详解 ClickHouse 的分片集群
一、简介
分片功能依赖于 Distributed 表引擎,Distributed 表引擎本身不存储数据,有点类似于 MyCat 之于 MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据
ClickHouse 进行分片集群的目的是解决数据的横向扩容,通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上,再通过 Distributed 表引擎把数据拼接起来一同使用。
二、集群规划
3 分片 2 副本共 6 个节点,s 表示分片数,r 表示副本数
| hadoop1 | hadoop2 | hadoop3 | hadoop4 | hadoop5 | hadoop6 |
|---|---|---|---|---|---|
| s1r1 | s1r2 | s2r1 | s2r2 | s3r1 | s3r2 |
1. 写入流程
实际生产中会设置 internal_replication=true,开启副本内部同步

2. 读取流程

- 优先选择 error_count 值小的副本进行读取
- 当同一分片的 error_count 值相同时选择方式有随机、顺序、优先第一顺位和主机名称近似等四种
3. 集群配置
su root
cd /etc/clickhouse-server/config.dvim metrika.xml#添加配置
<yandex><remote_servers><gmall_cluster> <!-- 自定义集群名称--><shard> <!--集群的第一个分片--><internal_replication>true</internal_replication><!--该分片的第一个副本--><replica><host>hadoop101</host><port>9000</port></replica><!--该分片的第二个副本--><replica><host>hadoop102</host><port>9000</port></replica></shard><shard> <!--集群的第二个分片--><internal_replication>true</internal_replication><replica> <!--该分片的第一个副本--><host>hadoop103</host><port>9000</port></replica><replica> <!--该分片的第二个副本--><host>hadoop104</host><port>9000</port></replica></shard><shard> <!--集群的第三个分片--><internal_replication>true</internal_replication><replica> <!--该分片的第一个副本--><host>hadoop105</host><port>9000</port></replica><replica> <!--该分片的第二个副本--><host>hadoop106</host><port>9000</port></replica></shard></gmall_cluster></remote_servers>
</yandex>#也可以直接在 config.xml 的<remote_servers>中指定
三、三节点版本集群配置操作
生产上 ClickHouse 建议独立部署在服务器上,建议资源:100G内存,CPU为32线程
1. 分片及副本规划
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| s1r1 | s1r2 | s2r1 |
2. 实操步骤
-
在 hadoop102 节点的
/etc/clickhouse-server/config.d目录下创建metrika-shard.xml文件su root cd /etc/clickhouse-server/config.d vim metrika-shard.xml#添加配置 <?xml version="1.0"?> <yandex><remote_servers><gmall_cluster> <!-- 自定义集群名称--><shard> <!--集群的第一个分片--><internal_replication>true</internal_replication><replica> <!--该分片的第一个副本--><host>hadoop102</host><port>9000</port></replica><replica> <!--该分片的第二个副本--><host>hadoop103</host><port>9000</port></replica></shard><shard> <!--集群的第二个分片--><internal_replication>true</internal_replication><replica> <!--该分片的第一个副本--><host>hadoop104</host><port>9000</port></replica></shard></gmall_cluster></remote_servers><zookeeper-servers><node index="1"><host>hadoop102</host><port>2181</port></node><node index="2"><host>hadoop103</host><port>2181</port></node><node index="3"><host>hadoop104</host><port>2181</port></node></zookeeper-servers><macros><shard>01</shard> <!--不同机器放的分片数不一样--><replica>rep_1_1</replica> <!--不同机器放的副本数不一样--></macros> </yandex>chown clickhouse:clickhouse metrika-shard.xml#也可以直接在 config.xml 的<remote_servers>中指定 -
