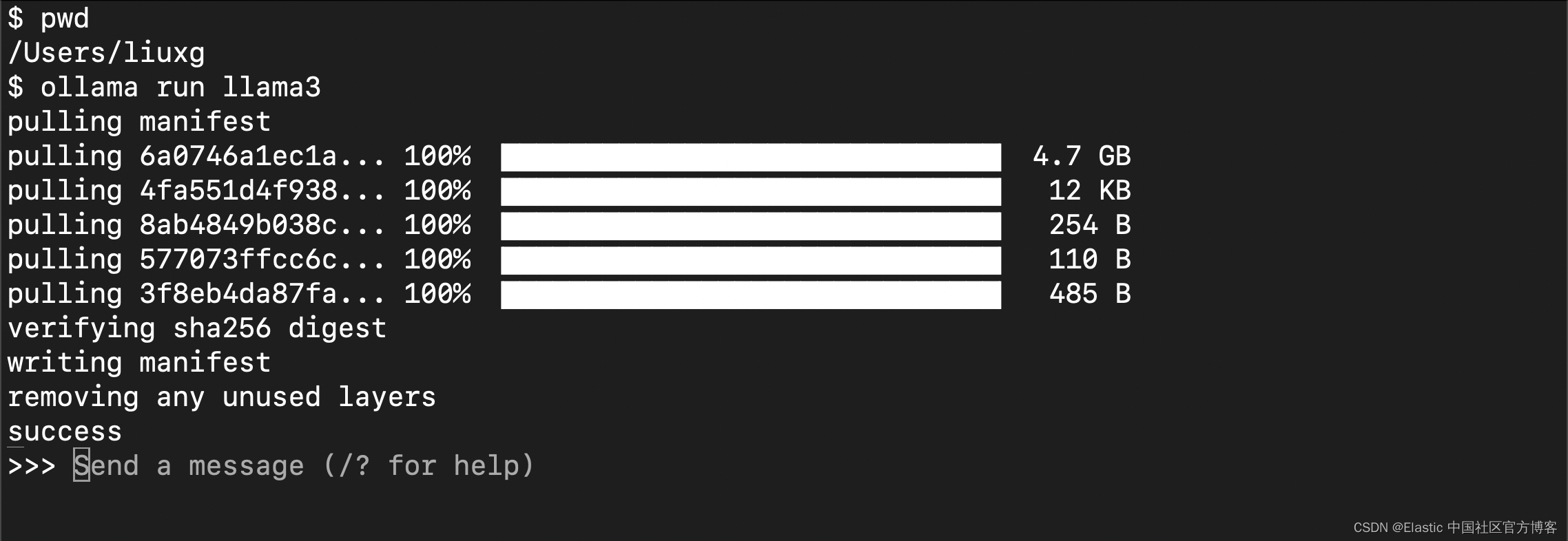
这可能需要一些时间,具体取决于你的网络带宽。运行完成后,你将看到如上的界面。
要测试 Llama3,请从新终端运行以下命令或在提示符下输入文本。
curl -X POST http://localhost:11434/api/generate -d '{ "model": "llama3", "prompt":"Why is the sky blue?" }'
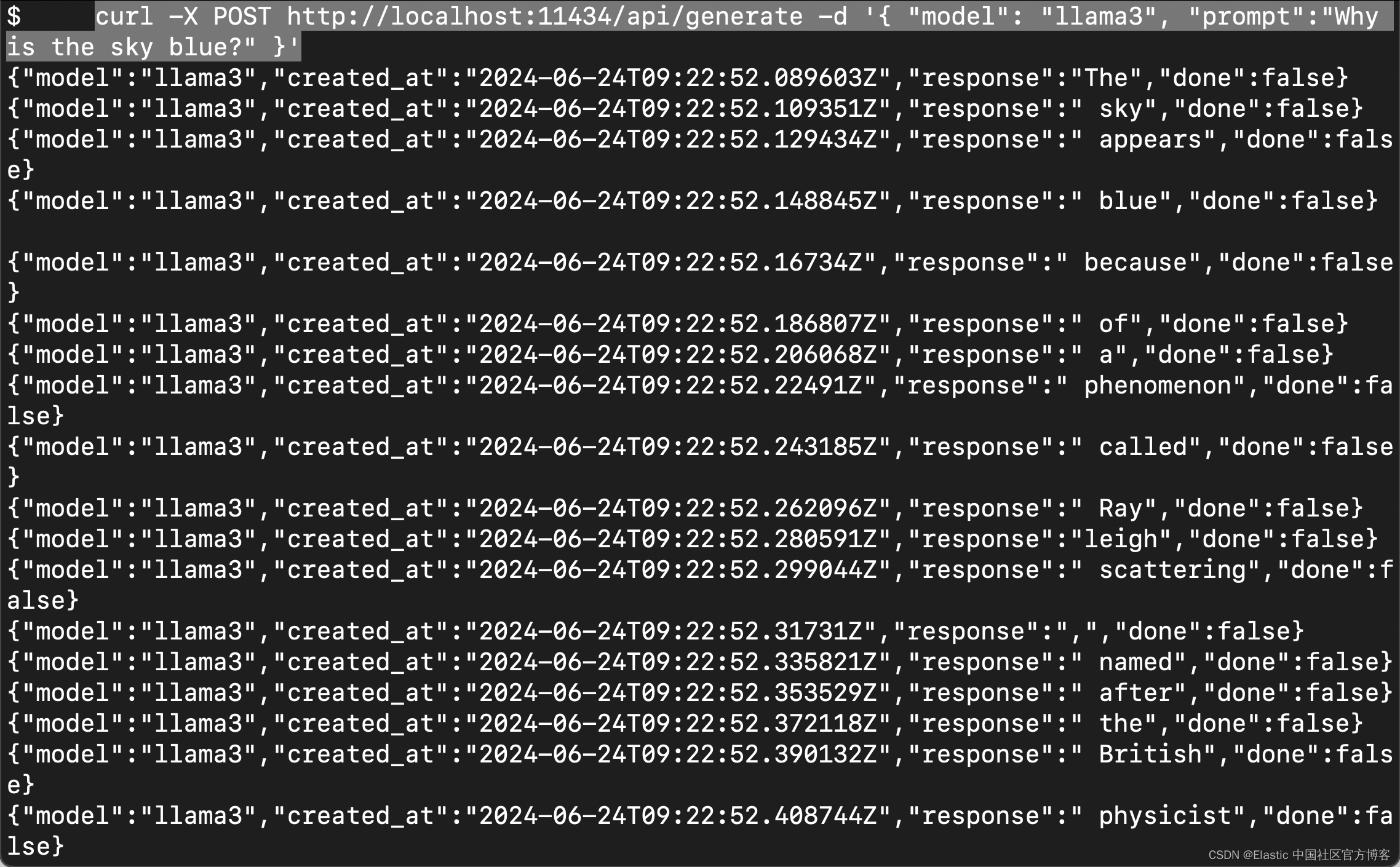
在提示符下,输出如下所示。
我们现在使用 Ollama 在本地运行 Llama3。
下载数据集文档
我们可以使用如下的命令来下载文档:
wget https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json$ pwd
/Users/liuxg/python/elasticsearch-labs/notebooks/integrations/llama3
$ ls
README.md rag-elastic-llama3-elser.ipynb
http_ca.crt rag-elastic-llama3.ipynb
$ wget https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json
--2024-06-25 10:54:01-- https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.110.133
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.110.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 52136 (51K) [text/plain]
Saving to: ‘workplace-documents.json’workplace-documents.jso 100%[=============================>] 50.91K 260KB/s in 0.2s 2024-06-25 10:54:02 (260 KB/s) - ‘workplace-documents.json’ saved [52136/52136]$ ls
README.md rag-elastic-llama3-elser.ipynb workplace-documents.json
http_ca.crt rag-elastic-llama3.ipynb展示
我们在项目当前的目录下打入如下的命令:
jupyter notebook rag-elastic-llama3.ipynb读入变量并连接到 Elasticsearch
