机器学习辅助的乙醇浓度检测(毕设节选)
目录
1.为什么要机器学习
2. 神经网络一般组成
3.BP神经网络工作过程
4.评价指标
5.实操代码
1.为什么要用机器学习
人工分析大量的谐振模式,建立各种WGM的响应与未知目标之间的关系,是一个很大的挑战。机器学习(ML)能够自行识别全谱的全部特征。作为一种数据驱动的分析技术,它可以自动从大型数据集中搜索有效信息,揭示数据背后的机制,从而建立数据之间的映射关系输入数据与未知目标参数。(我的理解是,采集的是乙醇的光谱数据,人眼识别或者记录比较困难,故而借助机器学习。)
2. 神经网络一般组成
(1)输入层:输入层是神经网络的起始部分,它的作用是接收外部输入的数据。输入层的设计直接影响到神经网络的性能,因为它决定了网络能够接收和处理的信息类型和结构。
(2)隐藏层:隐藏层在神经网络中的作用尤为重要,它们负责特征的转换和提取。通过应用非线性变换,隐藏层能够提升模型对复杂数据的表达能力。
(3)输出层:输出层是模型的最后一层,它的任务是生成模型的最终预测结果。这一层的神经元数量与所解决的问题类型密切相关。在回归问题中,通常只需要一个输出神经元来预测连续的数值;而在分类问题中,输出神经元的数量则与目标类别的数量一致。
(4)权重和偏置:这些是网络中的参数,可以在训练过程中进行学习。权重决定了输入特征如何影响隐藏层和输出层,而偏置则用于调整神经元的激活水平。
(5)激活函数:激活函数是神经网络中的关键组件,它负责为网络引入非线性。在神经网络中,每个神经元在接收到输入信号后,会通过一个激活函数来决定是否以及如何激活。
(6)损失函数:损失函数(Loss Function)是神经网络训练过程中用于衡量模型预测值与实际值之间差异的函数。它为网络提供了一个优化的目标,即最小化损失函数的值。损失函数的选择取决于具体的任务和模型的需求。
(7)优化器:优化器在神经网络训练中起着至关重要的作用,它的主要工作是调整网络的权重和偏置,目的是减少损失函数的值。
3.BP神经网络工作过程
(1)初始化:首先,需要初始化网络中的权重和偏置。
(2)输入数据:将输入数据送入网络,进而传递到第一层的神经元,即输入层。
(3)前向传播:数据在网络中逐层向前传递,每一层的神经元接收来自前一层的输出,通过激活函数处理,生成当前层输出。激活函数常使用Sigmoid、Tanh或ReLU等。
(4)计算误差:在网络的最后一层,即输出层,计算预测结果与实际目标值之间的误差。误差通常使用均方误差(Mean Squared Error, MSE)或其他损失函数来衡量。
(5)反向传播:利用计算出的误差,通过反向传播算法调整网络中的权重和偏置。这个过程涉及到梯度的计算,即损失函数对权重的偏导数。
(6)权重更新:根据反向传播得到的梯度信息,使用梯度下降或其变体(如动量法、AdaGrad等)来更新权重和偏置。
(7)迭代训练:重复步骤(3)至(6),直到满足停止条件,如达到预定的迭代次数或误差降低到可接受的水平。
(8)评估和应用:训练完成后,使用测试数据集评估网络的性能,然后可以将训练好的神经网络应用于实际问题。
4.评价指标