在 hadoop102 上修改
/etc/clickhouse-server/config.xmlcd /etc/clickhouse-servervim config.xml#添加外部文件路径 <zookeeper incl="zookeeper-servers" optional="true" /> <include_from>/etc/clickhouse-server/config.d/metrika-shard.xml</include_from> -
分发配置到 hadoop103 和 hadoop104
/etc/clickhouse-server/config.d/metrika-shard.xml /etc/clickhouse-server/config.xml -
分别修改 hadoop103 和 hadoop104 中
metrika-shard.xml的<macros>的配置#hadoop103 sudo vim /etc/clickhouse-server/config.d/metrika-shard.xml<macros><shard>01</shard> <!--不同机器放的分片数不一样--><replica>rep_1_2</replica> <!--不同机器放的副本数不一样--> </macros>#hadoop104 sudo vim /etc/clickhouse-server/config.d/metrika-shard.xml<macros><shard>02</shard> <!--不同机器放的分片数不一样--><replica>rep_2_1</replica> <!--不同机器放的副本数不一样--> </macros> -
分别在三台节点上启动 clickhouse 服务
sudo clickhouse start -
在 hadoop102 上创建一张本地表
create table st_order_mt on cluster gmall_cluster (id UInt32,sku_id String,total_amount Decimal(16,2),create_time Datetime ) engine=ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt','{replica}') partition by toYYYYMMDD(create_time) primary key (id) order by (id,sku_id);--on cluster 的集群名字要和配置文件中自定义的集群名一致 --分片和副本名称从配置文件的宏定义中获取 --hadoop103 和 hadoop104 上会自动同步创建这张表 -
在 hadoop102 上创建 Distribute 分布式表
create table st_order_mt_all2 on cluster gmall_cluster (id UInt32,sku_id String,total_amount Decimal(16,2),create_time Datetime ) engine=Distributed(gmall_cluster, default, st_order_mt, hiveHash(sku_id));--on cluster 的集群名字要和配置文件中自定义的集群名一致 --hadoop103 和 hadoop104 上会自动同步创建这张表 --表引擎为 Distributed,其中的参数分别为:集群名称,数据库名,本地表名,分片键 --分片键必须是整型数字,所以用 hiveHash 函数转换,也可以 rand() -
向 hadoop102 上的分布式表插入数据
insert into st_order_mt_all2 values (201,'sku_001',1000.00,'2020-06-01 12:00:00') , (202,'sku_002',2000.00,'2020-06-01 12:00:00'), (203,'sku_004',2500.00,'2020-06-01 12:00:00'), (204,'sku_002',2000.00,'2020-06-01 12:00:00'), (205,'sku_003',600.00,'2020-06-02 12:00:00'); -
分别在 hadoop102、hadoop103 和 hadoop104 上查询本地表和分布式表的数据进行对比
--hadoop102 select * from st_order_mt; select * from st_order_mt_all2;--hadoop103 select * from st_order_mt; select * from st_order_mt_all2;--hadoop104 select * from st_order_mt; select * from st_order_mt_all2;
相关文章:
详解 ClickHouse 的分片集群
一、简介 分片功能依赖于 Distributed 表引擎,Distributed 表引擎本身不存储数据,有点类似于 MyCat 之于 MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据 ClickHouse 进行分片集群的…...

