人工智能--自然语言处理NLP概述

欢迎来到 Papicatch的博客
目录
🍉引言
🍈基本概念
🍈核心技术
🍈常用模型和方法
🍈应用领域
🍈挑战和未来发展
🍉案例分析
🍈机器翻译中的BERT模型
🍈情感分析在市场分析中的应用
🍈智能客服系统中的对话管理
🍉代码示例
🍈分词
🍈 词性标注
🍈命名实体识别
🍈文本生成
🍈情感分析
🍈机器翻译
🍉总结
🍉引言
自然语言处理(Natural Language Processing,NLP)是计算机科学和人工智能领域的一个重要分支,专注于计算机与人类语言的互动。它涉及使用计算机算法来处理和理解人类语言。以下是NLP的一些关键概念和应用。
🍈基本概念
- 语法和句法分析:分析句子的结构,包括词性标注(POS tagging)和依存句法分析(Dependency Parsing)。这些技术帮助理解句子的组成部分和它们之间的关系。
- 语义分析:理解句子的意义,包括词义消歧(Word Sense Disambiguation)和命名实体识别(Named Entity Recognition)。语义分析使计算机能够理解不同词汇在不同上下文中的含义。
- 文本生成:生成自然语言文本,如文本摘要、自动回复、对话系统等。这些应用使得机器可以生成符合语法和语义的自然语言文本。
- 情感分析:分析文本中的情感倾向,包括情感分类和情感强度分析。情感分析在市场分析和舆情监控中有重要应用。
🍈核心技术
- 分词:将文本分解为单独的词或词组,是中文处理中特别重要的一步。
- 词性标注:为每个词分配一个词性标签(如名词、动词等),帮助理解词在句子中的功能。
- 命名实体识别:识别并分类文本中的实体,如人名、地名、组织名等。对于信息抽取和检索非常关键。
- 依存句法分析:分析句子中词与词之间的依存关系,有助于理解复杂句子的结构。
- 语义角色标注:识别句子中各个成分的语义角色,如施事、受事等,帮助深入理解句子含义。
🍈常用模型和方法
- 规则基础方法:基于语言学规则进行处理,但难以扩展和适应不同领域。
- 统计方法:利用大规模语料库和概率模型进行处理,如n-gram模型。
- 机器学习:包括支持向量机、决策树等传统机器学习算法,用于分类和预测。
- 深度学习:尤其是基于神经网络的方法,如循环神经网络(RNN)、长短期记忆网络(LSTM)、Transformer等。深度学习模型能够处理大规模数据并从中学习复杂的模式。
- 预训练模型:如BERT、GPT等,通过在大规模语料库上进行预训练,再进行特定任务的微调,这些模型显著提高了NLP任务的性能。
🍈应用领域
- 机器翻译:如Google翻译,通过自动翻译不同语言之间的文本,使得跨语言交流更加便捷。
- 信息检索:如搜索引擎,通过关键词匹配和自然语言理解提高搜索结果的相关性。
- 文本分类:如垃圾邮件过滤、新闻分类等,帮助自动化处理大量文本数据。
- 对话系统:如智能客服、虚拟助手(如Siri、Alexa等),实现人与机器的自然对话。
- 文本生成:如新闻自动生成、内容创作辅助等,提升内容生成的效率和质量。
- 情感分析:用于市场分析、舆情监控等,帮助理解公众对某些事件或产品的态度。
🍈挑战和未来发展
- 多语言处理:处理不同语言的多样性和复杂性,提高跨语言模型的性能。
- 上下文理解:提高模型对上下文的理解和推理能力,尤其是长文本和复杂句子中的上下文关系。
- 模型解释性:增强模型的可解释性和透明性,使得用户和开发者能够理解模型的决策过程。
- 数据隐私:保护用户数据隐私和安全,尤其在处理敏感信息时。
🍉案例分析
🍈机器翻译中的BERT模型

