自然语言处理——英文文本预处理
高质量数据的重要性
数据的质量直接影响模型的性能和准确性。高质量的数据可以显著提升模型的学习效果,帮助模型更准确地识别模式、进行预测和决策。具体原因包括以下几点:
- 噪音减少:高质量的数据经过清理,减少了无关或错误信息,这可以降低模型学习过程中的干扰,从而提高模型的准确性。
- 一致性:一致的数据格式和规范化处理使模型能够更有效地学习特征,避免因数据格式不一致带来的混淆和误差。
- 代表性:高质量的数据集通常具有良好的代表性,能够覆盖更多的实际场景和情况,使模型在训练过程中接触到更多的可能性,提高其泛化能力。
- 复杂性处理:高质量的数据能帮助模型更好地处理数据的复杂性,通过正确的标签和特征,可以引导模型识别和学习数据中的复杂模式。
数据标注是将原始数据进⾏加⼯处理,⽐如分类、拉框、注释、标记等操作转换成机器可识别信息的过程。国内数据标注⼚商,⼴义称之为基础数据服务提供商,通常需要完成数据集结构/流程设计、数据处理、数据质检等⼯作,为下游客⼾提供通⽤数据集、定制化服务、数据闭环⼯具链等。这也是本次AIGC数据标注全景报告的研究对象。