from elasticsearch import Elasticsearch, AsyncElasticsearch, helpers
from dotenv import load_dotenv
import osload_dotenv()ES_USER = os.getenv("ES_USER")
ES_PASSWORD = os.getenv("ES_PASSWORD")
ES_ENDPOINT = os.getenv("ES_ENDPOINT")
COHERE_API_KEY = os.getenv("COHERE_API_KEY")url = f"https://{ES_USER}:{ES_PASSWORD}@{ES_ENDPOINT}:9200"
print(url)client = AsyncElasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)
info = await client.info()
print(info)
从上面的输出中,我们可以看到已经成功地连接到 Elasticsearch 了。
注意:在上面我们使用了 AsyncElasticsearch 而不是 Elasticsearch。这个是由于下面的一个 Ollama 调用所需要的。详细情况,请参阅帖子。
准备文档以进行分块和提取
我们现在准备使用 Llamaindex 进行处理的 Document 类型的数据。我们先读入文件:
import json
# from urllib.request import urlopen
from llama_index.core import Document# url = "https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/workplace-documents.json"# response = urlopen(url)
# workplace_docs = json.loads(response.read())import json# Load data into a JSON object
with open('workplace-documents.json') as f:workplace_docs = json.load(f)# Building Document required by LlamaIndex.
documents = [Document(text=doc["content"],metadata={"name": doc["name"],"summary": doc["summary"],"rolePermissions": doc["rolePermissions"],},)for doc in workplace_docs
]在 LlamaIndex 中定义 Elasticsearch 和提取管道以进行文档处理。使用 Llama3 生成嵌入。