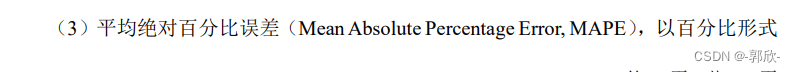
5.实操代码
%% BP神经网络回归预测
%% 1.初始化
clear all
close all
clc
format short %2位小数,format short精确4位,format long精确15位%% 2.读取数据
data=xlsread("D:\Matlab\machine learning\machine learning.xlsx"); %使用xlsread函数读取EXCEL中对应范围的数据即可; xlsread函数报错时,可用Load函数替代 % 设置神经网络的输入和输出
T=data(:,1); %步长
X=data(:,2); %第1列至倒数第2列为输入
Y=data(:,3); %最后1列为输出
N=length(Y); %计算样本数量
input=X;
output=Y;%% 3.设置训练集和测试集
%(1)随机选取测试样本code5
k=rand(1,N);
[m,n]=sort(k);
testNum=9; %设定测试集样本数量——修改
trainNum=N-testNum; %设定训练集样本数量
input_train = input(n(1:trainNum),:)'; % 训练集输入
output_train =output(n(1:trainNum))'; % 训练集输出
input_test =input(n(trainNum+1:trainNum+testNum),:)'; % 测试集输入
output_test =output(n(trainNum+1:trainNum+testNum))'; % 测试集输出%% 4.数据归一化
[inputn,inputps]=mapminmax(input_train,0,1); % 训练集输入归一化到[0,1]之间
%[outputn,outputps]=mapminmax(output_train,0,1);
[outputn,outputps]=mapminmax(output_train); % 训练集输出归一化到默认区间[-1, 1]
inputn_test=mapminmax('apply',input_test,inputps); % 测试集输入采用和训练集输入相同的归一化方式%% 5.求解最佳隐含层
inputnum=size(input,2); %size用来求取矩阵的行数和列数,1代表行数,2代表列数
outputnum=size(output,2);
disp(['输入层节点数:',num2str(inputnum),', 输出层节点数:',num2str(outputnum)])
disp(['隐含层节点数范围为 ',num2str(fix(sqrt(inputnum+outputnum))+1),' 至 ',num2str(fix(sqrt(inputnum+outputnum))+10)])
disp(' ')
disp('最佳隐含层节点的确定...')%根据hiddennum=sqrt(m+n)+a,m为输入层节点数,n为输出层节点数,a取值[1,10]之间的整数
MSE=1e+5; %误差初始化
transform_func={'tansig','purelin'}; %激活函数采用tan-sigmoid和purelin
train_func='trainlm'; %训练算法
for hiddennum=fix(sqrt(inputnum+outputnum))+1:fix(sqrt(inputnum+outputnum))+10net=newff(inputn,outputn,hiddennum,transform_func,train_func); %构建BP网络% 设置网络参数net.trainParam.epochs=1000; % 设置训练次数net.trainParam.lr=0.01; % 设置学习速率net.trainParam.goal=0.000001; % 设置训练目标最小误差% 进行网络训练net=train(net,inputn,outputn);an0=sim(net,inputn); %仿真结果mse0=mse(outputn,an0); %仿真的均方误差disp(['当隐含层节点数为',num2str(hiddennum),'时,训练集均方误差为:',num2str(mse0)])%不断更新最佳隐含层节点if mse0<MSEMSE=mse0;hiddennum_best=hiddennum;end
end
disp(['最佳隐含层节点数为:',num2str(hiddennum_best),',均方误差为:',num2str(MSE)])%% 6.构建最佳隐含层的BP神经网络
net=newff(inputn,outputn,hiddennum_best,transform_func,train_func);% 网络参数
net.trainParam.epochs=1000; % 训练次数
net.trainParam.lr=0.01; % 学习速率
net.trainParam.goal=0.000001; % 训练目标最小误差%% 7.网络训练
net=train(net,inputn,outputn); % train函数用于训练神经网络,调用蓝色仿真界面%% 8.网络测试
an=sim(net,inputn_test); % 训练完成的模型进行仿真测试
test_simu=mapminmax('reverse',an,outputps); % 测试结果反归一化
error=test_simu-output_test; % 测试值和真实值的误差% 权值阈值
W1 = net.iw{1, 1}; %输入层到中间层的权值
B1 = net.b{1}; %中间各层神经元阈值
W2 = net.lw{2,1}; %中间层到输出层的权值
B2 = net.b{2}; %输出层各神经元阈值%% 9.结果输出
% BP预测值和实际值的对比图
figure
plot(output_test,'bo-','linewidth',1.5)
hold on
plot(test_simu,'rs-','linewidth',1.5)
legend('实际值','预测值')
xlabel('测试样本'),ylabel('指标值')
title('BP预测值和实际值的对比')
set(gca,'fontsize',12)% BP测试集的预测误差图
figure
plot(error,'bo-','linewidth',1.5)
xlabel('测试样本'),ylabel('预测误差')
title('BP神经网络测试集的预测误差')
set(gca,'fontsize',12)%计算各项误差参数
[~,len]=size(output_test); % len获取测试样本个数,数值等于testNum,用于求各指标平均值
SSE1=sum(error.^2); % 误差平方和
MAE1=sum(abs(error))/len; % 平均绝对误差
MSE1=error*error'/len; % 均方误差
RMSE1=MSE1^(1/2); % 均方根误差
MAPE1=mean(abs(error./output_test)); % 平均百分比误差
r=corrcoef(output_test,test_simu); % corrcoef计算相关系数矩阵,包括自相关和互相关系数
R1=r(1,2); % 显示各指标结果
disp(' ')
disp('各项误差指标结果:')
disp(['误差平方和SSE:',num2str(SSE1)])
disp(['平均绝对误差MAE:',num2str(MAE1)])
disp(['均方误差MSE:',num2str(MSE1)])
disp(['均方根误差RMSE:',num2str(RMSE1)])
disp(['平均百分比误差MAPE:',num2str(MAPE1*100),'%'])
disp(['预测准确率为:',num2str(100-MAPE1*100),'%'])
disp(['相关系数R: ',num2str(R1)])%%读取待预测数据
kes=xlsread("D:\Matlab\machine learning\self.xlsx");%%数据转置
kes=kes';%%数据归一化
n_test = mapminmax('apply',kes,inputps,0,1);%%仿真测试
t_sim = sim(net,n_test);%%数据反归一化
T_sim = mapminmax('reverse',t_sim,outputps,0,1);%%保存结果
xlswrite('self_product',T_sim')
相关文章:

