以Bert训练为例,测试torch不同的运行方式,并用torch.profile+HolisticTraceAnalysis分析性能瓶颈
以Bert训练为例,测试torch不同的运行方式,并用torch.profile+HolisticTraceAnalysis分析性能瓶颈
- 1.参考链接:
- 2.性能对比
- 3.相关依赖或命令
- 4.测试代码
- 5.HolisticTraceAnalysis代码
- 6.可视化
- A.优化前
- B.优化后
以Bert训练为例,测试torch不同的运行方式,并用torch.profile+HolisticTraceAnalysis分析性能瓶颈
1.参考链接:
- Accelerating PyTorch with CUDA Graphs
- BERT
- torch-compiler
2.性能对比
| 序号 | 运行方式 | build耗时(s) | warmup耗时(s) | 运行耗时(w) | 备注 |
|---|---|---|---|---|---|
| 1 | 普通模式 | 0.70 | max:0.0791 min:0.0358 std:0.0126 mean:0.0586 | CPU Bound | |
| 2 | torch.cuda.CUDAGraph() | 0.01 | max:0.0109 min:0.0090 std:0.0006 mean:0.0094 | Kernel Bound | |
| 3 | torch.compile(“cudagraphs”) | 0.7126 | 10.7256 | max:3.9467 min:0.0197 std:1.1683 mean:0.4590 | |
| 4 | torch.compile(“inductor”) | 0.0005 | 45.1444 | max:5.9465 min:0.0389 std:1.7684 mean:0.6415 |
3.相关依赖或命令
# 安装pytorch
pip install torch==2.3.1 -i https://pypi.tuna.tsinghua.edu.cn/simple# 安装HTA
git clone https://github.com/facebookresearch/HolisticTraceAnalysis.git
cd HolisticTraceAnalysis
git submodule update --init
pip install -r requirements.txt
pip install -e .# 运行jupyter
pip install jupyter
jupyter notebook --allow-root --no-browser --ip=192.168.1.100 --port 8080
4.测试代码
import os
import warnings
warnings.filterwarnings("ignore")
import copy
import sys
import torch
from tqdm import tqdm
from torch.profiler import profile
import time
from typing import Final, Any, Callable
import random
import numpy as np
import os
import requests
import importlib.util
import sys
import jsondef download_module(url, destination_path):response = requests.get(url)response.raise_for_status()with open(destination_path, 'wb') as f:f.write(response.content)def module_from_path(module_name, file_path):spec = importlib.util.spec_from_file_location(module_name, file_path)module = importlib.util.module_from_spec(spec)sys.modules[module_name] = modulespec.loader.exec_module(module)return moduledef load_or_download_module(module_url, module_name, cache_dir=".cache"):if not os.path.exists(cache_dir):os.makedirs(cache_dir)destination_path = os.path.join(cache_dir, module_name + ".py")if not os.path.isfile(destination_path):download_module(module_url, destination_path)module = module_from_path(module_name, destination_path)return moduleimport sys
sys.path.append(".cache/")module_url = "https://raw.githubusercontent.com/NVIDIA/DeepLearningExamples/master/PyTorch/LanguageModeling/BERT/file_utils.py"
module_name = "file_utils"
load_or_download_module(module_url, module_name)module_url = "https://raw.githubusercontent.com/NVIDIA/DeepLearningExamples/master/PyTorch/LanguageModeling/BERT/modeling.py"
module_name = "modeling"
modeling = load_or_download_module(module_url, module_name)def fix_gelu_bug(fn):def wrapper(tensor, *args, **kwargs):return fn(tensor)return wrapper