我们现在使用所需的索引名称、文本字段及其相关嵌入来定义 Elasticsearchstore。我们使用 Llama3 生成嵌入。我们将在索引上运行语义搜索,以查找与用户提出的查询相关的文档。我们将使用 Llamaindex 提供的 SentenceSplitter 对文档进行分块。所有这些都作为 Llamaindex 框架提供的 IngestionPipeline 的一部分运行。
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.vector_stores.elasticsearch import ElasticsearchStorees_vector_store = ElasticsearchStore( index_name="workplace_index",es_url = url, es_client = client, vector_field="content_vector",text_field = "content",es_user = ES_USER,es_password = ES_PASSWORD)# Embedding Model to do local embedding using Ollama.
ollama_embedding = OllamaEmbedding("llama3")
# LlamaIndex Pipeline configured to take care of chunking, embedding
# and storing the embeddings in the vector store.
pipeline = IngestionPipeline(transformations=[SentenceSplitter(chunk_size=512, chunk_overlap=100),ollama_embedding,],vector_store=es_vector_store,
)执行管道
这将对数据进行分块,使用 Llama3 生成嵌入并将其提取到 Elasticsearch 索引中,并将嵌入到密集向量字段中。
pipeline.run(show_progress=True, documents=documents)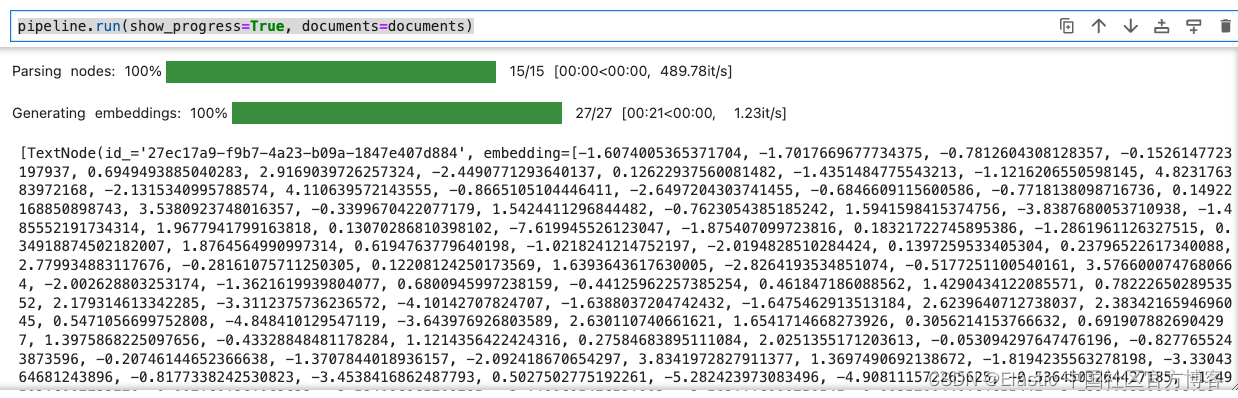
嵌入存储在维度为 4096 的密集向量场中。维度大小来自于从 Llama3 生成的嵌入的大小。
定义 LLM 设置。
这将连接到您的本地 LLM。有关在本地运行 Llama3 的步骤的详细信息,请参阅 https://ollama.com/library/llama3。
如果你有足够的资源(至少 >64 GB 的 RAM 和 GPU 可用),那么你可以尝试 70B 参数版本的 Llama3
from llama_index.llms.ollama import Ollama
from llama_index.core import SettingsSettings.embed_model = ollama_embedding