数据标注中的⼆⼋定律:通常在一个AI项目中,数据准备工作需要80%时长,模型训练和部署仅占20% 。

本文主要介绍再自然语言处理中的英文文本处理。

英文文本相关技术
文本预处理是自然语言处理 (NLP) 中的一个关键步骤,旨在清理和规范化原始文本数据,以便后续的分析和建模。以下是常见的文本预处理步骤:
英文文本预处理
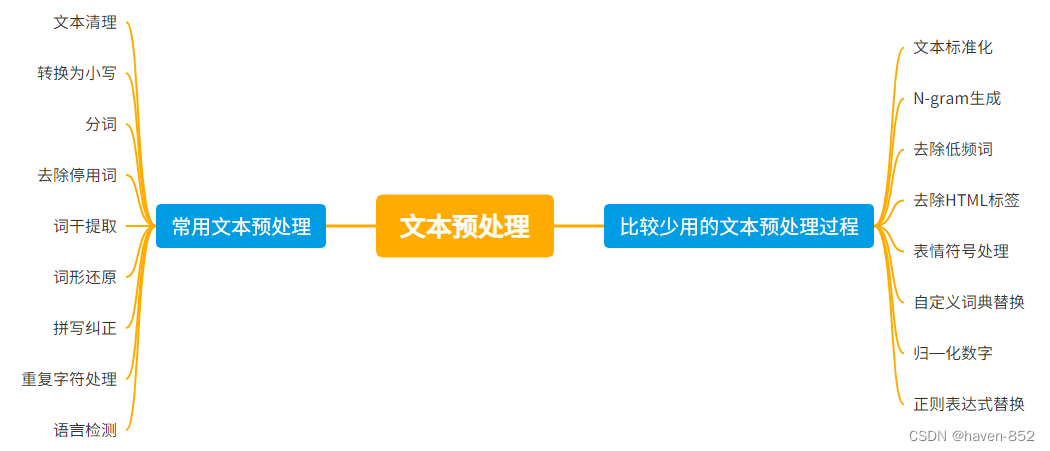
文本清理 (Text Cleaning):
去除标点符号 (Removing Punctuation):删除文本中的标点符号。
去除数字 (Removing Numbers):删除或替换文本中的数字。
去除多余的空格 (Removing Extra Whitespace):规范化空格,去除多余的空格。
去除特殊字符 (Removing Special Characters):删除或替换文本中的特殊字符。
转换为小写 (Lowercasing):
将所有文本转换为小写,以确保一致性。
分词 (Tokenization):
将文本分割成单个单词或标记(tokens)。
去除停用词 (Removing Stopwords):
删除常见的无意义词(如“the”、“is”、“and”)以减少噪音。
词干提取 (Stemming):
将单词还原为词干形式,如“running”变为“run”。
词形还原 (Lemmatization):
将单词还原为其基本形式(词元),如“better”还原为“good”。
拼写纠正 (Spelling Correction):
纠正文本中的拼写错误。
文本标准化 (Text Normalization):
处理缩写和俚语,将其转换为标准形式。
N-gram 生成 (N-gram Generation):
创建连续的 N 个单词的组合,以捕捉上下文信息。
去除低频词 (Removing Rare Words):
删除出现频率很低的单词,以减少噪音和数据维度。
去除 HTML 标签 (Removing HTML Tags):
在处理网页文本时,去除 HTML 标签。
表情符号处理 (Handling Emojis):
识别和处理表情符号,将其转换为文本描述或删除。
重复字符处理 (Handling Repeated Characters):
处理文本中重复的字符,如将“loooove”转换为“love”。
自定义词典替换 (Custom Dictionary Replacement):
使用自定义词典将特定短语或俚语替换为标准形式。
语言检测 (Language Detection):
检测并处理多语言文本,选择性地处理特定语言的文本内容。
归一化数字 (Normalization of Numbers):
统一处理数字表示形式,如将“twenty”转换为“20”。
正则表达式替换 (Regular Expression Replacement):
使用正则表达式进行复杂的文本替换或模式匹配。
其他文本相关技术
主题建模 (Topic Modeling):
使用主题建模技术(如 LDA)提取文本中的主题,以简化文本表示。
特征提取 (Feature Extraction):
使用 TF-IDF、词嵌入(如 Word2Vec、GloVe)或句子嵌入(如 BERT)等技术将文本转换为数值特征向量。
这些步骤的具体选择和顺序可能会根据具体的任务和数据集而有所不同,但上述步骤提供了一个全面的文本预处理流程概览。
文本拆分 (Text Segmentation):
尤其是在处理中文文本时,将连续的汉字分割成独立的词语。
实体识别 (Named Entity Recognition, NER):
识别文本中的专有名词,如人名、地名、机构名等。
情感分析 (Sentiment Analysis):
预处理过程中标记文本的情感极性,如积极、消极、中性。
话题过滤 (Topic Filtering):
只保留或删除特定话题相关的文本片段。
特定领域术语处理 (Domain-Specific Term Handling):
处理特定领域的术语和缩写,确保其正确解析和分析。
处理否定 (Handling Negations):
在情感分析中特别重要,标记或处理否定词以正确捕捉其影响。
上下文扩展 (Context Expansion):
使用上下文信息扩展或解释单词的含义,增强文本理解。
这些步骤可以根据具体的应用场景和文本数据的特点进行选择和组合,以实现最佳的文本预处理效果。
希望各位能不吝啬轻轻的点赞,这将是我后续更新博客的动力。
相关文章:
自然语言处理——英文文本预处理
高质量数据的重要性 数据的质量直接影响模型的性能和准确性。高质量的数据可以显著提升模型的学习效果,帮助模型更准确地识别模式、进行预测和决策。具体原因包括以下几点: 噪音减少:高质量的数据经过清理,减少了无关或错误信息…...
2024年二级建造师机电工程专业历年考试题库精选答案解析。
1.根据《标准施工招标文件》,关于施工合同变更权和变更程序的说法,正确的是()。 A.发包人可以直接向承包人发出变更意向书 B.承包人书面报告发包人后,可根据实际情况对工程进行变更 C.承包人根据合同约定࿰…...
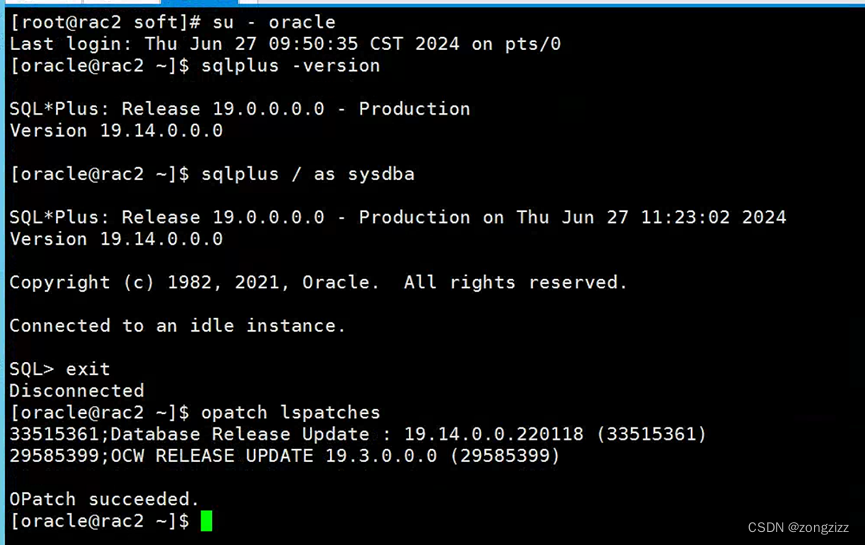
Oracle 19C19.3 rac安装并RU升级到19.14
19C支持RU补丁安装。 下载好19.14的RU补丁 [rootrac1 soft]# ll total 9830404 -rw-r--r-- 1 grid oinstall 3059705302 Jun 18 15:26 LINUX.X64_193000_db_home.zip -rw-r--r-- 1 grid oinstall 2889184573 Jun 18 15:27 LINUX.X64_193000_grid_home.zip -rw-r--r-- 1 grid …...