机器学习辅助的乙醇浓度检测(毕设节选)
目录 1.为什么要机器学习 2. 神经网络一般组成 3.BP神经网络工作过程 4.评价指标 5.实操代码 1.为什么要用机器学习 人工分析大量的谐振模式,建立各种WGM的响应与未知目标之间的关系,是一个很大的挑战。机器学习(ML)能够自行识别全谱的全部特征。作为…...
YOLO系列改进
yolo核心思想:把目标检测转变成一个回归问题。将整个图像作为网络的输入,仅仅经过一个神经网络,得到边界框的位置及其所属的类别。 YOLOv1 CVPR2016 输出7730的张量表示2个框的5个参数和20个种类。leaky ReLU,leaky并不会让负数…...
cuda与cudnn下载(tensorflow-gpu)
目录 前言 正文 前言 !!!tensorflow-gpu的版本要与cuda与cudnn想对应。这点十分重要!推荐下载较新的。即tensorflow-gpu2.60及以上,cuda11.x及以上,cudnn8.x及以上。 所以,下载之前先检查好…...

git 多分支实现上传文件但避免冲突检测
文章目录 背景实现步骤 背景 对于某些通过命令生成的配置文件(如 TypeScript 类型文件等) 实现步骤 1...
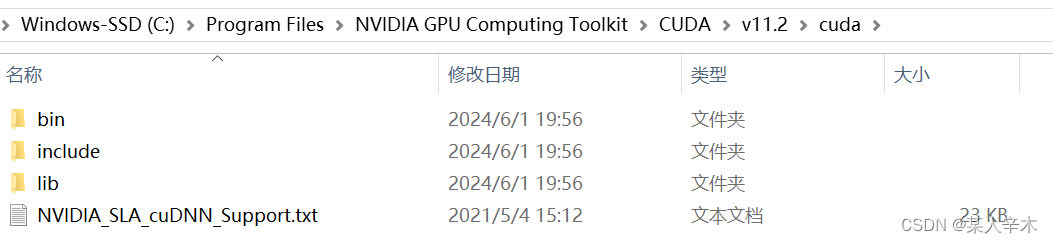
聊聊 golang 中 channel
1、引言 Do not communicate by sharing memory; instead, share memory by communicating Golang 的并发哲学是“不要通过共享内存进行通信,而要通过通信来共享内存”,提倡通过 channel 进行 goroutine 之间的数据传递和同步,而不是通过共享…...
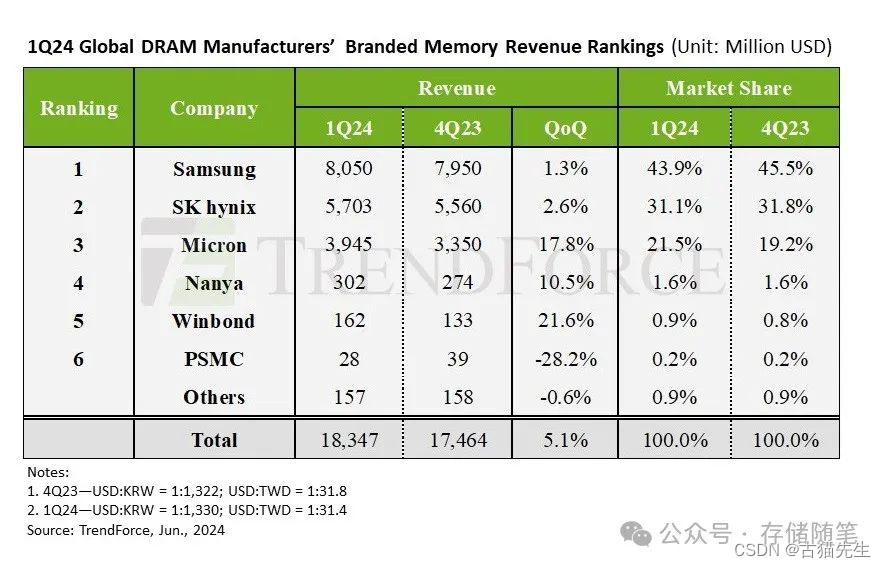
SK Hynix 3D DRAM良率突破56.1%,开启存储新时代
根据韩国财经媒体Business Korea独家报道:在刚刚结束的VLSI 2024国际研讨会上,韩国半导体巨头SK Hynix公布了一项振奋人心的进展:其五层堆叠3D DRAM的制造良率已达到56.1%。此成果标志着3D DRAM技术在商业化道路上迈出了坚实的一步࿰…...