local_llm = Ollama(model="llama3")设置语义搜索并与 Llama3 集成
我们现在将 Elasticsearch 配置为 Llamaindex 查询引擎的向量存储。然后使用 Llama3 的查询引擎通过来自 Elasticsearch 的上下文相关数据回答你的问题。
from llama_index.core import VectorStoreIndex, QueryBundleindex = VectorStoreIndex.from_vector_store(es_vector_store)
query_engine = index.as_query_engine(local_llm, similarity_top_k=10)# Customer Query
query = "What are the organizations sales goals?"
bundle = QueryBundle(query_str=query, embedding=Settings.embed_model.get_query_embedding(query=query)
)response = query_engine.query(bundle)print(response.response)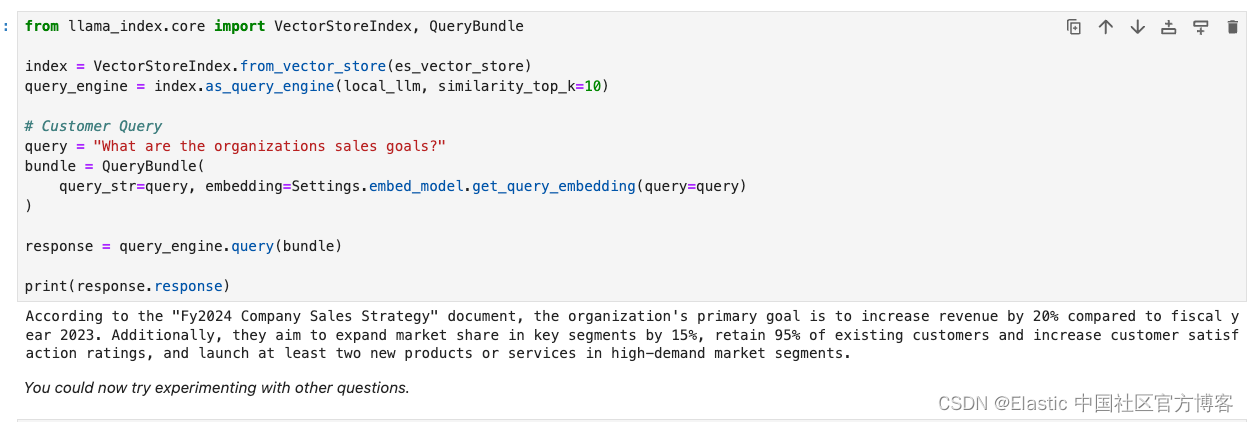
所有的代码可以在地址下载:elasticsearch-labs/notebooks/integrations/llama3/rag-elastic-llama3.ipynb at main · liu-xiao-guo/elasticsearch-labs · GitHub
相关文章:
Elasticsearch:使用 Llamaindex 的 RAG 与 Elastic 和 Llama3
这篇文章是对之前的文章 “使用 Llama 3 开源和 Elastic 构建 RAG” 的一个补充。我们可以在本地部署 Elasticsearch,并进行展示。我们将一步一步地来进行配置并展示。你还可以参考我之前的另外一篇文章 “Elasticsearch:使用在本地计算机上运行的 LLM 以…...
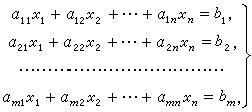
AcWing算法基础课笔记——高斯消元
高斯消元 用来求解方程组 a 11 x 1 a 12 x 2 ⋯ a 1 n x n b 1 a 21 x 1 a 22 x 2 ⋯ a 2 n x n b 2 … a n 1 x 1 a n 2 x 2 ⋯ a n n x n b n a_{11} x_1 a_{12} x_2 \dots a_{1n} x_n b_1\\ a_{21} x_1 a_{22} x_2 \dots a_{2n} x_n b_2\\ \dots \\ a…...

