MySQL索引,事务
一.MySQL索引介绍
索引是一个排序的列表,在这个列表中存储着索引的值和包含这个值的数据所在行的物理地址。在数据十分大的时候,索引可以大大加快查询的速度。这是因为使用索引后可以不用扫描全表来定位某行的数据,而是先通过索引表找到该行数据对应的物理地址然后访问相应的数据。索引的作用类似于图书的目录,可以根据目录中的页码快速找到所需的内容。
1.概述
当数据保存在磁盘类存储介质上时,它是作为数据块存放。这些数据块是被当作一个整体来访问的,这样可以保证操作的原子性。硬盘数据块存储结构类似于链表,都包含数据部分,以及一个指向下一个节点(或数据块)的指针,不需要连续存储。
记录集只能在某个关键字段上进行排序,所以如果需要在一个无序字段上进行搜索,就要执行一个线性搜索(LinearSearch)的过程,平均需要访问N/2的数据块,N是表示所占据的数据块数日。如果这个字段是一个非主键字段(也就是说,不包含唯一的访问入口)那么需要在N个数据块上搜索整个表格空间
但是对于一个有序字段,可以运用二分查找(BinarySearch),这样只需要访间log2(N)的数据块。这就是为什么数据表使用索引后性能可以得到本质上提高的原因。
素引是对记录集的多个字段进行排序的方法。在一张表中为一个字段创建一个索引,将创建另外一个数据结构,包含字段数值以及指向相关记录的指针,然后对这个索引结构进行排序,允许在该数据上进行二分法排序。
使用索引的副作用是需要额外的磁盘空间。对于MyISAM引而言,这些索引是被统一保存在一张表中的。如果很多字段都建立了索引,那么会占用大量的磁盘空间,这个文件将很快到达底层文件系统所能够支持的大小限制
2.索引作用
- 设置了合适的索引之后,数据库利用各种快速定位技术,能够大大加快查询速度,这是创建索引的最主要的原因。
- 当表很大或查询涉及到多个表时,使用索引可以成千上万倍地提高查询速度。
- 可以降低数据库的IO成本,并且索引还可以降低数据库的排序成本。
- 通过创建唯一性索引,可以保证数据表中每一行数据的唯一性。
- 可以加快表与表之间的连接。
- 在使用分组和排序时,可大大减少分组和排序的时间。
3.索引分类
从物理存储的角度来划分,索引分为聚族索引和非聚族索引两种,聚族索引是按照数据存放的物理位置为顺序的,而非聚族索引就不一样了;聚索引能提高多行检索的速度,而非聚族索引对于单行的检索更快
从逻辑的角度来划分,索引分为普通索引、唯一索引、主键索引、组合索引和全文索引。
(1)普通索引
普通索引是最基本的索引,它没有任何限制,也是大多数情况下用到的索引。
创建普通索引
mysql> create index index_name on users(user_name(20));
备注:index索引,on后面跟要创建索引的表名,表名括号内跟该表内标准型字段名以及它的字符长度。
修改表格式添加索引
alter table 表名 add index 索引名(用于索引的字段)创建表结构时,同时创建索引
CREATE TABLE table01 (
id int(11) NOT NULL AUTO_INCREMENT ,
title char(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,
content text CHARACTER SET utf8 COLLATE utf8_general_ci NULL ,
time int(10) NULL DEFAULT NULL ,
PRIMARY KEY (id),
INDEX index_table01_title (title(11))
);(2)唯一索引
唯一索引与普通索引类似,不同的就是:唯一索引的索引列的值必须唯一,但允许有空值(注意和主键不同)。如果是组合索引,则列值的组合必须唯一。唯一索引创建方法和普通索引类似。
创建唯一索引
create unique index 索引名 on 表名(索引字段(长度));修改表结构的时候添加唯一索引
alter table 表名 add unique 索引名(索引字段(长度))创建表的时候同时创建唯一索引
create table 表名 (
id int(10),
name char(20),
pwd char(50),
unique index 索引名(ip)
);(3)主键索引
主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引。
create table t2(
id int(10),
name char(20),
age char(2),
pwd char(50),
primary key (id)
);(4)组合索引(最左前缀)
平时用的SQL查询语句一般都有比较多的限制条件,所以为了进一步榨取MySQL的效率,就要考虑建立组合索引。在组合索引的创建中,有两种场景,即为单列索引和多列索引。下面通过一个场景来具体说明单列索引和多列索引
在一个user用户表中,有name,age,sex三个字段,分别分三次建立了INDEX普通索引。那么在select * from user where name="" AND age="" AND sex="";数据查询语句中就会分别检索三条索引,虽然扫描效率有所提升,但却还未达到最优。这个时候就需要使用到组合索引(即多列索引)
create table user(
name char(20),
age int(3),
sex tinyint(1),
index user(name,age,sex)
);在MySQL中,有一个知识点叫最左原则。下面的select语句的where条件是依次从左往右执行的。
select * from user where name="" and age="" and sex="";若使用的是组合索引index user(name,age,sex)。在查询中,name,age,sex的顺序必须如组合索引中一致排序,否则索引将不会生效,所以一般在建立索引时,要先想好响应的查询业务,尽量避免虽然有索引,但是使用不上的问题。
(5)全文索引
对于较大的数据集,将资料输入一个没有FULLTEXT索引的表中,然后创建索引,其速度比把资料输入现在FULLTEXT索引的速度更快。不过切记对于大容量的数据表,生成全文索引是一个非常消耗时间,非常消耗硬盘空间的做法。
创建表的全文索引语法
CREATE TABLE table (
id int(11) NOT NULL AUTO_INCREMENT ,
title char(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,
content text CHARACTER SET utf8 COLLATE utf8_general_ci NULL ,
time int(10) NULL DEFAULT NULL ,
PRIMARY KEY (id),
FULLTEXT (content)
);修改表结构添加全文索引:
ALTER TABLE article ADD FULLTEXT index_content(content);直接创建索引语法:
mysql>CREATE FULLTEXT INDEX index_content ON article(content);4.创建索引的原则依据
数据库建立索引的原则:
- 确定针对该表的操作是大量的查询操作还是大量的增删改操作;
- 尝试建立索引来帮助特定的查询。检查自己的 sql 语句,为那些频繁在 where 子句中出现的字段建立索引;
- 尝试建立复合索引来进一步提高系统性能。修改复合索引将消耗更长时间,同时复合索引也占磁盘空间;
- 对于小型的表,建立索引可能会影响性能;
- 应该避免对具有较少值的字段进行索引;
- 避免选择大型数据类型的列作为索引。
索引建立的原则:
索引查询是数据库中重要的记录查询方法,要不要建立索引以及在那些字段上建立索引都要和实际数据库系统的查询要求结合来考虑,下面给出实际生产环境中的一些通用的原则:
- 表的主键、外键必须有索引。因为主键具有唯一性,外键关联的是子表的主键,查询时可以快速定位。
- 记录数超过300行的表应该有索引。如果没有索引,需要把表遍历一遍,会严重影响数据库的性能。
- 经常与其他表进行连接的表,在连接字段上应该建立索引。
- 唯一性太差的字段不适合建立索引。
- 更新太频繁地字段不适合创建索引。
- 经常出现在 where 子句中的字段,特别是大表的字段,应该建立索引。索引应该建在选择性高的字段上。
- 索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引。
5.查看索引
查看索引的方法有三个:
- show create table 表名;
- show index from 表名;
- show keys tables 表名;
6.删除索引
索引的删除方法有两种:
- drop index 索引名 on 表名;
- alter table 表名 drop index 索引名;
二.MySQL事务
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,要删除一个人员,即需要删除人员的基本资料,又需要删除和该人员相关的信息,如信箱,文章等等。这样,这些数据库操作语句就构成一个事务。
在MySQL中只有使用了Innodb数据库引擎的数据库或表才支持事务。
事务处理可以用来维护数据库的完整性,保证成批的SQL语句要么全部执行,要么全部不执行。
是一个不可分割的工作逻辑单元,在数据库系统上执行并发操作时,事务是最小的控制单元
适用于多用户同时操作的数据库系统的场景,如银行、保险公司及证券交易系统等
一般来说事务是必须满足4个条件:原子性(不可分割性),一致性,隔离性,持久性。
-
原子性(Atomicity)
- 一个事务中的所有操作被视为一个单独的工作单元,即不可分割。这意味着事务中的所有操作要么全部成功完成,要么全部失败回滚,不会出现只完成部分操作的情况。
- 如果事务在执行过程中发生错误或被中断,系统将撤销事务中已经执行的所有操作,将数据库状态回滚到事务开始前的状态,以确保数据的一致性和完整性。
-
一致性(Consistency)
- 在事务开始之前和事务结束以后,数据库的完整性没有被破坏。
- 这意味着事务必须使数据库从一个一致性状态转换到另一个一致性状态。换句话说,事务的执行不会破坏数据的完整性和业务规则。
- 例如,在一个转账操作中,从一个账户扣除的金额必须等于在另一个账户中添加的金额,以确保账户总金额的一致性。
-
隔离性(Isolation)
- 事务在并发执行时,彼此之间是不可见的,即一个事务的执行不能被其他事务所干扰。
- 数据库允许多个并发事务同时对其数据进行读写和修改,但隔离性确保了这些操作之间的独立性。一个事务对数据的修改在最终提交之前对其他事务是不可见的。
- 事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(Read committed)、可重复读(Repeatable read)和串行化(Serializable)。这些级别提供了不同程度的并发控制和数据一致性保证。
-
持久性(Durability)
- 一旦事务被提交,其对数据的修改就是永久性的,即使系统发生故障也不会丢失。
- 为了确保持久性,DBMS(数据库管理系统)通常会将事务的修改写入到磁盘上的稳定存储介质中,并在系统恢复时重新应用这些修改以恢复数据的一致性状态。
事务的控制语句
- begin transaction 或 start transaction:用于开始一个新的事务。
- commit:提交事务。将事务中的所有更改永久地保存到数据库中。
- rollback:回滚事务。撤销事务中所做的所有更改,并将数据库恢复到事务开始之前的状态。
- savepoint:在事务中设置一个保存点。允许在后续的回滚操作中只撤销到指定的保存点。
- rollback to savepoint:将事务回滚到指定的保存点。撤销从上一个保存点(或事务开始)到当前点之间的所有更改。
- set transaction:设置事务的属性,如隔离级别、访问模式等。
- lock table 和 unlock table:锁定和解锁表。用于在事务中控制对表的并发访问。
- set autocommit:设置自动提交模式。当自动提交模式打开时,每个单独的SQL语句都被视为一个单独的事务,并在执行后自动提交,值为1开启自动提交,0关闭自动提交。
- set transaction isolation level:设置事务的隔离级别。不同的隔离级别提供了不同程度的并发控制和数据一致性保证
MySql事务处理主要有两种方法
(1)用BEGIN,ROLLBACKCOMMIT来实现
- BEGIN开始一个事务
- ROLLBACK事务回滚
- COMMIT事务确认
(2)直接用SET来改变MySQL的自动提交模式
- SETAUTOCOMMIT=0禁止自动提交
- SETAUTOCOMMIT=1开启自动提交
注意:
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
mysql> SET AUTOCOMMIT=0;mysql>use auth;
mysql>CREATE TABLE kgc_transaction_test( id int(5)) engine=innodb;
mysql>select * from kgc_transaction_test; mysql>begin; //开始事务
mysql>insert into kgc_transaction_test value(1);
mysql> insert into kgc_transaction_test value(2);
mysql> commit; //提交事务
mysql>select * from kgc_transaction_test;mysql>begin; //开始事务
mysql>insert into kgc_transaction_test values(3);
mysql>rollback; //回滚
mysql> select * from kgc_transaction_test; //因为回滚所以数据没有插入相关文章:

MySQL索引,事务
一.MySQL索引介绍 索引是一个排序的列表,在这个列表中存储着索引的值和包含这个值的数据所在行的物理地址。在数据十分大的时候,索引可以大大加快查询的速度。这是因为使用索引后可以不用扫描全表来定位某行的数据,而是先通过索引表找到该行数…...
)
嵌入式软件面试记录(5)
1.FreeRTOS使用,是自己移植的吗,移植过程中设置了多少个任务? 答:是自己移植的,从官网下载的包根据手册移植的。 主要涉及以下几个任务: 主任务:负责系统初始化和创建其他任务。创建队列任务点…...
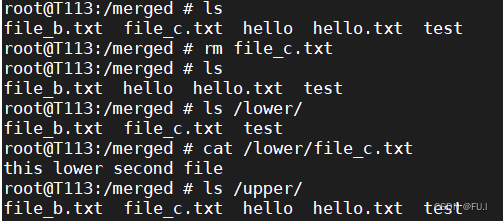
Linux-笔记 OverlayFS文件系统入门
目录 前言 主要概念 工作原理 特点特性 1、上下合并 2、同名文件覆盖 3、同名目录合并 4、写时拷贝 实操入门 内核配置 挂载文件系统 验证 1、同名文件覆盖 2、同名目录合并 3、写时拷贝 1)验证新增文件或目录 2)验证修改文件 3&…...