AI问答-医疗:什么是“手术报台”
手术报台并不是传统意义上的医疗工具或设备,而是一个与手术耗材追溯管理相关的系统或工具。以下是对手术报台的详细解释: 一、定义与功能 手术报台系统,如医迈德手术报台系统,是一款面向医院跟台人员的微信小程序。 它通过手术耗…...
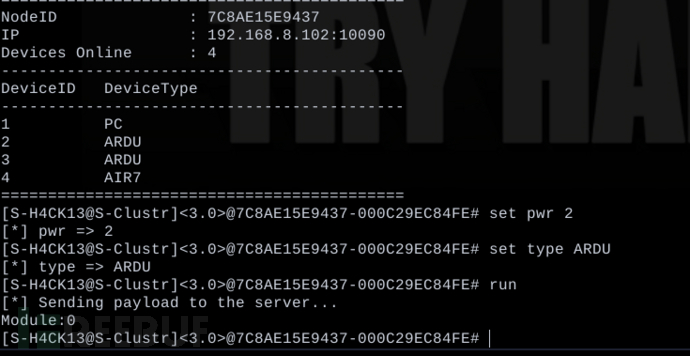
S-Clustr(影子集群)V3 高并发,去中心化,多节点控制
S-Clustr 项目地址:https://github.com/MartinxMax/S-Clustr/releases/tag/S-Clustr-V3.0 Maptnh Не ограничивайте свои действия виртуальным миром. GitHub: Maptnh Jay Steinberg Man kann die Menschen, die man hasst, in d…...
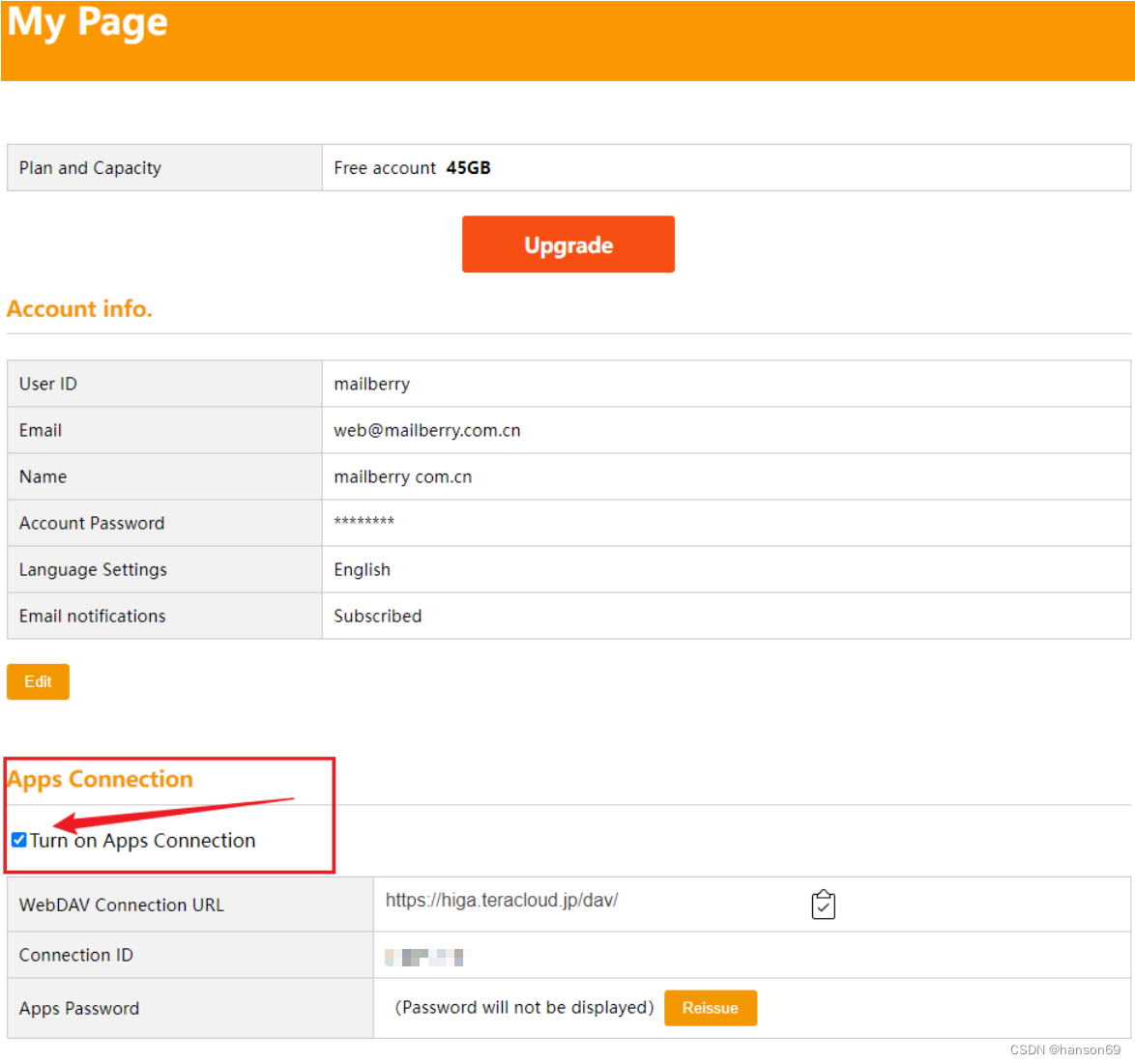
支持WebDav的网盘infiniCloud(静读天下,Zotero 等挂载)
前言 WebDav是一种基于HTTP的协议,允许用户在Web上直接编辑和管理文件,如复制、移动、删除等。 尽管有一些网盘支持WebDav,但其中大部分都有较多的使用限制。这些限制可能包括:上传文件的大小限制、存储空间的限制、下载速度的限…...