【JavaScript脚本宇宙】图形魔术:探索领先的图像处理库及其独特功能
深入了解HTML5视频:最受欢迎的库及其功能 前言 图像处理是现代数字媒体开发中不可或缺的一部分,从调整图像大小到创建复杂的图形场景。有许多库可用,每个库都有其特定的优点和适用场景。在本文中,我们将探讨六种流行的图像处理库…...

Nemotron-4
Nemotron-4是英伟达(NVIDIA)发布的一系列高级人工智能模型,特别着重于大尺度语言模型(LLMs)的发展。这些模型在不同的参数量级上展现出了卓越的性能和效率,其中特别提到了150亿参数的Nemotron-4 15B和3400亿…...

【神经网络】神经元的基本结构和训练过程
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步! 神经元的基本结构和训练过程 …...
第28课 绘制原理图——绘制导线
概述 放置完元器件之后,接着就要用导线将元器件的管脚一个一个连起来了。 绘制导线的方法 点击快速工具条上的“线”命令,进入绘制导线的过程。 点击选择某个管脚或电源端口,作为导线的起始端。 再点击选择另一个管脚或电源端口,…...

NLP 相关知识
NLP 相关知识 NLPLLMPrompt ChainingLangChain NLP NLP(Natuarl Language Processing)是人工智能的一个分支,中文名自然语言处理,专注于处理和理解人类使用的自然语言。它涵盖了多个子领域,如文本分类、情感分析、机器…...

Java中的设计模式:实战案例分享
Java中的设计模式:实战案例分享 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 设计模式是软件开发中的宝贵工具,它们为常见的问题提供…...
并发编程理论基础——合适的线程数量和安全的局部变量(十)
多线程的提升方向 主要方向在于优化算法和将硬件的性能发挥到极致想要发挥出更多的硬件性能,最主要的就是提升I/O的利用率和CPU的利用率以及综合利用率操作系统已经解决了磁盘和网卡的利用率问题,利用中断机制还能避免 CPU 轮询 I/O 状态,也提…...

Python使用抽象工厂模式和策略模式的组合实现生成指定长度的随机数
设计模式选择理由: 抽象工厂模式: 抽象工厂模式适合于创建一组相关或依赖对象的场景。在这里,我们可以定义一个抽象工厂来创建不同类型(数字、字母、特殊符号)的随机数据生成器。 策略模式: 策略模式允许你…...

python-17-零基础自学python-
学习内容:《python编程:从入门到实践》第二版 知识点: 类、子类、继承、调用函数 练习内容: 练习9-6:冰激凌小店 冰激凌小店是一种特殊的餐馆。编写一个名为IceCreamStand的类,让它继承为完成练习9-1或…...

Web应用和Tomcat的集成鉴权1-BasicAuthentication
作者:私语茶馆 1.Web应用与Tomcat的集成式鉴权 Web应用部署在Tomcat时,一般有三层鉴权: (1)操作系统鉴权 (2)Tomcat容器层鉴权 (3)应用层鉴权 操作系统层鉴权包括但不限于:Tomcat可以和Windows的域鉴权集成,这个适合企业级的统一管理。也可以在Tomcat和应用层独立…...