BERT(Bidirectional Encoder Representations from Transformers)是一种深度学习模型,通过双向编码器表示从大量文本数据中学习语言模式。它在翻译任务中显著提升了翻译的准确性和流畅度。例如,在中英翻译中,BERT模型能够更好地理解和翻译复杂句子结构,提高了翻译质量。
from transformers import MarianMTModel, MarianTokenizer# 加载预训练的MarianMT模型和tokenizer
model_name = 'Helsinki-NLP/opus-mt-en-zh'
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)# 翻译文本
text = "Natural Language Processing is an important field in AI."
translated = model.generate(**tokenizer.prepare_seq2seq_batch([text], return_tensors="pt"))
translated_text = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
print(translated_text)
🍈情感分析在市场分析中的应用

某电商平台使用情感分析技术来监控用户对新产品的反馈。通过分析用户评论,平台能够快速了解产品的优缺点,并进行相应的改进。这种实时的情感分析帮助企业及时响应市场变化,优化产品和服务。以下是一个简单的情感分析示例:
from transformers import pipeline# 加载预训练的情感分析模型
sentiment_analyzer = pipeline('sentiment-analysis')# 示例用户评论
reviews = ["This new product is fantastic! It exceeded my expectations.","I am not satisfied with the quality of this item.","Great value for money. I will definitely recommend it to others.",
]# 分析情感
results = sentiment_analyzer(reviews)
for review, result in zip(reviews, results):print(f"Review: {review}\nSentiment: {result['label']}, Confidence: {result['score']}\n")
🍈智能客服系统中的对话管理

某银行引入了基于NLP的智能客服系统,使用LSTM和Transformer模型处理客户的自然语言查询。智能客服能够理解客户问题并提供准确的回答,大大提升了客户服务效率和满意度。此外,通过对对话数据的分析,银行还能够不断改进和优化客服系统。以下是一个简单的对话系统示例:
from transformers import AutoModelForCausalLM, AutoTokenizer# 加载预训练的DialoGPT模型和tokenizer
model_name = "microsoft/DialoGPT-medium"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)# 初始化对话历史
chat_history_ids = Nonedef chat_with_bot(user_input):global chat_history_idsnew_user_input_ids = tokenizer.encode(user_input + tokenizer.eos_token, return_tensors='pt')# 将新用户输入添加到对话历史中bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if chat_history_ids is not None else new_user_input_ids# 生成响应chat_history_ids = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)# 解码并打印响应response = tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)return response# 与客服系统进行对话
user_input = "I have an issue with my account balance."
response = chat_with_bot(user_input)
print(f"Bot: {response}")user_input = "What is the current interest rate for savings account?"
response = chat_with_bot(user_input)
print(f"Bot: {response}")
🍉代码示例
🍈分词
分词是将文本分解为单独的词或词组。在中文处理中尤其重要,因为中文没有明显的词界定符。
import jieba# 示例文本
text = "自然语言处理是人工智能领域的一个重要分支。"# 使用jieba进行中文分词
words = jieba.lcut(text)
print(words)
🍈 词性标注
词性标注是为每个词分配一个词性标签,帮助理解词在句子中的功能。
import nltk
from nltk import pos_tag, word_tokenize# 下载需要的数据
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')# 示例文本
text = "Natural Language Processing is an important field in AI."# 分词
words = word_tokenize(text)# 词性标注
tagged_words = pos_tag(words)
print(tagged_words)
🍈命名实体识别
命名实体识别(NER)用于识别并分类文本中的实体,如人名、地名、组织名等。
import spacy# 加载预训练的spaCy模型
nlp = spacy.load("en_core_web_sm")# 示例文本
text = "Apple is looking at buying U.K. startup for $1 billion."# 处理文本
doc = nlp(text)# 提取命名实体
for ent in doc.ents:print(ent.text, ent.label_)
🍈文本生成
使用预训练模型生成自然语言文本。以下示例使用Transformers库和GPT模型生成文本。
from transformers import pipeline# 加载预训练的文本生成模型
generator = pipeline('text-generation', model='gpt2')# 示例文本
text = "Natural Language Processing is"# 生成文本
generated_text = generator(text, max_length=50, num_return_sequences=1)
print(generated_text)
🍈情感分析
情感分析用于分析文本中的情感倾向,以下示例使用Transformers库的情感分析模型。
from transformers import pipeline# 加载预训练的情感分析模型
sentiment_analyzer = pipeline('sentiment-analysis')# 示例文本
text = "I love using natural language processing for text analysis!"# 情感分析
result = sentiment_analyzer(text)
print(result)
🍈机器翻译
使用预训练模型进行机器翻译。以下示例将英文文本翻译成法文。
from transformers import pipeline# 加载预训练的翻译模型
translator = pipeline('translation_en_to_fr')# 示例文本
text = "Natural Language Processing is a fascinating field."# 翻译文本
translated_text = translator(text)
print(translated_text)
🍉总结
NLP是一个跨学科领域,结合了计算机科学、语言学、数学和认知科学的知识,随着深度学习和大数据技术的发展,NLP的应用越来越广泛和深入。未来,随着技术的不断进步,NLP将在更多领域展现其潜力,推动人机交互的进一步发展。