如何封装自动化测试框架?
封装自动化测试框架,测试人员不用关注框架的底层实现,根据指定的规则进行测试用例的创建、执行即可,这样就降低了自动化测试门槛,能解放出更多的人力去做更深入的测试工作。 本篇文章就来介绍下,如何封装自动化测试框…...
基于Java的在线编程考试系统【附源码】
毕业设计(论文) 题目:基于 二级学院: 现代技术学院 专业(方向): 计算机应用技术 班 级: 计科B2015 学 生: 指导教师: 2024年1月 29 日 本科毕业论文(设计)学术诚信声明 本人郑重…...

Beautiful Soup的使用
1、Beautiful Soup简介 Beautiful Soup是一个Python的一个HTML或XML的解析库,我们用它可以方便地从网页中提取数据。 Beautiful Soup 提供一些简单的、Python 式的函数来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓…...
633. 平方数之和(中等)
633. 平方数之和 1. 题目描述2.详细题解3.代码实现3.1 Python3.2 Java内存溢出溢出代码正确代码与截图 1. 题目描述 题目中转:633. 平方数之和 2.详细题解 本题是167. 两数之和 II - 输入有序数组(中等)题目的变型,由两数之和变…...

GIT回滚
1. 使用 git revert git revert 命令会创建一个新的提交,这个提交会撤销指定提交的更改。这通常用于公共分支(如 main 或 master),因为它不会重写历史。 git revert HEAD # 撤销最近的提交 # 或者指定一个特定的提交哈希值 …...
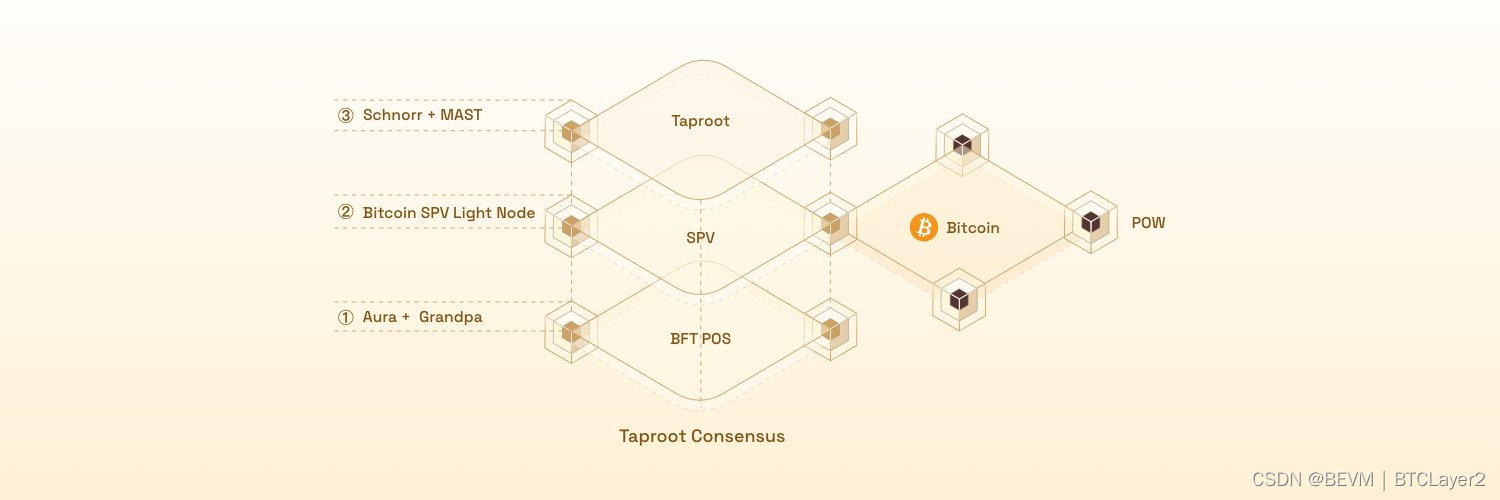
BEVM基于OP-Stack发布首个以WBTC为GAS连接以太坊和比特币生态的中继链
为了更好的连接以太坊和比特币生态,BEVM团队正在基于OPtimism的OP Stack来构建一个以WBTC为GAS兼容OP-Rollup的中继链,这条中继链将作为一种完全去中心化的中间层,把以太坊上的主流资产(WBTC/ ETH/USDC/USDT等)引入到BEVM网络。 不仅如此&am…...