解决Linux下Java应用因内存不足而崩溃的问题
在Linux系统中运行内存密集型的Java应用时,经常会遇到因系统内存不足而导致应用崩溃的问题。本文将探讨如何诊断这类问题以及提供有效的解决方案。 问题诊断 首先,使用 free -h 命令查看系统的内存使用情况,得到以下输出: total…...
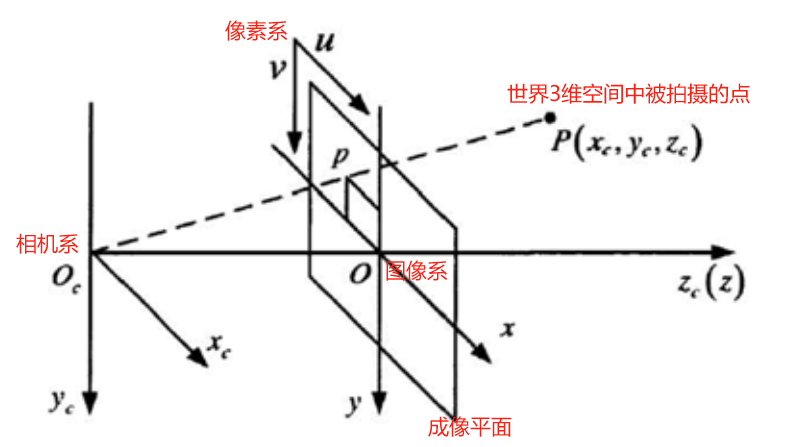
ardupilot开发 --- 视觉伺服 篇
风驰电掣云端飘,相机无法对上焦 1.视觉伺服分类2.视觉伺服中的坐标系3.成像模型推导4.IBVS理论推导5.IBVS面临的挑战6.visp 实践参考文献 1.视觉伺服分类 控制量是在图像空间中推导得到还是在欧式空间中推导得到,视觉伺服又可以分类为基于位置(PBVS)和基…...

KVM配置嵌套虚拟化
按照以下步骤启用、配置和开始使用嵌套虚拟化,默认情况下禁用该功能,要启用它,请在宿主机物理机上进行配置。在centos stream 9和ubuntu 22部署kvm默认支持虚拟机嵌套虚拟化。 1、英特尔 1.1检查嵌套虚拟化在您的主机系统上是否可用 $cat /sys/module/kvm_intel/paramete…...

Springboot应用的信创适配-补充
Springboot应用的信创适配-CSDN博客 因为篇幅限制,这里补全Spring信创适配、数据库信创适配、Redis信创适配、消息队列信创适配等四个章节。 Springboot应用的信创适配 Springboot应用的信创适配,如上图所示需要适配的很多,从硬件、操作系统、…...

制图工具(14)导出图层字段属性信息表
在制图工具(13)地理数据库初始化工具中我们提到,有一个参数为:“输入Excel表”,并要求表格中的图层字段属性项需要按工具的帮助文档中的示例进行组织… 如下图: 此外,总有那个一个特别的需求&am…...