torch.nn.functional.gelu=fix_gelu_bug(torch.nn.functional.gelu)class SyncFreeStats :def __init__(self) :self.host_stats = {}self.device_stats = {}self.device_funcs = {}def add_stat(self, name, dtype=torch.int32, device_tensor=None, device_func=None) :if device_tensor is not None :assert dtype == device_tensor.dtype, "Error: dtype do not match: {} {}".format(dtype, device_tensor.dtype)self.host_stats[name] = torch.zeros(1, dtype=dtype).pin_memory()self.device_stats[name] = device_tensorself.device_funcs[name] = device_funcdef copy_from_device(self) :for name in self.host_stats.keys() :# Apply device function to device statif self.device_stats[name] is not None and self.device_funcs[name] is not None:self.host_stats[name].copy_(self.device_funcs[name](self.device_stats[name]), non_blocking=True)elif self.device_stats[name] is not None :self.host_stats[name].copy_(self.device_stats[name], non_blocking=True)elif self.device_funcs[name] is not None :self.host_stats[name].copy_(self.device_funcs[name](), non_blocking=True)def host_stat(self, name) :assert name in self.host_statsreturn self.host_stats[name]def host_stat_value(self, name) :assert name in self.host_statsreturn self.host_stats[name].item()def update_host_stat(self, name, tensor) :self.host_stats[name] = tensordef device_stat(self, name) :assert self.device_stats[name] is not Nonereturn self.device_stats[name]def update_device_stat(self, name, tensor) :self.device_stats[name] = tensorclass BertPretrainingCriterion(torch.nn.Module):sequence_output_is_dense: Final[bool]def __init__(self, vocab_size, sequence_output_is_dense=False):super(BertPretrainingCriterion, self).__init__()self.loss_fn = torch.nn.CrossEntropyLoss(ignore_index=-1)self.vocab_size = vocab_sizeself.sequence_output_is_dense = sequence_output_is_densedef forward(self, prediction_scores, seq_relationship_score, masked_lm_labels, next_sentence_labels):if self.sequence_output_is_dense:# prediction_scores are already densemasked_lm_labels_flat = masked_lm_labels.view(-1)mlm_labels = masked_lm_labels_flat[masked_lm_labels_flat != -1]masked_lm_loss = self.loss_fn(prediction_scores.view(-1, self.vocab_size), mlm_labels.view(-1))else:masked_lm_loss = self.loss_fn(prediction_scores.view(-1, self.vocab_size), masked_lm_labels.view(-1))next_sentence_loss = self.loss_fn(seq_relationship_score.view(-1, 2), next_sentence_labels.view(-1))total_loss = masked_lm_loss + next_sentence_lossreturn total_lossdef setup_model_optimizer_data(device="cuda"):train_batch_size=1max_seq_length=128config=modeling.BertConfig(21128)sequence_output_is_dense=Falsemodel = modeling.BertForPreTraining(config, sequence_output_is_dense=sequence_output_is_dense)model=model.half()model.train().to(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.1)criterion = BertPretrainingCriterion(config.vocab_size, sequence_output_is_dense=sequence_output_is_dense).to(device)batch = {'input_ids': torch.ones(train_batch_size, max_seq_length, dtype=torch.int64, device=device),'token_type_ids': torch.ones(train_batch_size, max_seq_length, dtype=torch.int64, device=device),'attention_mask': torch.ones(train_batch_size, max_seq_length, dtype=torch.int64, device=device),'labels': torch.ones(train_batch_size, max_seq_length, dtype=torch.int64, device=device),'next_sentence_labels': torch.ones(train_batch_size, dtype=torch.int64, device=device),}stats = SyncFreeStats()stats.add_stat('average_loss', dtype=torch.float32, device_tensor=torch.zeros(1, dtype=torch.float32, device=device))return model,optimizer,criterion,batch,statsdef train_step(model,optimizer,criterion,batch,stats):optimizer.zero_grad(set_to_none=True)prediction_scores,seq_relationship_score=model(input_ids=batch['input_ids'],token_type_ids=batch['token_type_ids'],attention_mask=batch['attention_mask'],masked_lm_labels=batch['labels'])loss = criterion(prediction_scores, seq_relationship_score, batch['labels'], batch['next_sentence_labels'])stats.device_stat('average_loss').add_(loss.detach())loss.backward()optimizer.step() def reset_seed():random.seed(0)np.random.seed(0)torch.manual_seed(0)torch.cuda.manual_seed(0)def stat(data):return f"max:{np.max(data):.4f} min:{np.min(data):.4f} std:{np.std(data):.4f} mean:{np.mean(data):.4f}"def prof_bert_native():reset_seed()activities=[torch.profiler.ProfilerActivity.CPU]activities.append(torch.profiler.ProfilerActivity.CUDA)model,optimizer,criterion,batch,stats=setup_model_optimizer_data()t0=time.time()train_step(model,optimizer,criterion,batch,stats) torch.cuda.synchronize()t1=time.time()print(f"warmup:{t1-t0:.2f}")latency=[] with profile(activities=activities,record_shapes=True,with_stack=True,with_modules=True,schedule=torch.profiler.schedule(wait=1,warmup=1,active=3,repeat=0),with_flops=True,profile_memory=True) as prof:for i in range(10):t0=time.time()train_step(model,optimizer,criterion,batch,stats) torch.cuda.synchronize()t1=time.time()latency.append(t1-t0)prof.step()stats.copy_from_device() print(f"native average_loss:{stats.host_stat_value('average_loss'):.4f} {stat(latency)}")prof.export_chrome_trace("prof_bert_native.json")def prof_bert_cudagraph():reset_seed()activities=[torch.profiler.ProfilerActivity.CPU]activities.append(torch.profiler.ProfilerActivity.CUDA)model,optimizer,criterion,batch,stats=setup_model_optimizer_data()# Warmup Steps - includes jitting fusionsside_stream = torch.cuda.Stream()side_stream.wait_stream(torch.cuda.current_stream())with torch.cuda.stream(side_stream):for _ in range(11):train_step(model,optimizer,criterion,batch,stats)torch.cuda.current_stream().wait_stream(side_stream)# Capture Graphfull_cudagraph = torch.cuda.CUDAGraph()with torch.cuda.graph(full_cudagraph):train_step(model,optimizer,criterion,batch,stats)print("build done")t0=time.time()full_cudagraph.replay()torch.cuda.synchronize()t1=time.time()print(f"warmup:{t1-t0:.2f}")latency=[]with profile(activities=activities,record_shapes=True,with_stack=True,with_modules=True,schedule=torch.profiler.schedule(wait=1,warmup=1,active=3,repeat=0),with_flops=True,profile_memory=True) as prof:for i in range(10):t0=time.time()full_cudagraph.replay()torch.cuda.synchronize()t1=time.time()latency.append(t1-t0)prof.step()stats.copy_from_device() print(f"cudagraph average_loss:{stats.host_stat_value('average_loss'):.4f} {stat(latency)}")prof.export_chrome_trace("prof_bert_cudagraph.json")def prof_bert_torchcompiler(backend):reset_seed()activities=[torch.profiler.ProfilerActivity.CPU]activities.append(torch.profiler.ProfilerActivity.CUDA)model,optimizer,criterion,batch,stats=setup_model_optimizer_data()latency=[] t0=time.time()new_fn = torch.compile(train_step, backend=backend)t1=time.time()print(f"torchcompiler_{backend} build:{t1-t0:.4f}s")new_fn(model,optimizer,criterion,batch,stats) torch.cuda.synchronize()t2=time.time()print(f"torchcompiler_{backend} warmup:{t2-t1:.4f}s")with profile(activities=activities,record_shapes=True,with_stack=True,with_modules=True,schedule=torch.profiler.schedule(wait=1,warmup=1,active=3,repeat=0),with_flops=True,profile_memory=True) as prof:for i in range(10):t0=time.time()new_fn(model,optimizer,criterion,batch,stats) torch.cuda.synchronize()t1=time.time()latency.append(t1-t0)prof.step()stats.copy_from_device()print(f"torchcompiler_{backend} average_loss:{stats.host_stat_value('average_loss'):.4f} {stat(latency)}")prof.export_chrome_trace(f"prof_bert_torchcompiler_{backend}.json")os.environ['LOCAL_RANK']="0"
os.environ['RANK']="0"
os.environ['WORLD_SIZE']="1"
os.environ['MASTER_ADDR']="localhost"
os.environ['MASTER_PORT']="6006"import torch.distributed as dist
dist.init_process_group(backend='nccl')
rank=torch.distributed.get_rank()prof_bert_native()
prof_bert_cudagraph()
prof_bert_torchcompiler("cudagraphs")
prof_bert_torchcompiler("inductor")
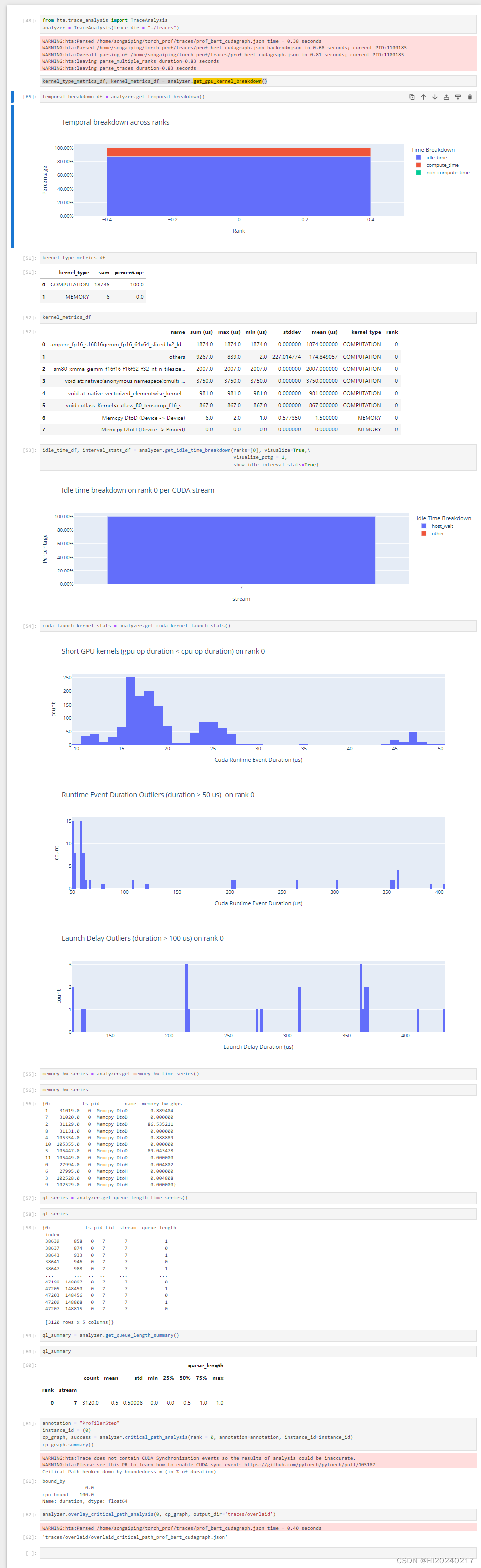
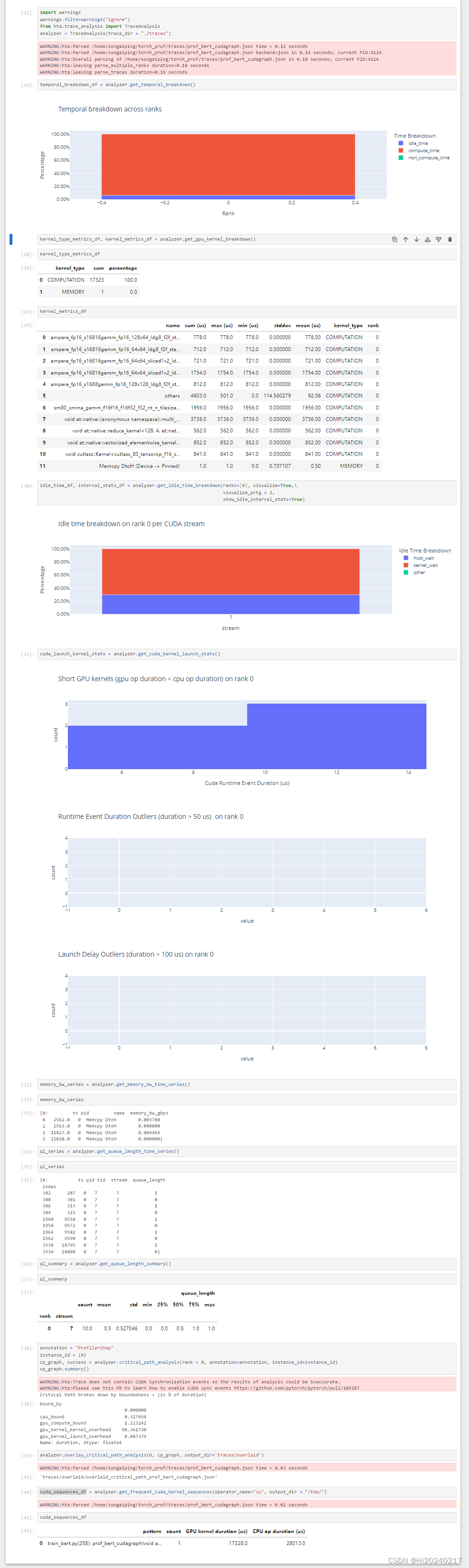
5.HolisticTraceAnalysis代码
#!/usr/bin/env python
# coding: utf-8
# In[25]:
import warnings
warnings.filterwarnings("ignore")
from hta.trace_analysis import TraceAnalysis
analyzer = TraceAnalysis(trace_dir = "./traces")
# In[26]:
temporal_breakdown_df = analyzer.get_temporal_breakdown()
# kernel_type_metrics_df, kernel_metrics_df = analyzer.get_gpu_kernel_breakdown()
# In[28]:
kernel_type_metrics_df
# In[29]:
kernel_metrics_df
# In[30]:
idle_time_df, interval_stats_df = analyzer.get_idle_time_breakdown(ranks=[0], visualize=True,\visualize_pctg = 1,show_idle_interval_stats=True)
# In[31]:
cuda_launch_kernel_stats = analyzer.get_cuda_kernel_launch_stats()
# In[32]:
memory_bw_series = analyzer.get_memory_bw_time_series()
# In[33]:
memory_bw_series
# In[34]:
ql_series = analyzer.get_queue_length_time_series()
# In[35]:
ql_series
# In[36]:
ql_summary = analyzer.get_queue_length_summary()
# In[37]:
ql_summary
# In[38]:
annotation = "ProfilerStep"
instance_id = (0)
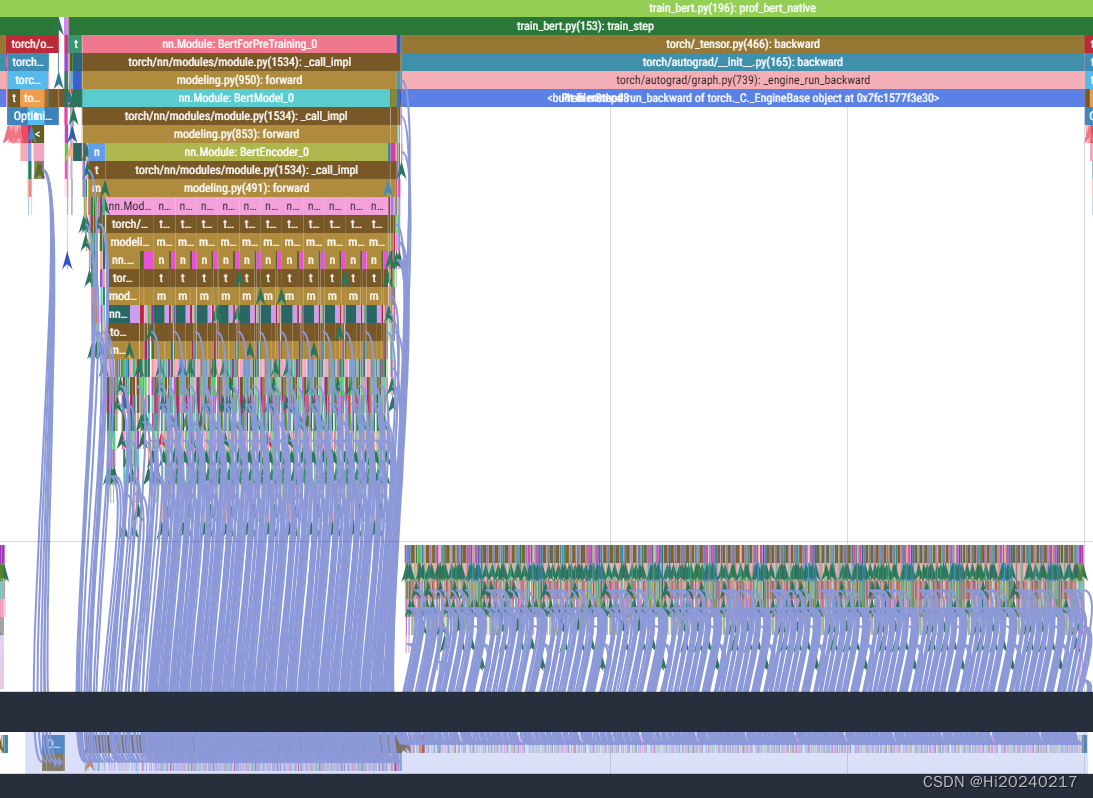
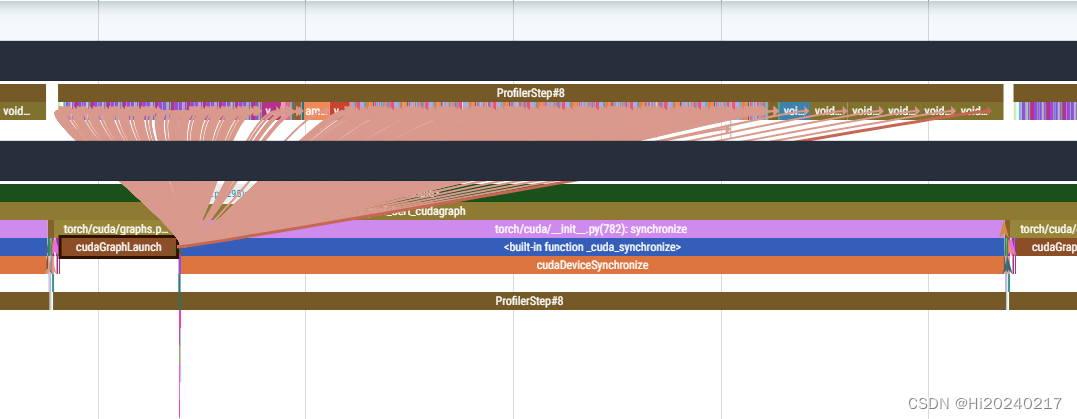
cp_graph, success = analyzer.critical_path_analysis(rank = 0, annotation=annotation, instance_id=instance_id)
cp_graph.summary()
# In[39]:
analyzer.overlay_critical_path_analysis(0, cp_graph, output_dir='traces/overlaid')
# In[40]:
cuda_sequences_df = analyzer.get_frequent_cuda_kernel_sequences(operator_name="cu", output_dir = "/tmp/")
# In[42]:
cuda_sequences_df
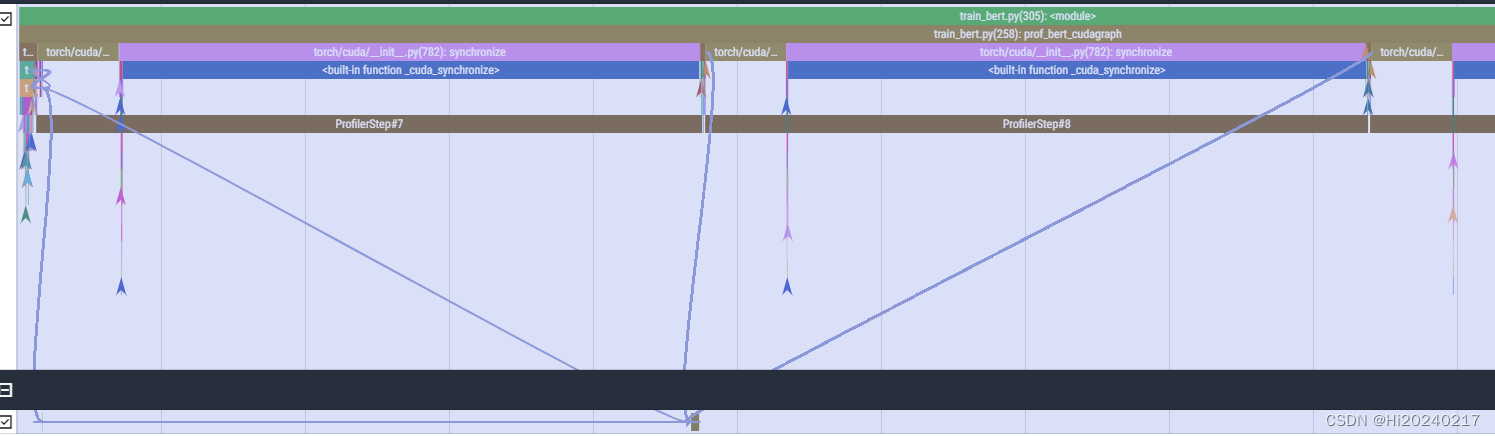
6.可视化
A.优化前
B.优化后
相关文章:
以Bert训练为例,测试torch不同的运行方式,并用torch.profile+HolisticTraceAnalysis分析性能瓶颈
以Bert训练为例,测试torch不同的运行方式,并用torch.profileHolisticTraceAnalysis分析性能瓶颈 1.参考链接:2.性能对比3.相关依赖或命令4.测试代码5.HolisticTraceAnalysis代码6.可视化A.优化前B.优化后 以Bert训练为例,测试torch不同的运行方式,并用torch.profileHolisticTra…...