1012:Joseph
网址如下: OpenJudge - 1012:Joseph 其中一个解法 只想到了一个快速找到下一位处决的人的方法,本质上还是遍历,暂时没想到更优的方法了 代码如下: #include<cstdio> int k;bool judge(int tt, int m, int r){if(tt k) …...
)
【高级篇】备份与恢复:守护数据的长城(十一)
引言 在上一章《性能优化》中,我们深入探讨了如何通过调整查询、优化索引和配置服务器参数等手段,提升MySQL的运行效率。然而,再高效的数据处理能力也无法抵御硬件故障、软件错误或人为失误带来的数据损失。因此,建立健全的备份与恢复机制是确保数据安全和业务连续性的关键…...

Docker构建多平台镜像
docker的多架构镜像构建 目前很多服务器都是基于arm架构的,而现在大多数的docker镜像都是基于x86架构的。一种情况就是同样的代码编译成业务包做成镜像需要部署在不同架构的服务器上,这个时候我们就可以使用docker的多平台构建了。 以下操作是在centos7.…...

群体优化算法---石墨烯优化算法介绍以及在期权定价上的应用(Black-Scholes模型来计算欧式期权的理论价格)
介绍 石墨烯算法是一种新兴的优化算法,灵感来自于石墨烯的结构和特性。石墨烯是一种由碳原子构成的二维蜂窝状晶格结构,具有优异的机械、电学和热学性能。石墨烯算法通过模拟石墨烯原子之间的相互作用和迁移,来求解复杂的优化问题 基本概念…...

创纪录!沃飞长空完成新一轮融资,实力获资方认可
作为全球竞逐的战略性新兴产业,今年首次写入政府工作报告的“低空经济”热度正持续提升,在政策、产业等多个层面均有重大突破。行业的飞速发展也吸引了投资界的目光,越来越多资本正投向低空经济。 近期,国内领先的低空出行企业吉…...
1991java Web体检预约管理系统eclipse定制开发mysql数据库BS模式java编程jdbc
一、源码特点 JSP体检预约管理系统是一套完善的web设计系统,对理解JSP java 编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为TOMCAT7.0,eclipse开发,数据库为Mysql5.0,使用…...

如何优雅终止线程/线程池
如何优雅终止线程 分为两个阶段终止线程 1、interrupted(): 让线程从休眠状态转换到RUNNABLE 状态 2、线程终止的标志位:线程会在合适的时机检查这个标志位,如果发现符合终止条件,则自动退出 run() 方法 public class MonitorThread extends Thread {/…...
泰迪智能科技实验室产品-云计算资源管理平台介绍
云计算资源管理平台是一款集群应用程序管理平台,以Docker、Kubernetes为核心引擎的容器化应用部署、运行环境,对数据中心的物理服务器、网络、存储、虚拟服务器等基础架构资源进行集中统一的管理、分配、监控等。平台旨在围绕行业应用逐步由“虚拟化”向…...

.Net WebApi启动 Swagger异常报错: Failed to load API definition
问题描述: 基于.Net6.0的WebApi 启动Swagger报错:Failed to load API definition。即无法加载API定义。 解决方法: 分析程序输出日志: 错误信息: ERROR Microsoft.AspNetCore.Diagnostics.DeveloperExceptionPageMid…...
CSS新手入门笔记【导入方法、选择器介绍、选择器优先级、属性详细介绍、盒子模型】
目录 一、目的与优势二、CSS导入方式三、语法结构四、选择器类型基本选择器组合选择器伪类与伪元素属性选择器 六、选择器优先级总结 六、CSS属性1. 字体与文本属性2. 背景属性3. 尺寸与盒模型属性4. 布局与定位5. 列表样式6. 边框与轮廓7. 文本装饰与效果8. 动画与过渡9. 伪类…...