代码随想录——买股票的最佳时机Ⅱ(Leecode122)
添加链接描述 贪心 局部最优:手机每天的正利润 全局最优:求最大利润 class Solution {public int maxProfit(int[] prices) {int res 0;for(int i 1; i < prices.length; i){res Math.max(prices[i] - prices[i - 1], 0);}return res;} }...
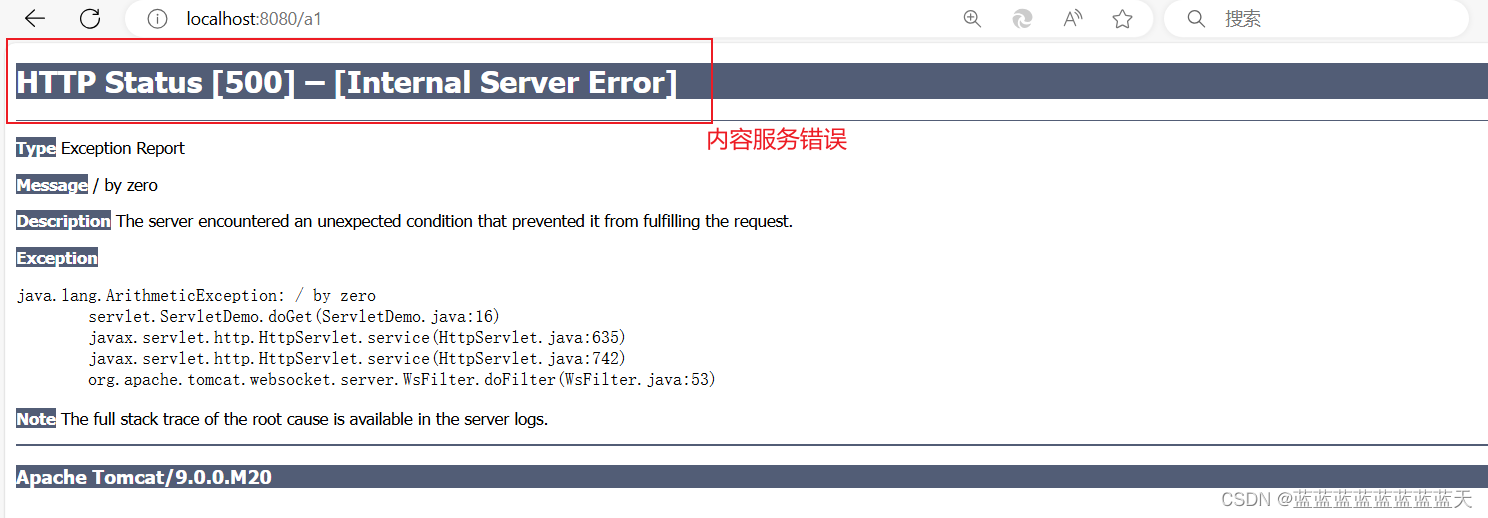
使用Servlet开发javaweb,请求常见错误详解及其解决办法【404、405、500】
Servlet报错的情况多种多样,涵盖了配置错误、代码逻辑错误、资源未找到、权限问题等多个方面。以下是一些常见的Servlet报错情况及其可能的原因和解决方法: 404 Not Found: 错误原因图示: URL映射 发送请求,出现404错误 原因: 请…...
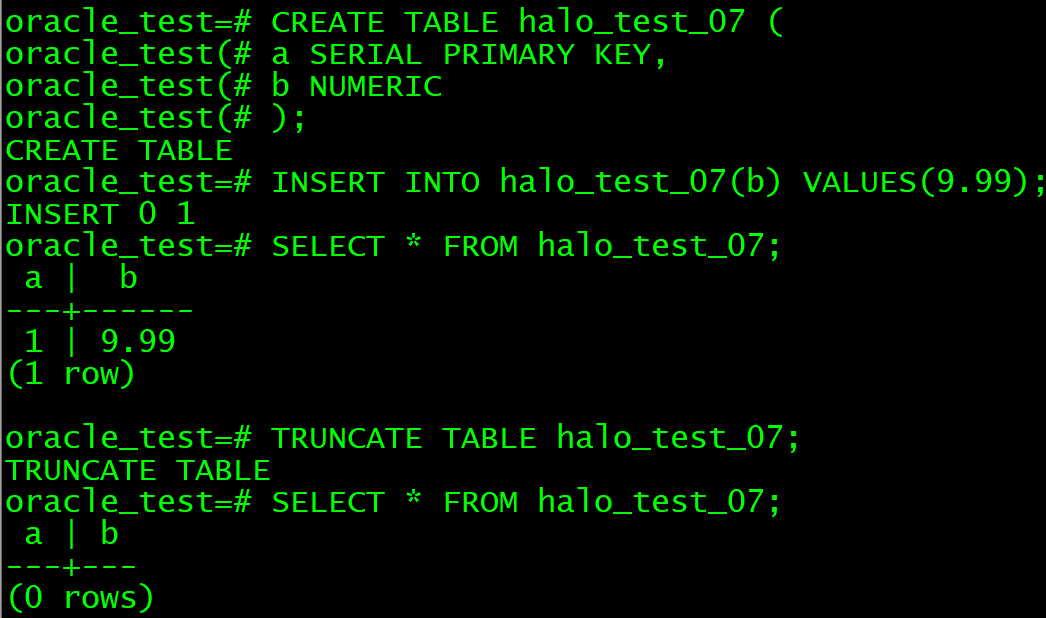
数据库管理-第210期 HaloDB-Oracle兼容性测试02(20240622)
数据库管理210期 2024-06-22 数据库管理-第210期 HaloDB-Oracle兼容性测试02(20240622)1 表增加列2 约束3 自增列4 虚拟列5 表注释6 truncat表总结 数据库管理-第210期 HaloDB-Oracle兼容性测试02(20240622) 作者:胖头…...