地球地图:快速进行先进土地监测和气候评估的新工具Earth Map
地球地图:快速进行先进土地监测和气候评估的新工具 这个工具是居于GEE 开发的多功能的一个APP应用,主要进行土地监测和气候评估 Earth Map 什么是地球地图? 地球地图是联合国粮食及农业组织(粮农组织)在粮农组织与谷歌合作框架内开发的一个创新、免费和开放源码的工具。…...
6.22套题
B. Dark 题意:每次能在数列中能使相邻两个数-1,求当数列没有连续非0值的最小贡献 解法:设表示前i个数中前i-1个数是否为0,当前数是j的最小贡献。表示i1以后减掉d的最小贡献。 C. 幸运值 D. 凤凰院真凶...

openEuler搭建hadoop Standalone 模式
Standalone 升级软件安装常用软件关闭防火墙修改主机名和IP地址修改hosts配置文件下载jdk和hadoop并配置环境变量配置ssh免密钥登录修改配置文件初始化集群windows修改hosts文件测试 1、升级软件 yum -y update2、安装常用软件 yum -y install gcc gcc-c autoconf automake…...

nginx更新https/ssl证书的步骤
一、上传nginx证书到服务器 上传步骤略。。。 二、更新证书 (一)确认nginx的安装目录 我这里的环境是/etc/nginx/ (二)确认nginx的证书目录 查看/etc/nginx/nginx.conf,证书目录就在/etc/nginx目录下 将新的证书tes…...