Kubernetes面试整理-如何配置和使用Service, Ingress?
在 Kubernetes 中,Service 和 Ingress 是用于管理和暴露应用程序的网络访问的主要资源。以下是如何配置和使用 Service 和 Ingress 的详细指南: Service Service 是一种抽象,用于定义一组 Pod 的逻辑集合,并提供一种访问这些 Pod 的策略。Service 可以使应用程序内部或外部…...

深入浅出:NPM常用命令详解与实践
深入浅出地讲解npm常用命令及其实践,可以帮助开发者更好地理解和使用这个强大的Node.js 包管理工具。以下是一些常用的npm命令及其详细解释和实践案例: 1:初始化项目: 命令:npm init用途:生成一个package…...

IPv6 address status lifetime
IPv6 地址状态转换 Address lifetime (地址生存期) 每个配置的 IPv6 单播地址都有一个生存期设置,该设置确定该地址在必须刷新或替换之前可以使用多长时间。某些地址设置为“永久”并且不会过期。“首选”和“有效”生存期用于指定其使用期限和可用性。 自动配置的…...

OpenVINO部署
OpenVINO部署 什么是 OpenVINO?OpenVINO 的优势安装指南系统要求:安装步骤 环境设置部署示例代码优化和部署步骤详细部署示例 什么是 OpenVINO? OpenVINO(Open Visual Inference and Neural Network Optimization)是由…...

面试题:MySQL优化,项目中举例
目录 一、SQL优化分两部分,如何发现慢SQL和如何优化慢SQL 二、项目举例 一、SQL优化分两部分,如何发现慢SQL和如何优化慢SQL 发现慢SQL有两种方案:第一种是开启我们的慢日志, 第二种就是使用skywalling发现慢的接口,进…...

Spring Boot中的事件驱动编程
Spring Boot中的事件驱动编程 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨在Spring Boot应用中如何利用事件驱动编程模式,实现…...

代码随想录算法训练营第五十天| 1143.最长公共子序列、1035.不相交的线、53. 最大子序和、392.判断子序列
LeetCode 1143.最长公共子序列 题目链接:https://leetcode.cn/problems/longest-common-subsequence/description/ 文章链接:https://programmercarl.com/1143.%E6%9C%80%E9%95%BF%E5%85%AC%E5%85%B1%E5%AD%90%E5%BA%8F%E5%88%97.html 思路 * dp[i][j]…...

【Redis】数据持久化
https://www.bilibili.com/video/BV1cr4y1671t?p96 https://blog.csdn.net/weixin_54232666/article/details/128821360 单点redis问题: 数据丢失问题:实现Redis数据持久化并发能力问题:搭建主从集群,实现读写分离故障恢复问题&…...
基于Python+Flask+MySQL+HTML的B站数据可视化分析系统
FlaskMySQLVue 基于PythonFlaskMySQLHTML的B站数据可视化分析系统 项目采用前后端分离技术,项目包含完整的前端HTML,以及Flask构成完整的前后端分离系统 爬虫文件基于selenium,需要配合登录账号 简介 主页 登录页面,用户打开浏…...

桥接模式
对象的继承关系是在编译时就定义好了,所以无法在运行时改变从父类继承的实现。子类的实现与它的父类有非常紧密的依赖关系,以至于父类实现中的任何变化必然会导致子类发生变化。当你需要复用子类时,如果继承下来的实现不适合解决新的问题&…...

docker中mysql突然无法远程连接设置
docker登陆到docker.hub docker login -u 用户名 回车密码 将容器打包成自己的镜像 docker commit -a "用户名" -m "redis" 533d6f1402ca 用户名/myredis:v1.2 将镜像发布到平台上 docker push用户名/myredis:v1.2 删除本地镜像 docker rm image …...

Nuxt3 的生命周期和钩子函数(二)
title: Nuxt3 的生命周期和钩子函数(二) date: 2024/6/26 updated: 2024/6/26 author: cmdragon excerpt: 摘要:本文深入介绍了Nuxt.js框架中几个关键的生命周期钩子函数,包括app:redirected(SSR环境下重定向前触发…...

用英文介绍孟买:Mumbai India‘s Transforming MEGACITY
Mumbai: India’s Transforming MEGACITY Link: https://www.youtube.com/watch?vtWD_-Rzrn8o Summary First Paragraph: Mumbai, India’s financial and entertainment capital, is undergoing a major transformation. With its contiguous urban population nearing 25…...