Linux命令行导出MySQL数据库备份并压缩
Linux命令行导出MySQL数据库备份并压缩 导出SQL: 如果使用的是 MySQL 或者 MariaDB 可以使用mysqldump工具进行数据备份的导出; 基本命令: mysqldump -u用户名 -p密码 数据库名称 > 要导出的文件名.sql替换掉你实际的数据库“用户名”…...
)
二叉树的广度优先搜索(层次遍历)
目录 定义 层序遍历的数据结构 实现过程简述 具体代码 定义 层序遍历就是从左到右一层一层地遍历二叉树。 层序遍历的数据结构 层序遍历需要借用一个辅助数据结构实现,由于队列具有先进先出的特性,符合一层一层遍历的逻辑,而栈先进后出…...
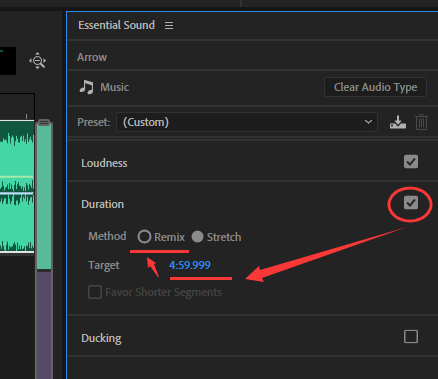
AU音频重新混合音频,在 Adobe Audition 中无缝延长背景音乐,无缝缩短BGM
导入音频,选中音频,并且点 New Multitrack Session 的图标 设计文件名和存储路径,然后点 OK 点 Essential Sound 面板点 Music (如果没有这个面板 点菜单栏 Windows > Essential Sound 调出来) 点 Duration 展…...
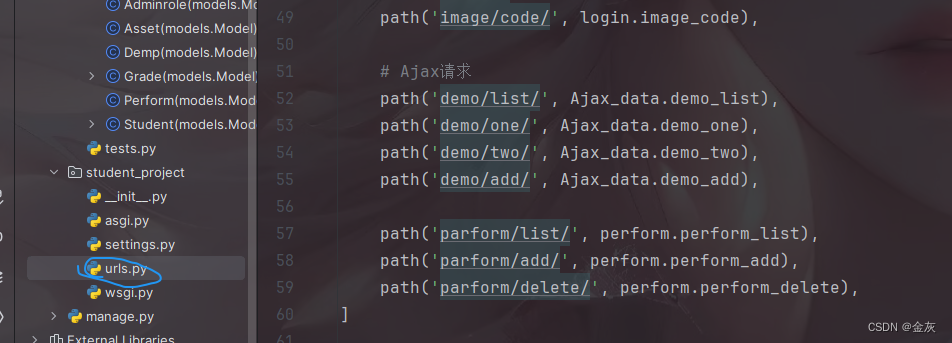
11-Django项目--Ajax请求二
目录 模版: demo_list.html perform_list.html 数据库操作: 路由: 视图函数: Ajax_data.py perform.py 模版: demo_list.html {% extends "index/index.html" %} {% load static %} # 未实现修改,删除操作{% block content %}<div class"container…...