相关文章:
人工智能--自然语言处理NLP概述
欢迎来到 Papicatch的博客 目录 🍉引言 🍈基本概念 🍈核心技术 🍈常用模型和方法 🍈应用领域 🍈挑战和未来发展 🍉案例分析 🍈机器翻译中的BERT模型 🍈情感分析在…...
基于Java微信小程序火锅店点餐系统设计和实现(源码+LW+调试文档+讲解等)
💗博主介绍:✌全网粉丝10W,CSDN作者、博客专家、全栈领域优质创作者,博客之星、平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 🌟文末获取源码数据库🌟感兴趣的可以先收藏起来,还…...

SpringCloud_GateWay服务网关
网关作用 Gateway网关是我们服务的守门神,所有微服务的统一入口。 网关的核心功能特性: 请求路由和负载均衡:一切请求都必须先经过gateway,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务&a…...

使用Dropout大幅优化PyTorch模型,实现图像识别
大家好,在机器学习模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络时,过拟合具体表现在模型训练数据损失函数较小,预测准确率较高,但是在测…...

Vue3中的常见组件通信(超详细版)
Vue3中的常见组件通信 概述 在vue3中常见的组件通信有props、mitt、v-model、 r e f s 、 refs、 refs、parent、provide、inject、pinia、slot等。不同的组件关系用不同的传递方式。常见的撘配形式如下表所示。 组件关系传递方式父传子1. props2. v-model3. $refs4. 默认…...
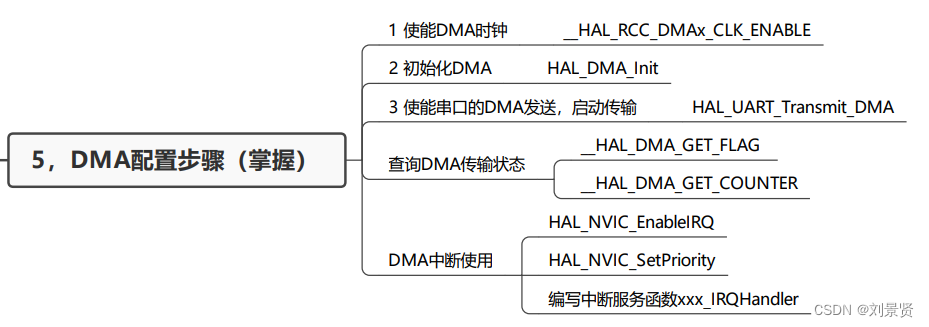
Stm32的DMA的学习
一,介绍 二,DMA框图 三,DMA通道 四,相关HAL库函数 五,配置DMA 六,Stm32CubeMX配置 【13.1】减少CPU传输负载 DMA直接存储器访问—Kevin带你读《STM32Cube高效开发教程基础篇》_哔哩哔哩_bilibili...
)
应用安全(补充)
Nessus是目前全世界最多人使用的系统漏洞扫描与分析软件。NMAP是一个网络连接端扫描软件,用来扫描网上电脑开放的网络连接端。X-SCAN安全漏洞扫描工具AppScan是IBM的一款web安全扫描工具,可以利用爬虫技术进行网站安全渗透测试,根据网站入口自…...