HS2-HF Patch:为《Honey Select 2》注入新生命的魔法补丁
HS2-HF Patch:为《Honey Select 2》注入新生命的魔法补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是不是曾经打开《Honey Select 2》时&am…...

5分钟快速掌握Windows右键菜单终极管理神器ContextMenuManager
5分钟快速掌握Windows右键菜单终极管理神器ContextMenuManager 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是不是经常在右键文件时,面对几十个…...

基于RP2040与CircuitPython的HDMI倒计时器:RTC与DVI原生输出实践
1. 项目概述与核心价值如果你手头有一块带HDMI输出的微控制器开发板,比如Adafruit的Feather RP2040 DVI,又恰好需要一个能摆在桌面上、精确到秒的倒计时器,那么今天这个项目就是为你量身定做的。它不仅仅是一个简单的“Hello World”式显示应…...

基于WLED分段功能与激光切割的多层智能艺术灯板制作全攻略
1. 项目概述与核心价值如果你和我一样,对那种能随着音乐呼吸、或者能独立变换不同区域色彩的智能灯光装置着迷,那么你一定会喜欢这个项目。它远不止是把LED灯条粘在板子后面那么简单,而是将激光切割的精密工艺、分层的艺术设计,与…...
)
ElevenLabs克隆成功率从31%飙升至96.7%:基于LPC共振峰校准+Prosody Transfer双引擎微调法(实测数据包已脱敏上传)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs语音克隆方法概览 ElevenLabs 提供了高保真、低延迟的语音克隆能力,其核心依赖于少量高质量语音样本(通常 1–3 分钟)与上下文感知的零样本/少样本微调技术…...

量子最优控制中的iLQR算法实践与优化
1. 量子最优控制基础与挑战量子最优控制(Quantum Optimal Control, QOC)是现代量子计算中的核心技术,其核心目标是通过精心设计的控制脉冲序列,实现对量子系统状态演化的精确操控。在超导量子计算体系中,这一技术尤为重…...

告别玄学调试:用英飞凌TC37X/TC38X的DSADC做旋变软解码,这些配置坑你别再踩了
英飞凌TC37X/TC38X DSADC旋变解码实战避坑指南 从实验室到产线:那些DSADC配置中容易忽视的细节 在新能源汽车电机控制领域,旋转变压器(Resolver)作为位置传感器的主力军,其解码稳定性直接决定了矢量控制的精度。英飞凌…...

基于ESP32-S2与MAX17048的物联网电池监控系统设计与实现
1. 项目概述与核心价值 对于任何一个需要长期部署在户外的物联网设备,比如环境监测站、智能农业传感器或者远程摄像头,最让人头疼的问题往往不是代码bug,而是“它什么时候会没电?”。你不可能天天跑现场去检查,而设备…...

锂电池安全使用指南:从原理到实践,避免常见风险
1. 项目概述:从“能用”到“用好”的锂电安全课如果你玩过任何需要脱离电源线工作的电子项目,无论是给一个Arduino小车供电,还是驱动一架四轴飞行器,最终都绕不开一个核心问题:电源。从最基础的碱性电池,到…...

ROFL-Player:终极免费英雄联盟回放播放器解决方案
ROFL-Player:终极免费英雄联盟回放播放器解决方案 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player ROFL-Player是一款专门为《…...