代码评审——Java占位符%n的处理
问题描述 在软件开发项目中,特别是在处理动态内容生成与呈现至前端界面的过程中,正确运用占位符以确保文本完整性和数据准确性显得尤为重要。不当的占位符管理不仅可能导致语法错误或逻辑混乱,还会引发一系列隐蔽的问题,这些问题…...

超低排放标准
据朗观视觉小编了解发现,超低排放标准作为衡量一个行业或企业环保水平的重要指标,越来越受到社会各界的关注。本文将深入探讨超低排放标准的内涵、实施意义以及未来展望。 一、超低排放标准的定义 超低排放标准,是指在特定工业生产过程中&am…...
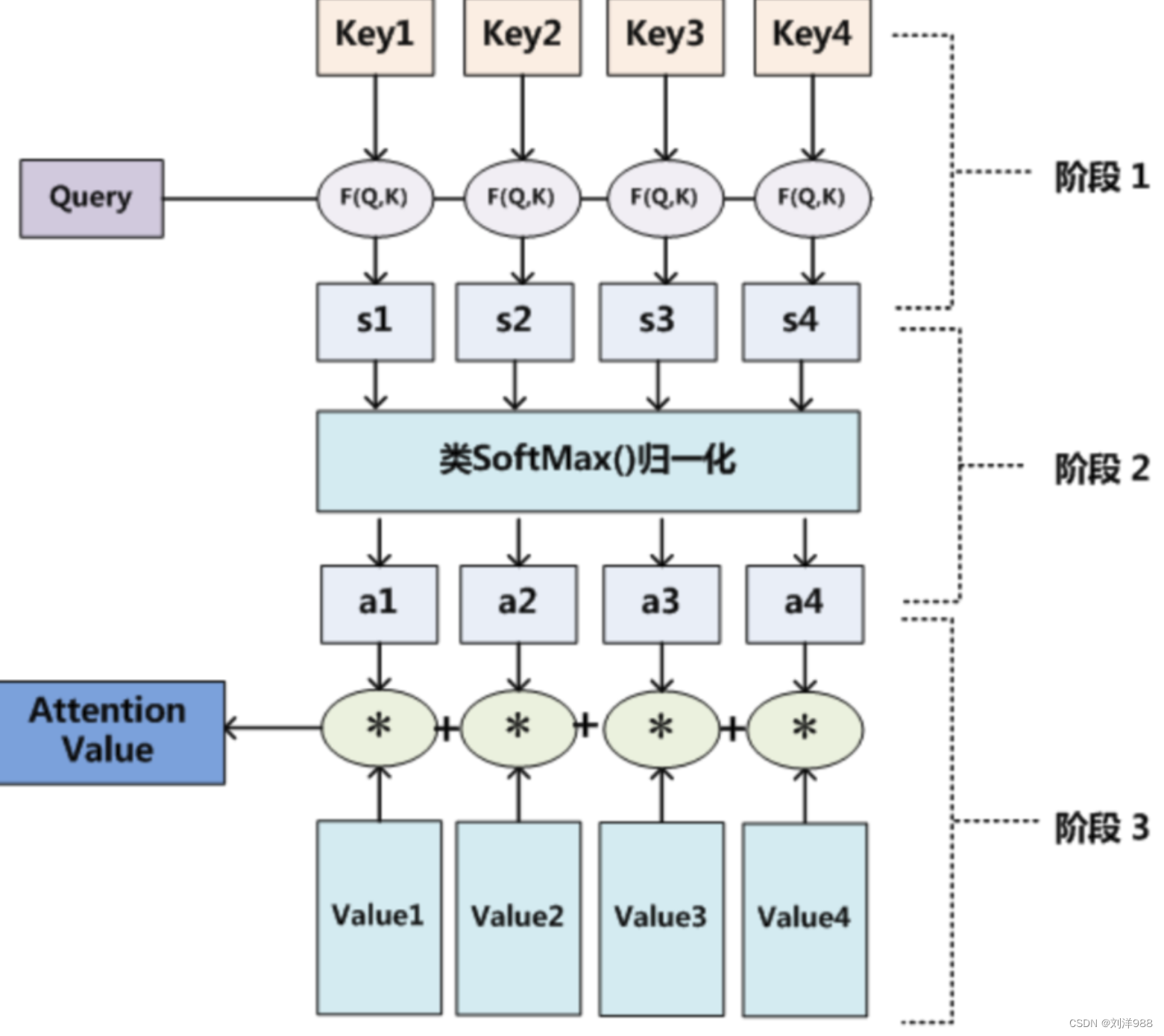
Day15 —— 大语言模型简介
大语言模型简介 大语言模型基本概述什么是大语言模型主要应用领域大语言模型的关键技术大语言模型的应用场景 NLP什么是NLPNLP的主要研究方向word2vecword2vec介绍word2vec的两种模型 全连接神经网络神经网络结构神经网络的激活函数解决神经网络过拟合问题的方法前向传播与反向…...