鸿蒙开发Ability Kit(程序框架服务):【FA模型切换Stage模型指导】 app和deviceConfig的切换
app和deviceConfig的切换 为了便于开发者维护应用级别的属性配置,Stage模型将config.json中的app和deviceConfig标签提取到了app.json5中进行配置,并对部分标签名称进行了修改,具体差异见下表。 表1 配置文件app标签差异对比 配置项FA模型…...

通过命令行配置调整KVM的虚拟网络
正文共:1234 字 20 图,预估阅读时间:2 分钟 在上篇文章中(最小化安装的CentOS7部署KVM虚拟机),我们介绍了如何在最小化安装的CentOS 7系统中部署KVM组件和相关软件包。因为没有GUI图形界面,我们…...

Apache POI操作excel
第1部分:引言 1.1 Apache POI简介 Apache POI是一个开源的Java库,用于处理Microsoft Office文档。自2001年首次发布以来,它已经成为Java社区中处理Office文档事实上的标准。Apache POI支持HSSF(用于旧版本的Excel格式࿰…...

Python错误集锦:faker模块生成xml文件时提示:`xml` requires the `xmltodict` Python library
原文链接:http://www.juzicode.com/python-error-faker-exceptions-unsupportedfeature-xml-requires-the-xmltodict-python-library 错误提示: faker模块生成xml文件时提示: xml requires the xmltodict Python library Traceback (most r…...

Vue3-尚硅谷笔记
1. Vue3简介 2020年9月18日,Vue.js发布版3.0版本,代号:One Piece(n 经历了:4800次提交、40个RFC、600次PR、300贡献者 官方发版地址:Release v3.0.0 One Piece vuejs/core 截止2023年10月,最…...

RockChip Android12 System之MultipleUsers
一:概述 System中的MultipleUsers不同于其他Preference采用system_dashboard_fragment.xml文件进行加载,而是采用自身独立的xml文件user_settings.xml加载。 二:Multiple Users 1、Activity packages/apps/Settings/AndroidManifest.xml <activityandroid:name="S…...

第12天:前端集成与Django后端 - 用户认证与状态管理
第12天:前端集成与Django后端 - 用户认证与状态管理 目标 整合Django后端与Vue.js前端,实现用户认证和应用状态管理。 任务概览 设置Django后端用户认证。创建Vue.js前端应用。使用Vuex进行状态管理。实现前端与后端的用户认证流程。 详细步骤 1. …...

在ROS2中蓝牙崩溃的原因分析
在ROS2中,如果蓝牙模块没有成功启动,可能的原因有几个方面: 1. **硬件问题**:首先需要确认蓝牙硬件本身是否正常工作,包括检查蓝牙模块是否正确连接到系统,以及模块是否存在物理损坏。 2. **驱动问题**&a…...

【PythonWeb开发】Flask中间件钩子函数实现封IP
在 Flask 框架中, 提供了几种类型的钩子(类似于Django的中间件),它们是在请求的不同阶段自动调用的函数。这些钩子让你能够对请求和响应的处理流程进行扩展,而无需修改核心代码。 Flask钩子的四种类型 before_first_r…...

可以一键生成热点营销视频的工具,建议收藏
在当今的商业环境中,热点营销已经成为了一种非常重要的营销策略。那么,什么是热点营销呢?又怎么做热点营销视频呢? 最近高考成绩慢慢公布了,领导让结合“高考成绩公布”这个热点,做一个关于企业或产品的营销…...

Unity Meta Quest 开发:关闭 MR 应用的安全边界
社区链接: SpatialXR社区:完整课程、项目下载、项目孵化宣发、答疑、投融资、专属圈子 📕教程说明 这期教程我将介绍如何在应用中关闭 Quest 系统的安全边界。 视频讲解: https://www.bilibili.com/video/BV1Gm42157Zi …...
)
4.sql注入攻击(OWASP实战训练)
4.sql注入攻击(OWASP实战训练) 引言1,实验环境owasp,kali Linux。2,sql注入危害3,sql基础回顾4,登录owasp5,查询实例(1)简单查询实例(2࿰…...