【Android面试八股文】说一说Handler的sendMessage和postDelay的区别?
文章目录 一、`sendMessage` 方法1.1 主要用法1.2 适用场景二、`postDelayed` 方法2.1 主要用法2.2 适用场景三、 区别总结3.1 区别3.2 本质上有差别吗?四、实例对比4.1 使用`sendMessage`4.2 使用`postDelayed`五、结论Handler类在Android中用于消息传递和任务调度。 sendMe…...
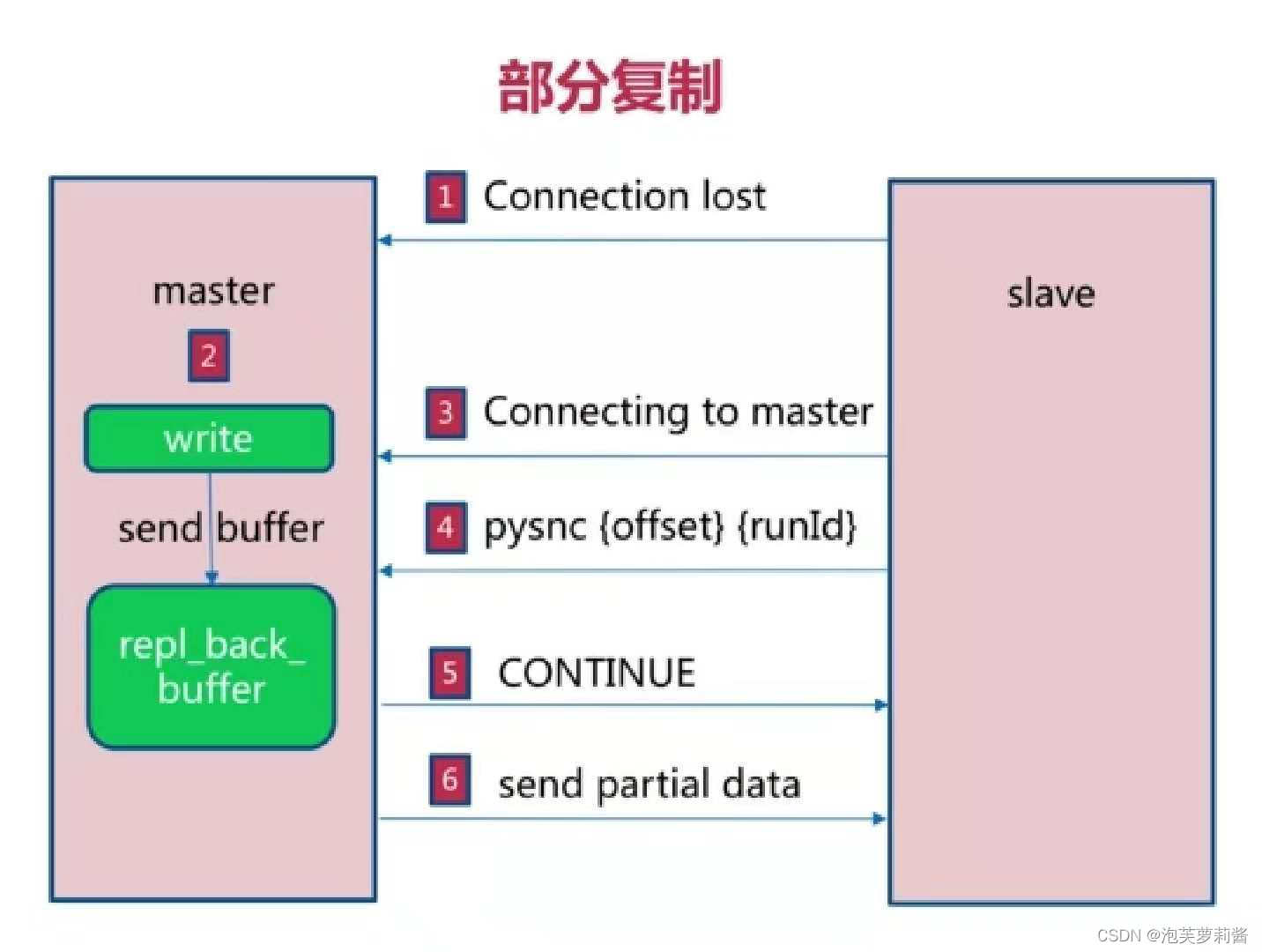
Java学习 - Redis主从复制
主从复制是什么 用于建立一个和主数据库完全一样的数据库环境,称为从数据库 主从复制的作用 数据备份读写分离 主从复制使用方式 通过slaveof命令 创建从节点 redis-slave> slaveof 127.0.0.1 6379取消从节点 redis-slave> slaveof no one通过配置 配置…...