镜像发布至dockerHub
1、login 没有账号的话去注册一个 https://hub.docker.com docker login 输入账号密码和账号2、修改镜像名格式 可以直接招我的修改 格式为你的 hub名/镜像名 3、推送...

vscode + CMake编译(opencv显示图片工程)
1.opencv 1.1Mat容器: 在OpenCV中,cv::Mat是一个重要的类,用于表示和操作矩阵或多维数组,通常用于图像处理和计算机视觉任务。 cv::Mat类具有以下特点和功能: 多维数据存储:cv::Mat可以存储多维数据&…...

JavaScript的学习之强制类型转换
目录 一、什么是强制类型转换 二、其他类型转化为String类型 方式一:调用被转化数据类型的toString()方法 方式二:调用String函数,并将我们要转换的数据添加进去为参数 三、其他类型转化为Number类型 方式一:使用Number()函数…...

天润融通:AI赋能客户体验,推动企业收入和业绩增长
“客户体验已经成为全球企业差异化的关键。人工智能与数据分析等创新技术正在加速推动企业在客户体验计划中取得成功,以保持领先地位”。Customer Insights & Analysis 研究经理Craig Simpson说道。 客户体验 (CX,Customer Experience) 是客户在与企…...

MAA明日方舟自动辅助工具终极指南:一键解放双手的智能解决方案
MAA明日方舟自动辅助工具终极指南:一键解放双手的智能解决方案 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: htt…...

2025届最火的十大AI写作平台实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在这个信息呈现爆炸态势的时代当中,内容创作已然变成了个人以及企业所具备的核心…...

ArcMap栅格图像平滑滤波实战:从焦点统计到重采样的多工具对比与应用
1. 栅格图像平滑滤波基础概念与应用场景 当你拿到一张遥感影像时,可能会发现图像上存在一些"瑕疵"——比如拼接产生的条带痕迹、传感器噪声或者不自然的过渡区域。这时候就需要用到栅格图像平滑滤波技术了。简单来说,这就像给照片做"美颜…...
)
告别裸机延时!ESP32-C3/ESP32-S3用RMT外设精准驱动WS2812B灯带(Arduino/IDF双平台教程)
ESP32-C3/ESP32-S3 RMT外设驱动WS2812B灯带实战指南 当你的灯光项目从十几颗WS2812B升级到上百颗时,GPIO模拟驱动方式很快就会遇到瓶颈——闪烁、卡顿、颜色失真,这些问题的根源在于时序精度不足。ESP32系列芯片内置的RMT(Remote Control&…...

专业级音频编辑免费开源:Audacity 4.0 全面解析与使用指南
专业级音频编辑免费开源:Audacity 4.0 全面解析与使用指南 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity 还在为寻找一款功能全面、易于上手且完全免费的音频编辑软件而烦恼吗?是否曾经因…...

深入TEA5767数据手册:51单片机I²C驱动FM收音模块的避坑指南与调试心得
深入解析TEA5767:51单片机驱动FM收音模块的实战技巧 在嵌入式开发领域,能够独立解读芯片手册并实现功能驱动是工程师的核心能力之一。TEA5767作为一款经典的FM收音芯片,因其低功耗、高集成度和简单的IC接口而广受欢迎。本文将从一个实际开发者…...

NHSE终极指南:5分钟掌握动物森友会存档编辑器的完整教程
NHSE终极指南:5分钟掌握动物森友会存档编辑器的完整教程 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》中收集稀有物品而烦恼吗?想…...

3步解决Beyond Compare 5评估模式错误:密钥生成与完全激活指南
3步解决Beyond Compare 5评估模式错误:密钥生成与完全激活指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 当Beyond Compare 5的30天评估期结束后,软件会显示"评…...

ARM TLB机制与虚拟化加速:TLBIP指令与TLBID域深度解析
1. ARM TLB机制与虚拟化加速 在现代ARM架构中,TLB(Translation Lookaside Buffer)作为内存管理单元(MMU)的核心组件,其性能直接影响虚拟地址转换效率。随着虚拟化技术的普及,ARMv8/v9架构引入了…...
)
从聊天到拿Shell:一个Netcat命令的‘黑白’两面实战指南(含正向/反向Shell演示)
从聊天到拿Shell:Netcat命令的双面实战手册 在网络安全领域,很少有工具能像Netcat这样同时扮演"天使"与"恶魔"的双重角色。这个被称为"网络瑞士军刀"的轻量级工具,既能帮助管理员快速排查网络问题,…...