前端Web开发HTML5+CSS3+移动web视频教程 Day1
链接 HTML 介绍 写代码的位置:VSCode 看效果的位置:谷歌浏览器 安装插件 open in browser: 接下来要保证每次用 open in browser 打开的是谷歌浏览器。只需要将谷歌浏览器变为默认的浏览器就可以了。 首先进入控制面板,找到默…...

大语言模型底层逻辑:从LM到Agent的完整工作流解析!
本文深入剖析了大语言模型(LM)的核心架构与工作原理,重点介绍了Token作为数据处理单元、Context作为临时记忆体的作用,以及Prompt、Tool、MCP等关键组件如何协同运作。文章还探讨了Agent的自主决策系统与Agent Skill的任务定制机制…...

Nooploop TOFSense激光测距模块:从快速上手指南到多平台实战应用
1. Nooploop TOFSense激光测距模块初体验 第一次拿到TOFSense激光测距模块时,我完全被它的小巧体积震惊了。这个比火柴盒大不了多少的装置,居然能实现0.1-12米的精确测距,精度高达1cm!作为一名经常在无人机项目中折腾的嵌入式工程…...

终极Windows热键冲突解决方案:Hotkey Detective一键定位占用程序
终极Windows热键冲突解决方案:Hotkey Detective一键定位占用程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

什么是大模型:概念、分类与当前主流模型全梳理
什么是大模型? 大模型,通常指的是参数规模很大、训练数据很多、具备较强通用能力的人工智能模型。它之所以叫“大”,通常体现在几个方面: 第一,参数量大。 从早期的几千万、几亿参数,发展到几十亿、上百亿&…...

保姆级图解:NCCL的bootstrap网络连接到底是怎么“手拉手”建起来的?
保姆级图解:NCCL的bootstrap网络连接到底是怎么"手拉手"建起来的? 想象一群小朋友要围成一个圆圈玩游戏,但彼此都不认识。NCCL的bootstrap网络建立过程,就像这个"手拉手成圈"的奇妙旅程。本文将用最直观的类…...

如何利用 Taotoken 为 Hermes Agent 提供自定义模型支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何利用 Taotoken 为 Hermes Agent 提供自定义模型支持 对于使用 Hermes Agent 构建复杂应用的开发者而言,其强大的自…...

巨头转身难的地方,我们的星辰大海:开发版机巢,为千行百业而生
未来的低空经济图景是怎样的?它绝不仅仅是几架无人机在天上飞。 未来的城市与能源基础设施中,将隐藏着无数形态各异、能力专精的“机巢”。它们将像毛细血管一样渗透在城市的各个角落,定时自动穿梭,替代人力进行精细化巡检&#x…...

深度解析ArtPlayer.js:5个高级视频播放器实战技巧
深度解析ArtPlayer.js:5个高级视频播放器实战技巧 【免费下载链接】ArtPlayer :art: ArtPlayer.js is a modern and full featured HTML5 video player 项目地址: https://gitcode.com/gh_mirrors/ar/ArtPlayer ArtPlayer.js是一款功能全面且高度可定制的现代…...

GenAIScript:用脚本化AI工作流提升代码生成效率与工程化实践
1. 项目概述:当AI遇上代码生成,GenAIScript带来了什么?如果你最近在关注AI如何改变开发工作流,特别是微软在AI领域的动作,那么microsoft/genaiscript这个项目绝对值得你花时间深入研究。这不仅仅是一个简单的代码生成工…...

书匠策AI官网www.shujiangce.com|别再硬扛了!这个AI把写期刊论文变成了“填空题“
微信公众号搜一搜「书匠策AI」,三分钟治好你的论文拖延症! 各位还在深夜对着Word文档发呆的同学们,今天我不讲道理,只讲工具。 你们有没有想过一个问题:为什么写期刊论文这件事,让90%的人觉得痛苦…...