图的拓扑排序
图的拓扑排序(Topological Sorting)是一种线性排序,用于有向无环图(Directed Acyclic Graph,DAG)。拓扑排序将图中的顶点排成一个线性序列,使得对于每一条有向边 (u, v),顶点 u 都排…...

windows USB 设备驱动开发-总章
通用串行总线 (USB) 提供可扩展的即插即用串行接口,确保外围设备的标准、低成本的连接。 USB 设备包括键盘、鼠标、游戏杆、打印机、扫描仪、存储设备、调制解调器、视频会议摄像头等。USB-IF 是一个特别兴趣组 (SIG),负责维护官方 USB 规范、测试规范和…...
springboot解析自定义yml文件
背景 公司产品微服务架构下有十几个模块,几乎大部分模块都要连接redis。每次在客户那里部署应用,都要改十几遍配置,太痛苦了。当然可以用nacos配置中心的功能,配置公共参数。不过我是喜欢在应用级别上解决问题,因为并不…...

【C/C++】静态函数调用类中成员函数方法 -- 最快捷之一
背景 注册回调函数中,回调函数是一个静态函数。需要调用类对象中的一个成员函数进行后续通知逻辑。 方案 定义全局指针,用于指向类对象this指针 static void *s_this_obj;类构造函数中,将全局指针指向所需类的this指针 s_this_obj this…...

佣金的定义和类型
1. 佣金的定义 基本定义:佣金是指在商业交易中,代理人或中介机构为促成交易所获得的报酬。它通常是按交易金额的一定比例计算和支付的。支付方式:佣金可以是固定金额,也可以是交易金额的百分比。 2. 佣金的类型 销售佣金&#…...
)
python数据分析实训任务二(‘风力风向’)
import numpy as np import matplotlib.pyplot as plt # 数据 labelsnp.array([东风, 东北风, 北风, 西北风, 西风, 西南风, 南风, 东南风]) statsnp.array([2.1, 2, 0, 3, 1.5, 3, 6, 4]) # 将角度转换为弧度 anglesnp.linspace(0, 2*np.pi, len(labels), endpointFalse).toli…...
Java技术栈总结:数据库MySQL篇
一、慢查询 1、常见情形 聚合查询 多表查询 表数据量过大查询 深度分页查询 2、定位慢查询 方案一、开源工具 调试工具:Arthas运维工具:Prometheus、Skywalking 方案二、MySQL自带慢日志 在MySQL配置文件 /etc/my.conf 中配置: # …...

vue-cli 项目打包优化-基础篇
1、项目打包完运行空白 引用资源路径问题,打包完的【index.html】文件引用其他文件的引用地址不对 参考配置:https://cli.vuejs.org/zh/config 修改vue.config.js ,根据与 后端 或 运维 沟通修改 module.export {// 默认 publicPath: //…...