【vuejs】 $on、$once、$off、$emit 事件监听方法详解以及项目实战
1. Vue实例方法概述 1.1 vm.$on vm.$on是Vue实例用来监听自定义事件的方法。它允许开发者在Vue实例上注册事件监听器,当事件被触发时,指定的回调函数会被执行。 事件监听:vm.$on允许开发者绑定一个或多个事件到Vue实例上,并且可…...

如何下载植物大战僵尸杂交版,最全攻略来了
《植物大战僵尸杂交版》由热爱原版游戏的B站UP主“潜艇伟伟迷”独立开发,带来了创新的游戏体验。如果你是策略游戏的爱好者,下面这份全面的下载和游玩攻略将是你的理想选择。 游戏亮点: 杂交植物系统:结合不同植物特性,…...

小公司全栈是归宿吗?
在软件开发领域,特别是在小公司或初创公司中,全栈开发者的角色确实相对普遍和重要。然而,说“全栈是归宿”可能过于绝对,因为每个开发者的职业路径和兴趣点都是不同的。 以下是关于全栈开发在小公司的一些考虑: 需求…...
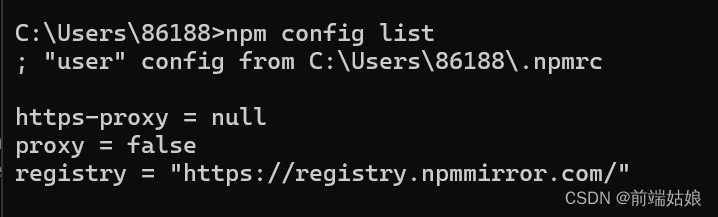
对https://registry.npm.taobao.org/tyarn的请求失败,原因:证书过期
今天安装yarn时,报错如下: request to https://registry.npm.taobao.org/yarn failed, reason: certificate has expired 原来淘宝镜像过期了,需要重新搞一下 记录一下解决过程: 1.查看当前npm配置 npm config list 2.清…...

Redisson-Lock-加锁原理
归档 GitHub: Redisson-Lock-加锁原理 Unit-Test RedissonLockTest 说明 源码类:RedissonLock // 加锁入口 Override public void lock() { lock(-1, null, false); }/*** 加锁实现 */ private void lock(long leaseTime, TimeUnit unit, boolean interruptib…...

deepspeed win11 安装
目录 git地址: aio报错: 编译 报错 ops已存在: 修改拷贝代码: git地址: Bug Report: Issues Building DeepSpeed on Windows Issue #5679 microsoft/DeepSpeed GitHub aio报错: setup.py 配置变量 os.environ[DISTUTILS_USE_SDK]=1 os.environ[DS_BUILD_AIO]=…...
和extend()的区别)
Python列表函数append()和extend()的区别
Python列表提供了两个容易混淆的追加函数:append()和extend()。它们之间的使用区别如下: list.append(obj):对象进栈。将一个对象作为整体追加到列表最后,返回Nonelist.extend(iter):可迭代对象的元素逐个进栈。将一个…...