制作高校专属PPT时,如何将校徽设置成透明底色?无须PS
目录 示例:以清华大学为例 1必应搜索“清华大学校徽” 2保存清华大学校徽及校名。 3将校徽导入到PPT中 4 选中校徽,然后依次选择“图片格式”-->颜色-->设置透明色编辑 5出现“画笔”,由于截图的缘故,画笔没有在截…...

设计模式之【适配器模式】
类适配器实现(继承) 类适配器通过继承来实现适配器功能 // 目标接口 public interface Target {void request(); }// 被适配者 public class Adaptee {public void specificRequest() {System.out.println("Adaptee: specificRequest");} }/…...
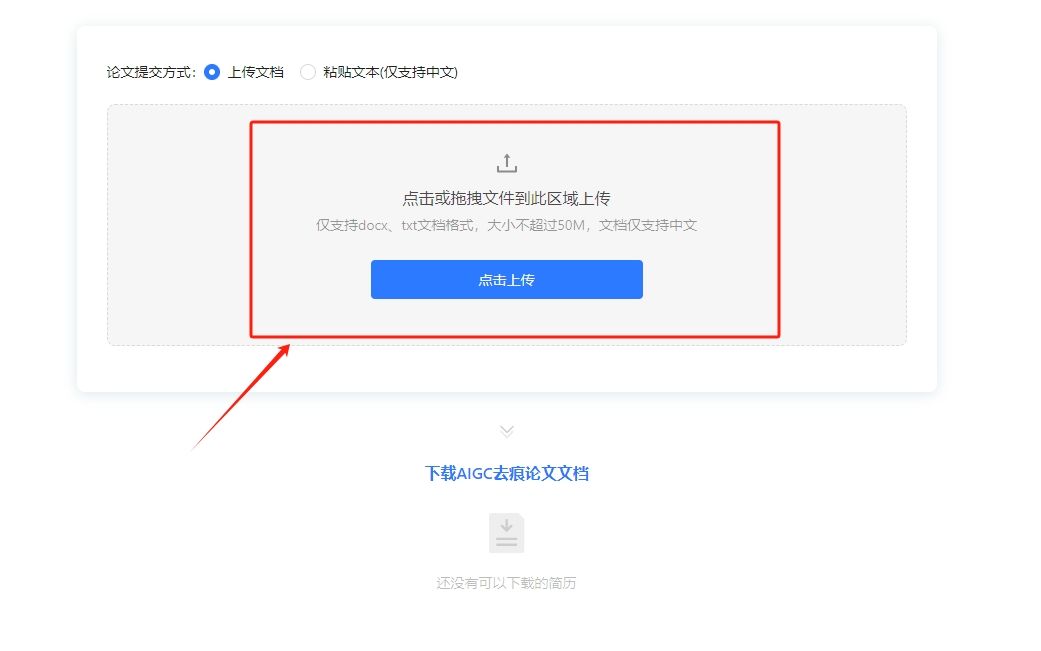
AI论文降重:一键操作,让你的论文查重率瞬间下降
高查重率是许多毕业生的困扰。通常,高查重率源于过度引用未经修改的参考资料和格式错误。传统的降重方法,如修改文本和增添原创内容,虽必要但耗时且成效不一。 鉴于此,应用AI工具进行AIGC降重成为了一个高效的解决方案。这些工具…...

Cmake--学习笔记
🚀write in front🚀 🔎大家好,我是黄桃罐头,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝…...

LangChain让LLM带上记忆
最近两年,我们见识了“百模大战”,领略到了大型语言模型(LLM)的风采,但它们也存在一个显著的缺陷:没有记忆。 在对话中,无法记住上下文的 LLM 常常会让用户感到困扰。本文探讨如何利用 LangCha…...
Word恢复历史文档,记好4个方法就足够
“我正在准备一个重要的报告,但是电脑突然就崩溃了,导致我的文档还没保存就被关闭了,大家有什么方法可以恢复Word历史文档吗?快给我出出主意吧!” 在数字化时代,文档编辑和保存已经成为我们日常工作和学习中…...
收银系统源码-千呼新零售2.0【线上营销】
千呼新零售2.0系统是零售行业连锁店一体化收银系统,包括线下收银线上商城连锁店管理ERP管理商品管理供应商管理会员营销等功能为一体,线上线下数据全部打通。 适用于商超、便利店、水果、生鲜、母婴、服装、零食、百货等连锁店使用。 详细介绍请查看&a…...