使用了CDN,局部访问慢,如何排查
如果是局部访问慢,则可从如下角度查看 是否DNS设置错误导致? 个别用户可能存在local DNS设置错误,导致出现跨地域或跨运营商访问。因为CDN的权威DNS是基于用户请求的localDNS来判断所属的地区和运营商,从而将请求引导至对应最近…...

谈谈SQL优化
SQL优化是数据库性能优化中的关键环节,旨在提高查询执行的效率和响应速度。下面是一些常见的SQL优化技巧和策略,涵盖索引、查询设计、表结构设计等方面: 1. 索引优化 创建索引:为常用查询的过滤条件(WHERE 子句&…...

力扣随机一题 6/26 哈希表 数组 思维
博客主页:誓则盟约系列专栏:IT竞赛 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 题目一: 2869.收集元素的最少操作次数【简单】 题目ÿ…...

自动化办公04 使用pyecharts制图
目录 一、柱状图 二、折线图 三、饼图 四、地图 1. 中国地图 2. 世界地图 3. 省会地图 五、词云 Pyecharts是一个用于数据可视化的Python库。它基于Echarts库,可以通过Python代码生成各种类型的图表,如折线图、柱状图、饼图、散点图等。 Pyecha…...

【Elasticsearch】在es中实现mysql中的FIND_IN_SET查询条件
需求场景: 有个文章表里面有个type字段,它存储的是文章类型,有 1头条、2推荐、3热点、4图文等等 。 商品表中有一个type字段,储存的事商品类型例如:1.热销单品,2.品类TOP10,3.销量榜TOP10等等 它的type字段值很有可能是1,2,3,4 在mysql中实现语句 select * from produc…...

内网一键部署k8s-kubeshpere,1.22.12版本
1.引言 本文档旨在指导读者在内网环境中部署 Kubernetes 集群。Kubernetes 是一种用于自动化容器化应用程序部署、扩展和管理的开源平台,其在云原生应用开发和部署中具有广泛的应用。然而,由于一些安全或网络限制,一些组织可能选择在内部网络…...
Python数据分析第一课:Anaconda的安装使用
Python数据分析第一课:Anaconda的安装使用 1.Anaconda是什么? Anaconda是一个便捷的获取包,并且对包和环境进行管理的虚拟环境工具,Anaconda包括了conda、Python在内的超过180多个包和依赖项 简单来说,Anaconda是包管理器和环境…...