Spring AI 实现调用openAi 多模态大模型
什么是多模态? 多模态(Multimodal)指的是数据或信息的多种表现形式。在人工智能领域,我们经常会听到这个词,尤其是在近期大型模型(如GPT-4)开始支持多模态之后。 模态:模态是指数据的一种形式,例如文本、图像、音频等。每一种形式都是一种模态。多模态:多模态就是将…...

3步突破语言障碍:FigmaCN中文插件零基础使用指南
3步突破语言障碍:FigmaCN中文插件零基础使用指南 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?FigmaCN中文插件专为国内设计师…...

如何在不同设备上高效格式化SD卡
对于任何使用相机、智能手机或电脑的人来说,格式化SD卡都是一项基本技能。无论是清理旧文件为新照片腾出空间,还是修复“卡错误”提示,掌握正确的SD卡格式化方法都能确保其使用寿命和性能。接下来,我们将介绍几种格式化方法。第一…...

GPT-5级能力提前落地,ChatGPT 2026新增9大生产级功能,含RAG++动态知识图谱、零样本工作流编排、联邦学习微调接口——错过本轮升级将落后至少18个月
更多请点击: https://intelliparadigm.com 第一章:GPT-5级能力提前落地的技术本质与产业影响 当前,所谓“GPT-5级能力”并非依赖单一巨型模型发布,而是通过模型蒸馏、多专家协同推理(MoE)、实时知识注入与…...

开源项目发布自动化:GitHub与ClawHub技能包一键发布工具详解
1. 项目概述与核心价值如果你和我一样,经常需要将本地开发的项目,尤其是那些为ClawHub平台准备的技能包,发布到GitHub并同步推送到ClawHub技能市场,那你一定对下面这个场景不陌生:每次发布前,都要在脑子里重…...

为什么迅雷下载比浏览器稳?从原理到实战的完整使用手册
目录 为什么迅雷下载比浏览器稳?从原理到实战的完整使用手册 前言 一、核心原理:为什么迅雷下载断网也不怕? 1. 断点续传:下载到一半断网也能续 2. 多线程下载:同时开多个 “下载通道” 3. P2P 分布式加速&#…...

华为OD机试真题 新系统 2026-5-13 多语言实现【查找能被整除的最大整数】
查找能被整除的最大整数(Py/Java /C/C/Js/Go)题解 华为OD新系统机试真题 华为OD新系统上机考试真题 5月13号 100分题型 华为OD机试真题目录点击查看: 华为OD机试真题题库目录|机考题库 算法考点详解 题目内容 给定一个字符串和一个正整数,字符串由大…...
:从模糊关键词到JCR一区论文PDF的全自动链路搭建)
Perplexity + Sage期刊深度协同方案(科研人私藏版):从模糊关键词到JCR一区论文PDF的全自动链路搭建
更多请点击: https://intelliparadigm.com 第一章:Perplexity Sage期刊深度协同方案(科研人私藏版):从模糊关键词到JCR一区论文PDF的全自动链路搭建 核心协同逻辑:语义增强型检索闭环 Perplexity 的实时…...

IT68353:双DP 1.4 + HDMI 2.0 转 HDMI 2.0 单芯片KVM切换方案
一、前言多主机协同办公、电竞直播、工控监控、视频会议等场景,对4K60Hz高画质切换、键鼠共享、Type-C一线通、多路信号兼容、极简外围的需求持续攀升。传统KVM方案普遍采用多芯片拼凑架构,需要DP切换芯片、HDMI切换芯片、USB Hub、PD控制器、外置MCU等多…...

电动汽车充电站控制系统的Intel处理器实践与优化
1. 电动汽车充电站的技术架构解析电动汽车充电站作为新型能源基础设施的核心节点,其技术实现远比传统加油站复杂。一个完整的充电站系统通常包含三个层级:电力转换模块(AC/DC)、控制管理系统(CMS)和云端服务…...

从零掌握生成式AI:开源学习路径与实战项目全解析
1. 项目概述与核心价值最近在GitHub上看到一个名为“panaverse/learn-generative-ai”的项目,作为一个在AI领域摸爬滚打多年的从业者,我立刻被它吸引住了。这个项目直译过来就是“学习生成式AI”,名字非常直接,但它的内容组织和深…...