Agent-Layer:构建多智能体协作系统的中间层框架设计与实践
1. 项目概述:Agent-Layer 是什么,以及它想解决什么问题最近在开源社区里,一个名为lopushok9/Agent-Layer的项目引起了我的注意。乍一看这个标题,你可能会想,这又是一个关于“智能体”或“代理”的框架吧?确…...

Deep Lake:统一多模态AI数据存储与向量检索的实践指南
1. 项目概述:Deep Lake,一个为AI而生的数据湖 如果你正在构建一个需要处理图像、文本、音频、PDF,甚至医学影像DICOM文件的大模型应用,或者你在训练一个需要高效加载海量数据的深度学习模型,那么你很可能正被数据管理…...

Dify工作流构建指南:从业务需求到可运行AI应用的全流程解析
1. 项目概述:从业务需求到可运行工作流的全栈构建器如果你正在使用 Dify 这类低代码 AI 应用开发平台,大概率遇到过这样的困境:脑子里有一个清晰的业务想法,比如“我想做一个能自动处理客服工单并生成摘要的机器人”,但…...

基于大语言模型的自动化信息处理系统:从RSS聚合到AI摘要的实践
1. 项目概述:一个能帮你“读”新闻的AI助手 在信息爆炸的时代,每天光是处理订阅的RSS、关注的社交媒体动态、收藏的YouTube视频和没读完的长文,就足以让人精疲力尽。我们总想保持对行业趋势的敏感,却又被海量信息淹没,…...

CocoaPods终极版本管理指南:掌握语义化版本控制与依赖锁定策略
CocoaPods终极版本管理指南:掌握语义化版本控制与依赖锁定策略 【免费下载链接】CocoaPods The Cocoa Dependency Manager. 项目地址: https://gitcode.com/gh_mirrors/co/CocoaPods CocoaPods是iOS和macOS开发中最受欢迎的依赖管理器,它通过智能…...

量子信号处理技术及其在离子阱系统中的应用
1. 量子信号处理技术概述量子信号处理(Quantum Signal Processing, QSP)是近年来量子计算领域涌现的一项基础性技术,它通过精心设计的量子比特旋转序列,实现对量子数据的系统性多项式变换。这项技术的核心价值在于,它为…...

ClawSuite:模块化网络安全工具集在渗透测试中的实战应用
1. 项目概述:ClawSuite,一个被低估的网络安全工具集如果你在网络安全领域摸爬滚打了一段时间,尤其是在渗透测试或者红队评估的圈子里,你大概率听说过或者用过像 Metasploit、Nmap、Burp Suite 这些耳熟能详的“瑞士军刀”。但今天…...

嵌入式产品如何通过RTOS选型抢占市场先机
1. 项目概述:为什么“上市时机”是嵌入式产品的生死线在嵌入式系统开发这个行当里摸爬滚打了十几年,我见过太多团队把“功能实现”和“性能达标”作为项目的终极目标,却在一个更根本的问题上栽了跟头:上市时机。你可能觉得&#x…...

基于大语言模型的银行对账单自动化分析与财务预测实战
1. 项目概述:当大语言模型遇上个人财务分析最近在GitHub上看到一个挺有意思的项目,叫“AI银行对账单文档自动化与个人财务分析预测”。光看这个标题,就能感觉到一股浓浓的“技术赋能生活”的味道。简单来说,这个项目想干的事儿&am…...
)
告别启动盘识别难题:手把手教你搞定CentOS 7在SR650上的UEFI启动与自定义分区(含/dev/sdX查找技巧)
告别启动盘识别难题:手把手教你搞定CentOS 7在SR650上的UEFI启动与自定义分区(含/dev/sdX查找技巧) 在服务器运维领域,系统安装看似基础却暗藏玄机。特别是当面对企业级硬件如Lenovo SR650时,UEFI启动模式与传统BIOS的…...