24/06/26(1.1129)动态内存
strtok 字符串分割函数 #include<stdio.h> int main(){ char str[] "this,a sample string."; char* sep ","; char* pch strtok(str, sep); printf("%s\n", pch); while (pch ! NULL){ printf("%s\…...
基于 elementUI / elementUI plus,实现 主要色(主题色)的一件换色(换肤)
一、效果图 二、方法 改变elementUI 的主要色 --el-color-primary 为自己选择的颜色,核心代码如下: // 处理主题样式 export function handleThemeStyle(theme) {document.documentElement.style.setProperty(--el-color-primary, theme) } 三、全部代…...

js 计算某个日期加月份最后月份不会增加或者跳变
/** * * param {*} dateString 原来日期 2023-12-31 * param {*} months 加月份 2 * returns 2024-02-29 */ export function getDateByMonth(dateString, months0) { console.log(1); let oldMonths dateString.substring(0,7); let day dateString.substring(8); let …...

Git简介与详细教程
一、简介 什么是Git? Git是一款分布式版本控制系统,由Linux之父Linus Torvalds于2005年开发。它旨在快速、高效地处理从小型到大型项目的所有内容。Git与传统的版本控制系统相比,具备显著的优势,主要体现在其分布式架构、强大的…...
创建OpenWRT虚拟机
环境:Ubuntu 2204,VM VirtualBox 7.0.18 安装必备软件包: sudo apt update sudo apt install subversion automake make cmake uuid-dev gcc vim build-essential clang flex bison g gawk gcc-multilib g-multilib gettext git libncurses…...

长期使用Taotoken Token Plan套餐在项目开发中的成本控制体会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐在项目开发中的成本控制体会 在中长期AI项目的开发实践中,成本的可预测性与可控性是团…...

从遥感图像到文字识别:手把手教你用旋转目标检测搞定那些‘歪着’的目标
旋转目标检测实战:从遥感图像到倾斜文本的高效解决方案 在计算机视觉领域,目标检测技术已经取得了长足进步,但传统水平边界框检测方法在面对旋转目标时往往表现不佳。无论是遥感图像中的飞机、船舶,还是自然场景中倾斜的文本&…...

基于 4SAPI 的企业文档智能处理系统:效率提升 20 倍,信息提取准确率 95%
前言 在数字化转型的今天,企业积累了海量的非结构化文档数据,包括合同、财务报表、技术手册、产品说明书、会议纪要、法律文件等。这些文档中蕴含着企业最核心的知识和资产,但传统的人工文档处理模式已经成为企业数字化的最大瓶颈࿱…...

蓝牙窃密攻防实战:从协议漏洞到固件后门,国家安全部警示的近场威胁全解析
2026年5月11日,国家安全部官方发布重磅警示,明确指出蓝牙设备已成为不法分子实施近距离窃密、监听、跟踪的"隐形獠牙"。从日常使用的无线耳机、智能手表,到办公场景的蓝牙键鼠、会议音箱,再到工业控制中的蓝牙传感器&am…...

基于reflectt-node的WebSocket RPC实践:构建实时协作待办应用
1. 项目概述与核心价值 最近在折腾一个需要实时双向通信的Web应用,传统的轮询和长轮询方案在性能和资源消耗上总感觉差那么点意思。后来把目光投向了WebSocket,但原生WebSocket的API相对底层,自己管理连接、心跳、重连、消息序列化这些琐事&a…...

人机冲突类型学:基于意义行为原生论与自感痕迹论的系统性分析
人机冲突类型学:基于意义行为原生论与自感痕迹论的系统性分析 摘要:本文旨在构建一种新的人机冲突类型学,其理论基础是岐金兰的“意义行为原生论”与“自感痕迹论”。不同于现有研究从外部功能或伦理原则出发分类冲突,本文提出&am…...

产品经理必备:Gemini3.1Pro高效撰写需求文档指南
做产品经理的人,大多都写过需求文档,但真正让人头疼的,往往不是“写”,而是“写得清楚”。 需求背景要交代,目标要明确,流程要完整,边界条件要说明,异常情况还不能漏,最后…...

分类记单词:哺乳动物
分类记单词:哺乳动物快来记单词,这里有好多哺乳动物哦一、宠物、家畜 pet 宠物cat 猫tom 公猫;汤姆dog 狗pup 小狗bitch 母狗;泼妇pig 猪sow 母猪;播种boar 未阉的公猪;野猪piglet 小猪livestock 牲口cattl…...

基于硬件虚拟化的AI智能体安全隔离方案Clawcage设计与实现
1. 项目概述:为AI智能体打造一个坚不可摧的“笼子”如果你最近在尝试运行一些本地的AI智能体,比如Claude Desktop、Cursor的Agent模式,或者各种开源的AI助手工具,心里可能总会有点打鼓。这些工具功能强大,但它们背后运…...

终端里的编程副驾:DeepSeek-TUI-项目深度拆解,实测与原理分析
刷 GitHub Trending 又看到一个挺有意思的东西:DeepSeek-TUI。说白了,就是把 DeepSeek V4 这个编程大模型,直接塞进了你的终端里。 这玩意儿不是简单的 CLI 包装。我跑了一下 curl 看 README,发现他们搞了个完整的 TUI(…...