数据结构——
1. 什么是并查集? 在计算机科学中,并查集(英文:Disjoint-set data structure,直译为不数据结构交集)是一种数据结构,用于处理一些不交集(Disjoint sets,一系列没有重复元…...

微信小程序建议录音机
在小程序中实现录音机功能,可以通过使用小程序提供的wx.getRecorderManager() API来获取录音管理对象,然后使用这个对象的start()方法来开始录音,使用stop()方法来停止录音,并使用onStop()方法来监听录音的结束。以下是一个简单的…...
)
YOLOv8植物病害识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 植物病害是威胁全球农业产量与质量的主要因素之一,传统的人工识别方法依赖专家经验,效率低、主观性强。本文基于YOLOv8目标检测算法,构建了一套涵盖30类植物及其叶片病害的检测系统,包括苹果、玉米、马铃薯、番茄、葡萄等主…...

可编程投币器集成指南:从硬件连接到游戏积分映射
1. 项目概述:从“投币”到“积分”的硬件魔法“Insert Coin”——对于任何一个经历过街机黄金年代的玩家来说,这三个字背后所承载的,远不止是启动游戏的指令,更是一种充满仪式感的期待。如今,我们大多通过模拟器上的一…...

FAST开发方法在系统分析中四个阶段
在系统分析师考试中,被频繁考查的FAST(Framework for the Application of Systems Thinking)方法,是一个聚焦于系统分析阶段的框架。 它的核心是将复杂的分析工作拆解为四个环环相扣的阶段:初始研究、问题分析、需求分析和决策分析。 📊 四个阶段速览 阶段 核心任务 1…...

3DMax对齐功能全解析:从基础操作到高阶建模实战
1. 3DMax对齐功能基础入门 刚接触3D建模的新手最常遇到的困扰就是:为什么我的模型总是对不齐?记得我第一次用3DMax做建筑模型时,花了两小时都没能把一扇窗户准确地装到墙面上。直到后来掌握了对齐工具,才发现原来这种问题5秒钟就能…...
)
YOLOv8树上自然生长的苹果识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 针对自然果园环境中苹果目标检测面临的光照变化、枝叶遮挡及果实密集等挑战,本研究基于YOLOv8目标检测算法构建了一套树上苹果检测系统。实验采用自建苹果图像数据集,包含训练集1355张、验证集77张、测试集39张,目标类别为单一“Apples…...

面试时被问“你的缺点是什么”,这样回答反而加分
面试中,当面试官看似随意地问出“你的缺点是什么”时,空气往往会突然安静几秒。对软件测试工程师而言,这个问题尤其微妙——我们每天都在和“找茬”打交道,对缺陷和风险有着本能的敏感。然而,面试官抛出这个问题&#…...

创业团队如何用Taotoken低成本试验多个AI模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何用Taotoken低成本试验多个AI模型 对于资源有限的创业团队而言,在开发产品原型或验证AI功能时,…...

2026年国内数字人平台推荐:有哪些创作者与企业的高效创作利器?
一、引文/摘要在数字人领域,制作成本高、技术门槛高、生产效率低已成为内容创作的核心痛点。 2026年,AI数字人市场持续扩张,创作者与企业对低成本、易上手、全链路的数字人解决方案需求激增。但市场平台繁杂,功能与技术差异显著&a…...

对比直连与通过taotoken调用大模型api的实际延迟感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直连与通过 Taotoken 调用大模型 API 的实际延迟感受 在集成大模型 API 到实际应用时,响应延迟是影响开发者体验和…...
)
零代码也能做游戏?用UE5蓝图系统10分钟做个会转的潜艇(附完整资产包)
零代码游戏开发:用UE5蓝图10分钟打造动态潜艇 当第一次打开虚幻引擎5时,许多初学者会被其庞大的功能体系所震撼——从影视级的光照系统到数百万面的高精度模型渲染,这款引擎几乎能实现任何你能想象到的视觉效果。但更令人惊喜的是,…...